一种基于神经网络的容器挖矿异常检测方法及系统
文献发布时间:2023-06-19 12:14:58
技术领域
本发明设计一种基于神经网络的容器挖矿异常检测方法及系统,属于容器入侵检测领域。
背景技术
近年来,随着云计算的快速发展及“云原生”概念的普及,越来越多企业选择将应用和服务部署到轻量快捷的容器中,以完成迁移到云上,同时其部署规模处于一直增长的趋势。但容器是在软件层面实现隔离,安全保护性差;且共享宿主机内核,因此一旦容器中出现恶意行为,之后将会危害到集群中的所有容器及物理机,因此容器的异常检测变得至关重要,成为了学术界、工商业界的一大研究热点。
容器由两部分构成——镜像和容器运行时。镜像是一种分层结构,各个层保存着应用程序和库之间的关联关系,整体代表着应用程序未运行时的静止状态;容器运行时实质是镜像通过容器引擎与宿主机内核交互,实现应用程序的运行,指的是应用程序运行中的状态。目前对于容器的异常检测主要从这两部分开展。
从镜像方面的入侵检测,目前多采用静态扫描方式,如业界主流静态扫描工具Clair。其工作原理是扫描镜像层中的软件安装目录,将已安装的软件信息及版本信息与CVE漏洞数据库进行对比,判断镜像的威胁性。此种方法只能检测出重大的公开的软件漏洞的威胁,无法对未公开或人为制造的恶意操作进行检测。
另一种是从容器运行时进行检测,由于容器基于软件隔离且共享宿主机内核,因此其运行时的行为都需要与内核通过系统调用交互,来完成对硬件资源的操作。所以系统调用序列可以表征容器的行为,此种方式可以更细致捕捉到容器的行为,检测更为全面,可以弥补上述方式的不足。所以学术界和业界目前也是有着这方面的研究趋势,但目前此种检测方法有以下不足
1缺少容器挖矿行为数据
以往研究对于容器的异常检测,只关注了两种行为,正常行为和对容器造成攻击的异常行为。但随着近年来,容器逐渐成熟且规模逐渐扩展,发现了容器中存在着恶意传播的挖矿程序,其表现形式与正常行为无差别,但是却抢占其他容器资源、大量耗费着宿主机的资源,带来大量的资源、金钱损失。同时由于云环境中容器规模庞大,存在着各种高负载应用,所以很难辨别哪个容器为恶意挖矿容器。因此目前缺少容器挖矿行为的系统调用序列数据。
2现有检测方案精度低
对于容器异常行为的检测,以往研究主要有几种方式:1)基于规则,人为制定检测规则,因此其制定的范围有限;2)基于异常检测,利用正常行为建立基线来区别异常,但其偏离基线的阈值难以确定,同时误报率高;3)基于特征检测,利用n-gram分割异常序列,之后通过统计学习算法计算相似度,此方案只关注了序列的局部性,忽略了全局特征,精度较低;4)基于神经网络方法,目前多采用RNN模型,只关注了全局特征,忽略局部特征,精度较低。综上,以往研究的方案都只关注容器行为系统调用序列的某一部分特征,未对局部、全局等特征全面考虑,精度偏低。
因此如何分析提取挖矿容器的行为特征,设计一种合适的方案来检测容器中的挖矿异常,来保障云环境的安全,成为了目前亟待解决的技术问题。
发明内容
本发明所要解决的技术问题是针对现有容器挖矿数据缺失和异常检测精度低的不足,提出一种基于神经网络的容器挖矿异常检测方法及系统。本发明提供容器挖矿行为系统调用数据采集分析处理的整套方案,同时设计了基于神经网络的异常检测方案,完成挖矿行为的准确检测,从而实现云环境的安全防护。
本发明的技术方案为:
一种基于神经网络的容器挖矿异常检测方法,包括以下步骤:
步骤1:数据采集:构建挖矿容器的运行环境,采集不同系统上多种挖矿容器的系统调用数据并进行预处理,得到系统调用序列;
步骤2:挖矿行为特征分析:对于不同的挖矿容器,对系统调用序列进行分析,统计不同长度子序列和对应频率之间的集合,按照频率大小排序,提取频率处于中间一定范围的子序列作为挖矿行为的核心范围数据,并将该范围内的子序列的最大值作为最大边界长度,利用该最大边界长度截取所述核心范围附近的数据,将核心范围数据和核心范围附近的数据共同组建为挖矿行为模式数据集,并将该最大边界长度作为实时采集时的采集粒度;
步骤3:数据合并:将挖矿行为模式数据集与已公开的或自行采集的系统调用数据集进行整合,形成一全量数据集;
步骤4:模型设计及训练:利用所述全量数据集对基于神经网络的挖矿行为检测模型进行训练,提取容器系统调用序列中的特征,同时调整模型参数,提高模型判别精度;
步骤5:异常行为检测:将训练好的挖矿行为检测模型部署到云环境中,按照所述采集粒度实时采集容器挖矿行为数据,并进行异常行为的检测。
进一步地,采用云环境所使用的容器引擎和系统环境,部署相应的系统调用采集工具,来构建挖矿容器的运行环境。
进一步地,从官方仓库或私人仓库拉取容器镜像,或寻找挖矿程序自行搭建容器镜像。
进一步地,预处理方法为:提取系统调用数据中的系统调用名称,根据所在系统的系统调用表,将系统调用名称处理为系统调用号。
进一步地,利用定量分析法和滑动窗口法统计不同长度子序列和对应的频率;其中,定量分析法为固定序列的长度,统计其出现频率;滑动窗口法为设定一个固定大小的窗口来进行频率统计,若当前窗口已被统计过,则向前滑动一个窗口的距离进行下一次的频率统计。
进一步地,利用定量分析法和滑动窗口法统计不同长度子序列和对应的频率的步骤包括:
首先固定子序列起点;
然后固定子序列的长度,利用滑动窗口法统计当前长度子序列Si的频率Pi,用元组记录其统计信息(Si,Pi);若当前子序列频率不为1,则更改当前子序列的长度,保持起点不变,再统计频率,记录此时的统计信息(Sj,Pj);重复该过程,直至出现频率为1时停止;
最后更改子序列的起始点,在当前起始点向后滑动1步,按照上述步骤继续统计,直至最后序列全部统计结束,得到子序列和对应频率之间的集合C={(Si,Pi),(Sj,Pj)…}。
进一步地,通过建立不同系统间的映射表,来将挖矿行为模式数据集与已公开的或自行采集的系统调用数据集进行整合。
进一步地,基于神经网络的挖矿行为检测模型,采用Attention机制对系统调用序列中的低频信息加强关注,采用CNN网络提取系统调用序列中的局部时序性信息,采用Bi-LSTM提取系统调用序列中的全局时序性信息,采用全连接层接收全局时序性信息并通过softmax分类器对容器行为进行判别分类。
进一步地,将训练好的挖矿行为检测模型部署到云环境中时,采用容器形式或守护进程形式。
一种基于神经网络的容器挖矿异常检测系统,包括:
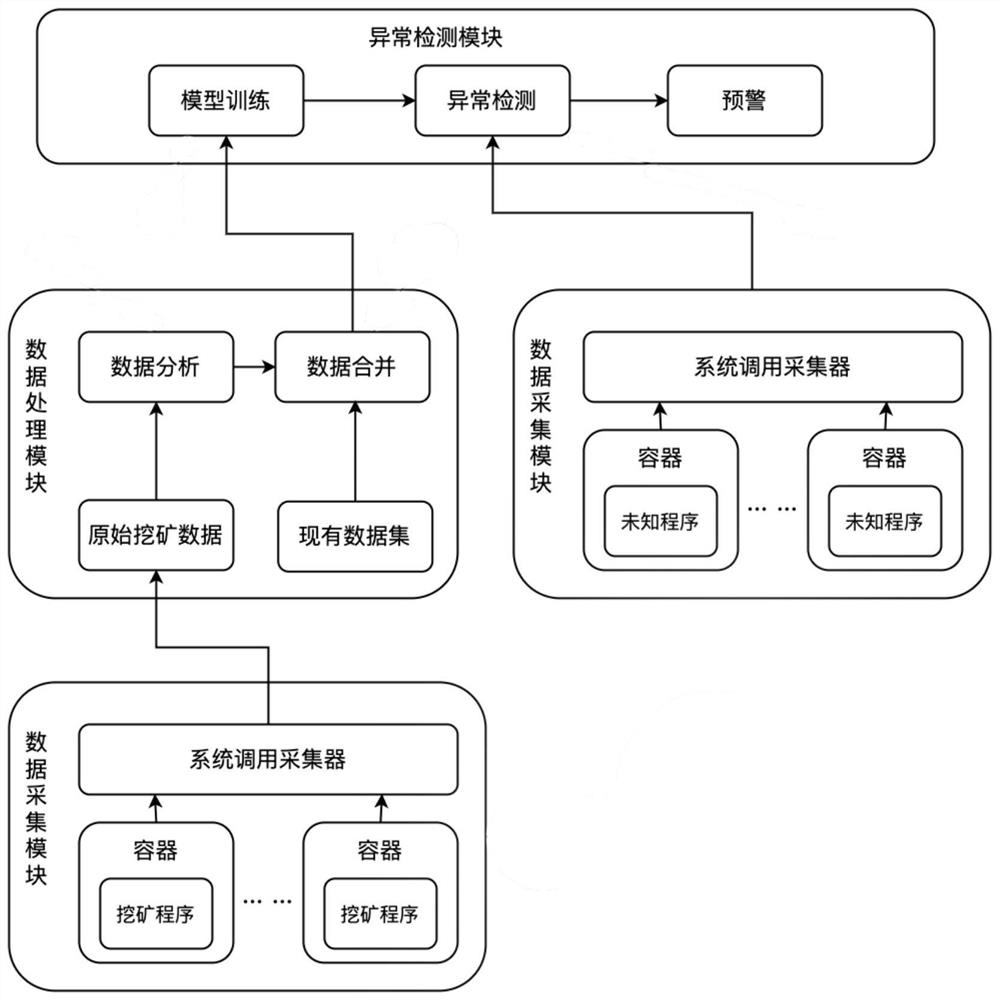
数据采集模块,包括挖矿容器和系统调用采集器,该数据采集模块负责构建挖矿容器的运行环境并运行挖矿容器,该系统调用采集器负责采集不同系统上多种挖矿容器的系统调用数据并进行预处理,得到系统调用序列;
数据处理模块,包括数据分析子模块和数据合并子模块,该数据分析子模块负责对不同挖矿容器采集到的系统调用序列进行分析,统计不同长度子序列和对应频率之间的集合,按照频率大小排序,提取频率处于中间一定范围的子序列作为挖矿行为的核心范围数据,并将该范围内的子序列的最大值作为最大边界长度,利用该最大边界长度截取所述核心范围附近的数据,将核心范围数据和核心范围附近的数据共同组建为挖矿行为模式数据集,并将该最大边界长度作为实时采集时的采集粒度;该数据合并子模块负责将挖矿行为模式数据集与已公开的或自行采集的系统调用数据集进行整合,形成一全量数据集;
异常检测模块,包括模型训练子模块、异常检测子模块和预警子模块,该模型训练子模块负责利用全量数据集对基于神经网络的挖矿行为检测模型进行训练,逐步调整模型参数,提高模型的判别精度;该异常检测子模块包括基于神经网络的挖矿行为检测模型,并负责按照采集粒度实时采集容器挖矿行为数据,并进行异常行为的检测;该预警子模块负责当检测到容器挖矿行为异常时进行预警。
与现有技术相比,本发明的积极效果为:
1)提出容器挖矿行为采集分析的完整流程,弥补现有业界挖矿数据缺失的空白;
2)提出挖矿数据与现有数据的合并方案,丰富现有数据集的特征;
3)设计一种新型基于神经网络的容器异常行为检测模型,更全面利用容器系统调用序列的特征,实现全面、准确的检测;
附图说明
图1为本发明实施例的基于神经网络的容器挖矿异常检测系统的整体架构图。
图2为本发明实施例的定量分析法和滑动窗口法分析系统调用序列的流程图。
图3为本发明实施例的挖矿行为检测模型处理数据的整体流程图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
本实施例公开一种基于神经网络的容器挖矿异常检测方法,其可以基于图1所示的一种系统来实现,该系统包括数据采集模块(包括容器和系统调用采集器)、数据处理模块(包括数据分析和数据合并子模块)和异常检测模块(包括模型训练子模块、异常检测子模块和预警子模块),该方法包括如下步骤:
步骤1:数据采集:构建容器挖矿环境,采集不同系统上多种挖矿容器的系统调用数据并预处理;
步骤2:挖矿行为特征分析:对于不同的挖矿容器,对上面采集到系统调用序列进行分析,提取不同挖矿行为的模式,确定采集的粒度;
步骤3:数据合并:将采集到的容器挖矿行为的系统调用数据与已有的或自行采集的正常异常系统调用数据集进行整合,形成一全量数据集,用于之后的检测模型训练;
步骤4:模型设计及训练:利用多种神经网络模型更细化提取容器系统调用序列中的特征,同时调整模型参数,提高模型判别精度;
步骤5:异常行为检测:将训练好的模型部署到云环境中,实时采集容器行为并进行检测报警。
下面结合实例描述本发明的具体流程:
假设目前有很多比特币挖矿容器,以其中一个为例,如比特币的挖矿程序bitcoin,展示整个从数据采集、数据分析到模型训练的过程,具体步骤如下:
步骤1中容器挖矿行为的系统调用序列数据采集的具体步骤如下:
步骤11:环境搭建及采集工具部署,容器引擎选择为目前业界主流引擎Docker,运行的系统环境为Centos 7;接下来部署相应的系统调用采集工具,本案例采用一个Linux系统性能分析工具sysdig,之后验证其采集性能,这样完成基础环境的部署;
步骤12:运行挖矿容器,从Docker官方仓库通过docker pull命令拉取bitcoin镜像,之后配置相应的个人账户等信息,实现容器的正常运行,之后利用sysdig实现对此容器的系统调用数据采集;
步骤13:数据预处理,上述采集到的系统调用数据会包含着很多冗余的信息,如“3998910:11:57489706584 4sshd(15008)
步骤2中挖矿行为特征分析的具体步骤如下:
步骤21:寻找挖矿行为系统调用序列中的重复模式。由于上述采集到容器行为的系统调用序列是一直连续的,无法界定哪段序列更能表现容器的挖矿行为。
因此利用挖矿需要周期性Pow(工作量证明)算法,行为有非常强的周期性的特点,对采集的完成容器行为的系统调用序列进行分析。因此需要寻找到频率高、长度长的子序列,频率高是要满足挖矿行为强重复性特点,长度长是为了更好覆盖容器的挖矿行为。由于这两者处于反比关系,就是长度短的子序列出现的频率高,长度长的子序列出现的频率低,所以难以直接获取到长度长、频率高的子序列,因此采用定量分析法和滑动窗口法进行分析。
定量分析法指的是固定子序列长度,统计其出现频率;滑动窗口法指的是进行频率统计时,若当前窗口已被统计过,则向前滑动一个窗口的距离,而不是滑动距离为1,这样避免了重复统计。
具体算法流程如图2所示,首先固定子序列起点,然后固定子序列的长度,利用滑动窗口法统计当前长度子序列Si的频率Pi,用元组记录其统计信息(Si,Pi);若当前子序列频率不为1,则更改当前子序列的长度,但并不更改起点,之后统计频率,记录此时(Sj,Pj);重复此过程,直至出现频率为1时停止,这是因为起点不变继续增长子序列长度,其频率只会降低,所以之后全部为1,没有必要统计下去;之后更改子序列的起始点,就是在当前起始点向后滑动1,按照上述方法继续统计,直至最后序列全部统计结束,得到子序列和频率之间的集合C={(Si,Pi),(Sj,Pj)……}。
步骤22:建立挖矿行为模式数据集。由于频率高对应的子序列长度偏短,频率低对应的子序列长度过长,因此利用上面获得的系统调用子序列和其频率的集合C,按照频率Pi大小对此集合进行排序,取其频率居中的系统调用子序列部分作为挖矿行为的核心范围数据,同时确定取该范围内子序列的最大值作为最大边界长度,用来截取核心范围附近的数据,共同组建挖矿行为模式数据集,同时该边界长度也作为实时采集时的采集粒度。
步骤3中数据集合,由于已有公开数据集或自采数据集只考虑两种类别(正常、异常),缺少挖矿数据,因此需要与上述采集的挖矿数据集融合,形成一全量数据集。但现有公开数据集或自行采集的数据集,由于时间久远,其与现有挖矿数据采集所用的操作系统版本方面存在着差异,因此不同数据集间相同系统调用号表示含义不同,但由于不同操作系统具有的基础相同功能,因此利用此性质,建立不同系统间的映射表,以完成不同数据集的合并,形成具有挖矿类别的三类别数据集。
本实例将采集的挖矿数据集与2012年的ADFA数据集合并。ADFA数据集中的系统调用序列只关注正常和异常两种行为,正常行为主要关注web等高负载应用,异常行为主要关注黑客攻击及提权攻击等攻击行为,如密码爆破(FTP AND SSH)、添加新的超级用户、Java-Meterpreter、C100 WebShell,未对挖矿行为进行关注。
由于本实例是在Centos 7系统进行的系统调用序列采集,而ADFA是基于Ubuntu1104进行采集,虽然其操作系统不同,但其系统调用的主体功能基本上是一致的,只是系统调用号上有所差异;因此对这两个系统的系统调用列表进行分析,通过名称和语义分析建立起映射表(如以下表1),成功将300个系统调用进行映射,由于挖矿行为利用与正常行为相同的基础系统调用,因此这300个系统的调用足以覆盖挖矿行为,从而完成两种数据集的合并,建立三类别数据集。
表1两个系统之间的映射表
步骤4中设计的神经网络,整体流程如图3所示,具体步骤如下:
步骤41:首先采用Attention机制对系统调用序列中的低频信息加强关注。采用的是self-attention机制,输入为容器行为的系统调用序列,因此公式(1)中的Q、K、V都为相同的系统调用序列输入,T代表转置操作,d
步骤42:之后采用CNN网络提取其中的局部信息。也就是将上述经过Attention获得的信息,通过卷积进行进一步提取。卷积是一种数学运算,其通过滤波器可以提取数据中的局部信息,二维卷积已在图像处理中有广泛应用,一维卷积在文本处理领域有广泛应用。本模型需要对系统调用序列处理,其类似文本时间序列性质,因此采用一维卷积来提取局部信息。
步骤43:最后采用Bi-LSTM提取全局信息。传统RNN用循环的单元来先前的信息连接到到当前的任务上,例如使用过去的时间段来推测对当前段的理解;但却具有长期依赖的问题,随着时间的间隔不断增大时,RNN会丧失到连接到远处信息的能力。
LSTM解决了上述问题,其通过输入门、遗忘门、输出门三个门机制,避免了梯度爆炸和梯度消失,从而解决了远程依赖的问题。但考虑LSTM只是单向捕获序列的长期依赖的特征,因此进一步优化,采用了Bi-LSTM进行双向捕获,得到序列的全局信息。
最后将提取的全局信息输入到全连接层中,通过softmax分类器实现容器正常、异常、挖矿行为的三分类。利用上面得到的三类别数据集进行训练,得到挖矿行为检测模型。
步骤5中异常行为检测,将步骤4得到的挖矿行为检测模型部署到云环境中,可以采用容器形式或守护进程形式,之后利用系统调用采集工具,采集粒度为步骤21中确定的最大边界,将采集到的系统调用序列,输入到检测模型中,可准确检测出bitcoin挖矿异常,完成挖矿异常的检测。
本发明提出了一种基于神经网络的容器挖矿异常检测方法并设计了相应的系统,提供了面向容器场景的挖矿数据采集分析手段以及挖矿异常检测手段,弥补了现有业界挖矿容器数据的空白,并提供了快速、准确的检测方案,为云环境的安全提供保障。利用本发明方法可采集更多的容器挖矿行为数据,细化模型参数调整,实现更精准、全面的检测。
本发明提供了一种基于神经网络的容器异常检测的方法及系统,该方法不限于具体实施例中所述的例子,由本领域技术人员根据本发明的技术方案得出的其他实施例,也在本发明的权利要求的保护范围内。
- 一种基于神经网络的容器挖矿异常检测方法及系统
- 一种基于动态宽度图神经网络的群体传感器异常数据检测方法和系统