一种使用自注意力机制和可变卷积的车道线检测方法
文献发布时间:2023-06-19 18:53:06
技术领域
本发明属于图像处理技术领域,涉及图像车道线检测方法,具体是一种使用自注意力机制和可变卷积的车道检测方法。
背景技术
车道线检测在先今自动驾驶技术中被广泛应用。在深度学习方向上,现代车道线检测方法主要将车道线检测视为像素分割问题。传统CNN模型对于上下文和全局信息的轻视导致了遮挡和强光条件下检测效率降低;SCNN方法虽然注重全局信息提取,但循环计算流程导致计算复杂度上升;UFSA方法将车道线检测过程视为使用全局特征的基于行的选择问题,其将图片进行网格划分,其中一张图像(H,W)尺寸的图像被划分为尺寸(h,w)的网格,其中h、w远小于H、W。UFSA将像素分割处理变为网格分类处理,其仅关注每个网格的分类,从而大大减小参数量和提高计算速度,显著降低了计算成本。但是其在复杂的culane数据集上F1-score表现仍有提升空间。首先由于UFSA用以提高计算速度的图像网格化方法对于占像素点较少的远处图像无法做到细致的分类;其次其使用ResNet卷积网络作为特征提取的主干网络由于卷积核感受野较小且局限在矩形局部范围内,无法提取到更多全局范围的特征;最后UFSA作者在训练网络时使用的多项式损失函数中包括限制车道线弯曲程度的方法,故检测生成的车道线偏直,在弯道情况下并没有很好的检测表现。
发明内容
本发明的目的是提出一种使用自注意力机制和可变卷积的车道检测方法,解决当前车道线检测技术对于在道路弯道、强光和遮挡等需要更多全局信息的场景中难以做出准确检测的问题。
本发明提供了一种使用自注意力机制和可变卷积的车道线检测方法,包括如下步骤:
S1、获取原始图像数据并构建数据集;
S2、数据集预处理,将原始图像数据经过遮挡、亮度调节、对比度调节、随机噪声生成得到预处理后的图像数据;
S3、预处理后的图像数据作为输入,进行特征提取
S3-1、通过由4个卷积堆叠模块组成的ResNet18提取出后三个卷积模块生成的3个特征图T
S3-2、输出的特征图T
S4、特征融合,由于T
S5、将融合了不同卷积层和自注意力特征的特征图T
S6、车道线预测
以T
M=fc(relu(fc(T
作为优选,所述步骤S3-1中生产的三个特征图T
作为优选,所述步骤S3-2中,自注意力提取的方法为:仅对ResNet最后输出的一个特征图T
T
输出结果通过T
T
其中final_conv为最后经过一层卷积进行特征过滤,得到的最终特征图输出作为T
作为优选,所述步骤S4中,特征融合方法为:
S4-1、通过线性插值法进行上采样到T
S4-2、将尺寸相同的T
S4-3、i=i-1;
S4-4、重复S4-1到S4-3,即得到特征图T
作为优选,所述步骤S5包括如下子步骤:
S5-1、首先将T
S5-2、将T
T
S5-3、将T
S5-4、将T
T
本发明具有以下的特点和有益效果:
通过对自注意力机制、可变卷积方法、多尺度特征融合的结合使用,强化网络对全局信息的提取能力;取消损失计算时先验信息从而减小模型过拟合带来的复杂场景下的误检。本发明对车道线检测数据集culane中弯道、强光、阴影、遮挡等特殊复杂场景均表现出更高的检出性能。
附图说明
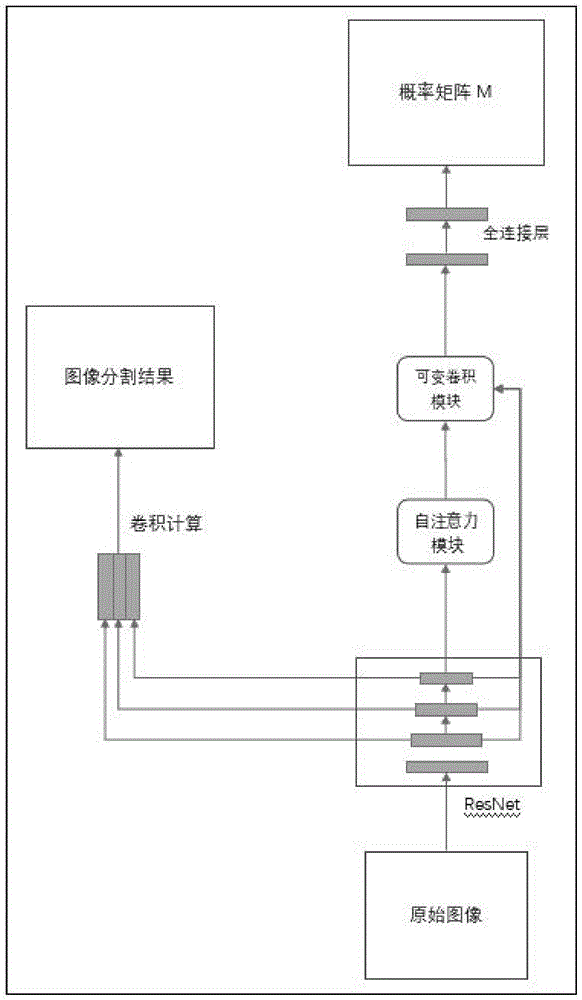
图1是本发明的整体实施方案流程结构图;
图2是本发明实施例中可变卷积处理流程图。
图3、4是本发明实施样例图
具体实施方式
为了更清楚地说明本发明实施例技术方案,下面将对实施例并结合附图作进一步的介绍。
本实施例的主要创新集中在对UFSA的特征提取、训练方法、损失计算修改,创建一个检测表现更优的车道线检测模型。主要通过自注意力机制,特征金字塔(FPN)和可变卷积方法对图像数据做进一步特征提取;通过增加新的计算流程来对可变卷积的结果进行损失计算保证其卷积位置为车道线位置。
首先,在UFSA结构中仅使用了ResNet34作为特征提取的主干网络,而在特征提取之后使用的两层全连接则是用以分类,考虑到卷积网络的感受野较小,对于全局特征提取并不到位的问题,本发明添加自注意力机制网络和可变卷积网络来提高特征提取的感受野,强化全局信息在最终特征图中的占比。另外,基于UFSA在远端弯道上的表现略有不足的现实情况,本发明添加FPN结构用以强化网络对于细微车道的特征提取。
其次,UFSA结构为了更快的计算速度导致其特征提取不够深入,故在损失计算时采用了限制车道线弯曲程度的方法作为先验信息进行结果导向,却对细微弯道和遮挡等场景产生了负面影响。本发明取消限制车道线弯曲程度的损失计算这一先验信息导向,通过前文所提到的更深入的特征提取来让网络自行学习应对复杂场景。
最后添加对可变卷积输出的结果点进行损失计算,保证其卷积位置为车道线位置,使卷积感受野呈“条状”,让卷积过程更关注车道线位置信息。
综合以上方法,本发明提出新的网络结构,对比UFSA,在保证了可用的计算速度同时大大提高了特征提取能力和最终的车道线检测能力,一下为详细的网络结构说明,参照附图1.
1主干特征提取
1-1主干流程接受原始图像数据作为输入,将原始图像数据经过遮挡、亮度调节、对比度调节、随机噪声生成等图像数据增广方法后输入到由ResNet18
1-2ResNet18做初步的特征提取:ResNet由4个相似的卷积堆叠模块组成,提取出后三个模块生成的特征图结果用以后续。故该步骤得到3个特征图T
1-3输出的特征图进行自注意力提取:为了保持原有的计算速度,仅对ResNet最后输出的一个特征图T
T
输出结果通过T
T
其中final_conv为最后经过一层卷积进行特征过滤。得到的最终特征图输出作为T
2特征融合:由于T
2-1通过线性插值法进行上采样到T
2-2将尺寸相同的T
2-3i=i-1
2-4重复2-1到2-3,即得到一个融合了不同卷积层和自注意力特征的特征图T
3可变卷积方法。
3-1首先将T
3-2将T
T
3-3将T
3-4将T
T
4车道线预测阶段。以T
M=fc(relu(fc(T
图像分割损失计算:在本发明1-2中流程中得到了3张特征图T
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式包括部件进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
- 一种基于注意力机制卷积神经网络的自然场景文字检测方法
- 基于注意力机制和可变形卷积神经网络的人群分析方法
- 一种基于注意力机制和可变形卷积的点云目标检测方法
- 基于可变形卷积和注意力机制的视频目标检测方法及装置