文本的分类方法、装置、存储介质及电子设备
文献发布时间:2023-06-19 19:30:30
技术领域
本公开涉及计算机技术领域,具体地,涉及一种文本的分类方法、装置、存储介质及电子设备。
背景技术
针对多分类问题,目前已有的典型小样本学习方法包括自然语言模版法PET(Pattern-Exploting Training)、参数向量模版法P-Tuning,针对标注样本数据集合,训练对应的模型。自然语言模版法PET需要手工构造模版,不同的模版效果差异比较大,而参数向量模版法P-Tuning学习到的模版缺乏可解释性。并且这两种方法只针对标注样本数据集合进行模型训练,对于大量的无标注样本数据,无法进行充分利用。
发明内容
本公开的目的是提供一种文本的分类方法、装置、存储介质及电子设备,用于提高文本分类的准确度。
根据本公开实施例的第一方面,提供一种文本的分类方法,所述方法包括:
获取目标文本;
根据所述目标文本和目标分类模板,得到目标输入数据,所述目标分类模板包括目标参数向量和目标自然语言模板,所述目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,所述第一训练样本数据是标注有类别的样本数据,所述第一预设网络模型包括预设参数向量和预设分类模型;
将所述目标输入数据输入预设的目标文本分类模型,以得到所述目标文本分类模型输出的目标文本类别,所述目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,所述第二训练样本数据是未标注类别的样本数据,所述第二预设网络模型包括所述目标参数向量和所述预设分类模型。
可选地,所述第一训练样本数据包括至少一个预设分类模板;所述目标参数向量和所述目标文本分类模型是通过以下方式确定的:
针对每个所述预设分类模板,根据所述第一训练样本数据对所述第一预设网络模型进行训练,得到所述预设分类模板对应的候选参数向量;
针对每个所述候选参数向量,根据所述第二训练样本数据对所述候选参数向量对应的待用网络模型进行训练,得到所述候选参数向量对应的候选文本分类模型,所述待用网络模型包括所述候选向量参数和所述预设分类模型;
根据预设验证数据集,从所述候选参数向量和所述候选文本分类模型中确定所述目标参数向量和所述目标文本分类模型,所述预设验证数据集包括样本验证文本和所述样本验证文本对应的样本验证类别。
可选地,所述第一训练样本数据包括第一样本输入数据和所述第一样本输入数据对应的第一样本类别;所述根据所述第一训练样本数据对所述第一预设网络模型进行训练,得到所述预设分类模板对应的候选参数向量包括:
根据所述第一样本输入数据和所述第一样本类别对所述第一预设网络模型进行训练,得到所述候选参数向量。
可选地,所述第一样本输入数据包括所述预设分类模板和第一样本文本,所述预设分类模板包括预设参数向量和预设自然语言模板;所述根据所述第一样本输入数据和所述第一样本类别对所述第一预设网络模型进行训练,得到所述候选参数向量包括:
根据所述第一样本文本和所述预设分类模板,得到所述第一样本输入数据;
将所述第一样本输入数据作为所述第一预设网络模型的输入,并将所述第一样本类别作为所述第一预设网络模型的输出,对所述第一预设网络模型进行训练,得到所述候选参数向量。
可选地,所述第二训练样本数据包括第二样本输入数据和所述第二样本输入数据对应的第二样本输出数据;所述根据所述第二训练样本数据对所述候选参数向量对应的待用网络模型进行训练,得到所述候选参数向量对应的候选文本分类模型包括:
针对每个所述候选参数向量,根据所述第二样本输入数据和所述第二样本输出数据对所述待用网络模型进行训练,得到所述候选文本分类模型。
可选地,所述第二样本输入数据包括候选分类模板和第二样本文本,所述候选分类模板包括所述候选参数向量和所述预设自然语言模板;所述第二样本输出数据为从预设样本文本中提取的文本,所述第二样本文本为从所述预设样本文本中提取所述第二样本输出数据之后得到的文本;所述根据所述第二样本输入数据和所述第二样本输出数据对所述待用网络模型进行训练,得到所述候选文本分类模型包括:
根据所述第二样本文本和所述候选分类模板,得到所述第二样本输入数据;
将所述第二样本输入数据作为所述待用网络模型的输入,并将所述第二样本输出数据作为所述待用网络模型的输出,对所述待用网络模型进行训练,得到所述候选文本分类模型。
可选地,所述根据预设验证数据集,从所述候选参数向量和所述候选文本分类模型中确定所述目标参数向量和所述目标文本分类模型包括:
针对每个所述候选参数向量,根据所述样本验证文本和所述候选参数向量对应的所述候选分类模板,得到验证输入数据;
将所述验证输入数据作为所述候选参数向量对应的所述候选文本分类模型的输入,得到所述候选文本分类模型输出的目标验证类别;
根据所述目标验证类别和所述样本验证类别,确定每个候选网络模型的分类准确度,所述候选网络模型包括所述候选参数向量和所述候选参数向量对应的所述候选文本分类模型;
将分类准确度最高的所述候选网络模型中的所述候选参数向量作为所述目标参数向量,并将分类准确度最高的所述候选网络模型中的所述候选文本分类模型作为所述目标文本分类模型。
根据本公开实施例的第二方面,提供一种文本的分类装置,所述装置包括:
获取模块,用于获取目标文本;
输入模块,用于根据所述目标文本和目标分类模板,得到目标输入数据,所述目标分类模板包括目标参数向量和目标自然语言模板,所述目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,所述第一训练样本数据是标注有类别的样本数据,所述第一预设网络模型包括预设参数向量和预设分类模型;
分类模块,用于将所述目标输入数据输入预设的目标文本分类模型,以得到所述目标文本分类模型输出的目标文本类别,所述目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,所述第二训练样本数据是未标注类别的样本数据,所述第二预设网络模型包括所述目标参数向量和所述预设分类模型。
可选地,所述第一训练样本数据包括至少一个预设分类模板;所述目标参数向量和所述目标文本分类模型是通过以下方式确定的:
针对每个所述预设分类模板,根据所述第一训练样本数据对所述第一预设网络模型进行训练,得到所述预设分类模板对应的候选参数向量;
针对每个所述候选参数向量,根据所述第二训练样本数据对所述候选参数向量对应的待用网络模型进行训练,得到所述候选参数向量对应的候选文本分类模型,所述待用网络模型包括所述候选向量参数和所述预设分类模型;
根据预设验证数据集,从所述候选参数向量和所述候选文本分类模型中确定所述目标参数向量和所述目标文本分类模型,所述预设验证数据集包括样本验证文本和所述样本验证文本对应的样本验证类别。
可选地,所述第一训练样本数据包括第一样本输入数据和所述第一样本输入数据对应的第一样本类别;所述根据所述第一训练样本数据对所述第一预设网络模型进行训练,得到所述预设分类模板对应的候选参数向量包括:
根据所述第一样本输入数据和所述第一样本类别对所述第一预设网络模型进行训练,得到所述候选参数向量。
可选地,所述第一样本输入数据包括所述预设分类模板和第一样本文本,所述预设分类模板包括预设参数向量和预设自然语言模板;所述根据所述第一样本输入数据和所述第一样本类别对所述第一预设网络模型进行训练,得到所述候选参数向量包括:
根据所述第一样本文本和所述预设分类模板,得到所述第一样本输入数据;
将所述第一样本输入数据作为所述第一预设网络模型的输入,并将所述第一样本类别作为所述第一预设网络模型的输出,对所述第一预设网络模型进行训练,得到所述候选参数向量。
可选地,所述第二训练样本数据包括第二样本输入数据和所述第二样本输入数据对应的第二样本输出数据;所述根据所述第二训练样本数据对所述候选参数向量对应的待用网络模型进行训练,得到所述候选参数向量对应的候选文本分类模型包括:
针对每个所述候选参数向量,根据所述第二样本输入数据和所述第二样本输出数据对所述待用网络模型进行训练,得到所述候选文本分类模型。
可选地,所述第二样本输入数据包括候选分类模板和第二样本文本,所述候选分类模板包括所述候选参数向量和所述预设自然语言模板;所述第二样本输出数据为从预设样本文本中提取的文本,所述第二样本文本为从所述预设样本文本中提取所述第二样本输出数据之后得到的文本;所述根据所述第二样本输入数据和所述第二样本输出数据对所述待用网络模型进行训练,得到所述候选文本分类模型包括:
根据所述第二样本文本和所述候选分类模板,得到所述第二样本输入数据;
将所述第二样本输入数据作为所述待用网络模型的输入,并将所述第二样本输出数据作为所述待用网络模型的输出,对所述待用网络模型进行训练,得到所述候选文本分类模型。
可选地,所述根据预设验证数据集,从所述候选参数向量和所述候选文本分类模型中确定所述目标参数向量和所述目标文本分类模型包括:
针对每个所述候选参数向量,根据所述样本验证文本和所述候选参数向量对应的所述候选分类模板,得到验证输入数据;
将所述验证输入数据作为所述候选参数向量对应的所述候选文本分类模型的输入,得到所述候选文本分类模型输出的目标验证类别;
根据所述目标验证类别和所述样本验证类别,确定每个候选网络模型的分类准确度,所述候选网络模型包括所述候选参数向量和所述候选参数向量对应的所述候选文本分类模型;
将分类准确度最高的所述候选网络模型中的所述候选参数向量作为所述目标参数向量,并将分类准确度最高的所述候选网络模型中的所述候选文本分类模型作为所述目标文本分类模型。
根据本公开实施例的第三方面,提供一种非临时性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开第一方面中所述方法的步骤。
根据本公开实施例的第四方面,提供一种电子设备,包括:
存储器,其上存储有计算机程序;
处理器,用于执行所述存储器中的所述计算机程序,以实现本公开第一方面中所述方法的步骤。
通过上述技术方案,本公开首先获取目标文本,并根据目标文本和包括目标参数向量和目标自然语言模板的目标分类模板,得到目标输入数据,然后将目标输入数据输入预设的目标文本分类模型,以得到目标文本分类模型输出的目标文本类别。其中,目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,第一训练样本数据是标注有类别的样本数据,第一预设网络模型包括预设参数向量和预设分类模型。目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,第二训练样本数据是未标注类别的样本数据,第二预设网络模型包括目标参数向量和预设分类模型。本公开通过预先训练得到的目标参数向量和目标文本分类模型,确定目标文本对应的目标文本类别,融合了自然语言模版法和参数向量模版法的分类方法,并充分利用了大量未标注的训练数据,能够得到更加准确的文本分类结果。
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。
图1是根据一示例性实施例示出的一种文本的分类方法的流程图。
图2是根据一示例性实施例示出的一种目标参数向量和目标文本分类模型的确定方法的流程图。
图3是根据一示例性实施例示出的一种候选参数向量的确定方法的流程图。
图4是根据一示例性实施例示出的一种候选文本分类模型的确定方法的流程图。
图5是根据一示例性实施例示出的一种目标参数向量和目标文本分类模型的确定方法的流程图。
图6是根据一示例性实施例示出的一种文本的分类装置的框图。
图7是根据一示例性实施例示出的一种电子设备的框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
在介绍本公开示出的文本的分类方法、装置、存储介质及电子设备之前,首先对本公开实施例涉及的应用场景进行介绍。针对投诉文本的多分类问题,输入是用户的投诉文本,例如“有人乱停车”、“小区内部随处可见垃圾”等,输出是投诉文本的分类,分类数量可以有多个,包括“违章停车”、“绿化垃圾”、“路灯不亮”等。目前,针对多分类问题,已有的典型小样本学习方法包括自然语言模版法PET、参数向量模版法P-Tuning,针对标注样本数据集合,训练对应的模型。自然语言模版法PET是通过人工构建的自然语言模版与BERT(英文:Bidirectional Encoder Representation from Transformers,中文:基于双向表示编码算法)模型的MLM模型(英文:Masked Language Model,中文:掩码语言模型)结合,将任务转化为完形填空,来进行小样本学习,但是需要手工构造模版,不同的模版效果差异比较大。参数向量模版法P-Tuning通过使用预训练模型中未使用的字的表示来自动学习到最佳的模板,该方法可以自动学习模版参数,但是学习到的模版缺乏可解释性,而且无法利用人类根据先验知识生成的模版。
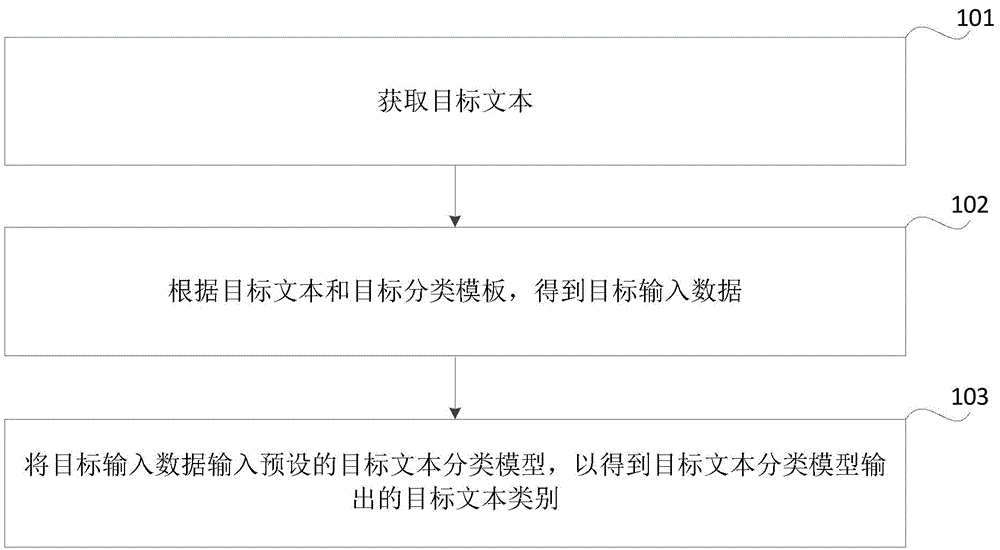
图1是根据一示例性实施例示出的一种文本的分类方法的流程图,如图1所示,该方法可以包括以下步骤。
步骤101,获取目标文本。
步骤102,根据目标文本和目标分类模板,得到目标输入数据。其中,目标分类模板包括目标参数向量和目标自然语言模板,目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,第一训练样本数据是标注有类别的样本数据,第一预设网络模型包括预设参数向量和预设分类模型。
举例来说,首先可以从用户提交的投诉文本中获取目标文本,然后将目标文本和目标分类模板进行拼接,得到目标输入数据。其中,目标分类模板可以包括目标参数向量和目标自然语言模板。例如,目标分类模板可以是“[u
步骤103,将目标输入数据输入预设的目标文本分类模型,以得到目标文本分类模型输出的目标文本类别。其中,目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,第二训练样本数据是未标注类别的样本数据,第二预设网络模型包括目标参数向量和预设分类模型。
示例的,在得到目标输入数据之后,可以将目标输入数据输入预设的目标文本分类模型,从而得到目标文本分类模型输出的目标文本类别。在一些实施例中,目标文本分类模型可以根据第二训练样本数据对第二预设网络模型训练得到,其中,第二预设网络模型可以包括目标参数向量和预设分类模型,也就是说,第二预设网络模型是将第一预设网络模型中的预设参数向量,替换为目标参数向量得到的模型。第二训练样本数据可以是未标注类别的样本数据,通过使用未标注类别的样本数据进行模型训练,微调预设分类模型的参数,可以达到半监督学习的效果。
综上所述,本公开首先获取目标文本,并根据目标文本和包括目标参数向量和目标自然语言模板的目标分类模板,得到目标输入数据,然后将目标输入数据输入预设的目标文本分类模型,以得到目标文本分类模型输出的目标文本类别。其中,目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,第一训练样本数据是标注有类别的样本数据,第一预设网络模型包括预设参数向量和预设分类模型。目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,第二训练样本数据是未标注类别的样本数据,第二预设网络模型包括目标参数向量和预设分类模型。本公开通过预先训练得到的目标参数向量和目标文本分类模型,确定目标文本对应的目标文本类别,融合了自然语言模版法和参数向量模版法的分类方法,并充分利用了大量未标注的训练数据,能够得到更加准确的文本分类结果。
图2是根据一示例性实施例示出的一种目标参数向量和目标文本分类模型的确定方法的流程图,如图2所示,目标参数向量和目标文本分类模型是通过以下步骤确定的。
步骤201,针对每个预设分类模板,根据第一训练样本数据对第一预设网络模型进行训练,得到该预设分类模板对应的候选参数向量。
步骤202,针对每个候选参数向量,根据第二训练样本数据对该候选参数向量对应的待用网络模型进行训练,得到该候选参数向量对应的候选文本分类模型,待用网络模型包括候选向量参数和预设分类模型。
步骤203,根据预设验证数据集,从候选参数向量和候选文本分类模型中确定目标参数向量和目标文本分类模型,预设验证数据集包括样本验证文本和样本验证文本对应的样本验证类别。
示例的,第一训练样本数据中可以包括至少一个预设分类模板,其中,预设分类模板可以包括预设参数向量和预设自然语言模板,可以理解为,预设分类模板是预设参数向量和预设自然语言模板融合得到的模板,每个预设分类模板中的预设自然语言模板可以不同。例如预设分类模板可以包括:“[u
针对每个预设分类模板,可以根据第一训练样本数据对第一预设网络模型进行训练,得到该预设分类模板对应的候选参数向量。其中,每个候选参数向量和预设分类模型可以构成一个待用网络模型,在预设分类模板有P个的情况下,训练得到的候选参数向量可以有P个,相应的,待用网络模型可以有Model
针对每个候选参数向量,可以根据第二训练样本数据对该候选参数向量对应的待用网络模型进行训练,得到该候选参数向量对应的候选文本分类模型。每个候选参数向量和该候选参数向量对应的候选文本分类模型可构成一个候选网络模型。在待用网络模型有Model
最后,可以根据预设验证数据集,从候选参数向量和候选文本分类模型中,确定分类准确度最高的目标参数向量和目标文本分类模型。其中,预设验证数据集可以包括样本验证文本和样本验证文本对应的样本验证类别。在一些实施例中,可以根据预设验证数据集,从候选网络模型中确定分类准确度最高的目标网络模型,然后将目标网络模型中包括的候选参数向量作为目标参数向量,并将目标网络模型中包括的候选文本分类模型作为目标文本分类模型。
在一种实施例中,步骤201的一种实现方式可以为:根据第一样本输入数据和第一样本类别对第一预设网络模型进行训练,得到候选参数向量。
图3是根据一示例性实施例示出的一种候选参数向量的确定方法的流程图,如图3所示,步骤201可以通过以下步骤来实现。
步骤2011,根据第一样本文本和预设分类模板,得到第一样本输入数据。
步骤2012,将第一样本输入数据作为第一预设网络模型的输入,并将第一样本类别作为第一预设网络模型的输出,对第一预设网络模型进行训练,得到候选参数向量。
示例的,第一训练样本数据可以包括第一样本输入数据和第一样本输入数据对应的第一样本类别,第一样本输入数据可以包括预设分类模板和第一样本文本。可以对预设分类模板和第一样本文本进行拼接,得到第一样本输入数据。以预设分类模板为“[u
之后可以将第一样本输入数据作为第一预设网络模型的输入,并将第一样本类别作为第一预设网络模型的输出,根据预设的第一损失函数对第一预设网络模型进行训练,从而得到候选参数向量。在一种实施例中,在训练第一预设网络模型的过程中,可以采用pytorch框架,使用Adam optimizer作为优化器,学习率可以设置为1e-4。首先可以加载第一训练样本数据,并按照预设的batch_size进行数据分批,假设共有M批数据,其中,batch_size例如可以为8,即单次传递给程序用以训练的样本个数为8,预设参数向量的初始值可以为随机取值。
以预设分类模型为BERT模型为例,针对预设参数向量,可以先通过LSTM(英文:Long Short-Term Memory,中文:长短期记忆网络)进行处理,得到预设参数向量对应的隐状态向量h
(公式1)
其中,L
在另一些实施例中,可以将M批数据分别作为训练数据,重复上述训练步骤,从而对参数u更新M次,完成一次epoch运算,即使用第一训练样本数据对第一预设网络模型进行一次完整的训练。按照上面的步骤,可以进行epoch_size=50次训练,通过对参数u进行多次更新,从而得到候选参数向量。
在另一种实施例中,步骤202的一种实现方式可以为:针对每个候选参数向量,根据第二样本输入数据和第二样本输出数据对待用网络模型进行训练,得到候选文本分类模型。
图4是根据一示例性实施例示出的一种候选文本分类模型的确定方法的流程图,如图4所示,步骤202可以通过以下步骤来实现。
步骤2021,根据第二样本文本和候选分类模板,得到第二样本输入数据。
步骤2022,将第二样本输入数据作为待用网络模型的输入,并将第二样本输出数据作为待用网络模型的输出,对待用网络模型进行训练,得到候选文本分类模型。
示例的,第二训练样本数据可以包括第二样本输入数据和第二样本输入数据对应的第二样本输出数据,其中,第二样本输入数据可以包括候选分类模板和第二样本文本,候选分类模板可以包括候选参数向量和预设自然语言模板,可以理解为,候选分类模板是用候选参数向量替换预设分类模板中的预设参数向量得到的模板。
首先可以对候选分类模板和第二样本文本进行拼接,得到第二样本输入数据,然后将第二样本输入数据作为待用网络模型的输入,并将第二样本输出数据作为待用网络模型的输出,对待用网络模型进行训练,得到候选文本分类模型。其中,第二样本输出数据可以是从预设样本文本中提取的文本,第二样本文本可以是从预设样本文本中提取第二样本输出数据之后得到的文本。以预设样本文本为“某小区停水,要求尽快恢复”为例,可以提取“尽快”作为第二样本输出数据,并将“某小区停水,要求[M1][M2]恢复”作为第二样本文本。
在一种实施例中,在训练第二预设网络模型的过程中,可以采用pytorch框架,使用Adam optimizer作为优化器,学习率可以设置为1e-4。首先可以加载第一训练样本数据,并按照batch_size进行数据分批,假设共有N批数据,其中,batch_size例如可以为32,即单次传递给程序用以训练的样本个数为32,通过训练可以对预设分类模型中的参数para
以预设分类模型为BERT模型为例,针对每一批第二训练样本数据,可以根据预设的第二损失函数可以得到该批数据对应的损失函数值,根据pytorch的Adam optimizer优化器和学习率设置,可以求解出更新后的参数para
(公式2)
其中,L
在另一些实施例中,可以将N批数据分别作为训练数据,重复上述训练步骤,从而对参数para
图5是根据一示例性实施例示出的一种目标参数向量和目标文本分类模型的确定方法的流程图,如图5所示,步骤203可以通过以下步骤来实现。
步骤2031,针对每个候选参数向量,根据样本验证文本和该候选参数向量对应的候选分类模板,得到验证输入数据。
步骤2032,将验证输入数据作为该候选参数向量对应的候选文本分类模型的输入,得到该候选文本分类模型输出的目标验证类别。
步骤2033,根据目标验证类别和样本验证类别,确定每个候选网络模型的分类准确度,候选网络模型包括候选参数向量和候选参数向量对应的候选文本分类模型。
步骤2034,将分类准确度最高的候选网络模型中的候选参数向量作为目标参数向量,并将分类准确度最高的候选网络模型中的候选文本分类模型作为目标文本分类模型。
示例的,在得到至少一个候选参数向量和每个候选参数向量对应的候选文本分类模型之后,可以从至少一个候选参数向量和候选文本分类模型中确定分类准确度最高的目标参数向量和目标文本分类模型。如果候选参数向量和候选文本分类模型为一个,那么可以将该候选参数向量和候选文本分类模型作为目标参数向量和目标文本分类模型。如果候选参数向量和候选文本分类模型有多个,那么可以根据每个候选网络模型的分类准确度,来确定目标参数向量和目标文本分类模型,其中,每个候选网络模型包括一个候选参数向量和该候选参数向量对应的候选文本分类模型。
在一些实施例中,针对每个候选网络模型,首先可以将样本验证文本和该候选网络模型中候选参数向量对应的候选分类模板进行拼接,得到验证输入数据。然后将验证输入数据作为该候选参数向量对应的候选文本分类模型的输入,得到该候选文本分类模型输出的目标验证类别。再进一步通过目标验证类别和样本验证类别的匹配度,确定每个候选网络模型对应的分类准确度。目标验证类别和样本验证类别的匹配度越高,该目标验证类别对应的候选网络模型的分类准确度就越高,相应的,目标验证类别和样本验证类别的匹配度越低,该目标验证类别对应的候选网络模型的分类准确度就越低。在确定每个候选网络模型的分类准确度之后,可以将分类准确度最高的候选网络模型作为目标网络模型。同时,将目标网络模型中的候选参数向量作为目标参数向量,并将目标网络模型中的候选文本分类模型作为目标文本分类模型。
综上所述,本公开首先获取目标文本,并根据目标文本和包括目标参数向量和目标自然语言模板的目标分类模板,得到目标输入数据,然后将目标输入数据输入预设的目标文本分类模型,以得到目标文本分类模型输出的目标文本类别。其中,目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,第一训练样本数据是标注有类别的样本数据,第一预设网络模型包括预设参数向量和预设分类模型。目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,第二训练样本数据是未标注类别的样本数据,第二预设网络模型包括目标参数向量和预设分类模型。本公开通过预先训练得到的目标参数向量和目标文本分类模型,确定目标文本对应的目标文本类别,融合了自然语言模版法和参数向量模版法的分类方法,并充分利用了大量未标注的训练数据,能够得到更加准确的文本分类结果。
图6是根据一示例性实施例示出的一种文本的分类装置的框图,如图6所示,该装置300可以包括以下模块。
获取模块301,用于获取目标文本。
输入模块302,用于根据目标文本和目标分类模板,得到目标输入数据。其中,目标分类模板包括目标参数向量和目标自然语言模板,目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,第一训练样本数据是标注有类别的样本数据,第一预设网络模型包括预设参数向量和预设分类模型。
分类模块303,用于将目标输入数据输入预设的目标文本分类模型,以得到目标文本分类模型输出的目标文本类别。其中,目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,第二训练样本数据是未标注类别的样本数据,第二预设网络模型包括目标参数向量和预设分类模型。
在一种实施例中,第一训练样本数据包括至少一个预设分类模板。目标参数向量和目标文本分类模型是通过以下方式确定的。
针对每个预设分类模板,根据第一训练样本数据对第一预设网络模型进行训练,得到预设分类模板对应的候选参数向量。
针对每个候选参数向量,根据第二训练样本数据对候选参数向量对应的待用网络模型进行训练,得到候选参数向量对应的候选文本分类模型,待用网络模型包括候选向量参数和预设分类模型。
根据预设验证数据集,从候选参数向量和候选文本分类模型中确定目标参数向量和目标文本分类模型,预设验证数据集包括样本验证文本和样本验证文本对应的样本验证类别。
在另一种实施例中,第一训练样本数据包括第一样本输入数据和第一样本输入数据对应的第一样本类别。根据第一训练样本数据对第一预设网络模型进行训练,得到预设分类模板对应的候选参数向量包括:根据第一样本输入数据和第一样本类别对第一预设网络模型进行训练,得到候选参数向量。
在另一种实施例中,第一样本输入数据包括预设分类模板和第一样本文本,预设分类模板包括预设参数向量和预设自然语言模板。根据第一样本输入数据和第一样本类别对第一预设网络模型进行训练,得到候选参数向量包括以下步骤。
根据第一样本文本和预设分类模板,得到第一样本输入数据。
将第一样本输入数据作为第一预设网络模型的输入,并将第一样本类别作为第一预设网络模型的输出,对第一预设网络模型进行训练,得到候选参数向量。
在另一种实施例中,第二训练样本数据包括第二样本输入数据和第二样本输入数据对应的第二样本输出数据。根据第二训练样本数据对候选参数向量对应的待用网络模型进行训练,得到候选参数向量对应的候选文本分类模型包括:针对每个候选参数向量,根据第二样本输入数据和第二样本输出数据对待用网络模型进行训练,得到候选文本分类模型。
在另一种实施例中,第二样本输入数据包括候选分类模板和第二样本文本,候选分类模板包括候选参数向量和预设自然语言模板。第二样本输出数据为从预设样本文本中提取的文本,第二样本文本为从预设样本文本中提取第二样本输出数据之后得到的文本。根据第二样本输入数据和第二样本输出数据对待用网络模型进行训练,得到候选文本分类模型包括以下步骤。
根据第二样本文本和候选分类模板,得到第二样本输入数据。
将第二样本输入数据作为待用网络模型的输入,并将第二样本输出数据作为待用网络模型的输出,对待用网络模型进行训练,得到候选文本分类模型。
在另一种实施例中,根据预设验证数据集,从候选参数向量和候选文本分类模型中确定目标参数向量和目标文本分类模型包括以下步骤。
针对每个候选参数向量,根据样本验证文本和候选参数向量对应的候选分类模板,得到验证输入数据。
将验证输入数据作为候选参数向量对应的候选文本分类模型的输入,得到候选文本分类模型输出的目标验证类别。
根据目标验证类别和样本验证类别,确定每个候选网络模型的分类准确度,候选网络模型包括候选参数向量和候选参数向量对应的候选文本分类模型。
将分类准确度最高的候选网络模型中的候选参数向量作为目标参数向量,并将分类准确度最高的候选网络模型中的候选文本分类模型作为目标文本分类模型。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
综上所述,本公开首先获取目标文本,并根据目标文本和包括目标参数向量和目标自然语言模板的目标分类模板,得到目标输入数据,然后将目标输入数据输入预设的目标文本分类模型,以得到目标文本分类模型输出的目标文本类别。其中,目标参数向量是根据第一训练样本数据对第一预设网络模型训练得到的,第一训练样本数据是标注有类别的样本数据,第一预设网络模型包括预设参数向量和预设分类模型。目标文本分类模型是根据第二训练样本数据对第二预设网络模型训练得到的,第二训练样本数据是未标注类别的样本数据,第二预设网络模型包括目标参数向量和预设分类模型。本公开通过预先训练得到的目标参数向量和目标文本分类模型,确定目标文本对应的目标文本类别,融合了自然语言模版法和参数向量模版法的分类方法,并充分利用了大量未标注的训练数据,能够得到更加准确的文本分类结果。
图7是根据一示例性实施例示出的一种电子设备的框图。例如,电子设备400可以被提供为一服务器。参照图7,电子设备400包括处理器422,其数量可以为一个或多个,以及存储器432,用于存储可由处理器422执行的计算机程序。存储器432中存储的计算机程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理器422可以被配置为执行该计算机程序,以执行上述的文本的分类方法。
另外,电子设备400还可以包括电源组件426和通信组件450,该电源组件426可以被配置为执行电子设备400的电源管理,该通信组件450可以被配置为实现电子设备400的通信,例如,有线或无线通信。此外,该电子设备400还可以包括输入/输出接口458。电子设备400可以操作基于存储在存储器432的操作系统。
在另一示例性实施例中,还提供了一种包括程序指令的计算机可读存储介质,该程序指令被处理器执行时实现上述的文本的分类方法的步骤。例如,该非临时性计算机可读存储介质可以为上述包括程序指令的存储器432,上述程序指令可由电子设备400的处理器422执行以完成上述的文本的分类方法。
在另一示例性实施例中,还提供一种计算机程序产品,该计算机程序产品包含能够由可编程的装置执行的计算机程序,该计算机程序具有当由该可编程的装置执行时用于执行上述的文本的分类方法的代码部分。
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 短文本分类模型的生成方法、分类方法、装置及存储介质
- 一种文本标识的方法、装置、电子设备及存储介质
- 文本属性字段的匹配方法、装置、电子设备及存储介质
- 文本分析方法、装置、电子设备及可读存储介质
- 宫廷服饰文本主题生成方法、装置、电子设备及存储介质
- 文本分类方法、文本分类装置、电子设备及存储介质
- 文本语句分类方法和分类装置、电子设备及存储介质