一种基于联邦迁移学习的供热管网失水诊断方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于智慧供热技术领域,具体涉及一种基于联邦迁移学习的供热管网失水诊断方法。
背景技术
热力管网又称热力管道,从锅炉房、直燃机房、供热中心等出发,从热源通往建筑物热力入口的供热管道。多个供热管道形成管网。城市集中供热管网(district heatsupply network)由城市集中供热热源向热用户输送和分配供热介质的管线系统。热网由输热干线、配热干线、支线等组成。输热干线自热源引出,一般不接支线;配热干线自输热干线或直接从热源接出,通过配热支线向用户供热。一般来说,集中式供热管网可以分为一次网和二次网。供热的一次网是指集中供暖系统总供热源(供热首站或锅炉房)到各个供暖小区热交换站之间的管网。供热的二次网是指供暖小区热交换站到供暖用户楼入口的热水管网。
近年来,随着我国经济的快速发展和城镇现代化脚步的加快,作为现代化城市基础建设之一的集中供热系统的普及率也随之升高,供热的规模也越来越大。与此同时,集中供热系统中的失水问题却非常严重。二次网失水也被称作管网泄漏,其会给供热端带来很大的损失。因此,如何准确对二次管网内的失水状况进行诊断,俨然成为研究重点。
早期的泄漏诊断方法侧重于基于硬件的泄漏分析,主要通过人工或硬件设备来监测管线的管壁及周边环境参数,从而达到故障诊断的目的。目前学界的研究内容表明,硬件泄漏诊断大多易于实现,但存在造价较高或者信号量大且杂,在大型管网区域定位困难的问题,在大型管网泄漏诊断中更多是作为辅助手段。基于软件的泄漏诊断方法进行管网泄漏诊断通过监控和数据采集系统(Supervisory Control and Data Acquisition,SCADA)采集传感器数据并传输到系统中,利用诊断算法实现对管网的分析和判断,进而确定管网的运行状况。目前,深度学习凭借其强大的自适应提取特征能力,被广泛应用于二次管网失水诊断领域。
但是基于深度学习的故障诊断方法在模型训练过程中通常需要大量已知标签样本集。不同供热二次管网会由于供热地区、管网铺设方式、数据采集标准等条件的差异导致已知标签样本数量稀缺,建立的故障诊断模型难以达到理想效果。并且,随着数据安全问题逐渐受到关注,世界各国政府纷纷颁布多条相关法律以加大数据隐私管理力度。二次管网供热数据中也暗藏诸多敏感信息,无论是出于安全方面还是商业竞争方面考虑,相关数据都难以直接进行集中式建模。
由上述内容可以得到,目前供热管网的失水诊断问题总结为以下几点:
1、传统的失水诊断基于硬件实现,在大规模管网中进行硬件检测不仅经济效益差,且实施难度很高,不具备现实实施可能。
2、不同供热二次管网会由条件差异导致已知标签样本数量稀缺,难以建模。且出于安全性考虑,难以对供热数据进行大规模的集中式模型训练。
3、由于不同供热系统二次管网供热数据之间差异较大,无法直接聚合多个用户不同规格供热系统二次管网供热数据;而用户仅使用本地孤岛数据直接建模会因已知标签数据较少无法建立有效的失水诊断模型。
发明内容
本发明的目的在于针对上述问题,提出一种基于联邦迁移学习的二次管网失水诊断方法,该方法在解决各供热方“数据孤岛”现象的同时,充分考虑可能出现的弱监督和数据特征重叠少情况,最终结合深度学习算法实现高效准确故障诊断,用以解决现有深度学习方法对于不同供热系统二次管网失水诊断效果不佳的问题。
为实现上述目的,本发明提供的技术方案如下所述:
一种基于联邦迁移学习的供热管网失水诊断方法,
步骤1,选取供热管网的供水温度、回水温度、流量过程数据构建各参与方的本地数据集;
步骤2,将各参与方的本地数据集转为数据相关性图,以便后续模型训练提取特征;
步骤3,各参与方进行失水诊断模型训练,多次迭代得到本地模型参数;步骤4,各参与方将各自的本地模型参数发送至联邦学习中心计算单元;步骤5,联邦学习中心计算单元使用联邦平均算法聚合各参与方上传的参数构建共享模型;
步骤6,联邦学习中心计算单元将共享模型参数发送至各参与方;
步骤7,各参与方使用本地数据集对共享模型微调,得到适用于用户本地数据集的个性化模型;
步骤8,将数据输入训练好的个性化模型中,得到诊断结果。
步骤1所述的联邦学习各参与方为需要失水诊断服务的供热方以及其他需要该类服务的主体。
步骤2所述的数据转图方法为格拉姆角场法转图,或其他时域频域转图方法;步骤2所述的数据相关性图包括由格拉姆角场法转换或其他各类数据转图方法得到的相关性剖析图以及原数据集简单转图。
步骤3所述的失水诊断模型训练算法包括卷积神经网络(CNN)、深度残差网络(RCNN)、残差收缩网络(DRSN)。
步骤4进行数据交互时,为保证安全性采取措施包括使用隐私保护方法。
步骤5所述的联邦学习中心计算单元为云端服务器、权限最高的参与方;步骤5所述的联邦学习算法采用联邦平均算法(FedAvg)、联邦梯度聚合算法(FedProx)。
步骤7所述的微调方法为用了新的逐层解冻策略的迁移学习。
所述的隐私保护方法包括同态加密、安全多方计算、差分隐私方法;所述逐层解冻策略,其策略包括除开全连接层外,将用于迁移学习的共享模型的模型参数从后往前迁移至目标域网络,以此作为目标域网络的初始化参数并使用目标域数据进行新一轮迭代。
所述的微调方法包括使用新的逐层解冻策略的迁移学习方法、正常迁移学习以及各类迁移学习策略。
所述的一种基于联邦迁移学习的供热管网失水诊断方法,采用平衡热量表来获取过程测量值,所述的平衡热量表内置供回水温度传感器、流量传感器和压力传感器,并具备远程通讯功能。
与现有技术相比,本发明的有益效果为:
1、本发明采用基于深度学习的失水诊断方法,无需对供热管道进行大规模改造,进而降低失水诊断成本。
2、本发明设计的基于联邦学习的二次网失水诊断机制,打破“数据孤岛”壁垒,实现无数据交互的二次网失水协同检测。
3、在联邦学习框架内引入迁移学习思路,充分考虑各参与方采集数据的差异性问题,如各方数据样本特征重叠少和部分参与方数据内含数据样本缺少标签等情况,使参与方可以拥有自己的特征空间,而无需强制要求所有参与方都拥有或使用相同特征的数据,实现更适用于现实多个供热企业协同学习的联邦迁移学习框架,提高模型性能。
附图说明
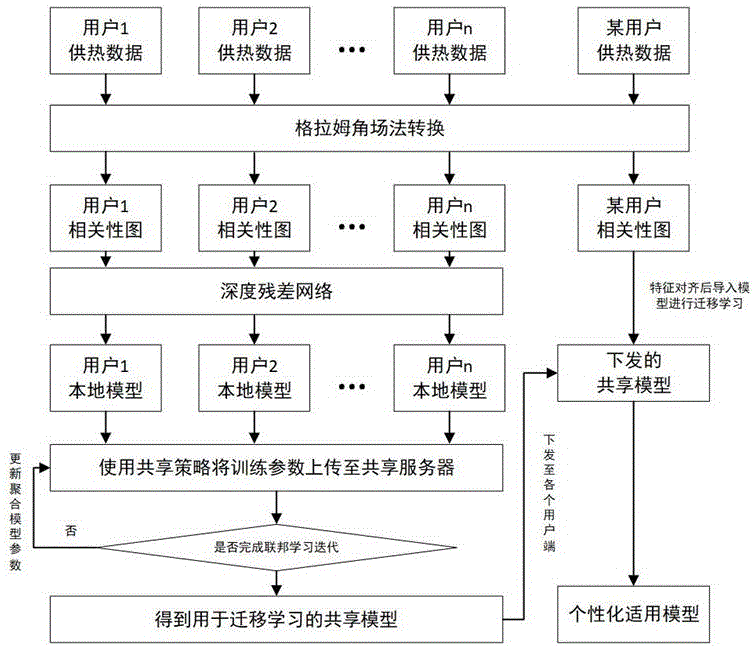
图1为本发明基于联邦迁移学习的二次管网失水诊断方法的一种流程图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
需要说明的是,除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本申请。
如图1所示,本发明提出的一种基于联邦迁移学习的二次管网失水诊断方法包括如下步骤:
S1、本地数据集构建:
选取不同供热系统的二次管网供水温度、回水温度、回水水压、流速等作为各用户本地数据集;
S2、各参与方通过格拉姆角场法变换得到用户本地数据相关性表达图样本集,具体步骤可分为如下:
S21、将收集到的数据进行最小最大标定法处理缩放到[-1,1]区间内,完成归一化处理,使用到的公式(1)如下:
其中,
S22、进一步将S21得到的新数据集{
其中,
其中,
S3、本地模型构建:
利用本地数据相关性表达图样本集在深度残差神经网络训练得到多个用户本地模型,以用于后续的模型聚合。
S4、本地模型参数上传:
各参与方向联邦学习中心计算单元上传训练好的本地模型参数,期间采用同态加密、隐私保护等加密手段对参数进行加密;
S5、共享模型构建:
联邦学习中心计算单元使用联邦平均算法聚合用户上传的参数并更新服务器的本地模型,不断重复此过程直至达到最大联邦迭代次数,得到用于迁移学习的共享模型,该步骤具体操作如下:
联邦迁移学习中心计算单元将收集到的多方训练模型和梯度通过联邦学习聚合算法进行聚合迭代。
进一步地,共享模型构建中所述联邦平均算法是联邦学习中的模型参数聚合方法,其表达式如下式(3)所示:
其中,表示
S6、共享模型参数下发:
联邦学习中心计算单元将共享模型参数发送至各参与方,期间采用同态加密、隐私保护等加密手段对参数进行加密;
S7、适用性模型构建:
各参与方使用本地数据集对共享模型微调,得到适用于用户本地数据集的个性化模型;
S8、将部分样本作为测试集输入上一步训练好的个性化模型中,得到诊断结果。
实施例
本实例的运行环境和使用软件如下:
CPU:AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz;
内存:16GB RAM;
操作系统:Windows 10;
Python版本:Python 3.9.12;
IDE:PyCharm 2022.1.4。
如图1所示,一种基于联邦迁移学习的二次管网失水诊断方法得到个性化的适应模型,包括如下步骤:
S1、本地数据集构建:
各参与方选取不同供热系统的二次管网供水温度、回水温度、回水水压、流速等作为各参与方本地数据集。也即用参与方1、参与方2会选取各自本地的供热数据作为参与方1本地数据集、参与方2本地数据集;
S2、各参与方通过格拉姆角场法变换得到用户本地数据相关性表达图样本集,具体步骤可分为如下:
S21、将收集到的数据进行最小最大标定法处理缩放到[-1,1]区间内,完成归一化处理,使用到的公式(1)如下:
其中,
S22、进一步将S21得到的新数据集
其中,
其中,
S3、本地模型构建:
利用本地数据相关性表达图样本集在深度残差神经网络训练得到多个用户本地模型,以用于后续的模型聚合。以用户1为例,用户1利用多表示域适应网络提取目标域1和源域数据的多表示下特征,在多个特征空间内同时进行特征对齐,其中,多表示特征是指通过上文的多表示域适应网络提取到的同一样本的不同表示下特征,如一张图片的色调特征、对比度特征等;最后,本地模型1的目标函数设置为交叉熵分类损失以及不同表示下的损失之和。经过一定次数的迭代训练,目标函数收敛,完成本地模型1的构建。其他用户模型的构建过程同理。
S4、本地模型参数上传:
各参与方向联邦学习中心计算单元上传训练好的本地模型参数,期间采用同态加密对参数进行加密;
S5、共享模型构建:
联邦学习中心计算单元使用联邦平均算法聚合用户上传的参数并更新服务器的本地模型,不断重复此过程直至达到最大联邦迭代次数,得到用于迁移学习的共享模型,该步骤具体操作如下:
联邦迁移学习中心计算单元将收集到的多方训练模型和梯度通过联邦学习聚合算法进行聚合迭代。
进一步地,共享模型构建中所述联邦平均算法是联邦学习中的模型参数聚合方法,其表达式如下式(3)所示:
其中,表示
S6、共享模型参数下发:
联邦学习中心计算单元将共享模型参数发送至各参与方,期间采用同态加密进行加密;
S7、适用性模型构建:
各参与方根据逐层解冻策略决定保留共享模型哪些层参数,并使用本地数据集对共享模型微调,得到适用于用户本地数据集的个性化模型,具体方法为除开全连接层外,将用于迁移学习的共享模型的模型参数从后往前迁移至目标域网络,以此作为目标域网络的初始化参数并使用目标域数据进行新一轮迭代;
S8、将部分样本作为测试集输入上一步训练好的个性化模型中,得到诊断结果。
现有方法大多未考虑真实供热条件下各供热企业数据难以互通的情况,无法解决用户隐私保护等问题。设计了基于联邦学习的二次网失水诊断机制,打破“数据孤岛”壁垒,实现无数据交互的二次网失水协同检测。在联邦学习框架内引入迁移学习思路,充分考虑各参与方采集数据的差异性问题,如各方数据样本特征重叠少和部分参与方数据内含数据样本缺少标签等情况,使参与方可以拥有自己的特征空间,而无需强制要求所有参与方都拥有或使用相同特征的数据,实现更适用于现实多个供热企业协同学习的联邦迁移学习框架,进而降低失水诊断成本、提高模型性能。
本实施例于步骤三所用的本地模型训练方法为深度残差神经网络,其余深度学习方法如深度残差收缩网络、卷积神经网络等,如运用在本发明所述框架下,应属于本申请的保护范围。同样的,步骤四所用的联邦聚合算法为联邦平均算法,其余算法如加权平均等也应属于本申请的保护范围。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请描述较为具体和详细的实施例,但并不能因此而理解为对申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 一种主机板的串行高阶硬盘架构SATA接口功能测试装置
- 主机板的串行高阶硬盘架构接口功能测试装置