一种视频质量评估方法、系统、计算机设备及存储介质
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及视频处理及计算机视觉技术领域,特别是涉及一种基于空时注意力机制的视频质量评估方法、系统、计算机设备和存储介质。
背景技术
随着社交媒体的蓬勃发展,移动用户捕获的视频内容在各大社交平台呈现爆炸性增加,例如TikTok,Facebook,Instagram,YouTube,and Twitter等。对这些海量内容的存储、传输和处理都给视频服务行业的带了很大挑战,尤其是业余用户在恶劣环境下拍摄的低质量视频涌入互联网,不仅影响人们的视频观感,而且影响人们从视频中获取有用信息。于是,利用自动化视频质量评估工具过滤低质量视频,防止其扩散影响视频服务效果逐渐成为视频服务工作迫切需要解决的问题。现有视频质量评估的解决方案大多是基于合成失真视频给出的研究成果,然而,合成失真视频与自然失真视频并不相同,自然失真视频由于缺少原始参考和失真类型复杂且未知等特点导致对该类视频感知质量的评估更加困难,且在合成失真视频上表现较好的方法也无法适用。
因此,亟需提供一种能够应对无法获得自然失真视频的原参考视频和自然失真类型等挑战,以真正有效解决自然失真视频质量评估问题的视频质量评估方法。
发明内容
本发明的目的是提供一种基于空时注意力机制的视频质量评估方法、系统、计算机设备及存储介质,通过基于视频评估需求对不包含任何卷积操作的纯Transformer架构进行适当改进建立视频质量评估网络(StarVQA网络),并采用StarVQA网络从输入视频帧里捕捉长时间范围内的空时依赖,以真正有效解决自然失真视频质量评估问题,并提高视频评估性能。
为了实现上述目的,有必要针对上述技术问题,提供了一种视频质量评估方法、系统、计算机设备及存储介质。
第一方面,本发明实施例提供了一种视频质量评估方法,所述方法包括以下步骤:
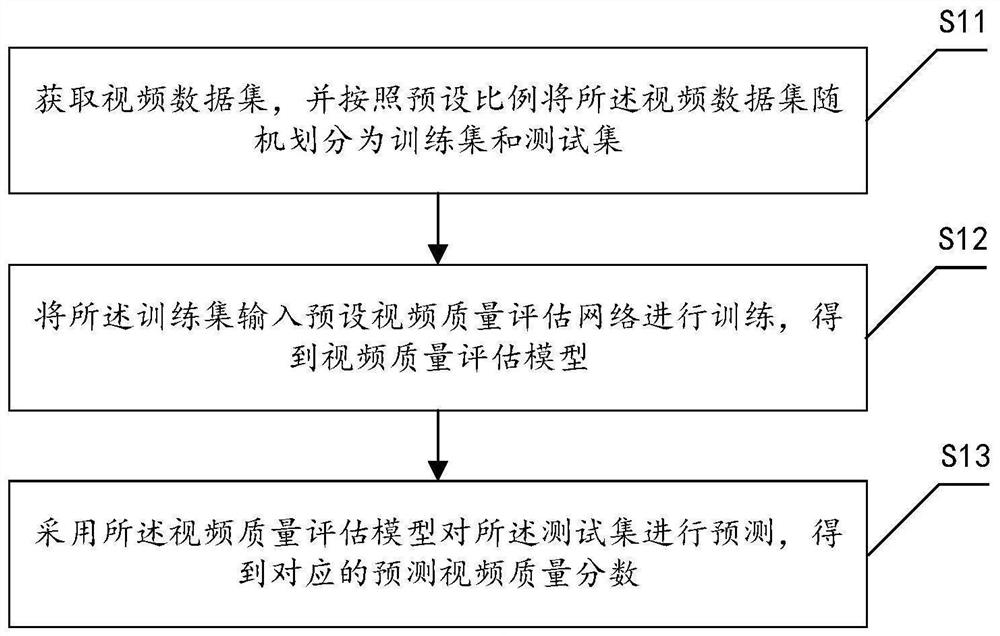
获取视频数据集,并按照预设比例将所述视频数据集随机划分为训练集和测试集;所述视频数据集为带视频质量分数标注的视频序列;
将所述训练集输入预设视频质量评估网络进行训练,得到视频质量评估模型;所述视频质量评估网络依次包括预处理模块、注意力编码模块和矢量回归模块;所述注意力编码模块包括多个时空注意编码模块;所述时空注意编码模块依次包括时间注意力模块、空间注意力模块和多层感知机模块;
采用所述视频质量评估模型对所述测试集进行预测,得到对应的预测视频质量分数。
进一步地,所述将所述训练集输入预设视频质量评估网络进行训练,得到视频质量评估模型的步骤包括:
将所述训练集输入所述预处理模块进行词嵌入与位置嵌入处理,得到编码输入矩阵;
将所述编码输入矩阵输入所述注意力编码模块进行时间注意力与空间注意力的交互编码,得到视频时空特征;
将所述视频时空特征输入所述矢量回归模块进行回归预测,得到视频质量分数概率向量,并根据所述视频质量分数概率向量,采用矢量化回归损失函数对所述视频质量评估网络进行训练,得到所述视频质量评估模型。
进一步地,所述将所述训练集输入所述预处理模块进行词嵌入与位置嵌入处理,得到编码输入矩阵的步骤包括:
根据等间隔采样,从所述训练集的各个视频中选择预设数目的视频帧;
将各个视频帧按照第一预设大小进行裁剪,得到待分割视频帧序列;
将各个待分割视频帧按照第二预设大小进行分割,得到对应的视频块;
获取各个视频块对应的视频块列向量,并采用时空位置向量对所述视频块列向量进行编码,得到视频块嵌入向量;所述视频块嵌入向量为:
式中,
根据所述视频块嵌入向量,得到对应的编码矩阵,并在所述编码矩阵的第一列位置添加质量分数学习向量,得到所述编码输入矩阵;所述编码输入矩阵表示为:
式中,E
进一步地,所述将所述编码输入矩阵输入所述注意力编码模块进行时间注意力与空间注意力的交互编码,得到视频时空特征的步骤包括:
根据所述编码输入矩阵,采用所述时间注意力模块提取视频时域特征;所述视频时域特征表示为:
式中,
根据所述视频时域特征,采用所述空间注意力模块提取视频空域特征;所述视频空域特征表示为:
式中,
根据所述视频空域特征,采用所述多层感知机模块,得到所述视频时空特征;所述视频时空特征表示为:
式中,
进一步地,所述矢量回归模块包括多层感知机、softmax激活函数和矢量化回归损失函数;
所述将所述视频时空特征输入所述矢量回归模块进行回归预测,得到视频质量分数概率向量,并根据所述视频质量分数概率向量,采用矢量化回归损失函数对所述视频质量评估网络进行训练,得到所述视频质量评估模型的步骤包括:
将所述视频时空特征依次经过所述多层感知机和softmax激活函数处理,得到所述视频质量分数概率向量;所述视频质量分数概率向量表示为:
式中,
根据视频真实质量分数,得到视频真实质量分数向量;
根据所述视频质量分数概率向量和所述视频真实质量分数向量,采用所述矢量化回归损失函数得到预测损失值;所述矢量化回归损失函数表示为:
式中,y和
根据所述预测损失值,对所述视频质量评估网络进行更新训练,得到所述视频质量评估模型。
进一步地,所述根据视频真实质量分数,得到视频真实质量分数向量的步骤包括:
将所述视频真实质量分数缩放至预设范围内,得到待编码视频质量分数;
根据所述待编码视频质量分数,得到视频真实质量分数向量。
进一步地,所述采用所述视频质量评估模型对所述测试集进行预测,得到对应的预测视频质量分数的步骤包括:
将所述测试集输入到所述视频质量评估模型进行预测,得到对应的视频质量分数概率向量;
采用支持向量回归机对所述视频质量分数概率向量进行解码,得到所述预测视频质量分数。
第二方面,本发明实施例提供了一种视频质量评估系统,所述系统包括:
获取模块,用于获取视频数据集,并按照预设比例将所述视频数据集随机划分为训练集和测试集;所述视频数据集为带视频质量分数标注的视频序列;
训练模块,用于将所述训练集输入预设视频质量评估网络进行训练,得到视频质量评估模型;所述视频质量评估网络依次包括预处理模块、注意力编码模块和矢量回归模块;所述注意力编码模块包括多个时空注意编码模块;所述时空注意编码模块依次包括时间注意力模块、空间注意力模块和多层感知机模块;
预测模块,用于采用所述视频质量评估模型对所述测试集进行预测,得到对应的预测视频质量分数。
第三方面,本发明实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
第四方面,本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
上述本申请提供了一种视频质量评估方法、系统、计算机设备及存储介质,通过所述方法,实现了通过获取视频数据集,并按照预设比例将所述视频数据集随机划分为训练集和测试集后,将训练集输入依次包括预处理模块、注意力编码模块和矢量回归模块的预设视频质量评估网络采用对应的矢量化回归损失函数进行训练,得到视频质量评估模型,采用视频质量评估模型对测试集进行预测得到对应的视频质量分数概率向量,再采用支持向量回归机对视频质量分数概率向量进行解码得到预测视频质量分数的技术方案。与现有技术相比,该视频质量评估方法,不仅有效解决了自然失真视频的质量评估问题,而且能高效捕捉视频序列中长范围的空时依赖特性,提高训练收敛速度和视频评估性能,还拓展了Transformer架构的应用领域。
附图说明
图1是本发明实施例中视频质量评估方法的应用场景意图;
图2是本发明实施例中视频质量评估方法的流程示意图;
图3是本发明实施例中视频质量评估网络的架构示意图;
图4是图2中步骤S12对视频质量评估网络进行训练的流程示意图;
图5是图4中步骤S121预处理得到编码输入矩阵的流程示意图;
图6是图4中步骤S122注意力编码得到视频时空特征的流程示意图;
图7是图4中步骤S123根据视频时空特征进行视频质量评估网络训练得到视频质量评估模型的流程示意图;
图8是图2中步骤S13使用视频质量评估模型进行预测的流程示意图;
图9是本发明实施例中视频质量评估网络的收敛速度示意图;
图10(a、b和c)分别表示本发明实施例中视频质量评估网络基于LIVE-VQC、KoNViD-1k和LSVQ数据集上的预测性能示意图;
图11是本发明实施例中视频质量评估网络与现有5种SOTA模型性能对比示意图;
图12是本发明实施例中视频质量评估系统的结构示意图;
图13是本发明实施例中计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案和有益效果更加清楚明白,下面结合附图及实施例,对本发明作进一步详细说明,显然,以下所描述的实施例是本发明实施例的一部分,仅用于说明本发明,但不用来限制本发明的范围。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供的视频质量评估方法,致力于解决自然失真视频的质量评估问题,其应用于如图1所示的视频服务应用场景。其中,终端可以但不限于是各种个人计算机、笔记本电脑、智能手机、平板电脑和便携式可穿戴设备,用于实现在各社交媒体上观看、浏览、上传和下载各类视频;服务器可以用独立的服务器或者是多个服务器组成的服务器集群来实现,用于运行支持某社交媒体的视频服务业务,该视频服务业务采用本发明的视频质量评估实现对平台所有视频进行质量评估,有效避免低质量视频带来的不良影响,以保证正常视频服务业务有序开展的同时,进一步提升服务质量。下述实施例将对本发明的基于空时注意力机制的视频质量评估方法进行详细阐述。
在一个实施例中,如图2所示,提供了一种视频质量评估方法,所述方法包括以下步骤:
S11、获取视频数据集,并按照预设比例将所述视频数据集随机划分为训练集和测试集;所述视频数据集为带视频质量分数标注的视频序列;
其中,视频数据集的选取及划分训练集和测试集的预设比例的确定都可根据实际应用需求确定。视频质量分数标注为MOS分标注,即视频数据集内的视频都有对应的视频真实质量分数,便于后续训练视频质量评估网络(StarVQA网络)使用。
S12、将所述训练集输入预设视频质量评估网络进行训练,得到视频质量评估模型;所述视频质量评估网络依次包括预处理模块、注意力编码模块和矢量回归模块;所述注意力编码模块包括多个时空注意编码模块;所述时空注意编码模块依次包括时间注意力模块、空间注意力模块和多层感知机模块;
其中,视频质量评估网络(StarVQA网络)是基于纯Transformer架构改进得到,具体网络架构如图3所示,其中,预处理模块、注意力编码模块和矢量回归模块分别实现对视频数据集的预处理、对预处理得到的视频数据进行注意力编码和基于注意力编码结果对模型进行回归训练,且注意力编码模块内的时空注意编码模块个数根据实际应用需求进行设置,此处不作具体限制。时空注意编码模块内的时间注意力模块、空间注意力模块和多层感知机模块的具体结构和功能可参见下述视频质量评估网络(StarVQA)网络训练的详细过程,此处不作赘述。如图4所示,具体使用训练集对视频质量评估网络进行回归训练的步骤包括:
S121、将所述训练集输入所述预处理模块进行词嵌入与位置嵌入处理,得到编码输入矩阵;
其中,预处理模块的功能是为了将训练集的视频数据处理为可以匹配视频质量评估网络的输入,除了常规的Word Embedding操作外,为了适用于视频视频评估,会在Embedding操作后,添加对应的质量分数学习向量,以得到最终可输入注意力编码模块的编码输入矩阵。如图5所示,所述将所述训练集输入所述预处理模块进行词嵌入与位置嵌入处理,得到编码输入矩阵的步骤包括S121:
S1211、根据等间隔采样,从所述训练集的各个视频中选择预设数目的视频帧;
其中,等间隔采样可以理解为采样频率固定且预设数目可根据实际应用需求进行灵活调整,即在该预设数目确定后,就可以按照等间隔采样的方法从训练集中的每个视频选出预设数目的视频帧用于后续的处理使用。
S1212、将各个视频帧按照第一预设大小进行裁剪,得到待分割视频帧序列;
其中,第一预设大小也可以根据实际应用需要进行设定,并按照该大小要求对每个视频的每个视频帧都进行相应的裁剪处理,如确定裁剪后的帧宽度为H,裁剪后的帧高度为W,则将各个视频帧裁剪成H×W×3大小的待分割视频帧,其中,3代表R,G和B三个颜色通道。
S1213、将各个待分割视频帧按照第二预设大小进行分割,得到对应的视频块;
其中,第二预设大小同样也可以根据实际应用需要进行设定,并按照该大小要求对每个视频的每个视频帧都进行相应的分割处理,如确定裁剪后的视频块宽度和视频块高度均为P,则将各个待分割视频帧分割成不重叠的P×P×3大小的视频块。因此,每个视频帧将会产生
S1214、获取各个视频块对应的视频块列向量,并采用时空位置向量对所述视频块列向量进行编码,得到视频块嵌入向量;所述视频块嵌入向量为:
式中,
其中,视频块列向量通过将对应的视频块伸直成一个维度为P×P×3列向量得到后,基于自注意力机制能够捕捉长时间序列的空时位置信息的特性,采用一个空时位置向量对每个视频块列向量进行编码得到对应的视频块嵌入向量,具体编码过程如式(1)所示。
S1215、根据所述视频块嵌入向量,得到对应的编码矩阵,并在所述编码矩阵的第一列位置添加质量分数学习向量,得到所述编码输入矩阵;所述编码输入矩阵表示为:
式中,E
本实施例通过在对训练集内的视频数据预处理编码时,加入质量分数学习向量,得到如式(2)所示的编码输入矩阵,为后续通过对视频质量评估网络训练得到每个视频的视频质量分数概率向量提供了实施依据和可靠保障。
S122、将所述编码输入矩阵输入所述注意力编码模块进行时间注意力与空间注意力的交互编码,得到视频时空特征;
其中,注意力编码模块采用的是交替的更加有效的空时注意力机制,即将时间注意力和空间注意力的交互进行拆分,时间注意力模块和空间注意力模块被分开一个接着一个的进行计算,最终得到对应的视频时空特征,用于后续的训练使用。如图6所示,所述将所述编码输入矩阵输入所述注意力编码模块进行时间注意力与空间注意力的交互编码,得到视频时空特征的步骤S122包括:
S1221、根据所述编码输入矩阵,采用所述时间注意力模块提取视频时域特征;所述视频时域特征表示为:
式中,
其中,视频时域特征采用时间注意力模块提取的过程中,需要先计算时间注意力的q、k和v向量,对于每一个视频块,第l个时间注意力模块(block)的q、k和v值可以利用第l-1个时间注意力模块(block)的输出来计算得到。为了方便表述,后面的p和t都仍从0开始取值,且q,k,v值的计算过程如下:
式中,LN(·)表示LayerNorm归一化;
按照上述方法计算得到时间注意力的q、k和v向量后,需要计算时间自注意力系数。如上所述本实施例使用交替空时自注意力机制,通过计算同一个空间位置的所有的不同时间位置中的视频块来进行计算时间注意力系数,具体计算过程表示如下:
式中,SM(·)表示softmax激活函数。从式(7)可以看出计算时间注意力系数时,代表空间位置的p是固定的。得到时间注意力系数后,通过使用时间注意力系数来计算编码系数,对应的计算过程表示如下:
通过式(8)把所有单头得到的编码系数连接起来,然后进行投影得到式(3)所示的视频时域特征,用于输入与其连接的空间注意力模块进行步骤S1222的视频空域特征提取。
S1222、根据所述视频时域特征,采用所述空间注意力模块提取视频空域特征;所述视频空域特征表示为:
式中,
其中,视频空域特征采用空间注意力模块提取的过程中,同样需要先计算空间注意力的q、k和v向量,此时只需将式(3)计算得到的
因此,空间注意力的编码系数也可以被计算出来,其计算过程如下所示:
通过式(11)把所有单头得到的编码系数连接起来,然后进行投影得到式(8)所示的视频空域特征,用于输入后续与其连接的多层感知机模块进行步骤S1223的视频时空特征提取。
S1223、根据所述视频空域特征,采用所述多层感知机模块,得到所述视频时空特征;所述视频时空特征表示为:
式中,
其中,视频空域特征通过上述步骤得到后,可直接输入多层感知机网络,并且进行一个残差连接得到如式(12)所示的视频时空特征,到此就完成了一个时空注意编码模块的处理。需要说明的是,本实施例仅以一个视频块经过第l个时空注意编码模块(block)为例进行说明,得到一个时空注意编码模块(block)的处理结果后,将会作为下一个时空注意编码模块(block)l+1的输入,直到l=L(即经过预设的L个时空注意编码模块处理)为止,再将最后得到的视频时空特征输入到矢量回归模块完成后续的回归训练。
本实施例采用交替的空时注意力机制对视频数据进行处理,能够更加有效的从视频帧里捕捉长时间范围内的空时依赖,以保证后续训练得到视频质量评估模型更加精准有效。
S123、将所述视频时空特征输入所述矢量回归模块进行回归预测,得到视频质量分数概率向量,并根据所述视频质量分数概率向量,采用矢量化回归损失函数对所述视频质量评估网络进行训练,得到所述视频质量评估模型。
其中,矢量回归模块如图3所示,包括多层感知机、softmax激活函数和矢量化回归损失函数,主要用于根据注意力编码模块提取的视频时空特征进行回归预测得到,对应视频的视频质量分数概率向量,并采用创新的矢量化回归损失函数来评估视频质量分数概率向量与视频真实质量分数的差异来对视频质量评估网络进行回归训练。如图7所示,所述将所述视频时空特征输入所述矢量回归模块进行回归预测,得到视频质量分数概率向量,并根据所述视频质量分数概率向量,采用矢量化回归损失函数对所述视频质量评估网络进行训练,得到所述视频质量评估模型的步骤S123包括:
S1231、将所述视频时空特征依次经过所述多层感知机和softmax激活函数处理,得到所述视频质量分数概率向量;所述视频质量分数概率向量表示为:
式中,
其中,
S1232、根据视频真实质量分数,得到视频真实质量分数向量;
其中,视频真实质量分数为视频数据集中各个视频原始标注的视频质量分数,用于与上述步骤得到视频质量分数概率向量进行对比,评估视频质量评估网络(StarVQA网络)的预测损失。如前文所述为了适应Transformer架构,需要在时空注意力编码模块的编码输入矩阵中嵌入一个特殊的矢量化的可学习的质量分数学习向量作为标签标记。同样,此处的视频真实质量分数MOS也需要被编码成对应的向量形式才能满足后续矢量化回归损失函数的应用。具体地,所述根据视频真实质量分数,得到视频真实质量分数向量的步骤S1232包括:
将所述视频真实质量分数缩放至预设范围内,得到待编码视频质量分数;
其中,预设范围可根据实际应用需求确定,即对视频真实质量分数进行归一化处理,便于后续利用矢量化回归损失函数计算预测损失。如训练集的视频真实质量分数部分为[0.0,100.0],部分为[0.0,5.0]时,就可以将预设范围定为[0.0,5.0],对所有视频真实质量分数全部调整至[0.0,5.0]。需要说明的是,此处的范围仅为举例说明,不作具体范围限制。
根据所述待编码视频质量分数,得到视频真实质量分数向量。
其中,待编码视频质量分数按照上述步骤方法得到后,将该待编码视频质量分数(视频训练的MOS分)编码为与预设范围对应的视频真实质量分数向量,如预设范围定为[0.0,5.0]时,就可以将待编码视频质量分数转换为维数与预设范围内整数个数对应的向量y=[y
式中,b=[0,1,2,3,4,5]表示一个锚点向量;y
S1233、根据所述视频质量分数概率向量和所述视频真实质量分数向量,采用所述矢量化回归损失函数得到预测损失值;所述矢量化回归损失函数表示为:
式中,y和
S1234、根据所述预测损失值,对所述视频质量评估网络进行更新训练,得到所述视频质量评估模型。
其中,预测损失值L
本实施例针对Transformer架构设计了一种新的矢量化回归损失函数,并以此对本发明提出的视频质量评估网络进行训练,不仅有效解决了Transformer应用于视频评估领域的不适配问题,而且还为提升视频质量评估网络的收敛速度和视频评估性能提供了可靠的技术支撑。
S13、采用所述视频质量评估模型对所述测试集进行预测,得到对应的预测视频质量分数。
其中,视频质量评估模型通过上述步骤训练得到后,就可以用于对待测试视频进行测试,具体将测试集的视频数据输入视频质量评估模型进行预测的过程与训练类似,可参见前述训练时模型内各个模块的处理过程,此处不再赘述。需要说明的是,通过视频质量评估网络进行矢量回归预测得到的是每个视频对应的质量分数概率向量,而不是一个具体的质量分数,此处需要作相应调整。具体地,如图8所示,所述采用所述视频质量评估模型对所述测试集进行预测,得到对应的预测视频质量分数的步骤S13包括:
S131、将所述测试集输入到所述视频质量评估模型进行预测,得到对应的视频质量分数概率向量;
S132、采用支持向量回归机对所述视频质量分数概率向量进行解码,得到所述预测视频质量分数。
其中,支持向量回归机进行解码的具体方法参见现有技术即可实现,此处不再详述。
本实施例基于纯Transformer架构进行改进,通过在编码模块block嵌入一个特殊矢量化可学习变量标签标记,以及将视频真实MOS分编码成对应向量形式配合新的矢量化回归损失函数得到的预设视频质量评估网络,在将获取的视频数据集按照预设比例随机划分为训练集和测试集后,将训练集输入视频质量评估网络采用对应的矢量化回归损失函数进行训练,得到视频质量评估模型,采用视频质量评估模型对测试集进行预测得到对应的视频质量分数概率向量,再采用支持向量回归机对视频质量分数概率向量进行解码得到预测视频质量分数的技术方案,不仅有效解决了自然失真视频的质量评估问题,而且能高效捕捉视频序列中长范围的空时依赖特性,提高训练收敛速度和视频评估性能,还拓展了Transformer架构的应用领域。
为了验证本发明视频质量评估模型(StarVQA)的上述实际应用效果,基于Pytorch框架开发视频质量评估网络(StarVQA网络),并使用机器配备为4块特斯拉P100的GPU在多个自然失真的视频数据集上(即LIVE-VQC,KoNViD-1k,LSVQ和LSVQ-1080p)进行了大量实验,其中,LIVE-VQC包括585个视频序列,其标注的MOS的范围是[0.0,100.0],视频分辨率从240p到1080p;KoNViD-1k包含1200个视频序列,其标注的MOS的范围是[0.0,5.0],视频分辨率是固定的960p;LSVQ(包括LSVQ-1080p)包含38811个视频序列,其标注MOS的范围[0.0,100.0],视频分辨率十分丰富;LSVQ-1080p包含3573个视频序列,其中超过93%的视频分辨率都高于或者等于1080p,其内部所有样本均来自LSVQ,但LSVQ-1080p中的视频与LSVQ的视频没有一个是重复的,它被单独设计用于验证本发明的视频质量评估网络(StarVQA网络)对于高分辨率视频的性能,具体实验过程如下:
实验对收集的四种自然失真视频数据集按照8:2的比例进行训练集和测试集的划分,并将相关参数设定为F=8,H=W=224,P=16,A=12,时空注意编码模块block的数量L=12,分别进行了收敛速度验证、性能对比验证和性能交叉验证,并取10次运行的平均值作为对应的实验结果。
如图9所示,本发明的视频质量评估网络(StarVQA网络)当训练次数达到5次时,视频质量评估网络(StarVQA网络)就达到了很高的SROCC和PLCC性能。当训练次数超过10以后,视频质量评估网络(StarVQA网络)的性能基本保持不变,已经到达最高性能,可见,看出视频质量评估网络(StarVQA网络)的收敛速度极快。
图10(a-c)所示的视频质量评估网络(StarVQA网络)在不同数据集上预测视频质量分数的散点图,可以看到视频质量评估网络(StarVQA网络)的预测结果十分接近真实视频质量分数标注,也可说明视频质量评估网络(StarVQA网络)在不同数据集上的性能十分稳定,尤其是在数据集LSVQ上表示更是亮眼,其预测结果非常靠近标注参考线。同时,该实验结果也说明了在相同计算量的基础上,基于Transformer的架构在大数据集应用上表现更为突出。
性能对比验证时,将视频质量评估网络(StarVQA网络)和5个SOTA方法进行比较,包括BRISQUE,VSFA,TLVQM,VIDEVAL和PVQ,得到如表1所示的对比结果。从表1中易知视频质量评估网络(StarVQA网络)的性能在KoNViD-1k和LSVQ数据集上是最好的,同时进一步验证了前述的Transformer架构不是十分适合小数据集应用,然而对于高分辨率的视频表现出来的优势却非常显著。图11示出的使用LSVQ-1080p数据集在LSVQ数据集上预训练好的质量评估模型测试结果,可知视频质量评估网络(StarVQA网络)超越了所有竞争者,有力验证了该模型同样适用于高分辨率视频的质量评估,且表现优异。
表1 StarVQA网络与其他模型的性能对比
此外,为了验证视频质量评估网络(StarVQA网络)的泛化能力,还进行了交叉性能验证,实验结果如表2所示。从表2的数据可以看出,视频质量评估网络(StarVQA网络)以LSVQ作为训练集以KoNViD-1k作为测试集时,性能表现非常优异,远远高于其他网络模型;以LSVQ作为训练集以LIVE-VQC作为测试集时,性能表现也非常具有竞争性。
表2.交叉验证数据对比
基于上述实验结果,可知本发明设计的一个全新的空时注意力网络StarVQA在解决VQA问题时的表现已超越了目前性能最优越的网络模型,可见,本发明的研究拓展了Transformer架构的应用领域,并且也展示了注意力机制在视频质量评估领域的潜能。由于上述实验计算资源的限制(实验中每个视频采样只取了8帧),基于现有报道视频分类的精度随着被选择的视频帧的增加几乎呈线性增加可知,本发明的实验性能可能会随着被选择视频帧数的增加而得到进一步提升,如,将每个视频的采用帧数提升为32帧或者64帧,视频质量评估网络(StarVQA网络)的性能表现将会比上述展示结果更优异。
需要说明的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。
在一个实施例中,如图12所示,提供了一种视频质量评估系统,所述系统包括:
获取模块1,用于获取视频数据集,并按照预设比例将所述视频数据集随机划分为训练集和测试集;所述视频数据集为带视频质量分数标注的视频序列;
训练模块2,用于将所述训练集输入预设视频质量评估网络进行训练,得到视频质量评估模型;所述视频质量评估网络依次包括预处理模块、注意力编码模块和矢量回归模块;所述注意力编码模块包括多个时空注意编码模块;所述时空注意编码模块依次包括时间注意力模块、空间注意力模块和多层感知机模块;
预测模块3,用于采用所述视频质量评估模型对所述测试集进行预测,得到对应的预测视频质量分数。
需要说明的是,关于视频质量评估系统的具体限定可以参见上文中对于视频质量评估方法的限定,在此不再赘述。上述视频质量评估系统中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
图13示出一个实施例中计算机设备的内部结构图,该计算机设备具体可以是终端或服务器。如图13所示,该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、显示器和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现上述视频质量评估方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
本领域普通技术人员可以理解,图13中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有同的部件布置。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述方法的步骤。
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述方法的步骤。
综上,本发明实施例提供的一种视频质量评估方法、系统、计算机设备及存储介质,其视频质量评估方法实现了基于纯Transformer架构进行改进,通过在编码模块block嵌入一个特殊矢量化可学习变量标签标记,以及将视频真实MOS分编码成对应向量形式配合新的矢量化回归损失函数得到的预设视频质量评估网络(StarVQA网络),在将获取的视频数据集按照预设比例随机划分为训练集和测试集后,将训练集输入视频质量评估网络采用对应的矢量化回归损失函数进行训练,得到视频质量评估模型,采用视频质量评估模型对测试集进行预测得到对应的视频质量分数概率向量,再采用支持向量回归机对视频质量分数概率向量进行解码得到预测视频质量分数的技术方案。该视频质量评估方法,不仅有效解决了自然失真视频的质量评估问题,有效避免低质量视频带来的不良影响,以保证正常视频服务业务有序开展的同时,进一步提升服务质量,而且能高效捕捉视频序列中长范围的空时依赖特性,提高训练收敛速度和视频评估性能,还拓展了Transformer架构的应用领域。
本说明书中的各个实施例均采用递进的方式描述,各个实施例直接相同或相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。需要说明的是,上述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种优选实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本申请的保护范围。因此,本申请专利的保护范围应以所述权利要求的保护范围为准。