一种储层评价模型构建方法及储层识别方法
文献发布时间:2023-06-19 11:08:20
技术领域
本申请涉及一种储层评价模型构建方法及储层识别方法,属于地球物理勘探领域和人工智能领域。
背景技术
储层识别是对储层流体进行识别的过程。常规储层识别方法是通过储层的解释模型和测井数据计算储层的孔隙度、渗透率和含油饱和度的方法实现对储层识别。但随着油气田开发的深入,油气田的开发难度越来越大,常规储层识别方法因地质条件复杂、储层流体响应特征差异不明显,导致储层识别精度低。
采用机器学习方法对储层进行油气层识别,能够挖掘储层测井数据与储层流体之间的隐含关系,提高储层识别率。在机器学习领域中,主要采用支持向量机(SupportVector Machine,SVM)方法实现储层识别,但是如果研究目标区域内缺少储层识别样本数据,会造成支持向量机无法通过有限的储层识别样本完全掌握储层样本数据规律,导致其形成的模型在应用时符合率偏低。因此储层样本数量不足是我们面临的一个严峻问题。
目前在机器学习和深度学习中,为实现数据样本增大,扩大数据集,常用的方法有随机裁剪、翻转或镜像、旋转、亮度或对比度调节、色度调节、饱和度调节和图像模糊等。但这些方法是基于二维图像样本数据集的增强和扩大,并不适用于一维储层样本数据集的增强和扩大。
对于储层样本处理的方法,例如地球物理勘探领域和人工智能领域公开了申请公布号为CN109902390A、发明名称为“一种基于小样本扩充的有利储层发育区预测方法”的中国专利申请,所述方法包括:将地震数据体可以视为按照CDP、Inline划分成的网格长方体,其中地震属性数据以地震网格点的排列形式存储。根据地震属性样本附近地质情况连续的特点,将标记样本看作正方形网格一个顶点,复制该标记给正方形网格的其他顶点位置,提取网格其他顶点位置的地震属性作为扩充后的样本,从而增强了样本集,但这种方法扩充对象是三维地震属性样本,并不适用于一维储层样本数据集的扩充。
因此,为了解决现有技术中储层样本数据不足所导致的储层发育区预测精度低的问题,急需一种储层评价模型构建方法,以实现对储层发育的准确识别。
发明内容
本申请的目的在于提供一种储层评价模型构建方法及储层识别方法,解决研究目标区域内缺少储层识别样本数据,导致当对储层评价样本进行机器学习和深度学习时缺少样本支撑,以及偏少的样本学习后模型应用时符合率偏低的问题。
本发明采用如下技术方案:本发明提供了一种储层评价模型构建方法,该方法包括如下步骤:
1)获取不同类型储层对应深度段的测井数据;
2)将测井数据按深度分割成单深度点的测井行数据,构建储层特征样本库;所述单深度点的测井行数据为单深度点对应的各种类型的测井数据;
3)从构建的储层特征样本库中抽取设定数目测井行数据,组合成储层特征评价数据;
4)对储层特征评价数据中的不同类型测井数据分别按照设定规则进行计算,得到一个储层评价样本;
5)重复步骤3)和步骤4),直至获取所需数量的储层评价样本;
6)对所述储层评价样本进行训练,得到储层评价模型。
本发明根据用户需求的储层评价样本数量,通过对已有试油井井段的测井数据进行分割、排序和重组,形成新的储层评价样本,从而实现储层评价样本的扩充。通过储层评价样本的扩充,提高了试油数据利用效率,使得机器学习算法能够通过较少的评价数据,掌握其中的储层评价规律,提高了机器学习算法模型储层评价的符合率,提高了储层识别过程的精确性和效率。
进一步的,所述测井数据至少包括自然伽马测井数据、自然电位测井数据、补偿声波测井数据、补偿中子测井数据、补偿密度测井数据、中感应测井数据和深感应测井数据。
进一步的,所述储层类型包括油层、油水同层、水层、含油水层或干层。
进一步的,所述步骤2)中还包括对所述测井行数据进行排序的步骤:按照深电阻率曲线值或补偿声波测井数据由大到小的关系对测井行数据进行排序,所述深电阻率曲线值包括深感应测井数据。
进一步的,所述步骤3)中的抽取方式为:
当试油结果为油层或油水同层时,按照电阻率曲线值从大到小的规律抽取步骤2)中排序的测井行数据构建油层样本库;
当试油结论为水层或含油水层时,按照电阻率曲线值从小到大的规律抽取步骤2)中排序的、电阻率曲线的测井值较小的测井行数据构建水层样本库;
当试油结论为干层时,按照电阻率曲线值从大到小抽取步骤2)中排序的、电阻率曲线值较大的测井行数据构建干层样本库。
进一步的,所述步骤4)中按照设定规则进行计算的步骤为:按照中感应测井数据和/或深感应测井数据取极大值、其他测井数据取平均值的方法对储层特征评价数据中的不同测井数据进行计算,得到一个储层评价样本。
进一步的,所述步骤1)中还包括对层数据进行标准化处理的步骤。
进一步的,所述步骤3)中随机抽取设定数目的测井行数据。
进一步的,所述步骤6)中采用支持向量机的算法进行训练得到储层评价模型。
本发明还提供了一种储层识别方法,包括如下步骤:
1)获取不同类型储层对应起止深度段的测井数据;
2)将测井数据按深度分割成单深度点的测井行数据,构建储层特征样本库;所述单深度点的测井行数据为单深度点对应的各种类型的测井数据;
3)从构建的储层特征样本库中抽取设定数目测井行数据,组合成储层特征评价数据;
4)对储层特征评价数据中的不同类型测井数据分别按照设定规则进行计算,得到一个储层评价样本;
5)重复步骤3)和步骤4),直至获取所需数量的储层评价样本;
6)对所述储层评价样本进行训练,得到储层评价模型;
7)根据所述储层评价模型和不同类型的测井数据,进行储层识别。
本发明根据用户需求的储层评价样本数量,通过对已有试油井井段的测井数据进行分割、排序和重组,形成新的储层评价样本,从而实现储层评价样本的扩充。通过储层评价样本的扩充,提高了试油数据利用效率,使得机器学习算法能够通过较少的评价数据,掌握其中的储层评价规律,提高了机器学习算法模型储层评价的符合率,提高了储层识别过程的精确性和效率。
进一步的,所述测井数据至少包括自然伽马测井数据、自然电位测井数据、补偿声波测井数据、补偿中子测井数据、补偿密度测井数据、中感应测井数据和深感应测井数据。
进一步的,所述储层类型包括油层、油水同层、水层、含油水层或干层。
进一步的,所述步骤2)中还包括对所述测井行数据进行排序的步骤:按照深电阻率曲线值或补偿声波测井数据由大到小的关系对测井行数据进行排序,所述深电阻率曲线值包括深感应测井数据。
进一步的,所述步骤3)中的抽取方式为:
当试油结果为油层或油水同层时,按照电阻率曲线值从大到小的规律抽取步骤2)中排序的测井行数据构建油层样本库;
当试油结论为水层或含油水层时,按照电阻率曲线值从小到大的规律抽取步骤2)中排序的、电阻率曲线的测井值较小的测井行数据构建水层样本库;
当试油结论为干层时,按照电阻率曲线值从大到小抽取步骤2)中排序的、电阻率曲线值较大的测井行数据构建干层样本库。
进一步的,所述步骤4)中按照设定规则进行计算的步骤为:按照中感应测井数据和/或深感应测井数据取极大值、其他测井数据取平均值的方法对储层特征评价数据中的不同测井数据进行计算,得到一个储层评价样本。
进一步的,所述步骤1)中还包括对层数据进行标准化处理的步骤。
进一步的,所述步骤3)中随机抽取设定数目的测井行数据。
进一步的,所述步骤6)中采用支持向量机的算法进行训练得到储层评价模型。
附图说明
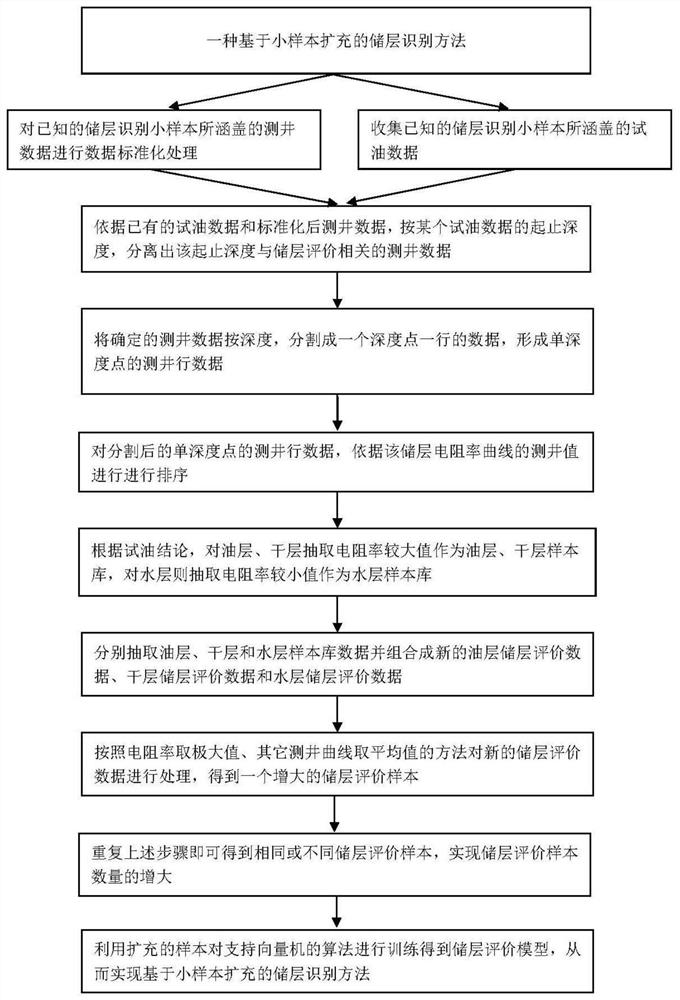
图1是本发明出储能识别方法流程图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本申请,并不用于限定本申请,即所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。
因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
以下结合实施例对本申请的特征和性能作进一步的详细描述。
由图1所示本发明实施例的技术路线框图可知,具体包括以下步骤:
储层评价模型构建方法实施例1:
以某油井的试油数据和测井数据为例,对本发明做进一步描述,
1、表1是收集的中原油田某研究区域某井目标层系内的试油数据起止深度段的测井数据表,该深度段的试油结果为油层,由表可知,该测井数据包括中感应RILM、深感应RILD、补偿密度DEN、补偿中子CNL和补偿声波AC数据;测井数据实际为连续的数据,表1中只是给出了其中一些点。
表1
2、将表1确定的测井数据(连续的数据)按深度,分割成一个深度点一行的数据,形成如表2所示的单深度点的测井行数据;
表2
3、将步骤2确定的单深度点的测井行数据,按深电阻率曲线RILD的数值由大到小逐深度点进行排序,形成如表3所示的数据表;
表3
4、根据该层试油结论为油层,利用步骤3按电阻率曲线RILD的数值排序后的测井数据,按照电阻率曲线值较大的前10行测井行数据构建如表4油层样本库;
表4
5、将步骤4建立的油层样本库抽取部分并组合成新的油层储层评价数据,形成如表5的油层储层样本数据;
表5
6、按照电阻率曲线(本实例电阻率曲线为RILD和RILM)取极大值、其它测井曲线取平均值的方法对步骤5生成的油层评价数据进行处理,得到一个如表6所示的,扩充后的油层储层评价样本;
表6
7、重复上述步骤5至步骤6扩充相同储层评价样本,直至所得到的储层评价样本能够满足支持向量机(Support Vector Machine,SVM)方法训练的需求。
储层评价模型构建方法实施例2:
本实施例中获取的某研究区某井目标层系内试油数据起止深度段内、试油结果为水层时,进行小样本扩容的过程为例,对本申请的方案做进一步说明。
1)表7是收集的某研究区域某井目标层系内的试油数据起止深度段标准化后的测井数据表,该深度段的试油结果为水层,由表可知,该测井数据包括中感应、深感应、补偿密度、补偿中子和补偿声波数据;
表7
2)将表7确定的测井数据按深度,分割成一个深度点一行的数据,形成如表8所示的单深度点的测井行数据;
表8
3)将步骤2)确定的单深度点的测井行数据,按电阻率曲线RILD的数值由小到大逐深度点进行排序,形成如表9所示的数据表;
表9
4)根据该层试油结论为水层,利用步骤3)按深电阻率曲线RILD的数值排序后的测井数据,按照电阻率曲线值较小的前10行测井行数据构建如表10油层样本库;
表10
5)将步骤4)建立的油层样本库抽取部分并组合成新的油层储层评价数据,形成如表11的油层储层样本数据;
表11
6)按照电阻率曲线(本实例电阻率曲线为RILD和RILM)取极大值、其它测井曲线取平均值的方法对步骤5)生成的油层评价数据进行处理,得到一个如表12所示的,扩充后的油层储层评价样本;
表12
7)重复上述步骤3至步骤6扩充不同储层的评价样本,重复上述步骤5至步骤6扩充相同储层评价样本,直至所得到的储层评价样本能够满足支持向量机(Support VectorMachine,SVM)方法训练的需求。
储层评价模型构建方法实施例3:
本实施例与上述具体实施例的区别仅在于:
本实施例中不需要对测井行数据进行排序,随机抽取设定数据的测井行数据。通过这种随机抽取的方式,有效提高了样本扩充效率。
储层评价模型构建方法实施例4:
本实施例与上述实施例的区别仅在于:
对获取不同类型储层对应起止深度段的测井数据进行标准化处理。此步骤为对测井数据进行预处理的步骤,通过这种方式提高了储层评价模型的准确性。
储层评价模型构建方法实施例5:
上述实施例中给出的是利用深电阻率曲线值即RILD的数值作为抽取储层测井行数据的依据。本实施例与上述实施例的区别仅在于:还可以采用补偿声波数值作为抽取储层测井行数据的依据,对单深度点的测井行数据进行排序,建立储层样本库。
储层识别方法实施例:
本实施例的具体过程如下:本发明还提供了一种基于小样本扩充的储层识别方法,包括如下步骤:
1)获取不同类型储层对应起止深度段的测井数据;
2)将测井数据按深度分割成单深度点的测井行数据,构建储层特征样本库;所述单深度点的测井行数据为单深度点对应的各种类型的测井数据;
3)从构建的储层特征样本库中抽取设定数目测井行数据,组合成储层特征评价数据;
4)对储层特征评价数据中的不同类型测井数据分别按照设定规则进行计算,得到一个储层评价样本;
5)重复步骤3)和步骤4),直至获取所需数量的储层评价样本;
6)对所述储层评价样本进行训练,得到储层评价模型;
7)根据所述储层评价模型和不同类型的测井数据,进行储层识别。利用扩充的样本对支持向量机的算法进行训练得到储层评价模型,从而实现基于小样本扩充的储层识别方法。
具体的储层评价模型已在上述基于小样本扩充的储层模型构建方法的具体实施例1-5中详细给出,此处不再赘述。
通过上述实施例,阐述了对储层样本相关的测井数据通过排序、抽取和组合后生成新的储层评价样本,从而实现了储层评价样本增大的方法,可形成如下结论:
1、利用本方法对储层样本的增大,提高了储层评价数据的利用效率,间接提高了机器学习模型储层评价的符合率;
2、根据电阻率或补偿声波数据抽取储层测井行数据作为样本库,可以排除储层样本中受围岩影响的行数据,提高样本库的精确度。
以上所述,仅为本申请的较佳实施例,并不用以限制本申请,本申请的专利保护范围以权利要求书为准,凡是运用本申请的说明书及附图内容所作的等同结构变化,同理均应包含在本申请的保护范围内。
- 一种储层评价模型构建方法及储层识别方法
- 储层类型识别用三维图版构建方法以及储层类型识别方法