融合主动学习和对比学习的血透并发心血管疾病预测系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及一种医疗健康信息技术领域,尤其涉及融合主动学习和对比学习的血透并发心血管疾病预测系统。
背景技术
维持性血液透析(血透)治疗是终末期肾病的主要治疗方式之一,保障血透患者得到有效治疗,已成为目前临床医疗领域的迫切需求。血透治疗是一种贯穿病程发展的长期治疗手段。长期血透过程中可能发生多种心血管并发疾病,严重影响患者生存状况。因此,对维持性血透的心血管并发症进行风险预测以及早期干预,对于提高终末期肾病患者生存质量至关重要。
对比学习是一种自监督算法,被广泛应用于计算机视觉、自然语言处理等多种领域,近年来甚至在各种主流任务中取得了超过监督学习的模型性能。将适用于自监督任务的对比学习方法应用于有监督的血透并发心血管疾病预测任务仍有一定困难。一方面,心血管并发症预测是有监督的任务,相较于无监督任务提供了额外的标签信息,如何有效利用真实的并发症结果标签提升模型性能是一个关键问题。另一方面,对比学习的关键在于匹配合适的正负样本,不合适的匹配方法将严重影响模型性能,如何匹配合适的、最有价值的正负样本以提升模型性能是一个关键问题。
本专利旨在针对以上问题,面向血透并发心血管疾病预测场景,构建融合主动学习和对比学习的血透并发心血管疾病预测系统,为临床决策提供准确、有效的决策支持。
发明内容
本发明为了解决上述技术问题,提供融合主动学习和对比学习的血透并发心血管疾病预测系统。
本发明采用的技术方案如下:
一种融合主动学习和对比学习的血透并发心血管疾病预测系统,包括:
血透数据准备模块,用于利用医院电子信息系统和日常监测设备提取患者样本的结构化数据,并对所述结构化数据处理得到扩增结构化数据;
血透并发心血管疾病风险预测模块,用于构建风险评价模型,将所述扩增结构化数据通过所述风险评价模型训练学习得到患者表征和评分,并利用所述患者表征和评分进行血透并发心血管疾病风险预测。
进一步地,所述结构化数据包括人口统计学数据、临床事件数据、用药数据和日常监测数据。
进一步地,所述血透数据准备模块具体包括:
数据获取单元,用于利用医院电子信息系统和穿戴设备提取患者样本的结构化数据;
数据清洗单元,用于对所述结构化数据进行缺失值处理、错误值的检测、重复数据的消除和/或不一致性的消除操作,得到静态数据和时序数据;
数据融合单元,用于对所述时序数据采用卷积操作得到的一维压缩数据和所述静态数据进行拼接后得到原始融合特征;
数据扩增单元,用于将所述原始融合特征采用单特征随机化法,得到扩增结构化数据。
进一步地,所述数据扩增单元的扩增过程为:
步骤S1:将所述原始融合特征为患有心血管并发症的患者作为原始阳性样本,所述原始融合特征为未患有心血管并发症的患者作为原始阴性样本,所有所述原始阳性样本构成原始阳性样本集合,所有所述原始阴性样本构成原始阴性样本集合;
步骤S2:当所述原始阳性样本的数量小于所述原始阴性样本的数量,则对所述原始阳性样本集合进行扩增,得到扩增阳性样本,直至阳性样本的数量等于所述原始阴性样本的数量;当所述原始阳性样本的数量大于所述原始阴性样本的数量,则对所述原始阴性样本集合进行扩增,得到扩增阴性样本,直至阴性样本的数量等于所述原始阳性样本的数量;
步骤S3:所述原始阳性样本集合和所述扩增阳性样本构成阳性样本扩增集,所述原始阴性样本集合和所述扩增阴性样本构成阴性样本扩增集;
步骤S4:所述阳性样本扩增集和所述阴性样本扩增集共同构成扩增结构化数据。
进一步地,所述步骤S2中得到扩增阳性样本的过程为:
将所述原始融合特征与所述原始阳性样本集合进行组合,得到组合阳性样本集,所述组合阳性样本集中包含单个原始融合特征及单个原始融合特征对应的单个阳性样本集;
将单个所述组合阳性样本集中的单个原始融合特征作为干预特征,将单个所述组合阳性样本集中的其余原始融合特征作为固定特征集,单个所述阳性样本集中的阳性样本作为扩增对象进行样本扩增,得到单个扩增阳性样本,直至扩增的次数为所述原始阴性样本与所述原始阳性样本的差值,完成整个扩增过程,得到最终的扩增阳性样本;
得到扩增阴性样本的过程为:
将所述原始融合特征与所述原始阴性样本集合进行组合,得到组合阴性样本集,所述组合阴性样本集中包含单个原始融合特征及单个原始融合特征对应的单个阴性样本集;
将单个所述组合阴性样本集中的单个原始融合特征作为干预特征,将单个所述组合阴性样本集中的其余原始融合特征作为固定特征集,单个所述阴性样本集中的阴性样本作为扩增对象进行样本扩增,得到单个扩增阴性样本,直至扩增的次数为所述原始阴性样本与所述原始阳性样本的差值,完成整个扩增过程,得到最终的扩增阴性样本。
进一步地,所述血透并发心血管疾病风险预测模块具体包括:
风险评价单元:用于构建风险评价模型,利用所述扩增结构化数据作为模型的训练数据,得到评分和患者表型;
主动学习单元:用于利用所述评分和所述患者表型,通过正负样本挑选规则器从所述扩增结构化数据中挑选出正负样本;
对比学习单元:用于利用所述正负样本进行对比学习,更新与风险评价单元共用的编码器的网络参数。
进一步地,所述风险评价单元具体包括:
用于利用编码器和风险评价网络构建模型,通过损失函数进行优化,完成风险评价模型的构建;
用于利用所述风险评价模型中的编码器提取患者表型,所述患者表型通过所述风险评价网络计算血透并发心血管疾病的评分;
用于为患者设置真实标签,当患者患有心血管并发症,则真实标签为1;反之,则真实标签为0;
用于利用所述评分和所述真实标签对损失函数进行优化。
进一步地,所述主动学习单元具体包括:
用于对所述风险评价模型输出的患者表型做归一化处理,得到的患者表征通过归一化处理映射到0-1空间中;
用于利用正负样本挑选规则器分别计算所述扩增结构化数据中的每个样本表征到其他样本表征在0-1空间方向的夹角;
用于将计算得到每个样本的夹角按照其他样本的真实标签是否和当前样本的真实标签相同,分为第一组和第二组,并将第一组和第二组内部分别按从小到大排序;
用于将排序后的第一组中选取上四分位数作为正样本集,排序后的第二组中选取下四分位数作为负样本集。
进一步地,所述对比学习单元具体包括:用于利用所述正负样本进行对比学习,正样本和患者样本的真实标签相同,负样本和患者样本的真实标签不同,计算正样本和患者样本的正样本余弦距离、负样本和患者样本的负样本余弦距离,通过正样本余弦距离和负样本余弦距离构建对比学习单元的损失函数,更新与风险评价单元共用的编码器的网络参数。
进一步地,所述风险评价单元、所述主动学习单元和所述对比学习单元共用所述编码器,所述编码器为5层全连接网络,每层节点数分别为1024、512、256、128、64,激活函数为ReLU。
本发明的有益效果是:
1、本发明提出基于主动学习的正负样本匹配方法,挑选出高价值的对比样本以提升模型性能,解决正负样本匹配问题。
2、本发明提出融合主动学习和对比学习的训练方法,利用血透并发心血管疾病的真实标签数据,迭代式地更新对比学习模型参数,解决有监督场景下如何有效利用真实的并发症结果标签提升模型性能的问题。
3、本发明提出单特征随机化法扩增原始数据,解决采集的样本过少或者阳性样本和阴性样本数量不平衡的问题,同时减少扩增数据与原始数据的差异性。
附图说明
图1为本发明融合主动学习和对比学习的血透并发心血管疾病预测系统的框架图;
图2为本发明血透数据准备模块的框架图;
图3为本发明血透并发心血管疾病风险预测模块的框架图。
具体实施方式
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
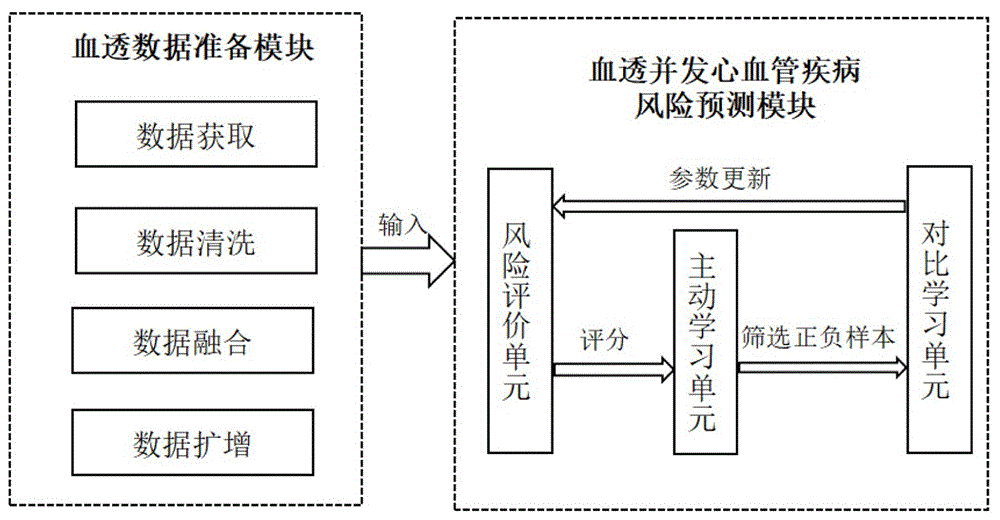
参见图1,一种融合主动学习和对比学习的血透并发心血管疾病预测系统,包括:
血透数据准备模块,用于利用医院电子信息系统和日常监测设备提取患者样本的结构化数据,并对所述结构化数据处理得到扩增结构化数据;
所述结构化数据包括人口统计学数据、临床事件数据、用药数据和日常监测数据;
(1)人口统计学数据:年龄、性别、地区等;(2)临床事件数据:血透事件、诊断事件等;(3)用药数据:药物名称、剂量等;(4)日常监测数据:血压、心率、体重等。
参见图2,所述血透数据准备模块具体包括:
数据获取单元,用于利用医院电子信息系统和穿戴设备提取患者样本的结构化数据;
数据清洗单元,用于对所述结构化数据进行缺失值处理、错误值的检测、重复数据的消除和/或不一致性的消除操作,得到静态数据和时序数据;
以并发症诊断事件信息为例,对于缺失的并发症确诊时间可以使用首次使用并发症药物时间填充;对于缺失的并发症名称可以通过并发症用药情况来判断具体的并发症名称;如果无法通过用药信息判断出该并发症名称时,则主动筛查掉该缺失的并发症诊断信息。
数据融合单元,用于对所述时序数据采用卷积操作得到的一维压缩数据和所述静态数据进行拼接后得到原始融合特征;
采集到的患者基本信息例如年龄、性别这些属于静态数据,而血透信息、日常检测信息属于一维的时序数据。对一维时序数据采用卷积操作,使其能够和静态数据融合,便于后续的数据处理和模型的训练。
数据扩增单元,用于将所述原始融合特征采用单特征随机化法,得到扩增结构化数据。
在采集的样本过少或者阳性样本和阴性样本数量不平衡的情况下,都会对模型的训练效果产生影响。为了减少这种影响,本发明将采用单特征随机化法扩增原始数据,解决采集的样本过少或者阳性样本和阴性样本数量不平衡问题。为了能够尽可能的减少扩增数据与实际数据的差别,在使用单特征随机化法扩增原始数据过程中,每次只选取一个特征作为干预特征剩余特性集作为固定特征进行样本扩增。
所述数据扩增单元的扩增过程为:
步骤S1:将所述原始融合特征为患有心血管并发症的患者作为原始阳性样本,所述原始融合特征为未患有心血管并发症的患者作为原始阴性样本,所有所述原始阳性样本构成原始阳性样本集合,所有所述原始阴性样本构成原始阴性样本集合;
步骤S2:当所述原始阳性样本的数量小于所述原始阴性样本的数量,则对所述原始阳性样本集合进行扩增,得到扩增阳性样本,直至阳性样本的数量等于所述原始阴性样本的数量;当所述原始阳性样本的数量大于所述原始阴性样本的数量,则对所述原始阴性样本集合进行扩增,得到扩增阴性样本,直至阴性样本的数量等于所述原始阳性样本的数量;
得到扩增阳性样本的过程为:
将所述原始融合特征与所述原始阳性样本集合进行组合,得到组合阳性样本集,所述组合阳性样本集中包含单个原始融合特征及单个原始融合特征对应的单个阳性样本集;
将单个所述组合阳性样本集中的单个原始融合特征作为干预特征,将单个所述组合阳性样本集中的其余原始融合特征作为固定特征集,单个所述阳性样本集中的阳性样本作为扩增对象进行样本扩增,得到单个扩增阳性样本,直至扩增的次数为所述原始阴性样本与所述原始阳性样本的差值,完成整个扩增过程,得到最终的扩增阳性样本;
现有原始阳性样本数量为M,原始阴性样本数量为N,并且
原始融合特征记作
然后将原始融合特征V和原始阳性样本集合X进行组合,得到组合阳性样本集,组合阳性样本集记作
对于单个的扩增阳性样本
其中,
得到扩增阴性样本的过程为:
将所述原始融合特征与所述原始阴性样本集合进行组合,得到组合阴性样本集,所述组合阴性样本集中包含单个原始融合特征及单个原始融合特征对应的单个阴性样本集;
将单个所述组合阴性样本集中的单个原始融合特征作为干预特征,将单个所述组合阴性样本集中的其余原始融合特征作为固定特征集,单个所述阴性样本集中的阴性样本作为扩增对象进行样本扩增,得到单个扩增阴性样本,直至扩增的次数为所述原始阴性样本与所述原始阳性样本的差值,完成整个扩增过程,得到最终的扩增阴性样本。
步骤S3:所述原始阳性样本集合和所述扩增阳性样本构成阳性样本扩增集,所述原始阴性样本集合和所述扩增阴性样本构成阴性样本扩增集;
步骤S4:所述阳性样本扩增集和所述阴性样本扩增集共同构成扩增结构化数据。
血透并发心血管疾病风险预测模块,用于构建风险评价模型,将所述扩增结构化数据通过所述风险评价模型训练学习得到患者表征和评分,并利用所述患者表征和评分进行血透并发心血管疾病风险预测。
血透并发心血管疾病风险预测模块包括三部分:风险评价单元、主动学习单元、对比学习单元,如图3所示。首先利用扩增结构化数据作为系统的输入,通过风险评价单元训练出一个初步的风险评价模型;然后主动学习单元利用风险评价单元的输出评分p和患者表型s1、s2,通过正负样本挑选规则器 R从扩增结构化数据中挑选出高价值的对比样本供对比学习单元学习;最后对比学习单元利用主动学习单元挑选的高质量对比样本进行学习,使得具有相同标签的样本更加接近,不同标签的样本更加远离,同时更新与风险评价单元共用的编码器 f参数,使得风险评价模型更加准确。
所述血透并发心血管疾病风险预测模块具体包括:
风险评价单元:用于构建风险评价模型,利用所述扩增结构化数据作为模型的训练数据,得到评分和患者表型;
所述风险评价单元具体包括:
用于利用编码器和风险评价网络构建模型,通过损失函数进行优化,完成风险评价模型的构建;
用于利用所述风险评价模型中的编码器提取患者表型,所述患者表型通过所述风险评价网络计算血透并发心血管疾病的评分;
用于为患者设置真实标签,当患者患有心血管并发症,则真实标签为1;反之,则真实标签为0;
用于利用所述评分和所述真实标签对损失函数进行优化。
所述风险评价单元、所述主动学习单元和所述对比学习单元共用所述编码器 f,所述编码器 f为5层全连接网络,每层节点数分别为1024、512、256、128、64,激活函数为ReLU。
患者原始融合特征利用编码器 f提取患者表型S(患者表型S是一个64位向量)后,通过风险评价网络
其中,N表示扩增结构化数据中所有样本的数量,
主动学习单元:用于利用所述评分和所述患者表型,通过正负样本挑选规则器从所述扩增结构化数据中挑选出正负样本;
主动学习单元作用是结合风险评价单元,挑选出高价值的对比样本供对比学习单元学习,使得相同标签的患者表征更加接近,不同标签患者表征之间更加远离。
所述主动学习单元具体包括:
用于对所述风险评价模型输出的患者表型做归一化处理,得到的患者表征通过归一化处理映射到0-1空间中;
首先,对风险评价单元产生的患者表型s做归一化处理,记作
正负样本规则挑选器R的作用是利用挑选规则从原始输入样本集中挑选出其正负样本。
正负样本规则挑选器R利用了如下规则:相同标签的患者表型向量之间的余弦距离应该是相近的,不同标签的样本他们患者表型向量之间的余弦距离应该远离。挑选样本i的正样本j的规则是样本j与样本i真实标签相同,但是样本j与样本i的余弦距离比较远。希望通过对比学习,使得样本i与正样本之间余弦距离更加接近;挑选样本i的负样本k的规则是样本k与样本i真实标签不同,但是样本k与样本i的余弦距离比较小。希望通过对比学习,使得样本i与负样本k之间余弦距离更加远离;
用于利用正负样本挑选规则器分别计算所述扩增结构化数据中的每个样本表征到其他样本表征在0-1空间方向的夹角;
利用公式
用于将计算得到每个样本的夹角按照其他样本的真实标签是否和当前样本的真实标签相同,分为第一组和第二组,并将第一组和第二组内部分别按从小到大排序;
将计算得到样本i与其他样本之间夹角余弦按照其他样本的真实标签是否和样本i的真实标签相同分为两组
用于将排序后的第一组中选取上四分位数作为正样本集,排序后的第二组中选取下四分位数作为负样本集。
在排序后的
对比学习单元:用于利用所述正负样本进行对比学习,更新与风险评价单元共用的编码器的网络参数。
所述对比学习单元具体包括:用于利用所述正负样本进行对比学习,正样本和患者样本的真实标签相同,负样本和患者样本的真实标签不同,计算正样本和患者样本的正样本余弦距离、负样本和患者样本的负样本余弦距离,通过正样本余弦距离和负样本余弦距离构建对比学习单元的损失函数,更新与风险评价单元共用的编码器的网络参数。
在对比学习单元里,主动学习单元基于真实标签与患者表征,挑选原样本的正负样本。正负样本通过编码器f得到正负样本的患者表征s,得到的正负样本患者表征s会通过投影器h进行表征映射得到映射后的对比表征t,投影器h是一个3层全连接网络,每层节点数量分别为512,256,128,激活函数为ReLU函数,使用SGD函数作为优化器。得到映射后的表征会进行归一化,记作
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。