一种基于深度学习的水稻种植结构遥感提取方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及遥感分类技术领域,尤其涉及一种基于深度学习的水稻种植结构的遥感提取方法。
背景技术
水稻是我国种植面积最大、覆盖范围最广的主粮作物,水稻种植结构的准确提取对水稻产量预估具有极为重要的意义。在气候变化等多种因素的共同作用下,区域水稻种植结构不断改变。水稻按照稻作制度的不同可细分为双季稻、单季晚稻、中稻、再生稻。其中双季稻、单季晚稻、中稻、再生稻作为水稻种植结构类型处于农田-水稻-水稻类型中的第三级细分类型。这些细分水稻类型都是“同物同谱”的水稻,区别仅在于稻作制度和栽培方式,区分再生稻和双季稻则更为困难。遥感技术具有覆盖范围广、探测周期短、现势性强和费用成本低等优点,已成为提取水稻种植结构的重要手段,利用遥感技术可以实时精确地得到大区域水稻种植地理空间分布信息。遥感技术主要包括单景光谱影像方法、基于时序光谱的物候特征法和机器学习分类算法,这些遥感技术用于提取水稻种植结构的缺点如下:
单景光谱影像方法难以克服“异物同谱”、“同物异谱”等问题,分类结果往往存在“椒盐现象”,影响作物识别准确性,存在种植面积大量错分、漏分等状况。
基于时序光谱的物候特征法采用了作物完整生长周期内的影像数据,虽然解决了单景光谱影像方法的“异物同谱”等问题,但基于时序光谱的物候特征法通过光谱指数阈值进行水稻识别,分类阈值依赖人工干预,需要主观反复推敲进行修订,光谱混淆区分类精度仍然不高。
而机器学习分类算法在处理高维数据与冗余数据方面有强大优势的同时,不依赖人工干预,与传统方法相比,其应用能显著提升运算效率与分类精度。现有的机器学习分类算法包括贝叶斯分类算法、随机森林分类算法、支持向量机分类算法、决策树分类算法、K-最近邻分类算法等。
但现有的单一机器学习分类算法,如随机森林算法,在区分这些“同物同谱”的细分水稻类型时仍然难以获得高精度的结果或者直接无法区分。因此,需要解决如何联用多种分类算法对多种不同水稻细分类型进行精细分类的问题。
发明内容
本申请旨在解决如何联用多种分类算法对“同物同谱”的多种不同水稻细分类型进行精细分类的问题。
为解决上述技术问题,本发明提供如下技术方案:
一种基于深度学习的水稻种植结构遥感提取方法,包括:
获取目标种植区域的遥感数据,并基于NDVI模型和所述目标种植区域的遥感数据,形成NDVI时间序列数据集;
获取水稻种植区域的实地样本点数据,并基于所述实地样本点数据,将NDVI时间序列数据集赋值到目标种植区域遥感数据的各像素点,获得水稻种植样本点;所述水稻种植区域为目标种植区域内的水稻种植区域;
以水稻种植样本点作为输入量,水稻种植区域的实地样本点数据作为输出量,训练和测试不同的机器学习算法,获得各机器学习算法的验证精度;
获取待测目标区域的遥感数据,选取验证精度达标的多种机器学习算法进入得分策略,以进入得分策略的多种机器学习算法分别对待测目标区域的遥感数据中目标像元进行水稻类型划分,每种机器学习算法对应输出一种水稻类型;
基于得分策略,输入各机器学习算法的验证精度和对应输出的水稻类型,获得待测目标区域的遥感数据中目标像元的水稻类型。优选地,所述得分策略具体为:多种机器学习算法进入得分策略后,将每个机器学习算法的验证精度作为权重值赋予其对应输出的水稻类型,将同一目标像元下水稻类型相同的权重值求和获得综合赋分值,最后比较不同水稻类型的综合赋分值,综合赋分值最大的水稻类型即为该目标像元的水稻类型。
优选地,以水稻种植样本点作为输入量,水稻种植区域的实地样本点数据作为输出量,训练和测试机器学习算法的具体方法为:
将水稻种植样本点分割为训练集与测试集,提取水稻种植样本点对应的NDVI时间序列数据集作为输入量,水稻种植区域的实地样本点数据作为输出量,运用训练集对每个机器学习算法进行训练,并调用混淆矩阵对每个机器学习算法精度进行定量评价,再利用测试集验证精度。
优选地,由目标种植区域内的归一化植被指数形成NDVI时间序列数据集的具体方法为:
基于归一化植被指数,以月内归一化植被指数的最大值计算得到NDVI月值,由NDVI月值形成NDVI时间序列数据集。
优选地,所述遥感数据和待分类的遥感数据均为已经过正射校正、几何精度矫正及大气校正处理的卫星影像数据。
优选地,机器学习算法包括但不限于K-近邻分类算法、决策树分类算法、朴素贝叶斯分类算法、逻辑回归分类算法、支持向量机分类算法、随机森林分类算法。
上述水稻种植结构的遥感提取方法针对的水稻类型为具有不同稻作制度或栽培模式的水稻细分类型。
进一步地,所述水稻细分类型包括再生稻。
本发明还提供一种基于深度学习的水稻种植结构的遥感提取系统,应用上述基于深度学习的水稻种植结构的遥感提取方法对待测目标区域的遥感数据进行水稻类型的识别,包含如下组件:
遥感数据处理模块:用于将多时相卫星影像数据计算处理形成NDVI时间序列数据集,将NDVI时间序列数据集输出至存储模块;
存储模块:用于接收并存储NDVI时间序列数据集和实地样本点数据,形成并存储水稻种植样本点;输出水稻种植样本点数据至训练模块;
训练模块:提取存储模块中的水稻种植样本点对应的NDVI月值数据输入训练机器学习分类算法,输出机器学习分类算法的验证精度至识别模块;
识别模块:接收输出机器学习分类算法的验证精度,利用得分策略计算输出待测目标区域的遥感数据中各像元的水稻类型。
本发明提供一种计算机存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述基于深度学习的水稻种植结构的遥感提取方法的步骤。
本发明取得的有益效果:
一、本发明利用处理后的遥感数据结合实地样本点形成水稻种植样本点,利用水稻种植样本点对多种机器学习模型同时训练并验证精度,将多个机器学习模型的精度输出至得分策略,通过得分策略识别判断像元的水稻类型。由于这一方法同步训练和测试了多种机器学习模型,且利用得分策略将多种机器学习模型有机地结合起来,用以判断识别单一模型难以区分的水稻细分类型,因此,本发明区分的地物非常精细,能够对“同物同谱”的多种不同水稻细分类型进行精细分类。
二、本发明中的得分策略并非简单地比较多种机器学习模型的精度来输出水稻类型,而是创造性地将不同机器学习模型的精度作为权重赋值给对应的水稻类型,再合并相同水稻类型的赋分值,在此基础上比较综合赋分值并输出水稻类型。这种赋分合并再比较的过程中充分调用了多种机器学习方法的输出模型,有机地将多种机器学习方法结合起来对像元的水稻类型进行识别,大幅提升了识别的准确度,规避了单一模型的缺点,多种模型之间优势互补,因而能够对水稻细分类型进行精确分类。
附图说明
图1为本申请实施例提供的用于划分水稻细分类型的K-最近邻分类算法流程图。
图2为本申请实施例提供的用于划分水稻细分类型的决策树分类算法流程图。
图3为本申请实施例提供的用于划分水稻细分类型的随机森林流程图。
图4为本申请实施例提供的用于划分水稻细分类型的支持向量机流程图。
图5为本发明总技术路线图。
图6为实地样本点分布图。
图7为4个水稻类型的水稻物候期统计图。
具体实施方式
以下对本申请的具体实施方式进行详细说明。显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
再生稻是我国近几年才推广种植的,是指在头季稻收割后,经过栽培管理措施,稻桩上的腋芽萌发生长、抽穗结实从而再收获一季的水稻种植模式。相对于单季稻,种植再生稻能充分利用光热资源,提高稻田复种指数和水稻产量;相对于双季稻,种植再生稻省工省肥,具有更高的经济效益。作为一种新兴的水稻栽培模式,传统的分类算法已经无法适应这种新加入的水稻类型细分需求,对整体水稻种植结构无法做到精准细分。
本实施例以双季稻、单季晚稻、中稻、再生稻四种水稻类型为例进行水稻种植结构的遥感提取,具体方法为:
1、获取用于训练和验证机器学习算法的目标种植区域遥感数据。
哨兵2号卫星包括哨兵2A(Sentinel-2A)、哨兵2B(Sentinel-2B)两颗卫星,彼此轨道相差180º,两颗卫星作为一组的图像采集时间分辨率为5天。哨兵2号卫星所携带的多光谱成像仪(MSI),高度为786 km,幅宽达290 km,覆盖了从可见光和近红外到短波红外的13个光谱波段,空间分辨率随具体波段为10 m、20 m、60 m不等,具体波段见表1。
表
卫星遥感的影像与处理均在GEE(Google Earth Engine)地理遥感云计算平台上进行。
2、基于NDVI模型和所述目标种植区域的遥感数据,形成NDVI时间序列数据集;
本实施例首先通过代码调用已经过正射校正、几何精度矫正及大气校正处理的某年哨兵2号卫星影像数据,通过波段运算计算出NDVI(归一化植被指数),NDVI计算公式如下,
式中:NIR指近红外波段光谱,为哨兵2数据Band 4,波段空间分辨率为10 m;RED指红光波段光谱,为哨兵2数据Band 8,波段空间分辨率为10 m。
基于归一化植被指数,以月内归一化植被指数的最大值计算得到NDVI月值,由NDVI月值形成NDVI时间序列数据集,本实例中操作方法如下:
月内多景影像取NDVI最大值为该月NDVI数据,生成年内12个月的逐月NDVI数据,形成NDVI时间序列数据集,此数据集为机器学习方法的输入数据。
3、获得水稻种植样本点并用于训练和验证机器学习算法。获取水稻种植区域的实地样本点数据,并基于所述实地样本点数据,将NDVI时间序列数据集赋值到目标种植区域遥感数据的各像素点,获得水稻种植样本点;所述水稻种植区域为目标种植区域内的水稻种植区域;
本实施例在该年对研究区内的水稻种植区域进行野外调查,获取实地样本点数据,实地样本点分布见图6。最终获得4个水稻类型共1000个水稻种植样本点,4个水稻类型水稻物候期见图7。
以水稻种植样本点作为输入量,水稻种植区域的实地样本点数据作为输出量,训练和测试机器学习算法的具体方法为:
将水稻种植样本点按照一定比例分割为训练集与测试集,提取水稻种植样本点对应的NDVI时间序列数据集作为输入量,水稻种植区域的实地样本点数据作为输出量,运用训练集对每个机器学习算法进行训练,并调用混淆矩阵对每个机器学习算法精度进行定量评价,再利用测试集验证精度,获得各机器学习算法的验证精度。
本实施例中提取1000个水稻种植样本点对应的年内12个月的逐月NDVI月值数据作为输入量导入多种机器学习算法,以野外调查结果作为水稻类型识别真值,将1000个水稻种植样本点按照7:3的比例随机抽取分割为训练集与测试集,训练集用于对机器学习算法进行训练,测试集用于验证机器学习算法的精度,本实施例中训练的机器学习算法包括K最邻近分类算法(图1)、决策树分类算法(图2)、随机森林分类算法(图3)和支持向量机分类算法(图4),并调用混淆矩阵对分类模型精度进行定量评价,获得各机器学习算法的验证精度。
4、基于得分策略输出待测目标像元的水稻类型。
获取待测目标区域的遥感数据,选取验证精度达标的多种机器学习算法进入得分策略,以进入得分策略的多种机器学习算法分别对待测目标区域的遥感数据中目标像元进行水稻类型划分,每种机器学习算法对应输出一种水稻类型;
基于得分策略,输入各机器学习算法的验证精度和对应输出的水稻类型,获得待测目标区域的遥感数据中目标像元的水稻类型。
将多种机器学习算法中精度高于80%的算法模型进入得分策略。得分策略为:多种机器学习算法进入得分策略后,将每个机器学习算法的验证精度作为权重值赋予其对应输出的水稻类型,将同一目标像元下水稻类型相同的权重值求和获得综合赋分值,最后比较不同水稻类型的综合赋分值,综合赋分值最大的水稻类型即为该目标像元的水稻类型。例如,令表2中4种机器学习算法的验证精度值直接作为权重值赋予各自对应划分的水稻类型,将目标像元1下双季稻、单季晚稻、中稻、再生稻的权重值分别求和获得综合赋分值,最后比较4种水稻类型的综合赋分值,综合赋分值最大的水稻类型即为该目标像元输出的水稻类型。再对像元2~6分别重复上述赋分、求和、比较过程,如表2和表3所示:
表2 四种机器学习算法对不同像元的水稻类型划分结果
表3综合赋分值和水稻类型输出结果
表2中4种机器学习算法训练并得出的验证精度分别为85%、87%、89%、91%(表3所示)。利用四种机器学习算法对待划分的不同像元(目标像元1~6)分别进行水稻类型的划分,同一像元的水稻类型利用不同的机器学习算法进行划分,可能会存在不同的划分结果,但同一像元的真值只有一个,这时就需要得分策略来进行水稻类型的判定输出。根据得分策略将85%、87%、89%、91%分别作为85、87、89和91的权重分值赋予对应的水稻类型,将同一像元下相同水稻类型的权重分值求和,将最大赋分值的水稻类型作为输出类型,即可识别目标像元的水稻类型(表3)。
当然,本实施例中的4种分类算法也可以等同替换为其他机器学习算法,机器学习算法包括但不限于K近邻、决策树、朴素贝叶斯、逻辑回归、支持向量机、随机森林等。
如图1~4所示,本实施例中四种机器学习算法的具体技术流程和精度如下:
一、运行环境
1、配备PyCharm 2019.3.3
2、导入相关库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.metrics import classification_report, confusion_matrix,accuracy_score
import joblib
二、导入数据
1、样本点:1000个,分为双季稻(250个)、单季晚稻(250个)、再生稻(250个)、中稻(250个),分别赋值为1、2、3、4;
2、特征变量:12个,月ndvi(归一化植被指数)
三、方法
1、分训练集(70%)、验证集(30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1,test_size=0.30)
2、机器学习算法
(1)随机森林分类算法(Random Forest)
classifier=RandomForestClassifier(n_estimators=65,max_depth=5,max_features=None,random_state=1)
l n_estimators:integer,optional(default=10)森林里的树木数量10,50,100,...
l max_depth:integer或None,可选(默认=无)树的最大深度5,8,15,...
l max_features:每个决策树的最大特征数量
If"auto",then sqrt(n_features)
If"sqrt",then sqrt(n_features)(same as"auto")
If"log2",then log2(n_features)
If None,then n_features
If "float",then float*n_features
l random_state:int/None,有必要控制随机的状态,才能重复的展现相同的结果
(2)支持向量机分类算法(SVM)
classifier=svm.SVC(kernel='rbf',gamma=0.8,decision_function_shape='ovr',C=0.95)
l kernel='linear'时,为线性核函数,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
kernel='rbf'(default)时,为高斯核函数,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
l decision_function_shape='ovo'时,为one v one分类问题,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
decision_function_shape='ovr'时,为one v rest分类问题,即一个类别与其他类别进行划分。
(3)决策树分类算法(Decision Tree)
classifier = DecisionTreeClassifier()
(4)K-最近邻算法分类
classifier=KNeighborsClassifier(n_neighbors=7,weights='uniform',algorithm='auto',leaf_size=50,p=2,metric='minkowski',metric_params=None,n_jobs=None)
l n_neighbors: int, 可选参数(默认为 5)用于kneighbors查询的默认邻居的数量
l weights(权重): str or callable(自定义类型), 可选参数(默认为‘uniform’)
‘uniform’ : 统一的权重. 在每一个邻居区域里的点的权重都是一样的。
‘distance’ : 权重点等于他们距离的倒数。使用此函数,更近的邻居对于所预测的点的影响更大。[
‘callable’ : 一个用户自定义的方法,此方法接收一个距离的数组,然后返回一个相同形状并且包含权重的数组。
l algorithm(算法): {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 可选参数(默认为 ‘auto’)
‘ball_tree’ 是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
‘kd_tree’ 构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
‘brute’ 使用暴力搜索.也就是线性扫描,当训练集很大时,计算非常耗时
‘auto’ 会基于传入fit方法的内容,选择最合适的算法。
l leaf_size(叶子数量): int, 可选参数(默认为 30)
传入BallTree或者KDTree算法的叶子数量。此参数会影响构建、查询BallTree或者KDTree的速度,以及存储BallTree或者KDTree所需要的内存大小。 此可选参数根据是否是问题所需选择性使用。
l p: integer, 可选参数(默认为 2)
用于Minkowski metric(闵可夫斯基空间)的超参数。
p = 1, 相当于使用曼哈顿距离 (l1);
p = 2, 相当于使用欧几里得距离(l2) ;
对于任何 p ,使用的是闵可夫斯基空间(l_p)。
l metric(矩阵): string or callable, 默认为 ‘minkowski’
用于树的距离矩阵。默认为闵可夫斯基空间,如果和p=2一块使用相当于使用标准欧几里得矩阵. 所有可用的矩阵列表请查询 DistanceMetric 的文档。
l metric_params(矩阵参数): dict, 可选参数(默认为 None),给矩阵方法使用的其他的关键词参数。
l n_jobs: int, 可选参数(默认为 1),用于搜索邻居的,可并行运行的任务数量。
四、方法精度对比
表4不同方法的精度
五、模型保存与调用
(1)模型输出
Model=joblib.dump(classifier,'sdClassifier.pkl')
(2)模型调用
Model=joblib.load('sdClassifier.pkl')。
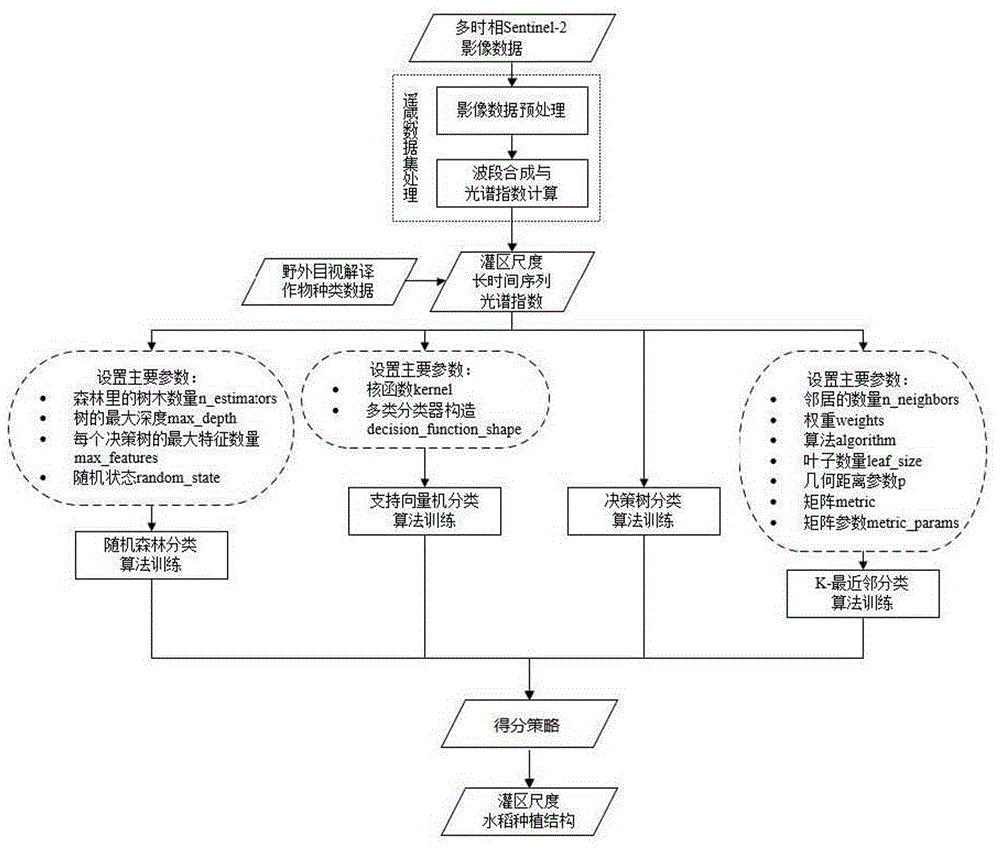
上述流程中包含4种机器学习分类算法的主要参数设置和调用函数,如图5所示,获取多时相卫星影像数据后,对多时相卫星影像数据进行预处理(例如正射校正、几何精度矫正及大气校正处理),再进行波段合成与光谱指数(例如NDVI)计算,将计算结果(即NDVI时间序列数据集)结合野外目视解译作物种类数据(即实地样本点数据),形成灌区尺度长时间序列光谱指数(即水稻种植样本点),多种机器学习算法分别设置主要参数后,利用灌区尺度长时间序列光谱指数作为输入量并行训练和验证多种机器学习算法,以训练后精度达标的多种机器学习算法对待测目标区域的遥感数据中目标像元进行水稻类型划分,以得分策略最终确认目标像元的唯一水稻细分类型输出值,以若干目标像元的水稻细分类型输出值形成灌区尺度水稻种植结构。
基于深度学习的水稻种植结构的遥感提取方法对待测目标区域的遥感数据进行水稻类型的识别,本申请还提供一种基于深度学习的水稻种植结构的遥感提取系统,包含如下组件:
遥感数据处理模块:用于将多时相卫星影像数据计算处理形成NDVI时间序列数据集,将NDVI时间序列数据集输出至存储模块;
存储模块:用于接收并存储NDVI时间序列数据集和实地样本点数据,形成并存储水稻种植样本点;输出水稻种植样本点数据至训练模块;
训练模块:提取存储模块中的水稻种植样本点对应的NDVI月值数据输入训练机器学习分类算法,输出机器学习分类算法的验证精度至识别模块;
识别模块:接收输出机器学习分类算法的验证精度,利用得分策略计算输出待测目标区域的遥感数据中各像元的水稻类型。
本发明还提供一种计算机存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述基于深度学习的水稻种植结构的遥感提取方法的步骤。
以上结合具体实施方式和范例性实例对本申请进行了详细说明,不过这些说明并不能理解为对本申请的限制。本领域技术人员理解,在不偏离本申请精神和范围的情况下,可以对本申请技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本申请的范围内。本申请的保护范围以所附权利要求为准。