一种语音智能床头柜及其语音处理方法、语音控制系统
文献发布时间:2023-06-19 09:29:07
技术领域
本申请涉及智能家具的领域,尤其是涉及一种语音智能床头柜及其语音处理方法、语音控制系统。
背景技术
现在的科学技术快速发展,智能家具的产生打破了传统家具的组合模式,将组合智能、电子智能、机械智能、物联智能融入到家具产品中,使家具智能化。
智能音箱常用于嵌入各式家具内,以实现家具的智能化,用于对装载智能音箱的家具发出语音命令,智能音箱对语音命令作出响应,以装载于床头柜内的智能音箱为例,床头柜内预设有容纳智能音箱的容纳腔,智能音箱接收容纳腔传进的单路语音信号。
针对上述中的相关技术,发明人认为存在有智能音箱对于语音的接收清晰度受使用者处于的位置影响,若使用者处于的位置与智能音箱内麦克风接收语音路径有较大的偏差,则智能音箱的语音接收效果较差的缺陷。
发明内容
为了提高床头柜内的智能音箱的语音接收效果,本申请提供一种语音智能床头柜及其语音处理方法、语音控制系统。
第一方面,本申请提供的一种语音智能床头柜采用如下的技术方案:
一种语音智能床头柜,包括柜体,所述柜体内设有智能音箱模块,所述智能音箱模块包括若干麦克风,所述柜体上若干个侧面均设有声音接收口,所述声音接收口的位置分别对应麦克风的位置。
通过采用上述技术方案,通过预设于智能音箱模块上的麦克风有声音接收口接收来自各个方向的语音信号,且通过处理将语音信号叠合,从而具有提高语音接收效果的作用。
优选的,所述柜体对应智能音箱模块的位置设有容纳腔,所述容纳腔内滑动设有承托智能音箱模块的承托板,所述柜体靠近容纳腔的侧壁设有位于承托板远离智能音箱模块一侧的滑轨,所述容纳腔位于滑轨长度方向的一侧与外界连通。
通过采用上述技术方案,承托板承托智能音箱模块,且承托板可沿滑轨滑动,具有可根据实际使用习惯调节麦克风位置的效果。
优选的,所述承托板靠近滑轨的一侧设有限位槽,所述滑轨上对应限位槽的位置设有贯穿滑轨的安装口,所述滑轨对应安装口的位置通过转动轴设有绕转动轴转动设于安装口且一侧由安装口倾斜伸出并卡接于限位槽内的卡板,所述卡板可完全容纳于安装口内,所述转动轴上设有分别连接卡板与滑轨的扭簧,所述滑轨靠近安装口的侧壁设有抵接与卡板远离卡接于限位槽内的一侧抵接以限位卡板卡接于限位槽内的定位板。
通过采用上述技术方案,卡板卡接于限位槽,具有限位承托板的位置的效果,从而使承托板不易由柜体内滑出。
优选的,位置对应一所述滑轨的限位槽沿滑轨长度方向设有至少两个。
通过采用上述技术方案,卡板与不同的限位槽卡接配合,具有调节智能音箱模块的位置,从而调节麦克风的位置,以适配更多的需求,同时使承托板不易由柜体滑落。
第二方面,本申请提供一种语音智能床头柜的语音处理方法,采用如下的技术方案:
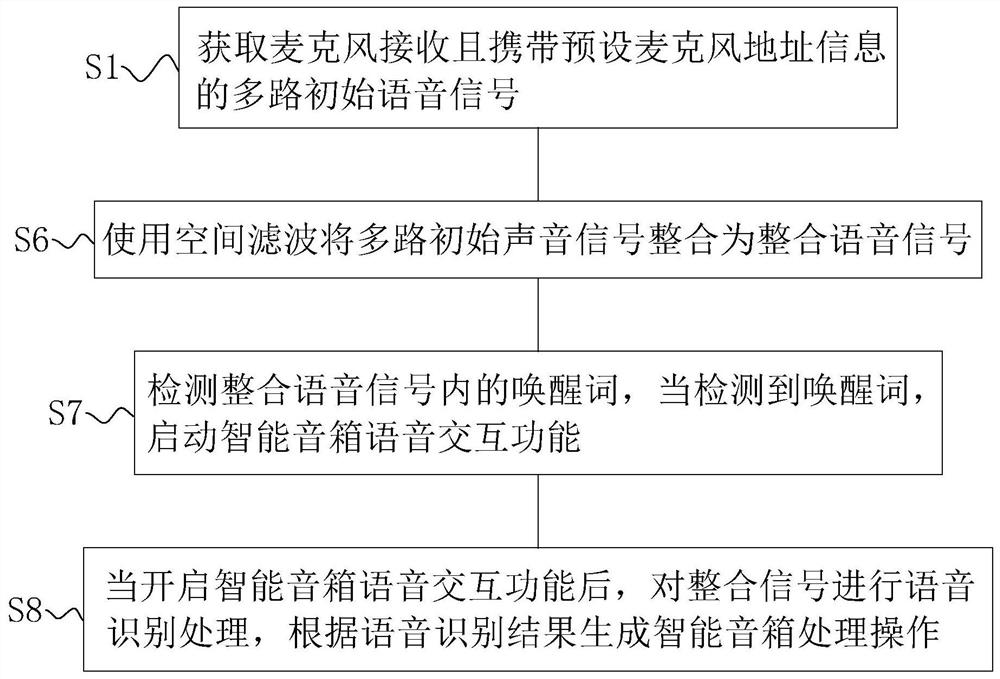
一种语音智能床头柜的语音处理方法,所述方法包括:获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号;使用空间滤波将多路初始声音信号整合为整合语音信号;检测整合语音信号内的唤醒词,当检测到唤醒词,启动智能音箱语音交互功能;当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作。
通过采用上述技术方案,获取麦克风的初始语音信号,将多路麦克风的初始语音信号整合为整合语音信号,并检测整合语音信号内是否有唤醒词,若有,则开启语音交互功能,并对整合信号进行语音识别处理,然后控制智能音箱处理操作,从而具有同时接收多路语音信号,且对多路语音信号进行处理,以提高智能音箱的语音接收效果。
优选的,所述步骤当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作,包括:开启智能音箱语音交互功能后,将整合语音信号转化为控制文本;识别控制文本中控制命令所属的领域集合;识别控制命令所属领域集合内的控制意图;生成控制意图对应的操作参数;根据操作参数执行智能语音处理操作。
通过采用上述技术方案,将整合语音信号转化为控制文本,通过对控制文本内的内容一步步解析,然后一步步判断,最终获取操作参数,具有提高语音识别的准确性以及效率的效果。
优选的,所述步骤获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号后包括:判断初始语音信号的达到时间;以最先达到的初始语音信号对应的麦克风地址信息为声音初始位置;增强声音初始位置对应的麦克风接收的初始语音信息;根据声音初始位置生成交互信号。
通过采用上述技术方案,判断声源的位置,从而便于定位使用人员的位置,增强靠近使用人员的位置的麦克风接收的初始声音信号,使后续声音处理是可获得失真更少的声音信号。
第三方面,本申请提供一种语音智能床头柜的语音控制系统,采用如下的技术方案:
一种语音智能床头柜的语音控制系统,包括:声音获取模块,用于获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号。数据整合模块,用于使用空间滤波将多路初始声音信号整合为整合语音信号;检测控制模块,用于检测整合语音信号内的唤醒词,当检测到唤醒词,启动智能音箱语音交互功能;主控制模块,用于当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作。
通过采用上述技术方案,声音获取模块获取麦克风的初始语音信号,通过数据整合模块采用空间滤波整合多路初始声音信号为整合语音信号,检测模块检测整合语音信号内的唤醒词,根据唤醒词启动智能音箱语音交互功能,主控制模块用于识别整个号信号,且根据识别结果智能音箱处理操作,从而整合多路初始语音信号,以提高智能音箱语音接收效果。
第四方面,本申请提供一种智能装置,采用如下的技术方案:
一种智能装置,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如权利要求1至7中任一种方案的计算机程序。
第五方面,本申请提供一种计算机可读存储介质,采用如下的技术方案:
一种计算机可读存储介质,存储有能够被处理器加载并执行如权利要求1至7中任一种方案的计算机程序。
综上所述,本申请包括以下至少一种有益技术效果:
通过预设于智能音箱模块上的麦克风有声音接收口接收来自各个方向的语音信号,且通过处理将语音信号叠合,从而具有提高语音接收效果的作用;
获取麦克风的初始语音信号,将多路麦克风的初始语音信号整合为整合语音信号,并检测整合语音信号内是否有唤醒词,若有,则开启语音交互功能,并对整合信号进行语音识别处理,然后控制智能音箱处理操作,从而具有同时接收多路语音信号,且对多路语音信号进行处理,以提高智能音箱的语音接收效果;
声音获取模块获取麦克风的初始语音信号,通过数据整合模块采用空间滤波整合多路初始声音信号为整合语音信号,检测模块检测整合语音信号内的唤醒词,根据唤醒词启动智能音箱语音交互功能,主控制模块用于识别整个号信号,且根据识别结果智能音箱处理操作,从而整合多路初始语音信号,以提高智能音箱语音接收效果。
附图说明
图1是本申请其中一实施例一种语音智能床头柜的结构示意图;
图2是本申请其中一实施例一种语音智能床头柜的剖视图;
图3是本申请一实施例一种语音智能床头柜的语音处理方法的流程框图;
图4是本申请另一实施例一种语音智能床头柜的语音处理方法的流程框图。
附图标记说明:1、柜体;11、支撑脚;12、声音接收口;13、防尘网;14、滑轨;141、安装口;15、卡板;16、定位板;2、壳体;21、麦克风;22、显示屏;3、承托板;31、限位槽。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图1-4及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本申请,并不用于限定本申请。
本申请实施例公开一种语音智能床头柜。参照图1,床头柜包括柜体1,柜体1靠近地面的一侧设有支撑脚11,在柜体1内设有容纳腔,容纳腔与柜体1其中一侧面连通,容纳腔内滑动设有智能音箱模块。
智能音箱模块包括有壳体2、设于壳体2内的控制主板、与控制主板连接且分布于壳体2各个侧面的麦克风21,以及与控制主板连接且固定于壳体2一侧的显示屏22,显示屏22位于容纳腔与柜体1连通处,便于使用人员查看显示屏22上的内容,麦克风21用于接收使用人员的控制语音,在本实施例中,麦克风21分别设于壳体2正常摆放时壳体2的上侧以及显示屏22相对的两侧。
智能音箱模块放置于容纳腔后,柜体1上对应麦克风21的位置均开设有声音接收口12,声音接收口12贯穿其设置的柜体1位置的侧壁,柜体1靠近声音接收口12的侧壁呈喇叭形设置,且声音接收口12靠近壳体2一侧的口径小于另一侧,声音接收口12设置多处,从而使麦克风21可更好的接收来自多个方向的信号。
设于柜体1远离支撑脚11的侧面上的声音接收口12上设有防尘网13,防尘网13为布料材质且其上设有若干通孔,防尘网13覆盖其对应的声音接收口12,以减少柜体1上表面的凹凸不平感。
容纳腔靠近支撑脚11的一侧与柜体1侧壁连通,柜体1靠近容纳腔的侧壁位于壳体2的下方设有承托板3,承托板3用于承托柜体1,且承托板3可沿容纳腔漏出显示屏22的一侧滑出柜体1外侧。
柜体1位于承托板3下方设有用于限位承托板3的滑轨14,滑轨14为长条形板状,滑轨14的长度方向沿承托板3的滑动方向设置。
参照图2,在滑轨14靠近显示屏22的一端开设安装口141,安装口141沿垂直滑轨14长度方向的方向贯穿滑轨14。
滑轨14对应安装口141的侧壁转动设有转动轴,转动轴的中轴线水平设置且与滑轨14的长度方向垂直,在转动轴上固定有可在安装口141内绕转动轴转动的卡板15,且卡板15可完全收于安装口141内。
承托板3靠近滑轨14的下端面开设有限位槽31,限位槽31位于滑轨14的正上方,且限位槽31沿滑轨14长度方向的长度长于安装口141沿滑轨14长度方向的长度,在转动轴上设有一端连接滑轨14、另一端连接卡板15的扭簧,当扭簧处于自然状态下时,卡板15的一端卡接于限位槽31内,在滑轨14位于对应安装口141的侧壁位于卡板15另一端的下方设有定位板16,当将承托板3向容纳腔内推动时,承托板3下端面抵压卡板15,使卡板15收于安装口141内,承托板3可滑动,当承托板3滑动至安装口141的位置正对限位槽31的位置时,卡板15在扭簧的弹性恢复力的作用下一端卡进限位槽31内、另一端向下抵压定位板16,定位板16限位卡板15的转动方向,当需要将承托板3移出时,只需按压卡板15靠近定位板16的一侧,使卡板15位于限位槽31内的一端向远离限位槽31的方向转动,以收入安装口141内,从而使承托板3可抽出柜体1外侧。
在承托板3对应一侧滑轨14的侧面沿滑轨14的长度方向设有至少两个限位槽31,在本实施例中,设置为两个,但也可以为三个、四个、五个等,限位槽31位于承托板3靠近滑轨14长度方向的两端的位置,当需要检修智能音箱模块时,将承托板3拉出,使卡板15卡接于远离显示屏22一侧的限位槽31,即可对智能音箱进行检修且使承托板3不易由柜体1滑出。
本实施例一种语音智能床头柜的实施原理为:柜体1上开设有若干声音接收口12,声音接收口12对应麦克风21,麦克风21可更好的接收声音信号,使人们处于柜体1的各个方向时,智能音箱模块均可具有良好的语音接收、处理效果。将智能音箱模块放置于容纳腔内,使承托板3沿滑轨14滑动至承托板3靠近显示屏22的限位槽31位置对应安装口141位置,卡块在扭簧的作用力下绕转动轴转动,且一端卡接于限位槽31,卡板15的另一端抵压于定位板16,使当承托板3有向外侧滑动的趋势时,卡板15与定位板16配合限位承托板3,使承托板3不易由柜体1内滑出。
本实施例还公开一种语音智能床头柜的语音处理方法,配合使用于上述语音智能床头柜,参照图3,方法包括:
S1:获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号。
具体的,智能音箱上设有若干麦克风,麦克风接收使用人员发出的语音信号,不同的麦克风对应有不同的预设麦克风地址信息,设于智能音箱上的控制主板通过总线接收麦克风传输的多路初始语音信号。
S6:使用空间滤波将多路初始声音信号整合为整合语音信号。
具体的,根据使用人员的位置定位生成空间滤波的参数,将多路初始语音信号利用空间滤波的方法整合,具有增强初始声音信号、抑制旁路信号的效果。
S7:检测整合语音信号内的唤醒词,当检测到唤醒词,启动智能音箱语音交互功能。
具体的,在控制主板上设有小型的语音识别引擎,用于检测整合信号内的唤醒词,对整合信号进行静音检测、降噪等处理后,采用语音识别引擎检测整合语音信号中的唤醒词,具体的,唤醒词为预设的语句,比如,唤醒词可以为:启动智能音箱,当语音识别引擎检测到整合语音信号内有:启动智能音箱,将信号传输至控制主板,控制主板控制开启智能音箱语音交互功能。
S8:当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作。
具体的,转换整合信号为控制文本,提取控制文本内的操作信号,根据操作信号控制智能音箱处理操作。
进一步的,在另一实施例中,参照图4,步骤S1与步骤S6之间还包括步骤S2、S3、S4、S5。
S2:判断初始语音信号的达到时间。
具体的,控制主板上设置有WiFi联网模块,联网实时更新麦克风接收到初始语音信号的时间,且对多路初始语音信号进行波形采样以及特征提取,根据多路初始语音的采样结果以及特征提取结果进行比对,筛选过滤采样结果与特征提取结果与其他组初始语音信号相差较大的初始语音信号,将筛选后的初始语音信号的达到时间由时间最早到时间最晚的初始语音信号进行排序。
S3:以最先达到的初始语音信号对应的麦克风地址信息为声音初始位置。
具体的,获取排序中达到时间最早的初始语音信号对应的麦克风地址信息为声音初始位置,使用人员说话时,语音会被墙壁多次反射,麦克风最先接收到的初始语音信息为反射次数最少的,因而该初始语音信息的损失也就越小,则该路初始语音信号的信号越强。
S4:增强声音初始位置对应的麦克风的初始语音信息。
具体的,增强声音初始位置对应的麦克风接收的初始语音信息具体可以为采用功率放大器放大该路初始语音信息。
S5:根据声音初始位置生成交互信号。
具体的,交互信号可以表征为预设于智能音箱周测对应麦克风位置的指示灯开启或闪烁,当使用人员说话时,麦克风接收多路初始语音信号,根据初始语音信号到达的时间判断使用人员站立的方向,控制主板控制对应麦克风的指示灯闪烁,加强使用人员与智能音箱的交互感,以初始语音信号的接收时间来定位使用人员的位置,便于精准定位,且使定位更为准确。
进一步的,在另一实施例中,步骤S8包括以下子步骤:
(1)开启智能音箱语音交互功能后,将整合语音信号转化为控制文本。
具体的,在控制开启智能音箱语音交互功能后,对整合语音信号进行语音文字转换处理,将整合语音信号转化为控制文本。
(2)识别控制文本中控制命令所属的领域集合。
具体的,预先设置领域集合,领域集合内包含智能音箱可执行的动作,比如播放音乐、天气预报,只需提取关键字识别即可,比如说,控制文本内的信息为:播放歌手演唱的歌曲,在进行领域集合判断时,只需识别到语句内包含播放,即可判定为此条控制语句属于预设的播放领域集合内。
进一步的,S8的子步骤(2)包括以下子步骤:
21)获取控制文本,由控制文本序列内的首个文字开始识别,按首字符检索的预设的第一检索表,第一检索表内存储有领域集合命名的首字。
22)当按顺序检索到控制文本中存在预设第一检索表内的首字相同的领域集合名称后,跳转至该首字对应的领域集合的第二字的预设第二检索表,而后检索控制文本内位于该首字后的文字是否位于第二检索表内。
23)若不在,将该首字判断为空信息,并对该首字后的第二字进行第一检索表检索;若该第二字位于第二检索表内,且首字与第二字组合形成某一领域集合的名称,则检索控制文本位于该第二字后的第三字是否在预设第三检索表内,若不在,则判断该首字与第二字对应的领域集合为控制文本信息所属的领域集合;若在,则检索控制文本位于该第三字后的第四字是否位于预设的第四检索表内。
24)按照控制文本内的文字进行逐字比对,直至比对至控制文本中的尾字,若无比对结果,判断此控制文本为空信息。
上述的第一检索表、第二检索表、第三检索表、第四检索表不代表本申请限定领域集合的名称为四个字,且对本实施例中,第一检索表、第二检索表、第三检索表、第四检索表的操作按照判断条件均可设置于对第一检索表、第二检索表、第三检索表、第四检索表的与控制文本的比对中。
(3)识别控制命令所属领域集合内的控制意图。
获取到控制文本所属的领域后,获取控制文本内属于控制意图集合内的关键字,比如在控制文本:播放歌手演唱的歌曲,提取的属于控制意图集合的关键字,比如演唱、歌曲,从而判断控制意图所属的操作为播放歌曲。
(4)生成控制意图对应的操作参数。
(5)根据操作参数执行智能语音处理操作。
获取控制文本中的控制意图后,提取控制文本内的操作参数,比如说歌手,根据领域获知此控制文本需要执行播放领域集合内,调用声音播放模块,比如说扬声器,此控制文本所属控制意图为播放歌曲,然后获取控制文本内与播放歌曲相关的操作参数,比如说演唱者名称,即可通过WiFi联网模块连接网络搜索歌手的歌曲且由扬声器播放,通过逐步解析控制文本内的内容,较于直接识别控制文本内的控制指令具有较高的准确性,且提取命令并作出响应的时间更短。
本申请实施例还公开一种语音智能床头柜的语音控制系统,适用于上述一种语音智能床头柜的语音处理方法,语音控制系统包括以下模块:
声音获取模块,用于获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号。
判断模块,用于判断初始语音信号的达到时间。
结果提取模块,用于以最先达到的初始语音信号对应的麦克风地址信息为声音初始位置。
声音增强模块,用于增强声音初始位置对应的麦克风接收的初始语音信息。
交互控制模块,用于根据声音初始位置生成交互信号。
数据整合模块,用于使用空间滤波将多路初始声音信号整合为整合语音信号。
检测控制模块,用于检测整合语音信号内的唤醒词,当检测到唤醒词,启动智能音箱语音交互功能。
主控制模块,用于当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作。
进一步的,主控制模块包括:
文本转换单元,用于在开启智能音箱语音交互功能后,将整合语音信号转化为控制文本。
领域集合判断单元,用于识别控制文本中控制命令所属的领域集合。
控制意图判断单元,用于识别控制命令所属领域集合内的控制意图。
操作参数生成单元,用于生成控制意图对应的操作参数。
以及,执行单元,用于根据操作参数执行智能语音处理操作。
本实施例还公开一种智能装置,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如下步骤的计算机程序。
S1:获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号。
S2:判断初始语音信号的达到时间。
S3:以最先达到的初始语音信号对应的麦克风地址信息为声音初始位置。
S4:增强声音初始位置对应的麦克风的初始语音信息。
S5:根据声音初始位置生成交互信号。
S6:使用空间滤波将多路初始声音信号整合为整合语音信号。
S7:检测整合语音信号内的唤醒词,当检测到唤醒词,启动智能音箱语音交互功能。
S8:当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作。
步骤S8包括以下子步骤:
(1)开启智能音箱语音交互功能后,将整合语音信号转化为控制文本。
具体的,在控制开启智能音箱语音交互功能后,对整合语音信号进行语音文字转换处理,将整合语音信号转化为控制文本。
(2)识别控制文本中控制命令所属的领域集合。
(3)识别控制命令所属领域集合内的控制意图。
(4)生成控制意图对应的操作参数。
(5)根据操作参数执行智能语音处理操作。
本实施例还公开一种计算机可读存储介质,存储有能够被处理器加载并执行如以下步骤的计算机程序。
S1:获取麦克风接收且携带预设麦克风地址信息的多路初始语音信号。
S2:判断初始语音信号的达到时间。
S3:以最先达到的初始语音信号对应的麦克风地址信息为声音初始位置。
S4:增强声音初始位置对应的麦克风的初始语音信息。
S5:根据声音初始位置生成交互信号。
S6:使用空间滤波将多路初始声音信号整合为整合语音信号。
S7:检测整合语音信号内的唤醒词,当检测到唤醒词,启动智能音箱语音交互功能。
S8:当开启智能音箱语音交互功能后,对整合信号进行语音识别处理,根据语音识别结果生成智能音箱处理操作。
步骤S8包括以下子步骤:
(1)开启智能音箱语音交互功能后,将整合语音信号转化为控制文本。
具体的,在控制开启智能音箱语音交互功能后,对整合语音信号进行语音文字转换处理,将整合语音信号转化为控制文本。
(2)识别控制文本中控制命令所属的领域集合。
(3)识别控制命令所属领域集合内的控制意图。
(4)生成控制意图对应的操作参数。
(5)根据操作参数执行智能语音处理操作。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink) DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。
- 一种语音智能床头柜及其语音处理方法、语音控制系统
- 语音处理方法、路由器及智能语音控制系统