一种基于集成学习的未知网络攻击行为漂移检测方法
文献发布时间:2024-04-18 19:44:28
技术领域
本发明涉及一种基于集成学习的未知网络攻击行为漂移检测方法,属于网络安全技术领域。
背景技术
随着互联网的发展,网络中的攻击行为也在不断发生,不仅会带来巨大的经济损失,甚至对国家的安全和社会的稳定发展造成威胁。研究发现,网络中超过40%的流量采用未知协议,该类协议通常不公开具体的规范和标准。考虑到通信的效率和安全性,未知协议被广泛运用到私密性较高的商业或者军队等领域。然而,也有一些不法分子利用未知协议发起网络攻击,不仅给网络管理带来了挑战,也使网络安全存在一定的隐患。为了维护网络空间安全,识别未知的攻击,从中提取特征,分析出此类攻击的规则,是非常值得研究且有意义的事情。
传统的检测模型通常是在一个静态的环境中,离线训练后再离线检测,然而,现实环境中的数据一般具有动态性,比如出现新的类、集群或特性,当数据的统计特性变化时,就会发生概念漂移现象。网络环境存在差异和变化,网络攻击者的行为使得网络流量经常发生概念漂移,传统的流量检测方法很难适应变化的数据流,因此需要新的方法来检测和处理概念漂移。
漂移检测是通过识别变化点或变化时间间隔来描述和量化概念漂移的技术和机制。常见的漂移检测方法基于错误率来量化概念漂移,如DDM算法以及其扩展算法EDDM和HDDM等。但是,网络攻击产生的概念漂移使得静态机器学习模型不能很好地适应流量特性变化,不利于未知攻击流量的检测,因此需要构建能处理概念漂移的异常流量检测模型。
发明内容
本发明目的在于针对上述现有技术的缺陷和不足,提出了一种基于集成学习的未知网络攻击行为漂移检测方法,该方法通过某种集成策略组合基分类器,从而达到比单一模型效果更佳的目标,本发明复合结构可以很容易地适应数据流中的变化,设计的在线集成模型用于适应网络流量的概念漂移,让分类器忘记旧实例,适应新实例,以便自然地跟踪网络流量中的漂移,其中在线学习的步骤和集成学习的组合策略都是构造模型的重要环节。
本发明解决其技术问题所采用的技术方案是:一种基于集成学习的未知网络攻击行为漂移检测方法,该方法包括以下步骤:
步骤1:数据采集和预处理。
首先从网络中捕获数据流量,在捕获数据流量之后,从中对数据进行筛选,去除掉一些公开的、商业的服务器流量,保留那些未知分类的网络流量。
定义数据矩阵X,其中每一行代表一个网络流,每一列代表一种属性(例如源IP地址、目标IP地址等)。假设我们有n个样本和m个属性,数据矩阵可以表示为:
X=[x
本发明五种类型网络流量属性定义如下:
1.源IP地址(Source IP Address),我们表示为A
2.目标IP地址(Destination IP Address),我们表示为A
3.端口号(Port Number),我们表示为A
4.协议类型(Protocol Type),我们表示为A
5.域名(Domain Name),我们表示为A
那么从X中抽取的每个网络流中提取的特征表示为一个五元组(A
F:X→A
对于网络流量矩阵X中的每一个网络流量样本x
通过这样的过程,我们将网络流量矩阵X转换为特征矩阵V,V的每一个元素都是一个五元特征向量,即V={v
设字符串匹配函数为M,此函数用于在网络流特征矩阵V中识别和筛选公开和商业服务器流量。此函数可以定义为:
M(V)→{0,1}
n表示网络流量样本的总数量。
对于特征矩阵V中的每个特征向量v
接下来,我们构造一个新的特征矩阵V',只包含被标记为未知流量的特征向量。我们可以定义V'如下:V′={v
V'包含了所有满足M(v
步骤2:基分类器训练和更新。
使用Hoeffding树作为基分类器,将数据以流的方式逐个输入以训练在线学习模型。训练在线学习的模型,在训练时将数据以流的方式逐一输入模型中,确保每次模型中只有一个训练样本数据。对于我们的数据流量特征矩阵V',我们可以定义一个在线学习函数L。函数可以描述为:L(V′,θ)→θ′(θ是在线学习模型的参数。θ'是更新后的参数)
同样将测试样本逐次输入训练好的模型中,预测单个样本的类别或者类别概率。设定一个测试样本为v
P(v
我们使用信息增益IG(D,A)来评估每个特性A对于数据集D的分类效果,其可以通过以下公式计算:
预测样本被模型学习从而更新模型,每次单个样本预测之后,用真实的类别值和预测的类别值来更新模型的评估指标。定义更新函数U,可以描述为:
U(θ′,y
这里y'
单个样本预测完成且模型更新之后,再进行下一个样本的预测。这是在线学习过程中的迭代步骤,该过程将持续进行,直到所有样本都已经过预测和学习过程。
步骤3:基分类器集成和攻击行为检测。
利用自适应随机森林(Adaptive Random Forest,ARF)将随机森林树算法扩展为一种处理概念漂移的方法,根据上述步骤2各基分类器的结果,自适应动态分配合理的权重,从而进行加权投票,得到最终的检测结果。
初始化样本权重,使其均等分布。假设我们有n个样本,并且我们设定权重w
W
也就是说,每个样本最初都有相同的权重。
重复以下操作直到达到预设的迭代次数或满足停止条件,在当前样本权重下,构建一个随机森林;对于每个决策树,计算样本的分类误差率,并根据误差率调整样本的权重;更新样本权重。假设我们有一个误差率计算函数E,它可以定义为:
E(y
其中,y
定义一个权重调整函数A,它可以定义为:
A(w
其中,w
最后,将所有决策树的预测结果进行综合,得到最终的预测结果。我们假设有一个结果集成函数C,它可以定义为:
C(y
其中,y
进一步的,本发明上述步骤1包括:
步骤1-1:使用Wireshark、Tcpdump或网络端口镜像等方式,从网络中捕获网络流量。
步骤1-2:从网络流量中抽取如源IP地址、目标IP地址、端口号、协议类型、域名等信息,形成网络流的属性集合。
步骤1-3:利用字符串匹配算法,匹配筛选出公开、商用的服务器流量,保留那些未知分类的网络流量。
进一步的,本发明上述步骤2包括:
步骤2-1:训练在线学习的模型,在训练时将数据以流的方式逐一输入模型中,确保每次模型中只有一个训练样本数据。
步骤2-2:同样将测试样本逐次输入训练好的模型中,预测单个样本的类别或者类别概率。
步骤2-3:预测样本被模型学习从而更新模型,每次单个样本预测之后,用真实的类别值和预测的类别值来更新模型的评估指标。
步骤2-4:单个样本预测完成且模型更新之后,再进行下一个样本的预测。
进一步的,本发明上述步骤3包括:
步骤3-1:初始化样本权重,使其均等分布。
步骤3-2:重复以下操作直到达到预设的迭代次数或满足停止条件,在当前样本权重下,构建一个随机森林;对于每个决策树,计算样本的分类误差率,并根据误差率调整样本的权重;更新样本权重。
步骤3-3:将所有决策树的预测结果进行综合,得到最终的预测结果。
有益效果:
1、本发明能够很好地提高未知网络攻击流量检测的准确率。
2、本发明能够很好地适应概念漂移,保证了未知网络攻击流量检测效果的稳定性。
附图说明
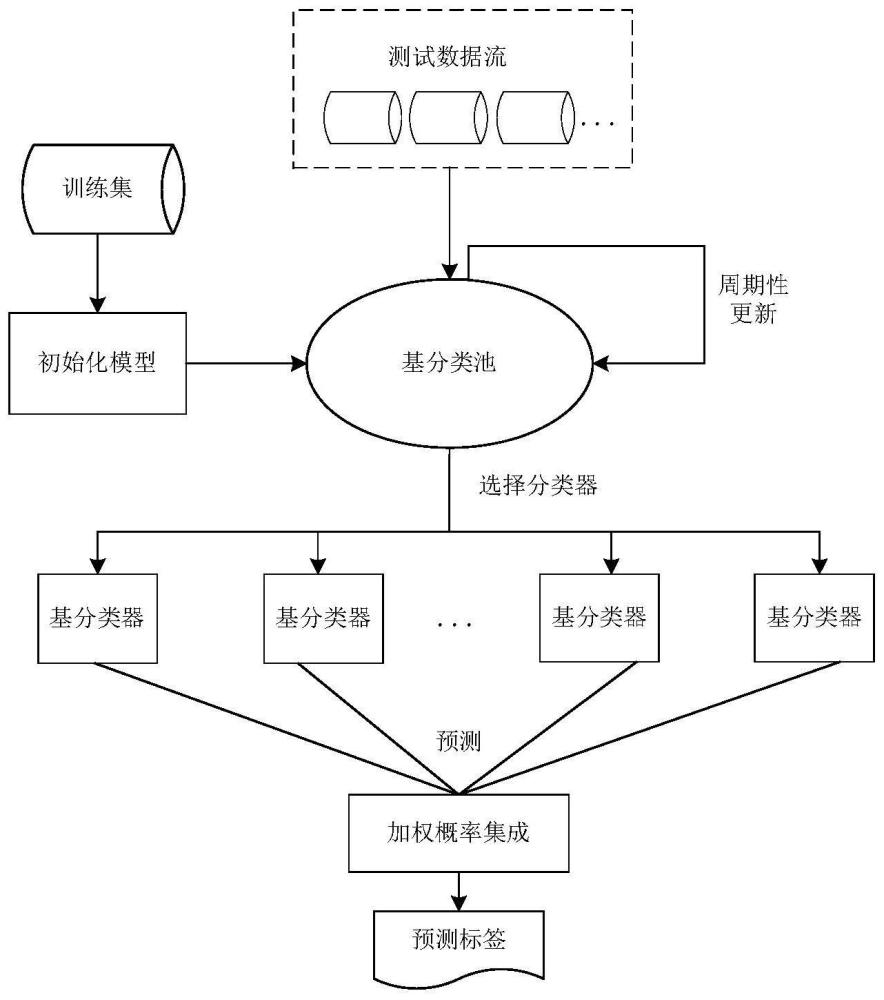
图1为本发明的检测方法结构示意图。
图2为本发明的基分类器训练和更新的方法流程图。
图3为动态权重投票的方法流程图。
具体实施方式
下面结合说明书附图对本发明创造作进一步的详细说明。
本实施例中提供一种基于集成学习的未知网络攻击行为漂移检测方法,关联方法总体结构如图1所示,首先从网络中采集网络流量数据,并对其进行预处理;然后使用Hoeffding树作为基分类器,将数据以流的方式逐个输入以训练在线学习模型,并不断对模型进行更新;最后利用自适应随机森林算法处理概念漂移,自适应分配权重进行投票,以实现未知网络攻击流量的检测。具体的实施步骤如下:
步骤(1)数据采集和预处理。
步骤1-1:本发明可以利用多种方式获取网络流量,一种方式是在Windows系统各种,进行可视化界面的数据流量获取,可以安装使用Wireshark软件,打开软件后点击菜单栏中的“捕获”,然后选择所需捕获的网卡,接着点击开始,则可以进行网络流量的获取,在获取完成后,点击停止并进行保存。另一种是利用Linux系统进行流量获取,则可以使用Tcpdump命令,具体命令为:tcpdump-i网卡号-w文件名。如果有更详细的参数要求,如ip地址,端口号等,可以参考tcpdump命令参数进行设置。当捕获的网络流量不止是一台机器,需要在路由器,交换机端口进行捕获时,可以通过配置将多个端口的网络流量镜像到一个端口上,然后再对该端口的网络流量进行抓取,以思科交换机为例,可使用monitor命令设置源端口和镜像端口。
步骤1-2:针对上一步所捕获的网络流量,需要对其进行属性抽取,主要包括源IP地址、目标IP地址、端口号、协议类型、域名等属性信息。一般的网络流量文件包括pcap文件头,数据包头,数据包三类信息,其中,pcap文件头包含了总文件大小等信息,数据包头包含数据包时间戳信息,数据包包含了ip地址、端口号、协议类型、域名等信息。通过对tcp层、应用层的信息进行抽取,可以获得上述属性。
步骤1-3:在抽取了上述属性之后,需要根据这些属性对网络流量进行初步的筛选。需要提前收集常用的公开、商用的服务器IP地址或URL等信息,利用字符串匹配,筛选过滤掉属于该类的网络流量,保留那些难以分类的网络流量。
步骤(2)基分类器训练和更新。
步骤2-1:构造基分类器形成在线学习的模型,在训练时将数据以流的方式逐一输入模型中,确保每次模型中只有一个训练样本数据。本发明集成学习可增强单一模型的鲁棒性,将多个模型组合成一个更好的模型,因此集成学习分类器的性能与基分类器息息相关,基分类器的选择尤为重要。本模型选择Hoeffding树(HT)作为基分类器,可以随时从大量数据流中学习,并且在连续学习的状态下保持学习的精确性,这种流数据算法比批量学习算法更有效地对网络数据进行分类。Hoeffding树是基于决策树的算法,数据存储在主内存中,初始化树结构,仅有一个根节点,创建决策树学习器,将每一个训练数据过滤到一个合适的叶子节点。
步骤2-2:将测试样本逐次输入训练好的模型中,预测单个样本的类别或者类别概率。决策树构造一般采用自顶向下的方法,在每个阶段选择一个属性对给定的数据集进行分割,根据不同的规则在每个分叉口选择最佳属性进行分割,并且这个过程将在每个结果子集上不断递归、重复,直到下一次分割不再增加新的属性。
步骤2-3:预测样本被模型学习从而更新模型,每次单个样本预测之后,用真实的类别值和预测的类别值来更新模型的评估指标。每个叶节点都有足够的数据来决定下一步操作,叶子节点上的数据评估了任意属性拆分时的信息增益。根据信息增益G在节点上找到最好的属性。首先抽样数据的信息增益为G(A),根据Hoeffding边界,G最小值应该为,这样就确定了信息增益为G的属性。在大量测试之后,若是该属性提供的结果比任何其他节点都好,那它就是树的增长分割节点。
步骤2-4:在单个样本预测完成且模型更新之后,再进行下一个样本的预测。
步骤(3)基分类器集成和攻击行为检测。
步骤3-1:选好基分类器后,组合基分类器的策略也是集成学习性能好坏的关键,在流数据领域的集成学习中,Bagging、Boosting和随机森林都是用于提高单一分类器性能的经典集成方法,每个实例只使用一次来模拟批处理模式装袋。另外自适应随机森林(ARF)将随机森林树算法扩展为一种处理概念漂移的方法。初始化样本权重,使其均等分布。
步骤3-2:投票是指多个基分类器分别预测,之后根据各模型不同的规则进行投票,例如多数投票和加权投票,本模型使用加权投票方式,加权概率投票法(WeightedProbability Voting)是一种多数表决的方法,其中每个选项的投票权重与其概率相关联。这种方法常用于集成多个分类器或模型的预测结果,以获得更准确的整体预测。在加权投票中权重的分配通常根据当前基分类器的性能决定,再根据模型的投票规则得到最终的预测结果。重复以下操作直到达到预设的迭代次数或满足停止条件,在当前样本权重下,构建一个随机森林;对于每个决策树,计算样本的分类误差率,并根据误差率更新样本权重。假设有N个选项(通常是不同的分类器或模型)和一个待预测的事件。每个选项都会对该事件进行预测,并给出一个概率值表示其预测的可信度或置信度。这些概率值可以是介于0和1之间的任意实数。为了进行投票,首先为每个选项分配一个权重。这些权重可以根据选项的性能、准确度或其他指标进行分配。通常情况下,性能更好的选项会被赋予更高的权重。
步骤3-3:将所有决策树的预测结果进行综合,得到最终的预测结果。具体对于每个选项的预测,将其概率值乘以相应的权重,得到加权后的概率。最后,将所有选项的加权概率相加,得到一个加权概率总和。最终的预测结果是具有最高加权概率的选项。换句话说,选择具有最高加权概率的选项作为最终预测结果。如果有多个选项具有相同的最高加权概率,可以进行进一步的处理,如随机选择或根据其他规则进行决策。这种综合方法能够利用决策树的集体智慧,提高预测的准确性和可靠性。
以上所述技术流程,仅是本发明的较佳实施方式,但并不能代表本发明的所有细节。任何熟悉本技术领域的专业人员在本发明揭露的技术范围内,在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种基于模糊度和集成学习的网络入侵检测方法
- 一种基于上游探针感知未知网络攻击行为的装置
- 一种基于上游探针感知未知网络攻击行为的装置