一种适应阴影情况的光伏电站直流侧故障实时监测方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及一种光伏阵列故障诊断的技术,具体是一种适应阴影情况的光伏电站直流侧故障实时监测方法。
背景技术
光伏能源是一种重要的可再生能源形式,已广泛应用于电力生产等领域。光伏阵列由多个太阳能电池组成,用于将太阳辐射能转化为电能。然而,由于环境条件、污染、阴影等因素的存在,光伏阵列可能会发生各种类型的故障,如开路、短路、部分遮挡(PartialShading,PS)等。
传统的光伏阵列故障诊断方法通常基于监督学习技术,使用已知场景下的标签数据来训练故障诊断模型。然而,实际运行过程中的PS情况复杂多变,随机性强,难以获取所有PS模式的样本进行模型训练。因此,传统方法建立的模型难以识别来自未知阴影情况的样本,从而显著降低了故障诊断模型的分类准确性。为解决上述问题,本发明提出了一种适应未知阴影的光伏阵列故障诊断方法,采用半监督学习技术,引入运行过程中实际采集的无标签数据进行模型更新,从而使得该模型可以解决未知阴影场景出现导致的类不匹配问题。
发明内容
本发明的目的在于提供一种适应阴影情况的光伏电站直流侧故障实时监测方法。本发明使用逻辑回归算法建立故障诊断的教师模型。然后,基于教师模型预测的概率分数,设计Y模型分别筛选和标记来自已知场景和未知阴影情况的无标签数据,与标签数据一起迭代更新模型,从而使得该模型可以显著提升未知阴影存在时光伏阵列故障分类的准确率。
为实现上述目的,本发明提供如下技术方案:
采集光伏阵列的标签数据,其中所述标签数据包括光伏阵列的特征向量和相应的样本标签,其中样本标签包括正常状态、LL故障、OC故障和PS情况。
采集光伏阵列的无标签数据,其中所述无标签数据的特征向量在光伏系统运行期间采集。
将所述标签数据和无标签数据组合为训练数据集。
使用逻辑回归算法建立故障诊断的教师模型,其中所述教师模型用于获取将训练数据集的特征向量映射到各个类别的概率分数。具体过程为:令
其中:
l
式(1)可以解释为一个随机优化问题,假定特征向量x和标签y遵循样本空间
进而建立基于逻辑回归算法进行故障诊断的教师模型。
将无标签数据划分为多个集合。
基于所述教师模型的预测结果,设计一个Y模型用于筛选和标记来自已知场景和未知阴影情况的无标签数据,其中所述Y模型包括一个主干和两个分支,其中主干使用标签数据训练的四个基于LR的二分类模型作为教师模型,为无标签数据提供概率分数。具体规则为:1)对于来自已知场景样本的无标签样本的筛选规则为:选择样本预测概率属于特定类别的概率分数大于γ,且属于其他类的概率分数小于ε的无标签样本;2)对于来自未知阴影情况的无标签样本的筛选规则为:将样本属于正常、LL故障、OC故障和PS情况的概率分数都很小的无标签样本标记为PS类。
根据所述Y模型的筛选和标记结果,将被选中的伪标签数据视为下一次训练学生模型的标签数据。
使用所述伪标签数据训练同样基于LR方法的学生模型,其中所述学生模型用于光伏阵列故障诊断;
重复无标签数据筛选和模型训练的步骤,直至所有无标签数据都被筛选过。该学生模型即为最终的分类模型,用于光伏阵列故障诊断。
与现有技术相比,本发明的有益效果是:本发明在存在未知阴影模式的情况下,可以有效地利用无标签样本来提升模型的分类准确率,克服了未知阴影模式对诊断性能的影响,从而增强了光伏阵列故障诊断的鲁棒性和可靠性。
附图说明
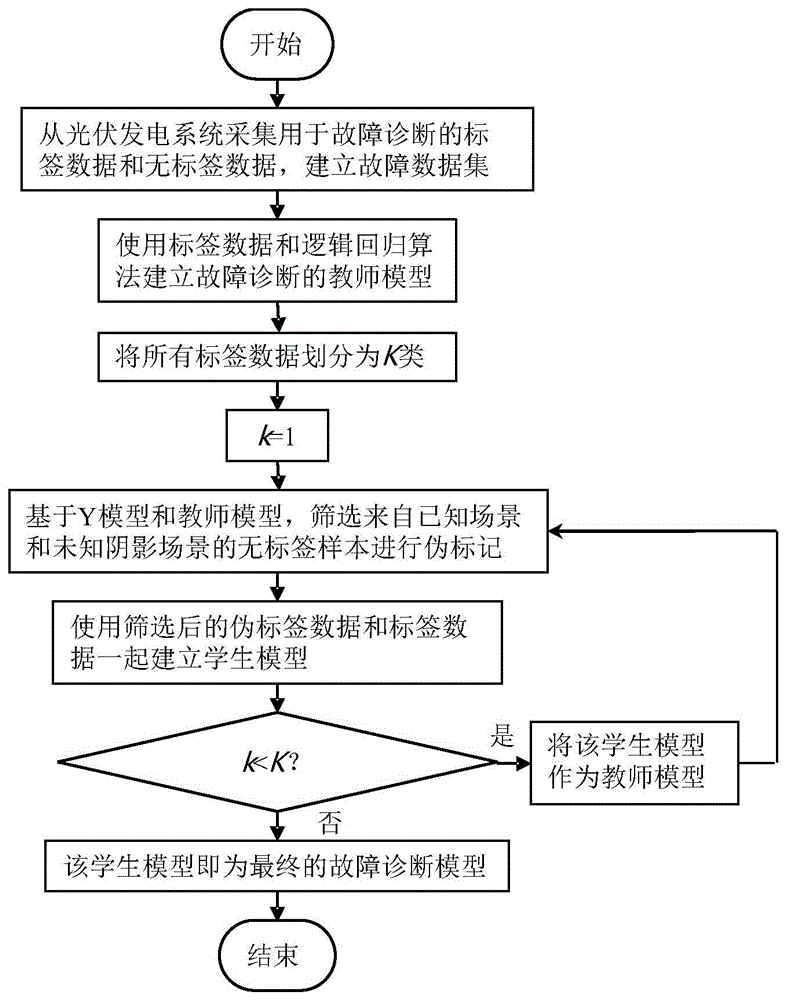
图1为本发明方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种适应阴影情况的光伏电站直流侧故障实时监测方法,包括如下步骤:
采集光伏阵列的标签数据,其中所述标签数据包括光伏阵列的特征向量和相应的样本标签,其中样本标签包括正常状态、LL故障、OC故障和PS情况。
采集光伏阵列的无标签数据,其中所述无标签数据的特征向量在光伏系统运行期间采集。
将所述标签数据和无标签数据组合为训练数据集。
使用逻辑回归算法建立故障诊断的教师模型,其中所述教师模型用于获取将训练数据集的特征向量映射到各个类别的概率分数。具体过程为:令
其中:
l
式(1)可以解释为一个随机优化问题,假定特征向量x和标签y遵循样本空间
进而建立基于逻辑回归算法进行故障诊断的教师模型。
将无标签数据划分为多个集合。
基于所述教师模型的预测结果,设计一个Y模型用于筛选和标记来自已知场景和未知阴影情况的无标签数据,其中所述Y模型包括一个主干和两个分支,其中主干使用标签数据训练的四个基于LR的二分类模型作为教师模型,为无标签数据提供概率分数。具体规则为:1)对于来自已知场景样本的无标签样本的筛选规则为:选择样本预测概率属于特定类别的概率分数大于γ,且属于其他类的概率分数小于ε的无标签样本;2)对于来自未知阴影情况的无标签样本的筛选规则为:将样本属于正常、LL故障、OC故障和PS情况的概率分数都很小的无标签样本标记为PS类。
根据所述Y模型的筛选和标记结果,将被选中的伪标签数据视为下一次训练学生模型的标签数据。
使用所述伪标签数据训练同样基于LR方法的学生模型,其中所述学生模型用于光伏阵列故障诊断;
重复无标签数据筛选和模型训练的步骤,直至所有无标签数据都被筛选过。该学生模型即为最终的分类模型,用于光伏阵列故障诊断。
下面用一个具体的实施例来说明本发明方法的实施过程。
首先,在中国上海市某高校楼顶搭建了光伏阵列的实际系统,该光伏阵列包括3个并联的光伏组串,每个组串包含4个串联的光伏组件。实验光伏阵列由12个Singfo SFM-80W型号的单晶硅太阳能电池板组成,总功率峰值为960W。使用I-V曲线数据采集器离线测量光伏阵列的I-V曲线,并记录Imp、Vmp和Pmax数据。辐照度和环境温度由气象分析仪进行测量。设置了不同的四类光伏阵列状态,包括正常状态、LL故障、OC故障和不同PS情况,采用不同厚度的薄膜遮挡光伏组件,实验中通过气象分析仪测量未遮挡部分和薄膜下的辐照度,以制造轻微和严重阴影。标签数据集包括正常状态、LL故障、OC故障、PS的标签样本各20个。无标签数据集包括正常状态、LL故障、OC故障、PS的无标签样本各2500个。学习过程中,将无标签数据划分为25组,即k=100,K=2500。测试数据集包含正常状态、LL故障、OC故障、五种不同的PS情况(其中一种与标签数据的PS情况相同)的样本各200个。选择已知情况样本的阈值设置为γ=0.99,ε=0.1。选择未知阴影情况样本的阈值第一轮学习中设置为0.49,在第二轮学习中设置为0.39,在第三轮学习中设置为0.19,在第四轮及以后的学习中设置为0.09。仿真是在PC上基于MATLAB R2020a进行的。
故障分类准确率如下表所示。可以看到,,学习无标签数据前,由于测试数据集中出现了未知的阴影模式,导致学习无标签数据前的模型在测试数据集上的故障诊断准确率仅为57.6%。在学习无标签数据后,在测试数据集上的故障诊断准确率提升了39.7%,达到97.3%。以上结果说明所提方法在出现未知阴影的情况下,可以有效利用无标签样本提升模型的分类准确率,不受未知阴影模式的影响。
表所提方法的准确率
综上所述,本发明在存在未知阴影模式的情况下,可以有效地利用无标签样本来提升模型的分类准确率,克服了未知阴影模式对诊断性能的影响,从而增强了光伏阵列故障诊断的鲁棒性和可靠性。证明了本发明方法在故障诊断领域具有较高的性能表现。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 光伏电站光伏区直流侧故障数据采集监测系统
- 光伏电站直流侧电缆故障检测系统及设备