基于联合学习的多回合对话回应选择方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及自然语言领域,具体涉及一种基于联合学习的多回合对话回应选择方法。
背景技术
随着深度学习的发展,人机交互技术给人们带来越来越多的便利。因此,人机多回合对话成为自然语言处理的热门领域,受到了学术界和工业界的广泛关注。人机多回合对话分为检索式和生成式。检索式又称回应选择旨在针对对话上文从备选回应中选择最相关的回应;生成式又称回应生成,主要针对对话上文内容通过自然语言生成技术生成与对话上文相关的回应。本发明主要研究回应选择任务。
最初的研究主要集中在短文本的单回合对话上。随着技术的不断发展,研究逐渐步入长文本的多回合对话中。早期的多回合对话回应选择主要借鉴短文本对话回应选择的方法,从最开始的基于匹配和编码的方法,这些方法主要通过将对话上文拼接成一个对话长文的办法,使用短文本对话回应选择技术解决多回合对话回应选择任务,Lowe使用RNN编码对话上文和备选回应的方法,此类方法又被称为平行编码方法。不久,Kadlec研究了不同种类编码器在平行编码网络上的性能。Yan采用了另一种做法,他们使用一个CNN计算对话上文和备选回应的匹配分数。由于对话文本的长度过长,编码器的信息捕捉能力有限,此类方法逐渐出现在长文本上效果较差的问题。为了解决文本过长的问题,研究人员提出层次匹配的方法,将对话上文的每一回合对话与备选回应进行匹配,之后将每一回合匹配的信息进行整合。Wu提出顺序匹配网络(Sequential Matching Network,SMN),将备选回应分别与对话上文中的每一次对话匹配,Zhan提出深度话语汇聚网络(deep utteranceaggregation network,DUA),该网络细化处理对话,同时使用自注意力机制来寻找每sss次对话中的重要信息。在实际中,对话之间存在多种语言现象,相邻对话之间关系十分密切,现有的层次匹配虽然捕捉到了每一回合对话与备选回应之间的联系但是忽视了对话上文的整体语义信息。同时现有的研究大多采取单个数据集训练的方法,事实上,不同语言的对话结构上存在相似性语言上存在互补性。具体体现在(a)不同语言对话中均存在省略和指代等语言现象。(b)相邻对话之间的关系最为密切,主要体现在对话中的省略和指代大多是最近一轮对话中的内容。对此本发明对多回合对话回应选择任务具有很重要的研究价值。
传统技术存在以下技术问题:
不同语言的对话在结构上存在相似性,语言上存在互补性。现有的研究大多采用单个数据集训练的方法,忽视了不同语言之间的互补性,为了提升性能他们只能不断增加模型的复杂度,这导致模型的执行效率大大下降。
发明内容
本发明要解决的技术问题是提供一种基于联合学习的多回合对话回应选择方法,利用对话语言结构的相通性以及不同语言的互补性提升多回合对话回应选择任务的性能。具体而言,首先将不同语言的对话文本进行预处理,得到相应的特征表示,作为联合学习框架的输入;其次使用共享的编码层,获得对话文本的内部语义信息的同时,利用不同语言的互补性拓展编码器对文本内部信息的挖掘能力;接着使用共享层次匹配模型将对话上文与备选回应进行匹配,获得对话上文与备选回应之间的匹配信息;最后将上述挖掘到的信息进行整合,并使用共享分类器对结果进行预测。
为了解决上述技术问题,本发明提供了一种基于联合学习的多回合对话回应选择方法,包括:(1)将不同语言的对话上文与备选回应进行预处理,得到相应对话上文和备选回应文本的潜在语义表征;(2)对不同语言对话上文文本与备选回应文本的特征进行特征提取,得到不同语言对话上文文本与备选回应文本的潜在语义信息;(3)对于每一种语言的对话,匹配每一回合对话与备选回应,同时整合对话上文整体语义信息;整体语义信息与备选回应进行匹配,将匹配到的信息整合;(4)将不同语言的输出进行整合,完成结果的有效预测。
本发明的有益效果:
利用对话语言结构的相通性以及不同语言的互补性提升多回合对话回应选择任务的性能。
在其中一个实施例中,步骤(2)中,使用轻量级编码器Trendoder对不同语言对话上文文本与备选回应文本的特征进行特征提取。
在其中一个实施例中,所述轻量级编码器Trencoder的输入是文本的表示向量P=[e
在其中一个实施例中,所述轻量级编码器Trencoder首先对文本做点积注意力操作,其次,使用层归一化操作处理得到的向量;再次,使用前馈神经网络和RELU激活函数对上述语义信息进行聚合。
在其中一个实施例中,所述点积注意力操作的具体如公式(20)~(21)所示:
Attention(P)=W(P)·P (21)
其中,P
在其中一个实施例中,使用前馈神经网络和RELU激活函数对上述语义信息进行聚合,具体计算如公式(22)所示:
FN(x)=max(0,xW
其中,x是一个和P形状一致的张量,W
在其中一个实施例中,步骤(3)中,使用双向注意力机制匹配每一回合对话与备选回应。
基于同样的发明构思,本申请还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现任一项所述方法的步骤。
基于同样的发明构思,本申请还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
基于同样的发明构思,本申请还提供一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
附图说明
图1是本发明多回合对话回应选择方法的模型结构图。
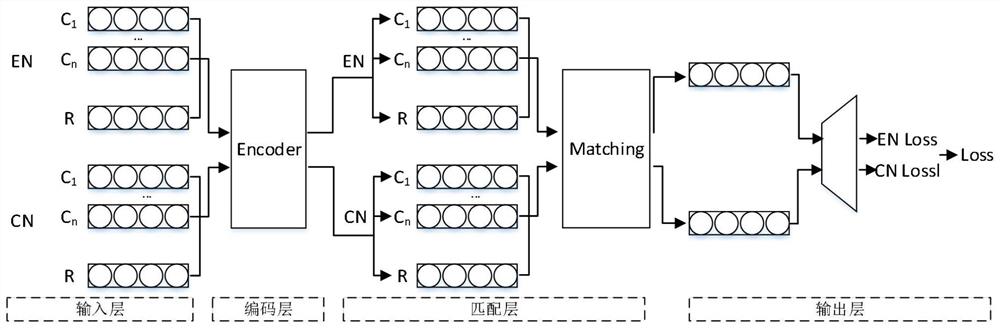
图2是本发明基于联合学习的多回合对话回应选择方法的模型结构图。
图3是本发明中编码器Trendoder的模型结构图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
多回合对话回应选择任务是自然语言处理研究热点,当前的研究主要放在层次匹配方法上,该方法主要通过将每一回合对话与备选回应匹配最后将匹配到的信息进行整合的方法。本发明用的基准模型是本发明在层次匹配的基础上融合对话上文整体语义信息,该模型构成如图1所示。
多回合对话回应选择:本发明的基准模型如下,首先,使用多头自注意力机制挖掘对话文本的潜在语义信息;其次,计算每一回合对话与备选回应在单词和回合级别的关联信息,并将每个回合和备选回应的关联信息拼接到一个矩阵中;接着,使用交叉注意力机制从上到下计算对话上文的整体语义信息,挖掘整体关联信息的同时保证对话历史的序列特性;之后,将对话上文的整体语义信息与备选的回应进行关联,并将关联的信息拼接到上述矩阵中;最后整合各类信息进行最终的回应选择。该方法在深度挖掘每一回合对话文本语义信息的同时将对话上文的整体信息融入该任务中,从而提升回应选择的性能。模型主要包括编码层、聚合层和输出层。
编码层:任务中,对话上文可以表示为:C=(u
为了得到对话上文中每一回合对话和备选回应的语义向量
r
聚合层:回应选择任务的重点在于如何有效的整合对话上文的信息,并准确找到对话上文与备选回应之间的联系。正确的回应一定与对话上文中的相关信息密切相关。因此,模型能否有效整合出对话上文和备选回应之间的联系是确定回应是否是正确回应的关键步骤。已有的层次编码方法采用将每一回合对话与备选回应进行交互,并把交互的信息进行整合的方法。这样做虽然能够捕捉到每一回合对话与备选回应之间的联系,但是忽视了对话上文的整体语义信息。实际生活中,对话之间存在较多的省略和指代现象,倘若忽视这些现象,模型很难捕捉到所有关键信息。为充分挖掘对话上文与备选回应之间的语义联系,本发明从对话上文整体、每一回合对话单词级别和每一回合对话整体语义三个层面将对话上文与备选回应进行交互。
输出层:获取到对话上文与备选回应之间匹配信息match之后,输出层的主要工作是对上述匹配信息进行进一步整合,得到最终的匹配信息,并得到最终的匹配结果。
本发明采用GRU对match进行进一步编码,并使用最后一层结果作为最终的匹配向量。具体操作如公式(18)~(19)所示。
last=GRU(match) (18)
label=Sigmoid(W
其中,label表示预测的结果,W
图2是本发明提出的基于联合学习的多回合对话回应选择的模型图。该方法使用相比多头自注意力机制更简洁的编码器挖掘对话文本的潜在语义信息,借助共享的层次匹配回应选择模型将对话上文和备选回应进行对齐,实现多语言的互补,最后通过共享输出层整合上述模型的到的匹配信息,预测得到最终的结果。该模型由以下部分组成:
(1)输入层:将不同语言的对话上文与备选回应进行预处理,得到相应对话上文和备选回应文本的潜在语义表征。
(2)共享编码层:使用轻量级编码器Trendoder对不同语言对话上文文本与备选回应文本的特征进行特征提取,得到不同语言对话上文文本与备选回应文本的潜在语义信息。
(3)共享层次匹配层:对于每一种语言的对话,首先使用双向注意力机制匹配每一回合对话与备选回应,同时整合对话上文整体语义信息。之后整体语义信息与备选回应进行匹配。最后,将匹配到的信息整合。
(4)共享输出层:将不同语言的输出进行整合完成结果的有效预测。
编码层:
多头自注意力机制在挖掘文本信息上有一定的效果,但是其结构较为复杂,为了降低本发明模型的量级,本发明使用Trencoder编码器挖掘文本的潜在语义信息。其结构与Transformer很相似。具体如图3所示:
Trencoder的输入是文本的表示向量P=[e
Attention(P)=W(P)·P (21)
其中,P
FN(x)=max(0,xW
其中,x是一个和P形状一致的张量,W
Trencoder(P) (23)编码层使用Trencoder对对话上文和备选回应进行语义挖掘。其中,不同语言的对话上文文本与备选回应文本共享编码器的模型参数。
聚合层:
之后针对不同语言的对话,本发明在对话上文整体、每一回合对话单词级别和每一回合对话整体语义三个层面将对话上文与备选回应进行交互。之后通过深度学习技术将三个层面的信息进行整合。同时,不同语言对话通过共享模型底层参数实现联合学习。
输出层:
进一步整合上文的信息,不同语言对话共享一个分类器的底层参数,得到最终的匹配结果。
优化策略:
本发明选择二分类交叉熵作为模型训练过程中的损失函数,具体计算如公式(24)~(26)所示:
其中,y表示真实答案,
本发明利用基准模型在Ubuntu Corpus V1,E-commerce Dialogue Corpus和Douban Conversation Corpus三个数据集上验证本发明提出方法的有效性。UbuntuCorpus V1数据集中的对话主要是关于Ubuntu系统故障排除的多回合英文对话。DoubanConversation Corpus数据集是从豆瓣中获取的开放域中文对话。E-Commerce DialogueCorpus数据集中的对话主要是关于淘宝客服与客户的多回合中文对话。三个数据集的具体分布如表1所示:(1)数据规模上,Ubuntu Corpus V1数据集的规模最大,其验证集和测试集均有500K条数据,其次是Douban Conversation Corpus数据集,其验证集有50K条数据,规模最小的是E-Commerce Dialogue Corpus。(2)文本长度上,Douban Conversation Corpus数据集的平均对话上文长度最长,对话上文平均长度均超过了~125~个单词,而UbuntuCorpus V1数据集的对话上文平均长度只有110,E-Commerce Dialogue Corpus的对话上文平均长度最短,只有35个单词左右。(3)备选回应数上,Douban Conversation Corpus数据集的测试集中备选回应平均个数为1.18,说明在Douban Conversation Corpus的测试集中,有一部分数据合适的备选回应不止一个,这也导致了数据集的作者增加了数据集的评价指标。
表1数据集数据详细分布
除了表1显示的数据集特点,本发明还对数据集中的样例(如表2~表4中的样例)进行了研究,本发明发现:(1)Ubuntu Corpus V1虽然数据规模大,但是该数据集的的语言逻辑比较简单,数据集中样例的内容全部是关于Ubuntu系统的话题,话题比较集中。E-Commerce Dialogue Corpus数据集的样例全是电商平台客服与用户的对话,但这些对话的主题却不是很集中,因为电商平台的聊天大多是与商品相关的,而每组对话所讨论的商品却是多种多样的。Douban Conversation Corpus数据集的样例多为较为开放的话题,所涉及的话题也较为广泛。(2)三个数据集虽然所涉及的话题不同,甚至Ubuntu Corpus V1与另外两个数据集的语言都不相同,但是数据集中样例在结构上具有相似性,语言上具有互补性。具体体现在(a)不同语言对话中均存在省略和指代等语言现象。(b)相邻对话之间的关系最为密切,主要体现在对话中的省略和指代大多是最近的一轮对话中的内容。
表2 Ubuntu数据集样例
表3 Douban数据集样例
表4 E-Commerce数据集样例
实验结果如表5所示。
具体实验设置如下:
Trencoder层次匹配:使用Trencoder挖掘文本的潜在语义信息,使用层次匹配交互模块挖掘对话文本与备选回应直接的相关信息,并将全文信息融入其中。
联合学习信息:通过联合学习的方法共享Trencoder编码器、层次匹配交互模块以及输出模块。
表5各个实验在Ubuntu Corpus V1和E-commerce Dialogue Corpus数据集的结果
表6各个实验在Douban Conversation Corpus数据集的结果
输入:
英文输入:
中文输入:
第一步:挖掘对话上文和备选回应的本发明语义信息。(不同语言样例共享编码器)
第二步:整合对话上文整体语义信息。
第三步:将每一回合对话、对话上文整体语义信息与备选回应进行信息交互。
第四步:将第三步得到的信息进行整合。
输出:利用上述整合到的信息输出对话上文与备选回应的匹配分数。(上述步骤中,不同语言的样例共享网络的参数)
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 基于联合学习的多回合对话回应选择方法
- 一种基于深度学习的MIMO系统联合预编码和天线选择方法