一种基于核心兴趣网络的点击率预测方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及商品点击率预测和基于深度学习的序列化推荐系统领域,尤其是一种基于点击率预测方法,为一种基于神经网络的商品推荐方法。
背景技术
随着互联网的发展,收集到用户的信息是越来越多,如何利用该信息提取用户兴趣变得尤为重要。获取用户兴趣,给用户推荐相应的物品带给公司巨大的收益。谷歌公司百分之八十以上的收入来自广告。广告的计费模式有很多,其中传统广告计费方式有:以展示量收费,即根据给用户展示的次数收费;以长期租赁的方式收费,即固定位置展示一定的时间收取相应的费用。但随着行业的发展更细致的方式更利于双方交易,如今则出现了,以点击量付费,用户点击了广告才收取相应费用,所以对一个公司来说提高点击率CTR则格外重要。
典型的CTR预测方法有微软研究院提出的逻辑回归模型(LR);斯坦福大学Friedman等人提出一种解决特征组合问题的方案GDBT;日本大阪大学Steffen Rendle等人于2010年提出FM模型,旨在解决数据量大而稀疏的情况下的特征组合的问题。但是由于深度学习优秀的拟合能力。并且端到端的学习方式,不需要再进行特征工程,使得深度学习在推荐领域大放异彩。
如今CTR的主流方法都是基于深度学习,而且如今已有很多代表工作。它们大致分为两类一类是基于池化的方法,将用户的各个历史行为分别学习它们的表征形式,最后通过求和或是平均的方式来学习到用户最终的兴趣,如DIN、FNN、NFM。这种方式忽略了用户行为之间的依赖性。另外一类是基于时序的方法,将用户各个时间购买的物品视为时间序列,用LSTM/GRU等模型从时序中捕获用户的兴趣,最终依据用户兴趣对候选物品进行点击率预测。然而,当序列长度相对较长时,例如超过100时,这些解决方案无法处理这种情况。这是由于RNN的消失梯度问题,即模型不能学习距离太远行为的信息。
发明内容
为了克服现有技术的不足,本发明提供一种基于核心兴趣网络的点击率预测方法。本发明提出了一种新的核心利益网络(CIN)模型,以减轻CTR预测中长序列的梯度消失问题。提出一种基于核心兴趣网络的点击率预测方法。本发明利用以下原理:本发明聚焦点击率(Click Through Rate,CTR)预测任务下的时序数据中的长序列问题。为了缓解臭名昭著的LSTM/GRU的梯度消失问题,提出了核心兴趣网络(Core Interest Network,CIN)模型,将一个长序列切分成多个子序列,在每个子序列中提取用户的核心兴趣。每个子序列提取的核心兴趣将向下一个子序列传递。通过这种方法,模型完成对整个长序列用户兴趣的学习。通过提取用户核心兴趣,这是用户更高阶更稳定的兴趣,使得传递给下一子序列数据中噪音更少,更利于学习到用户的兴趣。同时加入了多层感知机(Multi-Layer Perception,MLP)这一深度学习方法,可以从数据中学习任意函数,增加了点击率预测的准确性。
本发明解决其技术问题所采用的技术方案包括以下步骤:
步骤1:获取用户属性描述、用户行为列表、广告信息以及上下文信息;
步骤2:将用户行为序列按session切分,每个session中依据用户行为数据,提取用户核心兴趣:
u
r
其中,u
步骤3:根据用户的隐状态以及用户各个时刻的真实行为计算辅助损失;
步骤4:将每个session提取的核心向后传递捕获用户动态兴趣,描述为:
其中i
步骤5:根据用户行为与候选物品的相似度,计算对应的attention值;
步骤6:通过辅助损失函数以及目标损失函数来定义模型的损失,使用交叉熵损失函数来定义模型损失函数,描述为:
L=L
其中,L为系统全局损失值,L
步骤7:在得到全局损失L后,通过随机梯度下降方法计算得到整个神经网络模型参数更新迭代的大小及方向,设定迭代更新轮数,最终能够得到模型收敛的参数,在得到模型的所有训练后的参数以后,再将用户的历史行为以及候选物品作为输入,模型最终能够计算出点击率,即该用户点击候选物品的概率,从而能够点击率预测任务。
所述步骤1中,所述用户属性描述、用户行为列表、广告信息以及上下文信息,分别用one-hot编码表示成x
所述步骤3中,辅助损失描述为:
其中,L
所述步骤5中,attention值描述为:
其中,a
本发明的有益效果在于重点研究了CTR预测下序列数据中的长序列问题,为了缓解LSTM/GRU梯度消失的臭名昭著的问题,提出了CIN模型,将一个长序列划分为多个子序列,并在每个子序列中提取用户的核心兴趣,从每个子序列中提取的核心兴趣被传递给下一个子序列,以此模型就完成了整个长序列中用户兴趣的学习。通过提取用户的核心兴趣,这是用户在更高层次和更稳定的兴趣传递给下一个子序列的数据中的噪声较小,更有利于学习用户的兴趣。值得一提的是,本发明不仅可以用于推荐系统中的兴趣提取,还可以用于处理其他序列数据中的长序列问题。在推荐系统序列化预测场景有很多应用前景。
附图说明
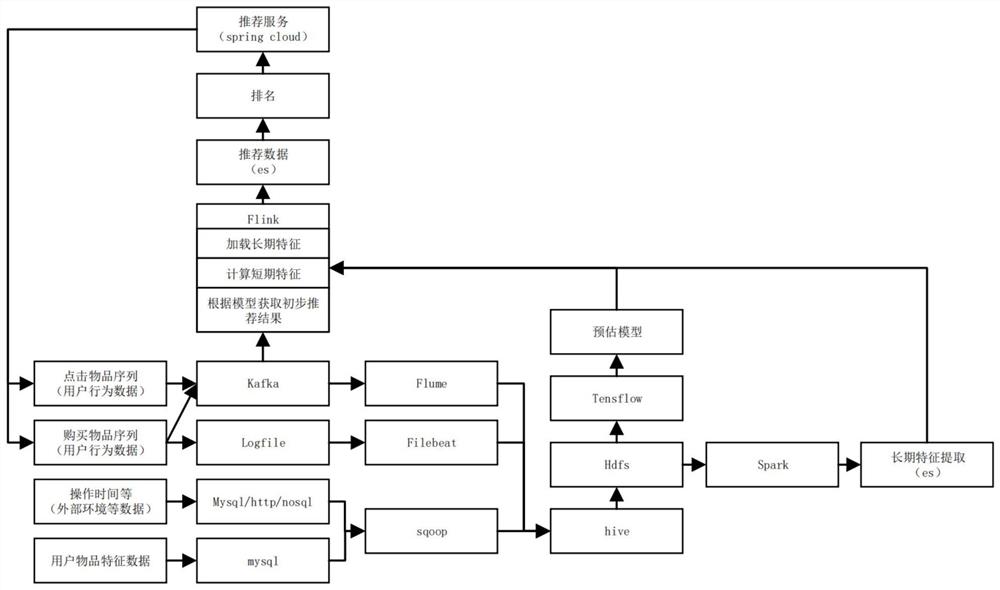
图1为本发明基于核心兴趣网络的点击率预测方法流程图。
图2为核心兴趣传递模型的示意图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本发明共有图1和图2,如图1所示,本发明的具体步骤如下:
步骤一:获取用户属性描述、用户行为列表、广告信息以及上下文信息。分别用one-hot编码表示成x
步骤二:将用户行为序列按session切分,每个session中依据用户行为数据,提取用户核心兴趣。
u
r
步骤三:根据用户的隐状态以及用户各个时刻的真实行为来计算辅助损失。
步骤四:将每个session提取的核心向后传递捕获用户动态兴趣。
步骤五:根据用户行为与候选物品的相似度,计算对应的attention值。
步骤六:通过辅助损失函数以及目标损失函数来定义模型的损失,使用交叉熵损失函数来定义模型损失函数。
L=L
步骤七:通过随机梯度下降更新模型参数,依据样本数据学习得到优化模型。最终能够依据用户核心兴趣对物品点击率进行预测。
本发明为基于核心兴趣网络的点击率预测方法,使用多层GRU提取每个session中用户的核心兴趣;将每个session提取的核心向后传递捕获用户动态兴趣;基于用户核心兴趣、用户特征以及物品属性,得到最终用户对物品的点击率预测值。
以上所述仅为本发明的较佳实施列,对于发明而言仅仅是说明性的,而非限制性的。本专业技术人员理解,在发明权利要求所限定的精神和范围内可对其进行许多改变、修改等,但都将落入本发明的保护范围内。
- 一种基于核心兴趣网络的点击率预测方法
- 一种基于多信息节点图网络的短视频点击率预测方法