一种基于FC-SAE的多源异构数据融合方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明涉及数据融合方法技术领域,具体是指一种基于FC-SAE的多源异构数据融合方法。
背景技术
目前,在基于深度学习数据融合研究中,大多数研究学者采用特征拼接和全连接层等方式对所提取特征进行融合。该类融合方式较为简单,但是未能充分挖掘多源异构数据之间的相关性。本申请技术方案中FC-SAE数据融合模型将深度稀疏自动编码器作为融合模型,在保留最大信息量的同时充分挖掘时间序列数据与文本数据之间的关联关系,以获取数据的共享特征表示。通过对多源异构数据进行融合能够有效地降低时间序列预测结果的误差,具有更好的融合性能。
发明内容
本发明要解决的技术问题是以上所述的技术问题,提供一种融合性能好、误差小的基于FC-SAE的多源异构数据融合方法。
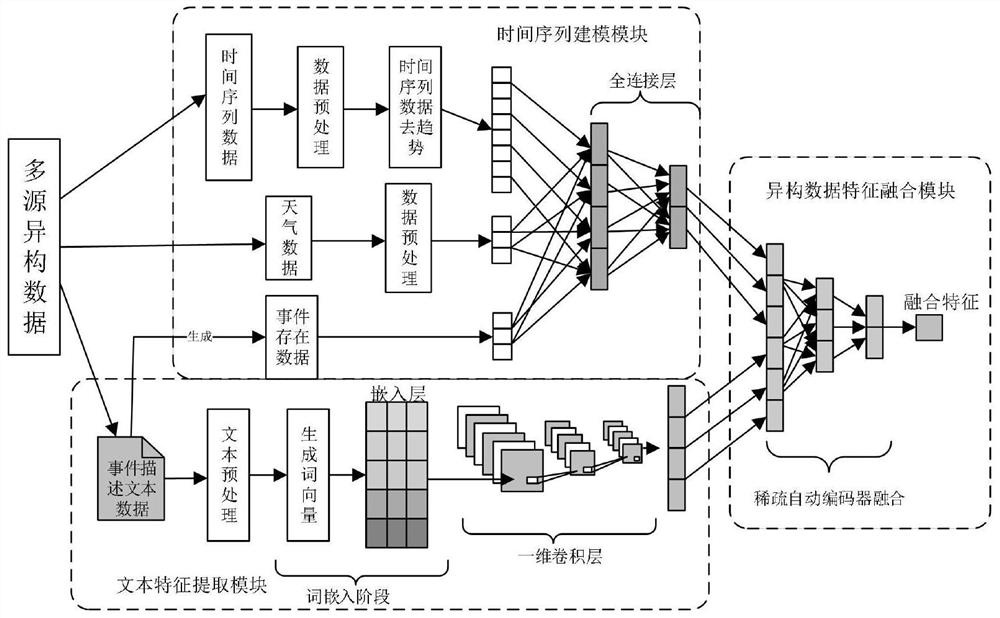
为解决上述技术问题,本发明提供的技术方案为:一种基于FC-SAE的多源异构数据融合方法,包括FC-SAE数据融合模型,所述的FC-SAE数据融合模型包括文本特征提取模块、时间序列建模模块以及异构数据特征融合模块,所述的文本特征提取模块包括GloVe词嵌入模型和卷积神经网络,所述的时间序列建模模块使用多层全连接神经网络进行建模,所述的异构数据特征融合模块包括稀疏自动编码器,所述的融合方法步骤如下:
Step1:对文本数据进行删除HTML标签、删除停用词、小写转换等预处理;
Step2:使用Tokenizer分词器对文本进行分词,生成不定长文本序列V,对不定长文本序列进行零填充V,使其成为等长文本向量V
Step3:使用GloVe词嵌入模型对文本向量V
Step4:卷积神经网络进一步提取词向量矩阵X[i:j]特征,获得文本数据特征Z
Step5:时间序列数据预处理,并根据事件描述数据生成事件存在数据;
Step6:采用历史平均法对时间序列数据进行去趋势,生成去趋势数据如下式所示;
Step7:多层全连接网络提取时间序列特征Z
Step8:将文本数据特征Z
作为改进,所述的文本向量V
作为改进,所述的GloVe词嵌入模型是利用词向量v
其中,N为语料库中词数量,共现矩阵X为N×N矩阵;X
通常,x
作为改进,所述的词向量矩阵X[i:j]通过卷积层进行卷积运算获得特征映射C,并通过最大池化层获得特征映射中的最大值
C
C=[C
其中,n为特征映射数量,m为卷积核个数。
作为改进,所述的多层全连接网络包括输入层、输出层和隐藏层,所述的多层全连接网络输出的计算步骤如下:
首先计算输入的加权和,如下式所示:
其中,W
其中,W
所述的多层全连接网络的输入向量采用滞后观察的形式作为固定输入向量,如下式所示:
Z
其中,Z
作为改进,所述的稀疏自动编码器是一种无监督深度学习模型,所述的稀疏自动编码器工作步骤为首先将文本数据特征Z
y=h(Wx+b)
x′=h′(W′y+b′)
其中,h与h′分别为编码器和解码器的激活函数,W和W′分别为编码器和解码器的权重矩阵,b和b′为编码器和解码器的偏置项;
所述的稀疏自动编码器通过对损失函数最小化来对参数进行优化,所述的稀疏自动编码器的损失函数可表达如下:
其中,L为隐藏层节点数目,n为数据样本数量,k为输入向量维度,λ和β为给定系数,分别控制权重系数正则项和稀疏正则项。
本发明与现有技术相比的优点在于:本申请在对时间序列数据进行去趋势的基础上,采用FC对时间序列进行建模,减小在某些时间序列预测问题上的误差,通过深度稀疏自动编码器作为融合模型,在保留最大信息量的同时充分挖掘时间序列数据与文本数据之间的关联关系,以获取数据的共享特征表示,通过对多源异构数据分别进行特征提取,并使用稀疏自动编码器即无监督深度学习模型进行融合,达到充分利用多源异构数据的目的,预测效果好。
附图说明
图1是本发明一种基于FC-SAE的多源异构数据融合方法的结构示意图。
图2是本发明一种基于FC-SAE的多源异构数据融合方法文本向量化示例图。
图3是本发明一种基于FC-SAE的多源异构数据融合方法GloVe词嵌入模型训练流程图。
图4是本发明一种基于FC-SAE的多源异构数据融合方法多层全连接网络的结构示意图。
图5是本发明一种基于FC-SAE的多源异构数据融合方法的流程图。
图6是本发明一种基于FC-SAE的多源异构数据融合方法预测结果对比图。
图7是本发明一种基于FC-SAE的多源异构数据融合方法增量分析实验预测结果对比图。
图8是本发明一种基于FC-SAE的多源异构数据融合方法多源异构数据融合实验评价指标:a)MAE指标、b)RMSE指标、c)R
具体实施方式
下面结合附图对本发明做进一步的详细说明。
实施例
选取纽约市出租车与豪华轿车委员会公开数据集中的布鲁克林区巴克莱中心区域出租车出行记录为研究对象。气象数据为美国国家海洋和大气管理局公开数据集,该数据集共13个特征,包括日期、最高气温、最低气温、风速、阵风风速、能见度、气压、降水量、降雪量、是否为冰雹天气、是否为冰冻天气、是否为雾天、是否为雷电天气等。事件文本数据从巴克莱中心官网获取,数据集共包含751条事件描述文本数据,每条数据包括标题、时间和事件描述。事件存在数据是由事件文本数据生成,在有事件发生的日期中该值为1,在无事件发生的日期中,所对应的该值为0。上述实验数据集的部分数据示例如表1所示,
表1数据集部分示例a)出租车出行数据
b)气象数据
c)事件文本描述数据
在出租车出行记录数据集预处理中,首先将原始数据按照日期进行相加,获得每日出租车出行数据。为降低数据偏移对后期计算影响,对数据进行去趋势操作,使模型着重关注于时间序列本身波动,提升预测性能。气象数据的预处理操作是将数据中的异常值用0代替,并对数据进行归一化处理。文本数据的预处理为常规文本预处理,包括HTML标签删除、小写转换、词根化以及删除停用词和介词等。
FC-SAE数据融合模型采用GloVe词嵌入模型和卷积神经网络对文本数据进行特征提取,其中卷积神经网络包含3个卷积层和3个池化层,使用ReLU函数为激活函数;对时间序列的建模采用了两层全连接神经网络,分别具有100个神经元和50个神经元,采用tanh函数作为激活函数,并在全连接网络层输入前对输入数据进行标准化。融合模型采用稀疏自动编码器,包含3层的编码器和3层的解码器,采用tanh函数作为激活函数,模型参数采用Adam优化器进行优化。
为验证FC-SAE数据融合模型相对于其他时间序列预测方法在预测方面的优越性,首先将FC-SAE数据融合模型与常用的非线性时间序列预测模型进行比较。此外,还将FC-SAE模型中的时间序列建模模块更换为LSTM,即LSTM-SAE模型,并验证其有效性。然后为评估不同信息来源对融合特征的贡献度,本文还对FC-SAE模型和LSTM-SAE模型进行增量分析实验。最后为对比不同融合策略对预测结果影响,在完整模型的情况下,对基于全连接层融合与基于稀疏自动编码器融合模型进行比较。
本实施例选取数据集中2013年1月至2014年9月共21个月的数据作为训练集,选取2014年10月至2014年12月的数据作为验证集,选取2015年1月至2016年6月共18个月的数据作为测试集,实验采用的平台为:Ubuntu 18.04,Intel CPU E5-2620,NVIDIA GTX 1080TiGPU,并使用基于TensorFlow的深度学习库Keras进行模型构建。
将FC-SAE数据融合模型的预测结果与支持向量回归(Support VectorRegression,SVR)、高斯过程(Gaussian Process,GP)、长短时记忆网络(LSTM)和LSTM-SAE模型的预测结果进行比较。其中,SVR采用线性核作为核函数,并设置惩罚因子为100,GP采用平方指数和白噪声协方差预测结果如图6与图7所示。
从图6的预测结果对比可以看出,上述模型均能对出租车需求做出有效地预测,但是预测结果相差较大。通过实验对比发现,LSTM神经网络和GP模型的预测曲线与真实值曲线的差别较大,具有不稳定性,拟合真实值曲线的效果较差;SVR模型的预测结果相较于LSTM神经网络和GP模型而言,和真实值曲线的拟合程度更好;LSTM-SAE模型与FC-SAE数据融合模型相较于其他三种模型,预测曲线与真实值曲线的拟合程度有了明显提升,这说明通过融合时间序列数据和文本数据可以有效的提升预测精度。比较LSTM-SAE模型和FC-SAE数据融合模型可发现,FC-SAE数据融合模型的预测曲线具有更好的稳定性,能够更好地拟合真实值曲线,这说明在该数据集上FC-SAE数据融合模型比LSTM-SAE模型具有更好的预测效果。
从图7的预测结果对比中可以看出,当依次加入时间序列数据(TS)、气象数据(W)、事件存在数据(E)以及事件文本数据(TE)时,FC-SAE数据融合模型的预测曲线对真实值曲线的拟合效果逐步提升。其中,当事件存在数据加入后(TS+W+E),FC-SAE数据融合模型的预测曲线拟合程度提升最大。这说明了在考虑多种因素影响的情况下,时间序列预测结果的误差将进一步减小,预测精度进一步提高。
本实施例选用均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和拟合优度R2(Goodness of Fit)指标对所提出模型进行评价。其计算公式如下:
其中,N表示测试集中数据量,y
本实施例首先比较了FC-SAE数据融合模型与SVR模型、GP模型、LSTM神经网络以及LSTM-SAE模型在MAE、RMSE和R2指标上的差异,如表2所示。结果表明,在本文的时间序列预测问题上,LSTM并不是最优选择。并且通过调整参数LSTM-SAE模型均无法达到FC-SAE数据融合模型的性能。该结果也验证了关于LSTM早期研究中的结论。FC-SAE数据融合模型与SVR算法、GP算法和LSTM算法相比较,在MAE指标上分别提升了1.3%、5.3%和6.6%,在RMSE指标上分别提升了1.8%、5.4%和4%,在R2指标上则分别提升了1.8%、6.6%和7.7%,具有明显的优势。
表2FC-SAE数据融合模型与常用时间序列模型和LSTM-SAE模型对比
为进一步分析多源异构数据对融合结果的影响程度,该部分实验采用增量分析方式进行。首先仅对时间序列建模(TS),然后依次增加气象数据(TS+W)、事件存在数据(TS+W+E)以及事件文本描述数据(TS+W+E+TE),结果如图8所示,从图8中我们可以看出,引入气象数据(TS+W)能够改善时间序列预测结果。从经验角度分析,恶劣的气象条件会改变人们的出行方式,这与我们实验结果相符。对预测结果影响最大的事件存在数据(E),在引入事件存在数据后,FC-SAE算法的MAE指标和RMSE指标分别降低了17.1%和12.6%。同样的LSTM-SAE算法的MAE指标和RMSE指标也分别下降了17%和15.3%。引入事件存在数据虽然对FC-SAE算法和LSTM-SAE算法预测效果有明显的提升,但是如果不进一步分析事件描述所包含的信息,就无法判断事件对预测结果的真实影响。本实施例通过GloVe词嵌入模型和卷积神经网络,将事件文本描述引入时间序列预测中。实验结果显示,在将事件文本描述数据(TS)与其他数据结合后,FC-SAE算法的MAE指标从99.3下降至95.9,RMSE指标也从140.3下降至135.8,R2从0.599提升至0.626。同样LSTM-SAE算法的MAE和RMSE指标分别降低6.6%和2.2%。因此,不同数据的引入对预测结果均有不同的影响,影响较大的为事件存在数据,事件描述文本数据对预测结果有一定程度提升,但不如前者明显。
为验证SAE融合模型的有效性,本文将FC-SAE数据融合模型、LSTM-SAE模型与使用全连接层融合模型:FC-FC模型、LSTM-FC模型进行比较,结果如表3所示。实验结果显示,使用SAE模型进行融合相较于使用FC层进行融合在预测结果方面有显著提升。FC-SAE数据融合模型相较于FC-FC模型在MAE指标和RMSE指标上分别下降了1.7%和2.3%,同样LSTM-SAE模型对比LSTM-FC算法在MAE和RMSE指标上分别下降了2.1%和2.2%。在实验过程中发现,使用SAE模型进行融合的优势在于能够较为充分的挖掘时间序列数据和文本数据之间的相关性,同时保留最大的信息量。该实验结果验证了SAE融合模型相较于全连接层在异构数据融合方面表现更出色。
表3FC-SAE模型、LSTM-SAE模型融合方法对比实验
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
- 一种基于FC-SAE的多源异构数据融合方法
- 一种基于物联网的多源异构数据融合方法