一种融合对比学习与聚类的智能问答语义表征方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及智能问答领域,特别涉及一种融合对比学习与聚类的智能问答语义表征方法。
背景技术
随着人工智能的发展,聊天机器人、智能助理机器人等产品已经大量应用与人们的日常生活中。而作为机器人的核心功能的智能问答随着自然语言处理的技术不断更新,效果上得到了很大的提高。bert作为通用的预训练模型,因为其优秀的效果,在自然语言处理中得到广泛应用。但是作为一种语义表征方法,bert的语义空间是各向异性的,各向异性导致词向量分布不均匀,高频的词更加稠密且离原点更近,而低频的词更加稀疏且离原点更远。因此原始bert不能直接用于语义表征中。
为了解决bert在语义表征时候的各向异性问题,bert-flow采用normalizingflows来将bert的句向量分布转换为高斯分布,得到一个光滑、各向同性的分布空间,但是该方法采用的normalizing flows较为复杂且无法很好的适用业务领域。
因此需要一种针对性强且适用性佳的智能问答语义表征方法。
发明内容
本发明所要解决的技术问题是克服现有技术的不足,提供一种融合对比学习与聚类的智能问答语义表征方法,对比学习在自然语言领域被不断尝试,simcse则是通过对比学习拉近相似句子的距离,拉远不相似句子的距离来简单解决bert的各向异性。尽管simcse能够通过对比学习来优化bert在语义表征的效果,但是作为一种基于样本对的训练方式,其只能学习样本对层面的语义信息,无法学习类别层面的高级语义信息。而智能问答的知识库是以标准问-相似问的组织形式,每一个标准问代表一个类别,即需要模型能够学到样本对层面的语义信息,也需要学习到类别层面的高级语义信息。因此simcse无法满足智能问答在类别层面的高级语义信息的要求。
为了有一个更加好的问答效果,所采用的语义表征方法既要学习样本对的语义信息,又要学习到类别的高级语义信息。本发明提供一种融合对比学习与聚类的智能问答语义表征方法,具体如下:
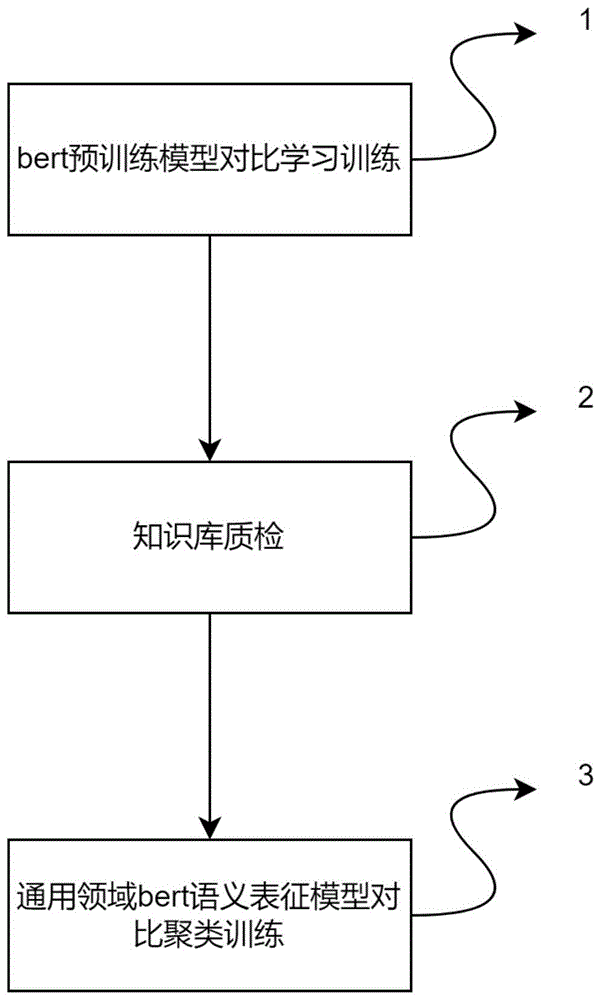
步骤1,从通用领域收集样本对数据,加载开源的bert预训练模型,并采用对比学习对bert预训练模型进行训练得到通用领域bert语义表征模型;
步骤2,利用聚类算法对知识库进行质检;
步骤3,在业务领域的数据集上利用对比聚类对通用领域bert语义表征模型继续训练得到业务领域bert语义表征模型。
所述步骤1包括如下具体步骤:
步骤1-1:收集通用领域的样本对数据作为训练样本对;
步骤1-2:搭建bert模型,并加载对应bert模型的开源的预训练权重,获得bert预训练模型;
步骤1-3:利用步骤1收集的通用领域数据集上,采用对比损失继续训练bert预训练模型得到通用领域bert语义表征模型。
步骤1-2中,所述预训练权重为roberta-wwm-base模型,步骤1-3中,利用对比损失函数优化bert预训练模型,得到通用领域bert语义表征模型,所述对比损失函数为:
其中I表示该损失为对比损失,M代表一个批次的句子对数目,i,j分别代表两组句子所在的批次的索引编号,1,2代表属于相同索引下的不同句子的编号,
所述步骤2中包括,对知识库的问题进行相似度聚类,发现并筛选出非重复交叉的标准问,包含如下具体步骤:
步骤2-1:利用通用领域bert语义表征模型,对知识库中的所有问题进行编码,得到每个问题的句向量表示;
步骤2-2:通过句向量的余弦相似度进行快速聚类,当两个问题的句向量表示的余弦相似度大于预设阈值时设定为相似,将所有的句向量划分为不止一个的类别;
步骤2-3:检测每个类别中的所有句向量是否属于相同的标准问下,如果该类句向量属于多个标准问且超过预设的比例,则合并该类别下的问题。
步骤3中,从非重复的标准问下采样样本对,使用联合损失函数训练业务领域的bert语义表征模型。
步骤3中,使用MLP的权重表示每个类别k的句向量μ
其中K表示知识库中的标准问数量,k表示x
其中
通过KL散度将类别概率分布向目标分布靠近,得到聚类损失为:
所述C用于区分对比损失,表示该损失是聚类损失;
联合损失表示为:
其中η表示对比损失的权重。
所述步骤1-3中,句子对数目取值为256,温控系数τ的取值为0.5,所述步骤3中,η的取值为10。
本发明所达到的有益效果:通过在通用领域样本数据上,基于对比学习训练bert预训练模型,解决bert预训练模型中语义空间的各向异性的问题;通过知识库质检,对知识库的问题进行聚类,解决知识库标准问的重复交叉的噪声问题;通过在业务领域样本数据上,基于对比聚类的方法对bert通用领域语义表征模型继续训练,解决了bert通用领域语义表征模型,只能学习样本对层面的语义信息,无法学习类别层面的高级语义信息的问题。
附图说明
图1为本发明的示例性实施例的系统流程图;
图2为本发明的知识库质检流程图;
图3为本发明的业务领域bert对比聚类训练流程图。
具体实施方式
下面结合附图和示例性实施例对本发明作进一步的说明:
如附图1所示的一种基于融合对比学习与聚类的智能问答语义标准方法,具体如下:
步骤1,bert预训练模型对比学习训练,具体为,从通用领域收集样本对数据,加载开源bert预训练模型,采用对比学习对bert预训练模型进行训练;得到通用领域的bert语义表征模型,具体步骤包含如下步骤:
步骤1-1:收集中文自然语言推理数据集作为训练样本对,该数据集的特点是相似问的具有更少的词汇重叠,使得模型能够学习到更好的语义信息;
步骤1-2:选择roberta-wwm-base作为bert预训练模型,相比传统的bert,其以更大的数据集和全词掩码的方式进行训练,取得了更好的效果;
步骤1-3:步骤1-1中的训练样本输入到步骤1-2的bert预训练模型中获取句向量,该句向量是由768维的向量进行表示,最后采用对比损失函数来最小化正例对样本对的句向量的距离,最大化负样本对的句向量的距离,所述对比损失函数为:
其中I表示该损失为对比损失,M代表一个批次的句子对数目,M的取值应该尽可能大,但实验中因此显存的限制,经过实践对比和调整,最终取值为256,i,j分别代表两组句子所在的批次的索引编号,1,2代表属于相同索引下的不同句子的编号,
步骤2,知识库质检,具体为,对知识库的问题进行相似度聚类,发现并筛选出非重复交叉的标准问。
如图2所示,具体步骤包含如下:
步骤2-1:知识库问题句向量编码,利用通用领域bert语义表征模型,对所有知识库中的问题进行编码,得到每个问题的句向量;
步骤2-2:知识库句向量快速聚类,通过句向量的余弦相似度进行快速聚类,当两个问题的句向量表示的余弦相似度大于0.94的时候,认为该样本对是语义一致的,最后将多个语义一致的样本聚成一个类;
步骤2-3:知识库标准问重复度检测,检测步骤2-2每个小类中的所有问句是否属于相同的标准问下,如果1/3比例以上的不一致,则说明该小类下的问题所属标准问存在重复交叉,需要合并该小类下的问题。
步骤3,通用领域bert语义表征模型对比聚类训练,具体为,利用知识库中筛选出的非重复标准问下的样本对,采用对比聚类损失,对通用领域bert语义表征模型继续训练。
如图3所示,具体步骤包含如下:
步骤3-1:训练样本对采样,从步骤2中得到标准问-相似问中采样得到样本对,同一个batch中样本对所属的标准问不能相同;
步骤3-2:设计对比聚类损失,不同于对比损失函数,聚类损失更加专注与高级的语义概念,并把具有相似的高级语义概念的样本聚在同一个类别中。因为实验中共有500个标准问,故此处取类别K取值为500;本模型采用MLP的权重来近似的表示每个类别向量μ
此处K是k的所能取的最大值,比如说标准问的数量是10。则K=10,那么k的取值范围为1-10;α取值为1,1是通过实践得出的适合应用的优选赋值,对该赋值简单的增大或减小都会造成系统的性能损失。假设此处计算问题x
最后使用一个辅助概率作为目标概率分布,其辅助概率分布表示为:
其中
最后通过KL散度将类别概率分布向目标分布靠近,即使得q
所述C用于区分对比损失,表示该损失是聚类损失;
步骤3-3:利用对比损失和聚类损失联合优化模型,具体为损失优化通用领域的模型。
其中η表示对比损失的权重,用于平衡对比损失与聚类损失,设定η为10,该取值与效能间没有可简单预计的比例关系,而10是通过实践得出的适合应用的优选赋值,对该赋值简单的增大或减小都会造成系统的性能损失。
本发明所达到的有益效果:通过在通用领域样本数据上,基于对比学习训练bert预训练模型,解决bert预训练模型中语义空间的各向异性的问题;通过知识库质检,对知识库的问题进行聚类,解决知识库标准问的重复交叉的噪声问题;通过在业务领域样本数据上,基于对比聚类的方法对bert通用领域语义表征模型继续训练,解决了bert通用领域语义表征模型,只能学习样本对层面的语义信息,无法学习类别层面的高级语义信息的问题。
以上实施例不以任何方式限定本发明,凡是对以上实施例以等效变换方式做出的其它改进与应用,都属于本发明的保护范围。
- 一种基于语义元语的词向量表征学习方法及系统
- 基于宏观到微观语义关联对比的视频自监督表征学习方法
- 基于跨模态语义表征学习和融合的图像分类方法及系统