用于大模型一体机的数据加密安全保护方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及数据处理技术领域,具体涉及用于大模型一体机的数据加密安全保护方法。
背景技术
办公一体机是一种常见的大模型一体机设备,作为一件现代办公室不可或缺的设备,其融合了多种功能,包括打印、扫描、复印和传真等,以达到提高工作效率和简化办公流程的效果,办公一体机内置了大容量的存储器,用于保存各种文档、扫描数据和打印任务,这些数据涉及敏感的财务信息、客户记录和商业文件,并且在传输时需要保证传输文件的防篡改和偷窥,并且实现数据备份操作,因此需要对办公一体机内的存储数据经过加密保存,避免敏感信息的丢失。
一体机设备中的明文数据具有较高的频率特征,即有强特征性,混沌加密算法对明文数据的强特征具有较高的敏感度,所以通过混沌加密算法对明文数据加密后,获得的密文数据中任然保留着明文数据的强特征,导致密文数据容易被破解,密文数据的安全性低。
发明内容
本发明提供用于大模型一体机的数据加密安全保护方法,以解决现有的问题。
本发明的用于大模型一体机的数据加密安全保护方法采用如下技术方案:
本发明一个实施例提供了用于大模型一体机的数据加密安全保护方法,该方法包括以下步骤:
将办公一体机的存储器中存储的每个文件作为明文数据;
将明文数据作为第一个采样块,对第一个采样块进行多次的下采样获得明文数据的所有采样块,将每次下采样的结果作为一个采样块,根据每个采样块中的每个数据的邻域内的数据得到每个采样块中的每个数据的第一延伸直线和第二延伸直线,根据每个数据、每个数据的第一邻域内所有数据的分布以及每个数据的第一延伸直线和第二延伸直线的夹角得到每个数据的延伸系数,所述每个数据的延伸系数表征了每个数据的邻域内数据之间的差异;
根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度,根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合,根据第一个采样块中的每个数据的所有匹配集合得到第一个采样块中的每个数据的特征强度;
根据每个数据的特征强度得到明文数据中的强特征数据,根据强特征数据对明文数据进行处理得到新的明文数据,对新的明文数据进行加密。
进一步地,所述明文数据的所有采样块的具体获取步骤如下:
统计明文数据中行字符个数和明文数据中的所有行数,将明文数据的所有行中字符个数最多的一行的字符个数记为HS,将明文数据中的所有行数记为H,根据HS和H得到调整行数
其中,每个采样块中的每个数据是一个字符。
进一步地,所述根据每个采样块中的每个数据的邻域内的数据得到每个采样块中的每个数据的第一延伸直线和第二延伸直线,包括的具体步骤如下:
以每个数据为中心点,获取
将明文数据的每个采样块中的任意一个数据记为目标数据,先获取目标数据的第二邻域,计算目标数据与对应的第二邻域内每个数据之间的差异,将与目标数据差异最小的第二邻域内的一个数据记为第一方向数据,将与目标数据差异第二小的第二邻域内的一个数据记为第二方向数据;其中,差异表示差值的绝对值,且每个数据之间的差异计算是通过十进制数进行运算的,即首先将每个字符转换为二进制数,再将二进制数转换为十进制数;
将目标数据的第二邻域内的所有数据记为标记数据,在目标数据的第一邻域内获取第一方向数据的第二邻域内的数据,将第一方向数据的第二邻域内的数据除去标记数据后剩余的数据记为第一方向数据的第三邻域,计算第一方向数据与对应的第三邻域内每个数据之间的差异,将与第一方向数据差异最小的第三邻域内的一个数据记为第三方向数据;
在目标数据的第一邻域内获取第二方向数据的第二邻域内的数据,将第二方向数据的第二邻域内的数据除去标记数据后剩余的数据记为第二方向数据的第三邻域,计算第二方向数据与对应的第三邻域内每个数据之间的差异,将与第二方向数据差异最小的第三邻域内的一个数据记为第四方向数据;
再获取目标数据、第一方向数据、第二方向数据、第三方向数据和第四方向数据的位置坐标,通过目标数据、第一方向数据和第三方向数据的位置坐标使用最小二乘法进行直线拟合,将得到的直线记为第一延伸直线;通过目标数据、第二方向数据和第四方向数据的位置坐标使用最小二乘法进行直线拟合,将得到的直线记为第二延伸直线。
进一步地,所述根据每个数据、每个数据的第一邻域内所有数据的分布以及每个数据的第一延伸直线和第二延伸直线的夹角得到每个数据的延伸系数,包括的具体步骤如下:
每个数据的延伸系数的计算公式为:
式中,
进一步地,所述根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度的具体公式如下:
式中,
进一步地,所述根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合,包括的具体步骤如下:
将第一采样块中的任意一个数据记为参考数据,计算参考数据与第2个采样块中每个数据之间的匹配程度,获取参考数据与第2个采样块中每个数据之间的匹配程度大于或者等于预设阈值T的所有数据,组成参考数据的第一匹配集合;
从第一匹配集合中的第一个数据开始,依次遍历第一匹配集合中的每个数据,计算第一匹配集合中第一个数据与第3个采样块中每个数据之间的匹配程度,获取第一匹配集合中第一个数据与第3个采样块中每个数据之间的匹配程度大于或者等于预设阈值T的所有数据,将其记为第一匹配集合中第一个数据的匹配集合;然后再计算第一匹配集合中第二个数据与第3个采样块中每个数据之间的匹配程度,获取第一匹配集合中第二个数据与第3个采样块中每个数据之间的匹配程度大于或者等于预设阈值T的所有数据,将其记为第一匹配集合中第二个数据的匹配集合;依次遍历第一匹配集合中的每个数据,得到第一匹配集合中每个数据的匹配集合,对第一匹配集合中所有数据的匹配集合进行并运算,将得到的结果记为参考数据的第二匹配集合;
同理再根据第二匹配集合中每个数据与第4个采样块中每个数据之间的匹配程度,得到参考数据的第三匹配集合;
依次,当相邻两个采样块的两个数据之间的匹配程度没有一个大于或者等于预设阈值T时停止;
此时,则得到参考数据在每个采样块中的匹配集合。
进一步地,所述根据第一个采样块中的每个数据的所有匹配集合得到第一个采样块中的每个数据的特征强度,包括的具体步骤如下:
每个数据的特征强度的计算公式为:
式中,
进一步地,所述根据每个数据的特征强度得到明文数据中的强特征数据,包括的具体步骤如下:
当明文数据中的每个数据特征强度大于或者等于预设阈值TH时,则判定该数据为强特征数据。
进一步地,所述根据强特征数据对明文数据进行处理得到新的明文数据,包括的具体步骤如下:
将明文数据中除了强特征数据之外的所有数据记为非强特征数据;
随机生成一个盐序列,在明文数据中的所有强特征数据后面加入盐序列,得到新的明文数据;
其中,明文数据中所有非强特征数据不做改变,在明文数据中保持不变。
进一步地,所述对新的明文数据进行加密,包括的具体步骤如下:
使用密码学安全的散列函数对新的明文数据进行散列操作,生成一个不可逆的散列值,将散列值结合logistics混沌加密算法,获得新密文。
本发明的技术方案的有益效果是:本发明通过对明文数据进行下采样处理,得到若干个采样块,根据采样块中每个数据的邻域内的数据分布得到每个数据延伸系数,提高了对强特征数据获取准确性,根据数据的延伸系数得到每个数据的所有匹配集合,完成了强特征数据的筛选,根据每个数据的匹配集合得到每个数据的特征强度,根据每个数据的特征强度得到明文数据中所有的强特征数据,再根据强特征数据对明文数据进行处理,得到新的明文数据,对新的明文数据进行加密,通过对明文数据中的强特征数据后面加盐来改变强特征数据之间的位置关系,以达到弱化明文数据中强特征的效果,提高了密文数据的安全性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
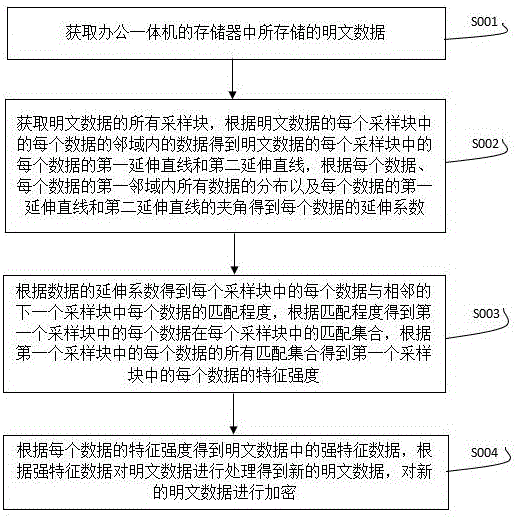
图1为本发明用于大模型一体机的数据加密安全保护方法的步骤流程图。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的用于大模型一体机的数据加密安全保护方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
下面结合附图具体的说明本发明所提供的用于大模型一体机的数据加密安全保护方法的具体方案。
在本发明中的明文数据中,其本身有强特征性,在下采样过程中,下采样的次数越多,获得的采样块中保留下来的数据具有越强的特征,因此通过下采样和采样块中数据之间的位置关系以及差异选取明文数据中的强特征数据,通过对明文数据中的强特征数据后面加盐来改变强特征数据之间的位置关系,以达到弱化明文数据中强特征的效果。
请参阅图1,其示出了本发明一个实施例提供的用于大模型一体机的数据加密安全保护方法的步骤流程图,该方法包括以下步骤:
步骤S001:获取办公一体机的存储器中所存储的明文数据。
需要说明的是,由于办公一体机内置了大容量的存储器,用于保存各种文档、扫描数据和打印任务,这些数据涉及敏感的财务信息、客户记录和商业文件,并且在传输时需要保证传输文件的防篡改和偷窥,并且实现数据备份操作,因此需要对办公一体机内的存储数据经过加密保存,避免敏感信息的丢失。
具体地,采集办公一体机的存储器中所存储的数据,其所存储的数据包含多个版式的若干个文件;将办公一体机的存储器中存储的每个文件作为明文数据。
至此,得到明文数据。
步骤S002:获取明文数据的所有采样块,根据明文数据的每个采样块中的每个数据的邻域内的数据得到明文数据的每个采样块中的每个数据的第一延伸直线和第二延伸直线,根据每个数据、每个数据的第一邻域内所有数据的分布以及每个数据的第一延伸直线和第二延伸直线的夹角得到每个数据的延伸系数。
需要说明的是,由于直接通过明文数据获取密文数据很容易被破解,导致加密后的数据安全性不高。由于办公一体机中的明文数据有着较高的频率特征,则加盐后的密文数据可以通过混沌吸引子的重构方法进行强行的破解,导致加盐后的密文数据的安全性还有待提升。
进一步需要说明的是,由于常规的加盐是在密文数据之前加盐,或者是在密文数据之后加盐的,这样加盐的方式复杂性不高,导致出现加盐之后被破解的情况。为了提高对密文数据加盐的复杂性,对明文数据进行下采样保留明文数据中的重要特征的数据,明文数据中的非强特征点在下采样过程中被平滑抹去。因此根据下采样后邻域内的数据分布关系进行分析。
具体地,预设一个下采样次数c,其中本实施例以c=10为例进行叙述,本实施例不进行具体限定,其中c可根据具体实施情况而定。通过对明文数据进行c次的下采样操作,将明文数据作为第一个采样块,对第一个采样快进行多次下采样,得到若干个采样块;将每次下采样的结果作为一个采样块。
需要说明的是,由于办公一体机中存储器所存储的数据为文本数据,在文本数据中每行的字符个数有限,也就几十个,而文本数据中可能包含几千或者几万行的数据,如果只将文本数据中每行数据作为二位平面中的一行数据,这样对文本数据进行下采样后,每行中只有一个字符或者两个字符了,而采样后的总行数依然很多,这样使得对二维平面上的每个数据的邻域中的数据进行分析时,对其结果影响很大,因此需要将文本数据中几行数据作为二维平面上的一行数据,这样就能减小对其结果的影响。
具体地,统计明文数据中行字符个数和明文数据中的所有行数,将明文数据的所有行中字符个数最多的一行的字符个数记为HS,将明文数据中的所有行数记为H,根据HS和H得到调整行数
(1)根据明文数据的每个采样块中的每个数据的邻域内的数据得到明文数据的每个采样块中的每个数据的第一延伸直线和第二延伸直线。
需要说明的是,在下采样过程中强特征点不会被抹去,而弱特征点在下采样过程中会被抹去,强特征点在明文数据中为纹理、边缘或角点,而在分析多层级之间的匹配关系时,特征点所处的边缘、纹理和角点会在舍弃非重要点的情况下,保留边缘的延伸关系,因此根据每个采样块中每个数据与邻域中数据的差异进行分析数据的重要信息。
具体地,预设一个阈值A,其中本实施例以A=5为例进行叙述,本实施例不进行具体限定,其中A可根据具体实施情况而定。以每个数据为中心点,获取
将明文数据的每个采样块中的任意一个数据记为目标数据,先获取目标数据的第二邻域,计算目标数据与对应的第二邻域内每个数据之间的差异,将与目标数据差异最小的第二邻域内的一个数据记为第一方向数据,将与目标数据差异第二小的第二邻域内的一个数据记为第二方向数据。其中,差异表示差值的绝对值,且每个数据之间的差异计算是通过十进制数进行运算的,即首先将每个字符转换为二进制数,再将二进制数转换为十进制数。其中,字符转换为二进制的数的编码方式有:ASCII编码、Unicode编码等等。
将目标数据的第二邻域内的所有数据记为标记数据,在目标数据的第一邻域内获取第一方向数据的第二邻域内的数据,将第一方向数据的第二邻域内的数据除去标记数据后剩余的数据记为第一方向数据的第三邻域,计算第一方向数据与对应的第三邻域内每个数据之间的差异,将与第一方向数据差异最小的第三邻域内的一个数据记为第三方向数据。
在目标数据的第一邻域内获取第二方向数据的第二邻域内的数据,将第二方向数据的第二邻域内的数据除去标记数据后剩余的数据记为第二方向数据的第三邻域,计算第二方向数据与对应的第三邻域内每个数据之间的差异,将与第二方向数据差异最小的第三邻域内的一个数据记为第四方向数据。
再获取目标数据、第一方向数据、第二方向数据、第三方向数据和第四方向数据的位置坐标,通过目标数据、第一方向数据和第三方向数据的位置坐标使用最小二乘法进行一次多项式拟合,将得到的直线记为第一延伸直线;通过目标数据、第二方向数据和第四方向数据的位置坐标使用最小二乘法进行一次多项式拟合,将得到的直线记为第二延伸直线。然后获取第一延伸直线和第二延伸直线的夹角,记为目标数据的延伸直线的夹角。
同理,获取明文数据的每个采样块中每个数据的第一延伸直线和第二延伸直线的夹角。
(2)根据每个数据、每个数据的第一邻域内所有数据的分布以及每个数据的第一延伸直线和第二延伸直线的夹角得到每个数据的延伸系数。
需要说明的是,由于在明文数据中,具有强特征的数据与邻域中差异较小的强特征之间的角度和越小,表明该数据越是强特征数据;当每个数据与邻域中所有数据的均值之间的差异越大,表明该数据的越是强特征数据。
具体地,根据每个数据、每个数据的第一邻域内所有数据的均值和每个数据的延伸直线的夹角得到每个数据的延伸系数,用公式表示为:
式中,
其中,当每个数据的延伸直线的夹角越小,对应的余弦值就越大,则表示该数据为强特征数据的可能性越大,当每个数据与邻域中所有数据的均值之间的差异越大,则表示该数据为强特征数据的可能性越大。
至此,得到明文数据的每个采样块中每个数据的延伸系数。
步骤S003:根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度,根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合,根据第一个采样块中的每个数据的所有匹配集合得到第一个采样块中的每个数据的特征强度。
(1)根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度。
需要说明的是,明文数据在下采样的过程中会保留特征点,因此若在第
具体地,根据数据的延伸系数得到每个采样块中的每个数据与相邻的下一个采样块中每个数据的匹配程度,用公式表示为:
式中,
其中,
至此,得到两个数据之间的匹配程度。
(2)根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合。
预设一个阈值T,其中本实施例以T=0.78为例进行叙述,本实施例不进行具体限定,其中T可根据具体实施情况而定。根据匹配程度得到第一个采样块中的每个数据在每个采样块中的匹配集合的具体过程为:
将第一采样块中的任意一个数据记为参考数据,计算参考数据与第2个采样块中每个数据之间的匹配程度,获取参考数据与第2个采样块中每个数据之间的匹配程度大于或者等于预设阈值T的所有数据,组成参考数据的第一匹配集合;
从第一匹配集合中的第一个数据开始,依次遍历第一匹配集合中的每个数据,计算第一匹配集合中第一个数据与第3个采样块中每个数据之间的匹配程度,获取第一匹配集合中第一个数据与第3个采样块中每个数据之间的匹配程度大于或者等于预设阈值T的所有数据,将其记为第一匹配集合中第一个数据的匹配集合;然后再计算第一匹配集合中第二个数据与第3个采样块中每个数据之间的匹配程度,获取第一匹配集合中第二个数据与第3个采样块中每个数据之间的匹配程度大于或者等于预设阈值T的所有数据,将其记为第一匹配集合中第二个数据的匹配集合;依次遍历第一匹配集合中的每个数据,得到第一匹配集合中每个数据的匹配集合,对第一匹配集合中所有数据的匹配集合进行并运算,将得到的结果记为参考数据的第二匹配集合;
同理再根据第二匹配集合中每个数据与第4个采样块中每个数据之间的匹配程度,得到参考数据的第三匹配集合;
依次,当相邻两个采样块的两个数据之间的匹配程度没有一个大于或者等于预设阈值T时停止;
此时,则得到参考数据在每个采样块中的匹配集合。
至此,得到第一采样块中每个数据在每个采样块中的匹配集合。
(3)根据第一个采样块中的每个数据的所有匹配集合得到第一个采样块中的每个数据的特征强度。
需要说明的是,由于下采样过程是一个数据逐渐减少的过程,因此下采样后的一个数据表征原先的多个数据,又因为每个数据的所有匹配集合是通过相邻采样块之间的差异进行匹配的,即这些数据之间有很大的相似性,因此可以根据每个数据的所有匹配集合来分析每个数据的强弱特征。
具体地,根据每个数据的所有匹配集合得到每个数据的特征强度,用公式表示为:
式中,
其中,当每个数据的所有匹配集合中的数据总个数越小,每个数据的所有匹配集合个数越多时,表明该数据的特征强度越大,即该数据越为强特征数据;当每个数据的所有匹配集合中的数据总个数越大,每个数据的所有匹配集合个数越少时,表明该数据的特征强度越小,即该数据越为弱特征数据。
至此,得到明文数据中每个数据的特征强度。
步骤S004:根据每个数据的特征强度得到明文数据中的强特征数据,根据强特征数据对明文数据进行处理得到新的明文数据,对新的明文数据进行加密。
需要说明的是,为了提高数据的安全性,在明文数据中进行加盐操作,得到加盐后的明文数据,在对加盐后的明文数据进行加密操作。
预设一个阈值TH,其中本实施例以TH=0.68为例进行叙述,本实施例不进行具体限定,其中TH可根据具体实施情况而定。当明文数据中的每个数据特征强度大于或者等于预设阈值TH时,则判定该数据为强特征数据;当明文数据中的每个数据特征强度小于预设阈值TH时,则判定该数据为弱特征数据。
将明文数据中除了强特征数据之外的所有数据记为非强特征数据;随机生成一个盐序列,在明文数据中的所有强特征数据后面加入盐序列,得到新的明文数据;其中,明文数据中所有非强特征数据不做改变,在明文数据中保持不变。
使用密码学安全的散列函数对新的明文数据进行散列操作,生成一个不可逆的散列值,将散列值结合logistics混沌加密算法,获得新密文。其中,本实施例中的散列函数使用SHA-256,本实施例不进行具体限定。
至此,本实施例完成。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种固体废弃物筛分处理装置及固体废弃物高效处理方法
- 一种固体废弃物分离处理装置及固体废弃物综合处理方法
- 一种医疗一次性用品处理装置
- 一种用于环保的一次性筷子回收处理装置
- 一种一次性固体医疗器械处理装置
- 一种一次性固体医疗器械处理装置