有害音频识别解码方法及装置
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及一种有害音频识别解码方法及装置,属于音频识别技术领域。
背景技术
而目前大量的有害音频文件意图会被刻意的伪装,与有害音频有关的名词及采取的各类活动会借用其它词来替代,仅从字面上理解是很难与有害活动关联起来的,导致有害音频这类正例样本难以收集。相对海量的音频文件,有害音频的数量几乎可以忽略不计,而且需要大量有专业经验的Z察人员从海量音频数据中人工进行甄别、筛选,耗时长且工作量大,样本获取难度大。基于网络安全监管的需要,急需设计有害音频识别解码方法和装置方案解决有害音频文件的识别解码。
发明内容
本发明的目的在于,克服现有技术存在的技术缺陷,解决上述技术问题,提出有害音频识别解码方法及装置。
本发明具体采用如下技术方案:有害音频识别解码方法,包括:
获取待识别音频数据,提取待测音频中的声学特征,对所述声学特征进行有效音频检测得到有效音频段;
将所述有效音频段输入到有害音频分类网络模型,从文本意图的角度对待测样本进行分类,输出文本集合分类结果;
将所述文本集合分类结果输入声学模型中输出解码结果。
作为一种较佳的实施例,所述有害音频分类网络模型的训练方法如下:
设计一个大数据量的意图分类网络称之为基分类器g(x;θ),设计一个参数回归映射网络F(.);给定大数据量的意图分类网络k-shot的标注样本,进行普通的分类训练,得到参数θ
通过构建元学习的目标函数,获取大数据量的意图分类网络参数更新过程,来指导小样本(V
作为一种较佳的实施例,所述将所述文本集合分类结果输入声学模型中输出解码结果具体包括:
将所述文本集合分类结果分别输入各个环境无关的声学模型中得到各个声学模型的第一轮解码结果;结合所述文本集合分类结果、所述第一轮解码结果以及各个不同声学单元的声学模型进行环境自适应分别得到对应的各个不同声学单元的环境自适应后的声学模型;使用所述各个不同声学单元的环境自适应后的声学模型对所述文本集合分类结果分别解码,得到第二轮解码结果;对所述第二轮解码结果使用投票的方法以得到最终解码结果。
作为一种较佳的实施例,所述进行环境自适应包括:
冻结环境无关的声学模型的全部参数,在所述环境无关的声学模型的第一个隐层后添加一个线性缩放层,初始化参数包括设置为1;
使用CTC准则对所述线性缩放层进行优化,其中,优化后的模型即为针对测试环境自适应后的声学模型。
作为一种较佳的实施例,所述声学模型包括单音素声学模型、三音素声学模型和字符声学模型;
所述对所述第二轮解码结果使用投票的方法以得到最终解码结果包括:将所述单音素声学模型的第二轮解码结果和所述三音素声学模型的第二轮识别结果进行对齐得到第一对齐序列;将所述第一对齐序列与所述字符声学模型的第二解码结果进行对齐得到第二对齐序列;基于所述第二对齐序列在各个声学模型的第二轮结果上进行投票,得到最终解码结果。
本发明还提出有害音频识别解码装置,包括:
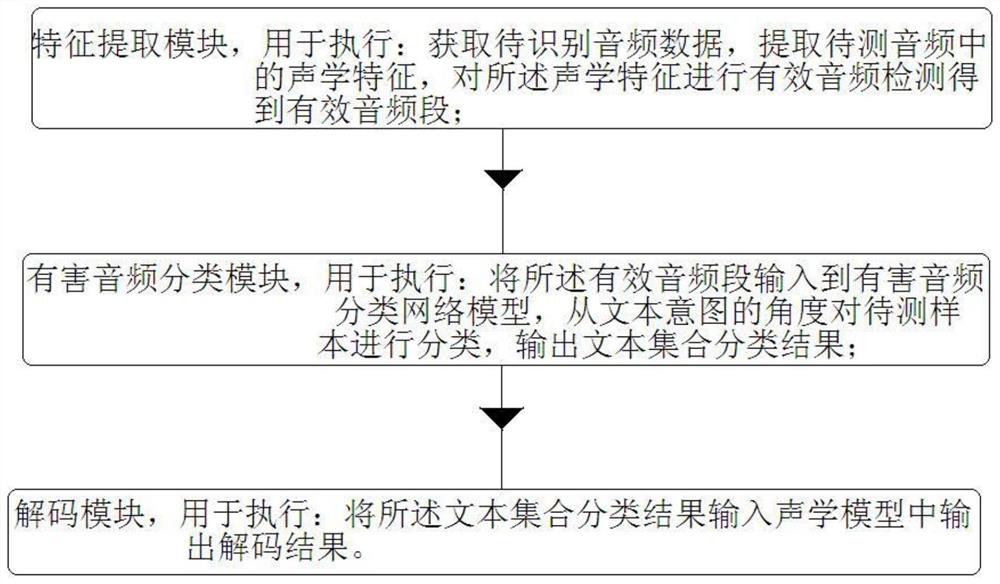
特征提取模块,用于执行:获取待识别音频数据,提取待测音频中的声学特征,对所述声学特征进行有效音频检测得到有效音频段;
有害音频分类模块,用于执行:将所述有效音频段输入到有害音频分类网络模型,从文本意图的角度对待测样本进行分类,输出文本集合分类结果;
解码模块,用于执行:将所述文本集合分类结果输入声学模型中输出解码结果。
作为一种较佳的实施例,所述有害音频分类网络模型的训练方法如下:
设计一个大数据量的意图分类网络称之为基分类器g(x;θ),设计一个参数回归映射网络F(.);给定大数据量的意图分类网络k-shot的标注样本,进行普通的分类训练,得到参数θ
通过构建元学习的目标函数,获取大数据量的意图分类网络参数更新过程,来指导小样本(V
作为一种较佳的实施例,所述将所述文本集合分类结果输入声学模型中输出解码结果具体包括:
将所述文本集合分类结果分别输入各个环境无关的声学模型中得到各个声学模型的第一轮解码结果;结合所述文本集合分类结果、所述第一轮解码结果以及各个不同声学单元的声学模型进行环境自适应分别得到对应的各个不同声学单元的环境自适应后的声学模型;使用所述各个不同声学单元的环境自适应后的声学模型对所述文本集合分类结果分别解码,得到第二轮解码结果;对所述第二轮解码结果使用投票的方法以得到最终解码结果。
作为一种较佳的实施例,所述进行环境自适应包括:
冻结环境无关的声学模型的全部参数,在所述环境无关的声学模型的第一个隐层后添加一个线性缩放层,初始化参数包括设置为1;
使用CTC准则对所述线性缩放层进行优化,其中,优化后的模型即为针对测试环境自适应后的声学模型。
作为一种较佳的实施例,所述声学模型包括单音素声学模型、三音素声学模型和字符声学模型;
所述对所述第二轮解码结果使用投票的方法以得到最终解码结果包括:将所述单音素声学模型的第二轮解码结果和所述三音素声学模型的第二轮识别结果进行对齐得到第一对齐序列;将所述第一对齐序列与所述字符声学模型的第二解码结果进行对齐得到第二对齐序列;基于所述第二对齐序列在各个声学模型的第二轮结果上进行投票,得到最终解码结果。
本发明所达到的有益效果:本发明针对如何解决目前大量的有害音频文件意图会被刻意的伪装,与有害音频有关的名词及采取的各类活动会借用其它词来替代,仅从字面上理解是很难与有害活动关联起来的,导致有害音频这类正例样本难以收集的技术需求,通过设计一种有害音频识别解码方法,获取待识别音频数据,提取待测音频中的声学特征,对所述声学特征进行有效音频检测得到有效音频段;将所述有效音频段输入到有害音频分类网络模型,从文本意图的角度对待测样本进行分类,输出文本集合分类结果;将所述文本集合分类结果输入声学模型中输出解码结果,通过构建元学习的目标函数,获取大数据量的意图分类网络参数更新过程,来指导小样本(V
附图说明
图1是本发明的有害音频识别解码装置的拓扑原理示意图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
实施例1:本发明提出有害音频识别解码方法,包括:
获取待识别音频数据,提取待测音频中的声学特征,对所述声学特征进行有效音频检测得到有效音频段;
将所述有效音频段输入到有害音频分类网络模型,从文本意图的角度对待测样本进行分类,输出文本集合分类结果;
将所述文本集合分类结果输入声学模型中输出解码结果。
作为一种较佳的实施例,所述有害音频分类网络模型的训练方法如下:
设计一个大数据量的意图分类网络称之为基分类器g(x;θ),设计一个参数回归映射网络F(.);给定大数据量的意图分类网络k-shot的标注样本,进行普通的分类训练,得到参数θ
通过构建元学习的目标函数,获取大数据量的意图分类网络参数更新过程,来指导小样本(V
作为一种较佳的实施例,所述将所述文本集合分类结果输入声学模型中输出解码结果具体包括:
将所述文本集合分类结果分别输入各个环境无关的声学模型中得到各个声学模型的第一轮解码结果;结合所述文本集合分类结果、所述第一轮解码结果以及各个不同声学单元的声学模型进行环境自适应分别得到对应的各个不同声学单元的环境自适应后的声学模型;使用所述各个不同声学单元的环境自适应后的声学模型对所述文本集合分类结果分别解码,得到第二轮解码结果;对所述第二轮解码结果使用投票的方法以得到最终解码结果。
作为一种较佳的实施例,所述进行环境自适应包括:
冻结环境无关的声学模型的全部参数,在所述环境无关的声学模型的第一个隐层后添加一个线性缩放层,初始化参数包括设置为1;
使用CTC准则对所述线性缩放层进行优化,其中,优化后的模型即为针对测试环境自适应后的声学模型。
作为一种较佳的实施例,所述声学模型包括单音素声学模型、三音素声学模型和字符声学模型;
所述对所述第二轮解码结果使用投票的方法以得到最终解码结果包括:将所述单音素声学模型的第二轮解码结果和所述三音素声学模型的第二轮识别结果进行对齐得到第一对齐序列;将所述第一对齐序列与所述字符声学模型的第二解码结果进行对齐得到第二对齐序列;基于所述第二对齐序列在各个声学模型的第二轮结果上进行投票,得到最终解码结果。
实施例2:如图1所示,本发明提出有害音频识别解码装置,包括:
特征提取模块,用于执行:获取待识别音频数据,提取待测音频中的声学特征,对所述声学特征进行有效音频检测得到有效音频段;
有害音频分类模块,用于执行:将所述有效音频段输入到有害音频分类网络模型,从文本意图的角度对待测样本进行分类,输出文本集合分类结果;
解码模块,用于执行:将所述文本集合分类结果输入声学模型中输出解码结果。
可选的,所述有害音频分类网络模型的训练方法如下:
设计一个大数据量的意图分类网络称之为基分类器g(x;θ),设计一个参数回归映射网络F(.);给定大数据量的意图分类网络k-shot的标注样本,进行普通的分类训练,得到参数θ
通过构建元学习的目标函数,获取大数据量的意图分类网络参数更新过程,来指导小样本(V
可选的,所述将所述文本集合分类结果输入声学模型中输出解码结果具体包括:
将所述文本集合分类结果分别输入各个环境无关的声学模型中得到各个声学模型的第一轮解码结果;结合所述文本集合分类结果、所述第一轮解码结果以及各个不同声学单元的声学模型进行环境自适应分别得到对应的各个不同声学单元的环境自适应后的声学模型;使用所述各个不同声学单元的环境自适应后的声学模型对所述文本集合分类结果分别解码,得到第二轮解码结果;对所述第二轮解码结果使用投票的方法以得到最终解码结果。
可选的,所述进行环境自适应包括:
冻结环境无关的声学模型的全部参数,在所述环境无关的声学模型的第一个隐层后添加一个线性缩放层,初始化参数包括设置为1;
使用CTC准则对所述线性缩放层进行优化,其中,优化后的模型即为针对测试环境自适应后的声学模型。
可选的,所述声学模型包括单音素声学模型、三音素声学模型和字符声学模型;
所述对所述第二轮解码结果使用投票的方法以得到最终解码结果包括:将所述单音素声学模型的第二轮解码结果和所述三音素声学模型的第二轮识别结果进行对齐得到第一对齐序列;将所述第一对齐序列与所述字符声学模型的第二解码结果进行对齐得到第二对齐序列;基于所述第二对齐序列在各个声学模型的第二轮结果上进行投票,得到最终解码结果。本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 有害音频识别解码方法及装置
- 音频识别解码方法和装置