一种基于神经网络激活分布的可重构近似乘累加单元
文献发布时间:2024-04-18 19:53:33
技术领域
本发明涉及MAC(Multiplicative accumulation,乘累加)单元领域,尤其是一种基于神经网络激活分布的可重构近似乘累加单元。
背景技术
神经网络的高计算需求给嵌入式系统带来了严重的性能瓶颈和关键的功耗。神经网络在推理过程中的核心是MAC(乘累加)操作,先进的神经网络集成了数千个MAC。使得能源消耗巨大。以前的近似MAC大部分都为无符号乘数而设计,因此,在计算有符号或不均匀分布数据时精度不高。
神经网络权重的分布都遵循高斯分布,激活的分布遵循类高斯分布。在这之前,有一部分工作考虑了输入的权重分布,但没考虑激活的分布。有一部分工作考虑了激活的分布,但却没有与booth乘法器以及近似压缩的特性结合起来。
radix-8 booth乘法器相比以往的有符号乘法器会生成更少的部分积,因此会带来更少的延迟,并且radix-8 booth乘法器中偶数倍的部分积生成可以通过位移实现,但与普通的有符号乘法器相比,radix-8 booth在部分积生成器中会产生奇数倍的部分积,这会导致更多的功耗。
发明内容
发明目的:提供一种基于神经网络激活分布的可重构近似乘累加单元,以解决现有技术存在的上述问题。
技术方案:一种基于神经网络激活分布的可重构近似乘累加单元,包括:
乘法模块,包括:
编码器,将神经网络的激活输入和权重输入进行radix-8 booth编码,生成对应的部分积选择信号;
部分积生成器,根据部分积选择信号,生成部分积;
第一加法器,将部分积按照从上到下的顺序进行累加,得到乘法结果;
加法模块,包括:
分类器,根据所述乘法结果的高位进行分类,若乘法结果的高位不全为0,则分类为大数;若乘法结果的高位全为0,则分类为小数;
压缩器,将大数进行精确压缩,将小数进行近似压缩;
第二加法器,将压缩结果通过第二加法器相加,得到卷积结果。
根据本申请的一个方面,所述部分积生成器包括精确部分积生成器和近似部分积生成器,具体为:
当输入激活的高位全部为0时,在近似部分积生成器中采用近似编码的方式生成权重较高的后几行部分积;当输入激活的高位不是全为0时,在精确部分积生成器中采用精确编码的方式生成权重较高的后几行部分积,采用近似编码的方式生成权重较低的前几行部分积。
根据本申请的一个方面,所述压缩器包括:3-2压缩器,用于精确压缩;4-2压缩器,用于近似压缩。
根据本申请的一个方面,所述第二加法器为超前进位加法器。
根据本申请的一个方面,还包括使用低位宽整数或定点数来表示所述激活输入和权重输入。
根据本申请的一个方面,还包括生成对抗网络或变分自编码器,具体为使用生成对抗网络或变分自编码器对所述卷积结果进行后处理,用于增强视觉效果。
有益效果:本发明在不损失太多精度的前提下有效地减少神经网络中计算单元的功耗和延时,并且能够动态的适应不同的网络类型,有着良好的实际应用价值。
附图说明
图1是卷积神经网络的权重分布示意图。
图2是卷积神经网络的激活分布示意图。
图3是本发明的乘法器编码示意图。
图4是本发明的乘法器结构示意图。
图5是本发明的加法器结构示意图。
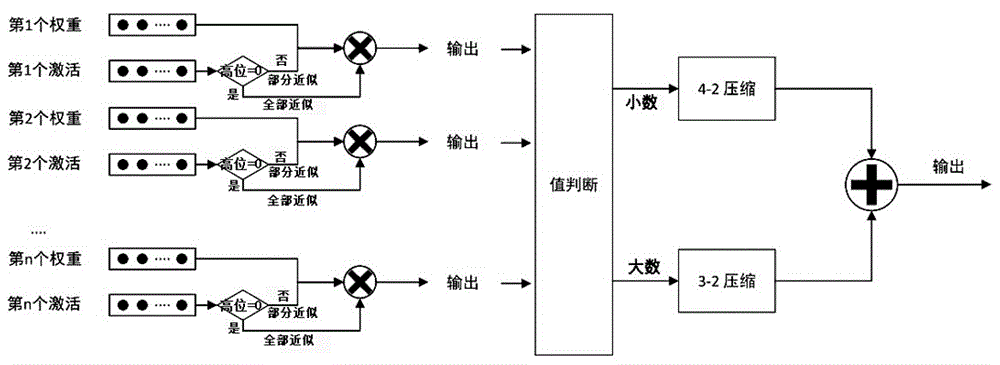
图6是本发明的MAC单元结构示意图。
图7是卷积神经网络的推理精度计算公式示意图。
图8是本发明在不同网络下测试的推理精度示意图。
图9本发明与精确乘累加单元的仿真功耗与面积对比示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明进行详细的说明。
如图1和图2所示的是较常见的神经网络中16bit量化的权重和激活分布示意图,不难看出,神经网络中的权重遵循高斯分布;激活值全为正,也同样遵循类高斯分布,因此所有激活输入的最高位均为0,并且激活最高的3位出现1的概率不到20%,本发明针对这一特性对传统的radix-8 booth乘法器和加法器做出了改进。传统的radix-8 booth乘法器通过编码表产生对应数量的部分积并从上到下形成部分积树,最终进行累加。
在本发明中,具体包括乘法模块和加法模块,其中乘法模块包括:
编码器,将神经网络的激活输入和权重输入进行radix-8 booth编码,生成对应的部分积选择信号;
部分积生成器,根据部分积选择信号,生成部分积;
第一加法器,将部分积按照从上到下的顺序进行累加,得到乘法结果。
所述部分积生成器包括精确部分积生成器和近似部分积生成器,具体为当输入激活的高位全部为0时,在近似部分积生成器中采用近似编码的方式生成权重较高的后几行部分积;当输入激活的高位不是全为0时,在精确部分积生成器中采用精确编码的方式生成权重较高的后几行部分积,采用近似编码的方式生成权重较低的前几行部分积。
在乘法模块中根据神经网络的激活输入分布调整乘法器的结构,神经网络的特性是可以容忍较小的错误,因此本发明先通过高位判断激活的相对大小,再决定用近似还是精确的方式生成高权重的部分积,这可以在减少功耗的同时又能保证较高的精度。
本发明的乘法模块充分考虑到了神经网络的激活输入分布特性,通过神经网络的激活输入特征生成对应的乘法器单元,在其乘法器模块中设有编码器、部分积生成器和加法器;在部分积生成器中设有可重构的精确部分积生成器和近似部分积生成器,部分积生成器可以根据输入的激活大小,动态地调整近似部分积的行数,由于将精确radix-8 booth乘法器的前几行部分积进行近似编码,对最终的推理精度几乎不会造成影响,因此本发明主要考虑了radix-8 booth乘法器中占权重较高的最后几行部分积;并将输入激活的大小与部分积树中的后几行部分积的近似情况关联了起来,当输入激活较小时,激活的高位全部为0,此时便可以将权重较高的后几行部分积全部采用近似编码的方式生成,当输入激活较大时,将权重较高的后几行部分积全部采用精确编码的方式生成,将权重较低的前几行部分积采用近似编码的方式生成。
本发明的乘法模块还可以根据网络的不同或激活输入的不同灵活的调整近似或者精确的工作模式,因此可以同时适应任意规模的网络。
加法模块包括:
分类器,根据所述乘法结果的高位进行分类,若乘法结果的高位不全为0,则分类为大数;若乘法结果的高位全为0,则分类为小数;
压缩器,将大数进行精确压缩,将小数进行近似压缩;所述压缩器包括:3-2压缩器,用于精确压缩;4-2压缩器,用于近似压缩。
超前进位加法器,将压缩结果通过超前进位加法器相加,得到卷积结果。
本发明在加法模块中设有3-2压缩器(全加器)和近似4-2压缩器,根据乘法结果的数据大小将其进行分类,将大数进行3-2压缩,将小数进行4-2压缩,最终将压缩结果通过超前进位加法器合成为最后的卷积结果。这样可以较好的实现功耗、延时与精度之间的平衡。
进一步的还包括使用低位宽整数或定点数来表示所述激活输入和权重输入。使用8位整数或定点数来表示激活输入和权重输入,那么相比于使用32位浮点数,可以节省75%的存储空间和计算资源。这样可以减少存储空间和计算复杂度,提高运算效率和节省能耗。
进一步的还包括生成对抗网络或变分自编码器,具体为使用生成对抗网络或变分自编码器对所述卷积结果进行后处理。使用生成对抗网络对卷积结果进行去噪处理,那么可以利用生成器和判别器之间的对抗学习,生成更接近真实图像的去噪结果;使用变分自编码器对卷积结果进行去噪处理,可以利用编码器和解码器之间的重构误差和隐变量的先验分布,生成更具有结构信息和纹理细节的去噪结果。这样可以增强视觉效果,提高图像质量和还原度。
在进一步的实施例中,如图3所示的是本发明的radix-8 booth乘法器编码示意图,该乘法器模块对经典的radix-8 booth乘法器编码做出了改进,在radix-8 booth乘法器编码中,输入D使用重叠的四位(di+2, di+1, di, di-1)分组。并从所示的集合(±4C,±3C±2C,±C或±0)中选择相应的部分积。需要注意的是,计算±3C的乘数与其它相比会带来更高的延迟和能耗;因此本发明借鉴了现有工作的近似方法,将±3C近似为最接近的±2C,在激活输入遵循类高斯分布的前提下,这种近似方法带来的误差可以相互抵消。
在进一步的实施例中,如图4所示,是本发明的乘法器模块示意图,以16bit乘累加单元为例,该乘法器模块对经典的radix-8 booth乘法器模块做出了改进。由于神经网络的激活输入全为整数,且遵循类高斯分布,因此激活的最高位Msb全部为0,且第二最高位Smsb和第三最高位Tmsb为1的概率不足20%,因此本发明按照图右侧的编码分组,通过激活的第15位判断是否生成部分积树中权重最大的那一列部分积即最下面一行的部分积,并将激活的第15位和14位进行或逻辑判断,如果输出为0,那么证明该激活是一个较小的数,会带来较小的误差,因此该激活的第五行部分积也可以使用图3的近似编码APP-PP
在进一步的实施例中,如图5所示的是本发明的加法器模块示意图,该加法器模块采用了分类压缩模块,通过加数的第32位和31位是否为零判断该乘法结果是较大的数还是较小的数,较大的加数采用3-2精确压缩,较小的加数采用4-2近似压缩,最终的3-2压缩和4-2压缩结果通过超前进位加法器相加,作为卷积的输出结果。
在进一步的实施例中,如图6所示的是本发明的总体模块示意图,激活和权重在本发明的近似乘法器中先进行高位的数值判断,若为0则全部采用近似方法生成部分积,若不为0则权值较大的最后几行部分积采用精确方法生成,在将部分积进行求和后得到乘法结果,然后送进入加法器进行高位的数值判断,若高位全为0则送入带有误差的4-2压缩器,若高位不全为0则送入无误差的3-2压缩器,反复压缩直至两行结果(分别为当前和和进位输出),最后将两个压缩器输出的共四行结果使用超前进位加法器cla进行相加,求得卷积的最终结果。
如图7所示的是本发明用于神经网络推理的精度Accurate的计算公式,其可表示为在近似计算模式下推理的正确率与在精确计算模式下推理的正确率的比值,其中推理正确率可用推理正确的图片数量除以输入的图片总数量计算。
如图8和图9所示的是本发明和精确乘累加单元的精度、功耗和面积结果对比,本发明选择了一个小规模的神经网络Alexnet和一个大规模的网络VGG16测试16bit的乘法器,近似的行数设置为2行,即根据输入激活的高位判断最后两行是否使用近似技术生成,测试数据集为cifar10。可以看出,此近似乘累加单元在两个网络下均以将近1%的精度为代价换取了21.3%面积节省和31.7%的功耗节省。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
- 一种航空发动机中压气机转子平衡结构及其方法
- 一种航空发动机中压气机串列转子叶片装配结构及其方法