车机系统、用于其的数据传输方法和包括其的车辆
文献发布时间:2024-01-17 01:15:20
技术领域
本申请涉及车辆中的数据传输领域,具体地涉及基于串口的数据传输。
背景技术
在车辆与用户的交互过程中,车辆的指令响应速度直接影响用户的使用感受。例如,在用户调用车辆的某项功能(例如,车速更新、空调风量调整、转向灯开启)时,期望车辆能够对用户的指令快速、流畅地做出反应,而不会出现卡顿。
相关技术中,车辆的车载系统通常包括多个处理器,在多个处理器之间可以相互通信联接,以进行数据交换。例如,在外部设备(例如,与车辆总线物理连接的单片机MCU)与上层车机系统的CPU之间,处理器之间的数据传输大多采用FIFO模式。
在FIFO的工作模式下,例如,在使用串口通信的情况下,CPU从串行接口直接读取串口数据以进行数据处理。即,只要车机系统的串行接口从外部设备(例如,单片机MCU)接收到数据,便被CPU读走。
通常,CPU可以通过中断方式实现串口数据的接收和发送。然而,在FIFO的工作模式下,CPU需要一个字节一个字节地从串行接口读取数据,这也就意味着,每接收一个字节的数据就需要向CPU发送一次中断请求。这样使得CPU处理中断非常频繁,大量占用了CPU资源,从而大幅度降低车载系统的运行效率。
发明内容
本申请的一个目的在于提供一种基于Linux内核的车机系统的车机系统的数据传输方法,其优势在于通过该方法可以有效改善串口数据传输的实时性,防止出现明显的不期望的交互卡顿现象。
本申请的另一个目的在于提供一种基于Linux内核的车机系统,其优势在于该车机系统可以有效改善串口数据传输的实时性,防止出现明显的不期望的交互卡顿现象。
本申请的另一个目的在于提供一种包括上述基于Linux内核的车机系统的车辆,其优势在于该车辆可以有效减少出现明显的不期望的交互卡顿现象。
本发明的其它优势和特点通过下述的详细说明得以充分体现并可通过所附权利要求中特地指出的手段和装置的组合得以实现。
根据本申请的第一方面,提供了一种用于基于Linux内核的车机系统的数据传输方法。该方法包括:将车机系统初始化为DMA模式;响应于接收到串口数据,将串口数据暂存至DMA控制器并且检测DMA控制器的状态;以及响应于检测到DMA控制器处于空闲状态或读满状态,从DMA控制器向车机系统的主处理器传输串口数据。
在实施方式中,所述方法还包括:响应于接收到串口数据,在将串口数据暂存至DMA控制器之前,基于Linux内核唤醒串口任务。
在实施方式中,所述方法还包括:对串口任务赋予校验标志,以及其中,基于Linux内核唤醒串口任务包括:响应于检测到校验标志,调整Linux调度的就绪队列,使得串口任务处于就绪队列之首。
在实施方式中,响应于暂存在DMA控制器中的串口数据的大小在预定时间内没有改变,则确定DMA控制器处于空闲状态。
在实施方式中,预定时间处于1至50微秒的范围内。
在实施方式中,响应于暂存在DMA控制器中的串口数据的大小达到预定值,则确定DMA控制器处于读满状态。
在实施方式中,所述方法还包括:从外围设备接收到串口数据,以及其中,外围设备包括车载的MCU,以及串口数据对应于MCU从车辆总线获取的车辆硬件数据。
根据本申请的第二方面,提供了一种基于Linux内核的车机系统。所述车机系统包括:处理器;串口通信器,接收串口数据,DMA控制器,与串口通信器进行数据通信,以及DMA状态监测器,与DMA控制器和处理器连接。处理器配置成:响应于接收到串口数据,处理器控制DMA控制器从串口通信器读取并暂存串口数据,并且控制DMA状态监测器实时监测DMA控制器的状态;以及响应于确定DMA控制器处于空闲状态或读满状态,从DMA控制器接收串口数据。
在实施方式中,处理器还配置成:控制DMA控制器从串口通信器读取并暂存串口数据之前,基于Linux内核唤醒串口任务。
在实施方式中,处理器还配置成:对串口任务赋予校验标志;以及响应于检测到校验标志,调整Linux调度的就绪队列,使得串口任务处于就绪队列之首。
在实施方式中,处理器还配置成:响应于暂存在DMA控制器中的串口数据的大小在预定时间内没有改变,则确定DMA控制器处于空闲状态。
在实施方式中,预定时间处于1至50微秒的范围内。
在实施方式中,处理器还配置成:响应于暂存在DMA控制器中的串口数据的大小达到预定值,则确定DMA控制器处于读满状态。
在实施方式中,串口通信器从外围设备接收串口数据,以及其中,外围设备包括车载的MCU,以及串口数据对应于MCU从车辆总线获取的车辆硬件数据。
根据本申请的第三方面,还提供了一种包括基于Linux内核的车机系统的车辆。
与本领域的相关技术相比,本申请具有下列至少一个技术效果:
1)通过DMA控制器的使用,可以在很大程度上减轻CPU资源占有率,大大节省系统资源;
2)通过修改Linux内核层对串口进程的调度方式,可以显著减少数据搬运等待时间,例如可以从毫秒级别缩减至微秒级别,从而有效改善串口数据传输的实时性;
3)基于调度策略的改变以及校验标志的设置,实质上并没有修改UART进程/线程的优先级,所以并不会导致没有串口数据的情况下,影响正常的CPU调度,并没有平白占用CPU资源;以及
4)用户在调用车辆的任何功能时,车辆可以根据用户的指令流畅、快速地做出反应,有效避免了在交互过程中出现明显的、不期望的交互卡顿现象。
附图说明
通过参照附图详细描述本公开的实施方式,本公开的以上和其它实施方式和特征将变得更加显而易见,在附图中:
图1是示出了根据示例性实施方式的车辆的车载系统的示意性结构图;
图2是示出了根据对比性实施方式的利用DMA模式进行串口数据传输方法的示意性流程图;
图3是示出了根据本申请的实施方式的利用DMA模式进行串口数据传输方法的示意性流程图;
图4是示出了根据本申请的实施方式的图3中的方法2000的更具体的流程图;以及
图5是示出了确定是否满足向CPU搬运数据的条件的步骤S230的示意性流程图。
具体实施方式
现将参照附图在下文中更全面地描述本发明,在附图中示出了本发明的实施方式。然而,本发明可以以不同的形式来实现,并且不应被解释为限于本文中阐述的实施方式。相反,提供这些实施方式是为了使本公开将是透彻且完整的,并且将向本领域的技术人员充分地传达本发明的范围。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本申请的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。
本技术领域技术人员可以理解,除非另外限定,这里使用的所有术语(包括技术术语和科学术语),具有与本申请所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像本申请实施例中一样被特定定义,否则不会用理想化或过于正式的含义来解释。
图1是示出了根据示例性实施方式的车辆的车载系统的示意性结构图。
如图1中所示,根据示例性实施方式的车载系统100可以包括:车辆总线10、包括微控制单元MCU的下位机装置20、以及包括一个或多个处理器(例如,CPU)的上位机装置30。
在示例性实施方式中,车辆总线10可以捕获通过用户交互而产生的车辆硬件信息,诸如车速变化、转向灯开启和显示、空调风量调整等,并且可以将其传输至下位机装置20。例如,下位机装置20可以与车辆总线10物理联接。
示例性地,车辆总线10可以是基于CAN通信协议的CAN总线,并且所捕获的车辆硬件信息可以以CAN报文的形式传输给下位机装置20。
另外,下位机装置20可以将从车辆总线10接收的车辆硬件信息传输给上位机装置30。上位机装置30接收到车辆硬件信息之后,可以对车辆硬件信息进行处理分析,并驱动相应的车辆子系统执行动作。
在本文中,上位机装置30也可被称为车机系统,其是对整个车辆的各个子系统的功能进行调度管控的主机部分,并且可以包括显示器、语音系统等,来提供与用户进行直观交互的接口。例如,用户可以通过显示屏幕向车辆下达操作指令,也可通过显示屏幕获取各种车辆信息,例如与来自下位机装置20的车辆硬件信息对应的信息。
示例性地,以车速变化为例,当车辆速度发生改变(例如由于用户执行刹车动作而使得车辆减速)时,车辆变化信息通过车辆总线10传输至下位机装置20,并经由下位机装置20进行特定数据转化后传输至上位机装置30,并且通过上位机装置30进行解析后在仪表盘或显示屏幕上实时更新当前的最新车速。在该应用场景下,一旦上位机装置30与下位机装置20之间的数据传输发生较长时间的延迟(例如,毫秒级别的延迟),便会在更新车辆时速时产生明显卡顿,由此带来较差的用户体验。因而,通常要求在上位机装置30与下位机装置20的数据传输具有较高的实时性。
根据本申请的实施方式,上位机装置30可以使用基于Linux内核的安卓(Android)车载系统,并且其上可以集成有各种应用程序。Android系统可以采用分层的架构,例如可以划分为四层,从高到低分别是应用层、应用框架层、系统运行层和Linux内核层。其中,应用层可以包括用java语言编写的运行在虚拟机上的应用程序;应用框架层是用来支持应用层中的程序的运行的框架层,其可以提供构建应用程序时可能用到的各种API;系统运行库层可以提供用于支持各个组件使用的C/C++库;以及Linux内核层可以包括进程调度、内存管理、虚拟文件系统、网络接口和进程间通信五个子系统,并且可以实现硬件底层驱动,并且还可以实现对多进程的控制、管理和调度等。
然而,在其他示例性实施方式中,上位机装置30不限于在本文中作为示例的Android系统,其可以是基于Linux内核的任何其它操作系统。
示例性地,可以采用串口通信的方式来实现下位机装置20和上位机装置30之间的数据交互。串口通信方式是指串口按位(bit)发送和接收字节的通信方式,其可以将接收来自CPU的并行数据字符转换为连续的串行数据流发送出去,同时可将接收的串行数据流转换为并行的数据字符供给CPU。
根据示例性实施方式,下位机装置20和上位机装置30可以分别包括具有相同类型和配置以进行数据交互的第一串口通信器210和第二串口通信器310。
示例性地,第一串口通信器210和第二串口通信器310可以实现为通用异步收发传输器(UART)。然而,这仅是示例,本申请对串口通信的形式不作具体限制。仅出于描述的便利,在下文中以串口通信器为UART的情况为例进行描述。
如前所述,在单片机MCU(对应于下位机装置20)与上层车机系统(对应于上位机装置30)的串口通信模式设置为FIFO模式的情况下,CPU一直在从串口通信器读取数据,CPU资源被串口线程长期占用,CPU在此期间无法处理其他事务。由此,FIFO工作模式虽然可以保证数据传输实时性,但同时也牺牲了CPU一部分的处理性能。
为解决以上问题,根据本申请的实施方式,采用DMA模式来代替FIFO模式进行串口数据传输。DMA是Direct Memory Access的缩写,也称为“直接内存访问”。在DMA模式下,CPU不直接从串口通信器读取数据,而是在CPU和串口通信器之间引入DMA控制器作为数据中转站,在利用DMA控制器读取预定大小的数据之后再一次性发送给CPU。由此,可以在很大程度上减轻CPU资源占有率,大大节省系统资源。
然而,根据对比性实施方式,在上述DMA模式下,需要DMA控制器读满预设大小的数据或系统轮询检测发现串口数据长时间没有更新的情况下才能触发向CPU的数据搬运。此时,系统自动轮询检测时间通常可以长达数十毫秒。
这也就意味着,在对比性实施方式中,从下位机装置完成数据传输开始,直至CPU接收到该数据,至少由于上述原因而存在数毫秒的延迟,使得串口数据传输的实时性大大降低。然而,这种毫秒级别的延迟,会直接导致车辆与用户交互时无法根据用户的指令流畅、快速地做出反应,即,明显地出现不期望的交互卡顿现象。
然而,进一步地,在对比性实施方式中,上述“触发CPU的数据搬运”过程并不意味着可以直接向CPU传输数据,而是仅表示触发串口进程的唤醒以将其放入Linux调度的就绪队列中,以下将对此进行详细描述。只有在结束当前任务的运行之后轮转到串口进程运行(即,Linux调度串口进程使用CPU资源)时,才能开始从DMA控制器朝向CPU搬运数据。由此,在DMA控制器接收完串口数据之后,仍需等待一段时间才能开始向CPU搬运数据,这段搬运等待时间不仅包括由上述系统轮询检测时间(长达数十毫秒),还包括此处所提及的串口进程等待调度的时间(以下简称,调度等待时间)。产生该调度等待时间的原因在于,在根据对比文件的基于Linux内核的车载系统中,其所采用的操作系统的任务模式为非抢占式多任务调度,而上述调度等待时间则对应于在该调度模式下的调度周期。
下文中,首先将对基于Linux内核的车载系统的调度方式进行详细描述。
在基于Linux内核的车载系统中,通常会同时运行有多个进程。多个进程同时抢占CPU资源,Linux内核层利用调度器来基于进程/线程的调度策略(scheduling policy)和静态调度优先级(static scheduling priority)决定哪个进程/线程来运行。在Linux中,进程是资源管理的最小单位,线程是程序执行的最小单位。线程是由进程来实现,线程就是轻量级进程(lightweight process),因此在Linux中,线程的调度是按照进程的调度方式来进行调度的。
在本文中,下文描述的术语“进程/线程”(诸如,串口进程/线程、或UART进程/线程)可以对应于相应的应用程序(也简称为程序),并且在本文中可以统称为“任务”(诸如,串口任务或UART任务)。应理解,在Linux的调度策略方面,这些术语可以是可互换的,并且这些术语的使用仅出于描述的目的,而非是对本申请保护范围的限定。
如上所述,根据对比性实施方式,Linux内核层仅采用了非抢占式调度的调度方式,例如分时调度策略(SCHED_OTHER)。分时调度策略是基于Linux内核的系统的默认的线程调度策略。
在该调度模式下,所有进程均被视为普通进程,并且在就绪队列中选择动态优先级最高的进程运行,只有在该进程的时间片用完后或者主动放弃CPU时才能轮到下一个进程。
在这种调度策略下,在上位机装置的串口通信器(或UART通信器)从下位机装置接收到串口数据之后,只能暂存在DMA控制器中。等到当前进程运行结束才能轮到当前队列中实时优先级较高的串口进程(例如,UART进程),在切换到串口进程(例如,UART进程)之后,才能开始从DMA控制器向CPU搬运数据。
图2是示出了根据对比性实施方式的利用DMA模式进行串口数据传输方法的流程图。以下将参照图2对根据对比性实施方式的数据传输方法1000进行描述。
首先,在步骤S110中,将下位机装置和上位机装置的串口通信器初始化为DMA模式。
其次,在步骤S120中,上位机装置的串口通信器从下位机装置接收串口数据,并将所接收的串口数据暂存至DMA控制器。
接着,在步骤S130中,确定DMA控制器的当前状态是否满足向CPU搬运数据的条件。如上所述,在对比性实施方式中,满足CPU搬运数据的条件包括:满足在DMA控制器读满预设大小的数据以及系统轮询检测发现串口数据长时间没有更新这两个条件中的任一个。
具体的,在对比性实施方式中,“读满预设大小的数据”是指:DMA控制器中的串口数据的大小达到预定值;以及“串口数据长时间没有更新”是指:DMA控制器中的串口数据的大小在第一预定时间内没有改变,即,在第一预定时间内没有接收到新数据。示例性地,在对比性实施方式中,该第一预定时间对应于系统自动轮询检测时间,可以约为10毫秒至20毫秒。
如上所述,在步骤S140中,响应于在步骤S130中检测到满足向CPU搬运数据的条件,唤醒串口进程(例如,UART进程),并将其调入至Linux调度的就绪队列中。由于根据对比性实施方式的Linux内核层仅采用分时调度策略,因而,串口进程(例如,UART进程)仅能在就绪队列中等待当前进程运行结束(等待其主动放弃或CPU时间片用完)。
通常,串口进程(例如,UART进程)作为I/O密集型进程会具有相对较高的优先级,因而在当前进程运行结束后,Linux调度器遍历就绪队列中的各个任务,选择具有最高动态优先级的串口进程(例如,UART进程)来运行。该过程可以对应于方法1000中的步骤S150,等待Linux内核层来调度串口进程(例如,UART进程)。
响应于在步骤S150中确定出Linux内核层开始调度串口进程(例如,UART进程),即切换到串口进程(例如,UART进程)开始运行,执行步骤S160,从DMA控制器向CPU传输串口数据。
由此可见,根据对比性实施方式的方法1000中,在从下位机装置接收完串口数据之后,不仅需要在步骤S130中等待对应于自动轮询检测时间的第一预定时间(约数十毫秒),还需要在步骤S140和步骤S150中等待当前进程的运行结束(由当前进程的时间片长度决定,通常可以是数毫秒),才能轮到串口进程运行来向CPU传输串口数据。因而根据对比性实施方式,在DMA控制器和CPU之间的数据传输可能需要存在长达数十毫秒的延迟,使得串口数据的传输具有较低的实时性。
在本申请的示例中,基于Linux内核的车载系统可以采用抢占式多任务模式。根据本申请的示例性实施方式,可以至少针对串口进程(例如,UART进程)采用抢占调度。例如,将串口进程(例如,UART进程)的调度策略从系统默认的分时调度策略调整到实时调度策略。实时调度策略大于分时调度策略。当实时进程/线程准备就绪后,如果CPU当前正在运行分时进程/线程,则实时进程/线程立即抢占分时进程/线程。同样都是实时调度策略的情况下,则由优先级高的进程/线程先执行。
根据本申请的实施方式,例如,可以针对串口进程(例如,UART进程)使用SCHED_FIFO调度策略或SCHED_RR调度策略。
具体地,SCHED_FIFO调度策略可以理解为先到先服务。简言之,在该调度策略下,一旦进程/线程占用CPU则一直运行,直到有更高优先级任务到达或自己放弃。
SCHED_RR调度策略可以是时间片轮转调度。简言之,在该调度策略下,可以给每个进程/线程增加一个时间片限制,当时间片用完后,系统将把该线程置于队列末尾,由此可以保证所有具有相同优先级的RR任务的调度公平。
根据示例性实施方式,串口进程(例如,UART进程)作为实时进程,可以具有比采用分时调度策略的非实时进程高的优先级,并且可以抢断普通进程或优先级较低的进程的运行。示例性地,在上位机装置30的第二串口通信器310从下位机装置20接收到串口数据之后,CPU即可将该串口进程(例如,UART进程)调度至当前的就绪队列之首(或就绪队列的最前端),并将当前进程中断,切换到串口进程(例如,UART进程)。由此,在根据本申请的示例性实施方式中,可以在DMA控制器读完串口数据之后,直接触发向CPU的数据搬运。因而,相比于对比性实施方式,根据本申请的示例性实施方式的串口数据朝向CPU的传输的延迟时长可以从毫秒级别压缩至微秒级别,由此可以明显改善串口数据传输的实时性,防止卡顿现象的出现。
下面返回参照图1,来继续描述根据本申请的实施方式的车载系统100。在示例性实施方式中,车载系统100的上位机装置30可以包括:第二串口通信器310、DMA控制器320、DMA状态监视器330和至少一个处理器340。示例性地,为了简化描述,本文中,至少一个处理器340以中央处理器CPU为例进行描述。
根据示例性实施方式,第二串口通信器310可以从下位机装置20(可被视作上位机装置30的外部设备)接收串口数据。
示例性地,DMA控制器320可以与第二串口通信器310进行数据通信,并且可以在其中暂存从第二串口通信器310接收到的串口数据。在CPU 340被串口进程占用之后,可以从DMA控制器320读取暂存在其中的串口数据,即,从DMA控制器320向CPU 340发送串口数据。
根据示例性实施方式,DMA状态监视器330可以与DMA控制器320和CPU 340连接,并且可以实时监测DMA控制器320的状态。在DMA状态监视器330监测到DMA控制器320处于空闲状态或读满状态时,Linux内核层调度串口进程占用CPU 340,由此CPU 340便可以从DMA控制器320读取串口数据。
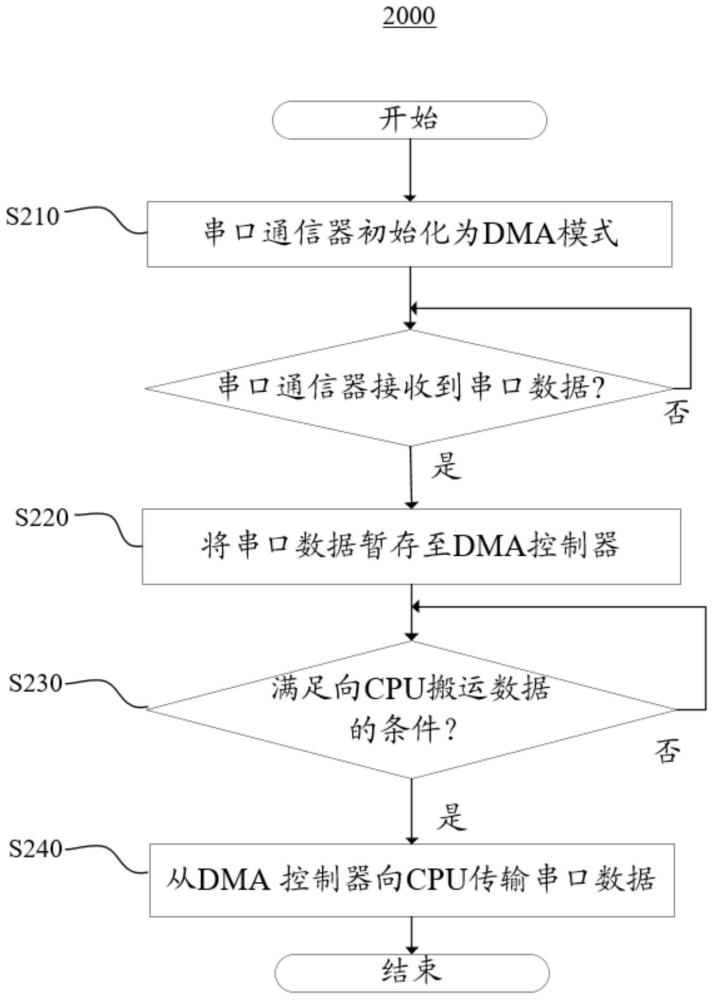
图3是示出了根据本申请的实施方式的利用DMA模式进行串口数据传输方法的流程图。图4是示出了根据本申请的实施方式的图3中的方法2000的更具体的流程图。
以下将参照图1、图3和图4对根据本申请的实施方式的数据传输方法进行描述。
如图3中所示,根据本申请的实施方式的方法2000可以包括:步骤S210,将上位机装置30(也称为车机系统)初始化为DMA模式;步骤S220和步骤S230,响应于接收到串口数据,将串口数据暂存至DMA控制器320并且检测DMA控制器320的状态;以及步骤S240,响应于检测到所述DMA控制器处于空闲状态或读满状态,从DMA控制器320向上位机装置30(也称为车机系统)的处理器340传输串口数据。
具体地,在步骤S210中,将上位机装置30的第二串口通信器310初始化为DMA模式。在该过程中,也将下位机装置20的第一串口通信器210初始化为DMA模式,以确保二者能够在相同的模式下进行数据传输。为便于描述,以UART通信器作为第一串口通信器和第二串口通信器情况为例进行详细描述。
示例性地,DMA模式的初始化可以包括:设置UART的波特率;设置数据流控制;设置帧的格式(即数据位个数,停止位,校验位);以及设置UART的收发模式为DMA方式。其次,配置DMA相关参数,包括DMA传输的源地址和目的地址、数据存储速度、数据存储地址等。由此,即可在源地址和目的地址之间形成用于数据传输的DMA通道。
参照图4,在步骤S210和步骤S220之间,方法2000还可以包括步骤S250,确定第二串口通信器310是否接收到串口数据;以及步骤S260,响应于接收到串口数据,唤醒串口进程。
根据本申请的实施方式,在步骤S260中,唤醒串口进程可以包括:对串口进程赋予校验标志mcu_need_resched;在Linux内核器对就绪队列中的各个任务进行调度时,在need_resched函数中优先检测该校验标志mcu_need_resched。响应于检测到该校验标志mcu_need_resched,则放弃就绪队列的当前调度顺序,使能串口进程以将其唤醒。
通过上述唤醒串口进程,可以对当前的就绪队列的调度顺序进行调整。例如,可以理解成,在步骤S260中,基于针对串口进程的校验标志mcu_need_resched将串口进程插队至就绪队列之首,以便于在步骤S230中满足数据搬运条件之后,可以由串口进程抢断当前运行的进程。
根据示例性实施方式,响应于接收到串口数据,唤醒串口进程(步骤S260)之后,进入Linux调度中断程序,在该调度中断程序中执行步骤S220和步骤S230。
具体地,在步骤S220中,将串口数据暂存至DMA控制器320,并且在步骤S230中,利用DMA状态监视器330实时检测DMA控制器320的状态是否满足向CPU搬运数据的条件。
示例性地,在步骤S230中,确定是否满足向CPU搬运数据的条件包括:确定DMA状态监视器330是否检测到DMA控制器320处于空闲状态和读满状态中的任一种。
图5是示出了确定是否满足向CPU搬运数据的条件的步骤S230的示意性流程图。
根据本申请的示例性实施方式,如图5中所示,在步骤S2310中,响应于暂存在DMA控制器320中的串口数据的大小在第二预定时间内没有改变,则确定DMA控制器320处于所述空闲状态。
示例性地,在该示例性实施方式中的第二预定时间不同于在参照图2描述的对比性实施方式中的第一预定时间。如上所述,第一预定时间可以对应于系统自动轮询检测时间,可以约为10毫秒至20毫秒。然而,根据本申请的示例性实施方式中的第二预定时间可以处于微秒级别,例如可以处于1至50微秒的范围内。进一步地,第二预定时间可以是约10微秒。
根据本申请的示例性实施方式,如图5中所示,在步骤S2320中,响应于暂存在DMA控制器320中的串口数据的大小达到预定值,则确定DMA控制器320处于读满状态。
示例性地,预定值可以是在对DMA控制器320初始定义时所限定的BufferSize的缓冲区SRC_Char_Buffer[]的大小。
根据本申请的示例性实施方式,响应于DMA状态监视器330确定DMA控制器320处于所述空闲状态或读满状态,确定满足向CPU搬运数据的条件。由此,Linux调度器可以调度串口进程抢占当前运行的进程,从而在CPU资源被串口进程占用期间,从DMA控制器320向CPU340传输串口数据。
在该过程中,根据示例性实施方式的Linux内核层至少针对串口进程采用抢占式调度策略,并且对串口进程赋予校验标志,因而可以基于该校验标志调整串口进程在就绪队列中的位置,以使之能够在满足抢占条件(例如,满足向CPU搬运数据的条件)的情况下,优先抢占当前运行的进程。同时,不管当前运行进程的类型(实时性进程或非实时性进程)和优先级(高于串口进程或低于串口进程的优先级),通过该方法均可以被串口进程抢占。
系统进程类型主要有两种:CPU密集型和I/O密集型。CPU密集型会把大部分时间用在CPU计算;而I/O密集型会把大部分时间消耗在I/O请求和等待I/O上,CPU的真正使用率很低。显然,串口进程(例如,UART进程)属于I/O密集型进程。如果将串口进程(例如,UART进程)分配更多时间片,使之具有更高的优先级,无疑是对CPU资源的一种浪费。
然而,根据本申请的实施方式,基于调度策略的改变以及校验标志的设置,实质上并没有修改串口进程(例如,UART进程)的优先级,所以并不会导致没有串口数据的情况下,影响正常的CPU调度,并没有平白占用CPU资源。
根据本申请的另一方面,提供了包括上述车机系统(例如,上位机装置30)的车辆,也提供了一种包括上述车机系统30的车载系统100的车辆。
以上对本申请的实施方式进行了描述。但是,这些实施方式仅仅是为了说明的目的,而并非为了限制本申请的范围。本申请的范围由所附权利要求及其等同限定。在不背离本申请的范围的情况下,本领域技术人员可以做出多种替代和修改,这些替代和修改都应落在本申请的范围之内。
本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离本申请的构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 用于求得将要驶过的轨迹和/或实施行驶干预的车辆系统的运行方法、控制系统的运行方法和机动车
- 车辆配置方法、系统、车机以及车辆
- 用于热交换器的管配置、包括所述管配置的热交换器、包括所述热交换器的流体加热系统及其制造方法
- 用于热交换器的挡板组合件、包括所述挡板组合件的热交换器、包括所述热交换器的流体加热系统及其制造方法
- 用于存储车辆标识的车钥匙、用于发射车辆标识的发射器、用于编程车钥匙的系统、包括所述车钥匙的运输工具、其使用以及在车钥匙中存储车辆标识的方法
- 用于存储车辆标识的车钥匙、用于发射车辆标识的发射器、用于编程车钥匙的系统、包括所述车钥匙的运输工具、其使用以及在车钥匙中存储车辆标识的方法