一种分布式爬虫调度系统
文献发布时间:2023-06-19 10:02:03
技术领域
本发明涉及网络爬虫调度领域,具体涉及一种分布式爬虫调度系统。
背景技术
网络爬虫,又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫,在进行爬虫作业时需要使用到爬虫调度系统,来调度爬虫工作。
现有的爬虫调度系统,专注于基于爬虫负载的调度,调度时间不够准确,过滤模式较为单一,提供的爬虫质量较差,给爬虫调度系统的使用带来了一定影响,因此,提出一种分布式爬虫调度的方法。
发明内容
本发明所要解决的技术问题在于:如何解决现有的爬虫调度系统,调度时间不够准确,过滤模式较为单一,提供的爬虫质量较差,给爬虫调度系统的使用带来了一定影响的问题,提供了一种分布式爬虫调度系统。
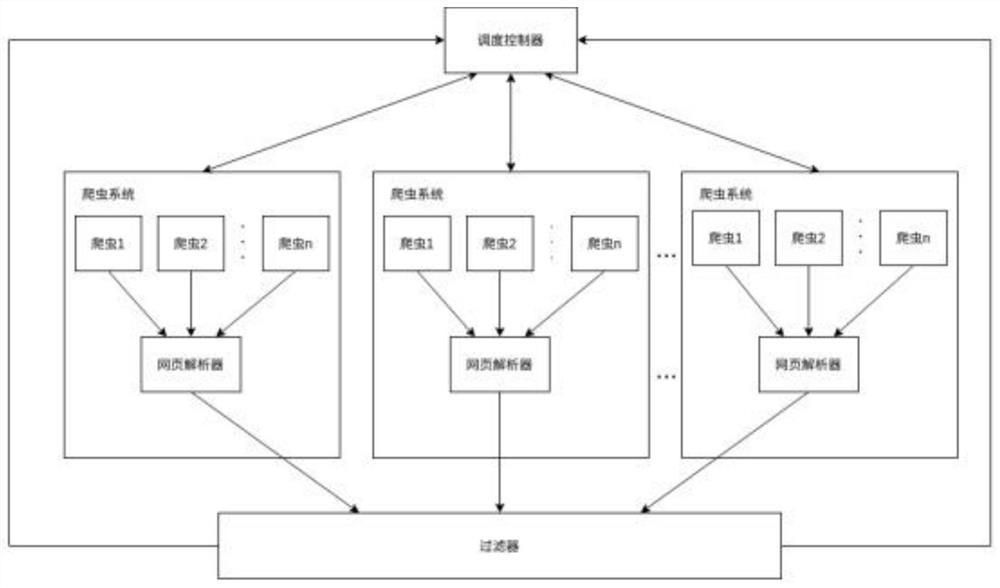
本发明是通过以下技术方案解决上述技术问题的,本发明包括调度控制器、爬虫系统与过滤器;
所述调度控制器包括调度器、分配器、内部配置有用于对爬虫任务按照调度时间进行正向排序的排序列表和用于分配爬虫任务的待采集队列;
所述爬虫系统包括网页解析器与多个爬虫,每个爬虫分配了一个爬虫队列,并接受调度控制器下发的任务;
所述爬虫系统的作用包括网页下载和网页解析;
所述爬虫系统启动时,把本系统具备的所有爬虫和爬虫位置信息上报到调度控制器;
所述调度控制器用于对爬虫系统进行调度处理,所述调度控制器内存放了所有需要进行调度的爬虫任务并根据下一次调度时间进行正向排序;
所述调度器用于定时从头遍历排序列表,当遍历到某个任务的下一次调度时间大于系统当前时间时,取出之前遍历到的所有任务放入待采集队列,并重新计算取出任务的下一次调度时间,写回排序列表;
所述分配器用于取出待采集队列中的采集任务,分配给空闲爬虫,没有空闲爬虫时,则一直等待爬虫系统上报空闲爬虫;
所述分配器获取到空闲爬虫后,根据爬虫位置信息,发送RPC请求到对应爬虫系统,再把待采集任务发送到其对应爬虫的队列;
每个爬虫消费自己的采集队列,并进行下载处理,队列清空后上报调度控制器本爬虫空闲;
所述过滤器用于对爬虫系统获取到的新的下载请求进行过滤处理。
优选的,所述待采集队列是一个优先级队列,待采集队列配置了最大尺寸,当爬虫系统不能及时释放爬虫,则队列达到上限,无法接受新的爬虫任务。
优选的,每个所述爬虫采集任务记录了调度时间间隔、请求url、请求方法、请求头、cookie、最大尝试次数等信息。
优选的,所述下载处理过程中下载失败时,判断是否需要重试,需要重试则直接通过RPC把采集任务加入调度器待采集队列;
所述下载处理过程下载成功后,将下载的网页传输给网页解析器,网页解析器会解析出信息实体和新的下载url,对于信息实体,输出到业务系统进行处理,对于新的下载请求,需要加上过滤模式发送给过滤器进行过滤处理。
优选的,所述过滤器基于布隆过滤,创建一个有界过滤列表,使用LRU作为过滤器的淘汰策略,判断重复时,从尾到头依次判断每个布隆过滤器是否已经写入该url,当所有的过滤器都没有写入该url,则写入url到最后一个布隆过滤器并返回true,否则返回false;
通过布隆过滤器处理后返回true的url,将其发送到任务调度器,并加入待采集队列,进行数据采集。
优选的,所述过滤器的过滤模式分为实例内调度过滤,全局过滤和无需过滤;
当发生下载过滤器淘汰时,由于采用了基于时间的存储,且淘汰了头部的过滤器,同时出现了较少数据重复时,将数据写入历史存储;所述实例内调度过滤为过滤器将为每个实例生成一个临时过滤器,实现临时过滤;
所述全局过滤为只要全局下载过一次就不再触发;
所述无需过滤针对不需要下载的链接,不需要下载的链接包括下一页获取列表的链接。
本发明相比现有技术具有以下优点:该分布式爬虫调度系统,用基于调度时间的排序列表,使得大批量任务调度时遍历列表的时间复杂度更小,每个爬虫使用一个队列,解决了本爬虫产生的新链接需要继续由本爬虫定向采集的问题,爬虫产生的新链接可自由定义下载需要使用的爬虫节点和爬虫,这样可以更好的使用上下文信息,使用基于LRU的布隆过滤器和基于时间的存储结构,解决了布隆过滤器进行旧元素淘汰时可能存在的数据重复问题。
附图说明
图1是本发明的整体流程图;
图2是本发明的调度控制器流程图;
图3是本发明的爬虫系统结构框图;
图4是本发明的过滤器流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1~4所示,本实施例提供一种技术方案:一种分布式爬虫调度系统,包括调度控制器、爬虫系统与过滤器;
所述调度控制器包括调度器、分配器、内部配置有用于对爬虫任务按照调度时间进行正向排序的排序列表和用于分配爬虫任务的待采集队列;
所述爬虫系统包括网页解析器与多个爬虫,每个爬虫分配了一个爬虫队列,并接受调度控制器下发的任务,每个爬虫使用一个队列,解决了本爬虫产生的新链接需要继续由本爬虫定向采集的问题;
所述爬虫系统的作用包括网页下载和网页解析;
所述爬虫系统启动时,把本系统具备的所有爬虫和爬虫位置信息上报到调度控制器;
所述调度控制器用于对爬虫系统进行调度处理,所述调度控制器内存放了所有需要进行调度的爬虫任务并根据下一次调度时间进行正向排序;
所述调度器用于定时从头遍历排序列表,当遍历到某个任务的下一次调度时间大于系统当前时间时,取出之前遍历到的所有任务放入待采集队列,并重新计算取出任务的下一次调度时间,写回排序列表,写回排序列表的作用是为了下一个周期调度完整运行;
当需要调度预设时间k点前的任务时,调度器对排序列表进行每秒遍历,将k点前的所有任务加入到待采集队列中等待任务进行运行处理,之后再次计算下一次的调度时间,并在加入到待采集队列中的任务运行完毕后,将其写回到排序列表中,来实现周期调度完整运行;
所述分配器用于取出待采集队列中的采集任务,准备分配空闲爬虫,如果没有空闲爬虫,则一直等待爬虫系统上报空闲爬虫;
所述分配器获取到空闲爬虫后,根据爬虫中记录的位置信息,发送RPC请求到对应爬虫系统,从而把爬虫请求发送到对应爬虫的队列;
每个爬虫消费自己的采集队列,并进行下载处理,队列清空后上报调度控制器本爬虫空闲;每个爬虫使用一个队列,解决了本爬虫产生的新链接需要继续由本爬虫定向采集的问题;
所述过滤器用于对爬虫系统获取到的新的下载请求进行过滤处理。
所述待采集队列是一个优先级队列,待采集队列配置了最大尺寸,当爬虫系统不能及时释放爬虫,则队列达到上限,无法接受新的爬虫任务。
每个所述爬虫采集任务记录了调度时间间隔、请求url、请求方法、请求头、cookie、最大尝试次数等信息。
所述下载处理过程中下载失败时,判断是否需要重试,需要重试则直接通过RPC把采集任务加入调度器待采集队列;
所述下载处理过程下载成功后,将下载的网页传输给网页解析器,网页解析器会解析出信息实体和新的下载url,对于信息实体,输出到业务系统进行处理,对于新的下载请求,需要加上过滤模式发送给过滤器进行过滤处理。
所述过滤器基于布隆过滤,创建一个有界过滤列表,使用LRU作为过滤器的淘汰策略,判断重复时,从尾到头依次判断每个布隆过滤器是否已经写入该url,当所有的过滤器都没有写入该url,则写入url到最后一个布隆过滤器并返回true,否则返回false,使用基于LRU的布隆过滤器和基于时间的存储结构,解决了布隆过滤器进行旧元素淘汰时可能存在的数据重复问题;
通过布隆过滤器处理后返回true的url,将其发送到任务调度器,并加入待采集队列,进行数据采集。
所述过滤器的过滤模式分为实例内调度过滤,全局过滤和无需过滤;
当发生过滤器淘汰时,由于采用了基于时间的存储,且淘汰了头部的过滤器,如此即使极端情况出现了较少数据重复也只会写入历史存储,不影响新的数据分析;所述实例内调度过滤为过滤器将为每个实例生成一个临时过滤器,实现临时过滤;
所述全局过滤为只要全局下载过一次就不再触发;
所述无需过滤针对不需要下载的链接,不需要下载的链接包括下一页获取列表的链接。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 一种分布式爬虫调度系统
- 一种通用型分布式爬虫调度系统