用于化身运动的多模态手的位置和取向
文献发布时间:2023-06-19 12:24:27
通过引用并入任何优先权申请
本申请要求于2018年11月30日提交的题为“MULTI-MODAL HAND LOCATION ANDORIENTATION FORAVATAR MOVEMENT(用于化身运动的多模态手的位置和取向)”的美国临时专利申请62/774,076的优先权。上述申请,以及在与本申请一起提交的申请数据表中确定了外国或国内优先权要求的其它申请,在此根据37CFR 1.57通过引用并入。
技术领域
本公开涉及虚拟现实和增强现实成像和可视化系统,并且更具体地涉及基于上下文信息动态调节和渲染虚拟化身。
背景技术
现代计算和显示技术促进了用于所谓“虚拟现实”、“增强现实”或“混合现实”体验的系统的开发,其中以数字方式再现的图像或其部分以它们似乎或可能被感知是真实的方式呈现给用户。虚拟现实或“VR”场景通常涉及数字或虚拟图像信息的呈现,而对其它实际真实世界的视觉输入没有透明度;增强现实或“AR”场景通常涉及数字或虚拟图像信息的呈现,作为对用户周围实际世界的可视化的增强;混合现实或“MR”,与合并真实世界和虚拟世界以产生物理和虚拟对象共存并实时交互的新环境有关。事实证明,人类的视觉感知系统非常复杂,并且产生在其它虚拟或真实世界的图像元素中促进舒适、自然、丰富的虚拟图像元素呈现的VR、AR或MR技术是具有挑战性的。在此公开的系统和方法解决了与VR、AR和MR技术相关的各种挑战。
发明内容
用于基于一组规则确定活动的手、活动的手的取向、活动的手的位置和/或相关联的置信水平的混合现实系统(在此称为“可穿戴系统”)的各种示例。该规则可以基于历史数据、运动数据和人体工程学数据。两个或更多个传感器可以提供数据,然后可以为该数据分配初始权重估计。然后可以将多个传感器流组合成单个估计,该估计可以被输出并馈送到化身渲染系统中。
附图说明
图1描绘了具有某些虚拟现实对象和由人观看的某些物理对象的混合现实场景的图示。
图2示意性地示出可穿戴系统的示例。
图3示意性地示出可穿戴系统的示例组件。
图4示意性地示出用于向用户输出图像信息的可穿戴设备的波导堆叠的示例。
图5是用于与虚拟用户界面交互的方法的示例的过程流程图。
图6A是示例可穿戴系统的框图。
图6B是示例可穿戴系统的框图。
图6C是示例可穿戴系统的框图。
图7是包括到可穿戴系统的各种输入的可穿戴系统的示例的框图。
图8是渲染与识别对象相关的虚拟内容的方法的示例的过程流程图。
图9A示意性地示出描绘彼此交互的多个可穿戴系统的整体系统视图。
图9B示出示例远程呈现会话。
图10示出由可穿戴系统的用户感知的化身的示例。
图11A-11B示出用于确定用户的活动的手、活动的手的位置、活动的手的取向和/或相关联的置信水平的示例过程。
图12示出用于一组示例传感器的一组示例FOV。
图13示出用于图12中描述的一组传感器的一组示例区域。
图14示出用于确定用户的活动的手、活动的手的位置、活动的手的取向和/或相关联的置信水平的示例过程。
图15示出用于组合和协调包括初始加权的传感器数据以产生跨所有传感器数据的单个估计的示例过程。
在整个附图中,可以重用附图标记来指示所引用元素之间的对应关系。附图被提供用以示出在此描述的示例实施例并且不旨在限制本公开的范围。
具体实施方式
虚拟化身可以是AR/VR/MR环境中真实或虚构的人(或生物或拟人化对象)的虚拟表示。例如,在两个AR/VR/MR用户彼此交互的远程呈现会话期间,观看者可以在观看者的环境中感知另一个用户的化身,并且从而在观看者的环境中创建其他用户存在的有形感觉。化身还可以为用户提供一种在共享的虚拟环境中彼此交互和一起做事的方式。例如,参加在线课程的学生可以在虚拟教室中感知其他学生或老师的化身,并可以与其他学生或老师的化身交互。
当利用虚拟化身来表示用户时,可能需要以模仿用户运动的方式来对化身制作动画。例如,当用户移动她的头部时,化身可以做出相同的运动。在另一个示例中,当用户移动她的手和/或手臂时,化身可以做出相同的手和/或手臂运动。匹配用户的运动可以为用户(以及与用户交互的其他人)创建更逼真和准确的AR虚拟化身体验。传统系统可能根本不对化身的手动作制作动画,可能基于用户输入(而不是传感器数据)对用户的手制作动画,或者可能使用一个数据源对化身的手制作动画,诸如来自由用户的手握住的图腾内IMU的数据(或其它手持控制器)。尽管这些传统方法对虚拟形象的手制作动画,但这些方法容易出错。例如,IMU可能会随时间漂移,导致用户手位置和/或运动不准确。在另一个示例中,视觉算法可用于识别用户的手,但这些方法仅限于相机FOV内的手运动,并且不考虑用户的手取向。此外,即使传统方法基于用户的运动对化身制作动画,传统方法也无法识别哪只手在进行运动(例如右手与左手),传统系统也无法确定正在进行运动的用户手的取向。在下面,进行运动的手可以被称为活动的手。在一些实施例中,仅存在一只活动的手。在一些实施例中,可以存在第一活动的手和第二活动的手。
有利地,在一些实施例中,在此描述的可穿戴系统和方法可以自动确定哪只手是活动的手以及活动的手的取向。这可以通过以下来实现:组合关于手的感测信息的两个或更多个不同模态,以产生比单个模态可以产生的对用户的手位置和取向更稳健和/或更准确的估计。在此的可穿戴系统可以能够提供以下益处:在手势感测的FOV之外无缝跟踪手,当手靠近FOV的边界(在此处使用手势的置信水平降低)时通过从控制器寻找协作证据,增加手跟踪的置信度,例如,使用改进的组合估计提高手位置的置信度。
在一些实施例中,在此描述的可穿戴系统和方法可以使用两个或更多个传感器数据源、人体工程学数据和运动数据来提高确定用户的哪只手(例如左手、右手)正在移动和/或那只手的取向的置信水平和准确度,用于用户的虚拟化身的动画。置信水平可以在0-100的值之间,并且可以分解为人类可读的类别,低置信度为0-30%,中置信度为30-70%,并且高置信度为70%以上。可以使用评估置信水平和/或划分类别的其它合适方式。例如,阈值可用于区分可接受与不可接受的置信水平。
在一些实施例中,在此描述的可穿戴系统和方法可以估计用户手的手姿势和形状,以用于应用,诸如对在表示用户的化身上的对应的手制作动画。在一些实现方式中,可穿戴系统可以组合和评估来自多个不同来源的信息,诸如手持控制器的6DOF外部主动跟踪、手持控制器的6DOF内部运动传感器、和/或手和/或控制器(例如图腾)的外部被动跟踪,例如使用视觉传感器、深度传感器、LIDAR传感器等。信息源可用于估计哪只手正在握持控件并提高手跟踪姿势和手形状的准确度。
因此,所公开的系统和方法的实施例可以提供与用户对应的化身的更加逼真和准确的动画。
可穿戴系统(在此也称为增强现实(AR)系统)可以被配置为向用户呈现2D或3D虚拟图像。图像可以是静止图像、视频的帧或视频的组合等。可穿戴系统的至少一部分可以被实现在可单独或组合呈现用于用户交互的VR、AR或MR环境(或“MR系统”)的可穿戴设备上。可穿戴设备可以被互换地使用为AR设备(ARD)。此外,出于本公开的目的,术语“AR”与术语“MR”可互换使用。
图1描绘了具有某些虚拟现实对象和人观看的某些物理对象的混合现实场景的图示。在图1中,描绘了MR场景100,其中MR技术的用户看到以人、树木、背景中的建筑物和混凝土平台120为特征的真实世界公园状环境110。除了这些项目之外,MR技术的用户MR技术还感知到他“看到”了站在真实世界平台120上的机器人雕像130,以及飞过的似乎是大黄蜂拟人化的卡通状化身角色140,即使这些元素没有存在于真实世界中。
为了使3D显示器产生真实的深度感觉,并且更具体地,产生表面深度的模拟感觉,可能需要显示器视野中的每个点生成与其虚拟深度对应的调节响应。如果对显示点的调节响应与该点的虚拟深度不对应,如由会聚和立体视觉的双目深度提示确定的那样,则人眼可能会遇到调节冲突,导致不稳定成像、有害的眼睛疲劳、头痛,并且,在没有调节信息的情况下,几乎完全缺乏表面深度。
VR、AR和MR体验可以由具有显示器的显示系统提供,在该显示器中与多个深度平面对应的图像被提供给观看者。对于每个深度平面,图像可能不同(例如,提供场景或对象的稍微不同的呈现),并且可以由观看者的眼睛分开聚焦,从而基于将位于不同深度平面上的场景的不同图像特征聚焦所需的眼睛的调节,或者基于观察不同深度平面上的不同图像特征失焦,来向用户提供深度提示。如在此别处所讨论的,此类深度提示提供对深度的可信感知。
图2示出可被配置为提供AR/VR/MR场景的可穿戴系统200的示例。可穿戴系统200也可以称为AR系统200。可穿戴系统200包括显示器220,以及支持显示器220功能的各种机械和电子模块和系统。显示器220可以耦合到框架230,该框架230可以由用户、佩戴者或观看者210佩戴。显示器220可以定位于用户210的眼睛前面。显示器220可以向用户呈现AR/VR/MR内容。显示器220可以包括佩戴在用户头上的头戴式显示器(HMD)。
在一些实施例中,扬声器240耦合到框架230并被定位为与用户的耳道相邻(在一些实施例中,另一个扬声器(未示出)被定位为与用户的另一耳道相邻以提供立体声/可塑形声音控制)。显示器220可以包括用于检测来自环境的音频流的音频传感器(例如,麦克风)232并捕获环境声音。在一些实施例中,一个或多个其它音频传感器(未示出)被定位为提供立体声接收。立体声接收可用于确定声源的位置。可穿戴系统200可以对音频流执行声音或语音识别。
可穿戴系统200可以包括面向外成像系统464(图4中所示),其观察用户周围环境中的世界。可穿戴系统200还可以包括面向内成像系统462(图4中所示),其可以跟踪用户的眼睛运动。面向内成像系统可以跟踪一只眼睛的运动或两只眼睛的运动。面向内成像系统462可以附接到框架230并且可以与处理模块260或270电通信,该处理模块260或270可以处理由面向内成像系统获取的图像信息,以确定例如用户210的瞳孔直径或眼睛取向、眼睛运动或眼睛姿势。面向内成像系统462可以包括一个或多个相机。例如,可以使用至少一个相机来对每只眼睛成像。由相机获取的图像可用于分别确定每只眼睛的瞳孔大小或眼睛姿势,从而允许向每只眼睛呈现的图像信息可以针对该眼睛被动态定制。
作为示例,可穿戴系统200可以使用面向外成像系统464或面向内成像系统462来获取用户姿势的图像。图像可以是静止图像、视频帧或视频。
显示器220可以诸如通过有线引线或无线连接操作性地耦合250到本地数据处理模块260,该本地数据处理模块260可以以各种配置安装,诸如固定地附接到框架230,固定地附接到由用户佩戴的头盔或帽子,嵌入耳机中,或以其它方式可移除地附接到用户210(例如,在背包式配置中,在腰带耦合式配置中)。
本地处理和数据模块260可以包括硬件处理器以及数字存储器,诸如非易失性存储器(例如,闪存),这两者都可以用于辅助数据的处理、缓存和存储。数据可以包括如下数据:a)从传感器(例如,其可以可操作地耦合到框架230或以其它方式附接到用户210)捕获的数据,该传感器诸如图像捕获设备(例如,面向内成像系统或面向外成像系统中的相机)、音频传感器(例如麦克风)、惯性测量单元(IMU)、加速度计、指南针、全球定位系统(GPS)单元、无线电设备或陀螺仪;或b)使用远程处理模块270或远程数据存储库280获取或处理,可能用于在此类处理或取得之后传送到显示器220。本地处理和数据模块260可以通过通信链路262或264,诸如经由有线或无线通信链路,可操作地耦合到远程处理模块270或远程数据存储库280,使得这些远程模块可用作本地处理和数据模块260的资源。此外,远程处理模块270和远程数据存储库280可以在操作上彼此耦合。
在一些实施例中,远程处理模块270可以包括一个或多个处理器,其被配置为分析和处理数据或图像信息。在一些实施例中,远程数据存储库280可以包括数字数据存储设施,该数字数据存储设施可以通过互联网或“云”资源配置中的其它联网配置可用。在一些实施例中,在本地处理和数据模块中存储所有数据并且执行所有计算,从而允许来自远程模块的完全自主使用。
图3示意性地示出可穿戴系统的示例组件。图3示出可包括显示器220和框架230的可穿戴系统200。放大图202示意性地示出可穿戴系统200的各种组件。在某些实现方式中,图3中示出的一个或多个组件可以是显示器220的一部分。单独或组合的各种组件可以收集与可穿戴系统200的用户或用户的环境相关联的各种数据(例如,音频或视觉数据)。应当理解,取决于使用可穿戴系统的应用,其它实施例可以具有附加的或更少的组件。尽管如此,图3提供了各种组件和可以通过可穿戴系统收集、分析和存储的数据类型中的一些的基本概念。
图3示出可以包括显示器220的示例可穿戴系统200。显示器220可以包括可以安装到用户的头部或壳体或框架230的显示透镜226,其对应于框架230。显示透镜226可以包括由壳体230定位在用户眼睛302、304前面的一个或多个透明镜子,并且可以被配置为将投射光338反弹到眼睛302、304中并促进光束成形,同时还允许来自当地环境的至少一些光的传输。投射光束338的波前可以弯曲或聚焦以与投射光的所需焦距一致。如图所示,两个(例如,宽视野机器)视觉相机316(也称为世界相机)可以耦合到壳体230以对用户周围的环境成像。这些相机316可以是双捕获可见光/不可见(例如,红外)光相机。相机316可以是图4中所示的面向外成像系统464的一部分。由世界相机316获取的图像可由姿势处理器336处理。例如,姿势处理器336可实现一个或多个对象识别器708(例如,图7中所示)以识别用户或另一人在用户环境中的姿势或识别用户环境中的物理对象。在一些实施例中,可以存在四个世界相机316。一个或多个世界相机316可以是灰度的。一个或多个世界相机可能是彩色的。在一些实施例中,两个世界相机可以面向内(例如,相机彼此成角度但仍然面向世界,远离用户),并且两个世界相机可以面向外(例如,彼此成角度)。
继续参考图3,示出了具有显示镜和光学器件的一对扫描激光成形波前(例如,用于深度)光投射器模块,其被配置为将光338投射到眼睛302、304中。所描绘的视图还示出了与红外光(例如发光二极管“LED”)配对的两个微型红外相机324,其被配置为能够跟踪用户的眼睛302、304以支持渲染和用户输入。相机324可以是图4中所示的面向内成像系统462的一部分。可穿戴系统200可以进一步以传感器组件339为特征,该传感器组件339可以包括X、Y和Z轴加速度计能力以及磁罗盘和X、Y和Z轴陀螺仪能力,优选地以相对高的频率(诸如200Hz)提供数据。传感器组件339可以是参考图3描述的IMU的一部分。所描绘的可穿戴系统200还可以包括头部姿势处理器336,诸如ASIC(专用集成电路)、FPGA(现场可编程门阵列)或ARM处理器(高级简化指令集机器),其可以被配置为基于从相机316(和/或其它输入设备)输出的宽视野图像信息计算实时或接近实时的用户头部姿势。头部姿势处理器336可以是硬件处理器并且可以实现为图3中所示的本地处理和数据模块260的一部分。
可穿戴系统还可以包括一个或多个深度传感器234。深度传感器234可以被配置为测量在环境中的对象到可穿戴设备之间的距离。深度传感器234可以包括激光扫描仪(例如,LIDAR)、超声波深度传感器或深度感测相机。在相机316具有深度感测能力的某些实现方式中,相机316也可被视为深度传感器234。
还示出了处理器332,其被配置为执行数字或模拟处理以从来自传感器组件339的陀螺仪、罗盘或加速度计数据导出姿势。处理器332可以是图2中所示的本地处理和数据模块260的一部分。如图3中所示的可穿戴系统200还可以包括诸如例如GPS 337(全球定位系统)的定位系统以辅助姿势和定位分析。此外,GPS可以进一步提供有关用户环境的基于远程(例如,基于云)的信息。该信息可用于识别用户环境中的对象或信息。
可穿戴系统可以组合由GPS 337和远程计算系统(诸如例如,远程处理模块270、另一个用户的ARD等)获取的数据,该数据可以提供关于用户环境的更多信息。作为一个示例,可穿戴系统可以基于GPS数据确定用户的位置并检索世界地图(例如,通过与远程处理模块270通信),该世界地图包括与用户位置相关联的虚拟对象。作为另一个示例,可穿戴系统200可以使用世界相机316(其可以是图4中所示的面向外成像系统464的一部分)来监视环境。基于由世界相机316获取的图像,可穿戴系统200可以检测环境中的对象(例如,通过使用图7中所示的一个或多个对象识别器708)。可穿戴系统可以进一步使用GPS 337获取的数据来解释字符。
可穿戴系统200还可以包括渲染引擎334,该渲染引擎334可以被配置为提供用户本地的渲染信息以促进扫描仪的操作并成像到用户的眼睛中,用于用户的世界视野。渲染引擎334可以由硬件处理器(诸如例如中央处理单元或图形处理单元)来实现。在一些实施例中,渲染引擎是本地处理和数据模块260的一部分。渲染引擎334可以通信地耦合(例如,经由有线或无线链路)到可穿戴系统200的其它组件。例如,渲染引擎334可以经由通信链路274耦合到眼睛相机324,并经由通信链路272耦合到投影子系统318(其可以经由扫描激光装置以类似于视网膜扫描显示器的方式将光投射到用户的眼睛302、304中)。渲染引擎334还可以分别经由链路276和294与其它处理单元(诸如例如传感器姿势处理器332和图像姿势处理器336)通信。
相机324(例如,微型红外相机)可用于跟踪眼睛姿势以支持渲染和用户输入。一些示例眼睛姿势可以包括用户正在看的地方或他或她聚焦的深度(这可以用眼睛聚散度来估计)。GPS 337、陀螺仪、罗盘和加速度计(在图3的示例中可以是传感器组件339的一部分)可用于提供粗略或快速姿势估计。相机316中的一个或多个相机可以获取图像和姿势,该图像和姿势结合来自相关联的云计算资源的数据,可以用于绘制本地环境地图并与其他人共享用户视图。
图3中描绘的示例组件仅用于说明目的。为了便于说明和描述,多个传感器和其它功能模块一起示出。一些实施例可以仅包括这些传感器或模块中的仅一个或子集。此外,这些组件的位置不限于图3中所示的位置。一些组件可能安装在或容纳在其它组件中,诸如皮带安装组件、手持组件或头盔组件。作为一个示例,图像姿势处理器336、传感器姿势处理器332和渲染引擎334可以放置在皮带包中并且被配置为经由无线通信(诸如超宽带、Wi-Fi、蓝牙等)或经由有线通信与可穿戴系统的其它组件通信。所描绘的壳体230优选地是可头戴的并且可由用户佩戴。然而,可穿戴系统200的一些组件可以被穿戴到用户身体的其它部分。例如,扬声器240可以插入用户的耳朵中以向用户提供声音。
关于光338到用户的眼睛302、304中的投射,在一些实施例中,相机324可用于测量用户眼睛的中心在几何上会聚的位置,该位置通常与眼睛的焦点位置或“焦点深度”重合。眼睛会聚的所有点的3维表面可以被称为“双眼单视界(horopter)”。焦距可以呈现有限数量的深度,或者可以无限变化。从聚散度距离投射的光似乎被聚焦到对象眼睛302、304,而聚散度距离前面或后面的光是模糊的。本公开的可穿戴设备和其它显示系统的示例还在美国专利公开号2016/0270656中进行了描述,其通过引用整体并入本文。
人类视觉系统是复杂的并且提供对深度的真实感知是具有挑战性的。由于聚散度和调节的组合,对象的观看者可能将对象感知为三维的。两只眼睛相对彼此的聚散运动(例如,瞳孔朝向或远离彼此的滚动运动以会聚眼睛的视线以注视在对象上)与眼睛的晶状体的聚焦(或“调节”)密切相关联。在正常情况下,改变眼睛晶状体的焦距,或调节眼睛,以将焦点从一个对象改变到不同距离处的另一个对象,将在称为“调节-聚散度反射”的关系下自动导致到相同距离的在聚散度中的匹配变化。同样,在正常条件下,聚散度中的变化将触发调节中的匹配变化。在调节和聚散度之间提供更好匹配的显示系统可以形成3D图像的更逼真和舒适的模拟。
具有小于约0.7毫米的光束直径的进一步空间相干光可以由人眼正确分辨,而不管眼睛聚焦在哪里。因此,为了产生适当焦深的错觉,可以用相机324跟踪眼睛聚散度,并且可以利用渲染引擎334和投影子系统318来渲染处于焦点的双眼单视界上或附近的所有对象,以及处于不同散焦程度的所有其它对象(例如,使用故意创建的模糊)。优选地,显示系统220以每秒约60帧或更高的帧速率向用户渲染。如上所述,优选地,相机324可以用于眼睛跟踪,并且软件可以被配置为不仅拾取聚散几何形状而且拾取聚焦位置提示以用作用户输入。优选地,此类显示系统配置有适合白天或夜间使用的亮度和对比度。
在一些实施例中,显示系统优选地具有小于约20毫秒的视觉对象对准的延迟、小于约0.1度的角对准和约1弧分的分辨率,不受理论的限制,该分辨率据信大约是人眼的极限。显示系统220可以与定位系统集成,该定位系统可以涉及GPS元件、光学跟踪、罗盘、加速度计或其它数据源,以帮助位置和姿势确定;定位信息可用于促进用户对相关世界视图的准确渲染(例如,此类信息将有助于眼镜了解它们相对于真实世界的位置)。
在一些实施例中,可穿戴系统200被配置为基于用户眼睛的调节来显示一个或多个虚拟图像。与强制用户聚焦在图像被投影的地方的现有3D显示方法不同,在一些实施例中,可穿戴系统被配置为自动改变所投影虚拟内容的焦点以允许更舒适地观看呈现给用户的一个或多个图像。例如,如果用户的眼睛具有1m的当前焦点,则可以将图像投影到与用户的焦点重合。如果用户将焦点移至3m,则图像被投影以与新焦点重合。因此,一些实施例的可穿戴系统200允许用户的眼睛以更自然的方式运作,而不是强迫用户到预定的焦点。
此类可穿戴系统200可以消除或减少眼睛疲劳、头痛和通常关于虚拟现实设备观察到的其它生理症状的发生率。为了实现这一点,可穿戴系统200的各种实施例被配置为通过一个或多个可变焦元件(VFE)以不同的焦距投射虚拟图像。在一个或多个实施例中,可以通过多平面聚焦系统实现3D感知,该多平面聚焦系统在远离用户的固定焦平面处投射图像。其它实施例采用可变平面焦距,其中焦平面在z方向中来回移动以与用户当前的焦距状态一致。
在多平面对焦系统和可变平面对焦系统两者中,可穿戴系统200可以采用眼睛跟踪来确定用户眼睛的聚散度,确定用户的当前焦点,并在确定的焦点处投射虚拟图像。在其它实施例中,可穿戴系统200包括光调制器,该光调制器通过光纤扫描仪或其它光生成源可变地投射以光栅图案跨视网膜改变焦点的光束。因此,可穿戴系统200的显示器以变化的焦距投射图像的能力不仅便于用户观看3D对象的调节,而且还可用于补偿用户眼部异常,如美国专利公开号2016/0270656中进一步描述,其通过引用整体并入本文。在一些其它实施例中,空间光调制器可以通过各种光学组件将图像投影给用户。例如,如下面进一步描述的,空间光调制器可以将图像投影到一个或多个波导上,该波导然后将图像传输给用户。
图4示出用于向用户输出图像信息的波导堆叠的示例。可穿戴系统400包括波导的堆叠或堆叠的波导组件480,其可用于使用多个波导432b、434b、436b、438b、4400b向眼睛/大脑提供三维感知。在一些实施例中,可穿戴系统400可以对应于图2的可穿戴系统200,图4更详细地示意性地示出了该可穿戴系统200的一些部分。例如,在一些实施例中,波导组件480可以被集成到图2的显示器220中。
继续参考图4,波导组件480还可包括位于波导之间的多个特征458、456、454、452。在一些实施例中,特征458、456、454、452可以是透镜。在其它实施例中,特征458、456、454、452可以不是透镜。相反,它们可能只是隔离物(例如,用于形成气隙的包层或结构)。
波导432b、434b、436b、438b、440b或多个透镜458、456、454、452可以被配置为向眼睛发送具有各种水平的波前曲率或光线发散的图像信息。每个波导层可以与特定深度平面相关联并且可以被配置为输出与该深度平面对应的图像信息。图像注入设备420、422、424、426、428可用于将图像信息注入波导440b、438b、436b、434b、432b中,每个波导可配置为跨每个相应波导分发入射光,用于朝向眼睛410输出。光离开图像注入设备420、422、424、426、428的输出表面并且被注入到波导440b、438b、436b、434b、432b的对应输入边缘。在一些实施例中,单个光束(例如,准直光束)可以被注入到每个波导中以输出克隆准直光束的整个场,该克隆准直光束以对应于与特定波导相关联的深度平面的特定角度(和发散量)指向眼睛410。
在一些实施例中,图像注入设备420、422、424、426、428是分立的显示器,其各自产生用于分别注入到对应的波导440b、438b、436b、434b、432b中的图像信息。在一些其它实施例中,图像注入设备420、422、424、426、428是单个多路复用显示器的输出端,该输出端可以例如经由一个或多个光导管(例如光纤电缆)将图像信息通过管道传送到图像注入设备420、422、424、426、428中的每一个图像注入设备。
控制器460控制堆叠波导组件480和图像注入设备420、422、424、426、428的操作。控制器460包括编程(例如,非暂态计算机可读介质中的指令),该编程规范图像信息到波导440b、438b、436b、434b、432b的定时和提供。在一些实施例中,控制器460可以是单个集成设备,或者是通过有线或无线通信信道连接的分布式系统。在一些实施例中,控制器460可以是处理模块260或270(图2中所示)的一部分。
波导440b、438b、436b、434b、432b可以被配置为通过全内反射(TIR)在每个相应的波导内传播光。波导440b、438b、436b、434b、432b可以各自是平面的或具有另一种形状(例如,弯曲的),具有主要的顶表面和底表面以及在这些主要顶表面和底表面之间延伸的边缘。在图示的配置中,波导440b、438b、436b、434b、432b可以各自包括光提取光学元件440a、438a、436a、434a、432a,该光提取光学元件被配置为通过将在每个相应波导内传播的光重定向到波导之外以将图像信息输出到眼睛410,来从波导提取光。提取的光也可以称为出耦合光,并且光提取光学元件也可以称为出耦合光学元件。提取的光束在波导中传播的光撞击光重定向元件的位置处由波导输出。光提取光学元件(440a、438a、436a、434a、432a)例如可以是反射或衍射光学特征。虽然为了便于描述和绘图清楚而被示为设置在波导440b、438b、436b、434b、432b的底部主表面处,但是在一些实施例中,光提取光学元件440a、438a、436a、434a、432a可以被安置在顶部或底部主表面,或者可以直接安置在波导440b、438b、436b、434b、432b的体积中。在一些实施例中,光提取光学元件440a、438a、436a、434a、432a可以形成在附接到透明基板以形成波导440b、438b、436b、434b、432b的材料层中。在一些其它实施例中,波导440b、438b、436b、434b、432b可以是单块材料,并且光提取光学元件440a、438a、436a、434a、432a可以形成在该块材料的表面上或内部中。
继续参考图4,如在此所讨论的,每个波导440b、438b、436b、434b、432b被配置为输出光以形成与特定深度平面对应的图像。例如,最靠近眼睛的波导432b可以被配置为将如注入到此类波导432b中的准直光传送到眼睛410。准直光可以表示光学无限远焦平面。下一个向上波导434b可以被配置为发出准直光,该准直光在其可以到达眼睛410之前穿过第一透镜452(例如,负透镜)。第一透镜452可以被配置为产生轻微的凸波前曲率,使得眼睛/大脑将来自下一个向上波导434b的光解释为来自从光学无限远向内更靠近眼睛410的第一焦平面。类似地,第三向上波导436b在到达眼睛410之前将其输出光穿过第一透镜452和第二透镜454两者。第一透镜452和第二透镜454的组合光功率可以被配置为产生另一个增量量的波前曲率,使得眼睛/大脑将来自第三波导436b的光解释为来自第二焦平面,与来自下一个向上波导434b的光相比,该第二焦平面从光学无限远更向内更加靠近人。
其它波导层(例如,波导438b、440b)和透镜(例如,透镜456、458)被类似地配置,堆叠中最高的波导440b通过它和眼睛之间的所有透镜发送其输出,以用于表示离人最近的焦平面的总焦度。为了在观看/解释来自堆叠波导组件480的另一侧的世界470的光时补偿透镜458、456、454、452的堆叠,补偿透镜层430可以被安置在堆叠的顶部以补偿下面透镜组458、456、454、452的总焦度。此类配置提供与可用波导/透镜配对一样多的感知焦平面。波导的光提取光学元件和透镜的聚焦方面两者都可以是静态的(例如,不是动态的或电活性的)。在一些替代实施例中,使用电活性特征,任一或两者可以是动态的。
继续参考图4,光提取光学元件440a、438a、436a、434a、432a可以被配置为将光重定向出它们相应的波导,并且对于与波导相关联的特定深度平面以适当的发散或准直量来输出该光。结果,具有不同关联深度平面的波导可具有光提取光学元件的不同配置,其取决于关联深度平面而输出具有不同发散量的光。在一些实施例中,如在此所讨论的,光提取光学元件440a、438a、436a、434a、432a可以是体积或表面特征,该体积或表面特征可以被配置为以特定角度输出光。例如,光提取光学元件440a、438a、436a、434a、432a可以是体积全息图、表面全息图和/或衍射光栅。2015年6月25日公布的美国专利公开号2015/0178939中描述了光提取光学元件,诸如衍射光栅,其通过引用整体并入本文。
在一些实施例中,光提取光学元件440a、438a、436a、434a、432a是形成衍射图案的衍射特征,或“衍射光学元件”(在此也称为“DOE”)。优选地,DOE具有相对低的衍射效率,使得光束中的仅一部分光利用DOE的每个交叉点朝向眼睛410偏转,而其余部分经由全内反射继续移动通过波导。因此,携带图像信息的光可以被分成多个相关的出射光束,该出射光束在多个位置处离开波导,并且对于在波导内反弹的特定准直光束,结果是朝向眼睛304的出射发射的相当均匀的图案。
在一些实施例中,一个或多个DOE可以在它们主动衍射的“开启”状态和它们不显著衍射的“关闭”状态之间可切换。例如,可切换DOE可以包括聚合物分散的液晶层,其中微滴在主体介质中包括衍射图案,并且微滴的折射率可以切换为基本上匹配主体材料的折射率(在这种情况下,图案不会明显衍射入射光),或者微滴可以切换到与主体介质的折射率不匹配的折射率(在这种情况下,图案主动衍射入射光)。
在一些实施例中,深度平面或景深的数量和分布可以基于观看者眼睛的瞳孔大小或取向而动态变化。景深可能与观看者的瞳孔大小成反比。结果,随着观看者眼睛的瞳孔的大小减小,景深增加,使得由于该平面的位置超出眼睛的焦深而无法辨别的一个平面可能变得可辨别,并且随着瞳孔大小的减小而更加聚焦且与景深的增加成比例。类似地,用于向观看者呈现不同图像的间隔开的深度平面的数量可以随着减小的瞳孔大小而减少。例如,在不调整眼睛对从一个深度平面到另一深度平面的调节的情况下,观看者可能无法在一个瞳孔大小下清楚地感知第一深度平面和第二深度平面两者的细节。然而,对于处于另一瞳孔大小的用户而言,这两个深度平面可以同时足够聚焦而不改变调节。
在一些实施例中,显示系统可以基于瞳孔大小或取向的确定,或者基于接收指示特定瞳孔大小或取向的电信号,来改变接收图像信息的波导的数量。例如,如果用户的眼睛无法区分与两个波导相关联的两个深度平面,则控制器460(其可以是本地处理和数据模块260的实施例)可以被配置或编程为停止向这些波导之一提供图像信息。有利地,这可以减少系统的处理负担,从而提高系统的响应能力。在波导的DOE在开启和关闭状态之间可切换的实施例中,当波导确实接收到图像信息时,DOE可以切换到关闭状态。
在一些实施例中,可能希望出射光束满足具有比观看者眼睛直径小的直径的条件。然而,鉴于观看者瞳孔大小的可变性,满足该条件可能具有挑战性。在一些实施例中,通过响应于观看者瞳孔大小的确定而改变出射光束的大小,在宽范围的瞳孔大小上满足该条件。例如,随着瞳孔大小减小,出射光束的大小也可能减小。在一些实施例中,可以使用可变孔径来改变出射光束大小。
可穿戴系统400可以包括对世界470的一部分进行成像的面向外成像系统464(例如,数码相机)。世界470的该部分可以被称为世界相机的视野(FOV),并且成像系统464有时被称为FOV相机。世界相机的FOV可以与观看者210的FOV相同或不同,该观看者210的FOV包含观看者210在给定时间感知的世界470的一部分。例如,在一些情况下,世界相机的FOV可大于可穿戴系统400的观看者210的FOV。观看者可以观看或成像的整个区域可以被称为视域(FOR)。FOR可以包括围绕可穿戴系统400的立体角的4π球面度,因为穿戴者可以移动他的身体、头部或眼睛以感知空间中的基本上任何方向。在其它上下文中,佩戴者的运动可能更加受限,并且因此佩戴者的FOR可能对向更小的立体角。从面向外成像系统464获得的图像可用于跟踪用户做出的姿势(例如,手或手指姿势)、检测用户前面的世界470中的对象,等等。
可穿戴系统400可以包括音频传感器232,例如麦克风,以捕获环境声音。如上所述,在一些实施例中,可以定位一个或多个其它音频传感器以提供对确定语音源的位置有用的立体声接收。作为另一个示例,音频传感器232可以包括定向麦克风,该定向麦克风还可以提供关于音频源所在位置的有用的定向信息。可穿戴系统400可以使用来自面向外成像系统464和音频传感器232两者的信息来定位语音源,或者确定特定时刻的活动说话者,等等。例如,可穿戴系统400可以单独使用语音识别或结合说话者的反射图像(例如,如在镜子中看到的)来确定说话者的身份。作为另一个示例,可穿戴系统400可以基于从定向麦克风获取的声音来确定扬声器在环境中的位置。可穿戴系统400可以采用语音识别算法解析来自说话者位置的声音,以确定语音的内容并使用声音识别技术来确定说话者的身份(例如,姓名或其他人口统计信息)。
可穿戴系统400还可以包括面向内成像系统466(例如,数码相机),该面向内成像系统466观察用户的运动,诸如眼睛运动和面部运动。面向内成像系统466可用于捕获眼睛410的图像,以确定眼睛304的瞳孔的大小和/或取向。面向内成像系统466可用于获得图像以用于确定用户正在看的方向(例如,眼睛姿势)或用于用户的生物特征识别(例如,经由虹膜识别)。在一些实施例中,可以为每只眼睛使用至少一个相机,以独立地分别确定每只眼睛的瞳孔大小或眼睛姿势,从而允许对每只眼睛的图像信息的呈现被针对该眼睛动态地定制。在一些其它实施例中,仅确定单只眼睛410的瞳孔直径或取向(例如,每双眼睛仅使用单个相机),并假设为对于用户的双眼是相似的。可以分析由面向内成像系统466获得的图像以确定用户的眼睛姿势或情绪,可穿戴系统400可以使用该眼睛姿势或情绪来决定应向用户呈现哪些音频或视觉内容。可穿戴系统400还可以使用姿势传感器(例如,诸如IMU、加速度计、陀螺仪等的传感器)来确定头部姿势(例如,头部位置或头部取向)。
可穿戴系统400可以包括用户输入设备466,用户可以通过该用户输入设备466向控制器460输入命令以与可穿戴系统400交互。例如,用户输入设备466可以包括触控板、触摸屏、操纵杆、多自由度(DOF)控制器、电容式传感设备、游戏控制器、键盘、鼠标、方向键(D-pad)、魔杖、触觉设备、图腾(例如,用作虚拟用户输入设备),等等。多DOF控制器可以在控制器的一些或所有可能的平移(例如,向左/向右、向前/向后或向上/向下)或旋转(例如,偏航、俯仰或滚动)中感测用户输入。支持平移运动的多自由度控制器可以被称为3DOF,而支持平移和旋转的多DOF控制器可以被称为6DOF。在一些情况下,用户可以使用手指(例如,拇指)在触敏输入设备上按压或滑动,以向可穿戴系统400提供输入(例如,向由可穿戴系统400提供的用户界面提供用户输入)。在可穿戴系统400的使用期间,用户输入设备466可以由用户的手握持。用户输入设备466可以与可穿戴系统400进行有线或无线通信。
在许多实现方式中,可穿戴系统可以包括除上述可穿戴系统的组件之外或替代的其它组件。例如,可穿戴系统可以包括一个或多个触觉设备或组件。触觉设备或组件可操作以向用户提供触感。例如,当触摸虚拟内容(例如,虚拟对象、虚拟工具、其它虚拟构造)时,触觉设备或组件可以提供压力或纹理的触感。触感可以复制虚拟对象表示的物理对象的感觉,或者可以复制虚拟内容表示的想象对象或角色(例如,龙)的感觉。在一些实现方式中,触觉设备或组件可由用户佩戴(例如,用户可佩戴手套)。在一些实现方式中,触觉设备或组件可由用户握持。
可穿戴系统可以例如包括一个或多个物理对象,该一个或多个物理对象可由用户操纵以允许与可穿戴系统进行输入或交互。这些物理对象在此可以被称为图腾(totem)。一些图腾可能采用无生命对象的形式,诸如例如一块金属或塑料、墙壁、桌子表面。在某些实现方式中,图腾实际上可能没有任何物理输入结构(例如,键、触发器、操纵杆、轨迹球、摇杆开关)。相反,图腾可以简单地提供物理表面,并且可穿戴系统可以渲染用户界面以便用户看起来在图腾的一个或多个表面上。例如,可穿戴系统可以渲染计算机键盘和触控板的图像,使其看起来驻留在图腾的一个或多个表面上。例如,可穿戴系统可以将虚拟计算机键盘和虚拟触控板渲染为看起来在薄矩形铝板的表面上,该薄矩形铝板可以用作图腾。矩形板本身不具有任何物理键、触控板或传感器。然而,可穿戴系统可以检测用户对矩形板的操纵或交互或触摸,作为经由虚拟键盘或虚拟触控板做出的选择或输入。用户输入设备466(如图4中所示)可以是图腾的实施例,其可以包括触控板、触摸板、触发器、操纵杆、轨迹球、摇杆或虚拟开关、鼠标、键盘、多自由度控制器或另一物理输入设备。用户可以单独或结合姿势使用图腾,以与可穿戴系统或其他用户交互。
可与本公开的可穿戴设备、HMD和显示系统一起使用的触觉设备和图腾的示例在美国专利公开号2015/0016777中进行了描述,其通过引用整体并入本文。
图5是用于与虚拟用户界面交互的方法500的示例的过程流程图。方法500可以由在此描述的可穿戴系统执行。可穿戴系统可以使用方法500的实施例来检测可穿戴系统的FOV中的人或文件。
在框510处,可穿戴系统可以识别特定的UI。UI的类型可以由用户预先确定。可穿戴系统可以基于用户输入(例如,手势、视觉数据、音频数据、感官数据、直接命令等)识别需要填充特定UI。UI可以特定于安全场景,其中系统的佩戴者正在观察向佩戴者呈现文件的用户(例如,在旅行检查站处)。在框520处,可穿戴系统可以为虚拟UI生成数据。例如,可以生成与UI的边界、一般结构、形状等相关联的数据。此外,可穿戴系统可以确定用户物理位置的地图坐标,使得可穿戴系统可以显示与用户物理位置相关的UI。例如,如果UI以身体为中心,则可穿戴系统可以确定用户的身体姿势、头部姿势或眼睛姿势的坐标,使得可以围绕用户显示环形UI或可以在墙壁上或在用户前面显示平面UI。在此处描述的安全上下文中,UI可以被显示为好像UI正在围绕着向系统佩戴者呈现文件的旅行者,使得佩戴者可以在看旅行者和旅行者的文件的同时容易地观看UI。如果UI以手为中心,则可以确定用户手的地图坐标。这些地图点可以通过经由FOV相机接收的数据、感官输入或任何其它类型的收集数据导出。
在框530处,可穿戴系统可以将数据从云发送到显示器,或者数据可以从本地数据库发送到显示器组件。在框540处,基于发送的数据向用户显示UI。例如,光场显示器可以将虚拟UI投影到用户的一只或两只眼睛中。一旦创建了虚拟UI,在框550处,可穿戴系统可以简单地等待来自用户的命令以在虚拟UI上生成更多虚拟内容。例如,UI可以是围绕用户身体或用户环境中的人(例如,旅行者)的身体的以身体为中心的环。可穿戴系统然后可以等待命令(手势、头部或眼睛运动、声音命令、来自用户输入设备的输入等),并且如果它被识别(框560),则与命令相关联的虚拟内容可以显示给用户(框570)。
可穿戴系统可以采用各种与地图绘制相关的技术,以便在渲染的光场中实现高景深。在绘制虚拟世界时,有利于了解真实世界中的所有特征和点,以准确描绘与真实世界相关的虚拟对象。为此,从可穿戴系统的用户捕获的FOV图像可以通过包括传达有关真实世界的各个点和特征的信息的新图片而被添加到世界模型中。例如,可穿戴系统可以收集一组地图点(诸如2D点或3D点)并找到新的地图点来渲染更准确的世界模型版本。可以将第一用户的世界模型(例如,通过诸如云网络的网络)传达给第二用户,使得第二用户可以体验围绕第一用户的世界。
图6A、6B和6C是示例可穿戴系统600A、600B和600C的框图,它们也可以单独称为或统称为可穿戴系统600。示例可穿戴系统600A、600B(图6B)和/或600C(图6C)中所示的一些或全部组件可以是图2中所示的可穿戴系统200的一部分。这些可穿戴系统600A、600B和600C中的每一个都包括系统600A的组件,并且示例系统600B和600C各自包括附加组件,其在下面进一步详细描述。
在图6A、6B和6C的示例中,可穿戴系统600可以包括地图620,该地图620可以包括地图数据库710(如图7所示)中的数据的至少一部分。地图可以部分地驻留在本地可穿戴系统上,并且可以部分地驻留在可通过有线或无线网络访问的网络存储位置(例如,在云系统中)。姿势过程610可以在可穿戴计算架构(例如,处理模块260或控制器460)上执行,并且利用来自地图620的数据来确定可穿戴计算硬件和/或用户和/或图腾的位置和取向。当用户正在体验系统并在世界中操作时,可以根据运行中收集的数据计算姿势数据。数据可以包括图像、来自传感器(诸如惯性测量单元,其通常包括加速度计和陀螺仪组件)的数据以及与真实或虚拟环境中的对象相关的表面信息。
稀疏点表示可以是同时定位和地图绘制(例如,SLAM或vSLAM,指的是其中输入仅是图像/视觉的配置)过程的输出。该系统可以被配置为不仅可以找出各种组件在世界上的位置,还可以了解世界是由什么组成的。姿势可以是实现许多目标的构建块,包括填充地图、使用来自地图的数据和/或确定如何对与用户对应的化身制作动画。
在一个实施例中,稀疏点位置可能本身并不完全足够,并且可能需要更多信息来产生多焦点AR、VR或MR体验。密集表示可以用来至少部分地填补该空白,密集表示通常是指深度地图信息。此类信息可以从称为立体640的过程计算,其中使用诸如三角测量或飞行时间感测的技术来确定深度信息。
在示例性可穿戴系统600中,图像信息和活动模式(例如使用活动投影仪创建的红外模式)、从图像相机获取的图像或手势/图腾650可以用作立体过程640的输入。大量的深度地图信息可以融合在一起,并且其中的一些可以用表面表示来概括。例如,数学上可定义的表面可能是高效的(例如,相对于大型点云)并且是其它处理设备(如游戏引擎)的可消化输入。因此,立体过程(例如,深度地图)640的输出可以在融合过程630中组合。姿势610也可以是该融合过程630的输入,并且融合630的输出变成填充地图过程620的输入。子表面可以诸如在地形绘制中彼此连接,以形成更大的表面,并且地图变成点和表面的大混合体。
为了解决混合现实模块660中的各个方面,可以利用各种输入。例如,游戏参数可以是输入以确定系统的用户正在玩在不同位置处与一个或多个怪物的怪物战斗游戏,怪物在各种条件下(诸如,如果用户射击怪物)死亡或逃跑,不同位置的墙壁或其它对象,等等。世界地图可以包括关于对象位置的信息或对象的语义信息(例如,诸如对象是平的还是圆的、水平的还是垂直的、桌子还是灯等的分类)的信息,并且世界地图可以成为对混合现实的另一个有价值的输入。相对于世界的姿势也成为输入,并且对几乎所有交互系统都起着关键作用。
来自用户的控制或输入是对可穿戴系统600的另一输入。如在此所述,用户输入可包括视觉输入、手势、图腾、音频输入、感官输入等。为了四处走动或玩游戏,例如用户可能需要指示可穿戴系统600关于他或她想要做什么。除了只是在空间中移动自己之外,还有可以利用的各种形式的用户控件。在一个实施例中,图腾(例如,用户输入设备,可替代地称为控制器)或诸如玩具枪的对象可由用户握持并由系统跟踪。该系统优选地将被配置为知道用户正握持该物品并了解用户正与该物品进行何种交互(例如,如果图腾或对象是枪,则该系统可被配置为了解位置和取向,以及用户是否正在点击触发器或其它感测到的按钮或元件,该按钮或元件可能配备有传感器,诸如IMU,这可能有助于确定正在发生的事情,即使此类活动不在任何相机的视野内)。
手势跟踪或识别也可以提供输入信息。可穿戴系统600可以被配置为跟踪和解释用于按钮按压、用于打手势向左或向右、停止、抓取、握持等的手势。例如,在一种配置中,用户可能想在非游戏环境中翻阅电子邮件或日历,或者与另一人或玩家“碰拳”。可穿戴系统600可以被配置为利用最小量的手势,该手势可以是也可以不是动态的。例如,手势可以是简单的静态手势,如张开手用于停止、竖起大拇指用于ok、下竖大拇指用于不ok;或手向右或向左或向上/向下翻转用于定向命令。
眼睛跟踪是另一种输入(例如,跟踪用户正在看哪里,以控制显示技术以按照特定深度或范围渲染)。在一个实施例中,可以使用三角测量确定眼睛的聚散度,并且然后使用为该特定人开发的聚散度/调节模型,可以确定调节。眼睛跟踪可由眼睛相机执行以确定眼睛注视(例如,一只或两只眼睛的方向或取向)。其它技术可用于眼睛跟踪,诸如例如通过放置在眼睛附近的电极进行的电位测量(例如眼电图)。
语音跟踪可以是可以单独使用或与其它输入(例如,图腾跟踪、眼睛跟踪、手势跟踪等)组合使用的另一个输入。语音跟踪可以包括单独或组合的语音识别、声音识别。可穿戴系统600可以包括从环境接收音频流的音频传感器(例如,麦克风)。可穿戴系统600可以将声音识别技术并入来确定谁在说话(例如,讲话是来自ARD的佩戴者还是来自另一个人或语音(例如,由环境中的扬声器发送的录制语音)),以及将语音识别技术并入以确定正在说什么。本地数据和处理模块260或远程处理模块270(图2)可以处理来自麦克风的音频数据(或另一流中的音频数据,诸如例如用户正在观看的视频流),以通过应用各种语音识别算法(诸如例如隐马尔可夫模型、基于动态时间扭曲(DTW)的语音识别、神经网络、深度学习算法(诸如深度前馈和循环神经网络)、端到端自动语音识别、机器学习算法(参考图7描述))或使用声学建模或语言建模的其它算法等,来识别语音内容。
本地数据和处理模块260或远程处理模块270还可以应用声音识别算法,该声音识别算法可以识别讲话者的身份,诸如讲话者是可穿戴系统600的用户210还是用户与之正在交谈的另一人。一些示例声音识别算法可以包括频率估计、隐马尔可夫模型、高斯混合模型、模式匹配算法、神经网络、矩阵表示、向量量化、讲话者分类、决策树和动态时间扭曲(DTW)技术。语音识别技术还可以包括反讲话者技术,诸如群组模型和世界模型。频谱特征可用于表示讲话者特性。本地数据和处理模块或远程数据处理模块270可以使用参考图7描述的各种机器学习算法来执行语音识别。
可穿戴系统的实现方式可以经由UI使用这些用户控制或输入。UI元素(例如,控件、弹出窗口、气泡、数据输入字段等)可用于例如消除信息的显示,例如对象的图形或语义信息。
关于相机系统,示例可穿戴系统600可以包括三对相机:布置在用户面部的两侧的相对宽的FOV或被动SLAM相机对;不同的相机对,其在用户前方取向以处理立体成像过程640并且还捕获用户面部前方的手势和图腾/对象跟踪。用于立体过程640的FOV相机和相机对可以是面向外成像系统464(图4中所示)的一部分。可穿戴系统600可以包括朝向用户的眼睛取向的眼睛跟踪相机(其可以是图4中所示的面向内成像系统462的一部分)以便对眼睛向量和其它信息进行三角测量。可穿戴系统600还可以包括用于将纹理注入场景的一个或多个纹理光投影仪(诸如红外(IR)投影仪)。
可穿戴系统600可以包括化身处理和渲染系统690。化身处理和渲染系统690可以被配置为基于上下文信息生成、更新、动画化和渲染化身。化身处理和渲染系统690中的一些或全部可以作为本地处理和数据模块260的一部分实现,或经由通信链路262、264分别单独或组合地实现到远程处理模块270和远程数据存储库。在各种实施例中,多个化身处理和渲染系统690(例如,如在不同的可穿戴设备上实现的那样)可用于渲染虚拟化身670。例如,第一用户的可穿戴设备可用于确定第一用户的意图,而第二用户的可穿戴设备可以确定化身的特征并基于从第一用户的可穿戴设备接收的意图来渲染第一用户的化身。例如如将参考图9A和9B所述,第一用户的可穿戴设备和第二用户的可穿戴设备(或其它此类可穿戴设备)可以经由网络进行通信。
图6B是示例可穿戴系统600B的框图,该示例可穿戴系统600B可以是图2中所示的可穿戴系统200的一部分。除了可穿戴系统600A的组件之外,可穿戴系统600B包括运动模块694、人体工程学模块696、历史模块698和传感器组合模块962。在一些实施例中,诸如通过包括模块692、694、696和/或698的化身处理和渲染系统690,692、694、696和698中的一个或多个可以被组合在可穿戴系统600的一个或多个组件中。
人体工程学模块696可以包括与人(例如用户)的手和/或手臂相关的人体工程学数据。在一些实施例中,人体工程学数据可以具有与3D空间中的位置(例如点)相关联的针对每只手的置信水平。在一些实施例中,人体工程学数据可以表示右手正在3D空间中的特定位置处的可能性的热图。类似地,人体工程学数据还可以包括左手在在3D空间中的特定位置处的可能性的热图,其中热图的较热区域指示手正在该位置处的较高置信度。在一些实施例中,3D空间中的位置可以是相对于用户的。在一些实施例中,3D空间中的位置可以是相对于由MR系统定义的世界坐标系的。在一些实施例中,3D空间中的位置是3D空间内的点、区域或体积(例如,其中3D空间是用户的真实世界环境)。例如,左手的热图会指示用户左边直接伸手可及的点具有是左手的高可能性/置信度,因为右手无法伸到左边那么远,因为右臂不够长,无法延伸那个距离。然而,相比之下,在眼睛水平处直接在用户前面的点对于右手和左手两者可能具有50%的置信水平。
在一些实施例中,人体工程学模块696也可以包括手方向数据。在一些实施例中,取向和位置人体工程学数据可以组合,但在其它实施例中,取向和位置人体工程学数据可以是分开的数据(例如,用于取向的热图和用于位置的分开的热图)。例如,MR系统可以使用一个或多个传感器,诸如图3和图6中描述的那些传感器,以在用户左肩正前方六英寸处识别用户的手掌。基于人体工程学,热图可以指示手是右手的可能性为80%,而手是左手的可能性仅20%。
运动模块694可以包括用户的手和/或图腾(或其它手持控制器/设备)的速度和/或加速度数据。速度数据可用于确定图腾是否从一个用户的手变成了另一个用户的手。
传感器组合模块692可以起到以下作用:组合两个或更多个传感器的数据和相关联的置信水平,以确定哪只手是活动的手的单个预测和相关联的置信水平。
历史模块698可以包括历史数据,诸如用户的一只手或两只手的过去位置、定位和/或置信水平。在一些实施例中,历史数据可用于对传入的传感器数据进行情境化和/或错误检查。
尽管在特定位置处的可穿戴系统600B中描绘了传感器组合模块692、运动模块694、人体工程学模块696和历史模块698,但是该模块可以位于示例可穿戴系统600B中的任何其它合适的位置。在一些实施例中,模块692-698可以在分开的处理器上定位和处理,并且输出被馈送到可穿戴系统600B中。
图6C是示例可穿戴系统600C的框图,其可以是图2中所示的可穿戴系统200的一部分。除了可穿戴系统600A的组件之外,可穿戴系统600C还包括活动的手模块602,该活动的手模块602可以包括可穿戴系统600B的传感器组合模块692、运动模块694、人体工程学模块696和历史模块698中的一个或多个。在一些实施例中,当两个或更多个模块一起工作时,它们可以起到以下作用:确定用户的活动的手(或多个手)、位置和/或活动的手的位置。在一些实施例中,传感器组合模块692可以位于处理模块260或270上。
图7是MR环境700的示例的框图。MR环境700可以被配置为从一个或多个用户可穿戴系统(例如,可穿戴系统200或显示系统220)或固定房间系统(例如,房间相机等)接收输入(例如,来自用户的可穿戴系统的视觉输入702、固定输入704(诸如室内相机)、来自各种传感器的感官输入706、手势、图腾、眼睛跟踪、来自用户输入设备466的用户输入等)。可穿戴系统可以使用各种传感器(例如,加速度计、陀螺仪、温度传感器、运动传感器、深度传感器、GPS传感器、面向内成像系统、面向外成像系统等)来确定用户环境的位置和各种其它属性。该信息可以被进一步补充来自房间内固定相机的信息,该信息可以从不同的视点提供图像或各种提示。由相机(诸如室内相机和/或面向外成像系统的相机)获取的图像数据可以简化为一组地图绘制点。
一个或多个对象识别器708可以爬取接收的数据(例如,点的集合),并且在地图数据库710的帮助下识别或绘制点、标记图像,将语义信息附连到对象。地图数据库710可以包括随时间推移收集的各种点及其对应的对象。各种设备和地图数据库可以通过网络(例如局域网、广域网等)彼此连接以访问云端。
基于该信息和地图数据库中点的集合,对象识别器708a至708n可以识别环境中的对象。例如,对象识别器可以识别面部、人、窗户、墙壁、用户输入设备、电视、文件(例如,如在此安全示例中所述的旅行票、驾驶执照、护照)、用户环境中的其它对象等。一个或多个对象识别器可以专门用于具有某些特性的对象。例如,对象识别器708a可用于识别面部,而另一对象识别器可用于识别文件。
可以使用多种计算机视觉技术来执行对象识别。例如,可穿戴系统可以分析由面向外成像系统464(如图4中所示)获取的图像以执行场景重建、事件检测、视频跟踪、对象识别(例如,人或文件)、对象姿势估计、面部识别(例如,来自环境中的人或文件上的图像)、学习、索引、运动估计或图像分析(例如,识别文件中的标记,诸如照片、签名、标识信息、旅行信息等)等等。一种或多种计算机视觉算法可用于执行这些任务。计算机视觉算法的非限制性示例包括:尺度不变特征变换(SIFT)、加速鲁棒特征(SURF)、定向FAST和旋转BRIEF(ORB)、二进制鲁棒不变可扩展关键点(BRISK)、快速视网膜关键点(FREAK)、Viola-Jones算法、Eigenfaces方法、Lucas-Kanade算法、Horn-Schunk算法、Mean-shift算法、视觉同时定位和地图绘制(vSLAM)技术、顺序贝叶斯估计器(例如,卡尔曼滤波器、扩展卡尔曼滤波器等)、束调节、自适应阈值化(和其它阈值化技术)、迭代最近点(ICP)、半全局匹配(SGM)、半全局块匹配(SGBM)、特征点直方图、各种机器学习算法(诸如例如,支持向量机、k-最近邻算法、朴素贝叶斯、神经网络(包括卷积或深度神经网络)或其它监督/无监督模型等)等等。
对象识别可以附加地或替代地由多种机器学习算法执行。一旦经过训练,机器学习算法就可以由HMD存储。机器学习算法的一些示例可以包括监督或非监督机器学习算法,包括回归算法(诸如例如,普通最小二乘回归)、基于实例的算法(诸如例如,学习向量量化)、决策树算法(诸如例如,分类和回归树)、贝叶斯算法(诸如例如,朴素贝叶斯)、聚类算法(诸如例如,k-means聚类)、关联规则学习算法(诸如例如,先验算法)、人工神经网络算法(诸如例如,感知器)、深度学习算法(诸如例如,深度玻尔兹曼机或深度神经网络)、降维算法(诸如例如,主成分分析)、集成算法(诸如例如,堆叠泛化)和/或其它机器学习算法。在一些实施例中,可以为单独的数据集定制单独的模型。例如,可穿戴设备可以生成或存储基本模型。基本模型可用作生成特定于数据类型(例如,远程呈现会话中的特定用户)、数据集(例如,在远程呈现会话中获得的用户的一组附加图像)、条件情况或其他变体的附加模型的起点。在一些实施例中,可穿戴HMD可以被配置为利用多种技术来生成用于分析聚合数据的模型。其它技术可以包括使用预定义的阈值或数据值。
基于该信息和地图数据库中点的集合,对象识别器708a到708n可以识别对象并且用语义信息补充对象以赋予对象生命。例如,如果对象识别器将一组点识别为一扇门,则系统可能会附加一些语义信息(例如,门具有铰链并且具有围绕铰链90度的运动)。如果对象识别器将一组点识别为镜子,则系统可以附加语义信息,即镜子具有可以反射房间中对象图像的反射表面。语义信息可以包括在此描述的对象的可供性。例如,语义信息可以包括对象的法线。系统可以分配一个向量,其方向指示对象的法线。随着时间推移,地图数据库会随着系统(其可能驻留在本地或通过无线网络访问)积累来自世界的更多数据而增长。一旦识别出对象,信息就可以传输到一个或多个可穿戴系统。例如,MR环境700可以包括关于发生在加利福尼亚的场景的信息。环境700可以被传输到纽约的一个或多个用户。基于从FOV相机和其它输入接收的数据,对象识别器和其它软件组件可以绘制从各种图像中收集的点,识别对象等,使得可以将场景准确地“传递”给可能在世界的不同地方的第二用户。环境700也可以使用拓扑图用于定位目的。
图8是渲染与识别对象相关的虚拟内容的方法800的示例的过程流程图。方法800描述了如何向可穿戴系统的用户呈现虚拟场景。用户可能在地理上远离场景。例如,用户可能在纽约,但可能想要观看当前在加利福尼亚发生的场景,或者可能想要与居住在加利福尼亚的朋友一起去散步。
在框810处,可穿戴系统可以从用户和其他用户接收关于用户环境的输入。这可以通过各种输入设备和地图数据库中已经拥有的知识来实现。在框810处,用户的FOV相机、传感器、GPS、眼睛跟踪等向系统传送信息。在框820处,系统可基于该信息确定稀疏点。稀疏点可用于确定姿势数据(例如、头部姿势、眼睛姿势、身体姿势或手势),该姿势数据可用于显示和理解用户周围环境中各种对象的取向和位置。在框830处,对象识别器708a-708n可以爬取这些收集的点并且使用地图数据库识别一个或多个对象。然后在框840处可以将该信息传送到用户的个人可穿戴系统,并且在框850处可以相应地向用户显示所需的虚拟场景。例如,可以在适当的取向、位置等处显示所需的虚拟场景(例如,CA中的用户),与纽约用户的各种对象和其它周围环境有关。
图9A示意性地图示了描绘彼此交互的多个用户设备的整体系统视图。计算环境900包括用户设备930a、930b、930c。用户设备930a、930b和930c可以通过网络990彼此通信。用户设备930a-930c可以各自包括网络接口以经由网络990与远程计算系统920(其也可以包括网络接口971)通信。网络990可以是LAN、WAN、对等网络、无线电、蓝牙或任何其它网络。计算环境900还可以包括一个或多个远程计算系统920。远程计算系统920可以包括聚类并位于不同地理位置的服务器计算机系统。用户设备930a、930b和930c可以经由网络990与远程计算系统920通信。
远程计算系统920可以包括远程数据存储库980,该远程数据存储库980可以维护关于特定用户的物理和/或虚拟世界的信息。数据存储装置980可以存储与用户、用户环境(例如,用户环境的世界地图)或用户化身的配置相关的信息。远程数据存储库可以是图2中所示的远程数据存储库280的实施例。远程计算系统920还可以包括远程处理模块970。远程处理模块970可以是图2中所示的远程处理模块270的实施例。远程处理模块970可以包括可以与用户设备(930a、930b、930c)和远程数据存储库980通信的一个或多个处理器。处理器可以处理从用户设备和其它来源获得的信息。在一些实现方式中,处理或存储装置的至少一部分可以由本地处理和数据模块260(如图2中所示)提供。远程计算系统920可以使给定用户能够与另一用户共享关于特定用户自己的物理和/或虚拟世界的信息。
用户设备可以是可穿戴设备(例如HMD或ARD)、计算机、移动设备或单独或组合的任何其它设备。例如,用户设备930b和930c可以是图2中所示的可穿戴系统200的实施例(或图4中所示的可穿戴系统400),该可穿戴系统可以被配置为呈现AR/VR/MR内容。
一个或多个用户设备可以与图4中所示的用户输入设备466一起使用。用户设备可以获得关于用户和用户环境的信息(例如,使用图4中所示的面向外成像系统464)。用户设备和/或远程计算系统1220可以使用从用户设备获得的信息来构造、更新和构建图像、点和其它信息的集合。例如,用户设备可以处理获取的原始信息并将处理的信息发送到远程计算系统1220以供进一步处理。用户设备还可以将原始信息发送到远程计算系统1220以供处理。用户设备可以从远程计算系统1220接收经处理的信息并在向用户投影之前提供最终处理。用户设备还可以处理获得的信息并将经处理的信息传递给其他用户设备。用户设备可以在处理所获取的信息的同时与远程数据存储库1280通信。多个用户设备和/或多个服务器计算机系统可以参与对所获取的图像的构造和/或处理。
关于物理世界的信息可以随着时间推移而开发并且可以基于由不同用户设备收集的信息。虚拟世界的模型也可以随着时间推移而开发并基于不同用户的输入。此类信息和模型有时在此可以被称为世界地图或世界模型。如参考图6和图7所述,由用户设备获取的信息可用于构造世界地图910。世界地图910可包括图6A中描述的地图620的至少一部分。各种对象识别器(例如708a,708b,708c……708n)可用于识别对象和标记图像,以及将语义信息附加到对象。这些对象识别器也在图7中描述。
远程数据存储库980可用于存储数据并促进世界地图910的构造。用户设备可不断更新关于用户环境的信息并接收关于世界地图910的信息。世界地图910可由用户或其他人创建。如在此所讨论的,用户设备(例如,930a、930b、930c)和远程计算系统920单独或组合地可以构造和/或更新世界地图910。例如,用户设备可以与远程处理通信模块970和远程数据存储库980通信。用户设备可以获取和/或处理关于用户和用户环境的信息。远程处理模块970可以与远程数据存储库980和用户设备(例如930a、930b、930c)通信以处理关于用户和用户环境的信息。远程计算系统920可以修改由用户设备(例如930a、930b、930c)获取的信息,诸如例如选择性地裁剪用户的图像,修改用户的背景,向用户的环境添加虚拟对象,用辅助信息注释用户的语音等。远程计算系统920可以将处理的信息发送给相同和/或不同的用户设备。
图9B描绘了相应可穿戴系统的两个用户进行远程呈现会话的示例。该图中示出两个用户(在该示例中名为Alice 912和Bob 914)。两个用户佩戴他们相应的可穿戴设备902和904,该可穿戴设备可以包括参考图2描述的HMD(例如,系统200的显示设备220),用于在远程呈现会话中表示其他用户的虚拟化身。两个用户可以使用可穿戴设备进行远程呈现会话。注意图9B中分开两个用户的垂直线旨在说明Alice和Bob在经由远程呈现进行通信时可能(但不必)在两个不同的位置(例如,Alice可能在她位于亚特兰大的办公室内,而Bob在波士顿的户外)。
如参考图9A所述,可穿戴设备902和904可以彼此通信或与其他用户设备和计算机系统通信。例如,Alice的可穿戴设备902可以例如经由网络990(如图9A中所示)与Bob的可穿戴设备904通信。可穿戴设备902和904可以跟踪用户的环境和环境中的运动(例如,经由相应的面向外成像系统464,或一个或多个位置传感器)和讲话(例如,经由相应的音频传感器232)。可穿戴设备902和904还可以基于由面向内成像系统462获取的数据来跟踪用户的眼睛运动或注视。在一些情况下,可穿戴设备还可以捕获或跟踪用户的面部表情或其它身体运动(例如,手臂或腿部运动),其中用户靠近反射表面并且面向外成像系统464可以获得用户的反射图像以观察用户的面部表情或其它身体运动。
可穿戴设备可以使用从第一用户和环境获取的信息来对虚拟化身制作动画,该虚拟化身将由第二用户的可穿戴设备渲染,以在第二用户的环境中创建第一用户的有形存在感。例如,可穿戴设备902和904、远程计算系统920单独或组合地可以处理Alice的图像或运动以供Bob的可穿戴设备904呈现,或者可以处理Bob的图像或运动以供Alice的可穿戴设备902呈现。如在此进一步描述的,可以基于上下文信息来渲染化身,诸如例如用户的意图、用户的环境或化身被渲染的环境,或人类的其它生物特征。
尽管示例仅涉及两个用户,但在此描述的技术不应限于两个用户。使用可穿戴设备(或其它远程呈现设备)的多个用户(例如,两个、三个、四个、五个、六个或更多)可以参与远程呈现会话。特定用户的可穿戴设备可以在远程呈现会话期间向该特定用户呈现其他用户的化身。此外,虽然该图中的示例将用户示为站在环境中,但用户不需要站立。在远程呈现会话期间,任何用户都可以站立、坐下、跪下、躺下、走或跑,或者处于任何位置或运动。用户还可以处于不同于在此示例中描述的物理环境中。在进行远程呈现会话时,用户可能处于分开的环境中或可能处于相同的环境中。并非所有用户都需要在远程呈现会话中佩戴其相应的HMD。例如,Alice可以使用其它图像采集和显示设备,诸如网络相机和计算机屏幕,而Bob佩戴可穿戴设备904。
图10示出由可穿戴系统的用户感知的化身的示例。图10中所示的示例化身1000可以是站在房间中物理植物后面的Alice的化身(图9B中所示)。化身可以包括各种特征,诸如例如大小、外观(例如,肤色、面色、发型、衣服、面部特征(例如,皱纹、痣、瑕疵、丘疹、酒窝等))、位置、取向、运动、姿势、表情等。这些特征可以基于与化身相关联的用户(例如,Alice的化身1000可以具有实际人物Alice的一些或全部特征)。如在此进一步描述的,化身1000可以基于上下文信息被制作动画,该上下文信息可以包括对化身1000的一个或多个特征的调节。虽然在此一般地描述为表示人(例如,Alice)的外貌,但是这是为了说明而不是限制。Alice的化身可以表示除了Alice之外的另一个真实或虚构人类的外貌、拟人化对象、生物或任何其它真实或虚构的表示。此外,图10中的植物不必是物理的,而可以是由可穿戴系统呈现给用户的植物的虚拟表示。此外,可以向用户呈现与图10中所示附加或不同的虚拟内容。
可穿戴系统可以使用装扮技术对化身制作动画。装扮的目标是基于简单的、人类可理解的控制提供令人愉悦的、高保真的化身变形。通常,最吸引人的变形至少部分地基于真实世界的样本(例如,真实人类执行身体运动、关节、面部扭曲、表情等的摄影测量扫描)或艺术指导的发展(其可基于真实世界采样)。混合现实环境中化身的实时控制可以由参考图6B描述的化身处理和渲染系统690的实施例提供。
装扮包括用于将关于化身的身体的变形(例如,面部扭曲)的信息传送到网格上的技术。网格可以是3D点(例如,顶点)以及共享这些顶点的一组多边形的集合。图10示出围绕化身1000的眼睛的网格1010的示例。对网格制作动画包括通过将一些或所有顶点移动到3D空间中的新位置来使网格变形。这些位置可能受到装备的底层骨骼的位置或方向(如下所述)的影响,或者通过由时间或用于动画的其它状态信息(诸如面部表情)参数化的用户控件来影响。用于这些网格变形的控制系统通常称为装备。图6B的示例化身处理和渲染系统690包括可以实现装备的3D模型处理系统680。
因为独立地移动每个顶点以实现所需的变形可能是非常耗时和费力的,所以装备通常将常见的、所需的变形提供为计算机化命令,该计算机化命令使得更容易控制网格。对于诸如电影的高端视觉效果制作,可能存在足够的制作时间让装备执行大量数学计算以实现高度逼真的动画效果。但是对于实时应用(诸如在混合现实中),变形速度可能非常有利,并且可以使用不同的装扮技术。装备通常利用依赖于骨架系统和/或混合形状的变形。
骨架系统将变形表示为层次结构中的关节集合。关节(也称为骨骼)主要表示空间变换,包括平移、旋转和依比例变化。可以表示关节的半径和长度。骨架系统是表示关节之间父子关系的层次结构,例如,肘关节是肩关节的子级,并且腕关节是肘关节的子级。子关节可以相对于其父关节进行变换,使得子关节继承父级的变换。例如,移动肩部会导致所有关节向下移动到指尖。尽管它的名字如此,骨架不需要表示真实世界的骨架,但可以描述装备中使用的层次结构来控制网格的变形。例如,头发可以表示为链中的一系列关节,由于化身面部扭曲引起的皮肤运动(例如,表示化身的表情,诸如微笑、皱眉、大笑、说话、眨眼等)可以由面部装备控制的一系列面部关节表示,肌肉变形可以由关节建模,并且衣服的运动可以由关节网格来表示。
骨架系统可以包括可能类似于化身的生物骨架的低级(在一些情况下也称为低阶)核心骨架。该核心骨架可能无法准确映射到一组真实的解剖正确的骨骼,但可以通过具有类似取向和位置中的骨骼的至少子集来类似于真实的骨骼集合。例如,锁骨可以大致平行于地面,大致位于颈部和肩部之间,但可能不是完全相同的长度或位置。表示肌肉、衣服、头发等的高阶关节结构可以在低级骨架的顶部分层。装备可以仅对核心骨架制作动画,并且可以基于核心骨架动画使用例如蒙皮技术(例如,诸如线性混合蒙皮(LBS)的顶点加权方法)由装扮逻辑以算法方式来驱动高阶关节结构。实时装扮系统(诸如化身处理和渲染系统690)可以对可以分配给给定顶点(例如,8个或更少)的关节数量施加限制,以由3D模型处理系统680提供高效、实时的处理。
混合形状包括网格的变形,其中一些或所有顶点基于权重在3D空间中移动了所需的量。每个顶点对于特定的混合形状目标可能具有其自己的定制运动,并且同时移动顶点将生成所需的形状。可以通过使用混合形状权重来应用混合形状的度数。装备可以组合应用混合形状以实现所需的变形。例如,要产生微笑,装备可应用混合形状来拉动唇角、抬高上唇、降低下唇、移动眼睛、眉毛、鼻子和酒窝。
装备通常构建在具有驱动更高阶层的更低、更简单的层的层中,这产生更逼真的网格变形。装备可以实现由装备控制逻辑驱动的骨架系统和混合形状二者。控制逻辑可以包括关节之间的约束(例如,目标、取向和位置约束,以提供特定运动或父子关节约束);动态(例如,头发和衣服);基于姿势的变形(PSD,其中骨架的姿势用于基于与所定义姿势的距离来驱动变形);机器学习技术(例如,参考图7描述的那些),其中从(骨架系统或混合形状的)一组较低级别的输入中学习所需的较高级别的输出(例如,面部表情);等等。一些机器学习技术可以利用径向基函数(RBF)。
在一些实施例中,3D模型处理系统680实时地在混合现实环境中对化身制作动画,以(与MR系统的用户)进行交互并在用户环境中提供适当的上下文的化身行为(例如,基于意图的行为)。系统680可以驱动包括核心骨架层次结构的分层化身控制系统,该分层化身控制系统进一步驱动表情、约束、变换(例如,3D空间中的顶点的运动,诸如平移、旋转、缩放、剪切)等的系统,该系统控制化身的更高级别的变形(例如,混合形状、校正)以产生化身的所需运动和表情。
图11A示出用于确定用户的活动的手、活动的手位置、活动的手取向和/或相关联的置信水平的示例过程1100a。在框1102处,数据处理模块(诸如活动的手模块602或处理模块260或270)可以从一个或多个传感器接收传感器数据,例如n个传感器,其中n可以是2、3或12个传感器。在一些实施例中,传感器可以是图2、3、6A-C中描述的传感器中的一个或多个传感器,诸如视觉传感器(例如灰度视觉相机、彩色视觉相机等)和深度传感器。在一些实施例中,传感器数据可以是原始数据。在一些实施例中,传感器数据可以包括已经包括与数据相关联的初始置信水平的传感器数据。在一些实施例中,传感器数据可以包括用于用户的一只手或两只手的数据和/或可以包括用于一个或多个图腾的数据。图腾可以用作用户手的大致位置,因为图腾通常握在用户的手中。在一些实施例中,位置偏移计算可以应用于图腾位置以考虑用户的手在图腾上方,同时抓握图腾。
在框1104处,可将人体工程学数据应用于所接收的传感器数据。在一些实施例中,这可能意味着表示用户(或其他一般人)的人体工程学约束的一组规则或代码可以修改所接收的传感器数据。在一些实施例中,修改可以包括以下一项或多项的初始估计或更新估计:用户的哪只手是活动的手,哪只手与接收的传感器数据相关联,用户的一只手或两只手的取向,用户的一只或两只手的位置,以及与一个或多个组件相关联的置信度(或整个估计的单个置信度)。
人体工程学数据可以表示右手在3D空间中的特定位置(例如,在用户周围的环境中)的可能性。人体工程学数据可以包括与人(例如用户)的手和/或手臂相关的任何数据。在一些实施例中,人体工程学数据可以具有与3D空间中的位置(例如点)相关联的每只手的置信水平。在一些实施例中,人体工程学数据可以表示右手在3D空间中的特定位置的可能性的热图。类似地,人体工程学数据还可以包括左手在3D空间中的特定位置的可能性的热图,其中热图的较热区域指示手在该位置处的较高置信度。在一些实施例中,3D空间中的位置可以相对于用户。在一些实施例中,3D空间中的位置可以相对于由MR系统定义的世界坐标系。在一些实施例中,3D空间中的位置是3D空间内的点、区域或体积(例如,其中3D空间是用户的真实世界环境)。例如,左手的热图将指示用户左手直接伸手可及的点是左手的可能性/置信度很高,因为右手无法伸到左边那么远,因为右臂不够长,无法延伸那个距离。然而,相比之下,直接在用户眼睛前面的点对于右手和左手二者可具有50%的置信水平。
在一些实施例中,在框1104中应用的人体工程学数据也可以包括手取向数据。在一些实施例中,取向和人体工程学数据可以被组合,但在其它实施例中,取向和人体工程学数据可以是单独的数据(例如,用于取向的热图和用于位置的单独热图)。例如,MR系统可以使用一个或多个传感器,诸如图3和图6中描述的那些传感器,以在用户左肩正前方六英寸处识别用户的手掌。基于人体工程学,热图可以指示手是右手的可能性为80%,而手是左手的机会仅20%。在一些实施例中,靠近身体的左侧点更容易用右手完成,而远离身体的左侧点更容易用左手完成。
在一些实施例中,人体工程学数据可以表示用户的手如何具有在用户的身体周围的区域/体积,在该区域/体积处更可能找到该手。例如,虽然有可能用左手伸手去抓右耳,但一个人更有可能用右手做所述抓挠。在一些实施例中,人体工程学数据可以表示用户的每只手的单个锥体(即右手的锥体,左手的锥体),以表示用户的手最有可能位于的体积。锥体可以从用户的肘部开始(如果用户的手臂垂直向下靠在用户的一侧)并远离用户的身体向外扩展(例如在z方向中)。
在一些实施例中,表示用户的手最可能位于的位置的区域或体积可能更复杂,并且甚至可以包括具有不同权重的多个区域。例如,最高权重可用于上述初始锥体,但围绕初始锥体的较宽锥体可被分配稍低的权重,并且任一锥体之外的所有区域可被分配低权重。可以使用定义人体工程学区域的替代方法。在一些实施例中,还可以考虑手取向数据。在一些实施例中,在框1104中应用的人体工程学数据可以存储在图6A的化身处理和渲染系统690、图6B的人体工程学模块696,或图6C的活动的手模块602中。
在一些实施例中,来自框1104的输出可以是具有初始估计的传感器数据,或者如果初始估计已经与从框1102接收的传感器数据相关联则是具有所更新估计的传感器数据,该估计是对哪只手(左手或右手)是活动的手、手的位置、手的定位和/或与这些相关联的置信度的估计。
在框1106,历史数据可以应用于框1104的输出。历史数据可以包括历史数据,诸如用户的一只手或两只手的过去位置、定位和/或置信水平。在一些实施例中,历史数据还可以包括从各个传感器接收的过去数据。在一些实施例中,历史数据可用于将传入的传感器数据置于上下文中和/或错误检查。例如,如果图腾或用户的手在后续帧读数之间移动超过阈值,则系统可以确定错误。例如,如果每1/60秒读取一个帧,但系统计算出帧之间一米的移动(当阈值为0.1米时),则系统可能会为用户的手位置分配低置信水平。
作为另一个示例,应用历史数据可以意味着比较单个传感器的帧之间的数据。如果图腾的位置在阈值帧数内没有移动,则系统可以确定图腾已经冻结,这可能导致数据不可靠,并且因此系统可以为该数据分配低置信水平。在一些实施例中,应用历史数据可意味着检查数据的有效性以确定与这些相关联的惯用手、位置、取向和/或置信水平。在一些实施例中,在框1106中应用的历史数据可以存储在图6A的化身处理和渲染系统690、图6B的历史模块698和/或图6C的活动的手模块602中。
在框1108处,运动数据可以应用于框1106的输出。在一些实施例中,这可能意味着表示用户(或其他通用人)或图腾的运动的一组规则或代码可以修改来自框1104的输出。例如,运动数据可以包括这样的规则,其表示如果用户的手快速移动则用户不太可能改变哪只手握持图腾。这可能有助于确定哪只手是活动的手(例如,握持图腾的手),例如,如果历史数据示出右手正握持图腾,并且速度高于阈值速度(因此将其分类为“快”),则活动的手仍然可能是右手。这在例如系统对于单个帧的哪只手是活动的手(即惯用手)的置信水平低的情况下可能是有利的。速度(和/或其它运动数据)和/或历史数据可以应用于惯用手估计,以便更准确地估计活动的手。在一些实施例中,在框1108中应用的运动数据可以存储在图6A的化身处理和渲染系统690、图6B的运动模块694和/或图6C的活动的手模块602中。
在一些实施例中,框1104、1106和1108可以具有不同的顺序。例如,可以首先应用1108历史数据,然后可以应用1104人体工程学数据,然后可以应用1108运动数据。其它顺序可能是合适的。
在框1110处,可以将前面框的n个输出(例如,每n个传感器一个)组合成用户的活动的手、位置、取向和/或与这些相关联的准确度的单个估计。组合和协调该估计可以包括一个或多个框。该一个或多个框可以是一组规则,用于比较数据以确定哪个最可靠。数据可靠性可取决于n个传感器的FOV相对于彼此的位置以及相对于这些FOV捕获数据的位置而变化。在一些实施例中,来自框1110的n个传感器的组合和协调的传感器数据可以存储在图6A的化身处理和渲染系统690、图6B的传感器组合模块692和/或图6C的活动的手模块602中。
图12示出一组示例传感器的示例一组FOV。在该示例中,存在八个传感器。1202可以表示第一和第二传感器组合的FOV,诸如一对左右面向内(向内,如彼此面对)灰度世界(背离用户,朝向世界)视觉相机,诸如图3的相机316。1204和1206可以表示面向外的左右灰度视觉相机,该灰度视觉相机可以彼此远离地指向以便对用户周围的更大空间成像。1208可以表示彩色视觉相机。1210可以表示深度传感器。1212可以表示用户佩戴的MR设备的左右显示器的FOV。在一些实施例中,可以使用更多或更少的传感器,诸如2、3或10个传感器。在一些实施例中,可以使用相同的传感器,但是相对于彼此采用不同的配置。
在一些实施例中,可以基于n个传感器的FOV来定义区域。区域可以取决于传感器相对于彼此的角度和距离而改变。图13示出用于图12中描述的一组传感器的示例一组区域。在一些实施例中,可以基于传感器的中心FOV与FOV的边缘来定义区域。例如,1302可以基本上定义两个面向内世界相机的整个FOV。1304可以定义在一对面向内世界相机的中心区域和边缘区域之间的边界。两个边界1302、1304可以定义具有增加的手势识别能力的中心区域和具有降低的手势识别能力的边缘区域(因为手势在边缘上,所以传感器可以仅感测手的一部分)。
在一些实现方式中,可以在框1110中使用区域来帮助组合和协调来自n个传感器的传感器数据。例如,如果来自过程1100a的n个传感器中的一个或两个传感器是来自两个面向内世界相机的手势数据(例如手在x、y、z处的位置),则框1110可以对在1302和1304之间的区域中捕获的数据应用操作,因此,与将在边界1304内的中心FOV中检测到的类似手势相比,置信水平可能降低(例如,减半)。附加规则可以在过程1100a的框1110中使用,并且可以起作用以:将来自一个传感器的数据优先于来自不同传感器的冲突数据,基于组合的传感器数据计算更新的置信水平(例如,如果第一传感器确定活动的手是右手,置信度为70%,并且第二传感器确定活动的手是右手,置信度为75%,则组合置信水平可能>75%),确定数据具有错误,丢弃不准确的数据,取决于在传感器的FOV中捕获数据的位置对来自特定传感器的数据进行优先级排序,等等。来自框1110的输出可以是对哪只手是活动的手、活动的手位置、活动的手定位和/或与这些输出中的每一个输出相关联的置信水平的单个估计。可以输出来自框1110的估计以在框1112中进一步使用。
在框1112处,可以将手估计输出到化身处理和渲染系统690。化身处理和渲染系统690可以使用来自框1112的数据来指导与用户相关联的虚拟化身(诸如示例化身1000)的运动。在一些实施例中,例如在图10的上下文中,可以通过使用如上所述的化身装扮系统来执行运动。取决于由传感器接收的数据,手估计可能是右手、左手或两者。在一些实施例中,可以仅确定惯用手(右手对左手)、位置和/或取向的子集。
过程1100a可以在系统和/或传感器的每一帧更新处重复。例如,可以将传感器设定为以某些时间间隔(例如,每1/60秒)更新,在该时间间隔处过程在框1102处再次开始。
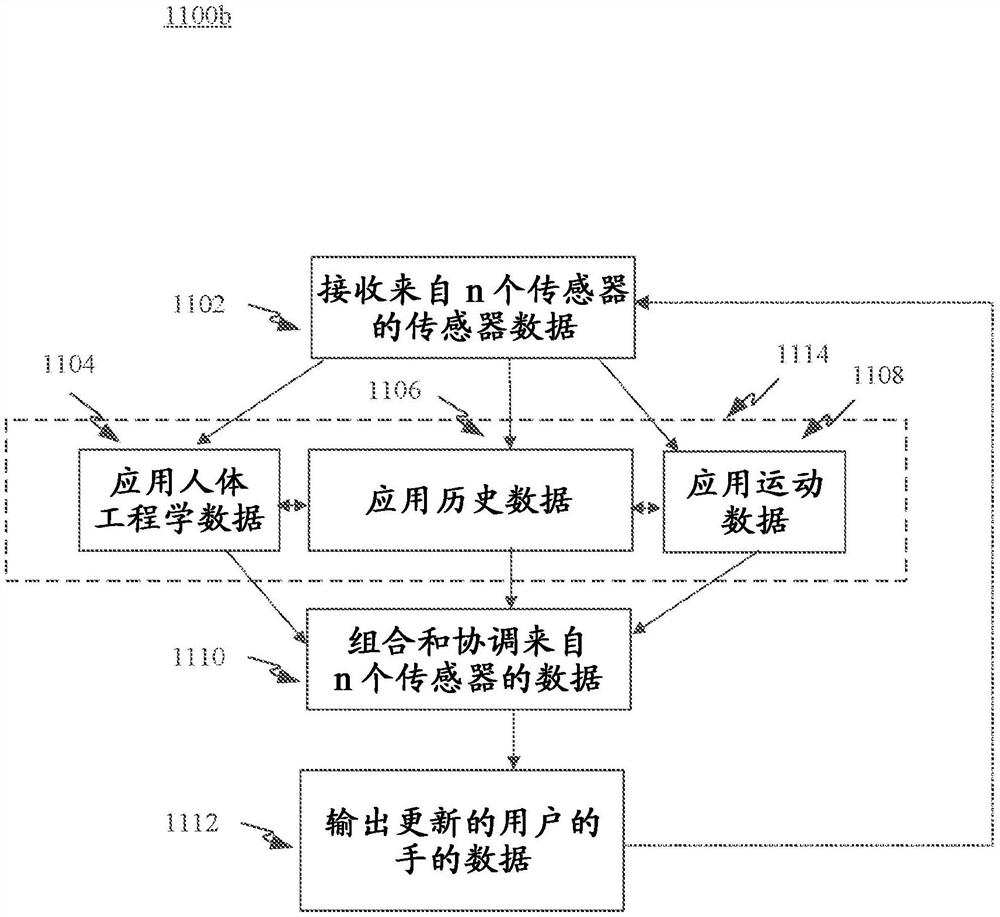
图11B示出用于确定用户的活动的手、活动的手的位置、活动的手的取向和/或相关联的置信水平的示例过程1100b。除了框1104-1108的顺序和数量外,图11B的框可以类似于图11A。在过程1100b中,过程1100a的框1104-1108可以被组合在一起成为确定与n个传感器相关联的置信水平的加权框1114。因此,这些框1104-1108可以同时或顺序执行以彼此共享输出。
框1114可以包括确定n个传感器数据中的每一个传感器数据的置信水平的一种或多种方法,该传感器数据例如包括用户简档模块(例如,如果用户简档声明用户是右手,则系统可以默认假设图腾数据表示用户的右手),和/或环境模块(例如,系统可以感测用户的环境以识别情况或上下文,诸如骑自行车,其中用户的手预期在特定位置和/或取向中,诸如在自行车的车把上或在船的桨上)。
图14示出用于确定用户的活动的手、活动的手的位置、活动的手的取向和/或相关联的置信水平的示例过程1400。在一些实施例中,ML系统可以被配置为检测用户的一只或两只活动的手。在一些实施例中,过程1400在活动的手模块602中发生。在一些实施例中,过程1400在处理模块260或270上发生。
过程1400在框1420处开始,其中从n个传感器接收传感器数据。框1420可以包括在框1402处接收传感器1数据、在框1404处接收传感器2数据,以及在框1406处接收传感器n数据。在一些实施例中,在框1420处从两个或更多个传感器接收传感器数据。在一些实施例中,从传感器接收的数据流(或“传感器数据流”)的数量可随着时间推移而改变,因此在任何给定的时间点,可以在过程1400中评估更多或更少的传感器。可以作为过程1400的一部分发送数据的示例传感器是手持控制器的一个或多个内部IMU(例如获取图腾的加速度数据)、手持控制器的外部跟踪(例如图腾上的基准点,安装在MR耳机上的相机跟踪基准点以获得真实世界中的图腾位置)、视觉传感器(例如相机,用于手势识别)、深度传感器(例如用于对象识别)等。
在一些实施例中,深度传感器可用于经由视觉算法确定惯用手。替代传感器可用于单独地或与在此公开的传感器组合来获得原始位置、取向和/或图像数据。在一些实施例中,接收的传感器数据可以是原始数据。原始数据可以是数据,诸如来自内部IMU的加速度数据,没有相关联的置信水平。
在框1408、1410和1412处,可以分析原始传感器数据并且可以确定初始加权(例如置信水平)。在一些实施例中,初始加权可以基于如上所述的历史数据。在一些实施例中,初始加权1408、1410和1412可以基于基于系统设计、传感器设计和/或人体工程学的一组规则。例如,来自图腾的数据越接近MR HMD,其可靠性可能越低。结果,系统可以被编程为执行这样的编程规则:当图腾位置在距耳机的阈值距离内,诸如在一英尺内时,该规则降低图腾数据的置信水平。作为另一个示例,系统可以被编程以降低来自不一致地输出所请求帧的传感器的数据的置信水平或加权。例如,如果传感器1周期性地不输出请求的帧,则该传感器的功率可能不足,这可能降低传感器的准确度。在一些实施例中,传感器可以多次输出相同的帧,和/或在多次重复帧后突然跳到新的帧。如果次数超过阈值,则系统可以确定传感器被冻结,这可能是由于没有足够的功率提供给传感器或EM干扰。因此,初始加权框1408、1410和1412可以包括用于丢弃或忽略传感器数据或调节(例如,降低或提高)该数据的置信水平的规则。在一些实施例中,数据的缺失(例如,跳过的帧)可能是有用的数据,并且可以在规则中利用以确定加权。可以使用用于确定接收的传感器数据的可靠性和准确度的各种其它规则。
在图14的示例中,每个接收的传感器数据与框1408、1410和/或1412中的加权相关联,但是可以基于传感器的类型不同地计算加权。在一些实施例中,图腾传感器数据的初始加权可以部分地基于数据是否出现冻结并且处于触发角。触发角可以取决于图腾设计而变化,并且例如可以是30度。图腾数据可能会在触发角处出现冻结,因为图腾被放下并且图腾底部的按钮阻止图腾平放,从而使静止设备以固定的触发角倾斜。在该情况下,与图腾数据相关联的初始加权框可能会丢弃、忽略或估计接近0%的初始置信度,因为用户的手没有握持图腾。
在一些实施例中,初始加权框1408、1410和/或1412可以使用这样的规则:基于图腾在空间中的位置来应用图腾位置的概率热图。如果图腾在右臂锥或左臂锥内,则规则可以指定高置信水平。在一些实施例中,臂锥可以被定义为起始于当上臂从肩部到肘部在用户的一侧笔直向下时用户的肘部所在的点,并且该锥体可以在z-方向中从用户向外延伸。此外,如果考虑手的取向,则置信水平可能会增加更多,因为右手和左手可能在不同时间处于空间中的同一点,但每只手都可能由于人体的生理限制,以不同的取向占据该空间。例如,右手在右锥体中时可以笔直向前取向,但是在右锥体内相同位置处的左手将成角度。
在确定初始加权之后,基于一个或多个规则,来自n个传感器的n个数据流在框1414处被组合和协调。在一些实施例中,来自n个传感器1110的框(例如,图11A和图11B)以及组合和协调框1414的协调传感器数据可以是相同的。在一个示例中,第一规则可以评估来自1408-1412的传入数据流以确定数据是用于右手、左手或二者。系统然后可以应用一个或多个规则直到确定第一只手的单个估计,并且可选地确定第二只手的单个估计。如果只接收到一只手的数据,则只确定一只手的估计。例如,图腾数据可表示单手,但一些手势可表示双手。本公开的可穿戴设备手势识别的示例还在美国专利公开号2015/0016777中描述,其全部内容通过引用并入本文。
在一些实施例中,在组合和协调框1414处使用的示例规则可以比较来自两个或更多个传感器的估计。如果对惯用手、取向和/或位置的估计一致,则框1414可以计算该估计的新的(例如更高的)置信水平。如果来自各种传感器流的估计不匹配,则系统可以评估传感器数据的获取位置。例如,在系统的视觉区域内(例如在一个或多个视觉传感器的FOV内),视觉数据应优先于来自其它传感器的数据。当在可视区域之外时,图腾数据可能反而优先。在给定区域中传感器优先于其它传感器的该组规则可以基于单个传感器的可靠性、传感器配置和/或环境条件(例如,深度传感器在低光设置下比视觉传感器更可靠)。
在框1416处,输出估计。在一些实施例中,输出可以被解释为,在给定当前和历史条件的情况下,存在左手中带有姿势Q的图腾的xx%的置信水平。随着新的数据更新被添加到系统,然后可以随着时间推移调节置信水平。估计可以用于右手、左手或二者。该估计可以用于一只手或两只手的位置和/或取向。该估计可以包括与该估计相关联的置信水平。当传感器发送新帧时,过程1400可以从框1416重复回到框1420。该过程可以定期(诸如以1/60秒的预编程帧更新)重复,或者可以间歇性(诸如基于事件)发生,或者可以基于用户输入(诸如来自化身聊天应用)发生。输出可以随后被馈送到化身处理和渲染系统,诸如图6A-6C的690,并且可以驱动与用户相关联的化身的运动。
图15示出用于组合和协调包括初始加权的传感器数据以产生跨在给定帧处的所有传感器数据(例如,在给定时间点来自一组传感器的一组读数)的单个估计的示例过程1500。组合和协调过程1414(图14)可以包括过程1500的一些或全部。过程1500在框1502处开始,其中接收预加权数据。例如,预加权数据可以是来自框1408-1412的数据。
在框1504处,评估预加权数据以确定预加权数据是否仅包括单个有效数据集。在一些实施例中,单个有效数据集可以包括用于右手的一个估计、用于左手的一个估计或用于每只手的一个估计。在一些实施例中,单个有效数据集可以包括用于右手的一个数据流、用于左手的一个数据流或用于每只手的一个数据流。
如果预加权的数据包括有效数据集,则过程进行到其中更新历史的框1506。历史可以包括历史数据,该历史数据包括关于来自传感器的过去帧输出的数据,该传感器用于评估用户的手的惯用手、位置和/或取向(例如,手跟踪)。在一些实施例中,历史还包括来自先前帧更新的过去输出结果。历史可以存储在历史模块698、化身处理和渲染系统690和/或活动的手模块602中。可替代地,历史数据可以存储在系统(诸如系统200)中的各个位置处。例如,用于传感器的历史数据可以存储在传感器本身中,或者可以存储在与每个传感器相关联的处理器中,该处理器可以包括传感器管理过程和数据。
在框1508处,过程1500利用一个或多个空闲图腾规则确定图腾是否处于空闲图腾状态。空闲图腾规则可以是如上所述的规则,例如,检查来自给定传感器的先前帧的阈值数量是否相同。在一些实施例中,可以通过检查图腾的状态并且如果图腾关闭或处于睡眠模式则将图腾分类为空闲,来确定空闲图腾。在一些实施例中,空闲图腾可以是结合触发角(诸如与水平方向成30度)具有阈值数量的帧的重复帧输出的图腾。在一些实施例中,空闲状态可以表示当用户放下图腾,将图腾放入用户的口袋,将图腾从用户的手腕上悬挂时,或图腾正在提供数据但图腾实际上不在用户的手中的其它情况。例如,空闲状态可以基于分析针对循环运动的传感器数据(例如访问历史数据)的规则来确定,该循环运动可以表示从用户手腕摆动的图腾。在一些实施例中,如果确定空闲状态,则数据可以被标记为空闲状态并且化身渲染系统可以决定不同地渲染。例如,化身渲染系统可能不渲染更新的输出结果,或者化身渲染系统可以选择改为显示可以提供更逼真的化身的空闲状态序列。例如,一个人长时间完全静止是不自然的。即使一个人没有移动,也可能存在姿势上微小的变化。在一些实施例中,如果图腾悬挂在用户的手腕上,则可以显示空闲状态序列而不是手的摆动运动。在一些实施例中,将仅确定高置信度空闲运动。在一些实施例中,可以确定空闲状态确定以便不会显示更新的输出,因为化身没有做任何有趣或有用的事情。例如,可以优选仅示出一只手在做某事,而不是一只手和一只空闲的手。在一些实施例中,空闲图腾数据可能无法从数据流中获得,并且过程进行到框1510。
在框1510处,过程1500确定数据是否包括高运动速率或加速度。在一些实施例中,运动可以是速度。可以通过访问先前帧数据并计算从第一帧到第二帧的距离差除以帧之间的时间间隔,来计算速度。在一些实施例中,运动可以是角速度。在一些实施例中,运动可以是空间中单个点、对象的一部分、整个对象、对象的棱镜(例如边界框)或任何其它合适的跟踪方法的运动。加速度可以基于IMU数据例如从嵌入在图腾或手持控制器中的IMU确定。取决于可用的数据流,可以使用确定速度和/或加速度的其它方法。在一些实施例中,速度和/或加速度数据可能不可用。速度和/或加速度可分为定义高、中和/或低速率的类别。类别可以基于特定应用。例如,用于跟踪汽车的类别比跟踪蜗牛的类别具有更高的速度。
如果运动和/或加速度处于高速率,则在框1512处,输出过程1500的结果。结果可能是估计。该估计可以包括以下中的一个或多个:一个或多个活动的手(例如左手和/或右手)、活动的手的取向和/或活动的手的位置。在一些实施例中,输出可用于驱动与用户的手和/或手臂相关联的化身的一部分的运动。在一些实施例中,输出被发送到化身处理和渲染系统690。在一些实施例中,输出被发送到数据处理模块260和/或270。
如果运动和/或加速度不是高速率,则过程1500可以进行到框1514。在框1514处,可以确定活动的手的惯用手。可以使用一组或多组规则来确定惯用手。例如,速度可以用作这样的规则的输入,该规则确定如果速度高于阈值速度则用户没有切换握持图腾的手。如果速度高于阈值速度,并且框1514的传入数据已经包含惯用手估计,则可以确定惯用手估计是相同的。
在框1504处,如果过程1500包括多于单个的有效数据集,则过程进行到框1516,其中将多个预加权的数据流彼此比较以确定它们是否彼此一致/全等,或者它们是否不同。如果数据集全等,则过程1500进行到框1506。如果数据集/流不全等,则过程进行到框1518。框1518可以与框1508相同。在一些实施例中,框1518可以仅确定低置信度空闲状态。这可能是因为,在框1504确定存在多于单个的数据集之后,该过程的目标可能是将数据剔除到单个估计。移除低置信度空闲状态可能有助于缩小剩余数据流的范围,因为移动/活动数据集可能更有趣和/或相关。在一些实施例中,全等数据可以包括多个(例如,两个)数据集,每个数据集包括作为活动的手的右手的惯用手估计。在一些实施例中,不全等的数据可以包括多个(例如两个)数据集,其中第一数据集包括左手的惯用手估计,而第二数据集包括右手的惯用手估计。在一些实施例中,存在多于两个的数据集。在一些实施例中,所有数据集必须包括被认为是全等的相同的惯用手估计。在一些实施例中,阈值数量的数据集必须匹配以便被认为是全等的,例如,9个数据集中的5个必须匹配。
在框1520处,如果数据集不全等(如在框1516处确定的),则低置信度额外点被剔除。在一些实施例中,额外点可以是额外数据点,该额外数据点可以是用于右手的多于一个的估计、用于左手的多于一个的估计或用于双手的多于一个的估计。来自框1520的输出最多可以包括用于每只手的单个数据流/估计/数据集。在一些实施例中,低置信度额外点可以是具有比第一数据集低的置信水平的单手的第二数据集。例如,用于右手的第一估计可具有90%的置信水平,而第二估计可具有30%的置信水平。第二数据集可以被从过程1500中移除,可以被移动到历史数据,或者可以用于更新第一数据集的置信水平(例如,从90%到92%)。
在一些实施例中,置信水平可以被分类为高、中和/或低置信类别。落入低置信度类别内的数据集可以在框1520处被剔除。在一些实施例中,高置信度可以高于80%,中置信度可以高于40%直至80%置信度,并且低置信度可以低于40%。可以使用其它类别,诸如具有多于或少于三个类别,或者这些类别的不同阈值。该过程可以在框1520之后进行到框1506。
在一些实施例中,过程的左手侧(框1502、1504、1516、1518和1520)可以用于将数据集缩小到用于右手的单个估计、用于左手的单个估计、或用于双手的单个估计。过程1500的右手侧(框1506-1514)可以是在已经估计可能的左手和/或右手之后的过程的一部分。此时过程1500重新评估估计,因为,即使已经做出估计,有时在框1512处输出后显示估计也没有意义(例如,图腾被冻结,所以我们不希望化身的左手正确地制作动画而右手奇怪地静止或奇怪地前后摆动)。框1512可能与框1416相同。
有利地,在此公开的方法和系统可以包括一组规则,该规则可以评估n个传感器输入的置信度值,使得当用户的手从由一种方法最优跟踪的区域移动到由不同方法最优跟踪的不同区域时,用户的手的运动和跟踪可以无缝地发生(例如,被动相机跟踪/手势识别直接在用户面前是最优的,而内部运动传感器可以提供同样精确的数据,而不管位置如何)。可以使用(例如深度)图像估计和手势识别来估计惯用手,并且可以使用6DOF控制信息来提供超出可穿戴显示器视野的更准确的手数据。使用多个数据源还有助于消除在仅使用单一数据源的情况下会发生的不确定的手估计。在视野内,由于来自多个不同来源的多个协作观察,可能会增加手姿势估计的置信度。
在此描述的系统、方法和设备各自具有若干方面,没有一个方面单独负责其所需的属性。在不限制本公开的范围的情况下,现在将简要讨论几个非限制性特征。以下段落描述了在此描述的设备、系统和方法的各种示例实现方式。一个或多个计算机的系统可以被配置为通过在系统上安装软件、固件、硬件或它们的组合来执行特定操作或动作,该软件、固件、硬件或它们的组合在操作中导致或使系统执行动作。一个或多个计算机程序可以被配置为通过包括在由数据处理装置执行时使装置执行动作的指令来执行特定操作或动作。
示例一:一种计算机化方法,由具有一个或多个硬件计算机处理器和一个或多个非暂态计算机可读存储设备的计算系统执行,该存储设备存储可由计算系统执行以执行计算机化方法的软件指令,该方法包括:访问来自混合现实设备的对应多个传感器的多个传感器数据流;对于所述多个传感器数据流中的每一个传感器数据流,确定用于传感器数据流的对应初始加权;分析所述多个传感器数据流中的惯用手信息和传感器数据流的对应初始加权,以确定整体惯用手;以及向在所述混合现实设备上执行的应用提供确定的整体惯用手。
示例二:根据示例一所述的计算机化方法,其中,所述整体惯用手指示左手或右手。
示例三:根据示例一至二中任一项所述的计算机化方法,其中,所述整体惯用手进一步指示置信水平。
示例四:根据示例一至三中任一项所述的计算机化方法,其中,置信水平响应于匹配所述多个传感器数据流中的惯用手信息而更高。
示例五:根据示例一至四中任一项所述的计算机化方法,其中,所述初始加权至少部分地基于传感器的类型。
示例六:根据示例一至五中任一项所述的计算机化方法,其中,所述传感器的类型包括以下中的至少一些:手持控制器的6DOF外部主动跟踪、手持控制器的6DOF内部运动跟踪,或手持控制器的外部被动跟踪。
示例七:根据示例六所述的计算机化方法,其中,传感器的类型进一步包括视觉传感器、深度传感器或LIDAR传感器中的一种或多种。
示例八:根据示例一至七中任一项所述的计算机化方法,其中,初始加权至少部分地基于来自对应传感器的最近数据读数的量。
示例九:根据示例一至八中任一项所述的计算机化方法,其中,所述初始加权至少部分地基于与对应传感器相关联的历史信息。
示例十:根据示例一至九中任一项所述的计算机化方法,其中,确定用于传感器数据流的初始加权包括:基于对应传感器的一个或多个特征选择一个或多个分析规则,其中,所述分析规则基于与传感器相关联的人体工程学数据、历史数据或运动数据中的一个或多个,并将所选的一个或多个分析规则应用于传感器数据流以确定对应的惯用手信息。
示例十一:根据示例十所述的计算机化方法,其中,所述一个或多个分析规则:基于与第二传感器数据流相比第一传感器数据流的所确定可靠性更高,使来自第一传感器的第一传感器数据流优先于来自第二传感器的第二传感器数据流。
示例十二:根据示例一至十一中任一项所述的计算机化方法,其中,一个或多个分析规则取决于传感器数据在传感器的视野中被捕获的位置而对来自特定传感器的传感器数据进行优先化。
示例十三:根据示例十一所述的计算机化方法,其中,至少基于第一传感器参考混合现实设备的可穿戴耳机的位置,所述第一传感器数据流与第一置信水平相关联,该第一置信水平高于与所述第二数据流相关联的第二置信水平。
示例十四:根据示例十至十三中任一项所述的计算机化方法,其中,所述一个或多个分析规则识别所述第一传感器数据流和所述第二传感器数据流之间的冲突。
示例十五:根据示例十至十三中任一项所述的计算机化方法,其中,所述一个或多个分析规则基于来自两个或更多个传感器的传感器数据流周期性地计算更新的置信水平。
示例十六:根据示例十至十三中任一项所述的计算机化方法,其中,所述一个或多个分析规则识别传感器数据流中的错误并且丢弃具有错误的传感器数据。
示例十七:根据示例十六所述的计算机化方法,其中,传感器数据流中的错误包括传感器数据中的丢失帧、不一致帧或重复帧。
示例十八:根据示例一至十七中任一项所述的计算机化方法,进一步包括:确定传感器中每个传感器的视野;确定一个或多个视野区域,该视野区域至少包括表示中心视野的第一区域,其中,传感器中的至少两个传感器提供与所述第一区域相关联的传感器数据。
示例十九:根据示例十八所述的计算机化方法,其中,与所述第一区域相关联的传感器数据关联于比所述第一区域外侧的传感器数据更高的置信水平。
示例二十:一种计算系统,包括:硬件计算机处理器;具有存储在其上的软件指令的非暂态计算机可读介质,该软件指令可由硬件计算机处理器执行以使计算系统执行包括以下操作的操作:访问来自混合现实设备的对应多个传感器的多个传感器数据流;对于所述多个传感器数据流中的每一个传感器数据流,确定用于传感器数据流的对应初始加权;分析所述多个传感器数据流中的惯用手信息和传感器数据流的对应初始加权,以确定整体惯用手;以及向在混合现实设备上执行的应用提供确定的整体惯用手。
示例二十一:根据示例二十所述的计算系统,其中,所述整体惯用手指示左手或右手。
示例二十二:根据示例二十一所述的计算系统,其中,所述整体惯用手进一步指示置信水平。
示例二十三:根据示例二十二所述的计算系统,其中,所述置信水平响应于匹配多个传感器数据流中的惯用手信息而更高。
示例二十四:根据示例二十至二十三中任一项所述的计算系统,其中,所述初始加权至少部分地基于传感器的类型。
示例二十五:根据示例二十四所述的计算系统,其中,所述传感器的类型包括以下中的至少一些:手持控制器的6DOF外部主动跟踪、手持控制器的6DOF内部运动跟踪,或手持控制器的外部被动跟踪。
示例二十六:根据示例二十五所述的计算系统,其中,传感器的类型进一步包括视觉传感器、深度传感器或激光雷达传感器中的一个或多个。
示例二十七:根据示例二十至二十六中任一项所述的计算系统,其中,所述初始加权至少部分地基于来自对应传感器的最近数据读数的量。
示例二十八:根据示例二十至二十七中任一项所述的计算系统,其中,所述初始加权至少部分地基于与对应传感器相关联的历史信息。
示例二十九:根据示例二十至二十八中任一项所述的计算系统,其中,确定传感器数据流的初始加权包括:基于对应传感器的一个或多个特征选择一个或多个分析规则,其中,所述分析规则基于与传感器相关联的人体工程学数据、历史数据或运动数据中的一个或多个,并且将所选的一个或多个分析规则应用于传感器数据流以确定对应的惯用手信息。
示例三十:根据示例二十九所述的计算系统,其中,一个或多个分析规则:基于与第二传感器数据流相比第一传感器数据流的所确定可靠性更高,使来自第一传感器的第一传感器数据流优先于来自第二传感器的第二传感器数据流。
示例三十一:根据示例三十所述的计算系统,其中,所述一个或多个分析规则取决于传感器数据在传感器的视野中被捕获的位置而对来自特定传感器的传感器数据进行优先化。
示例三十二:根据示例三十一所述的计算系统,其中,至少基于第一传感器参考混合现实设备的可穿戴耳机的位置,第一传感器数据流与第一置信水平相关联,该第一置信水平高于与第二数据流相关联的第二置信水平。
示例三十三:根据示例三十至三十二中任一项所述的计算系统,其中,所述一个或多个分析规则识别所述第一传感器数据流和所述第二传感器数据流之间的冲突。
示例三十四:根据示例三十至三十三中任一项所述的计算系统,其中,所述一个或多个分析规则基于来自两个或更多个传感器的传感器数据流周期性地计算更新的置信水平。
示例三十五:根据示例三十到三十四中任一项所述的计算系统,其中,所述一个或多个分析规则识别传感器数据流中的错误并且丢弃具有错误的传感器数据。
示例三十六:根据示例三十五所述的计算系统,其中,传感器数据流中的错误包括传感器数据中的丢失帧、不一致帧或重复帧。
示例三十七:根据示例三十六所述的计算系统,其中,软件指令进一步被配置为使硬件计算机处理器:确定传感器中每个传感器的视野;确定一个或多个视野区域,该视野区域至少包括表示中心视野的第一区域,其中,传感器中的至少两个传感器提供与第一区域相关联的传感器数据。
示例三十八:根据示例三十七所述的计算系统,其中,与所述第一区域相关联的传感器数据关联于比第一区域外侧的传感器数据更高的置信水平。
示例三十九:一种计算系统,包括:可穿戴系统的第一传感器,其被配置为获取第一用户数据,所述第一用户数据能用于确定用户的左手或右手中的哪一个是活动的;可穿戴系统的第二传感器,其被配置为获取第二用户数据,所述第二用户数据能用于确定用户的左手或右手中的哪一个是活动的;以及与第一和第二传感器通信的硬件处理器,该硬件处理器被编程为:基于与所述第一用户数据相关联的第一历史数据、第一运动数据或第一人体工程学数据中的一个或多个,确定用于所述第一用户数据的第一加权;基于与所述第二用户数据相关联的第二历史数据、第二运动数据或第二人体工程学数据中的一个或多个,确定用于所述第二用户数据的第二加权;基于所述第一用户数据、所述第一加权、所述第二用户数据和所述第二加权,确定所述用户的左手或右手中的哪一个是活动的;以及将该确定输出到化身处理和渲染系统。
示例四十:根据示例三十九所述的计算系统,其中,该输出能用于确定化身的运动。
示例四十一:根据示例三十九至四十中任一项所述的计算系统,其中,该输出能用于确定化身的手的运动。
示例四十二:根据示例三十九至四十一中任一项所述的计算系统,其中,所述硬件处理器被进一步编程为:确定所确定的活动的手的取向。
示例四十三:根据示例三十九至四十二中任一项所述的计算系统,其中,所述人体工程学数据指示用户的人体工程学约束。
示例四十四:根据示例四十三所述的计算系统,其中,所述人体工程学数据包括这样的规则,该规则指示当在第一区域中检测到手时左手是活动的高置信水平以及当在第一区域外侧检测到手时左手是活动的低置信水平。
示例四十五:根据示例四十四所述的计算系统,其中,基于所述第一用户数据和所述第二用户数据中的一个或二者来确定参照所述第一区域的手位置。
示例四十六:根据示例四十四到四十五中任一项所述的计算系统,其中,所述人体工程学数据包括这样的规则,该规则指示当在第二区域中检测到右手时右手是活动的高置信水平以及当在所述第二区域外侧检测到手时右手是活动的低置信水平。
示例四十七:根据示例三十九至四十六中任一项所述的计算系统,其中,所述历史数据指示:所述用户左手的第一过去位置或第一过去取向中的一个或多个,以及所述用户右手的第二过去位置或第二过去取向中的一个或多个。
示例四十八:根据示例三十九至四十七中任一项所述的计算系统,其中,历史数据指示如下的一个或多个热图:以一个或多个传感器的位置信息为基础的所述用户左手是活动的概率,以及以一个或多个传感器的位置信息为基础的所述用户右手是活动的概率。
示例四十九:根据示例四十七所述的计算系统,其中,所述历史数据进一步包括置信水平。
示例五十:根据示例三十九至四十九中任一项所述的计算系统,其中,所述运动数据指示:对应传感器的运动速度。
示例五十一:根据示例三十九至五十中任一项所述的计算系统,其中,所述第一加权通过第一应用历史数据、第二应用运动数据和第三应用人体工程学数据来确定。
示例五十二:根据示例三十九至五十一中任一项所述的计算系统,其中,所述硬件处理器被进一步编程为:确定被确定为活动的用户的左手或右手的位置或取向中的一个或多个。
示例五十三:根据示例三十九至五十二中任一项所述的计算系统,其中,硬件处理器被进一步编程为:确定所确定的第一加权的第一置信水平和所确定的第二加权的第二置信水平。
示例五十四:根据示例三十九至五十三中任一项所述的计算系统,其中,处理器被进一步编程为:确定对用户的左手或右手中的哪一个是活动的确定的总体置信水平。
示例五十五:一种计算机化方法,由具有一个或多个硬件计算机处理器和一个或多个非暂态计算机可读存储设备的计算系统执行,该存储设备存储可由该计算系统执行以执行该计算机化方法的软件指令,该方法包括:从可穿戴系统的第一传感器获取第一用户数据,所述第一用户数据能用于确定用户的左手或右手中的哪一个是活动的;从所述可穿戴系统的第二传感器获取第二用户数据,所述第二用户数据能用于确定用户的左手或右手中的哪一个是活动的;基于与所述第一用户数据相关联的第一历史数据、第一运动数据或第一人体工程学数据中的一个或多个,确定用于所述第一用户数据的第一加权;基于与所述第二用户数据相关联的第二历史数据、第二运动数据或第二人体工程学数据中的一个或多个,确定用于所述第二用户数据的第二加权;基于所述第一用户数据、所述第一加权、所述第二用户数据和所述第二加权,确定用户的左手或右手中的哪一个是活动的;以及将该确定输出到化身处理和渲染系统。
示例五十六:根据示例五十五所述的计算机化方法,其中,该输出能用于确定化身的运动。
示例五十七:根据示例五十五至五十六中任一项所述的计算机化方法,其中,该输出能用于确定化身的手的运动。
示例五十八:根据示例五十五至五十七中任一项所述的计算机化方法,其中,所述硬件处理器被进一步编程为:确定所确定的活动的手的取向。
示例五十九:根据示例五十五至五十八中任一项所述的计算机化方法,其中,所述人体工程学数据指示用户的人体工程学约束。
示例六十:根据示例五十九至六十中任一项所述的计算机化方法,其中,人体工程学数据包括这样的规则,该规则指示当在第一区域中检测到手时左手是活动的高置信水平和当在第一区域外侧检测到手时左手是活动的低置信水平。
示例六十一:根据示例六十所述的计算机化方法,其中,基于所述第一用户数据和所述第二用户数据中的一个或二者来确定参照所述第一区域的手位置。
示例六十二:根据示例六十至六十一中任一项所述的计算机化方法,其中,所述人体工程学数据包括这样的规则,该规则指示当在第二区域中检测到手时右手是活动的高置信水平和当在所述第二区域外侧检测到手时右手是活动的低置信水平。
示例六十三:根据示例五十五至六十二中任一项所述的计算机化方法,其中,所述历史数据指示:所述用户左手的第一过去位置或第一过去取向中的一个或多个,以及所述用户右手的第二过去位置或第二过去取向中的一个或多个。
示例六十四:根据示例五十五至六十三中任一项所述的计算机化方法,其中,所述历史数据指示如下的一个或多个热图:以一个或多个传感器的位置信息为基础的所述用户左手是活动的概率,以及以一个或多个传感器的位置信息为基础的所述用户右手是活动的概率。
示例六十五:根据示例六十三至六十四中任一项所述的计算机化方法,其中,所述历史数据还包括置信水平。
示例六十六:根据示例五十五至六十五中任一项所述的计算机化方法,其中,所述运动数据指示:对应传感器的运动速度。
示例六十七:根据示例五十五至六十六中任一项所述的计算机化方法,其中,所述第一加权通过第一应用历史数据、第二应用运动数据和第三应用人体工程学数据来确定。
示例六十八:根据示例五十五至六十七中任一项所述的计算机化方法,进一步包括确定被确定为活动的用户的左手或右手的位置或取向中的一个或多个。
示例六十九:根据示例五十五至六十八中任一项所述的计算机化方法,进一步包括确定所确定的第一加权的第一置信水平和所确定的第二加权的第二置信水平。
示例七十:根据示例五十五至六十九中任一项所述的计算机化方法,进一步包括:确定对用户的左手或右手中的哪一个是活动的确定的总体置信水平。
如上所述,上面提供的所述示例的实现方式可以包括硬件、方法或过程,和/或计算机可访问介质上的计算机软件。
在此描述和/或在附图中描绘的过程、方法和算法中的每一个可以体现在由一个或多个物理计算系统执行的代码模块、硬件计算机处理器、专用电路和/或被配置为执行特定和具体计算机指令的电子硬件中,并且由其完全或部分自动化。例如,计算系统可以包括用特定计算机指令编程的通用计算机(例如,服务器)或专用计算机、专用电路等。代码模块可以被编译并链接成可执行程序,安装在动态链接库中,或者可以用解释性编程语言编写。在一些实现方式中,特定操作和方法可以由特定于给定功能的电路来执行。
此外,本公开的功能的某些实现方式在数学上、计算上或技术上足够复杂,以至于可能需要专用硬件或一个或多个物理计算设备(利用适当的专用可执行指令)来执行该功能,例如,这是由于所涉及的计算量或复杂性,或实质上实时提供结果。例如,动画或视频可包括许多帧,每帧具有数百万个像素,并且需要专门编程的计算机硬件来处理视频数据以在商业合理的时间量内提供所需的图像处理任务或应用。
代码模块或任何类型的数据可以存储在任何类型的非暂态计算机可读介质上,诸如物理计算机存储装置,包括硬盘驱动器、固态存储器、随机存取存储器(RAM)、只读存储器(ROM)、光盘、易失性或非易失性存储器、它们的组合等。方法和模块(或数据)也可以作为生成的数据信号(例如,作为载波或其它模拟或数字传播信号的一部分)在各种计算机可读传输介质(包括基于无线和有线/基于电缆的介质)上传输,并且可以采用多种形式(例如,作为单个或多路复用模拟信号的一部分,或作为多个离散数字数据包或帧)。所公开的过程或过程步骤的结果可以持久地或以其它方式存储在任何类型的非暂态有形的计算机存储装置中,或者可以经由计算机可读传输介质进行通信。
在此描述和/或在附图中描绘的流程图中的任何过程、框、状态、步骤或功能应当被理解为潜在地表示代码模块、段或代码部分,其包括一个或多个可执行指令以用于在过程中实现特定功能(例如,逻辑或算术)或步骤。各种过程、框、状态、步骤或功能可以被组合、重新排列、添加到、从在此提供的说明性示例中删除、修改或以其它方式改变。在一些实施例中,附加的或不同的计算系统或代码模块可以执行在此描述的一些或全部功能。在此描述的方法和过程也不限于任何特定的顺序,并且与其相关的框、步骤或状态可以以其它适当的顺序执行,例如串行、并行或以一些其它方式。任务或事件可以被添加到所公开的示例实施例或从所公开的示例实施例中移除。此外,在此描述的实现方式中的各种系统组件的分离是为了说明的目的并且不应被理解为在所有实现方式中都需要此类分离。应当理解,所描述的程序组件、方法和系统通常可以集成在单个计算机产品中或打包成多个计算机产品。许多实现方式变化是可能的。
过程、方法和系统可以在网络(或分布式)计算环境中实现。网络环境包括企业范围的计算机网络、内联网、局域网(LAN)、广域网(WAN)、个域网(PAN)、云计算网络、众包计算网络、互联网和万维网。网络可以是有线或无线网络或任何其它类型的通信网络。
本公开的系统和方法各自具有若干创新方面,其中没有一个单独负责或要求在此公开的所需属性。上述各种特征和过程可以彼此独立地使用,或者可以以各种方式组合。所有可能的组合和子组合都旨在落入本公开的范围内。对本公开中描述的实现方式的各种修改对于本领域技术人员来说是显而易见的,并且在不脱离本公开的精神或范围的情况下,可以将在此定义的一般原理应用于其它实现方式。因此,权利要求不旨在限于在此所示的实现方式,而是符合与本公开、在此公开的原理和新颖特征一致的最宽范围。
在本说明书中在分开的实现方式的上下文中描述的某些特征也可以在单个实现方式中组合实现。相反,在单个实现方式的上下文中描述的各种特征也可以分开地或以任何合适的子组合在多个实现方式中实现。此外,虽然上述特征可能被描述为在某些组合中起作用,并且甚至最初要求保护,但在某些情况下可以从组合中删除来自要求保护的组合的一个或多个特征,并且要求保护的组合可以针对子组合或子组合的变体。没有单个特征或特征组对于每个和所有实施例是必需的或必不可少的。
在此使用的条件语言,例如“可以(can)”、“可(could)”、“可能(might)”、“可以(may)”、“例如”等,除非另有特别说明,或在上下文中以其它方式理解为使用,通常旨在传达某些实施例包括而其它实施例不包括某些特征、元素和/或步骤。因此,此类条件语言通常并不意在暗示特征、元素和/或步骤对于一个或多个实施例以任何方式是必需的,或者一个或多个实施例必然包括用于在具有或不具有作者输入或提示的情况下决定是否这些特征、元素和/或步骤被包括在任何特定实施例中或将在任何特定实施例中执行。术语“包含”、“包括”、“具有”等是同义词并且以开放式方式包含性地使用,并且不排除附加元素、特征、动作、操作等。此外,术语“或”以其包含的意义(而不是其排他的意义)使用,使得例如当用于连接元素列表时,术语“或”表示列表中元素中的一个、一些或全部。此外,除非另有说明,否则本申请和所附权利要求中使用的冠词“一”、“一个”和“该”应被解释为表示“一个或多个”或“至少一个”。
如在此所使用的,提及项目列表中的“至少一个”的短语是指那些项目的任何组合,包括单个成员。作为示例,“A、B或C中的至少一个”旨在涵盖:A、B、C、A和B、A和C、B和C,以及A、B和C。除非另外特别说明,否则连接语言(诸如短语“X、Y和Z中的至少一个”)与上下文一起理解为通常用于表达项目、术语等可以是X、Y或Z中的至少一个。因此,此类连接语言通常不旨在暗示某些实施例需要X中的至少一个、Y中的至少一个和Z中的至少一个各自存在。
类似地,虽然可以以特定顺序在附图中描绘操作,但是应当认识到,此类操作不需要以所示的特定次序或顺序执行,或者执行所有示出的操作,以实现所需的结果。此外,附图可以以流程图的形式示意性地描绘另一个示例过程。然而,未描绘的其它操作可以并入示意性示出的示例方法和过程中。例如,一个或多个附加操作可以在任何所示操作之前、之后、同时或之间执行。此外,在其它实现方式中,该操作可以重新排列或重新排序。在某些情况下,多任务和并行处理可能是有利的。此外,上述实现方式中各个系统组件的分离不应理解为在所有实现方式中都需要此类分离,并且应当理解,所述的程序组件和系统一般可以集成到单个软件产品中或打包成多种软件产品。此外,其它实现方式也在所附权利要求的范围内。在一些情况下,权利要求中记载的动作可以以不同的顺序执行,但仍能达到所需的结果。
- 用于化身运动的多模态手的位置和取向
- 用于评估手持个人护理设备相对于用户的位置和/或取向的系统、装置和方法