深度学习网络的优化方法、运算装置及计算机可读介质
文献发布时间:2024-04-18 19:58:30
技术领域
本发明是有关于一种机器学习技术,且特别是有关于一种深度学习网络的优化方法、运算装置及计算机可读介质。
背景技术
近年来,随着人工智能(Artificial Intelligence,AI)技术的日益更新,神经网络模型的参数量及运算复杂度也日益增长。因此,用于深度学习网络的压缩技术也随之蓬勃发展。值得注意的是,量化是压缩模型的重要技术。然而,现有量化后模型的预测准确度及压缩率仍有待改进。
发明内容
有鉴于此,本发明实施例提供一种深度学习网络的优化方法、运算装置及计算机可读介质,利用多尺度动态量化,可确保预测准确度及压缩率。
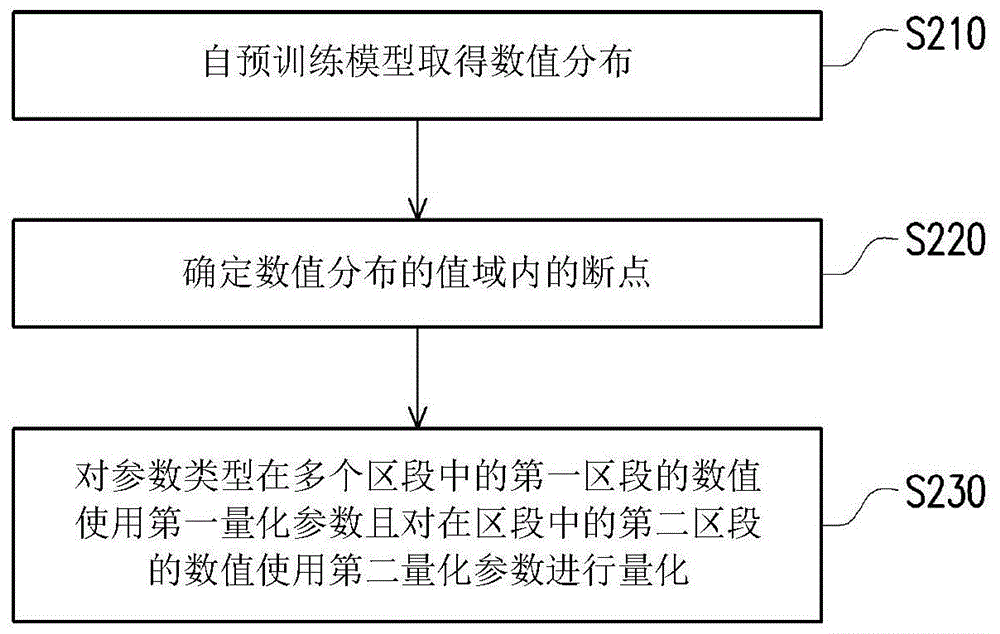
本发明实施例的深度学习网络的优化方法包括(但不仅限于)下列步骤:自预训练模型取得数值分布。确定数值分布的值域内的一个或更多个断点(breaking point)。对这参数类型在多个区段中的第一区段的数值使用第一量化参数且对在那些区段中的第二区段的数值使用第二量化参数进行量化。数值分布是深度学习网络中的参数类型的数值的统计分布。断点将值域区分成多个区段。第一量化参数不同于第二量化参数。
本发明实施例的深度学习网络的运算装置包括(但不仅限于)存储器及处理器。存储器用以存储程序代码。处理器耦接存储器。处理器经配置用以载入且执行程序代码以自预训练模型取得数值分布,确定数值分布的值域内的一个或更多个断点,并对这参数类型在多个区段中的第一区段的数值使用第一量化参数且对在那些区段中的第二区段的数值使用第二量化参数进行量化。数值分布是深度学习网络中的参数类型的数值的统计分布。断点将值域区分成多个区段。第一量化参数不同于第二量化参数。
本发明实施例的非暂态计算机可读取存储介质用于存储程序代码。处理器载入这程序代码以执行如上述的用于深度学习网络的优化方法。
基于上述,依据深度学习网络的优化方法、运算装置及计算机可读介质,依据断点将数值分布区分成多个区段,并对这些区段上的数值分别使用不同量化参数。藉此,量化后的分布可更加近似原数值分布,从而提升模型的预测准确度。
为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图式作详细说明如下。
附图说明
图1是依据本发明一实施例的运算装置的元件方块图。
图2是依据本发明一实施例的用于深度学习网络的优化方法的流程图。
图3是依据本发明一实施例的数值分布的示意图。
图4是依据本发明一实施例的断点搜寻的流程图。
图5是依据本发明一实施例的断点搜寻的流程图。
图6是依据本发明一实施例的第一阶段搜寻的示意图。
图7是依据本发明一实施例的第二阶段搜寻的示意图。
图8是依据本发明一实施例的多尺度(multiple scale)的动态固定点量化(Dynamic Fixed-Point Quantization)的示意图。
图9是依据本发明一实施例说明量化参数的示意图。
图10是依据本发明一实施例说明阶梯(step)型量化的示意图。
图11是依据本发明一实施例说明限制边界的直通估测器(Straight ThroughEstimator,STE)的示意图。
图12是依据本发明一实施例的模型修正的流程图。
图13是依据本发明一实施例的层层(layer-by-layer)阶级的量化层的流程图。
图14是依据本发明一实施例的层层后训练量化的流程图。
图15是依据本发明一实施例的模型微调的流程图。
附图符号说明:
100、运算装置;
110、存储器;
150、处理器;
S210~S130、S410~S440、S510~S560、S121~S123、S101~S110、S141~S145、S151~S159、步骤;
m、-m、绝对值最大者;
ES、区间;
FSP、第一搜寻点;
SSP、第二搜寻点;
p、BP、断点;
901、额外位元;
902、符号位元;
903、尾数;
904、整数部分;
905、小数部分;
Fl、小数长度;
x_max、数值最大者;
x_min、数值最小者。
具体实施方式
图1是依据本发明一实施例的运算装置100的元件方块图。请参照图1,运算装置100包括(但不仅限于)存储器110及处理器150。运算装置100可以是台式电脑、笔记本电脑、智能手机、平板电脑、服务器或其他电子装置。
存储器110可以是任何型态的固定或可移动随机存取存储器(Radom AccessMemory,RAM)、只读存储器(Read Only Memory,ROM)、快闪存储器(flash memory)、传统硬盘(Hard Disk Drive,HDD)、固态硬盘(Solid-State Drive,SSD)或类似元件。在一实施例中,存储器110用以存储程序代码、软件模组、组态配置、数据或档案(例如,样本、模型参数、数值分布或断点)。
处理器150耦接存储器110。处理器150可以是中央处理单元(Central ProcessingUnit,CPU)、图形处理单元(Graphic Processing unit,GPU),或是其他可编程的一般用途或特殊用途的微处理器(Microprocessor)、数字信号处理器(Digital Signal Processor,DSP)、可编程控制器、现场可编程逻辑闸阵列(Field Programmable Gate Array,FPGA)、特殊应用集成电路(Application-Specific Integrated Circuit,ASIC)、神经网络加速器或其他类似元件或上述元件的组合。在一实施例中,处理器150用以执行运算装置100的所有或部分作业,且可载入并执行存储器110所存储的各程序代码、软件模组、档案及数据。
下文中,将搭配运算装置100中的各项装置、元件及模组说明本发明实施例所述的方法。本方法的各个流程可依照实施情形而随之调整,且并不仅限于此。
图2是依据本发明一实施例的深度学习网络的优化方法的流程图。请参照图2,处理器150自预训练模型取得一个或更多个数值分布(步骤210)。具体而言,预训练模型是基于深度学习网络(例如,YOLO(You only look once)、AlexNet、ResNet、基于区段的卷积神经网络(Region Based Convolutional Neural Networks,R-CNN)、或快速R-CNN(FastCNN))。也就是说,预训练模型是对深度学习网络输入训练样本所训练得出的模型。须说明的是,这预训练模型可用于影像分类、物件侦测或其他推论,且本发明实施例不加以限制其用途。已训练的预训练模型可能达到预设准确度的标准。
值得注意的是,预训练模型在各层皆有对应的参数(例如,权重、输入/输出激活(activation)值/特征值)。可想而知,过多的参数会需要较高的运算及存储需求,参数的复杂度越高亦会提高运算量。而量化是用于减少神经网络的复杂度的其中一种技术。量化可减少用于表现激活/特征值或权重的位元数。量化方法的类型有很多种。例如,对称(symmetric)量化、非对称(Asymmetric)量化及裁减(clipping)方法。
另一方面,数值分布是深度学习网络中的一个或更多个参数类型的数值的统计分布。参数类型可以是权重、输入激活/特征值及/或输出激活/特征值。统计分布表现各数值的统计量(例如,总数)的分布情况。举例而言,图3是依据本发明一实施例的数值分布的示意图。请参照图3,预训练模型中的权重或输入/输出激活/特征值的数值分布类似高斯(Gaussian)、拉普拉斯(Laplacian)、铃状(bell-shaped)分布。值得注意的是,如图3所示,大部分数值位于数值分布的中间区段。若对这些数值使用均匀(uniform)量化,则中间区段的数值可能都被量化成零,并可能会降低模型预测的准确度。因此,需要针对用于深度学习网络的参数类型的数值,提供量化改进方案。
在一实施例中,处理器150可利用验证数据产生数值分布。例如,处理器150可将验证数据通过预训练的浮点数模型(Floating-point model)(即,预训练模型)进行推论(inference),收集各层参数(例如,权重、输入激活/特征值、输出激活/特征值),并统计这类型参数的数值以产生这参数的数值分布。
请参照图2,处理器150确定数值分布的值域内的一个或更多断点(步骤S220)。具体而言,如图3所示,数值在不同区段的总数可能有很大的差异。例如,中间区段的数值的总量明显多于两侧/尾部区段的数值的总量。而这些断点是用于将值域区分成多个区段。例如,图3中值域上的一个断点p(实数)将值域范围为[-m,m]的数值分布区分成两个对称区段。m(实数)代表数值分布中在值域上的绝对值最大者。两个对称区段包括中间区段及尾部区段。中间区段在[-p,p]的范围内,且尾部区段是范围[-m,m]内的其他区段。
以图3为例且假设数值是浮点数,若值域被区分成中间区段及尾部区段,则中间区段的数值可能需要多的位元宽度来表示小数部分,以避免过多的数值都被量化成零。此外,针对尾部区段,可能需要较多个位元宽度来表示整数部分,以提供足够能力来量化较大数值。由此可知,断点是用于将数值分类至不同量化需求的依据。此外,为了数值分布找出合适的断点,将有助于量化效果。
图4是依据本发明一实施例的断点搜寻的流程图。请参照图4,处理器150可自数值分布的值域确定多个第一搜寻点(步骤S410)。这些第一搜寻点将用于评估是否可作为断点。这些第一搜寻点位于值域内。在一实施例中,任两相邻第一搜寻点的间距相同于另两相邻第一搜寻点。在其他实施例中,相邻第一搜寻点的间距可能不同。
处理器150可依据那些第一搜寻点分别区分值域,以形成对应于每一第一搜寻点的多个评估段(步骤S420)。也就是说,任一搜寻点将值域区分成多个评估段,或是任一个评估段位于相邻两第一搜寻点之间。在一实施例中,处理器150可在数值分布的值域中确定第一搜寻空间。这第一搜寻点可对第一搜寻空间均分成多个评估段。处理器150可利用断点比例来定义第一搜寻空间及第一搜寻点。多个断点比例分别是那些第一搜寻点所占数值分布中的绝对值最大者的比例,其数学表示式(1)为:
breakpoint ratio=break point/abs max…(1)
breakpoint ratio为断点比例,break point为任一第一搜寻点、其他搜寻点或断点,abs max为数值分布中的绝对值最大者。例如,第一搜寻空间为[0.1,0.9]且间距为0.1。即,那些第一搜寻点的断点比例分别是0.1、0.2、0.3等,依此类推至0.9,并可依据数学表示式回推这些第一搜寻点。
处理器150可对每一第一搜寻点的那些评估段分别依据不同量化参数进行量化,以得出每一第一搜寻点对应的量化值(步骤S430)。也就是说,任一个搜寻点的不同评估段使用不同量化参数。以动态固定点量化为例,其量化参数包括位元宽度(Bit Width,BW)、整数长度(Integer Length,IL)及小数长度(Fraction Length,FL)。不同量化参数例如是不同整数长度及/或不同小数长度。须说明的是,不同量化方法所用的量化参数可能不同。在一实施例中,在相同位元宽度下,数值接近零的区段所用的小数长度较长,具有较大数值的区段所用的整数长度较长。
处理器150可比较那些第一搜寻点的差异量,以得出一个或更多个断点(步骤S440)。第一搜寻点的差异量包括其量化值与对应的未量化值(即,量化前的数值)之间的差异。例如,差异量是均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean SquaredError,RMSE)或平均绝对误差(Mean Absolute Error)。以MSE为例,其数学表示式(2)如下:
MSE为以MSE计算的差异量,x
x
在一实施例中,处理器150可使用那些第一搜寻点中具有较小差异量的一者或更多个作为一个或更多个断点。以一个断点为例,处理器150可选择那些第一搜寻点中具有最小差异量的一者作为断点。以两个断点为例,处理器150选择那些第一搜寻点中具有最小差异量及第二小差异量的两者作为断点。
以选择差异量最小者为例,图5是依据本发明一实施例的断点搜寻的流程图。请参照图5,处理器150可确定搜寻空间,并取得当前第一搜寻点的量化值(步骤S510)。例如,数值分布中的最大者及最小者作为搜寻空间的上限及下限。此外,对第一搜寻点所区分的两个区段使用不同量化参数进行量化。处理器150可确定当前第一搜寻点的差异量(步骤S520)。例如,量化值与未量化值的均方误差。处理器150可确定当前第一搜寻点的差异量是否小于先前差异量(步骤S530)。这先前差异量是上一次计算的另一个第一搜寻点的差异量。若当前差异量小于先前差异量,则处理器150可使用当前第一搜寻点更新断点比例(步骤S540)。例如,将第一搜寻点代入数学表示式(1)可得出断点比例。若当前差异量未小于先前差异量,则处理器150可禁能/忽略/不更新断点比例。接着,处理器150可确定当前第一搜寻点是否为搜寻空间中的最后搜寻点(步骤S550)。即,确认所有第一搜寻点皆已比较差异量。若尚有其他第一搜寻点的差异量未与其他差异量比较,则处理器150可确定下一个第一搜寻点的量化值(步骤S510)。若第一搜寻点皆已与其他第一搜寻点比较,则处理器150可输出最终的断点比例,且依据这断点比例确定断点(步骤S560)。
图6是依据本发明一实施例的第一阶段搜寻的示意图。请参照图6,这些第一搜寻点FSP中的相邻两者之间具有间距ES。在一实施例中,第一阶段搜寻可作为粗略搜寻,且可另提供第二阶段的精细搜寻。例如,第二阶段定义第二搜寻点,且相邻两第二搜寻点之间的间距小于相邻两第一搜寻点之间的间距。这些第二搜寻点也是用于评估是否可作为断点,且这些第二搜寻点位于数值分布的值域内。
在一实施例中,处理器150可依据那些第一搜寻点中具有较小差异量的一者或更多者确定第二搜寻空间。这第二搜寻空间小于第一搜寻空间。以断点比例定义,在一实施例中,处理器150可依据那些第一搜寻点中具有最小差异量的一者确定断点比例。这断点比例即是这具有最小差异量的一者所占数值分布中的绝对值最大者的比例,并可参照数学表示式(1)的相关说明,于此不再赘述。处理器150可依据这断点比例确定第二搜寻空间。这具有最小差异量的一者可位于第二搜寻空间中间。例如,断点比例是0.5,则第二搜寻空间的范围可以是[0.4,0.6],且相邻两第二搜寻点之间的间距可以是0.01(假设第一搜寻点之间的间距是0.1)。须说明的是,第一阶段中具有最小差异量的断点比例不限于位于第二搜寻空间中间。
图7是依据本发明一实施例的第二阶段搜寻的示意图。请参照图7是数值分布的局部放大图。与图6相比,图7中的相邻两第二搜寻点SSP之间的间距明显小于图6中的间距ES。此外,第二搜寻点SSP均分第二搜寻空间,并据以区分出对应的多个评估段。
相似地,针对第二阶段,处理器150可对每一第二搜寻点所区分的评估段上的数值使用不同量化参数进行量化,以得出每一第二搜寻点对应的量化值。接着,处理器150可比较那些第二搜寻点的差异量,以得出一个或更多个断点。第二搜寻点的差异量包括其量化值与对应的未量化值之间的差异。例如,差异量为MSE、RMSE或MAE。此外,处理器150可使用那些第二搜寻点中具有较小差异量的一者或更多个作为一个或更多个断点。以一个断点为例,处理器150可选择那些第二搜寻点中具有最小差异量的一者作为断点。
请参照图2,处理器150对这参数类型在多个区段中的第一区段的数值使用第一量化参数且对在那些区段中的第二区段的数值使用第二量化参数进行量化(步骤S230)。具体而言,如步骤S220的说明,断点是用于在数值分布中区分有不同量化需求的区段。因此,本发明实施例针对不同区段提供不同量化参数。例如,图8是依据本发明一实施例的多尺度(multiple scale)的动态固定点量化(Dynamic Fixed-Point Quantization)的示意图。请参照图8,一对断点BP将数值分布区分成中间区段及尾部区段,虚线代表量化参数进行量化的示意线,中间区段的数值较密集,尾部区段的数值较疏散,且两个区段利用不同的量化参数进行量化。
针对数值分布较密集的中间区段,处理器150可指派较多位元宽度给小数长度(FL);针对数值分布较稀疏的尾部区段,处理器150可指派较多位元宽度给整数长度(IL)。图9是依据本发明一实施例说明量化参数的示意图。请参照图9,以动态固定点量化为例,代表数值的12个位元中,除了额外位元901及符号(sign)位元902之外,尾数(Mantissa)903包括整数部分904及小数部分905。若小数长度为3(即,fl=3),则如图所示小数部分905占用三个位元。在一些应用情境中,动态固定点量化相较于非对称量化更加适用于硬体实现。例如,除了加法器及乘法器,神经网络加速器仅需要额外支援平移运算。然而,在其他实施例中,也可采用非对称量化或其他量化方法。
另须说明的是,若得出两个以上的断点,则不限于两种量化参数会应用在不同区段。
在一实施例中,处理器150可进行结合裁减(clipping)方法的动态固定点量化(Dynamic Fixed-Point Quantization)。处理器150可依据数值分布中的绝对值最大者及绝对值最小者确定第一量化参数、第二量化参数或其他量化参数中的整数长度。裁减方法以百分比裁减(Percentile Clipping)为例,图3所示的铃状分布中远离中间的数值非常少,而百分比裁减可减轻这些离峰值的影响。处理器150可将数值分布中位于百分之99.99的数值作为最大者Wmax,且将数值分布中位于百分之0.01的数值作为最小者Wmin。处理器150可依据方程式(5)确定例如是权重的整数长度IL
IL
须说明的是,最大者及最小者不限于上述99.99%及0.01,量化不限于结合百分比裁减,且量化方法也不限于动态固定点量化。此外,输入激活/特征值、输出激活/特征值或其他参数类型也可适用。以绝对最大值(Absolute Max Value)为例,处理器150可将一部分的训练样本作为校正样本,并推论校正样本以取得激活/特征值的数值分布。这数值分布中的最大者可作为裁减方法所用的最大者。而方程式(5)可确定例如是输入/输出激活/特征值的整数长度:
IL
IL
IL
另一方面,图10是依据本发明一实施例说明阶梯(step)型量化的示意图。请参照图10,量化方程式通常是阶梯型。数值最大者x_max及数值最小者x_min之间相同阶层的数值被量化成相同值。然而,伴随着阶梯型量化的神经网络训练,可能因参数有零梯度(gradient)而无法更新,进而难以学习。因此,需要改进量化方程式的梯度。
直通估测器(Straight Through Estimator,STE)可用于趋近量化方程式的梯度。在一实施例中,处理器150可使用限制边界(boundary constraint)的直通估测器(Straight Through Estimator,STE)来进一步减缓梯度杂讯。图11是依据本发明一实施例说明限制边界的直通估测器(Straight Through Estimator with Boundary Constraint,STEBC)的示意图。请参照图11,STEBC可避开量化方程式的微分,并设定量化方程式为输入梯度等于输出梯度。方程式(8)可表示STEBC:
lb为下限,ub为上限,fl为小数长度,R为实数,Q为已量化,
图12是依据本发明一实施例的模型修正的流程图。请参照图12,对预训练模型中的参数量化后可得到已量化模型。例如,深度学习网络中的各层的权重、输入激活/特征值及/或输出激活/特征值已被量化。在一实施例中,除了针对相同参数类型的不同区段使用不同量化参数,处理器150可针对不同参数类型使用不同量化参数。以AlexNet为例,参数类型为权重的值域范围为[2
在一实施例中,深度学习网络中加入多个量化层。这量化层可区分成用于权重、输入激活/特征值及输出激活/特征值三个部分。此外,可分别提供不同或相同的位元宽度及/或小数长度来表示量化层的三个部分的数值。藉此,可达成层层(layer-by-layer)阶级的量化层。
图13是依据本发明一实施例的层层阶级的量化层的流程图。请参照图13,处理器150可取得参数类型中的输入激活/特征值及权重(以浮点数为例)(步骤S101、S102),并分别量化权重或输入激活/特征值的数值(步骤S103、S104)(例如,前述动态固定点量化、非对称量化或其他量化方法),以取得量化的输入激活/特征值及量化的权重(步骤S105、S106)。处理器150可将量化的数值输入运算层(步骤S107)。这运算层例如执行卷积(convolution)运算、全连接(fully-connected)或其他运算。接着,处理器150可取得运算层所输出的参数类型中的输出激活/特征值(步骤S108),量化输出激活/特征值的数值(步骤S109),并据以取得量化的输出激活/特征值(步骤S110)。这些量化步骤S103、S104及S109可视为量化层。这机制可将量化层连接一般的浮点层或客制化层。此外,在一些实施例中,处理器150可使用浮点通用矩阵乘法(General Matrix Multiplication,GEMM)程式库(例如,统一计算架构(Compute Unified Device Architecture,CUDA))来加速训练及推论处理。
处理器50可后训练(post-training)已量化模型(步骤S121)。例如,利用已标记结果的训练样本训练已量化模型。图14是依据本发明一实施例的层层后训练量化的流程图。请参照图14,处理器150可利用例如百分比裁减或多尺度量化方法在已训练的权重,以确定已量化模型中的每一量化层的权重的整数长度(步骤S141、S143)。百分比裁减的范例可参酌方程式(5)的相关说明,于此不再赘述。接着,处理器150可依据已量化模型推论多个校正样本确定已量化模型中的每一量化层中的输入/输出激活/特征值的数值分布,并据以挑选裁减方法所用的最大者。处理器150可利用例如以绝对最大值或多尺度量化方法在已训练的输入/输出激活/特征值,以确定已量化模型中的每一量化层中的激活/特征值的整数长度(步骤S142、S143)。绝对最大值的范例可参酌方程式(6)、(7)的相关说明,于此不再赘述。
接着,处理器150可依据每一量化层的位元宽度限制确定每一量化层的权重/激活/特征值的小数长度(步骤S144)。方程式(11)是用于确定小数长度:
FL=BW-IL…(11)
FL为小数长度,BW为预定义的位元宽度限制,且IL为整数长度。在一些应用情况下,方程式(11)所得出的整数长度可能小于方程式(5)~(7)所得出的整数长度。例如,减少一个位元。针对整数长度的些微调整将有助于提升模型的预测准确度。最终,处理器150可取得后训练已量化模型(步骤S145)。
请参照图12,处理器150可重新训练/微调训练的量化模型(步骤S122)。在一些应用情境中,后训练已训练模型可能会降低预测准确度。因此,可通过微调来改进准确度。在一实施例中,处理器150可利用限制边界的直通估测器(STEBC)确定用于参数类型为权重的量化的梯度。这直通估测器经组态为在上限及下限之间的输入梯度等于输出梯度。如同前述说明,限制边界的直通估测器可改进梯度的趋近。而本发明实施例是针对深度学习网络中的单一层引入限制边界的直通估测器并提供层层(layer-by-layer)阶层的微调。也就是,除了对正向传递(forward propagation)提供层层量化,在反向传递(backwardpropagation)也可提供层层微调。而正向传递的层层量化可参酌图13的相关说明,于此不再赘述。
图15是依据本发明一实施例的模型微调的流程图。请参照图15,针对训练的量化模型,在反向传递中,处理器150可取得来自下一层(next layer)的梯度(步骤S151),并利用限制边界的直通估测器在输出激活/特征值的梯度进行微调(步骤S152),以取得量化层输出的梯度(步骤S153)。须说明的是,以神经网络推论为例,从神经网络的输入层开始,并依序往其输出层进行前向传播。以其中一层的相邻前后各一层而言,较靠近输入层的那一层为前一层(Previous layer),且较靠近输出层的那一层则为下一层。此外,处理器150可利用浮点运算自训练的量化模型的权重及输入激活/特征值确定其对应梯度(步骤S154),分别利用限制边界的直通估测器在权重及输入激活/特征值的梯度进行微调(步骤S155、S156),并据以确定权重的梯度及用于前一层的梯度(步骤S157、S158)。接着,处理器150可利用梯度下降(gradient decent)法更新权重(步骤S159)。这权重例如可在图13的步骤S102所用。值得注意的是,所更新的梯度仍可应用在浮点数的量化。最终,处理器150可取得微调的已量化模型(步骤S123)。藉此,可进一步提升预测准确度。
本发明实施例更提供一种非暂态计算机可读取存储介质(例如,硬盘、光盘、快闪存储器、固态硬盘(Solid State Disk,SSD)等存储介质),并用以存储程序代码。运算装置100的处理器150或其他处理器可载入程序代码,并据以执行本发明实施例的一个或更多个优化方法的相应流程。这些流程可参酌上文说明,且于此不再赘述。
综上所述,在本发明实施例的深度学习网络的优化方法、运算装置及计算机可读介质中,分析预训练模型参数的数值分布,并确定将值域区分成不同量化需求的断点。断点(breakpoint)可将不同参数类型的数值分布区分成多个区段及/或将单一参数类型的数值分布区分成多个区段。不同区段分别使用不同的量化参数。利用百分比裁减方法确定权重的整数长度,且利用绝对最大值方法确定输入/输出特征/激活值的整数长度。此外,引入限制边界的直通估测器来改进梯度的趋近。藉此,可降低准确度下降(accuracy drop),并达到可容许的压缩效果。
虽然本发明已以实施例揭露如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视申请专利范围所界定者为准。
- 基于深度学习的应答方法、装置及计算机可读存储介质
- 深度学习分布式运算方法、装置、计算机设备及存储介质
- 网络配置方法、计算机可读存储介质及网络装置
- 建筑表皮优化方法、装置、终端和计算机可读存储介质
- 基于大数据的脱硫装置脱水系统优化控制方法、系统及计算机可读介质
- 一种神经网络运算处理方法、装置及计算机可读介质
- 一种优化网络切换方法、装置及计算机可读存储介质