一种基于多源协同特征的图像描述生成方法
文献发布时间:2023-06-19 11:02:01
技术领域
本发明涉及多源特征提取、强化和融合,尤其是涉及一种基于多源协同特征的图像描述生成方法。
背景技术
图像描述生成是为输入图像自动生成描述性语句的任务。图像描述生成任务横跨计算机视觉和自然语言处理两个领域,它的主要挑战不仅在于通过物体识别、场景识别、属性和关系检测等对图像中的对象和关系进行全面理解,还在于生成符合视觉语义的流畅句子。图像描述生成的应用面很广泛,可以帮助自动驾驶领域理解道路情况,也可以帮助视觉障碍者了解所处的环境。
尽管图像描述生成任务充满挑战,经过多年的发展,图像描述生成的仍然取得了很大的进步,在基准数据集和方法上都取得了很大的进展。Lin等人(Lin,T.-Y.;Maire,M.;Belongie,S.;Hays,J.;Perona,P.;Ramanan,D.;Dollar,P.;and Zitnick,C.L.2014.Microsoft coco:Common objects in context.In ECCV.)提出图像描述生成的基准数据集COCO。Vinyals等人(Vinyals,O.;Toshev,A.;Bengio,S.;and Erhan,D.2015.Show and tell:A neural image caption generator.In CVPR.)首次借鉴机器翻译领域的编码器解码器结构作为图像描述生成的一大范式。Anderson等人(Rennie,S.J.;Marcheret,E.;Mroueh,Y.;Ross,J.;and Goel,V.2017.Self-critical sequencetraining for imagecaptioning.In CVPR)提出一种使用目标检测器提供图像先验的方法。Rennie等人(Anderson,P.;He,X.;Buehler,C.;Teney,D.;Johnson,M.;Gould,S.;andZhang,L.2018.Bottom-up and top-down attention for image captioning and visualquestion answering.In CVPR.)则使用强化学习方法来解决图像描述生成网络训练和测试时行为不一致的问题。
上述工作为图像描述生成打下了坚实基础。与早期方法中使用的网格特征相比,Anderson等人提出的通过目标检测网络提出了区域特征,因为图像中的大多数显著区域往往都是目标,因此区域特征极大地降低了视觉语义嵌入的难度。尽管取得了巨大的成功,但是区域特征仍然因缺乏上下文信息和细粒度细节而备受诟病。检测到的区域可能没有覆盖整个图像,导致无法正确地描述全局场景。同时,每个区域都由一个单一的特征向量来表示,这不可避免地会丢失大量的对象细节。然而,这些缺点是网格特征的优点,相比之下,网格特征以更零碎的形式覆盖了给定图像的所有内容。
基于这样的背景,本发明选择研究基于多源协同特征的图像描述生成方法,来弥补现有方法中的不足,得到更加准确、精细的图像描述内容,推进图像描述生成的工业化应用的步伐。
发明内容
本发明的目的在于针对传统图像报告生成方法图像特征上的缺点,提出多源特征协同的方法,提取并使用多样的图像特征,以此强化图像先验信息,进行更加准确细致的图像描述生成的一种基于多源协同特征的图像描述生成方法。
本发明包括以下步骤:
1)采用目标检测器同时提取图像的网格特征和区域特征;
2)利用特征的绝对位置信息和相对位置信息,建立一个综合关系注意力机制辅助模型进行特征理解和关系建模,辅助模型进行特征理解和两种特征自增强;
3)利用特征间的几何对齐关系,让两种特征进行交互协作增强,交换重要的视觉信息,实现更好的视觉表达。
在步骤1)中,所述采用目标检测器同时提取图像的网格特征和区域特征的具体方法可为:
(1)使用Faster-RCNN作为目标检测器,在Visual Genome数据集上进行目标检测和属性预测训练。
(2)将目标检测器检测出的置信度大于20%的检测框中对应的图像特征提取出来作为区域特征,将目标检测器骨干网络提取出的特征作为网格特征。
在步骤2)中,所述绝对位置信息为网格特征或区域特征在整张图片中的位置;所述相对位置信息可先将网格特征和区域特征的几何信息都表示为矩形框(x,y,w,h),其中(x,y)为框的左上角坐标,w,h为框的宽度和高度;然后将两个框box
得到4维相对编码向量之后,使用PE函数将其也映射为d
所述特征自增强,可在得到绝对位置编码和相对位置编码后,使用Transformer模型进行特征自增强。
在步骤3)中,所述利用特征间的几何对齐关系,让两种特征进行交互增强,交换重要的视觉信息,实现更好的视觉表达的具体步骤可为:
(1)根据区域特征和网格特征的位置信息构建几何对齐图。
(2)根据几何对齐图进行视觉信息交互和增强。
本发明具有以下突出优点:
1、本发明克服单源特征的局限性和缺点,首次考虑了多源特征的互补性,不仅考虑了各类特征内部的自我强化,而且考虑了特征之间的协同促进,构建一种多源协同特征的图像描述生成方法,设计实现了模型,得到了更加准确和精细的高质量图像描述文本。
2、本发明充分利用特征位置的元信息,且具体考虑了特征本身的绝对位置信息并具体建模了特征之间的相对位置信息,更进一步地帮助模型理解特征的内在属性以及相互之间的关系。
3、本发明设计一种轻量级的特征间交互的方法,通过不同类特征之间的几何位置信息进行更加高效和轻量级的信息交互。
附图说明
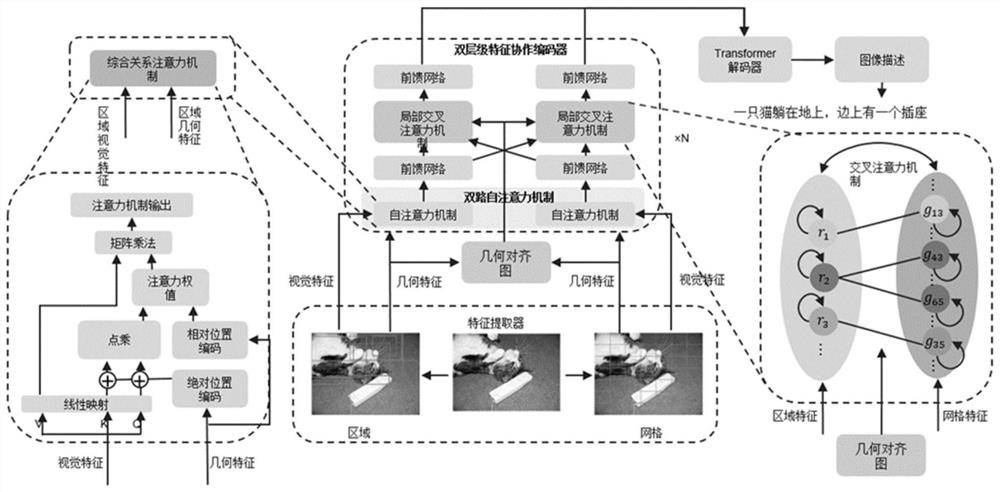
图1为本发明实施例的总体框架图。
图2为本发明实施例的特征自增强模块结构示意图。
图3为本发明实施例的特征协作增强模块结构示意图。
图4为本发明实施例的特征几何对齐图。
具体实施方式
以下实施例将结合附图对本发明作进一步的说明。
本发明提出的具有一种基于多源协同特征的图像描述生成方法的工作,整体框架如图1所示,具体包括以下几个方面:
1)图像特征提取。使用Faster-RCNN作为目标检测器,在Faster-RCNN目标检测器的基础上,合并第5个卷积模块到目标检测骨干网络中,在目标检测头网络中使用1x1的兴趣区域池化(RoI Pooling)方法,并使用两个全连接层作为目标检测器的检测头,在VisualGenome数据集上进行目标检测和属性预测训练。对于一张图片,使用训练得到的网络,计算到第5个卷积模块结束后得到特征图,然后平均池化为7x7的网格特征。对于区域特征,将目标检测器检测出的置信度大于20%的检测框中对应的图像特征提取出来作为区域特征,当区域特征不足10个时,提取置信度前10的检测结果,并设置区域特征的最大数量为100,即每张图片最多拥有100个区域特征。从而对于每张图片,可以得到7x7=49个网格特征以及10~100个区域特征。
2)特征自增强,模块结构如图2所示。特征自增强模块的目的是让网格特征和区域特征通过各自内部的交互来增强特征表达,在这个过程中,使用绝对位置信息和相对位置信息,建立一个综合关系注意力机制(CRA)辅助模型进行特征理解和关系建模。
绝对位置信息即网格特征或区域特征在整张图片中的位置,对于网格特征,可以使用一个二维坐标(i,j)来表示其绝对位置,为了将坐标输入到神经网络中,通过GPE函数将2维的坐标映射成一个高维的向量:
GPE(i,j)=[PE
其中,
其中,pos代表位置(即i或j),k代表维度。对于区域特征,通过一个线性映射RPE将其对应的矩形框(x
RPE(i)=B
其中,i是区域特征的下标,(x
为了更好地融合相对位置信息,根据基于几何信息加入了相对位置信息,为此,先将网格特征和区域特征的几何信息都表示为矩形框(x,y,w,h),其中(x,y)为框的左上角坐标,w,h为框的宽度和高度。然后将两个框box
得到4维相对编码向量之后,使用PE函数将其也映射为d
绝对位置编码和相对位置编码得到后,使用Transformer模型进行特征自增强,具体的,在Transformer模型中,有:
MHCRA(Q,K,V)=Concat(head
确定了综合关系注意力机制(CRA)计算方法之后,就可以进行特征的自增强步骤,记第l层的网格特征和区域特征分别为
其中,RPE和GPE分别是区域特征和网格特征的绝对位置编码,Ω
以上是特征自增强模块,自增强完成后,两路特征进入下一个模块,进行特征协作增强;
3)特征协作增强,模块结构如图3所示。特征协作增强模块的目的是建模两种不同特征之间的交互来增强特征表达为了更加高效地进行两种特征的交互,首先构建一个几何对齐图,G=(V,E),如图4所示,在这张几何图中,所有的区域特征和网格特征都是独立的结点,构成结点集合V,对于边集合E,一个区域特征结点和一个网格特征结点之间有一条边,当且仅当它们在几何上相交,特征协作增强模块中,使用了多头的交叉注意力机制(MHLCCA);
MHLCCA(Q,K,V)=Concat(head
其中,graph-softmax操作基于图G,对于每个结点,仅对所有与其相连的结点进行归一化操作,并将无连接的结点的权值置零;对于特征自增强模块的第l个输出
其中,Ω
特征自增强和协同增强模块交替作用3次,最后得到特征输入到语言生成模块中。
4)语言生成模块。语言生成模块在给定增强的特征
MHSA(Q,K,V)=Concat(head
其中,
M
H
第i+1个词最终预测为:
5)损失函数。整个模型分为两阶段训练,第一阶段损失函数为:
即每个词预测的概率,第二阶段的损失函数为:
为强化学习的Reinforce损失,其中,r表示CIDEr,b表示baseline,k为集束搜索大小。
具体实施结果如下:
在基准图像字幕数据集COCO上进行了实验。这个数据集包含123287张图片,每个图片都有5个不同的注释。对于数据划分,遵循广泛采用的Karpathy分割法,113287、5000、5000张图像分别用于训练、验证和测试。将d
表1
图像描述最终测试结果如表1所示。
- 一种基于多源协同特征的图像描述生成方法
- 一种基于人脸特征的汉语文本描述人脸图像生成方法