翻译模型构建方法、产物预测模型构建方法及预测方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及有机反应产物预测技术领域,具体地说是有机反应产物预测方法。
背景技术
目前人类虽然已掌握数以亿计的分子数量,但也只占未知分子数目的一小部分,阻挡化学家发现未知分子的一个重要因素是缺乏分子的合成路线,而有机合成能够为化学家们提供一种从简单结构分子破碎重组合成复杂的分子的方法。在有机合成领域早期主要依靠化学家累计的经验及制定的模板来进行合成实验,随着分子机器学习中的生成模型逐渐成熟,用数据驱动的方法应对有机合成的挑战成为未来的方向之一。
目前基于机器学习进行有机合成预测的方法主要分为两种,一种是基于模板,另一种是无模板的。基于模板的方法主要依靠反应模板库或规则库,其主要来源依靠机器学习算法的自动提取,而模板的自动提取算法主要依赖于预先存在的原子映射,提供原子映射功能的工具包则依赖于模板库和规则库,这样就形成一个死循环,最终还是要依赖于化学家前期经验积累的模板库与规则库。为了跳出这个循环,各学者在基于无模板的方法做出各种尝试,以期有效的解决这个问题。
基于上述分析,如何克服有机反应预测时对模板库和规则库的依赖,并提高有机合成预测准确率,是需要解决的技术问题。
发明内容
本发明的技术任务是针对以上不足,提供有机反应产物预测方法,来解决如何克服有机反应预测时对模板库和规则库的依赖、并提高有机合成预测准确率的技术问题。
第一方面,本发明提供翻译模型构建方法,包括如下步骤:
以公开的数据集USPTO作为原始数据集,所述数据集USPTO由包括 SMILES表达式的化学反应方程组成;
对所述原始数据集进行清洗过滤,并对SMILES表达式进行简化及正则化处理,得到预处理后数据集,所述化学反应方程中生成物的SMILES 表达式中分子所包含的元素为预处理后数据集中一类样本数据,反应物的 SMILES表达式中分子所包含的元素为所述预处理后数据集中的另一类样本数据,所述元素为化学元素;
将所述预处理后数据集划分为三个数据子集,分别为训练集、验证集和测试集;
基于Transformer模型构建翻译模型,所述翻译模型用于基于输入的生成物进行产物预测,输出预测产物以及所述预测产物对应的预测分数,所述预测产物作为生成物;
以训练集为输入优化所述翻译模型的参数,以验证集为输入对所述翻译模型的能力进行初步评估、并调整所述翻译模型的超参数,得到训练后翻译模型,以测试集为输入对所述训练后翻译模型进行测试,得到最终翻译模型。
作为优选,对所述原始数据集进行清洗过滤,包括如下步骤:
对于原始数据集中的化学反应方程,过滤掉产物数量大于1的化学反应方程;
对于原始数据集中的化学反应方程,过滤掉含有不合法SMILES表达式的化学反应方程;
对于原始数据集中的化学反应方程,删除重复的化学反应方程。
作为优选,对SMILES表达式进行简化及正则化处理,包括如下步骤:
对于过滤后的原始数据集,通过化学信息处理工具包RDKIT对 SMILES表达式进行简化,得到简化后数据集;
对于简化后数据集,从SMILES表达式筛选出分子所包含的元素,在元素之间通过空格进行分割,得到预处理后数据集。
作为优选,所述翻译模型包括:
嵌入层,所述嵌入层用于对输入的生成物和反应物提取对应的元素向量;
位置编码器,所述位置编码器用于基于元素向量和元素在化学反应方程中的位置计算每个元素对应的位置向量;
编码器,所述编码器用于以反应物相关的元素向量以及每个元素向量对应的位置向量为输入进行编码处理,提取并输出反应物相关的特征向量;
解码器,所述解码器用于以反应物相关的特征向量以及与生成物相关的元素向量以及每个元素向量对应的位置向量为输入进行解码处理,输出预测产物。
作为优选,所述位置编码器用于通过如下公式计算每个元素对应的位置向量矩阵:
其中,pos表示元素在对应化学反应方程的位置,d表示元素向量的维度,i表示元素向量的位置。
作为优选,所述编码器包括一个多头注意力机制模块,所述反应物相关的元素向量以及每个元素向量对应的位置向量作为所述编码器的输入数据,所述多头注意力机制模块用于通过attention(Q,K,V)公式对所述输入数据进行缩放采样处理,得到多个特征向量,所述特征向量的个数与所述多头注意力机制的头数相同,并将所述多个特征向量拼接处理后输出;
所述解码器包括两个多头注意力机制模块,分别为第一多头注意力机制模块和第二多头注意力机制模块,所述第一多头注意力机制模块用于对输入的生成物相关的元素向量以及每个元素向量对应的位置向量进行遮蔽处理后输出,所述第二多头注意力机制模块用于对输入的编码器的输出以及第一多头注意力机制模块的输出进行解码处理,输出预测产物;
所述遮蔽处理包括如下步骤:对于当前被预测的第n个元素,将第一多头注意力机制模块中第n个元素之后的元素向量使用Mask字符进行代替。
作为优选,以训练集为输入优化所述翻译模型的参数、并以验证集为输入调整所述翻译模型的超参数时,通过配置有Adam函数的优化器对所述翻译模型进行训练,并基于sparsemax损失函数计算预测产物与生成物之间的loss值,并采用反向传播算法对翻译模型的参数进行更新,直至loss值趋于稳定。
第二方面,本发明的产物预测模型构建方法,包括如下步骤:
通过如第一方面任一项所述的翻译模型构建方法构建并训练翻译模型,得到最终翻译模型;
以公开的数据集USPTO作为原始数据集,所述数据集USPTO由包括 SMILES表达式的化学反应方程组成;
对所述原始数据集进行清洗过滤,得到预处理后化学反应数据集;
通过RdChiral对所述预处理后化学反应数据集中每一条化学反应方程进行模板提取,得到候选模板库;
对所述候选模板库进行清洗,去除重复和无效的模板,得到模板库。
作为优选,对原始数据集进行清洗过滤,包括如下步骤:
对于原始数据集中的化学反应方程,过滤掉产物数量大于1的化学反应方程;
对于原始数据集中的化学反应方程,过滤掉含有不合法SMILES表达式的化学反应方程;
对于原始数据集中的化学反应方程,删除重复的化学反应方程;
所述无效的模板包括不完整的模板。
第三方面,本发明的产物预测方法,包括如下步骤:
通过如第二方面任一项所述的产物预测模型构建方法,构建并训练最终翻译模型以及模板库;
对于待处理的反应物,进行SMILES表达式的简化及正则化处理,得到预处理后反应物;
将预处理后反应物输入所述最终翻译模型进行产物预测,得到由候选产物组成的候选产物集合C以及由每个候选产物对应的预测分数组成的预测分数集合SC;
将预处理后生成物分别与候选产物集合C中每个产物结合,得到反应方程集合S,并通过原子匹配算法RxnMapper对反应方程集合S中所有元素进行原子匹配,得到初始集合SM;
通过RdChiral对所述初始集合SM中每个反应方程提取反应模板,并在模板库中进行模板匹配,得到匹配分数集合SSC;
基于预测分数集合SC和匹配分数集合SSC构建融合分数集合Score,所述融合分数集合Score中融合分数的计算公式为:
其中,α为预测分数的权重,β为匹配分数的权重,i为候选产物的下标,k为产物的个数;
选取融合分数集合Score中分值最高的融合分数所对应的候选产物作为最终的预测产物。
本发明的有机反应产物预测方法具有以下优点:
1、基于Transformer模型构建翻译模型,通过预处理后的数据集对翻译模型进行训练,得到最终翻译模型,通过最终翻译模型可以高效快速的进行有机反应的产物预测,且训练该翻译模型时,选取的数据集进行了清洗过滤,并对其中的SMILES表达式进行简化及正则化处理,确保了数据的有效性,通过训练集进行参数优化、通过验证集进行超参数调整,并通过测试集进行测试,保证了该翻译模型的精确性;
2、对选取的数据集进行清洗过滤处理,通过RdChiral从数据集中每一个化学反应方程进行模板提取,并对提取的模板去重得到最终的模板库,提高了模板库的精确度;
3、对生成物进行清洗过滤后,以生成物为输入,通过最终的翻译模型进行产物预测,得到候选产物集合以及每个候选产物对应的预测分数构成的预测分数集合SC,再将每个反应物分别与候选产物集合结合,组成反应方程集合S,利用原子匹配算法对反应方程集合S中所有元素进行原子匹配,得到集合SM,再通过RdChiral对集合SM中每一个元素提取反应模板,并在模板库中进行模板匹配,得到匹配分数集合SSC,基于预测分数集合以及匹配分数集合计算融合分数,选取分值最高的融合分数的对应的候选产物作为最终产物,该产物预测过程中基于翻译模型和模板库进行,提高了产物预测的精度和效率。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
下面结合附图对本发明进一步说明。
图1为实施例1翻译模型构建方法的流程框图;
图2为实施例2产物预测模型构建方法的流程框图;
图3为实施例3产物预测方法的流程框图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互结合。
本发明实施例提供有翻译模型构建方法、产物预测模型构建方法及预测方法,用于解决如何克服有机反应预测时对模板库和规则库的依赖,并提高有机合成预测准确率的技术问题。
实施例1:
本发明的翻译模型构建方法,包括如下步骤:
S100、以公开的数据集USPTO作为原始数据集,数据集USPTO由包括SMILES表达式的化学反应方程组成;
S200、对原始数据集进行清洗过滤,并对SMILES表达式进行简化及正则化处理,得到预处理后数据集,化学反应方程中生成物的SMILES表达式中分子所包含的元素为预处理后数据集中一类样本数据,反应物的 SMILES表达式中分子所包含的元素为所述预处理后数据集中的另一类样本数据;所述元素为化学元素;
S300、将预处理后数据集划分为三个数据子集,分别为训练集、验证集和测试集;
S400、基于Transformer模型构建翻译模型,翻译模型用于基于输入的生成物进行产物预测,输出预测产物以及所述预测产物对应的预测分数,预测产物作为生成物;
S500、以训练集为输入优化所述翻译模型的参数,以验证集为输入对翻译模型的能力进行初步评估、并调整翻译模型的超参数,得到训练后翻译模型,以测试集为输入对训练后翻译模型进行测试,得到最终翻译模型。
其中,步骤S200中对原始数据集进行过滤清洗,包括如下操作:过滤掉产物数量大于1的化学反应方程、过滤掉含有不合法SMILES表达式的化学反应方程以及删除重复的化学反应方程。
含有原子匹配的SMILES表达式过于复杂,不符合模型输入规则,故对其进行简化操作。本实施例中采用专业的化学信息处理工具包RDKIT对清洗过滤后的原始数据集进行简化,然后对其正则化处理,来满足模型的输入规则。
正则化规则为:对输入的SMILE表达式筛选出分子所包含的元素,然后元素之间用空格分割,得到正则化结果,以得到满足翻译模型的输入规则的数据。
结果示例如下:C C 1=C C=C(C=C 1)Cl
步骤S300中将预处理后数据集划分为三个数据子集,在划分过程中根据需求按照一定比例进行划分,本实施例中比例为8:1:1。
本实施例中翻译模型包括嵌入层、位置编码器、编码器和解码器,其中嵌入层用于对输入的生成物和反应物提取对应的元素向量,位置编码器用于基于元素向量和元素在化学反应方程中的位置计算每个元素对应的位置向量,编码器用于以反应物相关的元素向量以及每个元素向量对应的位置向量为输入进行编码处理,提取并输出反应物相关的特征向量,解码器用于以反应物相关的特征向量以及与生成物相关的元素向量以及每个元素向量对应的位置向量为输入进行解码处理,输出预测产物。
其中,位置编码器用于通过如下公式计算每个元素对应的位置向量矩阵:
其中,pos表示元素化学反应方程的位置,d表示元素向量的维度,i表示元素向量的位置。
编码器包括一个多头注意力机制模块,反应物相关的位置向量矩阵作为编码器的输入数据,多头注意力机制模块用于通过attention(Q,K,V)公式对所述输入数据进行缩放采样处理,得到多个特征向量,特征向量的个数与所述多头注意力机制的头数相同,并将多个特征向量拼接处理后输出。
解码器包括两个多头注意力机制模块,分别为第一多头注意力机制模块和第二多头注意力机制模块,第一多头注意力机制模块用于对输入的生成物相关的位置向量矩阵进行遮蔽处理后输出,第二多头注意力机制模块用于对输入的编码器的输出以及第一多头注意力机制模块的输出进行解码处理,输出预测产物。
遮蔽处理包括如下步骤:对于当前被预测的第n个元素,将第一多头注意力机制模块中第n个元素之后的元素向量使用Mask字符进行代替。
本实施例中,编码器的多头注意力机制模块以及解码器中的多头注意力机制模块中多头注意力层的头数设定为8,在训练过程中,优化器参数使用的自适应调整的Adam函数;损失函数使用的是sparsemax损失函数;batch_size为 4096;dropout为0.1。
训练过程如下:
(1)首先基于训练集Set构建词向量表,按照批次大小抽取数据经过向量化处理后作为模型的输入进行训练,训练时采用的是小批次随机梯度下降的方法,每次从训练集随机挑选一批数据用作模型的训练,本模型在训练时批次大小为4096,取其中一条数据分为反应物SMILES_A和生成物SMILES_B两部分分别阐述编码器与解码器在训练中的处理过程;
(2)将SMILES_A经过嵌入层转换成元素向量,并与位置编码相加得到 SMILES_A的向量矩阵,然后输入到编码器对数据进行编码处理,使用8头注意力层,相当于8个子空间分别对数据使用attention(Q,K,V)公式进行缩放采样处理得到特征向量,然后将8个特征向量进行拼接处理作为Encoder的输出,传递Decoder解码器;
(3)将SMILES_B经过嵌入层转换成元素向量,并与位置编码相加得到 SMILES_B的向量矩阵,然后输入到编码器中,其中第一个多头注意力模块处理SMILES_B的输入矩阵,并进行遮蔽处理;第二个多头注意力模块结合第一个模块的输出以及编码器的输出进行解码成预测产物;最后采用sparsemax损失函数计算其与生成物之间的loss值,然后采用反向传播算法对网络模型参数进行更新。经过多轮训练之后,当loss值趋于稳定,训练完成进行模型存储,得到模型prediction_model。
通过上述步骤,最后可得到最终翻译模型,该模型可用于预测有机反应的产物。
实施例2:
本发明的产物预测模型构建方法,包括如下步骤:
S100、通过实施例1公开的用于有机反应预测的翻译模型训练方法构建并训练翻译模型,得到最终翻译模型;
S200、以公开的数据集USPTO作为原始数据集,该数据集USPTO由包括SMILES表达式的化学反应方程组成;
S300、对原始数据集进行清洗过滤,得到预处理后化学反应数据集;
S300、通过RdChiral对预处理后化学反应数据集中每一条化学反应方程进行模板提取,得到候选模板库;
S400、对候选模板库进行清洗,去除重复和无效的模板,得到模板库,其中无效的模板包括不完整的模板。
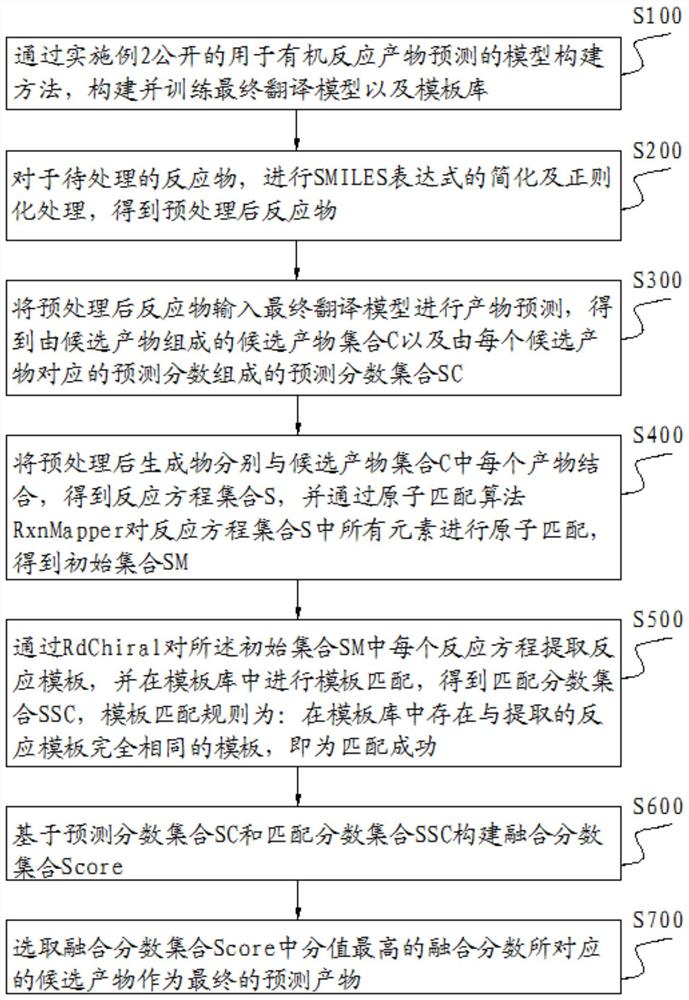
实施例3:
本发明的产物预测方法,包括如下步骤:
S100、通过实施例2公开的用于有机反应产物预测的模型构建方法,构建并训练最终翻译模型以及模板库;
S200、对于待处理的反应物,进行SMILES表达式的简化及正则化处理,得到预处理后反应物;
S300、将预处理后反应物输入所述最终翻译模型进行产物预测,得到由候选产物组成的候选产物集合C以及由每个候选产物对应的预测分数组成的预测分数集合SC;
S400、将预处理后生成物分别与候选产物集合C中每个产物结合,得到反应方程集合S,并通过原子匹配算法RxnMapper对反应方程集合S中所有元素进行原子匹配,得到初始集合SM;
S500、通过RdChiral对所述初始集合SM中每个反应方程提取反应模板,并在模板库中进行模板匹配,得到匹配分数集合SSC,模板匹配规则为:在模板库中存在与提取的反应模板完全相同的模板,即为匹配成功;
S600、基于预测分数集合SC和匹配分数集合SSC构建融合分数集合 Score,融合分数集合Score中融合分数的计算公式为:
其中,α为预测分数的权重,β为匹配分数的权重,i为候选产物的下标,k为候选产物的个数;
S700、选取融合分数集合Score中分值最高的融合分数所对应的候选产物作为最终的预测产物。
上文通过附图和优选实施例对本发明进行了详细展示和说明,然而本发明不限于这些已揭示的实施例,基与上述多个实施例本领域技术人员可以知晓,可以组合上述不同实施例中的代码审核手段得到本发明更多的实施例,这些实施例也在本发明的保护范围之内。