一种多场景下人机混驾智能列车的控制方法
文献发布时间:2023-06-19 19:05:50
技术领域
本发明涉及交通运输技术领域,特别是一种多场景下人机混驾智能列车的控制方法。
背景技术
随着智能机器与各类智能终端不断涌现,人与智能机器的交互、混合是未来社会的发展形态。然而,对于许多存在不确定性、脆弱性和开放性问题的情况下,任何智能的机器都无法完全取代人类。这将需要将人类的作用或人的认知模型引入到人工智能系统中,形成混合增强智能的形态。现有列车人机共驾的研究根据人机协同方法目前大体可分为两大类型:第一类是通过人与机切换控制,在自动驾驶系统和人驾驶两者之间相互切换,采用接管方式控制列车;第二大类是人机之间相互辅助驾驶,即人辅助机器驾驶,或者机器辅助人驾驶;第三大类是人机共享控制,列车驾驶员和驾驶自动化机器系统同时对车辆运动进行控制。其中,第三大类的控制方式,列车人机混合智能共驾通过发挥人机各自优势,是提升智能列车稳定性、安全性和舒适性的可行技术手段。
对于人机共享的控制方式来说,需要考虑机器档位操控和驾驶员人工档位操控的权重分配问题。然而现有技术中,通常对人机档位操控的权重进行平均分配,分配方式简单粗糙,很难满足列车对准点、能耗和乘坐舒适度三目标的要求。另一方面,不同的天气类型对驾驶员的档位操控决策有影响,此时不对人机档位操控的权重分配进行合理调整,会进一步使列车行驶的准点率降低,能耗提高,乘坐舒适度下降。
事实上,天气因素对机器档位操控决策也有影响,对于不同的天气类型,列车行驶路段的限速等参数是不同的,如果机器档位操控不考虑天气的影响,其输出的档位操控序列也很难满足对准点、能耗和乘坐舒适度三目标优化要。
发明内容
针对背景技术的问题,本发明提供一种多场景下人机混驾智能列车的控制方法,以解决现有技术中人机档位操控权重分配不合理,且未考虑天气因素对驾驶员及机器档位操控决策的影响,导致人机智能混驾列车准点率低、能耗高、乘坐舒适度差的问题。
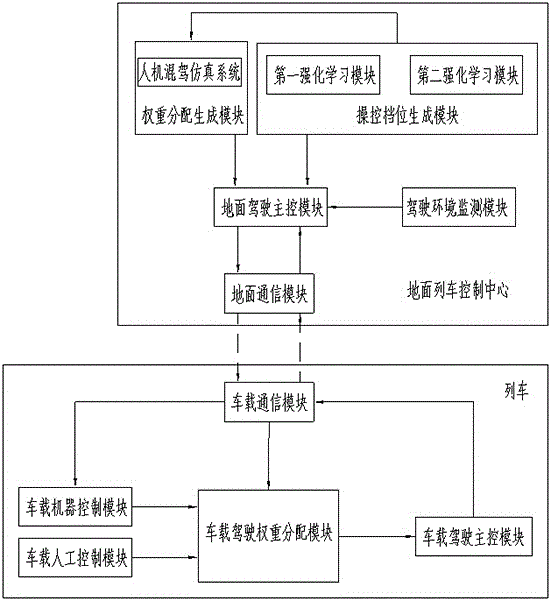
为实现本发明的目的,本发明提供了一种多场景下人机混驾智能列车的控制方法,其特征创新点在于:包括车载机器控制模块、车载人工控制模块、车载驾驶权重分配模块、车载驾驶主控模块、车载通信模块和地面列车控制中心;
所述地面列车控制中心包括地面通信模块、地面驾驶主控模块、驾驶环境监测模块、操控档位生成模块和权重分配生成模块;所述操控档位生成模块包括第一强化学习模块和第二强化学习模块;
所述权重分配生成模块包括人机混驾仿真系统,所述人机混驾仿真系统能模拟列车的驾驶环境,通过人机混驾仿真系统还能获取人机混合智能驾驶的仿真数据;
所述驾驶环境监测模块能获取列车运行路段的天气类型信息,并将天气类型信息传输给地面驾驶主控模块;所述天气类型包括晴好天气和恶劣天气;
地面驾驶主控模块能从权重分配模块获取列车驾驶路段的可用人机操控权重分配序列,并将获取的可用人机操控权重分配序列发送给车载通信模块;地面驾驶主控模块能根据天气类型信息从操控档位生成模块中获取可用最优档位操控序列,并将获取的可用最优档位操控序列发送给车载通信模块;
所述控制方法包括:
设列车将从A站点行驶到B站点,将A站点与B站点之间的路段记为AB路段,所述AB路段由N个步进长度相等的步进区段组成;
所述第一强化学习模块根据方法一生成列车在晴好天气下的第一最优档位操控序列,所述第二强化学习模块根据方法二生成列车在恶劣天气下的第二最优档位操控序列;
权重分配生成模块根据方法三生成列车在AB路段行驶的人机操控权重分配序列;
一)当列车从A站点驶出前,车载驾驶主控模块通过车载通信模块向地面通信模块发送数据装载请求;
二)地面通信模块将数据装载请求传输给地面驾驶主控模块,然后地面驾驶主控模块从驾驶环境监测模块获取AB路段当前的天气类型信息;
三)地面驾驶主控模块根据收到的天气类型信息按方法四获取可用最优档位操控序列和可用人机操控权重分配序列;
四)地面驾驶主控模块将所述可用最优档位操控序列数据和可用人机操控权重分配序列数据通过地面通信模块发送给车载通信模块,然后车载通信模块将收到的可用最优档位操控序列数据和可用人机操控权重分配序列数据分别传输给车载机器控制模块和车载驾驶权重分配模块;然后车载机器控制模块对收到的可用最优档位操控序列数据进行装载,车载驾驶权重分配模块对收到的可用人机操控权重分配序列数据进行装载;
五)车载机器控制模块根据可用最优档位操控序列实时向车载驾驶权重分配模块传输第一操控档位指令;同时,驾驶员通过车载人工控制模块实时向车载驾驶权重分配模块传输第二操控档位指令;
六)车载驾驶权重分配模块每次收到第一操控档位指令和第二操控档位指令即按方法五进行处理生成当前的融合操控档位A′
七)车载驾驶主控模块根据收到的融合操控档位指令控制列车运行;如果列车到达B站点程序结束,否则返回步骤五);
所述方法一包括:
1)对AB路段列车在晴好天气条件下的历史运行数据进行收集处理,获取多个经验档位操控序列,多个经验档位操控序列组成一个经验回放池;其中,单个经验档位操控序列τ可根据公式一确定;
2)以从经验回访池中随机选择一个经验档位操控序列为基础,采用DQN算法进行强化学习,生成第一最优档位操控序列;
所述公式一为:
τ={s
其中,i为0至N的整数;s
所述公式二为:
其中,所述d
所述公式三为:
r
其中,所述r
所述公式四为:
其中,所述
所述公式五为:
其中,所述u
所述公式六为:
其中,所述u
所述方法二包括:
对AB路段列车在恶劣天气条件下的历史运行数据进行收集处理,获取多个专家档位操控序列,单个专家档位操控序列τ′根据公式七获取;
A)采用强化学习的方法,使智能体与环境交互得到多个初始机器档位操控序列,单个机器档位操控序列τ″根据公式九获取;
B)程序首次循环时,采用GAIL算法对多个专家档位操控序列数据和多个初始机器档位操控序列数据进行处理,得到多个待判档位操控序列和判别概率p;
程序后续循环中,采用GAIL算法对多个专家档位操控序列数据和多个更新机器档位操控序列数据进行处理,得到多个待判档位操控序列和判别概率p;
C)对判别概率p进行判断,如果判别概率p满足大于设定值要求为真,则将多个所述待判档位操控序列中,累计奖励值最大的待判档位操控序列作为第二最优档位操控序列,程序结束;否则进入步骤D);
D)采用PPO算法对多个待判档位操控序列进行处理,得到多个更新档位操控序列;返回步骤B);
所述公式七为:
τ′={s′
其中,s′
所述公式八为:
其中,所述d′
所述公式九为:
τ″={s″
其中,s″
所述公式十为:
其中,所述d″
所述方法三包括:
1)强化学习环境搭建:从操控档位生成模块获取第一最优档位操控序列数据和第二最优档位操控序列数据;然后将所述第一最优档位操控序列数据和第二最优档位操控序列数据输入人机混驾仿真系统;人机混驾仿真系统利用第一最优档位操控序列数据,模拟晴好天气下车载机器控制模块在AB路段对列车的档位操控;人机混驾仿真系统利用第二最优档位操控序列数据,模拟恶劣天气下车载机器控制模块在AB路段对列车的档位操控;驾驶员通过向人机混驾仿真系统输入操控档位模拟在AB路段人工对列车的档位操控;将模拟晴好天气下车载机器控制模块和驾驶员在AB路段对列车的混合档位操控环境记为第一强化学习环境,将模拟恶劣天气下车载机器控制模块和驾驶员在AB路段对列车的混合档位操控环境记为第二强化学习环境;
2)采用Q-Learning算法,使智能体与强化学习环境互动,获取AB路段中每个步进区段对应的人机操控权重对(k
所述方法四包括:
当天气类型为晴好天气时,地面驾驶主控模块从操控档位生成模块中提取第一最优档位操控序列作为可用最优档位操控序列;地面驾驶主控模块从权重分配生成模块中提取所述λ
当天气类型为恶劣天气时,地面驾驶主控模块从操控档位生成模块中提取第二最优档位操控序列作为可用最优档位操控序列;地面驾驶主控模块根据以下方式获取可用人机操控权重分配序列:
Ⅰ)从权重分配生成模块中提取所述λ
Ⅱ)将λ
所述模糊推理表为:
{L,XL,XXL}为天气恶劣程度的模糊论域,其中,L表示大,XL表示很大,XXL表示特别大;
{S,M,H}为权重调节值Δk的模糊论域,其中,S表示小,M表示适中,H表示大;
所述方法五包括:
将AB线路中第i个步进区段对应的第一操控档位记为A
进一步地,所述Q-Learning算法涉及的奖励函数R
所述公式十一为:
R
其中,k
Q-Learning算法涉及的状态表为S
进一步地,所述权重调节值Δk的取值范围为0.1到0.9。
本发明的原理如下:
人机智能混驾列车的驾驶控制中,非常重要的一环就是对机器档位操控和人工档位操控的权重分配,以便输出并联融合的档位操控指令,然而,现有技术中通常采用全路段固定且平均的权重分配方式进行。事实上,随着列车的运行,其运行的位置、线路坡度、限速条件等环境都是在动态变化的,人和机器的决策也在随着环境的变化随时调整,两者对档位操控的决策判断不可能绝对一致,在这种环境下,采用人、机档位操控的权重分配各占0.5进行融合较简单、粗糙,非常不科学,采用上述分配方式得到的融合档位操控指令控制列车运行,也无法满足对准点、能耗、舒适度三目标的优化要求。另一方面列车行驶路段的天气情况,特别是恶劣天气情况对驾驶员的视线和心理等干扰较大,会影响驾驶员的档位操控决策,而天气对机器的档位操控决策却没什么影响,如果不根据天气类型对人机档位操控权重进行动态调整,势必会进一步劣化对列车行驶的三个优化目标。
本申请创造性地利用Q-Learning算法进行强化学习,使智能体分别与不同天气类型下的列车驾驶环境进行互动,以对组成列车行驶路段的各个步进区段的人机档位操控权重分配进行探索,以获取各个步进路段的人机操控权重对,路段所有步进区段的人机操控权重对的有序排列形成该路段的人机操控权重分配序列;而且,针对晴好天气和恶劣天气两种不同的列车操控环境,分别使智能体通过强化学习,得到两个于天气类型对应的人机操控权重分配序列λ
另一方面,现有技术中,车载机器控制模块需要加载的最优档位操控序列通常是提前通过强化学习等方法获取的,虽然在列车实际驾驶过程中,车载机器控制模块不受天气影响,但是其装载的可用最优档位操控序列本身如果与天气类型不匹配,也不能实现对上述驾驶三目标的优化要求。这是因为天气类型不同,比如晴好天气(晴天、阴天等能见度较好的天气)和恶劣天气(雨、雪、雾等影响能见度的天气)天气,列车驾驶路段的限速要求是不一样的,如果智能体在强化学习过程中采用统一的环境参数进行学习,得到的最优档位操控序列并不能完全与实际列车运行环境参数匹配,将与运行环境参数不匹配的最优档位操控序列装载到车载机器控制模块中控制列车运行,势必无法满足列车对准点、能耗和舒适度的要求。事实上,如果能针对不同天气场景进行强化学习得到相匹配的机器最优档位操控序列,也为后续人机档位操控权重分配的仿真提供了更准确的环境参数,使获取的人机档位操控权重分配序列也更合理和精准。
基于上述考虑,发明人在本申请中,使智能体分别在能见度相差明显的两大类天气环境下进行强化学习,以获取与这两大类天气相匹配的最优档位操控序列。为了提高强化学习的效率,避免智能体从零开始起步训练、探索次数过多、时间过长,本申请中从列车的真实行驶记录中提取历史数据作为经验数据,在此基础上进行强化学习,以提高学习效率。通常来说,这些历史数据中大部分为列车在晴好天气下的记录,可利用的样本数据较多,所以针对晴好天气,本发明将这些大量的样本数据进行处理,提取其中的档位操控相关参数形成多个经验档位操控序列,并将这些经验档位操控序列放入经验回访池供强化学习作为学习基础使用,本申请采用擅长利用经验数据进行强化学习的DQN(Deep-Q-Network)算法来进行求解,从而得到晴好天气下,列车在路段上行驶的最优档位操控序列。
然而,相对晴好天气的场景,恶劣天气下的历史数据相对较少,样本数据明显不足,就无法采用经验回访池技术来获取可用最优档位操控序列。针对恶劣天气类型,本发明采用生成对抗模仿学习GAIL(Generative Adversarial Imitation Learning)和近端策略优化算法PPO(Proximal Policy Optimization)相结合的办法来生成最优档位操控序列,具体来说:是以已有的专家档位操控序列为整体,采用生成对抗模仿学习GAIL来对恶劣气候下并不多的档位操控序列集进行扩充,产生更多、更为优秀的新档位操控序列数据集,对已有的档位操控序列集进行增强,该学习方式将恶劣气候下的为数不多的小样本档位操控序列作为专家数据,有利于提高学习效率。在数据增强与提高学习效率的同时,为进一步提高强化学习对档位操控序列最优解的求解质量,采用近端策略优化算法PPO来获取更优秀的档位操控序列。因此,在恶劣气候条件下,摒弃已有的经验回放池技术,将生成对抗模仿学习GAIL与近端策略优化算法PPO相结合进行模型训练和强化学习,将模型的训练分为引导阶段与探索阶段,在引导阶段让策略网络模仿学习专家的档位操控决策,减少前期学习中的试错,增强学习效率;在探索阶段让策略网络通过与环境的交互,在奖励的指导下,探索出更加优秀的驾驶策略。以上方法,在加强学习效率的同时,对档位操控序列数据不管从数量上,还是质量上都进行了明显提高。解决了列车在恶劣天气下运行历史数据样本少,经验回放池技术难以运用的问题。
由此可见,本发明具有如下的有益效果:采用本发明所述的控制方法,能根据天气类型不同选取相匹配的最优档位操控序列来实现列车驾驶的机器操控,同时还能根据天气类型不同选择匹配的人机操控权重分配序列来动态调整列车行驶的全路段人机档位操控的权重分配,实现对人机智能混驾列车行驶三目标的明显优化,大大提高了人机混驾智能列车在不同天气场景下行驶的准点率,降低了能耗,明显改善了乘坐舒适度。
附图说明
本发明的附图说明如下。
附图1为本发明所涉及硬件的连接结构示意图。
具体实施方式
下面结合实施例对本发明作进一步说明。
如附图1所示的本发明所涉及的硬件连接结构示意图,包括车载机器控制模块、车载人工控制模块、车载驾驶权重分配模块、车载驾驶主控模块、车载通信模块和地面列车控制中心;
所述地面列车控制中心包括地面通信模块、地面驾驶主控模块、驾驶环境监测模块、操控档位生成模块和权重分配生成模块;所述操控档位生成模块包括第一强化学习模块和第二强化学习模块;
所述权重分配生成模块包括人机混驾仿真系统,所述人机混驾仿真系统能模拟列车的驾驶环境,通过人机混驾仿真系统还能获取人机混合智能驾驶的仿真数据;
所述驾驶环境监测模块能获取列车运行路段的天气类型信息,并将天气类型信息传输给地面驾驶主控模块;所述天气类型包括晴好天气和恶劣天气;本申请所述的晴好天气包括晴天和阴天,所述恶劣天气包括雨天、雾天和雪天。
地面驾驶主控模块能从权重分配模块获取列车驾驶路段的可用人机操控权重分配序列,并将获取的可用人机操控权重分配序列发送给车载通信模块;地面驾驶主控模块能根据天气类型信息从操控档位生成模块中获取可用最优档位操控序列,并将获取的可用最优档位操控序列发送给车载通信模块;
所述控制方法包括:
设列车将从A站点行驶到B站点,将A站点与B站点之间的路段记为AB路段,所述AB路段由N个步进长度相等的步进区段组成;
所述第一强化学习模块根据方法一生成列车在晴好天气下的第一最优档位操控序列,所述第二强化学习模块根据方法二生成列车在恶劣天气下的第二最优档位操控序列;
权重分配生成模块根据方法三生成列车在AB路段行驶的人机操控权重分配序列;
一)当列车从A站点驶出前,车载驾驶主控模块通过车载通信模块向地面通信模块发送数据装载请求;
二)地面通信模块将数据装载请求传输给地面驾驶主控模块,然后地面驾驶主控模块从驾驶环境监测模块获取AB路段当前的天气类型信息;
三)地面驾驶主控模块根据收到的天气类型信息按方法四获取可用最优档位操控序列和可用人机操控权重分配序列;
四)地面驾驶主控模块将所述可用最优档位操控序列数据和可用人机操控权重分配序列数据通过地面通信模块发送给车载通信模块,然后车载通信模块将收到的可用最优档位操控序列数据和可用人机操控权重分配序列数据分别传输给车载机器控制模块和车载驾驶权重分配模块;然后车载机器控制模块对收到的可用最优档位操控序列数据进行装载,车载驾驶权重分配模块对收到的可用人机操控权重分配序列数据进行装载;
五)车载机器控制模块根据可用最优档位操控序列实时向车载驾驶权重分配模块传输第一操控档位指令;同时,驾驶员通过车载人工控制模块实时向车载驾驶权重分配模块传输第二操控档位指令;
六)车载驾驶权重分配模块每次收到第一操控档位指令和第二操控档位指令即按方法五进行处理生成当前的融合操控档位A′
七)车载驾驶主控模块根据收到的融合操控档位指令控制列车运行;如果列车到达B站点程序结束,否则返回步骤五);
所述方法一包括:
1)对AB路段列车在晴好天气条件下的历史运行数据进行收集处理,获取多个经验档位操控序列,多个经验档位操控序列组成一个经验回放池;其中,单个经验档位操控序列τ可根据公式一确定;其中历史运行数据包括线路静态数据、列车静态数据和列车运行动态数据,其中,线路静态数据包括线路坡度、区间限速值;列车静态数据包括列车牵引、制动相关参数;列车运行动态数据包括列车当前运行位置、速度、加速度以及列车运行时间。线路数据可从设计资料或列车运行监控装置LKJ中获取;列车基本参数和运行数据,可通过设计资料以及列车控制与管理系统TCMS设备上获得。
2)以从经验回访池中随机选择一个经验档位操控序列为基础,采用DQN算法进行强化学习,生成第一最优档位操控序列;DQN算法为现有技术,简单来说,智能体与环境进行交互,环境产生新的状态、奖励值以及状态值函数反馈给智能体,智能体通过值函数不断地进行策略评估和策略改进,选择最大动作值函数,并将该最大动作值函数对应的动作反馈给列车运行强化学习环境,通过上述闭环结构来不断地更新工况值,最终选择最优的工况动作,生成第一最优档位操控序列;
上述智能体动作值函数的更新,采用深度Q学习网络DQN(Deep-Q-Network),更新方式用梯度下降法:
θ,θ
所述公式一为:
τ={s
其中,i为0至N的整数;s
所述公式二为:
其中,所述d
所述公式三为:
r
其中,所述r
所述公式四为:
其中,所述
所述公式五为:
其中,所述u
所述公式六为:
其中,所述u
所述方法二包括:
对AB路段列车在恶劣天气条件下的历史运行数据进行收集处理,获取多个专家档位操控序列,单个专家档位操控序列τ′根据公式七获取;
A)采用强化学习的方法,使智能体与环境交互得到多个初始机器档位操控序列,单个机器档位操控序列τ″根据公式九获取;
B)程序首次循环时,采用GAIL算法对多个专家档位操控序列数据和多个初始机器档位操控序列数据进行处理,得到多个待判档位操控序列和判别概率p;
程序后续循环中,采用GAIL算法对多个专家档位操控序列数据和多个更新机器档位操控序列数据进行处理,得到多个待判档位操控序列和判别概率p;
C)对判别概率p进行判断,如果判别概率p满足大于设定值要求为真,则将多个所述待判档位操控序列中,累计奖励值最大的待判档位操控序列作为第二最优档位操控序列,程序结束;否则进入步骤D);
D)采用PPO算法对多个待判档位操控序列进行处理,得到多个更新档位操控序列;返回步骤B);
所述公式七为:
τ′={s′
其中,s′
所述公式八为:
其中,所述d′
所述公式九为:
τ″={s″
其中,s″
所述公式十为:
其中,所述d″
所述方法三包括:
1)强化学习环境搭建:从操控档位生成模块获取第一最优档位操控序列数据和第二最优档位操控序列数据;然后将所述第一最优档位操控序列数据和第二最优档位操控序列数据输入人机混驾仿真系统;人机混驾仿真系统利用第一最优档位操控序列数据,模拟晴好天气下车载机器控制模块在AB路段对列车的档位操控;人机混驾仿真系统利用第二最优档位操控序列数据,模拟恶劣天气下车载机器控制模块在AB路段对列车的档位操控;驾驶员通过向人机混驾仿真系统输入操控档位模拟在AB路段人工对列车的档位操控;将模拟晴好天气下车载机器控制模块和驾驶员在AB路段对列车的混合档位操控环境记为第一强化学习环境,将模拟恶劣天气下车载机器控制模块和驾驶员在AB路段对列车的混合档位操控环境记为第二强化学习环境;
2)采用Q-Learning算法,使智能体与强化学习环境互动,获取AB路段中每个步进区段对应的人机操控权重对(k
所述Q-Learning算法涉及的奖励函数R
所述公式十一为:
R
其中,k
Q-Learning算法涉及的状态表为S
所述方法四包括:
当天气类型为晴好天气时,地面驾驶主控模块从操控档位生成模块中提取第一最优档位操控序列作为可用最优档位操控序列;地面驾驶主控模块从权重分配生成模块中提取所述λ
当天气类型为恶劣天气时,地面驾驶主控模块从操控档位生成模块中提取第二最优档位操控序列作为可用最优档位操控序列;地面驾驶主控模块根据以下方式获取可用人机操控权重分配序列:
Ⅰ)从权重分配生成模块中提取所述λ
Ⅱ)将λ
所述模糊推理表为:
{L,XL,XXL}为天气恶劣程度的模糊论域,其中,L表示大,XL表示很大,XXL表示特别大;
{S,M,H}为权重调节值Δk的模糊论域,其中,S表示小,M表示适中,H表示大;
所述方法五包括:
将AB线路中第i个步进区段对应的第一操控档位记为A
本发明中应用到的强化学习、DQN算法、GAIL算法、PPO算法、Q-Learning算法和模糊推理理论均为现有技术中十分常见的处理手段或计算方法,相关的内容,本领域技术人员可从现有技术的相关文献中获取。