一种顾及地形特征的LiDAR点云聚类简化方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于点云简化技术领域,涉及一种顾及地形特征的LiDAR点云聚类简化方法。
背景技术
精准有效的三维时空信息是新型基础设施建设、实景三维中国建设、自然资源管理与监测等国家重大需求不可或缺的重要支撑。近年来,多种对地观测技术的创新发展提升了全空间和全时域的感知能力,尤其是以机载激光雷达技术(LiDAR)为代表的三维点云数据获取手段,为智能化测绘提供了一种全新技术。高质量、精细化的点云数据能准确地表达自然地表的多种空间要素,然而,机载LiDAR系统获取具有空间信息和属性信息的地面点时,一般按照复杂地形区对点密度需求设计数据采集规范,使得获取的地面点云在其他平坦地形区容易出现过度冗余,严重制约地形信息的存储、传输和分析效率。
点云简化是海量地面机载LiDAR地面点云进行高效传输和多尺度应用的前提。因此,如何实现高复杂性、多态性的海量地面点云自动化、智能化精简,满足地学分析对高精度、高效率的需求成为迫切攻克的难题。目前,学者们围绕机载LiDAR地面点云简化进行了深入研究,并根据现主流方法的工作原理将其分为5类:随机下采样法、体素格网下采样法、曲率采样法、减点法和加点法。随机下采样法以随机的方式选取一定数量的采样点;体素格网下采样法利用原始点云构造三维体素栅格,将每个体素点集的质心作为该体素的采样点。
上述两种算法简单、高效,但简化结果仅降低了点云密度,难以准确表达地形特征结构。而曲率采样法首先计算每个点云曲率值,然后将曲率小于一定阈值的点删除;但该方法容易造成平坦区出现数据空洞,进而带来地形细节信息丢失。
基于此,减点法和加点法被广泛采用。例如,现有技术文献曾提出通过对所有点云构建TIN迭代执行点删除操作,在每次迭代中,依次评估所有点云并将小于指定容差的点剔除。该方法性能较好,但计算效率低下,不适用于数据量巨大的机载LiDAR点云数据。针对加点法的研究中,经典的最大Z容差方法从待评价点云中选取与当前TIN表面偏差最大的点,利用更新后的关键点集再次重建TIN,该方法虽然顾及了全局地形特征,但易丢失河网特征处的形状和拓扑关系,且在微小地形处的特征总是被忽略。
随后,现有技术文献提出基于贪心的多面函数(MQ)方法,该方法先选择地形中的初始关键点进行插值,然后迭代对比MQ生成的插值表面与对应点集间的高程差值来评估所有候选点的重要性。该方法利用非线性插值方法提高了参考面的插值精度,但降低了选取关键点的计算效率。在此基础上,现有文献还提出利用薄板样条(TPS)插值方法选取地形关键点,相比于基于贪心的MQ方法,该方法不仅提升了简化效率,而且保持了地形中的河网特征;但该方法对地形特征提取算法的可靠性依赖程度较高。此外,现有技术文献还提出过一种由粗到精的点云精简方法,其主要通过区分局部地形复杂度以生成数据密度随地形表面复杂度变化的细化点云;但该方法忽略了地形骨架线上的特征点,易出现地形失真问题。
综上所述,目前在机载LiDAR地面点云简化时所采用的减点法和加点法,主要通过迭代删除原始点云中的冗余点或保留关键点实现点云精简。然而,这一过程严重依赖于插值方法的精确计算,且利用点与插值表面的高程差识别关键点,易丢失局部地形的细节特征。
发明内容
本发明的目的在于提出一种顾及地形特征的LiDAR点云聚类简化方法,以解决目前地面点云简化方法存在地形特征点识别不准确、地形细节特征易丢失等问题。
本发明为了实现上述目的,采用如下技术方案:
一种顾及地形特征的LiDAR点云聚类简化方法,包括如下步骤:
步骤1.以LiDAR地面点云为原始点云数据,使用K-means算法将原始点云数据划分为多个初始点云簇;依据点云簇地形复杂度将每个初始点云簇进一步细分成多个点云子簇;
步骤2.首先依据各点云子簇内地形特征线位置信息特点,查找每个点云子簇内地形特征点,并将查找到的地形特征点作为点云子簇代表点;
若点云子簇内不存在地形特征点,则使用点云子簇质心点作为点云子簇代表点;
步骤3.考虑到聚类简化方法导致的原始点云边界收缩问题,利用基于二维道格拉斯-普克方法,识别原始点云数据中的边界特征点;
最终地面简化点云包括各点云子簇代表点以及边界特征点。
本发明具有如下优点:
如上所示,本发明述及了一种顾及地形特征的LiDAR点云聚类简化方法,该方法针对目前机载LiDAR地面点云简化方法存在地形特征点识别不准确、地形细节特征易丢失等问题,首先采用顾及地形复杂程度的自适应点云聚类,生成点云子簇;然后通过识别点云子簇内的法向量突变特征点、高程突变特征点以及质心点来描述点云子簇;最后通过捕捉点云边界关键点防止原始点云边界收缩。与传统方法相比,在相同点云简化比例下,本发明生成的数字高程模型(DEM)精度及其派生品(包括平均坡度和地形粗糙度)精度均明显优于传统方法,而且较好的保留了地形特征信息,为遥感点云大数据精简提供了有效技术支撑。
附图说明
图1为本发明实施例中顾及地形特征的LiDAR点云聚类简化方法的流程图。
图2为本发明实施例中基于地形复杂度的点云聚类流程图。
图3为本发明实施例中地形特征线与TPI对比图。
图4为本发明实施例中TPI赋值初始点云簇示意图。
图5为本发明实施例中顾及地形复杂度的点云聚类示意图。
图6为本发明实施例中地形特征点识别流程图。
图7为本发明实施例中法向量突变区地形特征点识别示意图。
图8为本发明实施例中高程突变区地形特征点识别示意图。
图9为本发明实施例中聚类简化造成的地形边界缺失示意图。
图10为本发明实施例中边界点云的二维化示意图。
图11为本发明实施例中不同地形特征区简化点云分布示意图。
图12为六组数据的参考DEMs示意图。
图13为不同点云简化比例下,四种方法在各区域的RMSE和MAE对比示意图;
其中,左轴对应柱状图,右轴对应折线图。
图14为四种方法对Data2在简化率为1%时的DEM示意图。
图15为四种方法对Data6在简化率为1%时的DEM示意图。
图16为六种方法在各类研究区域的地形粗糙度和平均坡度示意图;
其中,左轴对应柱状图,右轴对应折线图。
具体实施方式
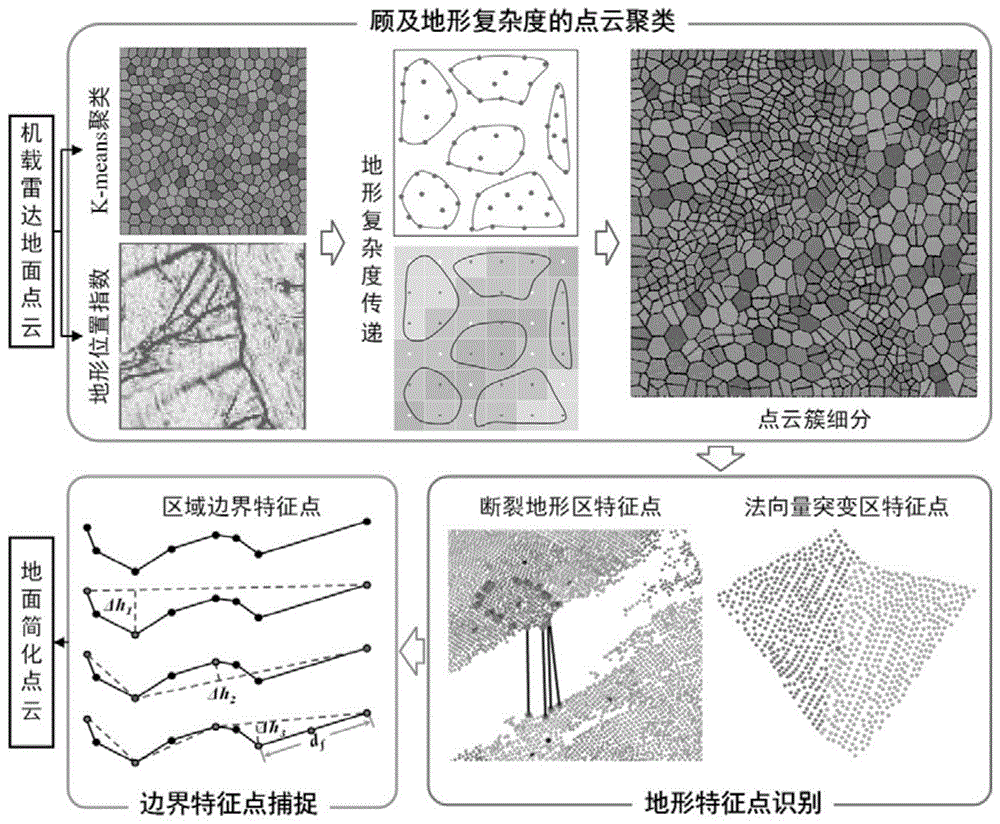
本发明述及了一种顾及地形特征的LiDAR点云聚类简化方法。该顾及地形特征的LiDAR点云聚类简化方法主要包括如下步骤:(1)利用地形复杂度对点云自适应聚类,减少地形特征处因简化点密度不足所造成的细节特征损失;(2)根据山脊、山谷、陡崖等地形特征的不同特点,识别点云簇内位于地形特征处的关键点,降低关键点识别不准确所造成的地形特征损失;(3)通过保留点云边界特征点,避免点云简化带来的边界缩减问题。
下面结合附图以及具体实施方式对本发明作进一步详细说明:
如图1所示,一种顾及地形特征的LiDAR点云聚类简化方法,包括如下步骤:
步骤1.以LiDAR地面点云为原始点云数据,使用K-means算法将原始点云数据划分为多个初始点云簇;依据点云簇地形复杂度将各初始点云簇进一步细分为多个点云子簇。
传统的基于三维体素栅格的点云简化方法将点云数据划分为大小均等的体素,并选取体素内一点代替体素内所有点云。该方法尽管运算效率较高,但容易造成复杂地形特征区精度损失。本发明利用相邻点集相似性将待简化点云聚类,生成点云簇,并以该簇作为处理单元。考虑到机载LiDAR地面点云具有海量的特点,本发明以计算效率较高的K-means方法为基础模型其快速划分。但是,该方法仅利用了点云的空间属性,并未考虑地形复杂度。因此,本发明提出了一种顾及地形复杂度的点云聚类方法,具体流程如图2所示。
首先使用K-means方法将点云划分为多个点云簇。
然后基于点云簇的地形复杂度将各簇进一步细分为更多的子簇。其中,簇的复杂度越高,对应的子簇数量就越多,由此用关键点代替子簇后保留的点也越多。
该步骤1具体为:
步骤1.1.初始点云簇划分。
利用K-means算法划分原始点云数据,依据公式(1)确定初始点云簇个数k
k
式中,[·]为向上取整符号,m为简化点云个数,t
步骤1.2.地形复杂度计算。
相对于海量且无序的散乱点云,利用规则格网提取地形特征更为快速。因此,本发明使用地形位置指数TPI描述地形复杂度,TPI如公式(2)所示。
/>
式中,|·|为绝对值符号,Z
如图3所示,地形位置指数TPI能够较好的描述地形特征信息,如山脊线、山谷线等。其中,图3(a)表示等高线及地形特征线,图3(b)表示与之对应的TPI值。
步骤1.3.地形复杂度赋值点云簇。
鉴于将点云栅格化计算TPI时会带来精度损失,为防止点云簇欠细分,本发明将每个初始点云簇所在的TPI网格点中的最大值赋予该初始点云簇,如图4所示。
其中,TPI值越大,表示该点云簇所在的地形越复杂。
步骤1.4.点云簇细分。
根据每个点云簇的地形复杂度即TPI值在所有点云簇中的占比,确定该初始点云簇进一步细分个数,并借助K-means完成子簇的划分。
第k个初始点云簇的进一步细分个数C
式中,[·]为向上取整符号,TPI
图5(a)示出了原始点云数据利用K-means聚类后的初始点云簇分布情况。
图5(b)示出了初始点云簇加入地形复杂度后进行细分的点云子簇分布情况。
图5(c)示出了点云子簇质心点。
步骤2.首先依据各点云子簇内地形特征线位置信息特点,查找每个点云子簇内地形特征点,并将查找到的地形特征点作为点云子簇代表点。
若点云子簇内不存在地形特征点,则使用点云子簇质心点作为点云子簇代表点。
由于直接将簇质心作为点云簇的代表点尽管简单,但当该质心点没有落在地形特征处时,会导致简化点难以准确描述地形特征信息的问题。
本发明采用点云子簇中的地形特征点代替质心点的策略表征该点子云簇。根据实际地形特征线类型,本发明提出了两种不同的地形特征点识别方案,如图6所示。
步骤2.1.对于山脊、山谷等地形特征,其法向突变地形特征点往往位于法向量突变处,如图7所示。因此,对比各子簇内法向量差异,判断子簇内是否存在法向量突变特征。
点云法向量由基于自适应邻域的主成分分析(PCA)方法计算。
法向量突变区特征点识别的具体步骤为:
先计算点云子簇内所有点的法向信息,再利用K-means方法依据法向量将点云子簇分割为两簇(图7中空心三角、空心方形),并计算两簇所代表曲面的法向夹角θ
若θ
若θ
步骤2.2.在高程变化剧烈的地形处(如陡崖),相邻点云间高程不连续。
K-means方法利用点云的三维坐标划分点云,高程差异明显的相邻点会被划分为不同簇,所以高程突变区地形特征点应位于点云子簇的边缘区域。
可利用相邻点云子簇间邻接边缘点的高程差异识别位于高程突变区的断裂地形特征点。
高程突变区地形特征点识别的具体步骤如下:
I.以点云子簇质心为节点,利用图(graph)结构描述所有点云子簇邻接关系,如图8(a)所示。
II.利用α-shape方法找到每个点云子簇的边缘点集,如图8(b)所示。
III.根据点云子簇间的邻近关系,逐点搜索点云子簇边缘点与其近邻子簇边缘点集的最近点,最终点云子簇的每个边缘点P
IV.计算P
如图8(d)所示,若d
步骤2.3.若点云子簇不存在上述步骤2.1中的法向突变地形特征点以及步骤2.2中的断裂地形特征点,表明点云子簇所在区域较为平坦,其代表点离质心越近,对所在地形表面的表征能力越强。则使用当前点云子簇的质心点作为点云子簇代表点。
步骤3.基于聚类方法选取的特征点容易导致边界点云丢失,使得原始点云边界收缩,即简化点覆盖面积小于原始点云面积,如图9所示。因此,本发明基于二维道格拉斯-普克方法抽稀边界点云,并保留其中关键点以防止原始点云边界收缩。具体步骤如下:
步骤3.1.提取原始点云数据的边界点集{P
其中,P
选择其中任意一点作为原点,沿逆时针方向将所有边界点集按其相邻关系排序,并依据公式(4)将三维边界点集转换为二维坐标,如图10所示。
其中,(x
X
步骤3.2.将二维坐标的边界点集标记为{P
取二维坐标边界点集中的边界点P
其中,P
若最大值d
步骤3.3.利用新基线点与基线点P
若存在新基线点则继续划分边界点集,否则保留边界点集的基线点;
最终,直到所有边界点集内的最大值d
将保留的三维边界点云作为原始点云数据的边界特征点。
最终地面简化点云包括各点云子簇代表点以及边界特征点。
图11中,山脊线、山谷线(图11(a))、高程突变处(图11(b))均存在特征点,研究区边界的特征点云也被较好的保留,由此表明简化点具有较好的地形特征保持能力。
此外,为了验证本发明顾及地形特征的LiDAR点云聚类简化方法的有效性,还开展了实验,实验中采用6组高密度机载LiDAR点云实例数据为研究对象,包含平原、山地和丘陵等不同地貌类型,并存在多条山脊线、山谷线以及陡崖等地形特征,如图12所示。
其中,Data1、Data 2整体地形起伏较小,Data1区域整体平坦,在左上位置存在明显的山包,Data2区域有明显的河网特征;Data3、Data 4整体地形起伏较大,山脊线和山谷线特征明显;Data5、Data 6区域中地形不连续,存在落差较大的高程断裂地形(如陡崖等地形特征)。由于获取的原始点云中包含地面点与非地面点,首先通过商业软件TerraSolid对其进行半自滤波与目视判别修正,进而精准提取其中的地面点。
其中,六组地面点数据的统计信息如表1所示。
表1六组数据地形统计信息
为验证本发明方法的有效性和适用性,将本发明方法与开源PCL(point cloudlibrary)中的随机方法(Random)、体素格网方法(VG)、曲率采样法(Curvature)和ArcGIS中的最大Z容差方法(Max-Z)对比分析。以上五种方法均采用保留相同简化点数的方式进行测试,选取的关键点数分别设置为地面点总点数的0.1%、0.2%、0.4%、0.6%、0.8%和1%。为了定量评估简化方法的性能,采用均方根误差(RMSE)和平均绝对误差(MAE)对比简化点云与原始点云生成DEM的差异。同时,使用平均坡度
/>
式中,H
本发明生成的所有DEM分辨率均为1m。为了测试算法的最佳性能,本发明各参数依据如下准则设置:格网大小l以能够提取主要地形特征为依据,断裂高差阈值f
基于此,本发明方法处理6组数据所采用的参数集为:
l=4m、f
如图13(a)至图13(f)所示,本发明对比了不同点云简化比例下,五种点云精简方法在各区域的RMSE和MAE。结果表明,不管何种方法,保留的简化点数越多,生成的DEM精度越高,即:RMSE和MAE随简化率的增加而降低。五种方法中,Random、Curvature和Max-Z精度较低,VG由于简化点云均匀分布,表现相对较好。相比而言,本发明方法精度最好,表现最为稳健,特别是在Data1-4区其RMSE和MAE显著低于其他方法。这主要得益于该方法采用了顾及地形复杂度的点云聚类和法向突变区域特征点的识别,在地形复杂区保留更多简化点的同时能识别区域内的地形特征点。在陡崖区(Data5、6),由于本发明方法可识别断裂地形处的特征点,其RMSE和MAE明显低于Random、Curvature和Max-Z方法。表2列出了各方法在不同简化比例条件下的平均误差。结果表明,本发明方法在各区域的平均RMSE和MAE均明显低于传统方法。其中,本发明方法对六组数据的平均RMSE较Random、Curvature、VG和Max-Z分别降低了37.8%、40.3%、12.1%、51.8%,平均MAE分别降低了28.5%、39.8%、9.6%、52.2%。
表2五种方法对各实验区在不同简化比例下的平均RMSE(m)和MAE(m)
相比于原始地形表面,简化后的地表会随着简化点云的减少而失真,故在同等简化比例下能突出和保留地形特征方法简化性能更好。因此,以Data2和Data6为例,对比了在1%点云精简率下,五种方法生成的DEM山体阴影图,如图14(a)至图14(f)、15(a)至图15(f)所示。五种方法中,Curvature存在数据空洞导致的平坦区域过度平滑,这是由于精化点容易聚集于曲率较大区域,而且在Data2的河谷处出现地形特征线不连续,Data6的断裂地形处特征严重失真。Random方法在各区域均出现了严重的地形特征模糊和局部平滑现象。VG方法整体表现略强于前者,但由于没有捕捉地形特征的能力,导致Data2中左侧的部分支流和右侧的山路等特征丢失,而且在Data6中部的陡崖处存在明显的锯齿。Max-Z方法易出现坑洞填充问题,且在非特征区域平滑严重,与原始地形特征不符。整体而言,本发明性能最优,其较好的保留了Data2中河网线细节特征和Data6中陡崖处的地形特征信息。
图16(a)至图16(f)展示了不同简化比例下,五种方法的平均坡度和地形粗糙度。结果表明,Random、Curvature和VG方法的平均坡度和地形粗糙度与参考值差异均较大,而本发明方法和Max-Z方法平均坡度和地形粗糙度高于其他方法,但前者在保留地形骨架特征的同时兼顾了地形中的细节特征,因而优于后者。在相同的简化率下,本发明方法总能保持较高平均坡度和地形粗糙度。总体而言,本发明方法与原始地形的吻合程度更高,明显优于其他方法。如表3所示,本发明方法平均坡度较Radom、VG和Curvature分别提升2.3%、1.7%、2.6%,平均地形粗糙度分别提升1.2%、0.9%、1.0%,表明其具有较强的地形特征保持能力。由于Max-Z方法在复杂地形处保留了较多的冗余点,增加了局部地形的起伏程度,因而在Data1、3、6区域的平均坡度和平均地形粗糙度与真值更为接近。
表3五种方法对六个区域在不同简化比例下的地形粗糙度和平均坡度
综上,通过选取6组高密度实例机载LiDAR地面点云为研究对象,并将本发明方法与随机方法、体素格网方法、Curvature方法和最大Z容差方法进行对比。根据六组实例数据分析表明,本发明方法计算精度明显优于Random、VG、Curvature和Max-Z方法,其构建的DEM平均RMSE较其他方法至少降低了12.1%,平均MAE至少降低了9.6%;相比传统的点云简化方法,本发明方法平均地形粗糙度和平均坡度与参考值更为吻合,前者提升了0.9%—1.2%,后者提升了1.7%—2.6%,表明本发明方法能较好的保持地形特征信息。
当然,以上说明仅仅为本发明的较佳实施例,本发明并不限于列举上述实施例,应当说明的是,任何熟悉本领域的技术人员在本说明书的教导下,所做出的所有等同替代、明显变形形式,均落在本说明书的实质范围之内,理应受到本发明的保护。
- 一种顾及多元地形特征的机载LiDAR点云抽稀方法
- 一种顾及房檐特征的机载与车载LiDAR点云配准方法