一种搭配构式的自动获取方法和系统、可视化方法
文献发布时间:2023-06-19 10:00:31
技术领域
本发明属于自然语言处理技术领域,更具体地,涉及一种搭配构式的自动获取方法和系统、可视化方法。
背景技术
基于自然语言处理技术的信息应用,包括自动文法批改系统、在线教育系统等依赖于显性语言知识库。由于语言本身的复杂性,人工构建语言知识库,如词典、语法知识库需耗费大量时间、人力和财力,且在覆盖率、一致性等方面存在缺陷。语言知识的自动获取是构建语言知识库的有效途径。与此同时,基于深度学习的知识获取尚不具备可解释性。现有能够自动获取的可解释的语言知识类型主要是搭配知识。认知语言学提出了新的语言知识基本构成单位-构式。构式是一个“形·义”复合体,而搭配构式是基于语料库的认知语言学研究所提出的构式表示形式,其中包含句法、词汇以及词语与构式间关联强度等多种类型知识。现有理论研究表明,搭配构式具有高度的可解释性,可用于解释多种语言现象,在自动文法批改、在线教育等方面具有广阔应用前景。
然而搭配构式并没有严格的形式化方法,也没有成熟的自动获取和可视化方法。
发明内容
针对现有技术的缺陷和改进需求,本发明提供了一种搭配构式的自动获取方法和系统、可视化方法,其目的在于提出了严格的搭配构式形式化定义、相应的自动获取方法以及可视化方法。
给定目标词语或句法模式,以及经过依存句法分析的特定语料,本发明能够从语料中自动获取目标词语或句法模式的搭配构式实例,并通过聚类方法自动生成搭配构式,并给出了可视化方法。所生成的知识库可解释性强,可用于语言在线教育、自动文法批改等领域。
为实现上述目的,按照本发明的第一方面,提供了一种搭配构式的自动获取方法,该方法包括以下步骤:
S1.从语料库中提取目标词语或目标句法模式的搭配构式实例集合,所述目标句法模式为依存树形式;
S2.将搭配构式实例集合聚类为多个社区;
S3.对于每个聚类社区,获取该社区对应的搭配构式。
优选地,从语料库中提取目标词语的搭配构式实例集合,具体如下:
(A1)检索语料库,获取所有包含目标词语的句子实例,并将获取到的每个句子实例通过依存句法分析转化为依存树,所有依存树构成依存树集合;
(A2)对于依存树集合中的每个依存树,进行以下操作,从而构建搭配构式实例集合:
初始化一个依存子树为空,遍历该依存树中的每一个三元组,选取中心词或者依存词与目标词语相同的三元组,加入该依存子树,遍历结束后将该依存子树作为该依存树对应的搭配构式实例。
有益效果:本发明目标词语的搭配构式实例获取以目标词语为中心,通过依存语法连接获取依赖于目标词语的句法成分的句法成分,从而全面反映了目标词语的具体句法使用模式。
优选地,从语料库中提取目标句法模式的搭配构式实例集合,具体如下:
(B1)从目标句法模式抽取检索词,构建检索词集合;
(B2)检索语料库,获取包含检索词集合中所有检索词的句子实例,并将获取到的每个句子实例通过依存句法分析转化为依存树,构成依存树集合;
(B3)对于依存树集合中的每个依存树,判断是否目标依存树中的所有三元组均包含在该依存树中,且在目标依存树中的顺序与在该依存树中顺序一致,若是,则进入步骤(B4),否则,不进行获取;从而构建搭配构式实例集合:
(B4)将该依存树与目标依存树进行比对,确定通配符的匹配项;
(B5)初始化一个依存子树为空,遍历该依存树中的每一个三元组,选取满足以下条件中任意一个的三元组加入该依存子树,遍历结束后将该依存子树作为该依存树对应的搭配构式实例,条件如下:
1)该三元组存在于目标依存树中;
2)该三元组的依存词是匹配项;
3)该三元组的中心词是匹配项。
有益效果:本发明句法模式的搭配构式实例获取通过依存语法连接确定关键句法部分,并使用通配符技术确定语句法模式相关的实词,进而获取实词的依赖句法成分和被依赖句法成分,组成全面反映句法模式的具体使用信息。
优选地,步骤S2中,给定搭配构式实例集合Γ′={C
(C1)依次考察C
(C2)获取C
(C3)逐个考察N中的C
有益效果:本发明在计算搭配构式实例的有序相似性基础上,对搭配构式实例进行聚类,并通过计算词语与搭配构式的关联强度确定搭配构式的典型语义使用范围,从而达到模拟人类在阅读过程中积累、抽象、归纳并最终习得语言知识的过程,形成与人类语言知识相似,便于理解和解释的语言知识形式。
优选地,搭配构式实例C
(D1)获取C
(D2)以距离为横轴,以位于距离取值区间的搭配构式个数为纵轴,制作D的直方图,定义第15个百分位数所对应的距离值为p
(D3)获取D的均方差σ;
(D4)C
其中,δ为倍增参数,1≤δ≤5。
有益效果:本发明以特定搭配构式实例与所有搭配构式实例之间的距离为随机变量,通过考察其概率质量函数的分布,并以15%为经验值,从而较好地获取改搭配构式实例的最大聚类距离。
优选地,搭配构式实例C
(E1)基于C
(E2)基于C
其中,len(C)为C中所包含的三元组个数,α和β分别表示C
(E3)基于C
有益效果:本发明引入基于AmosTversky的非对称性相似度计算方法,利用非对称性相似度计算中对相异部分特征权重的设置,从而实现了搭配构式实例之间的有序相似性,从而解决了搭配构式实例之间的包容性关系。
优选地,基于三元组的相似度,计算C
初始化大小为(J+1)×(K+1)的矩阵M,设置第一行和第一列中单元值为0;从第2行第2个单元开始,逐行计算单元值,使得:
其中,sim(e
其中:
sim(h
sim(c
其中,cosine(·)为余弦函数,vec(·)为词向量;
计算完成后,C
有益效果:本发明通过采用动态规划算法,由于动态规划算法可以考虑过程不同路径的费用,从而在考虑到搭配构式实例中三元组的现后顺序的同时,获取到两个搭配构式实例的最大特征相似性。
优选地,步骤S3包括以下子步骤:
(1)将聚类社区I
g
(2)合并从I
(3)选择入度为0且弧权重最大的节点n为初始节点,以深度优先方法遍历G并获取所有子图,并从中选择平均连接权重最高、且包含目标结构的子图G′作为搭配构式的句法模式;
(4)对于G′中的任意节点b,从I
(5)G′以及图中节点所对应的词语集合W及其关联强度
有益效果:本发明通过权重选取初始节点,并在深度优先遍历过程中采取权重优先策略,从而从有向有环图中获取最优路径作为搭配构式的典型代表句法模式。
为实现上述目的,按照本发明的第二方面,提供了一种搭配构式的可视化方法,该方法包括以下步骤:
采用如第一方面所述的方法,自动获取搭配构式;
对于每一个获取到的搭配构式,以依存类型和中心词为节点,并按照其在G′中出现顺序从左至右线性排列,如节点间的连接弧具有方向性,其中起始节点为中心词节点,箭头指向为依存词节点,连接弧显示连接权重。
有益效果:本发明通过利用搭配构式是以依存树为框架的的自有属性,将搭配构式转化为有向图,由于有向图的方向性从而生成的搭配构式知识库可解释性强,可用于语言在线教育、自动文法批改等领域。
为实现上述目的,按照本发明的第三方面,提供了一种搭配构式的自动获取系统,包括:计算机可读存储介质和处理器;
所述计算机可读存储介质用于存储可执行指令;
所述处理器用于读取所述计算机可读存储介质中存储的可执行指令,执行第一方面所述的搭配构式的自动获取方法。
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
本发明以特定词语或特定句式为单位,采用聚类方法模拟人类语言习得认知规律,获取搭配构式。搭配构式给出特定语言的一种典型语义交际功能,包含句法模式、词语、以及词语与该搭配构式之间的关联强度等信息。一方面克服了搭配的信息量不足的缺陷,又具有很强的解释性,能够满足在线语言教育和文法批改的需求。
附图说明
图1为本发明提供的一种搭配构式的自动获取方法流程图;
图2为本发明提供的一种搭配构式的可视化结果;
图3为本发明提供的一种具体搭配构式的可视化结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
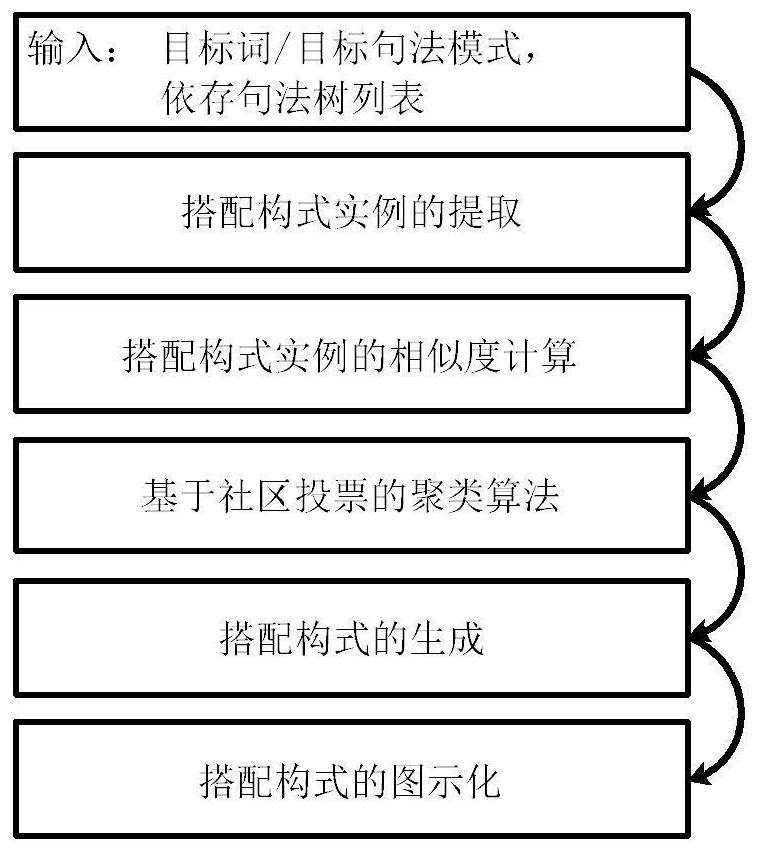
如图1所示,本发明提供了一种搭配构式的自动获取方法,该方法包括以下步骤:输入目标词/目标句法模式、依存句法树集合(语料),提取搭配构式实例,计算搭配构式实例的相似度,基于社区投票的聚类算法对搭配构式实例进行聚类,对于每个聚类社区生成搭配构式,最后,将搭配构式图示化。
1.输入格式定义
输入包括检索目标结构和依存树集合两项。
检索目标结构为第一项输入,有两种形式:(1)单个词语,可为动词、名词、形容词或副词,称为核心词w,如汉语中的形容词“快乐”;(2)依存子树。依存子树包含多个三元组,其中,三元组定义为
K=(e
其中,包含核心词通配符,记为CORE,CORE可以为h
第二项输入为依存树集合Γ={T
T
2.搭配构式实例的提取
(1)如果输入目标结构为单个词语,为获取搭配构式实例,遍历依存树集合Γ,逐个分析依存树T
选取条件为:对于依存树T
C=(e
其中,对于任意的e
(2)如果输入目标结构为依存子树K,遍历依存树集合Γ,逐个分析依存树T
对于依存树T
(1)e
(2)或c
(3)或h
3.搭配构式实例的相似度计算
两个三元组e
其中:
sim(h
sim(c
其中,cosine(·)为余弦函数,vec(·)为词向量。词向量获取可采用当前流行算法,如word2vec算法。
给定两个搭配构式实例C
C
C
C
其中,sim(e
基于C
上式中设置两个搭配构式实例的最低相似度为0.05,len(C)为C中所包含的三元组个数,
4.基于搭配构式社区的聚类方法
基于C
给定依存树集合Γ,逐个获取搭配构式实例,获得搭配构式实例集合Γ′={C
C
(1)获取C
(2)制作D的直方图,横轴为距离,取值范围为[0-1],纵轴为位于距离取值区间的搭配构式个数。假定Γ中与C
(3)获取D的均方差σ;
(4)定义构式C
其中,δ为倍增参数,1≤δ≤5。
步骤S2中,给定搭配构式实例集合Γ′={C
(C1)依次考察C
(C2)获取C
(C3)逐个考察N中的C
本实施例设置最大搜索距离r=0.6。
5.搭配构式的生成
对于每个聚类社区I
(1)将I
g
以下将 (2)合并从I (3)选择入度为0,弧权重最大的节点n,以n为初始节点,以深度优先方法遍历G并获取所有子图,并选择平均连接权重最高、且包含目标结构的子图G′为搭配构式的句法模式。平均连接权重为从起始节点到目的节点的路径中所有连接的权重之和/路径中连接个数。 (4)对于G′中的任意节点b,从I 设w
(5)G′以及图中节点所对应的词语集合及其关联强度构成由I 6.搭配构式的可视化 对于如下的搭配构式: ( X1={(W_1,V_1,F_1)} X2={(W_2,V_2,F_2),(W_3,V_3,F_3)} X3={(W_4,V_4,F_4)} CORE-WORD={(W_5,V_5,F_5),(W_6,V__6,F_6),(W_7,V__7,F_7)}) 其中,D1,D2和D3为依存类型,X1,X2和X3分别为句法槽位占位符,分别指向三个词语信息结构集合,其中每一个词语信息结构包括词性(W_·)、关联强度(V_·)和频次(F_·),所述频次(F_·)是词语在社区中出现的频次。 可视化规则如下所示:以依存类型和CORE-WORD为节点,并按照其在G’中出现顺序从左至右线性排列,如节点间的连接弧具有方向性,其中起始节点为中心词节点,即三元组中的第一个占位符,箭头指向为依存词节点,即三元组中的第二个占位符,连接弧显示连接权重。其可视化结果如图2所示。 具体地,以依存子树“auxpass(CORE,被)aspect(CORE,了)”为输入格式,语料库为《人民日报》语料库,可得到多个搭配构式,其中之一如图3所示。该搭配构式给出了汉语中“被”字句的一种典型运用模式,并具有良好的可解释性:ROOT节点表明该搭配构式不能内嵌成为其他句法成分,NSUBJ节点中给出的词语及其关联强度表明主语成分的语义类型为人,另一NSUBJ节点中的语义也以人为主体,CORE-WORD节点为谓语动词,除及物动词外,也包含部分习语。 这一技术克服了现有两类语言知识自动获取技术的缺陷:第一类语言知识自动获取技术源自语料库语言学领域,主要知识形态为仅限于两个词语之间的搭配信息,其信息量过少而难以满足语言在线教育、自动文法批改等需求。第二类语言知识自动获取方法源自基于深度学习的自然语言处理技术,以超大规模参数形式存在,可解释性不强,也不能满足语言教育和文法批改反馈对显性语言规则的需求。本发明以特定词语或特定句式为单位,采用聚类方法模拟人类语言习得认知规律,获取搭配构式。如图3所示,搭配构式给出特定语言(图中为汉语)的一种典型语义交际功能,包含句法模式、词语、以及词语与该搭配构式之间的关联强度等信息。这一方面克服了搭配的信息量不足的缺陷,又具有很强的解释性,能够满足在线语言教育和文法批改的需求。 本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 一种搭配构式的自动获取方法和系统、可视化方法
- 便携式电话信息可视化设备、便携式电话信息可视化系统以及在便携式电话信息可视化设备和系统中使用的便携式电话信息可视化方法