一种基于BERT-TextCNN的外卖评论分类方法
文献发布时间:2023-06-19 18:29:06
技术领域
本发明涉及情感倾向分析领域。
背景技术
2020年中国实体餐饮业呈现颓势,近十年来实体餐饮收入首次下跌。与之形成鲜明对比的是中国线上外卖市场的蓬勃发展。据统计, 2020年中国线上外卖用户达到了4.56亿人,较2019年增长了7.8%。线上订单量的激增和外卖交易规模的不断扩大造成了外卖评论文本的爆炸式增长。
分析外卖平台评论文本的情感倾向可以督促外卖平台完善服务体系,规范服务机制。情感分析目前被广泛应用于提取用户评论文本中的情感因素,从而精确表达用户对于商品的褒贬情绪,是文本挖掘的一种高效手段。但是现有的针对外卖评论文本的极性判别多倾向于总体情感倾向判别,而忽略了对于食品不同特征的情感倾向分类。一般的外卖评论文本往往涉及用户对商品不同特征的情感倾向,褒贬不一。笼统的判定整句极性不能协助平台高效挖掘用户行为倾向等特点。因此对外卖产品评论进行多特征情感极性分析可以更大程度的帮助平台实现高效管理,降低消费者对于多特征商品、商家的选择成本,为消费者提供更全面、有效的决策支撑。
BERT是近两年被广泛应用的自然语言处理手段,其应用动态词向量技术,开创性地同时进行下句预测和掩语言模型两个子任务,利用大规模数据预训练出 Transformer模型。由于BERT的词向量是依据上下文信息动态生成的,因此可以更好的解决一词多义等问题。结合电商评论文本长短不一,上下文关联性较强的特点,利用BERT进行词向量编码要比One-hot,word2vec,ELMo等方式更加准确,高效。故本发明用BERT编码代替传统Text-CNN网络嵌入层的word2ve c编码,增强评论文本的连贯性,为后续多任务学习打下更好的基础。为了提升分类准确率,本发明在Text-CNN的卷积和池化层加入了降维CBAM注意力机制。
发明内容
针对线上外卖平台评论文本,本发明设计了一种基于BERT-TextCNN的外卖评论分类方法。将BERT模型训练所获得词向量矩阵通过含有注意力机制的Tex t-CNN网络对文本进行长距离编码,判别外卖评论中的不同主题并对相关特征评价的情感极性进行分析,实现基于用户评论的多特征情感极性分析。该方法主要包含五个步骤:
步骤1:对输入的评论文本进行预处理,包括去除停用词和分词等,最终得到一个token列表。
步骤2:利用BERT进行文本向量化处理,通过字嵌入、段嵌入、位置嵌入和双向Transformer编码器生成词嵌入矩阵。
步骤3:搭建基于Text-CNN的多任务文本分类、极性判别模型。将步骤2 得到的词嵌入矩阵作为Text-CNN嵌入层的输出进行多标签文本分类,训练出基于Text-CNN的特征识别、极性判别模型。
步骤4:在Text-CNN模型的卷积和池化部分加入降维卷积注意力机制(CB AM),在通道和空间两个维度优化Text-CNN网络,提升分类准确率。
步骤5:对模型进行训练和验证。实现输入外卖评论文本,自动判别所涉主题情感极性的功能。
附图说明
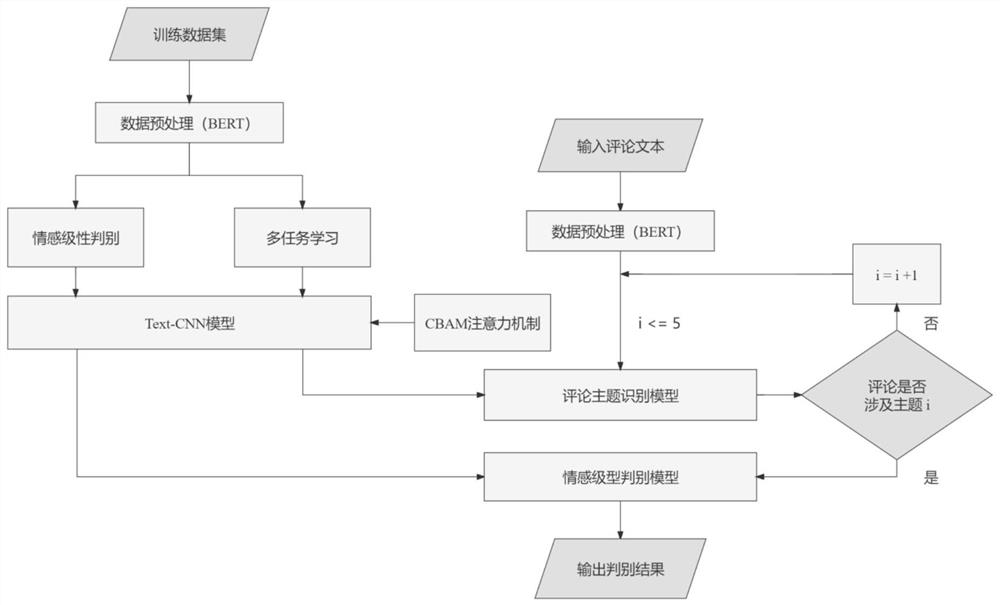
图1为:算法整体逻辑流程图。
图2为:BERT词向量嵌入表示图。
图3为:多任务学习模式图。
图4为:Text-CNN网络结构图。
图5为:CBAM降维注意力机制模型图。
图6为:训练模块定义函数及其功能。
图7为:评论文本特征、极性判别流程图。
图8为:输入输出文本示例。
具体实施方式
下面将结合本发明实施例中的附图,对本发明进一步说明。
图1是算法整体逻辑流程图,本发明主要以PyTorch框架为基础,利用 BERT-TextCNN模型,针对外卖平台评论文本的不同主题进行多任务情感极性分析,具体实施方式如下:
步骤1数据预处理
本发明采用BERT进行中文分词,BERT进行中文分词的方式与jieba、pyltp 等传统分词模型不同。BERT特有的tokenization模块为数据的预处理提供了很大的便利,tokenization模块主要有两个分词器:BasicTokenizer和 WordpieceTokenizer。前者可以被视作粗略分词器,后者在前者的基础上进行再一次切分,得到子词。FullTokenizer是两者的结合。比如对评论“包装还不错,但送来的时候菜已经凉了。”首先对该评论文本进行BasicTokenizer,流程为: (1)转化为可以读入的编码;(2)删除非法字符;(3)空格间隔分词;(4)去除多余字符、进行标点分词;(5)二次空格间隔分词;(6)结束。由此可以得到一个初步的token列表{‘包‘’装‘’还‘’不‘’错’‘但‘’送’‘来‘’的‘’时‘’候‘’菜’‘已‘’经’‘凉‘’了’}后再对每个token进行一次WordpieceTokenizer,但是这一步对纯中文文本分词结果影响不大。最终得到最终的分词结果{tok
步骤2利用BERT进行文本向量化处理
针对步骤1得到的词集,利用BERT进行文本向量化处理。BERT的输入由字嵌入(tokenembedding)、段嵌入(segment embedding)和位置嵌入(position embe dding)三部分相加构成。每句话用[CLS]和[SEP]作为开头和结尾的标记。在步骤1所得的分词结果前后分别加上{CLS},{SEP}起止符作为输入,即 {[CLS],tok
E=E
E=E
图2是BERT词向量嵌入表示图,最终的输出为:
{E
BERT模型采用双向Transformer编码器获取文本的特征表示。输入词嵌入列表,经过多层双向Transformer训练后生成相应的向量表征,如下式:
{C,T
Transformer编码器可以理解为一个基于自注意力机制的Seq2Seq模型,Transformer编码器采用Encoder-Decoder结构,仅使用自注意力机制进行进行词语间关联的挖掘。既大程度提升了长距离特征的捕获能力,又兼顾了并行计算。
步骤3搭建Text-CNN属性识别、极性判别模型
线上外卖平台评论文本通常涉及商品的多个特征,如“包装还不错,但送来的时候菜已经凉了。”该条评论包含配送与包装两个主题。本发明结合已有研究确定消费者对于外卖商品用户评论的五个主题:价格、口感、包装、分量和配送。
1.多任务学习
评论属性识别本质上是一个多标签的二分类任务。即,按照五个不同的属性一次将评论文本分类为“0”或“1”。“0”表示评论文本不包含该属性,“1”表示评论文本含有该属性。例如文本“包装还不错,但送来的时候菜已经凉了。”的输出为 {'0','0','1','0','1'}。
图3为多任务学习模式图。在本发明中利用Text-CNN模型来完成5个子任务的主题分类,构建一个基于Text-CNN的多任务分类模型。本发明采用多任务学习中的参数硬共享模式,这一模型最重要的部分是参数共享层,即共享词嵌入部分的数据,保留五个子任务的分类输出,以达到降低拟合率的目的。
2.Text-CNN模型
图4为Text-CNN模型的网络架构图,Text-CNN该模型由输入层(Input lay er)、词嵌入层(Embedding layer)、卷积层(Conv layer)、池化层(Pooling la yer)和全连接层(Fully-connected layer)组成。
2.1输入层和词嵌入
由步骤2经由BERT得到的词嵌入矩阵可以作为Text-CNN模型词嵌入层的输入,赋值给模型作为该层的参数,经过模型的不断训练,该层将BERT输出的词嵌入矩阵转化为低维、稠密且具有语义的向量。
2.2卷积层
在Text-CNN模型中,一个词向量就是一个最小的特征单元,所以卷积核 C(C∈R
确定卷积核的大小后就可以进行卷积操作了,用于文本分类的卷积操作是一维卷积,输入的数据只从一个维度通过,故用nn.Conv1d函数实现一维卷积,设置通道数为512。将卷积核c与词向量矩阵T中的第i个窗口t
f
其中θ为偏置量,ReLu()为激活函数。ReLu函数也名为修正线性单元,其数学图形形似斜坡函数,见下式:
ReLu(x)=max(0,x),ReLu(x)∈(0,∞)
卷积核C(C∈R
2.3池化层
Text-CNN模型池化层的作用是为了统一每个卷积核提取的特征向量的维度。一般是使用最大池化,选取每个特征向量的最大值作为特征值,最终得到 f
2.4全连接层和输出层
在本发明中Text-CNN模型需要两个全连接层,将池化所得的卷积核拼接后得到新的特征Y,其中m为768。
两个全连接层分别以ReLu、sigmoid为激活函数。sigmoid函数的输出中心远离0值,徘徊在0.5左右。中心频率的改变使得梯度总保持正值或负值;使输出值平滑地压缩于0~1之间,如下式所示:
全连接层还会将特征Y以10%的概率随即丢弃,最终输出结果Z如下式,其中w
步骤4利用CBAM注意力机制提高准确率
图5为CBAM降维注意力机制模型图。CBAM名为“卷积注意力机制,”是一种用于前馈卷积神经网络的简单而有效的注意力模块,具有量级轻、通用性强的特性,故可以以非常低廉的成本轻易地衔接到任何卷积神经网络架构中。由于卷积运算是将不同通道和空间的信息融合在一起来提取信息特征,因此,CBAM 模型可用于改进上述的两个关键维度。在给定特征矩阵的条件下,该模块依照通道和空间这两个独立维度顺次输出注意力矩阵。
CBAM至今为止只应用于二维图像处理方面。本发明首次将其应用在一维词向量的处理过程中,在Text_CNN模型的卷积和池化部分加入了CBAM注意力机制,最终得到了满意的效果。
1.通道注意力模块(CAM)
特征矩阵每个通道维度的处理过程都可以被视作数据检测的过程。本发明主要研究一维卷积过程,故默认通道数为1。
在Text_CNN的卷积和池化部分,模型分别应用平均、最大池化整合词向量的通道特征,分别求出最大(平均)池化后通过共享网络的特征矩阵。其中共享网络由具多层感知器Mlp组成,在本发明中为BERT-TextCNN模型。将二者整合在一起再进行激活就得到了通道注意力矩阵C
式中,F表示输入特征,
2.空间注意力模块(SAM)
CBAM通过利用特征的空间关系来生成空间注意力矩阵。为了计算空间注意力矩阵需要沿通道轴进行最大池化操作,并将结果连接起来生成有效的特征描述符。将他们沿通道轴合并,将CAM模块的输出C
其中
S
最后将该空间注意力特征图和该模块的输入F
步骤5训练验证模型
在训练模块,首先要进行数据的初始化。调用Pytorch的model.zero_grad将梯度置0。初始化后首先上传数据,将模型设置为train模式。接下来计算权重的梯度,利用model.eval函数验证模型,所用到的函数如图6所示。也可以用于后续的验证。
本发明最终实现的目标就是判别评论文本所包含的主题及其极性。与训练模型的过程相同,首先输入评论文本,利用BERT进行数据与处理,输入主题判别模型判断所包含的主题;然后依次输入对应的情感极型判别模型,得到判别结果,整体逻辑流程图如图7所示,实现效果如图8所示。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围。凡采用等同替换或等效替换,这些变化是显而易见,一切利用本发明构思的发明创造均在保护之列。
- 一种基于卷积神经网络和BM25的外卖评论情感极性分析方法
- 一种基于关联规则的Web评论观点自动分类系统及分类方法