一种中医药文本关键信息的智能抽取方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于文本处理领域,具体涉及一种中医药文本关键信息的智能抽取方法。
背景技术
实体识别技术是自然语言处理领域中一项关键的技术,是其他自然语言处理应用的基础,旨在从文本中抽取人们所关注的实体片段,例如人名、机构名、地名等。目前,针对中文命名实体识别在一定条件下已经取得较好的性能。
随着自然语言处理技术的深入应用,以及社会各行业的发展。文本的种类也越来越多,比如广播对话、电视新闻、网络博客等。在不同的领域所定义的命名实体也不尽相同。然而,在中医药命名实体识别领域中,还面临着巨大的挑战。
为了使中医药分类识别模型的效果更好,信息提取更加的准确,再信息提取模型的训练过程中需要大量的高质量标注数据,而对中医药领域的数据标注门槛较高,需要很多专业知识,普通人无法完成,标注代价昂贵;因此,如何利用有限的数据训练出效果更好的信息提取模型是目前亟待解决的问题。
发明内容
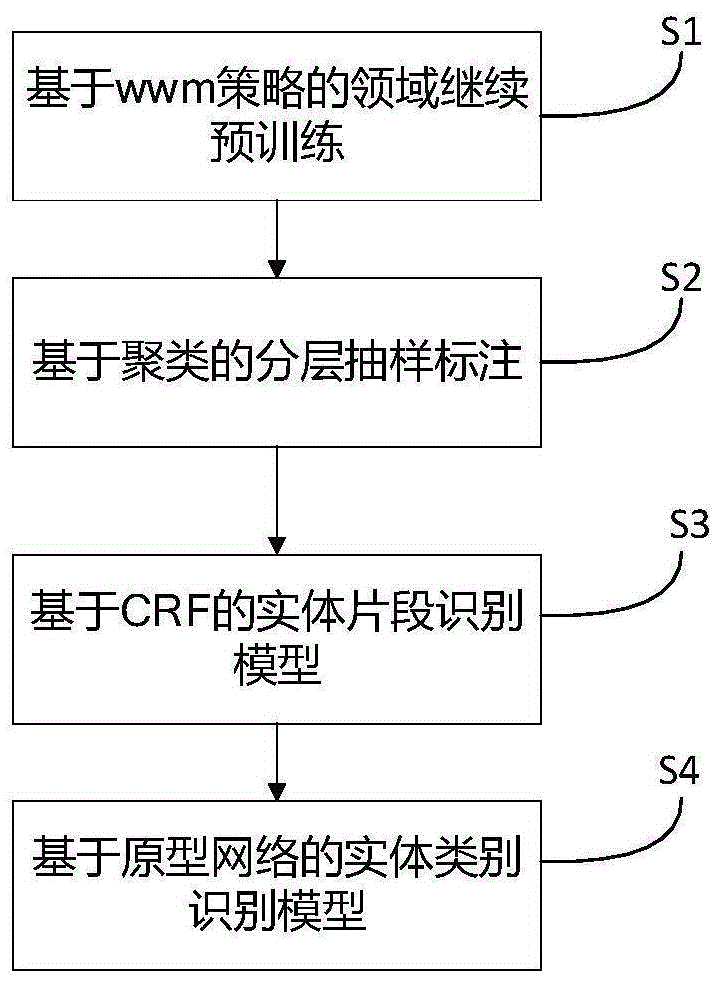
为了解决背景技术中存在的问题,本发明提供一种中医药文本关键信息的智能抽取方法,该方法包括:将待识别的中医药文本数据输入到训练好的实体片段识别模型中,预测中医药文本中实体的位置;将待识别的中医药文本数据以及对应的实体位置信息输入到训练好的实体类别识别模型,预测中医药文本中实体的类别;其中,所述实体片段识别模型采用BIO标记法结合Bert+CRF模型架构;所述实体类别识别模型采用原型网络结构;
对实体片段识别模型和实体类别识别模型进行训练的过程包括:
S1:获取原始中医药文本数据,采用全词掩盖策略对原始中医药文本数据进行继续预训练得到中医药文本的预训练模型M;
S2:采用基于语义聚类的分层抽样法抽取部分原始中医药文本进行人工标注生成具有标签信息的训练样本集,所述标签信息包括:原始中医药文本中实体的位置信息和原始中医药文本中实体的类别信息;
S3:根据中医药文本的预训练模型M、训练样本集和训练样本的标签信息利用反向传播机制对实体片段识别模型进行训练;
S4:根据中医药文本的预训练模型M、训练样本集和训练样本的标签信息利用反向传播机制对实体类别识别模型进行训练。
优选的,所述采用全词掩盖策略对原始中医药文本数据进行继续预训练包括:
S11:使用Jieba分词中的隐马尔科夫分词模型对原始中医药文本进行分词;
S12:采用全词掩盖策略将原始中医药文本中20%的词语替换为等长度的“[MASK]”标记得到x
S13:将x
优选的,所述采用基于语义聚类的分层抽样法抽取部分原始中医药文本进行人工标注生成具有标签信息的训练样本集包括:
S21:使用USE获取原始中医药文本的语义特征;
S22:将每个原始中医药文本的语义特征输入到K-means聚类算法进行聚类得到K个聚类簇;
S23:从每个聚类簇中随机抽取适量样本,安排专业标注人员进行标注,得到具有标签信息的训练样本集L。
优选的,所述对实体片段识别模型进行训练的具体步骤包括:
S31:采用BIO标记法对训练样本中的词进行标记,所述标记包括:当词属于实体片段开头标记为B,当词属于实体片段中间标记为I,当词属于非实体片段标记为O;
S32:采用中医药文本的预训练模型M提取训练样本中每个字符的向量得到训练样本的词向量序列;
S33:将训练样本的词向量序列线性映射后输入到CRF层根据BIO标记利用反向传播机制对实体片段识别模型的参数进行微调完成实体片段识别模型的训练。
优选的,所述对实体类别识别模型进行训练的具体步骤包括:
S41:采用中医药文本的预训练模型M作为初始化编码层对训练样本进行编码,得到训练样本的文本向量;
S42:根据训练样本实体的位置信息将每个实体片段S中所有的字符向量做平均聚合得到实体片段的词向量:
S43:根据训练样本中所有实体片段的词向量计算每个实体类别的类原型:
S44:计算训练样本中实体片段的词向量与每个实体类别类原型之间的距离;
S45:将训练样本中所有实体片段的词向量与每个实体类别类原型之间的距离输入到Softmax层进行归一化,得到训练样本中实体片段的概率分布:取概率最大的类别作为实体片段的预测输出;
S46:根据实体片段的词向量与每个实体类别类原型之间的距离和训练样本的类别信息构建损失函数,利用反向传播机制调节实体类别识别模型的参数,当损失函数小于设定阈值完成实体类别识别模型的训练。
优选地,所述损失函数包括:
其中,
本发明至少具有以下有益效果
本发明将聚类技术和元学习技术应用到中医药命名实体识别领域中,采用聚类技术辅助选择出具有代表性的标注样本,节省标注人力的同时提升标注质量;将命名实体识别任务拆分为实体位置识别和实体类别识别两个部分,减小模型的学习难度,提升单个模型的效果。在实体类别识别模型中,设计特定的原型网络学习到各实体类别的元向量,具有泛化能力和鲁棒性。
附图说明
图1为本发明的方法流程示意图;
图2为本发明模型结构流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1和图2,本发明提供一种中医药文本关键信息的智能抽取方法,该方法包括:将待识别的中医药文本数据输入到训练好的实体片段识别模型中,预测中医药文本中实体的位置;将待识别的中医药文本数据以及对应的实体位置信息输入到训练好的实体类别识别模型,预测中医药文本中实体的类别;其中,所述实体片段识别模型采用BIO标记法结合Bert+CRF模型架构;所述实体类别识别模型采用原型网络结构;
对实体片段识别模型和实体类别识别模型进行训练的过程包括:
S1:获取原始中医药文本数据,采用全词掩盖(Whole Word Masking)策略对原始中医药文本数据进行继续预训练得到中医药文本的预训练模型M;
在本发明中采用公开的Entity Recognition of Traditional ChineseMedicine's Manual中药说明书实体识别数据集。
优选地,所述采用全词掩盖策略对原始中医药文本数据进行继续预训练包括:
S11:使用Jieba分词中的隐马尔科夫分词模型(HMM)对原始中医药文本进行分词;
S12:采用全词掩盖策略将原始中医药文本中20%的词语替换为等长度的“[MASK]”标记得到x
S13:将x
S2:采用基于语义聚类的分层抽样法抽取部分原始中医药文本进行人工标注生成具有标签信息的训练样本集,所述标签信息包括:原始中医药文本实体的位置信息和原始中医药文本实体的类别信息;
S21:使用USE(Universal Sentence Encoder)获取原始中医药文本的语义特征;
S22:将每个原始中医药文本的语义特征输入到K-means聚类算法进行聚类得到K个聚类簇;
S23:从每个聚类簇中随机抽取适量样本,安排专业标注人员进行标注,得到具有标签信息的训练样本集L。
S3:根据中医药文本的预训练模型M、训练样本集和训练样本的标签信息利用反向传播机制对实体片段识别模型进行训练;
S31:采用BIO标记法对训练样本中的词进行标记,所述标记包括:当词属于实体片段开头标记为B,当词属于实体片段中间标记为I,当词属于非实体片段标记为O;例如,训练样本为:本品为薄膜衣片用于盆腔炎,那么该样本的BIO 标记序列为:OOOBIIIOOBII,所述样例中“薄膜衣片”和“盆腔炎”两个实体分别为中医药领域中的剂型和症状。
S32:采用中医药文本的预训练模型M提取训练样本中每个字符的向量得到训练样本的词向量序列h=M(x);
S33:将训练样本的词向量序列h=M(x)线性映射后输入到CRF层根据BIO 标记利用反向传播机制对实体片段识别模型的参数进行微调完成实体片段识别模型的训练。
S4:根据中医药文本的预训练模型M、训练样本集和训练样本的标签信息利用反向传播机制对实体类别识别模型进行训练;
S41:采用中医药文本的预训练模型M作为初始化编码层对训练样本进行编码,得到训练样本的文本向量T=M(x),T
S42:根据训练样本实体的位置信息将每个实体片段S中所有的字符向量做平均聚合得到实体片段的词向量:
其中,T
S43:根据训练样本中所有实体片段的词向量计算每个实体类别的类原型:
其中,C
S44:计算训练样本中实体片段的词向量与每个实体类别类原型之间的距离:
其中,T
S45:将训练样本中所有实体片段的词向量与每个实体类别类原型之间的距离输入到Softmax层进行归一化,得到训练样本中实体片段的概率分布:取概率最大的类别作为实体片段的预测输出;
其中,p
S46:根据实体片段的词向量与每个实体类别类原型之间的距离和训练样本的类别信息构建损失函数,利用反向传播机制调节实体类别识别模型的参数,当损失函数小于设定阈值完成实体类别识别模型的训练;
其中,
本发明将聚类技术和元学习技术应用到中医药命名实体识别领域中,采用聚类技术辅助选择出具有代表性的标注样本,节省标注人力的同时提升标注质量;将命名实体识别任务拆分为实体位置识别和实体类别识别两个部分,减小模型的学习难度,提升单个模型的效果。在实体类别识别模型中,设计特定的原型网络学习到各实体类别的元向量,具有泛化能力和鲁棒性。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。