使用深度信息净化声音的方法和系统以及计算机可读介质
文献发布时间:2023-06-19 10:22:47
技术领域
本申请涉及语音增强领域,特别涉及一种使用深度信息净化声音的方法和系统以及计算机可读介质。
背景技术
声音净化(voice purification)是一种语音增强或语音去噪技术,其旨在将噪声音频中的特定人的声音与背景噪声以及和该人处于同一环境中的其他人的声音分开。伴随噪声音频的人的视觉信息可用于声音净化。声音净化可提高人和/或机器的语音的质量和/或清晰度。
发明内容
本申请的目的在于提出一种使用深度信息净化声音的方法和系统以及计算机可读介质。
在本申请的第一方面,方法包括:
至少一个处理器接收多个第一图像,多个所述第一图像至少包括发出声音的人的与嘴相关的部分,且每一所述第一图像均具有深度信息;
所述至少一个处理器获取噪声谱,所述噪声谱包括人的声音的第一表示;
所述至少一个处理器使用所述第一图像提取多个视觉特征,其中,多个所述视觉特征中的一个使用多个所述第一图像中的第二图像的深度信息获得;
所述至少一个处理器使用所述噪声谱提取多个音频特征;
所述至少一个处理器使用所述视觉特征和所述音频特征确定第一谱;
所述至少一个处理器从所述噪声谱中减去所述第一谱,以获得人的声音的净化表示;以及
通过与输入/输出(I/O)相关的输出设备使用人的声音的净化表示输出响应。
根据本申请第一方面的实施例,多个所述视觉特征中的一个使用多个所述第一图像中的所述第二图像的深度信息中的人的舌头的深度信息来获得。
根据本申请第一方面的实施例,所述方法还包括:
在人发出声音时,通过摄像头产生红外光,所述红外光照亮与嘴相关的部分;以及
通过所述摄像头捕捉所述第一图像。
根据本申请第一方面的实施例,所述至少一个处理器接收多个所述第一图像的步骤包括:接收多个图像集,其中每一所述图像集包括所述第一图像中的对应的第三图像以及对应的第四图像,所述对应的第四图像具有颜色信息,且所述第四图像的颜色信息用于增强所述对应的第三图像的深度信息;以及所述至少一个处理器提取所述视觉特征的步骤包括:使用多个所述图像集提取所述视觉特征,且多个所述视觉特征中的一个使用多个所述图像集中的第一图像集的深度信息和颜色信息来获得。
根据本申请第一方面的实施例,所述视觉特征中的一个通过使用多个所述第一图像中的多个第五图像的深度信息来获得。
根据本申请第一方面的实施例,所述至少一个处理器确定所述第一谱的步骤包括:使用所述视觉特征和所述音频特征之间的关联确定第二表示。
根据本申请第一方面的实施例,所述第二表示为所述第一谱;以及确定所述第二表示的步骤通过循环神经网络(recurrent neural network,RNN)执行。
根据本申请第一方面的实施例,第二表示为视听表示;确定所述第二表示的步骤通过RNN执行;以及所述至少一个处理器确定所述第一谱的步骤还包括:通过全连接网络使用所述第二表示确定所述第一谱。
在本申请的第二方面,系统包括:至少一个存储器,至少一个处理器,以及输入/输出(I/O)相关的输出设备。所述至少一个存储器用于存储程序指令。所述至少一个处理器用于执行所述程序指令,且所述程序指令使所述至少一个处理器执行步骤:
接收多个第一图像,多个所述第一图像至少包括发出声音的人的与嘴相关的部分,且每一所述第一图像均具有深度信息;
获取噪声谱,所述噪声谱包括人的声音的第一表示;
使用所述第一图像提取多个视觉特征,其中,多个所述视觉特征中的一个通过使用多个所述第一图像中的第二图像的深度信息获得;
使用所述噪声谱提取多个音频特征;
使用所述视觉特征和所述音频特征确定第一谱;以及
从所述噪声谱中减去所述第一谱,以获得人的声音的净化表示。
所述输入/输出(I/O)相关的输出设备用于使用人的声音的净化表示输出响应。
根据本申请第二方面的实施例,多个所述视觉特征中的一个通过使用多个所述第一图像的所述第二图像的深度信息中的人的舌头的深度信息来获得。
根据本申请第二方面的实施例,所述系统还包括摄像头,所述摄像头用于:在人发出声音时产生红外光,所述红外光照亮与嘴相关的部分;以及捕捉所述第一图像。
根据本申请第二方面的实施例,所述接收多个所述第一图像的步骤包括:接收多个图像集,其中每一所述图像集包括所述第一图像中的对应的第三图像以及对应的第四图像,所述对应的第四图像具有颜色信息,且所述第四图像的颜色信息用于增强所述对应的第三图像的深度信息;以及所述提取所述视觉特征的步骤包括:使用多个所述图像集提取所述视觉特征,且多个所述视觉特征中的一个使用多个所述图像集中的第一图像集的深度信息和颜色信息来获得。
根据本申请第二方面的实施例,所述视觉特征中的一个通过使用多个所述第一图像中的多个第五图像的深度信息来获得。
根据本申请第二方面的实施例,所述确定所述第一谱的步骤包括:使用所述视觉特征和所述音频特征之间的关联确定第二表示。
根据本申请第二方面的实施例,所述第二表示为所述第一谱;以及确定所述第二表示的步骤通过RNN执行。
根据本申请第二方面的实施例,第二表示为视听表示;确定所述第二表示的步骤通过RNN执行;以及所述确定所述第一谱的步骤还包括:通过全连接网络使用所述第二表示确定所述第一谱。
在本申请的第三方面,提供了一种非暂时性计算机可读介质,其上存储有程序指令,所述程序指令在由至少一个处理器执行时使所述至少一个处理器执行步骤:
接收多个第一图像,多个所述第一图像至少包括发出声音的人的与嘴相关的部分,且每一所述第一图像均具有深度信息;
获取噪声谱,所述噪声谱包括人的声音的第一表示;
使用所述第一图像提取多个视觉特征,其中,多个所述视觉特征中的一个通过使用多个所述第一图像中的第二图像的深度信息获得;
使用所述噪声谱提取多个音频特征;
使用所述视觉特征和所述音频特征确定第一谱;
从所述噪声谱中减去所述第一谱,以获得人的声音的净化表示;以及
驱使与输入/输出(I/O)相关的输出设备使用人的声音的净化表示输出响应。
根据本申请第三方面的实施例,多个所述视觉特征中的一个通过使用多个所述第一图像中的所述第二图像的深度信息中的人的舌头的深度信息来获得。
根据本申请第三方面的实施例,驱使所述摄像头在人发出声音时产生红外光并捕捉所述第一图像,其中,所述红外光照亮与嘴相关的部分。
根据本申请第三方面的实施例,所述接收多个所述第一图像的步骤包括:接收多个图像集,其中每一所述图像集包括所述第一图像中的对应的第三图像以及对应的第四图像,所述对应的第四图像具有颜色信息,且所述第四图像的颜色信息用于增强所述对应的第三图像的深度信息;以及所述提取所述视觉特征的步骤包括:使用多个所述图像集提取所述视觉特征,且多个所述视觉特征中的一个使用多个所述图像集中的第一图像集的深度信息和颜色信息来获得。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中描述的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本申请的一些实施例。对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他实施例的附图。
图1示出了根据本申请一实施例的被人用作的(voice-related)系统的移动电话以及该语音相关系统的硬件模块的示意图。
图2示出了根据本申请一实施例的包括人发声的至少与嘴相关的部分的多个图像的示意图。
图3示出了根据本申请一实施例的语音相关控制设备的软件模块以及语音相关系统的相关硬件模块的框图。
图4示出了根据本申请一实施例的语音相关系统中的声音净化模块中的神经网络模型的框图。
图5示出了根据本申请的另一实施例的语音相关系统中的声音净化模块中的神经网络模型的框图。
图6示出了根据本申请一实施例的用于声音相关交互的方法的流程图。
具体实施方式
以下结合附图详细描述本申请实施例的技术内容、结构特征,以及实现的目的和效果。具体地,本申请实施例中的术语仅用于描述特定实施,并不用于限制本申请。
如本文中所使用的,术语“使用”是指直接使用对象来执行步骤的情形,或者通过至少一个中间步骤修改对象并且直接使用修改后的对象执行该步骤的情形。
图1示出了根据本申请一实施例的被人150用作声音相关系统的移动电话100以及该声音相关系统的硬件模块的示意图。如图1所示,人150使用移动电话100作为声音相关系统。其中,该声音相关系统使用视觉信息净化人150的声音中的噪声音频,并允许将人150的已净化的声音的音频用于生成输入/输出(input/output,I/O)相关的输出设备126的响应。移动电话100包括深度摄像头102、RGB摄像头104、至少一个麦克风106、存储设备(storagedevice)108、处理器模块110、存储模块(memory module)112、至少一个天线114、显示器116、至少一个扬声器118,以及总线120。声音相关系统包括I/O相关的输入设备122、声音相关控制设备124,以及I/O相关的输出设备126。声音相关系统能够使用替代源,例如存储设备108或网络170。
深度摄像头102用于产生红外光,该红外光在人150发出声音时照亮人150的至少与嘴相关的部分。该深度摄像头102还用于捕捉包括发出声音的人150的至少与嘴相关的部分的多个图像di
至少一个麦克风106用于从环境声音中产生噪声音频。噪声音频包括人150的声音的时域表示,还可以包括环境中其他人的声音和/或背景噪声的时域表示。
深度摄像头102和RGB摄像头104用作用于视觉输入的与I/O相关的输入设备122之一。由于深度摄像头102使用红外光以照亮人150,因此,与I/O相关的输入设备122允许人150处于光照条件差的环境中。至少一个麦克风106用作用于音频输入的另一与I/O相关的输入设备122。视觉输入和音频输入可以实时使用,例如用于拨打电话,进行视频/语音聊天和语音听写。或者,视觉输入和音频输入也可以录制视觉输入和音频输入并在后续使用,例如用于发送视频/语音消息,以及为事件录制视频/语音。当录制视觉输入和音频输入以备后续使用时,声音相关控制系统124不会直接从I/O相关的输入设备122中接收视觉输入和音频输入。该声音相关控制系统124可以从替代源,例如存储设备108或网络170中接收视觉输入和音频输入。
存储模块112可以为非暂时性计算机可读介质,其包括至少一个存储器,且该存储器存储可由处理器模块110执行的程序指令。处理器模块110包括至少一个处理器。该至少一个处理器可通过总线120直接或间接向深度摄像头102、RGB摄像头104、至少一个麦克风106、存储设备108、存储模块112、至少一个天线114、显示器116以及至少一个扬声器118发送信号,或者通过总线120直接或间接地从深度摄像头102、RGB摄像头104、至少一个麦克风106、存储设备108、存储模块112、至少一个天线114、显示器116以及至少一个扬声器118中接收信号。至少一个处理器用于执行将该至少一个处理器配置为声音相关控制设备124的程序指令。声音相关控制设备124控制I/O相关的输入设备122以生成图像di
至少一个天线114用于生成至少一个无线电信号,该至少一个无线电信号承载直接或间接地从声音净化结果中获得的数据。至少一个天线114用作与I/O相关的输出设备126之一。当响应例如是至少一个蜂窝无线电信号时,该至少一个蜂窝无线电信号可以承载例如声音数据,该声音数据从用于已净化的声音的音频中直接获得以拨打电话。当响应例如是至少一个蜂窝无线电信号或至少一个Wi-Fi无线电信号时,该至少一个蜂窝无线电信号或至少一个Wi-Fi无线电信号可以直接承载例如视频数据,该视频数据从图像di
显示器116用于直接或间接从声音净化结果中生成光。显示器116用作I/O相关的输出设备126之一。当响应例如是正在显示的视频的图像部分的光时,正在显示的图像部分的光可以对应于用于已净化的声音的视频的音频部分。当响应例如是所显示的图像的光时,所显示的图像的光可以承载例如通过语音识别从用于已净化的声音的音频中获得并被输入到移动电话100的文本。
至少一个扬声器118用于生成声音,该声音直接或间接地从声音净化结果中获得。至少一个扬声器118用作与I/O相关的输出设备126之一。当响应例如是用于已净化的声音的视频的音频部分的声音时,该声音直接从用于已净化的声音的视频的音频部分中获取。
图1中的声音相关系统为移动电话100。其他类型的声音相关系统,例如未将I/O相关的输入设备、声音相关控制设备和I/O相关的输出设备集成到一个设备中的电视会议系统也在本申请的预期范围内。
图2示出了根据本申请一实施例的包括发出声音的人150(参见图1)的至少与嘴相关的部分的图像di
图3示出了根据本申请一实施例的声音相关控制设备124(如图1所示)的软件模块以及声音相关系统的相关硬件模块的框图。声音相关控制设备124包括摄像头控制模块302、麦克风控制模块304、声音净化模块320、天线控制模块314、显示控制模块316,以及扬声器控制模块318。声音净化模块320包括视频图像预处理模块306、音频预处理模块308、神经网络模型310,以及音频后处理模块312。
摄像头控制模块302用于在人150发出声音时,控制深度摄像头102产生照亮人150(如图1所示)的至少与嘴相关的部分的红外光,并捕捉图像di
声音净化模块320用于使用图像di
视频图像预处理模块306用于从深度摄像头102中接收图像di
音频预处理模块308用于从至少一个麦克风106中接收噪声音频,并执行包括重采样和短时傅立叶变换(short-time Fourier transform,STFT)的步骤。在重采样步骤中,将噪声音频重新采样到例如16kHz。在STFT步骤中,对重采样的噪声音频执行STFT以生成包括人150的声音的频域相关表示的噪声谱(noisy spectrogram)402(如图4所示)。汉宁窗(Hann window)可以用于STFT。STFT的窗口大小设置为例如640个样本,以对应于单个图像rdi
神经网络模型310用于接收图像rdi
音频后处理模块312用于对去噪声谱418进行短时傅立叶逆变换(inverse short-time Fourier transform,ISTFT),以生成包括人150的声音的净化时域表示;其中,该去噪声谱418包括人150的声音的净化频域相关表示。
天线控制模块314用于驱使至少一个天线114根据声音净化结果生成响应;其中,该声音净化结果为包括声音的净化时域表示的音频。显示控制模块316用于驱使显示设备112根据声音净化结果生成响应;其中,该声音净化结果为包括声音的净化时域表示的音频。扬声器控制模块318用于驱使至少一个扬声器118根据声音净化结果产生响应;其中,该声音净化结果为包括声音的净化时域表示的音频。
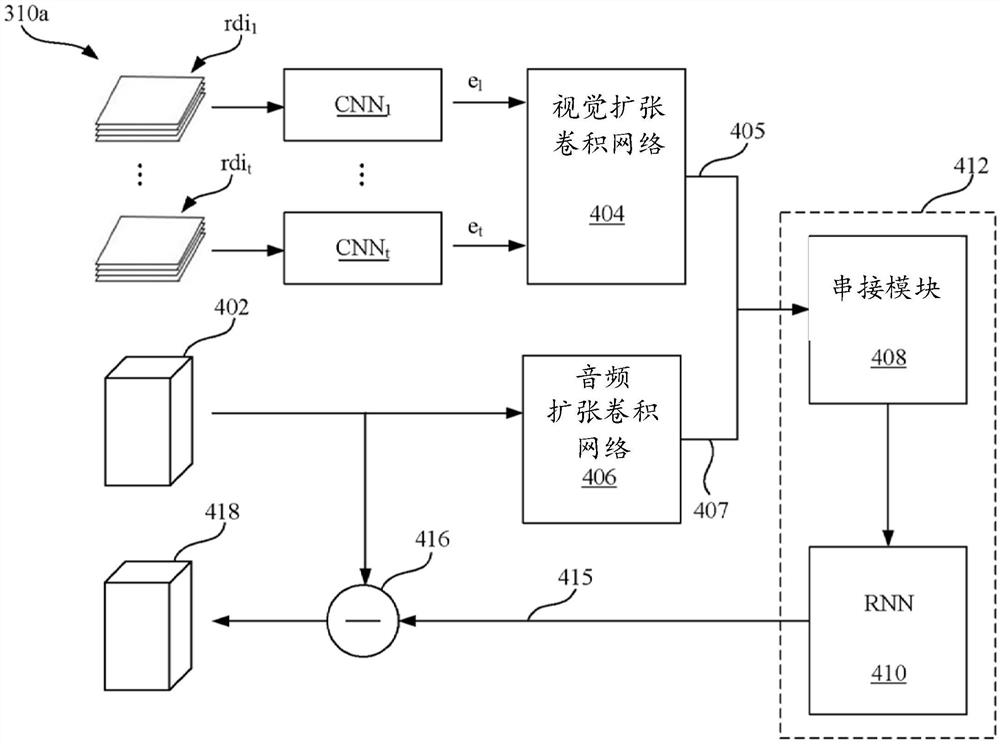
图4示出了根据本申请一实施例的声音相关系统中的声音净化模块320(如图3所示)中的神经网络模型310a的框图。参见图4,神经网络模型310a包括多个卷积神经网络(convolutional neural networks,CNN)CNN
其中,每一卷积神经网络CNN
每一卷积神经网络CNN
视觉扩张卷积网络404用于在考虑到与嘴相关的部分的嵌入部e
视觉扩张卷积网络404和音频扩张卷积网络406是可选的。可选地,将与嘴相关的部分的嵌入部e
视听融合与关联模块412用于融合并关联高级视觉特征405和高级音频特征407。串接模块408用于通过将高级视觉特征405和高级音频特征407在时间上对应串接来执行视听融合。RNN 410用于根据高级视觉特征405和高级音频特征407之间的关联来确定第一谱415。RNN410的每一RNN单元接收对应的串接的高级视觉特征和高级音频特征。通过考虑高级视觉特征405和高级音频特征407的交叉视图(cross-view)的时间上下文,可以获得高级视觉特征405和高级音频特征407之间的关联。与高级视觉特征405不相关的高级音频特征407的一部分反映在第一谱415中。RNN410可以是双向长短期记忆(bidirectional longshort-term memory,LSTM)网络,其可仅包括一个双向LSTM层或包括多个双向LSTM层的堆栈。其他类型的RNN,例如单向LSTM、双向门控循环单元,单向门控循环单元,都在本申请的预期范围内。
视听融合与关联模块412包括具有早期融合的高级视觉特征405和高级音频特征407作为输入的RNN 410。可选地,视听融合与关联模块412可以包括分别对应高级视觉特征405和高级音频特征407的分离的RNN,以及用于融合来自分离的RNN的输出的后期融合机构。仍可替代地,视听融合与关联模块412可以由包括多视图RNN且没有早期融合机构或后期融合机构的视听关联模块代替。
谱减法模块416用于从噪声谱402中减去第一谱415,以获得去噪声谱418;该去噪声谱418包括人150的声音的净化频域相关表示。谱减法模块416的方法示例在“Speechenhancement using spectral subtraction-type algorithms:A comparison andsimulation study,”Navneet Upadhyay,Abhijit Karmakar,Procedia Computer Science54,574-584,2015中详细描述。
整个神经网络模型310a可以通过最小化地面真值复频谱(ground truth complexspectrogram)(S
图5示出了根据本申请的另一实施例的声音相关系统中的声音净化模块320(如图3所示)中的神经网络模型310b的框图。与图4描述的神经网络模型310a相比,该神经网络模型310b还包括位于视听融合与关联模块512和谱减法模块416之间的全连接网络(fullyconnected network)514。与图4所描述的视听融合与关联模块512相比,该视听融合与关联模块512还包括RNN 510,用于使用高级视觉特征405和高级音频特征407之间的关联来确定视听表示513。高级音频特征407和高级视觉特征405的关联部分反映在视听表示中。可选地,高级音频特征407和高级视觉特征405的不相关部分反映在视听表示513中。全连接网络514用于使用视听表示513来确定第一谱515。该第一谱515与图像rdi
图6示出了根据本申请一实施例的用于声音相关交互的方法的流程图。参见图1-6,用于声音相关交互的方法包括由I/O相关的输入设备122执行的方法610、由声音相关控制设备124执行的方法630,以及由I/O相关的输出设备126执行的方法650。在步骤632中,通过摄像头控制模块302驱使摄像头生成在人发出声音时照亮与嘴相关的部分的红外光,并捕捉包括发出声音的人的至少与嘴相关的部分的多个第一图像。其中,该摄像头是深度摄像头102。在步骤612中,通过该摄像头生成在人发出声音时照亮与嘴相关的部分的红外光。在步骤614中,通过该摄像头捕捉第一图像。在步骤634中,视频图像预处理模块306从该摄像头处接收第一图像。在步骤636中,音频预处理模块308获得噪声谱,其中,该噪声谱包括人的声音的第一表示。在步骤638中,通过卷积神经网络CNN
可选地,在步骤632中,通过摄像头控制模块302驱使至少一个摄像头产生在人发出声音时照亮人的与嘴相关的部分的红外光,并捕捉包括发出声音的人的至少与嘴相关的部分的多个图像集。至少一个摄像头包括深度摄像头102和RGB摄像头104。每一图像集为is
一些实施例具有以下特征和/或优点中的一个或多个组合。在一实施例中,通过从包括人的声音的第一表示的噪声谱中减去第一谱来获得去噪音频;其中,第一谱通过使用包括发出声音的人的与嘴相关的部分的多个图像的深度信息来确定。由于谱减法相比例如相关技术中的谱掩模乘法便宜,而且深度信息提高了第一谱的准确性(这对于谱减法的有效性而言很重要),因此,去噪音频的质量和/或可懂度得到改善,而没有大量的速度成本。
本领域普通技术人员理解,本申请实施例中描述和公开的每一单元、模块、算法,以及步骤均可使用电子硬件或用于计算机的软件和电子硬件的组合来实现。这些功能是以硬件还是软件方式运行取决于应用条件以及技术计划的设计要求。本领域普通技术人员可以使用不同的方式来实现每一特定应用的功能,而这些实现均未超出本申请的范围。
本领域普通技术人员理解,由于上述系统、设备和模块的工作过程基本相同,他/她可以参考上述实施例中的系统、设备和模块。为了便于描述和简化,将不会详细描述这些工作过程。
应当理解,本申请实施例中公开的系统、设备和方法可以用其他方式来实现。上述实施例仅是示例性的。模块的划分仅仅基于逻辑功能,而在实施过程中还可存在其他划分。多个模块或组件可以组合或集成在另一个系统中。也有可能省略或跳过某些特征。另一方面,所显示或讨论的相互耦合,直接耦合或通信耦合通过一些端口、设备或模块以电、机械或其他形式间接或通信地进行操作。
作为用于解释的分离部件的模块在物理上可以分离或不分离。用于显示的模块可以为物理模块或不是物理模块,即用于显示的模块可以位于一个位置上或分布在多个网络模块上。根据实施例的目的可以使用一些或全部模块。
此外,每一实施例中的每一功能模块可以集成在一个物理独立的处理模块中,或者集成在具有两个或两个以上模块的一个处理模块中。
如果软件功能模块被实现,并被当做产品使用和销售,则该软件功能模块可以存储在计算机的可读存储介质中。基于该理解,可以将本申请提出的技术计划在本质上或部分地实现为软件产品形式。或者,可以将对传统技术有益的技术计划的一部分实现为软件产品形式。计算机中的软件产品可以存储在存储介质中,包括用于计算设备(例如个人计算机、服务器,或网络设备)的多个命令,以运行本申请实施例所公开的全部或部分步骤。该存储介质包括USB磁盘、移动硬盘、只读存储器(read-only memory,ROM),随机存取存储器(random access memory,RAM)、软盘,或其他可以存储程序代码的介质。
虽然本申请已经结合被认为是最实际和优选的实施例进行描述,然而应当理解,本申请不限于所公开的实施例,而是旨在覆盖在不脱离所附的权利要求的最广泛解释的范围的情形下做出的各种设置。
- 使用深度信息净化声音的方法和系统以及计算机可读介质
- 声音生成方法,计算机可读存储介质,独立声音生成和回放装置,以及保持网络通信联络的声音生成和回放系统