一种行程截止时间敏感的电子收费道路动态定价方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及智慧城市的收费道路定价领域,尤其涉及一种行程截止时间敏感的电子收费道路动态定价方法。
背景技术
城市交通运输在国家经济发展中发挥着举足轻重的作用。随着人们生活水平的提高,私人轿车保有量的迅速增加,导致了交通需求与道路基础设施建设之间不同步,引发了大量交通拥堵和交通事故。中国因交通拥堵造成的经济损失占城镇人口可支配收入的20%,每年约2500亿元,相当于全年国内生产总值损失的5%-8%。因此,交通问题已经成为禁锢城市经济向前发展的枷锁,会严重影响城市发展和其职能的发挥。传统城市管理方法通过改变城市道路结构来降低拥堵发生的情况。例如,大规模修建行车道路,增加道路供给能力,解决交通供需矛盾。虽然这一措施可以在初始阶段缓解交通堵塞,但效果是短暂。城市道路容量增加,交通需求也会增长,反而加剧了交通拥堵。
为了减少交通拥堵,道路收费机制在城市管理领域受到了极大的关注,其目的是通过对繁忙道路上的车辆收费对车流进行分流,使得想要减少出行成本的车辆自主前往不拥堵且收费低的道路上行驶,从而起到疏导车流,缓解交通拥堵的目的。目前,这种方式通过电子不停车收费系统已经得到了实现,并且在多个国家和地区得到了成功应用。
为了保证道路定价的合理性,在进行具体道路收费时,存在两个问题:第一,交通环境复杂,交通状况不断变化,具有很强的动态性,特别是在出行交通事故或异常天气等突发情况下。因此,必须实施基于实时交通流量的动态道路收费。第二,车辆的行驶路线与时间高度相关。例如上班族或者一些有预定航班或火车的人,可能会有严格的时间要求,他们必须在准确的时间之前到达目的地,不会在意道路收费值,而其他没有时间要求的出行者则可能更偏向于选择收费值较低的路线行驶。
现有的道路定价机制分为静态和动态定价机制。静态收费是在道路上设定固定通行费,虽然此机制很容易实施,但可能与交通动态性不匹配。在一些早期的工作中,动态定价是在不同的时间段对一条道路分配不同的通行费,但是这可能不能很好地适应动态的交通环境。虽然利用强化学习算法可以实现实时动态地调整道路收费,但是现有的方法对大规模的城市道路网络适应性较差,且没有考虑出行者的时间要求,因此不能很好地适应复杂而动态的环境。为此,为每条道路进行动态定价以适应实时变化的交通流量,对缓解交通拥堵同时兼顾出行者个人时间要求差异至关重要。
发明内容
发明目的:针对以上现有技术存在的问题,本发明提出了一种行程截止时间敏感的电子收费道路动态定价方法,着重解决在实时动态变化的交通环境下考虑出行者的时间要求,对道路进行动态定价收费缓解交通拥堵的问题。
技术方案:为实现本发明的目的,本发明所采用的技术方案是:一种行程截止时间敏感的电子收费道路动态定价方法,该方法包括以下步骤:
(1)建立行程截止时间敏感的模拟交通环境模型,所述模拟交通环境模型包括城市路网模型、行程截止时间模型、行程行驶成本模型;城市路网模型用于建立城市路网的拓扑结构,行程截止时间模型用于刻画出行者对于行程的时间要求,行程行驶成本模型计算车辆行程的成本,用以定义车辆的路径选择;
(2)所述行程截止时间敏感的模拟交通环境模型给予强化学习智能体奖赏值和状态转移信息;通过收集的城市中真实数据生成模拟交通数据,建立车辆行程需求的分布,并通过当前交通的状态,确定状态对应的动作的价值,并根据该价值确定出合理的定价;
(3)利用深度强化学习模型进行离线训练和学习,得到训练好的动态定价模型;
(4)利用训练好的动态定价模型对城市路网中的电子收费道路进行动态定价。
进一步的,其特征在于在步骤(1)中,所述的行程截止时间敏感的模拟交通环境模型中的路网模型描述如下:
抽象城市路网以有向图网络G=
进一步的,步骤(1)中所述的行程截止时间模型描述如下:行程截止时间d刻画了用户某一出行行程的时间要求,表示车辆行程的截止时间;
进一步的,步骤(1)中所述的行程行驶成本模型描述如下:
行程行驶成本模型为行程的时间成本和行程经过道路所收取的费用加和,车辆的行驶成本帮助车辆进行路径选择,进而影响车流状态;时间成本与行程的截止时间有关,以行程的截止时间d模拟出行者的时间需求,车辆须在行程截止时间前到达目的地,决策时长H分钟,随机分配车辆的行程截止时间d=0,1,…H,金钱成本则与行驶路径有关,以变量p表示行驶的路径,以变量e表示车辆行驶路径上经过的道路,变量t表示当前时间步,变量
所述行程行驶成本表示为
更具体的,当x>D时,行驶成本随着时间的迫近逐渐增大;当x 进一步的,其特征在于在步骤(2)中所述的当前城市路况的状态有三维,表示如下:s 进一步的,步骤(2)中所述的奖赏值基于出行者的时间要求以及拥堵缓解情况设定的奖赏函数计算输出奖赏值,奖赏值为强化学习智能体所执行动作的反馈,帮助强化学习智能体修正动作;所述奖赏函数根据智能体的优化目标来确定,计算方式包括三种:以最大化在行程截止时间前到达目的地的车辆数目为目标的奖赏计算、以最小化没有在行程截止时间前到达目的地的车辆数目为目标的奖赏计算或以最小化车辆超出行程截止时间到达目的地的总时间为目标计算奖赏; 以最大化在行程截止时间前到达目的地的车辆数目为目标的奖赏计算如下:
以最小化没有在行程截止时间前到达目的地的车辆数目为目标的奖赏计算如下:
以最小化车辆超出行程截止时间到达目的地的总时间为目标计算奖赏,计算如下:
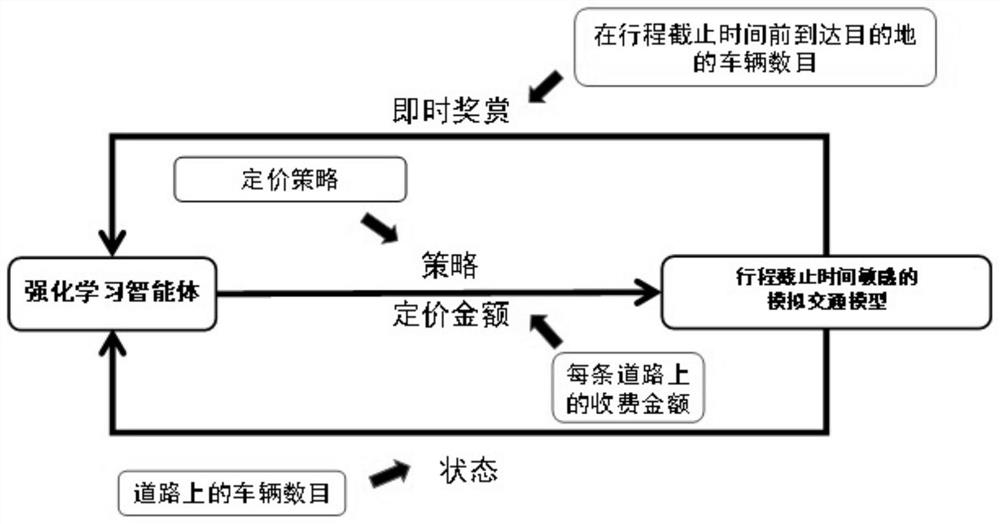
其中 进一步的,步骤(2)中,根据当前城市路况的状态,输出合理定价的过程具体包括: 行程截止时间敏感的模拟交通环境模型根据城市路网上的车流状态信息,进行状态抽象 进一步的,在步骤(4)中,所述行程截止时间敏感的模拟交通环境模型根据真实的城市车流环境,输出当前时间各条道路的车流信息作为状态,将其传输给动态定价模型,该动态定价模型根据输入的状态信息输出合理定价,将定价返回行程截止时间敏感的模拟交通环境模型; 行程截止时间敏感的模拟交通环境模型收到定价,执行定价操作;真实的城市车流环境中车流进行响应,得到下一车流信息状态,进而进行电子收费道路的动态定价。 进一步的,在步骤(2)中,所述车辆行程需求产生的分布为高斯分布。 进一步的,在步骤(2)中,所述的当前城市路况的状态将具有相同行程截止时间的车辆统计数目作为车流处理,降低训练深度强化学习模型的复杂度,提高收敛性。 进一步的,在步骤(3)中,所述深度强化学习模型采用多线程异步训练的方法训练,以此提高训练速度,加快定价策略的收敛。 有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果: (1)有利于扩展到大规模城市路网。传统的单个代理与环境交互学习策略时由于状态空间大,易出现难收敛的情况。本发明使用多个本地代理与全局代理异步学习收费策略,打破数据之间的相关性,提高策略的训练速度,使得策略更容易收敛。 (2)模型更加完善。现有模型假设车辆没有时间要求或时间要求是相同的,即没有考虑不同出行者对出行时间的差异。本发明在模型中加入截止时间模拟车辆的时间要求,考虑了不同车辆对到达目的地具有时间要求;对车辆行驶成本进行建模时,引入时间阈值,模拟当时间迫近截止时间,车辆只根据时间成本选择路径的特点,更贴合实际交通环境,使得模型更加完善。 (3)有利于缓解交通拥堵。一方面,动态道路收费可以对行驶在拥堵且收费高的道路上的车辆进行分流,起到缓解拥堵的作用。另一方面,可以根据策略想要取得的效果有针对性的从三种不同的奖励函数中进行选择,灵活性更大。 附图说明 图1面向城市收费道路动态定价的强化学习架构; 图2本发明实现的一种行程截止时间敏感的电子收费道路动态定价方法流程图。 具体实施方式 下面结合附图和具体实施例,进一步阐明本发明。 本发明所述的行程截止时间敏感的电子收费道路动态定价方法通过行程截止时间敏感的模拟交通环境模型和动态定价模型实现,如图1所示,行程截止时间敏感的模拟交通环境模型将高峰时段车辆数据作为动态定价模型的输入,根据训练好的动态定价模型对电子收费道路进行动态定价。本发明提出了一种城市交通车流高峰环境下面向缓解交通拥堵的一种行程截止时间敏感的电子收费道路动态定价方法,流程如图2所示。具体执行步骤如下: (1)建立行程截止时间敏感的模拟交通环境模型,所述模拟交通环境模型包括城市路网模型、行程截止时间模型、行程行驶成本模型;城市路网模型用于建立城市路网的拓扑结构,行程截止时间模型用于刻画出行者对于行程的时间要求,行程行驶成本模型计算车辆行程的成本,用以定义车辆的路径选择。 (2)所述行程截止时间敏感的模拟交通环境模型给予强化学习智能体奖赏值和状态转移信息;通过收集的城市中真实数据生成模拟交通数据,建立车辆行程需求的分布,并通过当前交通的状态,确定状态对应的动作的价值,并根据该价值确定出合理的定价; (3)利用深度强化学习模型进行离线训练和学习,得到训练好的动态定价模型; (4)利用训练好的动态定价模型对城市路网中的电子收费道路进行动态定价。 进一步的,其特征在于在步骤(1)中,所述的行程截止时间敏感的模拟交通环境模型中的路网模型描述如下: 抽象城市路网以有向图网络G= 进一步的,步骤(1)中所述的行程截止时间模型描述如下:行程截止时间d刻画了用户某一出行行程的时间要求,表示车辆行程的截止时间; 进一步的,步骤(1)中所述的行程行驶成本模型描述如下: 行程行驶成本模型为行程的时间成本和行程经过道路所收取的费用加和,车辆的行驶成本帮助车辆进行路径选择,进而影响车流状态;时间成本与行程的截止时间有关,以行程的截止时间d模拟出行者的时间需求,车辆须在行程截止时间前到达目的地,决策时长H分钟,随机分配车辆的行程截止时间d=0,1,…H,金钱成本则与行驶路径有关,以变量p表示行驶的路径,以变量e表示车辆行驶路径上经过的道路,变量t表示当前时间步,变量 所述行程行驶成本表示为
更具体的,当x>D时,行驶成本随着时间的迫近逐渐增大;当x 进一步的,其特征在于在步骤(2)中所述的当前城市路况的状态有三维,表示如下:s 进一步的,步骤(2)中所述的奖赏值基于出行者的时间要求以及拥堵缓解情况设定的奖赏函数计算输出奖赏值,奖赏值为强化学习智能体所执行动作的反馈,帮助强化学习智能体修正动作;所述奖赏函数根据智能体的优化目标来确定,计算方式包括三种:以最大化在行程截止时间前到达目的地的车辆数目为目标的奖赏计算、以最小化没有在行程截止时间前到达目的地的车辆数目为目标的奖赏计算或以最小化车辆超出行程截止时间到达目的地的总时间为目标计算奖赏; 以最大化在行程截止时间前到达目的地的车辆数目为目标的奖赏计算如下:
以最小化没有在行程截止时间前到达目的地的车辆数目为目标的奖赏计算如下:
以最小化车辆超出行程截止时间到达目的地的总时间为目标计算奖赏,计算如下:
其中 进一步的,步骤(2)中,根据当前城市路况的状态,输出合理定价的过程具体包括: 行程截止时间敏感的模拟交通环境模型根据城市路网上的车流状态信息,进行状态抽象 进一步的,在步骤(4)中,所述行程截止时间敏感的模拟交通环境模型根据真实的城市车流环境,输出当前时间各条道路的车流信息作为状态,将其传输给动态定价模型,该动态定价模型根据输入的状态信息输出合理定价,将定价返回行程截止时间敏感的模拟交通环境模型; 行程截止时间敏感的模拟交通环境模型收到定价,执行定价操作;真实的城市车流环境中车流进行响应,得到下一车流信息状态,进而进行电子收费道路的动态定价。 进一步的,在步骤(2)中,所述车辆行程需求产生的分布为高斯分布。 进一步的,在步骤(2)中,所述的当前城市路况的状态将具有相同行程截止时间的车辆统计数目作为车流处理,降低训练深度强化学习模型的复杂度,提高收敛性。 进一步的,在步骤(3)中,所述深度强化学习模型采用多线程异步训练的方法训练,以此提高训练速度,加快定价策略的收敛。
- 一种行程截止时间敏感的电子收费道路动态定价方法
- 一种基于道路路段行程时间预测模型的路段行程时间动态误差修正方法