一种基于异构图变换器计算疾病与RNA关联的方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及疾病预测技术领域,具体为一种基于异构图变换器计算疾病与RNA关联的方法。
背景技术
MicroRNA是一类短的非编码单链RNA,长度约为19-25个核苷酸,由基因转录而成。miRNA通过与靶miRNA的3'非翻译区结合来调节蛋白质和基因的表达水平。此外,越来越多的证据表明,miRNA在细胞增殖、分化、凋亡、衰老等多种生物过程中发挥着关键作用,并与人类许多疾病的发生密切相关。miR-15和miR-16导致慢性淋巴细胞白血病。此外,let-7、miR-143/miR-145的上调可导致癌症,而axl作为受体,受miR-34a和miR-199a/b调节,并在实体癌症细胞中发挥下调作用。因此,识别与miRNA相关的疾病可以更好地帮助人类了解各种疾病的机制;
基于“功能相似的miRNA与以相似表型为特征的疾病的相关性更高”的假设,已经开发出了使用相似性测量来预测相关性的方法。姜等人通过构建miRNA的功能网络和人类表型网络来预测miRNA与疾病之间的关联。Shi等人专注于蛋白质-蛋白质相互作用(PPI)网络中疾病基因和miRNA之间的关联,提出了一种随机游走计算方法。徐等人提出了一种综合疾病基因关联和miRNA靶点相互作用的预测方法。HDMP模型基于miRNA的功能相似性和与疾病相关的miRNA在k个邻居中的分布来预测miRNA与疾病的关联。此外,MDHGI模型充分利用矩阵分解将相似性信息整合到miRNA和疾病的异质网络中。由于基于相似性的方法中相似性得分的局限性,研究人员已经开始考虑基于机器学习的模型来预测miRNA-疾病的关联性。研究表明,机器学习在这一领域取得了良好的效果。例如,PBMDA模型构建了一个由三个相互关联的子图组成的异构图,并使用深度优先算法来获得与miRNA-疾病关联相关的分数。徐等人构建了一个异质性miRNA靶向失调网络(MTDN),并使用支持向量机来识别miRNA-疾病的阳性关联。此外,Chen等人提出了一种模型LRSSLMDA,该模型使用拉普拉斯正则化和稀疏子空间学习来学习miRNA与疾病之间的关联性。Chen等人使用随机森林分类器并基于自动编码器计算miRNA与疾病的相关性得分。尽管机器学习节省了时间成本,但也有一些局限性。因此提出了一种基于异构图变换器计算疾病与RNA关联的方法。
发明内容
针对现有技术的不足,本发明提供了一种基于异构图变换器计算疾病与RNA关联的方法,解决了上述背景技术中提出的问题。
为实现以上目的,本发明通过以下技术方案予以实现:一种基于异构图变换器计算疾病与RNA关联的方法,包括以下步骤:
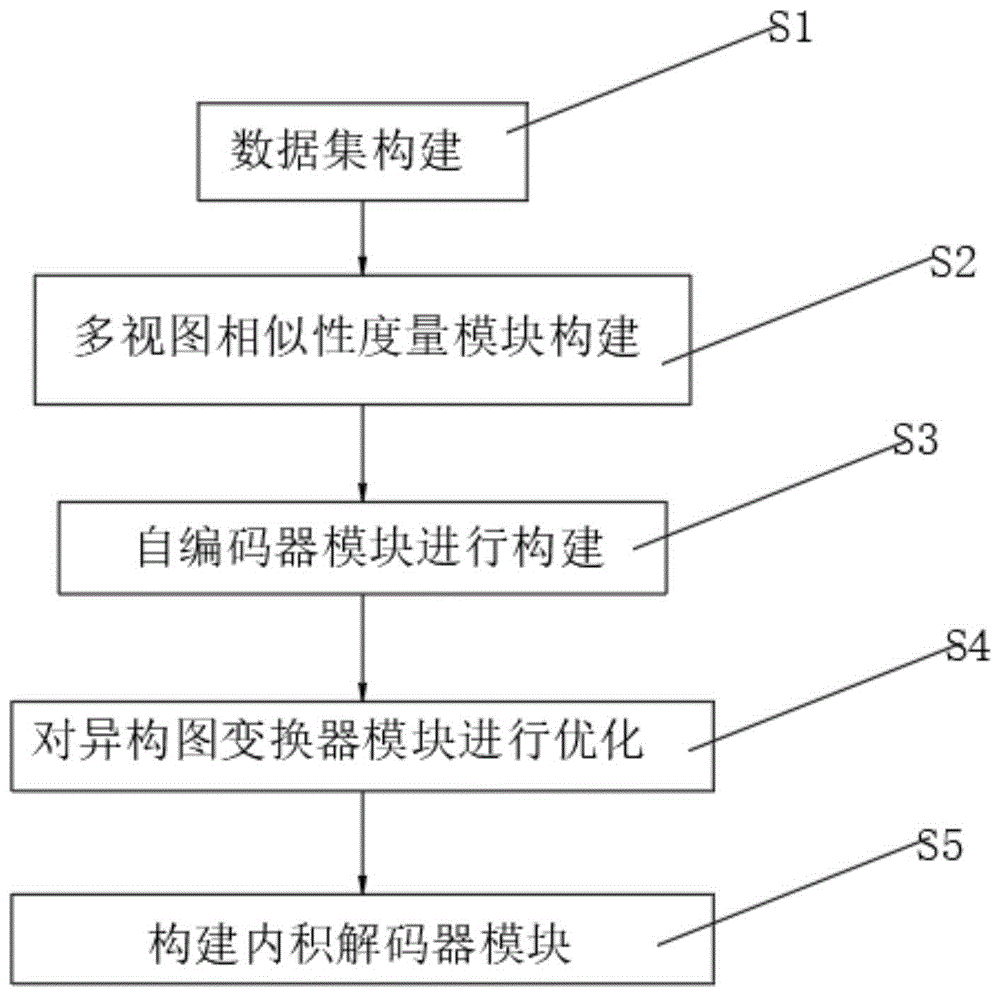
S1:数据集构建:利用人类MicroRNA疾病数据库下载了miRNA与疾病的关联性数据;
S2:多视图相似性度量模块构建:在miRNA和疾病之间建立网络,利用它们的相似性作为连接它们关系的基础:
M
D
其中,A
S3:自编码器模块进行构建:使用Python随机模块生成的数据代表miRNA和疾病编码的随机载体,将每一个载体输入到单独的自动编码器模型中,将随机生成的向量编码作为低维嵌入,以捕获原始数据的基本特征,嵌入过程定义如下:
M
D
其中M
S4:对异构图变换器模块进行优化:
首先,需要计算源节点d和目标节点m之间的相互注意力,基于注意力的图神经网络:
其中N(m)表示目标节点m的邻居,以及e=(d,m)表示从源节点d到目标节点m的所有边。在层次图变换器(HGT)模型中,层由l表示,基于注意力的图神经网络依赖于三个基本的操作符:注意力机制、消息传递和聚合,注意力机制计算每个源节点相对于给定目标节点的相关性得分,消息传递从源节点提取信息,并构造捕获它们之间的关系的消息,最后,目标特定的聚合将使用注意力分数作为权重来组合相邻节点的消息,为了提高GNN的性能,需要仔细设计这些操作符,并根据特定的应用领域进行定制;与GAT相比,异构相互注意机制能够计算目标节点m与其所有邻居节点之间的相互注意的能力,这可能存在于不同的分布中,这种机制对于涉及具有异构节点和不同分布的图的任务特别有用,这种计算是基于它们的元关系,即
提出了一种计算图中源节点和目标节点之间注意力得分的新机制,将目标节点转换为查询向量,将源节点转换为关键向量,为了实现参数共享和关系特定属性之间的平衡,将交互算子的权重矩阵分解为三个分量:源节点d的投影、边e的投影和目标节点m的投影,使用多头注意力来计算每条边e=(d,m)的h
K
Q
S41:对于第i个注意力ATT_head
S42:是计算Query vectorQ
S44:为每个注意力头计算一个加权值,并将它们连接起来,为每对节点创建一个注意向量,然后收集来自相邻节点的所有注意向量,并应用softmax函数将它们的值归一化化为一,该过程计算如下:
除了计算相互注意之外,引入一种将信息从源节点传播到目标节点的附加技术,为了克服不同类型的节点和边的不同分布所带来的挑战,将元边关系集成到消息传递过程中,针对一对节点的多头消息计算,定义如下:
e=(d,m)
为了检索第i个消息头MSG_head
为了将信息从源节点d传输到目标节点m,采用一种称为异构多头注意的技术,在使用公式(6)中使用的softmax函数计算每个目标节点的注意向量之后,可以使用这些向量作为权重来获得来自相应源节点的消息的加权平均值,能够有效地聚合相关信息,并将目标节点跟新的向量表示为:
通过使用这种聚合过程,可以从具有不同特征分布的附近节点收集信息,并使用它来更新目标节点;
最后一步涉及将目标节点的向量映射回它的节点τ(m)由节点类型索引的对应特定类型的分布,这是通过一系列步骤来实现的,包括对跟新的向量应用线性投影然后使用残差连接作为A_Linear
在执行上述步骤之后,得到目标节点m的第l个HGT层的输出h
通过采用新的基于元关系的方法,进一步提高ML-HGT捕获复杂图信息的能力,提出的方法模型的公式如下:
h
其中HGT
S5:构建内积解码器模块:为了获得更好的结果,将每一轮HGT操作的输出编码连接起来作为最终编码;
其中H
其中
为了优化模型,应用交叉熵损失函数来计算模型训练期间的损失:
其中y
优选的,所述S1:数据集构建:利用人类MicroRNA疾病数据库下载了miRNA与疾病的关联性数据的步骤:所述MicroRNA疾病数据库的版本为HMDDv3.2,HMDD v3.2是一个更新的数据库,包含人类miRNA与疾病之间的广泛关联。
优选的,所述S2:多视图相似性度量模块构建的步骤中将MA和DA分别表示miRNA和疾病的相似性矩阵。
优选的,所述S1:数据集构建:利用人类MicroRNA疾病数据库下载了miRNA与疾病的关联性数据的步骤:从HMDD v3.2数据库中,选择12446个实验证实的853种miRNA与591种疾病之间的关联,已知的miRNA疾病关联被标记为阳性样本,而其余样本被标记为阴性样本,表明miRNA与疾病之间没有关联。
优选的,所述S2:多视图相似性度量模块构建的步骤中使用miRNA的功能相似性、序列相似性和高斯相互作用谱核相似性矩阵,以及疾病的语义相似性、基于靶点的疾病相似性和Gaussian相互作用谱内核相似性矩阵来构建三种不同的miRNA-miRNA网络和三种不同疾病的疾病网络,这些矩阵被用作邻接矩阵,基于它们的相似性在miRNA和疾病之间建立联系。
优选的,所述S3:自编码器模块进行构建:使用Python随机模块生成的数据代表miRNA和疾病编码的随机载体,将每一个载体输入到单独的自动编码器模型中,将随机生成的向量编码作为低维嵌入,以捕获原始数据的基本特征的步骤中,自动编码器模型一个完全连接的层。
本发明提供了一种基于异构图变换器计算疾病与RNA关联的方法,具备以下有益效果:
该基于异构图变换器计算疾病与RNA关联的方法,通过基于异构图转换器的计算方法VRMHMD,预测miRNA-疾病之间的关联,VRMHMD在多模式编码的基础上增加了一个随机自动编码过程,对两组数据进行编码,并通过两个不同的多层HGT网络提取编码,来自HGT每层的输出编码被连接作为最终编码,使用注意力机制来融合这两组编码,并执行矩阵乘法解码,以预测新的miRNA疾病敏感性关联矩阵。
附图说明
图1为本发明步骤结构示意图;
图2为本发明研究不同隐藏通道对提出的HGT模型性能的影响图;
图3为本发明VRMHMD利用多头注意力机制为其提供更强大的表示学习能力图;
图4为本发明评估在模型中改变层数h对结果的影响图;
图5为本发明随机向量的维数大小会显著影响信息提取和模型性能图;
图6为本发明烧蚀试验图一;
图7为本发明烧蚀试验图二;
图8为本发明烧蚀试验图三;
图9为本发明六种模型测试图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
请参阅图1至图9,本发明提供一种技术方案:一种基于异构图变换器计算疾病与RNA关联的方法,包括以下步骤:
S1:数据集构建:利用人类MicroRNA疾病数据库下载了miRNA与疾病的关联性数据;
S2:多视图相似性度量模块构建:在miRNA和疾病之间建立网络,利用它们的相似性作为连接它们关系的基础:
M
D
其中,A
S3:自编码器模块进行构建:使用Python随机模块生成的数据代表miRNA和疾病编码的随机载体,将每一个载体输入到单独的自动编码器模型中,将随机生成的向量编码作为低维嵌入,以捕获原始数据的基本特征,嵌入过程定义如下:
M
D
其中M
S4:对异构图变换器模块进行优化:
首先,需要计算源节点d和目标节点m之间的相互注意力,基于注意力的图神经网络:
其中N(m)表示目标节点m的邻居,以及e=(d,m)表示从源节点d到目标节点m的所有边。在层次图变换器(HGT)模型中,层由l表示,基于注意力的图神经网络依赖于三个基本的操作符:注意力机制、消息传递和聚合,注意力机制计算每个源节点相对于给定目标节点的相关性得分,消息传递从源节点提取信息,并构造捕获它们之间的关系的消息,最后,目标特定的聚合将使用注意力分数作为权重来组合相邻节点的消息,为了提高GNN的性能,需要仔细设计这些操作符,并根据特定的应用领域进行定制;与GAT相比,异构相互注意机制能够计算目标节点m与其所有邻居节点之间的相互注意的能力,这可能存在于不同的分布中,这种机制对于涉及具有异构节点和不同分布的图的任务特别有用,这种计算是基于它们的元关系,即
提出了一种计算图中源节点和目标节点之间注意力得分的新机制,将目标节点转换为查询向量,将源节点转换为关键向量,为了实现参数共享和关系特定属性之间的平衡,将交互算子的权重矩阵分解为三个分量:源节点d的投影、边e的投影和目标节点m的投影,使用多头注意力来计算每条边e=(d,m)的h
K
Q
S41:对于第i个注意力ATT_head
S42:是计算Query vectorQ
S44:为每个注意力头计算一个加权值,并将它们连接起来,为每对节点创建一个注意向量,然后收集来自相邻节点的所有注意向量,并应用softmax函数将它们的值归一化化为一,该过程计算如下:
除了计算相互注意之外,引入一种将信息从源节点传播到目标节点的附加技术,为了克服不同类型的节点和边的不同分布所带来的挑战,将元边关系集成到消息传递过程中,针对一对节点的多头消息计算,定义如下:
e=(d,m)
为了检索第i个消息头MSG_head
为了将信息从源节点d传输到目标节点m,采用一种称为异构多头注意的技术,在使用公式(6)中使用的softmax函数计算每个目标节点的注意向量之后,可以使用这些向量作为权重来获得来自相应源节点的消息的加权平均值,能够有效地聚合相关信息,并将目标节点跟新的向量表示为:
通过使用这种聚合过程,可以从具有不同特征分布的附近节点收集信息,并使用它来更新目标节点;
最后一步涉及将目标节点的向量映射回它的节点τ(m)由节点类型索引的对应特定类型的分布,这是通过一系列步骤来实现的,包括对跟新的向量应用线性投影然后使用残差连接作为A_Linear
在执行上述步骤之后,得到目标节点m的第l个HGT层的输出h
通过采用新的基于元关系的方法,进一步提高ML-HGT捕获复杂图信息的能力,提出的方法模型的公式如下:
h
其中HGT
S5:构建内积解码器模块:为了获得更好的结果,将每一轮HGT操作的输出编码连接起来作为最终编码;
其中H
其中
为了优化模型,应用交叉熵损失函数来计算模型训练期间的损失:
其中y
进一步,S1:数据集构建:利用人类MicroRNA疾病数据库下载了miRNA与疾病的关联性数据的步骤MicroRNA疾病数据库的版本为HMDD v3.2,HMDDv3.2是一个更新的数据库,包含人类miRNA与疾病之间的广泛关联。
进一步,S2:多视图相似性度量模块构建的步骤中将MA和DA分别表示miRNA和疾病的相似性矩阵。
进一步,S1:数据集构建:利用人类MicroRNA疾病数据库下载了miRNA与疾病的关联性数据的步骤:从HMDD v3.2数据库中,选择12446个实验证实的853种miRNA与591种疾病之间的关联,已知的miRNA疾病关联被标记为阳性样本,而其余样本被标记为阴性样本,表明miRNA与疾病之间没有关联。
进一步,S2:多视图相似性度量模块构建的步骤中使用miRNA的功能相似性、序列相似性和高斯相互作用谱核相似性矩阵,以及疾病的语义相似性、基于靶点的疾病相似性和Gaussian相互作用谱内核相似性矩阵来构建三种不同的miRNA-miRNA网络和三种不同疾病的疾病网络,这些矩阵被用作邻接矩阵,基于它们的相似性在miRNA和疾病之间建立联系。
进一步,S3:自编码器模块进行构建:使用Python随机模块生成的数据代表miRNA和疾病编码的随机载体,将每一个载体输入到单独的自动编码器模型中,将随机生成的向量编码作为低维嵌入,以捕获原始数据的基本特征的步骤中,自动编码器模型一个完全连接的层。
为了评估所提出的模型的有效性,在标准数据集上进行5-CV和10-CV实验,阴性miRNA疾病敏感性以相等数量随机生成,以匹配阳性样本。随后,它们被划分为五个大小相等的子集,每个子集被用作测试集一次,而其他四个子集用于训练。此过程重复五次,以确保结果可靠。使用七个指标来评估模型的性能:受试者工作特征曲线下面积(AUC)、精密度-召回曲线下面积、准确性、精密度、召回率、F1分数和特异性。这些度量指标是使用特定的公式(21-25)来计算的;
实施例:
首先收集853种miRNA和591种疾病之间已知的miRNA疾病相关性的阳性样本。为了确保数据集中的平衡,为标记为0的样本随机选择相同数量的阴性样本。然后将数据划分为训练集和测试集,后者占数据集的20%。在训练过程中,采用5倍交叉验证来调整模型参数和结构,同时选择性能最好的模型进行独立测试。为了获得最佳的泛化性能,将隐藏层输出编码的维数设置为512,将层次图变换器(HGT)层数设置为2,将随机自动编码向量的维数设为256,并将HGT模型中的注意力头的数量设为8。此外,通过在训练过程中随机忽略一些神经元来实现丢弃(p=0.5),以解决潜在的过拟合问题。所有实验重复多次以确保结果的可靠;
在这项实验中,将本发明模型与基于单独测试的八种现有方法进行了比较,包括NIMCGCN、MMGCN、ERMDA、HGANMDA、AGAEMD、MINIMDA、MAGCN和AMHMDA;
1.NIMCGCN聚合图卷积网络(GCN)从相似网络中提取特征。随后,它使用NIMC模型生成了一个完整的关联矩阵;
2.MMGCN应用多视图GCN编码器、多通道注意力机制和CNN组合器来预测miRNA与疾病之间的关联;
3.ERMDA提出了一种重新采样策略,以构建从各种数据源导出的多个平衡训练子集,以获取特征表示。最终,它使用软投票集成方法,按照建议的策略预测miRNA与疾病之间的相关性;
4.HGANMDA利用节点和语义水平的注意机制来学习相邻节点和元路径的意义,从而重建miRNA与疾病的关联;
5.AGAEMD使用基于节点级注意力的自动编码器来聚集miRNA疾病网络中的相关信息,该信息被进一步用于重建miRNA疾病关联网络;
6.MINIMDA构建了不同的多模式网络,并通过融合来自这些网络的混合高阶邻域信息来学习miRNA和疾病的嵌入表示。这种方法可以推测miRNA与疾病的相关性;
7.MAGCN使用具有多通道注意机制的GCN和CNN的组合来学习已建立的lncRNA-miRNA和miRNA疾病网络,然后通过双线性解码器重建miRNA疾病关联;
8.AMHMDA使用相似性网络和具有超节点的图卷积网络融合注意力机制来构建异构超图,允许使用注意力机制预测miRNA疾病关联。
为了评估预测性能,对数据集进行了5倍的交叉验证实验。在相同的实验条件下,将所有方法与研究的最佳推荐参数进行了比较,在表1中,可以看到5-CV的实验结果的比较。AUC结果表明,VEMHMD显著优于其他方法,比其他方法高7.36%(NIMCGCN)、3.6%(MMGCN),5.1%(ERMDA)、4.16%(HGANMDA)、4.11%(AGAEMD),3.77%(MINIMDA)、4.36%(MAGCN)、2.59%(AMHMDA)。此外,VEMHMD的AUPRC平均值为0.9625,分别比其他方法高6.99%(NIMCGC)、3.05%(MMGCN)、4.52%(ERMDA)、3.72%(HGANMDA)、3.39%(AGAEMD)、2.75%(MINIMDA)、3.57%(MAGCN)、2.14%(AMHMDA)。表1中给出了各种性能指标的结果,如F1得分、准确度、召回率和准确度。在这些指标中,VRMHMD的得分最高,分别为0.9134、0.911、0.9389和0.8894。
表1 5-CV
1.参数敏感性分析:
VRMHMD模型包括以下参数:1.隐藏层输出编码的维数;2.多头注意机制中的头的数量;3.HGT中的层的数量;4.变分自动编码器的维数,为了评估其预测性能,使用5倍交叉验证在基准数据集上进行了实验:
2.隐藏层输出编码的维度:
研究不同隐藏通道对提出的HGT模型性能的影响,结果如图2所示,表明当隐藏通道的数量设置为512时,AUC、AUPR、Acc和F1得分达到了最佳性能得分;
3.多头注意机制中的头的数量:
VRMHMD利用多头注意力机制为其提供更强大的表示学习能力。如图3所示,当注意力头的数量达到8个时,可以获得最佳性能。结果表明,增加注意力头的数量可以在一定范围内提高HGT模型的性能。
4.HGT中的层数:
评估在模型中改变层数h对结果的影响,如图4所示,观察到,当层数达到两层时,可以获得最佳性能。基于这些实验,将随机向量的维数设置为256,将隐藏通道设置为512,并将多头注意力机制中的头部数量设置为4。就评估指标而言,这种配置带来了最佳性能。这些结果为HGT模型的设计选择提供了重要的参考意见。
变分自动编码器的维数
随机向量的维数大小会显著影响信息提取和模型性能。如图5所示,观察到不同维度的随机向量的评估指标得分不同。为了确保模型的鲁棒性和特征信息的最佳预测性能,将所有节点的特征维数标准化为256。
本发明提出的VRMHMD模型包括四个基本模块:多视图相似性测量、随机编码、多层HGT框架和连接解码。为了评估每个组件对结果的影响,在从AMHMDA模型中删除每个模块后,在基准数据集上进行了五次交叉验证实验。具体而言,测试并比较了以下六种模型:
1.VRMHMD模型:VRMHMD是一个基于异构图变换器(HGT)的计算框架,用于预测miRNA与疾病敏感性之间的关联。它利用了自动编码器、基于注意力的多轮输出编码和多视图相似性进行测量。
2.VRMHMD-LDE:该模型使用线性层进行解码。多层HGT框架通过基于注意力的信息传递机制捕捉miRNA和疾病之间的复杂相互作用。最后,基于线性解码模块,通过对HGT框架的最后隐藏状态应用线性变换来生成最终预测。
3.VRMHMD NBias:VRMHMD NB ias模型不使用随机编码。它仅依靠多视角相似性测量和HGT框架来预测miRNA与疾病之间的关联。
4.VRMHMD-HAN:该模型使用HAN作为中心编码,利用异构注意力机制来学习不同类型节点的特征,并对其复杂关系进行建模。VRMHMD-HAN模型还保留了随机编码模块和解码模块,用简单的HAN主干取代了MHGT框架。
5.VRMHMD-NL:该模型从解码器中删除第一个线性层。该模型直接从HGT框架的最后隐藏状态生成最终预测,而无需任何额外的线性变换。
6.VRMHMD Fout:该模型保留了随机编码模块和MHGT框架,使用HGT的最后一层作为最终解码向量。
图9中的结果表明,VRMHMD在ROC、PRC、Acc和f1分值方面始终优于其他模型。实验结果表明,使用随机生成的向量提高了自动编码器的鲁棒性,提高了模型的稳定性和泛化能力,此外,在处理异构图形数据时,VRMHMD的性能优于VRMHMD-NBias和VRMHMD-HAN。原因是VRMHMD在转换器模型中引入了一种自注意机制,以更好地捕捉节点之间的复杂依赖关系。相反,VRMHMD-NBias只能考虑同构关系,而VRMHMD-HAN只能在两层图之间建立注意联系,因此很难有效地处理多层异构图。应该注意的是,VRMHMD-HAN比VRMHMD-NL更灵活、更准确,并且具有比VRMHMD-NL更好的性能。此外,在解码过程中,VRMHMD通常比VRMHMD-LDE更适合。
以上,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种基于矩阵分解的食物-疾病关联预测方法
- 一种基于自回避随机游走的疾病关联miRNA预测方法及系统
- 一种基于拟合关联的自动化设备故障率计算方法
- 一种基于关联矩阵计算的电力系统网络重构方法
- 基于带权图注意力和异构图神经网络的环状RNA-疾病关联预测方法、设备和介质
- 一种基于异构图的miRNA与疾病关联预测方法及系统