利用超参自适用DBSCAN聚类的跨平台异常识别转译方法、装置、处理器及存储介质
文献发布时间:2023-06-19 10:21:15
技术领域
本发明涉及自然语言处理领域,尤其涉及文本聚类及语义解析领域,具体是指一种利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法、装置、处理器及其计算机可读存储介质。
背景技术
事实上目前自然语言处理技术不管在国内,还是国外都正处于快速发展的阶段,互联网经济时代的潮流对智能化服务的迫切需求,为其发展提供了强大的市场动力。而文本聚类是将文档集合自动归类的过程,隶属于自然语言处理的技术范畴。目前国内外关于文本聚类的算法研究也有很多,一般分为基于划分、基于层次、基于密度,基于网格以及基于模型的聚类算法,不同的算法适用于不同的应用场景。尽管现有的技术与应用都不少,但真正能够利用这些技术进行报错文本聚类,并与智能客服相结合,实现面向终端的智能跨平台异常识别转译闭环的工作却很少,原因如下:
1、目前人工智能在证券市场上的应用主要是以智能顾问和量化投资两种具体的模式,弹窗报错转译属于将人工智能嵌入进具体的业务操作流程中,是一种冷门类别。
2、聚类算法本身的局限性,大部分算法的聚类效果很大程度地依赖于对文本类别数量的预知,而终端每天的弹窗报错信息是没有办法提前预估其类别数量的。
大数据背景下,随着证券交易市场体系完善、交易品种创新、各类特色应用层出不穷,而隐藏在这些应用背后的柜台、行情、总线等系统建设庞大、复杂,在后期运维中生产海量的数据日志,其中不乏重要的业务报错异常。这些报错异常目前大多是采用将后台系统报错信息直接弹窗展示,由于后台系统平台纷繁复杂,对应前端应用的模式很难统一,弹窗展示出来的报错信息往往只包含了特定开发者指定的一些系统错误码、文字信息,对于客户而言过于专业术语化、难以理解。当想把这些信息转化为客户可以理解的友好引导时,发现主要有两个问题:
1、报错信息类别复杂,数量众多,难以枚举;
2、即使是同类型的报错,往往因为涵盖用户的一些特定信息或者不关键的文字,无法统一处理。
因此,本发明的主要目的就是如何通过自然语言处理中的文本聚类和语义解析技术,实现自动进行报错聚类、信息识别、引导转译一体化的过程,帮助用户在交易、业务办理等实际零售业务过程中获得更好的体验。
发明内容
本发明的目的是克服了上述现有技术的缺点,提供了一种满足准确性高、易于理解、适用范围较为广泛的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法、装置、处理器及其计算机可读存储介质。
为了实现上述目的,本发明的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法、装置、处理器及其计算机可读存储介质如下:
该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法,其主要特点是,所述的方法包括多平台交互引导的操作步骤,具体包括以下处理过程:
(1)操作遇报错,对接智能服务平台;
(2)对报错信息进行文本解析,判断是否有相对比较匹配的结果,如果是,则继续步骤(3);否则,继续步骤(5);
(3)展示结果,引导客户正确的操作;
(4)判断客户是否满意,如果是,则结束步骤,否则,继续步骤(5),且安抚客户,进行解答及意见反馈;
(5)记录报错内容;
(6)建立聚类算法模型,对报错信息进行聚类,将不同的报错聚类转化为后台运营知识点。
较佳地,所述的步骤(6)具体包括以下步骤:
(6.1)建立聚类算法模型;
(6.2)定时对收集的报错信息按照不同类别进行聚类并展示;
(6.3)判断是否能解决报错聚类,如果是,则继续步骤(6.4);否则,联系人员进行协助处理,继续步骤(6.4);
(6.4)填入解决方案,将不同的报错聚类转化为智能服务平台后台运营知识点。
较佳地,所述的步骤(6.4)具体包括以下步骤:
(6.4.1)填入解决方案;
(6.4.2)进行知识点查重,如果重复,则进行语义调优;否则,新建知识点,增加回溯效果。
较佳地,所述的方法还包括聚类算法的步骤,具体包括以下处理过程:
(1-1)获取当前需要聚类的数据集;
(1-2)删除历史模型;
(1-3)分调,生成训练员数据;
(1-4)建立doc2vec训练句向量模型;
(1-5)基于当前模型转换数据集;
(1-6)使用轮廓系数作为调优标准,遍历超参获取最优聚类。
较佳地,所述的步骤(1)中的轮廓系数,具体为:
根据以下公式计算轮廓系数:
其中,a(i)表示i向量到同一簇内其他点的不相似程度的平均值,b(i)表示i向量到其他簇的平均不相似程度的最小值。
该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的装置,其主要特点是,所述的装置包括:
处理器,被配置成执行计算机可执行指令;
存储器,存储一个或多个计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的方法的步骤。
该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的处理器,其主要特点是,所述的处理器被配置成执行计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的方法的步骤。
该计算机可读存储介质,其主要特点是,其上存储有计算机程序,所述的计算机程序可被处理器执行以实现上述的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的方法的各个步骤。
采用了该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法、装置、处理器及其计算机可读存储介质,在聚类数据较多的时候,轮廓系数非常接近,利用超参自适用DBSCAN聚类算法模型,很好地实现了报错聚类的需求。本发明通过自然语言处理中的文本聚类和语义解析技术,实现自动进行报错聚类、信息识别、引导转译一体化的过程,帮助用户在交易、业务办理等实际零售业务过程中获得更好的体验。
附图说明
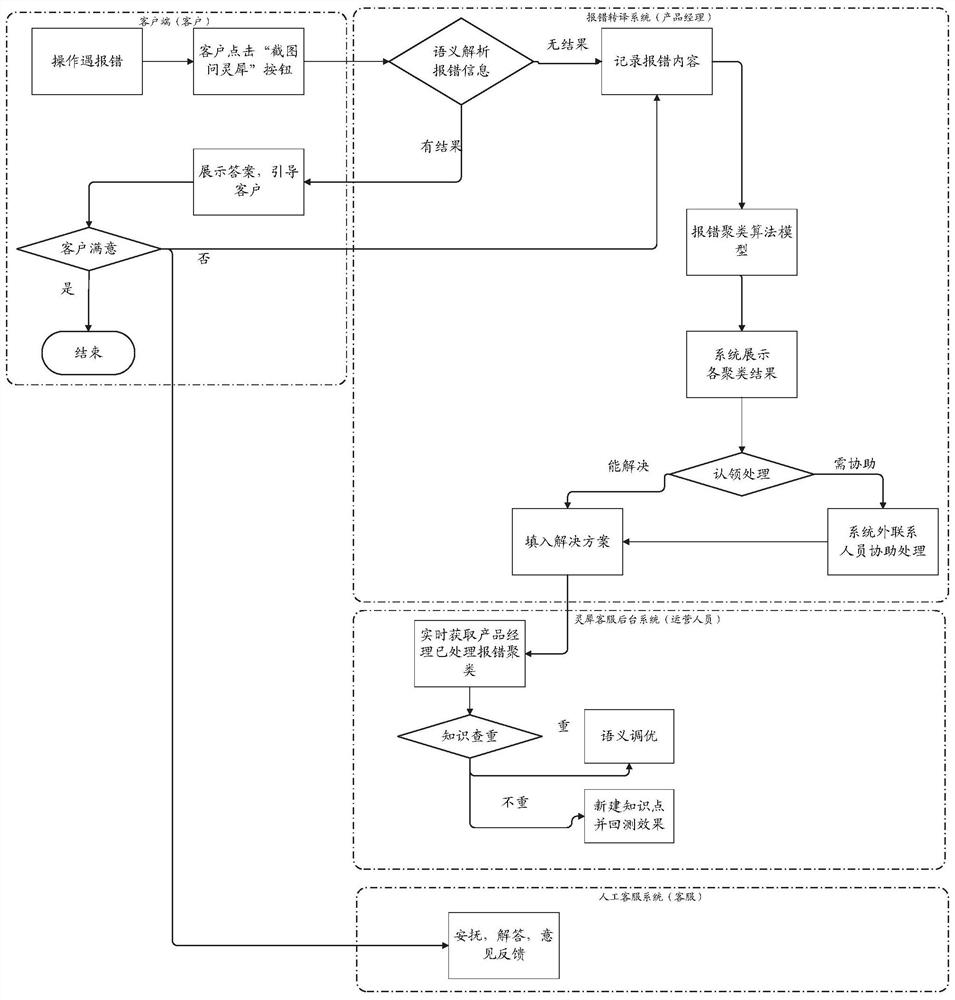
图1为本发明的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法的报错转译系统处理流程示意图。
图2为本发明的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法的聚类算法流程示意图。
图3为本发明的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法的自动获取最优参数的对比图。
图4为本发明的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法的聚类实验效果图。
图5为本发明的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法的报错转译系统页面示意图。
具体实施方式
为了能够更清楚地描述本发明的技术内容,下面结合具体实施例来进行进一步的描述。
本发明的该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法,其中包括(1)操作遇报错,对接智能服务平台;
(2)对报错信息进行文本解析,判断是否有相对比较匹配的结果,如果是,则继续步骤(3);否则,继续步骤(5);
(3)展示结果,引导客户正确的操作;
(4)判断客户是否满意,如果是,则结束步骤,否则,继续步骤(5),且安抚客户,
进行解答及意见反馈;
(5)记录报错内容;
(6)建立聚类算法模型,对报错信息进行聚类,将不同的报错聚类转化为后台运营知识点;
(6.1)建立聚类算法模型;
(6.2)定时对收集的报错信息按照不同类别进行聚类并展示;
(6.3)判断是否能解决报错聚类,如果是,则继续步骤(6.4);否则,联系人员进
行协助处理,继续步骤(6.4);
(6.4)填入解决方案,将不同的报错聚类转化为智能服务平台后台运营知识点;
(6.4.1)填入解决方案;
(6.4.2)进行知识点查重,如果重复,则进行语义调优;否则,新建知识点,
增加回溯效果。
作为本发明的优选实施方式,所述的方法还包括聚类算法的步骤,具体包括以下处理过程:
(1-1)获取当前需要聚类的数据集;
(1-2)删除历史模型;
(1-3)分调,生成训练员数据;
(1-4)建立doc2vec训练句向量模型;
(1-5)基于当前模型转换数据集;
(1-6)使用轮廓系数作为调优标准,遍历超参获取最优聚类。
作为本发明的优选实施方式,所述的步骤(1)中的轮廓系数,具体为:
根据以下公式计算轮廓系数:
其中,a(i)表示i向量到同一簇内其他点的不相似程度的平均值,b(i)表示i向量到其他簇的平均不相似程度的最小值。
该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的装置,其中包括:
处理器,被配置成执行计算机可执行指令;
存储器,存储一个或多个计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的方法的步骤。
该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的处理器,其中,所述的处理器被配置成执行计算机可执行指令,所述的计算机可执行指令被所述的处理器执行时,实现上述的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的方法的步骤。
该计算机可读存储介质,其上存储有计算机程序,所述的计算机程序可被处理器执行以实现上述的利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理的方法的各个步骤。
本发明的具体实施方式中,需要解决的技术问题是提供一个面向终端的跨平台报错转译系统,将终端上业务操作中出现的异常信息识别转译为面向客户友好的话术和后续业务引导,协助客户尤其是经验不足的新客户顺利进行行情浏览,股票交易等业务操作。
该报错转译系统主要分为两个部分:多平台交互引导流程和聚类算法流程。
一、多平台交互引导流程
报错转译系统使用上涉及客户、产品经理、运营人员、客服等多个业务方,后台涉及手机、电脑终端、智能服务平台运营后台、用户中心以及营销中台等多个系统。数据流的设计如附图1所示。
当用户遇到弹窗报错时,首先会对接智能服务平台,将该进行文本解析,当有相对比较匹配的答案的时候,会将该答案以弹窗的形式重新反馈给客户,引导客户进行正确的操作。而当客户对该答案不够满意或者智能服务平台未能解析出该报错的时候,收集该报错信息。
其中,所述的智能服务平台具体可以采用国泰君安公司的智能服务平台——灵犀客服系统,也可以为其他具备相应功能的服务平台,这些都属于本领域常用的智能服务平台,其技术细节为本领域所熟知,在此不再赘述。
报错转译系统定时对收集的报错信息按照不同类别进行聚类,并将结果展示给产品经理,由产品经理和客服运营人员协作一起将不同的报错聚类转化为智能服务平台后台运营知识点,当用户再次遇到该报错时,可以正确的引导客户,给客户一个满意的答案。
二、聚类算法流程
DBSCAN算法是由Martin Ester、Hans-Peter Kriegel等人在1996年提出的,是一种基于密度的空间聚类算法。
1、Eps邻域:一个对象p的Eps邻域是指以对象p为中心,以Eps为半径的区域内,即:
N
公式中,D为数据集;Dist(p,q)为对象p和对象q之间的距离;N
2、核心对象:给定数据集D,设定邻域密度阈值MinPts,若存在对象p∈D,且满足公式(2)时,则对象p是一个核心对象。
|N
公式中,|N
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。最早由Peter J.Rousseeuw在1986提出。它结合内聚度和分离度两种因素,可以用来在相同原始数据的基础上评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。其计算公式是:
公式中,a(i)表示i向量到同一簇内其他点的不相似程度的平均值,b(i)表示i向量到其他簇的平均不相似程度的最小值。
基于密度的聚类算法实质上是发现数据集中的高密度数据集合,即该数据集合中数据点之间的平均距离较小,而高密度数据集合之间存在着低密度区域。DBSCAN算法采用Eps和MinPts参数来确定划分高密度数据集合的阈值。而原始的DBSCAN算法使用的是基于词频的TF_IDF词向量,缺乏对报错本身的语义信息。本发明的算法流程图如附图2,使用基于数据集的doc2vec模型训练后的句向量替代TF_IDF词频向量,不仅涵盖了词频信息,也涵盖了文本本身的语义信息,再使用轮廓系数作为调优标准,自动获取最优参数,以获取相对最优的聚类结果。图3演示了算法流程中自动获取最优参数的对比。
如图4和图5分别是采用鸢尾花数据集和本系统实际采集报错信息集的聚类效果,从图4中可以看出,当聚类数据较多的时候,轮廓系数非常接近。由于类别较多,单纯从肉眼看颜色差异可能会有局限,所以图5展示了真实的系统页面截图,从图中可以看出,该系统利用超参自适用DBSCAN聚类算法模型,很好地实现了报错聚类的需求。
本发明的硬件要求:
系统部署需要一台内存8GB,CPU为16核,硬盘为500GB,系统为CentOS7的服务器。
数据使用mysql数据库存储,开发使用Django(python)和SpringCloud(java和angularJS)开发,其中模型训练和聚类算法使用docker部署。
本实施例的具体实现方案可以参见上述实施例中的相关说明,此处不再赘述。
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
需要说明的是,在本发明的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是指至少两个。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行装置执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
采用了该利用超参自适用DBSCAN聚类算法实现跨平台异常识别转译处理方法、装置、处理器及其计算机可读存储介质,在聚类数据较多的时候,轮廓系数非常接近,利用超参自适用DBSCAN聚类算法模型,很好地实现了报错聚类的需求。本发明通过自然语言处理中的文本聚类和语义解析技术,实现自动进行报错聚类、信息识别、引导转译一体化的过程,帮助用户在交易、业务办理等实际零售业务过程中获得更好的体验。
在此说明书中,本发明已参照其特定的实施例作了描述。但是,很显然仍可以作出各种修改和变换而不背离本发明的精神和范围。因此,说明书和附图应被认为是说明性的而非限制性的。
- 利用超参自适用DBSCAN聚类的跨平台异常识别转译方法、装置、处理器及存储介质
- 一种基于DBSCAN聚类的城市道路环境下的点云语义分割方法、系统及存储介质