一种基于三维地质模型的地质表征情况的评价方法及系统
文献发布时间:2023-06-19 10:35:20
技术领域
本发明涉及矿产资源预测领域,特别是涉及一种基于三维地质模型的地质表征情况的评价方法及系统。
背景技术
据统计,2013年中国21种矿产消费量位居世界首位,约占全球消费总量的1/3。未来的10到15年间,中国矿产资源的刚性需求仍将持续,大宗金属矿产需求峰值将陆续来临,对外依存度将大幅攀升,严重超越国家资源安全警戒线。如果未来10年探明资源储量不能大幅度增加,几乎所有的大宗金属矿产将面临消耗殆尽的危险局面,形势危急,前景堪忧。立足国内,寻找找矿战略新区,开辟第二找矿空间,实现找矿重大突破,提高资源保障程度,已成为中国一项紧迫、艰巨而又长期的重大战略任务。
无论是国外还是国内的找矿实践都证明,深部探矿是破解能源、资源困局的有效途径。随着找矿深度的不断加大,找矿工作也将从二维平面转向三维空间,传统的基于二维地理信息系统(Geographic Information System,GIS)图件开展的矿产资源预测评价已不再适应当代发展的需求,急需一种新的手段来表达地下存在的地质情况。因此,利用计算机三维地质建模技术与科学计算可视化定量表征地质模型、找矿勘探模型、预测模型,成为当前矿产资源预测领域的一大热点。
当前,大深度地质数据难识别、难获取是一个普遍难题,导致大量三维地质建模应用存在输入数据稀疏的情况,此外,在三维地质模型构建的过程中,受客观地质构造的复杂性、地质建模人员认识的主观性以及人工误差等,三维地质模型不可避免地存在着不确定性,缺乏实用性,导致地质表征情况准确性差,无法准确预测矿产资源。
发明内容
本发明的目的是提供一种基于三维地质模型的地质表征情况的评价方法及系统,以解决大深度地质数据难识别、难获取且在三维地质模型构建的过程中,受客观地质构造的复杂性、地质建模人员认识的主观性以及人工误差等,三维地质模型不可避免地存在着不确定性,缺乏实用性,导致地质表征情况准确性差,无法准确预测矿产资源的问题。
为实现上述目的,本发明提供了如下方案:
一种基于三维地质模型的地质表征情况的评价方法,包括:
获取地层和构造原始测量数据,根据所述地层和构造原始测量数据生成三维地质测量模型;
对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;所述三维地质测量模型以及所述三维扰动模型为三维地质模型;
将所述三维地质模型转换为三维矿块模型,并将所述三维矿块模型按照坐标展开成一维数组,完成预处理,形成地质模型评价数据集;
根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重;
基于所述每个信息源的真值点以及所述每个信息源的权重对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型;所述定性评价用于评价所述三维地质测量模型或所述三维扰动模型的质量;所述定量评价用于评价所述三维地质测量模型或所述三维扰动模型中观测值的不确定性;所述用于定量评价的三维地质模型用于评价地质表征情况。
可选的,所述对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型,具体包括:
基于蒙特卡洛模拟的不确定性传播方法对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;
其中,所述蒙特卡洛模拟的不确定性传播方法中的两种标准分布包括位置的正态分布以及方向的vMF分布;
所述位置的正态分布的概率密度函数为:
所述方向的vMF分布的概率密度函数为:
可选的,所述根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重,之后还包括:基于地质拓扑知识,利用所述三维地质模型反推地质构造的空间拓扑结构,形成地质拓扑坐标系,并与已知地质拓扑进行对比分析,验证所述三维地质模型的不确定性。
可选的,所述根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重,具体包括:
利用k-means聚类法将所述地质模型评价数据集P分成k个子集,并将k个所述子集的中心点放入集合U;
以所述集合U中的k个中心点{u
遍历所述网格点集G的所有顶点{g
可选的,所述目标函数为:
其中,p
可选的,所述根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重,之后还包括:
在所述原始测量数据上添加构造边界数据;所述构造边界数据包括钻孔、剖面以及地球物理数据;
根据所述构造边界数据修正所述三维地质测量模型,确定修正后的三维地质测量模型;
根据所述修正后的三维地质测量模型依次经过扰动以及转换,确定修正后的三维矿块模型;
对比所述三维矿块模型以及所述修正后的三维矿块模型;
若所述修正后的三维矿块模型内的格子数小于所述三维矿块模型,确定所述三维矿块模型的可靠性增加;
若所述修正后的三维矿块模型内的格子数大于所述三维矿块模型,确定所述三维矿块模型的可靠性降低。
可选的,基于所述每个信息源的真值点以及所述每个信息源的权重对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型,具体包括:
基于所述每个信息源的真值点以及所述每个信息源的权重,利用正态分布法或累积分布函数法对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型。
一种基于三维地质模型的地质表征情况的评价系统,包括:
三维地质测量模型生成模块,用于获取地层和构造原始测量数据,根据所述地层和构造原始测量数据生成三维地质测量模型;
三维扰动模型生成模块,用于对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;所述三维地质测量模型以及所述三维扰动模型为三维地质模型;
地质模型评价数据集形成模块,用于将所述三维地质模型转换为三维矿块模型,并将所述三维矿块模型按照坐标展开成一维数组,完成预处理,形成地质模型评价数据集;
不确定性确定模块,用于根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重;
用于定量评价的三维地质模型构建模块,用于基于所述每个信息源的真值点以及所述每个信息源的权重对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型;所述定性评价用于评价所述三维地质测量模型或所述三维扰动模型的质量;所述定量评价用于评价所述三维地质测量模型或所述三维扰动模型中观测值的不确定性;所述用于定量评价的三维地质模型用于评价地质表征情况。
可选的,所述三维扰动模型生成模块,具体包括:
三维扰动模型单元,用于基于蒙特卡洛模拟的不确定性传播方法对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;
其中,所述蒙特卡洛模拟的不确定性传播方法中的两种标准分布包括位置的正态分布以及方向的vMF分布;
所述位置的正态分布的概率密度函数为:
所述方向的vMF分布的概率密度函数为:
可选的,所述不确定性确定模块,具体包括:
聚类单元,用于利用k-means聚类法将所述地质模型评价数据集 P分成k个子集,并将k个所述子集的中心点放入集合U;
网格点集确定单元,用于以所述集合U中的k个中心点 {u
每个信息源的真值点确定单元,用于遍历所述网格点集G的所有顶点{g
根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供了一种基于三维地质模型的地质表征情况的评价方法及系统,首先,通过对真值发现结果的真值研究,优化了三维地质模型的不确定性的定量表达研究;其次,探索了减少三维地质模型不确定性有效途径;最后,通过对真值发现结果的权重研究,实现了基于全局最优解的三维地质模型可靠性的定量评价,解决了三维地质模型不确定性的整合和定量表达问题,实现了随机测量模型与扰动模型的可靠性评价,不受客观地质构造的复杂性、地质建模人员认识的主观性以及人工误差等影响,建立的用于定量评价的三维地质模型用于评价地质表征情况,能够准确评价地质表征情况,从而准确预测矿产资源。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明所提供的基于三维地质模型的地质表征情况的评价方法流程图;
图2为总体技术流程图;
图3为κ值的大小对vMF的影响示意图;
图4为累积分布法示意图,横坐标代表权重值的倒数,纵坐标代表累积概率值;
图5为本发明所提供的基于三维地质模型的地质表征情况的评价系统结构图;
图6为扬子板块大地构造分区图;
图7为随机扰动模型示意图;
图8为矿块扰动模型的转化示意图;
图9为三维地质模型的不确定性示意图;其中,图9(a)为三维地质模型总的不确定性示意图;图9(b)为三维地质模型向年轻地质年代变化的不确定性示意图;图9(c)为三维地质模型向年老地质年代变化的不确定性示意图;图9(d)为不确定性与断层和部分地层的叠加示意图;
图10为数据集1、数据集2和数据集3的不确定性可视化示意图;其中,图10(a)为第一组数据的不确定性结果;图10(b)为第二组数据的不确定性结果;图10(c)为第三组数据的不确定性结果;图10(d)为第一组数据的不确定性结果的主干剖面与断层和牛蹄塘组的叠加图;图10(e)为第二组数据的不确定性结果的主干剖面与断层和牛蹄塘组的叠加图;图10(f)为第三组数据的不确定性结果的主干剖面与断层和牛蹄塘组的叠加图;
图11为模型格子变化程度直方图;其中,直方图柱子上的数字代表着该范围对应的格子个数;图11(a)为模型1格子变化程度直方图;图11(b)为模型2格子变化程度直方图;图11(c)为模型3 格子变化程度直方图;图11(d)为模型1、2、3格子变化程度直方图的比较图;
图12为正态分布法结果示意图;
图13为数据集1,数据集2和数据集3的正态分布曲线的示意图;其中,图13(a)为数据集1的正态分布曲线图;图13(b)为数据集2的正态分布曲线图;图13(c)为数据集3的正态分布曲线图;图13(d)为数据集1、数据集2、数据集3正态分布曲线的比较图;
图14为累积分布函数法结果示意图;
图15为三组数据权重集的累积分布函数法比较图;
图16为地质拓扑构建技术流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于三维地质模型的地质表征情况的评价方法及系统,能够准确评价地质表征情况,从而准确预测矿产资源。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
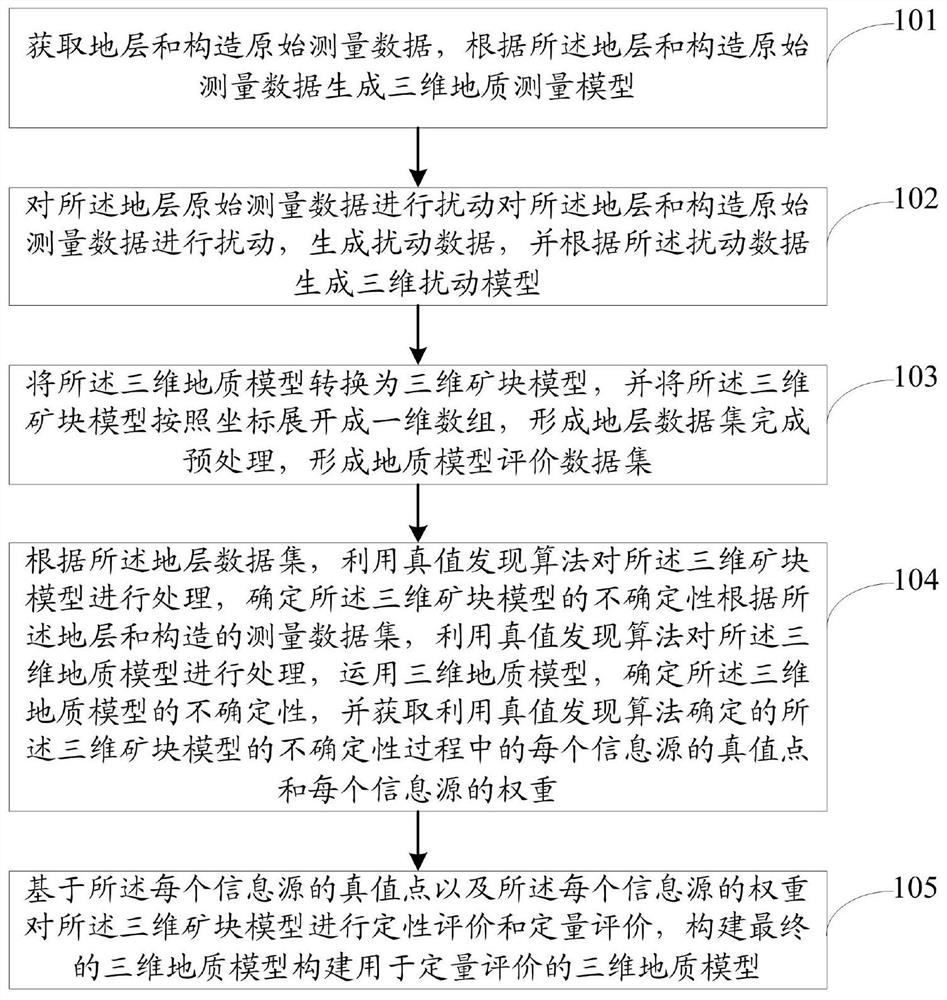
图1为本发明所提供的基于三维地质模型的地质表征情况的评价方法流程图,如图1所示,一种基于三维地质模型的地质表征情况的评价方法,包括:
步骤101:获取地层和构造原始测量数据,根据所述地层和构造原始测量数据生成三维地质测量模型。
步骤102:对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;所述三维地质测量模型以及所述三维扰动模型为三维地质模型。
所述步骤102具体包括:基于蒙特卡洛模拟的不确定性传播方法对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;其中,所述蒙特卡洛模拟的不确定性传播方法中的两种标准分布包括位置的正态分布以及方向的vMF分布;所述位置的正态分布的概率密度函数为:
步骤103:将所述三维地质模型转换为三维矿块模型,并将所述三维矿块模型按照坐标展开成一维数组,完成预处理,形成地质模型评价数据集。
步骤104:根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重。
三维地质模型交叉验证(仿真实验)的方法如下:基于地质拓扑知识,由三维地质模型反推地质构造的空间拓扑结构,形成地质拓扑坐标系,并于已知地质拓扑进行对比分析,验证三维地质模型的可靠性,图16为地质拓扑构建技术流程图,如图16所示。
所述步骤104具体包括:利用k-means聚类法将所述地质模型评价数据集P分成k个子集,并将k个所述子集的中心点放入集合U;以所述集合U中的k个中心点{u
所述目标函数为:
所述步骤104之后还包括:在所述原始测量数据上添加构造边界数据;所述构造边界数据包括钻孔、剖面以及地球物理数据;根据所述构造边界数据修正所述三维地质测量模型,确定修正后的三维地质测量模型;根据所述修正后的三维地质测量模型依次经过扰动以及转换,确定修正后的三维矿块模型;对比所述三维矿块模型以及所述修正后的三维矿块模型;若所述修正后的三维矿块模型内的格子数小于所述三维矿块模型,确定所述三维矿块模型的可靠性增加;若所述修正后的三维矿块模型内的格子数大于所述三维矿块模型,确定所述三维矿块模型的可靠性降低。
步骤105:基于所述每个信息源的真值点以及所述每个信息源的权重对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型;所述定性评价用于评价所述三维地质测量模型或所述三维扰动模型的质量;所述定量评价用于评价所述三维地质测量模型或所述三维扰动模型中观测值的不确定性;所述用于定量评价的三维地质模型用于评价地质表征情况。
所述步骤105具体包括:基于所述每个信息源的真值点以及所述每个信息源的权重,利用正态分布法或累积分布函数法对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型。
基于本发明上述的基于三维地质模型的地质表征情况的评价方法,在实际操作过程中,本发明的详细步骤如下:
图2为总体技术路线图,如图2所示,首先预处理阶段主要是构建研究所需的数据,包含收集原始数据、利用概率分布进行随机扰动、生成批处理数据;第二,应用隐式三维地质建模的方法将预处理的数据构建为N个可能性模型,同时为了方便处理,需要将这些可能性模型变为矿块模型;第三,结合权重和真值发现,求得各模块新旧变化的情况;第四,整合对照组,降低模型不确定性;第五,利用正态分布法和累积概率函数法进行可靠性评价。
第一步:预处理模块的主要功能是构建研究所需的数据。其主要包含3个部分:收集原始数据、利用概率分布进行随机扰动、生成批处理数据。
(1)原始数据的收集
基于蒙特卡罗模拟的不确定性传播方法(下文均使用简称MCUE) 通过对输入的原始数据进行扰动产生许多模型来传播输入数据的不确定性,然后将输出模型进行整合,用可视化的方式分析模型的不确定性。隐式建模方法是MCUE的首选方法,在建模过程中,主要使用三种类型的数据作为输入:构造边界上的控制点(三维点)、方向(倾向和倾角)和地质单元与地质单元之间的拓扑关系。因此,在本过程中,需要收集产状数据用来提供构造边界上的控制点以及方向,以及构造和侵入用来判断地质单元与地质单元之间的拓扑关系。此外,在这一步,也将利用上述数据构建研究区的初始模型。
(2)概率分布的确定
MCUE中的两种标准分布:
如果每个不确定源的方差总是确定的,则中心极限定理(CLT)对这些数据是成立的。不确定性可以更好地用与CLT一致的扰动分布来表示,即位置的正态分布(笛卡尔标量数据)和方向的von Mises-Fisher(vMF)分布。然而,MCUE并没有禁止使用任何类型的分布。其中,正态分布的概率密度函数记为:
其中ε为算数平均值,σ为标准差。
如图3所示,vMF分布()为球面数据的CLT分布;它是正态分布的超球面对应项,并且是p维单位超球面S
其中,γ
其中,I
在MCUE中的两种标准分布,即位置的正态分布和方向的(von Mises-Fisher,vMF)分布。事实上,在实际应用中,如何确定分布范围这需要一定的经验(地质经验或数学经验),因此需要使用者来判定分布范围的大小。
(3)批处理数据的生成
结合步骤(1)中的原始数据和(2)中给出的概率分布范围,会生成数以千计的模型。这为实验提供了数据基础。
第二步:在预处理模块中,可以生成数以千计的输入数据,这些数据应用隐式三维地质建模的方法可以构建N个可能性模型(这其中也包括初始模型),为了方便处理,需要将这些可能性模型变为矿块模型。为了可视化最终的不确定性,实验需要将所有的模型都作为初始模型,来计算剩余模型与该初始模型的差异。计算变化模型要通过以下标准:(1)当剩余模型与初始模型对应位置相同时,变化模型对应位置取0;(2)当剩余模型对应位置大于初始模型时,变化模型对应位置取1;(3)当剩余模型对应位置小于初始模型时,变化模型对应位置取-1。
应用此方法,便生成了以初始模型为中心的N-1个变化模型。接下来将这些模型展开成向量,作为真值发现算法的输入。
真值发现:
真值发现问题进行建模,则来自每个源的数据可以表示为一个 (可能是高维的)向量,其中每个维对应于一个属性。此外,需要一个变量来表示每个源的可靠性。则定义如下:
令P={p
目标函数:
在上述优化问题中,p
输入:
(1)利用k-means聚类法将数据集P分成k个子集,并将得到的k个中心点放入集合U;
(2)以U中的k个中心点{u
(3)遍历网格点集G的所有顶点{g
相较于之前的方法,主要在第一步中做了改动,这里有两个原因: (1)在实际应用中,数据量并未达到一定的数值,因此若使用该算法进行抽样,将会使得数据的抽样误差增大;(2)将数据集分成子集采用了k-means聚类法,该聚类方法有着速度快、效率高等特点,但却有着收敛到最优解难的缺点,因此,在实验中多运行几次该算法,取其中的最优解,从而使最终结果更加可靠。以此便得到了以第i个扰动模型为初始模型为变化的真值模型
第三步:在真值发现中求得所有的权重w
因此,为了得到最终的不确定性,该步骤需要对第二步得到的N 个
为了验证此假设,需要设计对照实验:(1)通过原始数据进行建模;(2)在原始数据的基础上,增加可靠的钻孔、剖面或地球物理数据,修正该模型;(3)对两组数据分别扰动若干次,对两组数据进行整合;(4)通过可视化的方法直观的比较两组数据发生的变化,并通过格子数来定量的表征这样的变化,来与假设进行对比,若数据发生变化的格子数降低,则说明模型的可靠性增加,假设成立;反之,若数据发生变化的格子数升高,则说明模型的可靠性降低,假设不成立。
第五步:在进行此步骤之前,需要做一个模拟实验:实验含随机扰动数据,通过真值发现算法,得到其符合正态分布规律的权重,为了证实这一点,本方法运用了卡方拟合优度检验。
在保证数据量足够大的时候,权重集服从正态分布,则可以使用正态分布法对测量模型进行可靠性评价。(1)正态分布法:地球化学异常求解中,有一种求解方法是用背景值加或减两倍标准差作为异常的上限和下限。正态分布法将该方法的核心思想纳入其中,将均值加或减一倍标准差和均值加或减两倍标准差作为临界点,将正态分布构成的区域划分为了5个区域,通过这种分级的方式来定性的评价模型的质量。
通过此方法,能够一定意义上评价测量模型或扰动模型的等级,可以对其进行定性分析。此外,本方法还对其进行定量分析,首先要将服从正态分布的模型权重转变为标准正态分布,通过查标准正态分布表的方式来确定该模型所对应的概率值,从而可以给出该模型的置信程度。
其中,μ是数据的均值,σ是数据的方差。
置信程度越大,意味着模型的可靠性越高;反之,置信程度越小意味着模型的可靠性越低。但此方法必须使得权重集W服从正态分布,因此有一定的局限性。而概率分布法既可以定量的评价测量模型和扰动,由不局限于正态分布的前提,因此可以应用此方法进行可靠性评价。
(2)累积分布函数法:累积分布函数(Cumulative Distribution Function),又叫分布函数,是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。一般以大写CDF标记,与概率密度函数 probability density function(小写pdf)相对。对于所有实数x,累积分布函数定义如下:
F
因此,可使用CDF确定取自总体的随机观测值将小于或等于特定值的概率,继而可以定量的确定该观测值的不确定性,如图4。
图5为本发明所提供的基于三维地质模型的地质表征情况的评价系统结构图,如图5所示,一种基于三维地质模型的地质表征情况的评价系统,包括:
三维地质测量模型生成模块501,用于获取地层和构造原始测量数据,根据所述地层和构造原始测量数据生成三维地质测量模型。
三维扰动模型生成模块502,用于对所述地层和构造原始测量数据进行扰动,生成扰动数据,并根据所述扰动数据生成三维扰动模型;所述三维地质测量模型以及所述三维扰动模型为三维地质模型。
地质模型评价数据集形成模块503,用于将所述三维地质模型转换为三维矿块模型,并将所述三维矿块模型按照坐标展开成一维数组,完成预处理,形成地质模型评价数据集。
不确定性确定模块504,用于根据所述地层和构造的测量数据集,利用真值发现算法对所述三维地质模型进行处理,运用所述三维地质模型,确定所述三维地质模型的不确定性,并获取利用真值发现算法确定的所述三维矿块模型的不确定性过程中的每个信息源的真值点和每个信息源的权重。
用于定量评价的三维地质模型构建模块505,用于基于所述每个信息源的真值点以及所述每个信息源的权重对所述三维矿块模型进行定性评价和定量评价,构建用于定量评价的三维地质模型;所述定性评价用于评价所述三维地质测量模型或所述三维扰动模型的质量;所述定量评价用于评价所述三维地质测量模型或所述三维扰动模型中观测值的不确定性;所述用于定量评价的三维地质模型用于评价地质表征情况。
以湖南花垣MVT铅锌矿矿集区为例,对湖南花垣MVT铅锌矿矿集区建模验证本发明的技术方案。
数据收集与整理:
花垣-渔塘铅锌矿自20世纪以来,进行了多次勘查工作,取得了海量的勘查数据,如钻孔数据、探槽数据、坑道工程数据、物化探数据、相关勘查报告等。研究区通过1:5万的区调和矿调工作,积累了花垣县幅和麻栗场幅等基础地质资料,为重点区域的区域三维地质建模提供了数据基础。
通过对相关资料进行收集、整理发现,随着数字化建设的不断深入,近年来的相关资料和图件基本采用电子文档和计算机制图,而早期的勘查资料大多为纸质资料。电子版资料需要按照研究区三维空间数据库的格式要求进行格式转换,或重新录入,经检查通过后进入数据库。而纸质文档和图件则首先要进行数字化,信息提取与重新录入,经格式检查后进入数据库,表1为花垣地质调查数据集示意表。
表1
以此为基础,获取隐式三维地质建模所需的三种数据:构造边界上的控制点(三维点)、方向(倾向和倾角)和地质单元与地质单元之间的拓扑关系。在此基础之上,应用Intrepid的GeoModeller软件,构建测量模型。
研究区地质背景:
如图6,花垣MVT铅锌矿矿集区位于扬子陆块东南缘与雪峰造山带的过渡区,花垣-张家界深大断裂与麻栗场断裂之间,总体走向北北东。矿集区内主要出露了从青白口系至寒武系的一系列地层,从下到上依次为青白口系板溪群、南华系大塘坡组、南沱组、震旦系陡山沱组、灯影组、寒武系牛蹄塘组、石牌组、清虚洞组、高台组、娄山关组。少量主体由灰岩组成的奥陶系地层分布于矿集区西北角,第四系零星分布于沟谷中。青白口系板溪群岩性为浅灰绿色绢云母板岩、粉砂质板岩,南华系大塘坡组为重要含锰矿层位,地层中夹菱锰矿层,岩性为黑色薄层炭质泥岩灰岩透镜体。南沱组为深灰色厚层状冰碛砾岩、含砾砂屑泥岩。陡山沱组为黑色薄层炭质泥岩与灰色厚层粉晶白云岩互层,灯影组为灰色厚层粉晶-细晶白云岩。寒武系地层在本区出露最广,寒武系底部牛蹄塘组为黑色薄层含炭泥岩,石牌组岩性为灰色薄-中厚层状粉砂质泥岩、粉砂岩夹岩屑细砂岩,清虚洞组下部为灰色中厚层状藻灰岩、泥质灰岩、泥晶灰岩,上部为浅灰、灰白色中厚层状白云质灰岩,高台组为灰白色薄-中层状粉细晶白云岩,娄山关组为灰白色厚层块状粉细晶白云岩。
具体流程:
总结并提出的真值发现出发,开展与MVT铅锌矿床深部少数据三维地质模型可靠性的评价技术工作。
(1)预处理。
预处理模块的主要功能是构建研究所需的数据,将早期的勘查纸质资料按照研究区三维空间数据库的格式要求进行格式转换,或重新录入。此外,根据这些实地测量数据,建立测量模型,具体过程包括①建立地层序列,添加断层;②创建地表,添加地表线和产状;③创建剖面,添加产状和地质界线等信息;④添加三维地质模型的相关信息;⑤生成三维地质模型。
(2)扰动数据的生成与扰动模型建立。
通过蒙特卡罗模拟对原始测量数据进行扰动,设置系数κ,并建立地层错断关系和顺序关系,生成扰动数据,最后利用扰动数据建立 50个扰动模型,如图7所示。
自此,已经得到了包含测量模型在内的51个三维地质模型。为了方便接下来的工作,需要将模型进行变换。事实上,应用 GeoModeller构建的模型是一种三角网格构成的曲面模型,这很难用于接下来的计算,这是因为曲面模型更像是一种矢量模型,不同模型之间很难进行比较。此外,对于真值发现算法,每条输入数据均为一维数组(向量)。因此,需要将矢量模型栅格化。
矿块模型可以说是二维GIS栅格模型的三维表示,每个格子具有不同的地质属性,从而可以方便的计算矿石含量。在这一步中,将 51个三维地质模型应用中国地质科学院矿产资源研究所自行研发的探矿者软件转化为大小为50×50×50的三维矿块模型,如图8所示。
最后,将上述矿块模型按照坐标展开成125000的一维数组,形成数据集P存储在data.csv中,表2为数据集P节选示意表,如表2 所示,其中1-13代表从老到新的地层需要,14代表地表以上的空白区域,15-17代表断层。自此,便得到了方法所用的数据。接下来,将应用真值发现方法对三维地质模型的不确定性进行评价。
表2
(3)三维地质模型的不确定性评价与表达。
本次实验将以测量模型p_50为初始模型,其它模型为比较模型。此环节将要用到Python数据分析中一个很重要的库:Pandas。其步骤如下所示:
第一步:应用Pandas中的read_csv方法读入data.csv存储在 models变量中。
第二步:将数据集中的p_50作为初始数据存储在initial_model 变量中。
第三步:将models中的p_50删除。
第四步:循环读入models中的数据放入temp,与initial_model 进行比较。若temp中的格子数字大于initial_model中的格子,则将该格子赋值1;若temp中的格子数字小于initial_model中的格子,则将该格子赋值-1;若temp中的格子数字等于initial_model中的格子,则将该格子赋值0,将结果存在列表list中。最后,将素有的list存储在二维列表list_whole中并应用model.to_csv函数输出成文件 input_data50.csv。
这便是真值发现算法所应用的第一个数据。遍历数据集P,将所有的p_i作为初始数据,循环计算上述步骤,即可得到所有的 input_datai.csv文件。
在应用input_data50.csv之前,首先需要将真值发现中几个重要的函数进行实现,在这里,主要应用的程序库有。首先是目标函数 object_function:
输入:数据集P、权重集W以及真值向量p
第一步:应用Numpy中的linalg.norm函数循环计算数据集P中 p
第二步:将列表object中的所有值进行求和,存储在add中。
输出:输出add。
其次要对求解权重值函数weights进行实现:
输入:数据集P、真值向量p
第一步:应用Numpy中的linalg.norm函数和math.pow函数循环计算p
第二步:以求解权重w
输出:权重集W。
接下来,将应用Pandas、math和Scikit-learn库对整个算法进行实现,为了方便说明,以得到的input_data50.csv作为输入数据:
第一步:用Pandas的read_csv方法读入input_data50.csv;
第二步:计算分组所需的k值,其计算公式为:
其中n代表数据集个数,Δ代表了数据集任意两两之间最大值与最小值之间的比值,ε代表误差系数。由公式可见,在n和Δ一定的情况下,ε越大,k越小。值得注意的是,k值的大小将影响格子数字的大小,从而影响整个实验的计算效率,在第四步中详细探讨这个情况。这里选择ε为0.1,即误差系数为10%。则k值为13。
第三步:应用Scikit-learn中的Kmeans函数将数据聚为13类。聚类算法有其固有缺陷,即不能有效的收敛到全局最优解,因此需要在此多做几次Kmeans,将其中最好的一组解挑出,得到其聚类中心点存储在U中,作为单纯形的顶点。
第四步:在单纯形U中构建网格。以往的网格化方式是对每个轴之间进行分割,然后将分割的结果进行组合从而生成网格。例如,在二维笛卡尔坐标系下,将x
因此,本发明提出了一个新的网格化算法:
Step1:计算单纯形顶点U中任意两点的中值,与原有顶点一起存在U1中。
Step2:对Step1进行迭代,直到网格点足够多的时候停止迭代。
Step3:去除重复的网格点。
这种方法规避了数据维度,也能够有效的增加格子,以本发明的 13个顶点为例,第一次迭代,能够生成91个新格子;第二次迭代,能够生5460个新格子;第三次迭代就可以生成15409576个新格子。因此该方法也能无限逼近最优解。
事实上,当该方法迭代到第四次时,实验所用的计算机已经很难进行计算。因此,本发明将三次迭代生成的格子放入Grid中。
第五步:遍历Grid中的网格点,作为
循环重复一到五步,直到带入最后一个input_datai.csv文件生成结果。
最后,将上述生成的51个p
本发明将基于探矿者软件二次开发的方式,可视化三维地质模型的不确定性。该工作的本质便是在探矿者开发程序中找到可视化矿块的模块,通过以下规则更改该模块:(1)不确定性为0的区域为第一颜色,代表该区域不存在不确定性;(2)不确定性大于0的区域为第二颜色,代表该区域的不确定性有着向年轻地质年代变化的趋势;(3) 不确定性小于0的区域为第三颜色,代表该区域的不确定性有着向年老地质年代变化的趋势。最终的结果如图9所示,其中,按照颜色由深至浅排列,第二颜色>第一颜色>第三颜色,通常情况下,在可视化显示时,第一颜色为蓝色,第二颜色为红色,第三颜色为绿色。由图 9可以看出,这组数据的不确定性很高。这是因为,本发明在扰动过程中,构造边界中提供的产状点数据略为稀疏。接下来,将通过在构造边界增加数据点的方式,减少隐式三维地质建模过程中的不确定性。
(4)三维地质模型不确定性的降低。
本阶段将设计两组数据来与上一步的结果进行对比。相较于第一组数据,第二组数据在牛蹄塘组增加了产状数据。第三组数据则在除错断关系外的构造边界增加了产状数据。通过真值发现的算法得到结果。首先对三组数据的不确定性进行可视化,如图10所示,可以清晰的看到,图10a、图10b到图10c有着明显的差距,图10a、图10b 的不确定性明显更高,然而图10a到图10b的变化似乎不那么明显。但从图10d到图10e可以清晰的看出,牛蹄塘组附近的不确定性明显降低了。
为了更加明确相比第一组数据,第二组数据的不确定性有着明显的降低,实验对三个模型125000个格子的变化程度做了统计,如图 11所示。由图11可以看出,从模型1到模型3,不确定性为0或几乎为0的格子数是递增的。由此可以确定,随着构造边界产状数据的增加,隐式三维地质建模中产生的不确定性是降低的。由此可以引出三维地质模型不确定性评价与表达工作的其中一个意义:为下一步勘察工作指明了方向。
(5)测量模型的可靠性评价。
①正态分布法应用与结果分析:
既然权重集W服从正态分布,那么就可以先应用正态分布法对权重w
第一步:应用Pandas库中的read_csv函数读入权重集W存入 weights变量中。
第二步:求weights变量的均值mean,标准差std,求得正态分布函数normfun。
第三步:应用正态分布函数计算均值加减一倍方差的坐标 (downx1,downy1)、(upx1,upy1);计算均值加减一倍方差的坐标 (downx2,downy2)、(upx2,upy2)。
第四步:应用正态分布函数normfun计算权重w
第五步:应用matplotlib库可视化第二、三、四步的信息,如图 12所示。
第六步:对权重w
第七步:应用scipy中的stats.norm.cdf函数,求出w50所对应的概率值。
由图12可知,w_50的概率位于正态分布曲线中间靠左侧的位置,属于C级,可以认为测量模型的可靠性一般。此外,通过将w_50进行标准正态分布化,通过累计概率密度函数可以得知,w_50的概率为0.308,因此,该模型的置信度为30.8%,可靠性也就是30.8%。
为了探究不确定性对测量模型可靠性的影响,还做了数据集1,数据集2和数据集3的正态分布曲线的比较,如图13。
从图13可以首先可以看出,三组数据的均值基本一致,方差有着一定的差异。第一组数据的方差较大,正态分布曲线的范围相对分散,与之相对,第三组数据的方差较小,分布范围相对集中。此外,第一组数据中,测量模型位于曲线偏右的位置;第二组数据中,测量模型位于曲线略偏左的位置;第三组数据中,测量模型更靠向右侧的底部。通过查表,第一组数据测量模型可靠性为30.8%,第二组数据测量模型可靠性为58.0%,第二组数据测量模型可靠性为97.0%。从而可以得出,随着不确定性的降低,权重集的分布范围会不断集中,测量模型的可靠性也会不断上升。
②累积分布函数法应用与结果分析:
可以说,累积分布函数法是正态分布法的改进。应用此方法,可以在定性的基础上给出定量的可靠性值。其方法如下所示:
第一步:应用Pandas库中的read_csv函数读入权重集W存入 weights变量中。
第二步:应用statsmodels.api中的distributions.ECDF求解累积分布函数ecdf。
第三步:对weights进行排序存储在x中,用ecdf对x求解得到 y。
第四步:对w_50进行排序存储在x1中,用ecdf对w_50求解得到y1。
第五步:应用matplotlib库可视化第二、三、四步的信息,如图 14所示。
最终结果表明,权重w_50处在累积分布函数的中间偏下的位置,与正态分布法类似,表明测量模型的可靠性一般。但不同于正态分布法,累积分布函数的纵坐标为累积概率和,经结果表明,权重w_50 的累积概率和为33.3%,从而可以定量的表达其可靠性高达33.3%。
此外,还做了模型1,模型2和模型3累计概率函数曲线的比较,如图15所示。结果表明:与正态分布法类似,从图15可以看出,第一组数据集的测量模型在中间下方的位置,其累积概率值为33.3%;第二组数据集的测量模型在靠近中间的位置,其累积概率值约为51.0%;第三组数据在左上方,其累积概率值约为82.0%。因此,也可以得出与正态分布法类似的结论,测量模型的可靠性也会不断上升。
事实上,这样的结果也符合三维地质模型不确定性存在的规律。随着模型越来越精确,势必会造成模型中存在的不确定性区域越来越少,使得扰动模型发生的变化越来越小,从而使得权重集的分布越来越集中。此外,随着模型越来越精确,由原始数据构成的测量模型就越来越可信,从而可靠性也会越来越高。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种基于三维地质模型的地质表征情况的评价方法及系统
- 一种基于三维地质模型的地质表征情况的评价方法及系统