用于无中心分布式文件系统的元数据分层缓存方法及装置
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及分布式文件系统技术领域,尤其涉及一种用于无中心分布式文件系统的元数据分层缓存方法及系统。
背景技术
无中心分布式文件系统即为不存在主控节点、任何节点都是同级的文件系统,且文件系统中的数据块由整个系统中所有存储节点来共同维护,每个节点负责维护节点本地的数据,可以避免中心式文件系统中不可避免的单点故障和性能瓶颈问题,提高系统的可靠性、可用性与拓展性。
元数据即为描述数据属性的信息,包括目录属性、文件属性等。无中心分布式文件系统没有元数据服务器,元数据分布在各个存储节点上,客户端对存储节点会存在目录操作(如create、mkdir、mknod、rmdir、unlink等)、文件属性操作(lookup、stat、setattr等)和文件内容读写操作(readv、writev等)等各类元数据操作。目前无中心分布式文件系统中元数据均是统一存储在磁盘中,该类将元数据统一存储在磁盘的方式,会使得单个存储节点需要同时面临大量客户端发送的目录操作、文件属性操作和文件内容读写操作,各种类型的操作相互之间会存在由于抢占磁盘IO而造成元数据请求拥塞的问题,这会极大的影响元数据请求的处理速度以及元数据的操作性能。
针对于数据缓存,为减少数据集中缓存量,一种典型的解决方案即是分类缓存,即将不同类型的数据分类别缓存在不同的缓存空间。但是该分类缓存方式仅仅是按照数据类型缓存至不同的缓存空间中,不同数据缓存之间通常是相互独立的。而无中心分布式文件系统中各存储节点上的元数据之间是具有层级、耦合关联性的,如目录项之间、文件之间存在耦合关系,目录项与文件属性之间存在层级关联性,若对元数据直接采用独立分类缓存的方式,由于缺少数据间的关联性信息,要从不同的缓存中独立获取出所需元数据实际仍需要耗费较长时间,尤其是当面对大量数据请求时,因而当客户端发送元数据请求时,就难以快速的从缓存中准确获取出所需的目标数据,仍然会存在元数据请求的处理速度慢以及数据操作性能差的问题。
发明内容
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种用于无中心分布式文件系统的元数据分层缓存方法及系统,能够在不影响无中心分布式文件系统的前提条件下,提高存储节点对元数据请求的处理速度,改善元数据操作性能。
为解决上述技术问题,本发明提出的技术方案为:
一种无中心分布式文件系统中元数据分层缓存方法,步骤包括:
步骤S1.分层缓存构建:为无中心分布式文件系统中各存储节点分层设置目录项缓存层、文件属性缓存层,所述目录项缓存层用于缓存目录项相关的元数据,所述文件属性缓存层用于缓存文件属性相关的元数据;
步骤S2.数据分层存储:查询虚拟文件系统中每个目录项对应的目录项元数据、目录项关系、目录项标识信息以及文件属性元数据,将查询得到的目录项元数据以及目录项关系存入所述目录项缓存层,所述目录项关系为目录项元数据与目录项之间的关系,将查询得到的所述目录项标识信息以及文件属性元数据按照对应关系存入所述文件属性缓存层中。
进一步的,所述步骤S1中,在内存中设置所述目录项缓存层,在快速存储介质中设置所述文件属性缓存层。
进一步的,所述步骤S2的步骤包括:
步骤S21.定义目录项结构体以用于存储目录项关系;定义用于存储所述目录项结构体的数组的目录项数组,以及定义用于存储目录项文件属性的文件属性数据库;
步骤S22.遍历虚拟文件系统中共享目录的所有目录项,遍历时查询每个目录项对应的目录项属性存储至所述目录项数组中,获取目录项关系写入所述目录项结构体,构建形成所述目录项缓存层,以及遍历时获取目录项标识信息与目录项的文件属性元数据按照对应关系存储至所述文件属性数据库,构建形成所述文件属性缓存层。
进一步的,步骤S22中每次遍历目录项时,先基于目录项的信息构建所述目录项结构体,并存入所述目录项数组中;存入所述目录项数组后,将遍历操作时获取的当前目录项的父目录值、子目录项链表的表头值、在子目录项链表的位置值写入所述目录项结构体对应的数据参数,构建形成所述目录项缓存层;使用所述目录项标识信息作为key、以目录项的文件属性值元数据作为value,组成k-v键值对的形式,插入到所述文件属性数据库中,完成所述文件属性缓存层的构建。
进一步的,所述存入所述目录项数组中时,存储的位置由散列函数计算得到,所述散列函数的输入为当前目录项中的目录项标识信息,输出为数组下标。
进一步的,所述步骤S2后还包括数据检索步骤S3,步骤包括:当接收到对存储节点的元数据请求操作时,根据接收到的请求类型以及目录标识信息检索所述目录项缓存层和/或所述文件属性缓存层;当接收到与目录项相关的请求操作时,根据接收到的所述目录项标识信息获取目的目录项元数据在目录项缓存层中的内存地址,按照获取的地址返回目的目录项元数据;如果同时需要查询当前目录项相关的父目录项或子目录项信息,遍历查询到的目录项元数据内的子目录链表,得到所有子目录项元数据;如果同时需要查询文件属性缓存层数据,获取当前在所述目录项缓存层检索到的目录项标识并作为索引,索引到所述文件属性缓存层查询对应的目标数据。
进一步的,所述遍历查询到的目录项元数据内的子目录链表时,具体通过目录项结构体中的父目录值、子目录项链表的表头值和在子目录项链表的位置值遍历所述子目录链表,以获得所述所有子目录项元数据。
进一步的,所述步骤S3中,通过将接收到的目录项标识信息作为输入,使用预设散列函数计算出哈希值,通过哈希表获取所述目录项元数据在目录项缓存层中的内存地址。
一种用于无中心分布式文件系统的元数据分层缓存装置,包括:
分层缓存结构,包括为无中心分布式文件系统中各存储节点分层设置的目录项缓存层、文件属性缓存层,所述目录项缓存层用于缓存目录项相关的元数据,所述文件属性缓存层用于缓存文件属性相关的元数据;
数据分层存储模块,用于查询虚拟文件系统中每个目录项对应的目录项元数据、目录项关系、目录项标识信息以及文件属性元数据,将查询得到的目录项元数据以及目录项关系存入所述目录项缓存层,所述目录项关系为目录项元数据与目录项之间的关系,将查询得到的所述目录项标识信息以及文件属性元数据按照对应关系存入所述文件属性缓存层中。
进一步的,还包括与所述数据分层存储模块连接的数据检索模块,用于当接收到对存储节点的元数据请求操作时,根据请求类型以及目录标识信息检索所述目录项缓存层和/或所述文件属性缓存层;当接收到与目录项相关的请求操作时,根据接收到的所述目录项标识信息获取目的目录项元数据在目录项缓存层中的内存地址,按照获取的地址返回目的目录项元数据;如果同时需要查询当前目录项相关的父目录项或子目录项信息,遍历查询到的目录项元数据内的子目录链表,得到所有子目录项元数据;如果同时需要查询文件属性缓存层数据,获取当前在所述目录项缓存层检索到的目录项标识并作为索引,索引到所述文件属性缓存层查询对应的目标数据。
与现有技术相比,本发明的优点在于:
1、本发明通过在存储节点建立局部元数据缓存,按照元数据类型构建分层缓存结构,同时在元数据存储时采用分层存储方式,依据元数据的类型以及层级关系,将目录项元数据以及目录项关系存入目录项缓存层,将目录项标识信息以及文件属性元数据按对应关系存入文件属性缓存层,基于该分层存储方式,可以避免所有元数据统一存储在同一硬盘中而造成请求阻塞,且当客户端需要查询元数据时,可以依据对应关系快速检索到所需的元数据,从而将客户端对存储节点的元数据请求操作转换为对分层缓存的快速检索,有效改善元数据操作的性能。
2、本发明通过结合分层缓存结构以及元数据间的对应关系对元数据进行分层缓存,能够在不影响无中心分布式文件系统架构的前提条件下,提高存储节点对客户端元数据请求的处理速度,合理的优化元数据请求路径,从而能够有效提高元数据请求速度,提升无中心分布式文件系统的性能。
3、本发明通过将目录项相关信息存入内存中,将文件属性相关信息存入快速硬盘设备中,不仅可以让元数据操作不再访问缓慢的磁盘IO,而且可以规避目录项元数据请求和文件属性元数据请求之间的相互影响,提升元数据检索的整体性能。
4、本发明进一步在数据分层缓存时,通过在遍历目录项时将目录项的父目录值、子目录项链表的表头值、在子目录项链表的位置值写入目录项结构体中以构建目录项缓存层,当客户端需要查询元数据时,通过目录项缓存层中目录项信息,可以快速返回所有相关的目录,而无需频繁的通过哈希计算来逐个进行检索,可以进一步提高数据请求效率,提高元数据操作性能。
附图说明
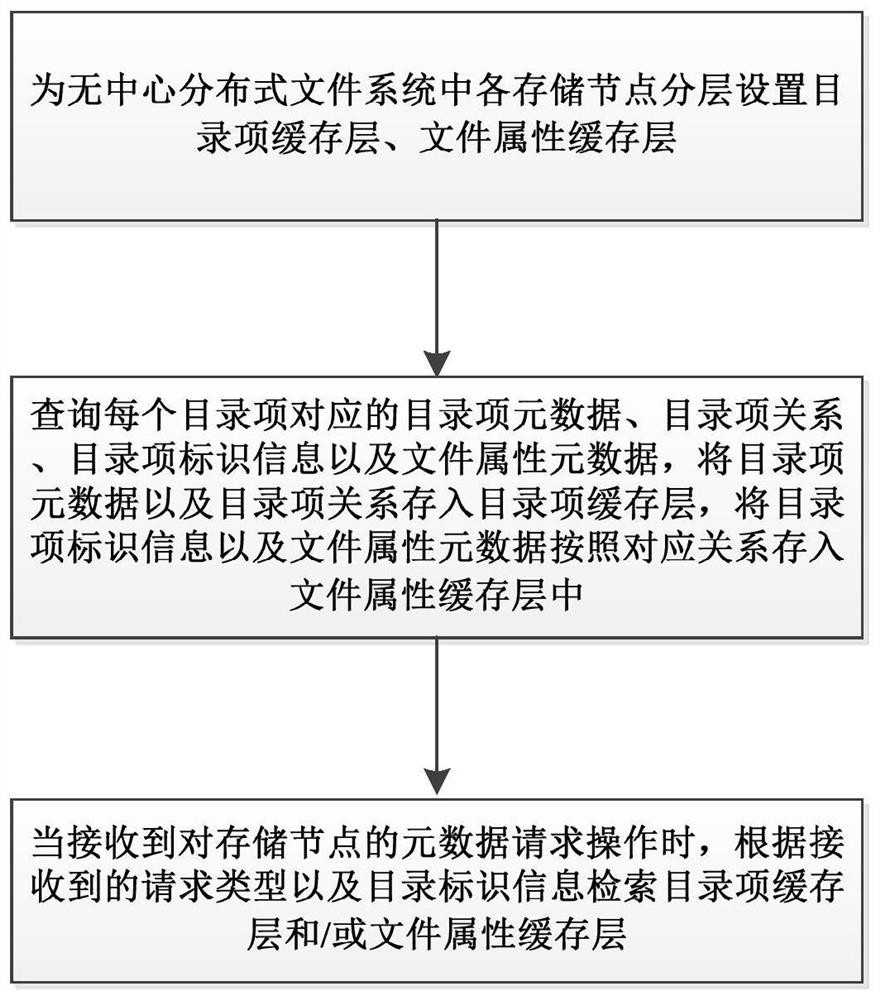
图1是本实施例无中心分布式文件系统中元数据分层缓存方法的实现流程示意图。
图2是本实施例分层缓存在无中心分布式文件系统中的位置原理示意图。
图3是本实施例中构建分层缓存的原理示意图。
图4是虚拟文件系统中目录项与文件属性的对象转化原理示意图。
图5是本实施例中基于分层缓存结构处理元数据请求的实现流程示意图。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
如图1所示,本实施例无中心分布式文件系统中元数据分层缓存方法的步骤包括:
步骤S1.分层缓存构建:为无中心分布式文件系统中各存储节点分层设置目录项缓存层、文件属性缓存层,目录项缓存层用于缓存目录项相关的元数据,文件属性缓存层用于缓存文件属性相关的元数据;
步骤S2.数据分层存储:查询虚拟文件系统中每个目录项对应的目录项元数据、目录项关系、目录项标识信息以及文件属性元数据,将查询得到的目录项元数据以及目录项关系存入目录项缓存层,目录项关系为目录项元数据与目录项之间的关系,将查询得到的目录项标识信息以及文件属性元数据按照对应关系存入文件属性缓存层中。
本实施例通过在存储节点建立局部元数据缓存,按照元数据类型构建分层缓存结构以分层存储目录项相关的元数据、文件属性相关的元数据,同时在元数据存储时采用分层存储方式,依据元数据的类型以及层级关系,将目录项元数据以及目录项关系存入目录项缓存层,将目录项标识信息以及文件属性元数据按对应关系存入文件属性缓存层。基于该分层存储方式,可以避免所有元数据统一存储在同一硬盘中而造成请求阻塞,且当客户端需要查询元数据时,可以依据对应关系快速检索到所需的元数据,从而将客户端对存储节点的元数据请求操作转换为对分层缓存的快速检索,有效改善元数据操作的性能。
本实施例具体在虚拟文件系统(Vitual File System,VFS)上建立元数据分层缓存,分层缓存在无中心分布式文件系统中的位置如图2所示,其中MetadataCache层即为分层缓存在无中心分布式文件系统中的位置。
在分布式存储系统中,每个存储节点均存在多个本地文件系统,本地文件系统使用之前都需要构建对应的虚拟文件系统。虚拟文件系统具体由文件系统类型、超级块、inode、dentry和vfsmount构成,其中dentry存储某个文件系统对象在文件系统树中的位置信息,inode保存文件系统对象的一般元数据,通过各接口完成对象关系之间的映射。
本实施例根据文件元数据的类型将其分为目录项元数据(dentry)和文件属性元数据(inode)两类,对应的建立目录项缓存层和文件属性缓存层。考虑目录项dentry相互之间的耦合关系较深(父子目录和同级目录)、数据量较小的特点,本实施例具体在内存中建立目录项缓存层。考虑各文件之间耦合关系较浅、数据量较大的特点,本实施例采用k-v键值对的形式在SSD等快速存储介质中建立文件属性缓存层。
本实施例中构建的分层缓存结构如图3所示,基于该分层缓存结构,可以将客户端对存储节点的元数据请求操作转换为对分层缓存的检索,将目录项相关信息存入内存中、文件属性相关信息存入SSD等快速硬盘设备,不仅可以让元数据操作不再访问缓慢的磁盘IO,而且可以规避目录项元数据请求和文件属性元数据请求之间的相互影响,提升元数据检索的整体性能。
可以理解的是,分层缓存结构的存储形式当然也可以根据实际需求采用其他方式,如将目录项相关信息、文件属性相关信息同时存入内存中不同地址,或同时存入硬盘设备中不同空间等。
本实施例中步骤S2的步骤包括:
步骤S21.定义目录项结构体以用于存储目录项关系;定义用于存储目录项结构体的数组的目录项数组,以及定义用于存储目录项文件属性的文件属性数据库;
步骤S22.遍历虚拟文件系统中共享目录的所有目录项,遍历时查询每个目录项对应的目录项属性存储至目录项数组中,获取目录项关系写入目录项结构体,构建形成目录项缓存层,以及遍历时获取目录项标识信息与目录项的文件属性元数据按照对应关系存储至文件属性数据库,构建形成文件属性缓存层。
虚拟文件系统系统中目录项关系分为父子、同级关系,通过目录项属性中的d_parent、d_child、d_subdir值进行保存。本实施例先定义目录项结构体,用以存储目录项元数据、目录项之间的关系(父子关系与同级关系),并提前申请一块内存空间作为存储目录项结构体的数组,用于构建目录项缓存层;同时选择轻便型数据库leveldb对目录项文件属性进行存储,构建文件属性缓存层。
本实施例上述步骤S22具体可采用深度优先算法(Depth First Search,DFS)从共享目录根目录开始遍历所有目录项。当然也可以根据实际需求采用其他的方式遍历各目录项。遍历过程中,使用操作系统提供的文件系统接口API,对每个目录项查询对应的目录项属性和文件属性元数据,处理后存入目录项缓存层和文件属性缓存层。
本实施例步骤S22中每次遍历目录项时,具体先基于目录项的信息构建目录项结构体,并存入目录项数组中;存入目录项数组后,将遍历操作时获取的当前目录项的父目录值d_parent、子目录项链表的表头值d_subdirs、在子目录项链表的位置值d_child写入目录项结构体对应的数据参数,d_child值用于链入父目录d_parent下属的d_child链表,通过d_parent值、d_subdirs值、d_child值共同实现目录关系的构建,从而构建形成目录项缓存层;使用目录项标识信息作为key、以目录项的文件属性值元数据作为value,组成k-v键值对的形式,插入到文件属性数据库中,完成文件属性缓存层的构建。基于上述目录关系的构建,如果需要返回某目录项的下属子目录项链表的目录项(所有子目录项,可以通过目录项结构中的d_subdir值找到子链表表头,然后通过d_child遍历链表快速返回所有的子目录项。
在实际应用中,可能需要获取相关的所有目录项,而不仅是某个单一的目录项。本实施例在分层缓存结构的基础上,对元数据进行分层缓存时,通过由d_parent值、d_subdirs值、d_child值共同构建目录关系,当对元数据进行请求操作时,由目录项缓存层中上述目录项信息,可以快速返回所有相关的目录,而无需频繁通过哈希计算来逐个进行检索,可以有效提高元数据处理速度,提高系统的元数据操作性能。
上述存入目录项数组中时,存储的位置具体由散列函数计算得到,散列函数的输入为当前目录项中的目录项标识信息,输出为数组下标。
在虚拟文件系统中,使用目录项构造目录项树,通过目录项接口(d_parent、d_child、d_subdirs操作)可以查找到目录项在文件系统树中与其相邻目录项的位置,通过文件属性接口(d_inode、i_dentry)可以进行目录项dentry和文件属性inode之间的双向查找,LINUX系统中虚拟文件系统vfs目录项与文件属性的相互关系如图4所示,其中dentry以及inode为分层结构的组织对象,对应为目录项值和文件属性值。
在具体应用实施例中,上述步骤S2的详细步骤为:
步骤S21:
(1)定义目录项结构体
定义目录项结构体用以存储目录项元数据、目录项之间的关系(父子关系与同级关系)。
(2)定义目录项数组和文件属性数据库
提前申请一块内存空间作为存储目录项结构体的数组,用于构建目录项缓存层;同时选择轻便型数据库leveldb对目录项文件属性进行存储,构建文件属性缓存层。
(3)构建目录项缓存层和文件属性缓存层
采用深度优先算法从共享目录根目录开始遍历整个目录;遍历过程中,使用操作系统提供的文件系统接口API,对每个目录项查询对应的目录项属性和文件属性元数据,处理后存入目录项缓存层和文件属性缓存层。
步骤S22:
(1)目录项缓存层
a.插入目录项
遍历到某个具体的目录项时,首先基于当前目录项的信息构建目录项结构体,并存入数组中。存储的位置(即数组下标)由预先构造的散列函数计算得到,散列函数的输入为该目录项中的特定标识,输出为数组下标。如果出现重复的散列函数计算结果,使用拉链法解决冲突。
b.存储目录项关系
对于步骤a中正在处理的目录项,在插入数组后,将遍历操作时获取的该目录项的父目录(d_parent)值、子目录项链表的表头(d_subdirs)值,写入目录项结构体对应的数据参数。
(2)文件属性缓存层
将步骤a中正在处理的目录项,使用目录项标识信息作为key,,以目录项的文件属性值元数据通过序列化处理成字符串的形式作为value,组成k-v键值对的形式,插入到数据库中完成文件属性缓存层的构建。
上述遍历结束后,基于分层缓存结构,对于客户端发送的元数据请求再进行元数据请求重定向。
本实施例步骤S2后还包括数据检索步骤S3,步骤包括:当接收到对存储节点的元数据请求操作时,根据接收到的请求类型以及目录标识信息检索目录项缓存层和/或文件属性缓存层;当接收到与目录项相关的请求操作时,根据接收到的目录项标识信息获取目的目录项元数据在目录项缓存层中的内存地址,按照获取的地址返回目的目录项元数据;如果同时需要查询当前目录项相关的父目录项或子目录项信息,遍历查询到的目录项元数据内的子目录链表,得到所有子目录项元数据;如果同时需要查询文件属性缓存层数据,获取当前在目录项缓存层检索到的目录项标识并作为索引,索引到文件属性缓存层查询对应的目标数据。
本实施例中,上述遍历查询到的目录项元数据内的子目录链表时,具体通过目录项结构体中的父目录值、子目录项链表的表头值和在子目录项链表的位置值遍历子目录链表,以获得所有子目录项元数据。具体在分层缓存构建时通过d_parent值、d_subdirs值、d_child值共同实现目录关系的构建,当接收到与目录项相关的请求操作时,返回目的目录项元数据后,如果同时需要返回目的目录项的下属子目录项链表的目录项(所有子目录项),则通过目录项结构中的d_subdir值找到子链表表头,然后通过d_child遍历链表快速返回所有的子目录项,可以快速的返回所有所需的子目录项。
本实施例通过按照对应关系分层存储元数据后,当接收到对元数据的请求操作时,根据请求类型以及标识确定对应的缓存内检索路径,将客户端对存储节点的元数据请求操作转换为对分层缓存的快速检索可以依据分层缓存,快速检索出所需检索的元数据,有效提高元数据请求的效率,从而提高请求操作的性能。
本实施例步骤S3中,上述具体通过将接收到的目录项标识信息作为输入,使用预设散列函数计算出哈希值,通过哈希表获取目录项元数据在目录项缓存层中的内存地址。
如图5所示,本实施例构建完成目录项缓存层和文件属性缓存层后,当接收到元数据请求时,若需要获取目录项缓存层目录项信息,进入目录项缓存层查询目录项信息,当需要查询文件属性元数据,则进入文件属性缓存层查询目录项属性,返回最终检索数据结果。
在具体应用实施例中,待目录项缓存层和文件属性缓存层构建完毕后,将客户端发来的元数据请求进行分类,如分为仅目录项相关、仅文件属性相关、目录项和元数据属性都相关三类。针对服务端发来的检索请求,先判断目标元数据的类型,如果是仅目录项相关,通过传入的目录项标识信息作为输入,通过预设的散列函数计算出哈希值,基于哈希表获取目录项信息在目录项缓存层中的内存地址,即可返回待查询目录项信息;如果进一步需要查询目的目录项的子目录项,遍历查询到的目录项元数据内的子目录链表,即可获得所有子目录项信息;如果同时需要查询文件属性缓存层数据,则根据目录项缓存层检索到的目录项标识作为索引,索引到文件属性缓存层查询对应的目标数据,快速检索出所需的目录属性、文件属性元数据。
本实施例用于无中心分布式文件系统的元数据分层缓存装置包括:
分层缓存结构,包括为无中心分布式文件系统中各存储节点分层设置的目录项缓存层、文件属性缓存层,目录项缓存层用于缓存目录项相关的元数据,文件属性缓存层用于缓存文件属性相关的元数据;
数据分层存储模块,用于查询虚拟文件系统中每个目录项对应的目录项元数据、目录项关系、目录项标识信息以及文件属性元数据,将查询得到的目录项元数据以及目录项关系存入目录项缓存层,目录项关系为目录项元数据与目录项之间的关系,将查询得到的目录项标识信息以及文件属性元数据按照对应关系存入文件属性缓存层中。
上述目录项缓存层具体设置在内存中,文件属性缓存层设置在快速存储介质中。
本实施例中,数据分层存储模块包括:
定义单元,用于定义目录项结构体以用于存储目录项关系;定义用于存储所述目录项结构体的数组的目录项数组,以及定义用于存储目录项文件属性的文件属性数据库;
遍历单元,用于遍历虚拟文件系统中共享目录的所有目录项,遍历时查询每个目录项对应的目录项属性存储至所述目录项数组中,获取目录项关系写入所述目录项结构体,构建形成所述目录项缓存层,以及遍历时获取目录项标识信息与目录项的文件属性元数据按照对应关系存储至所述文件属性数据库,构建形成所述文件属性缓存层。
本实施例中,还包括与数据分层存储模块连接的数据检索模块,用于当接收到对存储节点的元数据请求操作时,根据请求类型以及目录标识信息检索目录项缓存层和/或文件属性缓存层;当接收到与目录项相关的请求操作时,根据接收到的目录项标识信息获取目的目录项元数据在目录项缓存层中的内存地址,按照获取的地址返回目的目录项元数据;如果需要查询目的目录项的子目录项时,遍历查询到的目录项元数据内的子目录链表,得到所有子目录项元数据;如果同时需要查询文件属性缓存层数据,获取当前在目录项缓存层检索到的目录项标识并作为索引,索引到文件属性缓存层查询对应的目标数据。
本实施例用于无中心分布式文件系统的元数据分层缓存装置与上述用于无中心分布式文件系统的元数据分层缓存方法对应,具体实现原理如上所述,在此不再一一赘述。
本发明分层缓存方法,通过结合对应关系以及分层缓存结构对元数据进行分层缓存,能够在不影响无中心分布式文件系统架构的前提条件下,提高存储节点对客户端元数据请求的处理速度,合理的优化元数据请求路径,从而能够有效提高元数据请求速度,提升无中心分布式文件系统的性能。
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 用于无中心分布式文件系统的元数据分层缓存方法及装置
- 用于无中心分布式文件系统的元数据分层缓存方法及装置