一种免标注的特定说话人语音合成方法及装置
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及语音合成技术领域,具体涉及一种免标注的特定说话人语音合成方法及装置。
背景技术
语音合成技术,即将输入的文字信息转化为可听的声音信息,合成的声音保真度越高越受到大家的青睐。
随着业界语音技术的不断突破以及近年来人们认知水平和需求的提高,大家对语音合成技术提出了越来越多的挑战,例如用户希望合成的语音要听起来像某个特定说话人发出的声音,还要便捷地增添多个其他特定说话人的发音。
近年来,端到端的TTS系统实现了媲美人声的效果,已经成为了主流的语音合成系统框架,一般来说,端到端的TTS系统可以分为两个步骤:1)端到端的mel-spectrogram预测网络,该网络将高质量的<文本,mel-spectrogram>数据对作为网络的输入输出,通过基于注意力(attention)机制的序列到序列(seq2seq)的网络模型来学习对齐;2)声码器(vocoder)模型,将预测的mel-spectrogram高质量地恢复成语音。
上述所说的声码器模型的训练只需要高保真度的语音,并不需要任何的标注信息,然而,mel-spectrogram预测网络的训练要求一定数量的高质量的<文本,mel-spectrogram>数据对,而语音标注价格昂贵并且收集也很耗时,效率低,以至于合成特定说话人的语音就显得不够便捷高效。
正因如此,端到端的TTS系统对语音标注的需求限制了语音合成在无标注资源下的应用。
对于端到端的TTS系统,即使拥有了大量人工标注的样本数据,那也可能存在人为的标注错误造成数据质量不高,从而影响合成语音质量的问题。
发明内容
本发明的目的是针对现有技术存在的不足,提供一种免标注的特定说话人语音合成方法及装置。
为实现上述目的,在第一方面,本发明提供了一种免标注的特定说话人语音合成方法,包括:
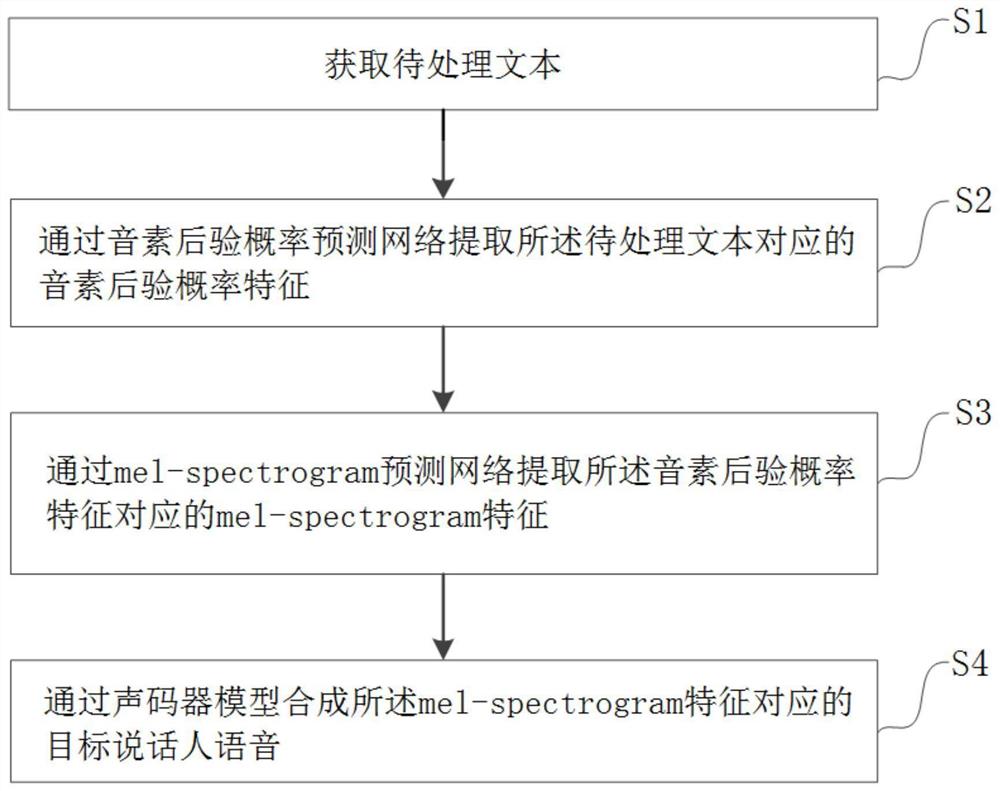
步骤S1:获取待处理文本;
步骤S2:通过音素后验概率预测网络提取所述待处理文本对应的音素后验概率特征;
步骤S3:通过mel-spectrogram预测网络提取所述音素后验概率特征对应的mel-spectrogram特征;
步骤S4:通过声码器模型合成所述mel-spectrogram特征对应的目标说话人语音。
进一步的,所述音素后验概率预测网络通过以下方式训练获得:
提取无关说话人的有标注语音的mel-spectrogram特征;
将所述无关说话人的mel-spectrogram特征输入到语音识别器,所述语音识别器输出所述无关说话人的mel-spectrogram特征对应的音素后验概率特征,所述语音识别器根据已有的语料样本预先生成;
基于每一条无关说话人的语音数据的标注文本和音素后验概率特征,对所述音素后验概率预测网络进行训练。
进一步的,所述mel-spectrogram预测网络通过以下方式训练获得:
提取目标说话人的无标注语音的mel-spectrogram特征;
将所述目标说话人的mel-spectrogram特征输入到语音识别器,输出所述目标说话人的mel-spectrogram特征对应的音素后验概率特征;
基于每一条目标说话人的无标注语音数据的音素后验概率特征和mel-spectrogram特征,对所述mel-spectrogram预测网络进行训练。
进一步的,所述声码器模型通过以下方式训练获得:
获取预先生成的通过大量语料训练的无关说话人的WaveGlow模型;
提取目标说话人的无标注语音的mel-spectrogram特征;
基于每一条目标说话人的无标注语音数据的mel-spectrogram特征和语音,对所述无关说话人的WaveGlow模型进行微调,得到目标说话人声码器模型。
进一步的,所述音素后验概率预测网络基于因子分解时延神经网络结构,以梅尔频率倒谱系数特征为输入,输出节点是经过状态树绑定的三音子状态,最后一个全连接层输出的后验概率便是音素后验概率特征。
进一步的,所述mel-spectrogram预测网络采用K组一维卷积核进行卷积,第h组卷积核的宽度是h,其中,h=1,2,…,K,接着将各组卷积输出堆叠起来,在时间轴上进行最大池化,然后把得到的结果序列传给几个定长一维卷积,并将卷积的输出通过冗余连接与原始的输入相加,然后通过高速公路网络和双向门控循环单元充分提取序列的高层信息和上下文信息,最后通过全连接层将这些高层特征连接到输出层mel-spectrogram,即得到待处理文本对应的mel-spectrogram特征;
当有多个目标说话人时,在mel-spectrogram预测网络基础上,将每个说话人都表示为one-hot向量,然后映射为连续的embedding向量;接着采用几层带Relu的FC层将embedding向量进行非线性映射,然后在输入高速公路网络前与卷积的输出、原始的输入相加,即可提取多说话人音素后验概率特征对应的mel-spectrogram特征。
在第二方面,本发明提供了一种免标注的特定说话人语音合成装置,包括:
获取模块,用以获取待处理文本;
音素后验概率特征生成模块,用以通过音素后验概率预测网络提取所述待处理文本对应的音素后验概率特征;
mel-spectrogram特征生成模块,用以通过mel-spectrogram预测网络提取所述音素后验概率特征对应的mel-spectrogram特征;
目标说话人语音合成模块,用以通过声码器模型合成所述mel-spectrogram特征对应的目标说话人语音。
进一步的,所述音素后验概率预测网络通过以下方式训练获得:
提取无关说话人的有标注语音的mel-spectrogram特征;
将所述无关说话人的mel-spectrogram特征输入到所述语音识别器,所述语音识别器输出所述无关说话人的mel-spectrogram特征对应的音素后验概率特征,所述语音识别器根据已有的语料样本预先生成;
基于每一条无关说话人的语音数据的标注文本和音素后验概率特征,对所述音素后验概率预测网络进行训练。
进一步的,所述mel-spectrogram预测网络通过以下方式训练获得:
提取目标说话人的无标注语音的mel-spectrogram特征;
将所述目标说话人的mel-spectrogram特征输入到语音识别器,输出所述目标说话人的mel-spectrogram特征对应的音素后验概率特征;
基于每一条目标说话人的无标注语音数据的音素后验概率特征和mel-spectrogram特征,对所述mel-spectrogram预测网络进行训练。
进一步的,所述声码器模型通过以下方式训练获得:
获取预先生成的通过大量语料训练的无关说话人的WaveGlow模型;
提取目标说话人的无标注语音的mel-spectrogram特征;
基于每一条目标说话人的无标注语音数据的mel-spectrogram特征和语音,对所述无关说话人的WaveGlow模型进行微调,得到目标说话人声码器模型。
有益效果:本发明不需要目标语音的文本标注信息,从而实现目标语音无标注的语音合成;本发明基于音素后验概率特征搭建起文本和mel-spectrogram之间的桥梁,对内容信息和音色信息分开建模;由于音素后验概率预测网络和语音识别器的训练所采用的数据为开源的有标注语音数据及少量目标说话人的无标注语音数据,从而极大的减少了人力、时间和资金成本。
附图说明
图1是本发明实施例的免标注的特定说话人语音合成方法的流程示意图;
图2是现有技术中的端到端的TTS系统的流程示意图;
图3是TPMW网络结构的系统的流程示意图;
图4是本发明实施例的免标注的特定说话人语音合成装置的示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,本实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
如图1所示,本发明实施例提供了一种免标注的特定说话人语音合成方法,包括:
步骤S1:获取待处理文本。待处理文本即为待合成特定说话人的语音内容,语音内容可以为中文的字词、短语、句子或段落。
步骤S2:通过音素后验概率预测网络提取待处理文本对应的音素后验概率特征。本发明实例中音素后验概率特征(PPGs)是连接文本和mel-spectrogram的桥梁,是内容信息的矢量表示,它的存在可以将既包含内容信息又包含音色信息的mel-spectrogram的预测分为两个步骤,从而分别对内容信息和音色信息进行建模。其中,音素后验概率预测网络基于因子分解时延神经网络结构(Factorized Time Delay Neural Networks,TDNN-F),以梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)特征为输入,输出节点是经过状态树绑定的三音子状态(senones),最后一个全连接层输出的后验概率便是音素后验概率特征(PPGs)。TDNN-F作为音素后验概率特征(PPGs)提取器有以下优势:(1)将权重矩阵分解为两个矩阵,其中一个为半正交矩阵,降低了参数的同时保持了很好的建模能力;(2)增加了跳层连接(Skip Connection),缓解了梯度消失;(3)通过dropout防止过拟合;
如图2所示,在现有的端到端的TTS系统中,采用端到端的mel-spectrogram预测网络(Text2Mel)网络结构直接将文本映射为频谱,通过tacotron2网络基于<文本,mel-spectrogram>数据对进行训练。
如图3所示,本发明实例中提出的TPMW(Text-PPGs-Mel-Wave)网络,基于attention的seq2seq结构tacotron2来预测音素后验概率特征(PPGs),采用音素后验概率预测网络(Text2PPGs)基于以<文本,PPGs>数据对进行训练,以音素后验概率特征(PPGs)作为桥梁,将内容信息和音色信息分开建模。
其中,音素后验概率特征(PPGs)严格来说,不是绝对说话人无关的,不同说话人的音素后验概率特征(PPGs)的分布有所不同。音素后验概率特征(PPGs)仅去除了说话人音色信息,却依旧保留了内容信息,也包括了风格、语气、语调、发音时长等其他信息。本发明实例主要考虑的是语音的内容信息和说话人的音色信息,因此所描述的音素后验概率特征(PPGs)只包含内容信息。
步骤S3:通过mel-spectrogram预测网络提取音素后验概率特征对应的mel-spectrogram特征。其中,mel-spectrogram预测网络(PPGs2Mel)由目标说话人的无标注语音mel-spectrogram特征和目标说话人的mel-spectrogram特征对应的音素后验概率特征(PPGs)训练得到;目标说话人的mel-spectrogram特征对应的音素后验概率特征(PPGs)由目标说话人的无标注语音mel-spectrogram特征通过语音识别器得到;音素后验概率特征对应的mel-spectrogram特征便是待处理文本对应的mel-spectrogram特征,用于表示待处理文本的内容信息和音色信息。
本发明实施例的mel-spectrogram预测网络采用K组一维卷积核进行卷积,第h组卷积核的宽度是h,其中,h=1,2,…,K,K为大于2的自然数,不同宽度的卷积有利于对PPGs的局部信息和上下文信息建模,接着将各组卷积输出堆叠起来,在时间轴上进行最大池化(Max Pooling),然后把得到的结果序列传给几个定长一维卷积,并将卷积的输出通过冗余连接(residual connection)与原始的输入相加,然后通过高速公路网络(HighwayNetwork)和双向门控循环单元(gated recurrent unit,GRU)充分提取序列的高层信息和上下文信息,最后通过全连接层(Fully Connected Layer,FC)将这些高层特征连接到输出层mel-spectrogram,即得到待处理文本对应的mel-spectrogram特征。当有多个目标说话人时,需在mel-spectrogram预测网络基础上,将每个说话人都表示为one-hot向量,然后映射为连续的embedding向量;接着采用几层带Relu的FC层将embedding向量进行非线性映射,然后在输入高速公路网络前与卷积的输出、原始的输入相加,即可提取多说话人音素后验概率特征对应的mel-spectrogram特征。
步骤S4:通过声码器模型合成mel-spectrogram特征对应的目标说话人语音。本发明通过WaveGlow模型将mel-spectrogram恢复出高质量的语音,基于目标说话人的无标注语音数据较少的情况,采用一种说话人自适应的方法。本发明实例的声码器模型(Vocoder)通过以下方式训练获得:首先训练一个有大量语料的无关说话人的WaveGlow模型;然后以这个训练好的模型作为初始化模型,用少量的目标说话人的数据进行微调(fine-tune),得到目标说话人的WaveGlow模型,最后使用WaveGlow模型将mel-spectrogram快速的恢复出高质量的语音。
本发明实施例的音素后验概率预测网络通过以下方式训练获得:
提取无关说话人的有标注语音的mel-spectrogram特征。
将无关说话人的mel-spectrogram特征输入到语音识别器,语音识别器输出无关说话人的mel-spectrogram特征对应的音素后验概率特征,语音识别器根据已有的语料样本预先生成。
基于每一条无关说话人的语音数据的标注文本和音素后验概率特征,对音素后验概率预测网络进行训练。
本发明实施例的mel-spectrogram预测网络通过以下方式训练获得:
提取目标说话人的无标注语音的mel-spectrogram特征。
将目标说话人的mel-spectrogram特征输入到语音识别器,输出目标说话人的mel-spectrogram特征对应的音素后验概率特征。
基于每一条目标说话人的无标注语音数据的音素后验概率特征和mel-spectrogram特征,对mel-spectrogram预测网络进行训练。
如图4所示,基于以上实施例,本领域技术人员可以理解,本发明还提供了一种免标注的特定说话人语音合成装置,包括:获取模块201、音素后验概率特征生成模块202、mel-spectrogram特征生成模块203和目标说话人语音合成模块204。
其中,获取模块201用以获取待处理文本。待处理文本即为待合成特定说话人的语音内容,语音内容可以为中文的字词、短语、句子或段落。
音素后验概率特征生成模块202用以通过音素后验概率预测网络提取待处理文本对应的音素后验概率特征。
本发明实施例的音素后验概率预测网络基于因子分解时延神经网络结构(Factorized Time Delay Neural Networks,TDNN-F),以梅尔频率倒谱系数(MelFrequency Cepstrum Coefficient,MFCC)特征为输入,输出节点是经过状态树绑定的三音子状态(senones),最后一个全连接层输出的后验概率便是音素后验概率特征(PPGs)。TDNN-F作为音素后验概率特征(PPGs)提取器有以下优势:(1)将权重矩阵分解为两个矩阵,其中一个为半正交矩阵,降低了参数的同时保持了很好的建模能力;(2)增加了跳层连接(Skip Connection),缓解了梯度消失;(3)通过dropout防止过拟合。
本发明实施例的音素后验概率预测网络通过以下方式训练获得:
提取无关说话人的有标注语音的mel-spectrogram特征。
将无关说话人的mel-spectrogram特征输入到语音识别器,语音识别器输出无关说话人的mel-spectrogram特征对应的音素后验概率特征,语音识别器根据已有的语料样本预先生成。
基于每一条无关说话人的语音数据的标注文本和音素后验概率特征,对音素后验概率预测网络进行训练。
mel-spectrogram特征生成模块203用以通过mel-spectrogram预测网络提取音素后验概率特征对应的mel-spectrogram特征。
本发明实施例的mel-spectrogram预测网络采用K组一维卷积核进行卷积,第h组卷积核的宽度是h,其中,h=1,2,…,K,K为大于2的自然数,接着将各组卷积输出堆叠起来,在时间轴上进行最大池化,然后把得到的结果序列传给几个定长一维卷积,并将卷积的输出通过冗余连接与原始的输入相加,然后通过高速公路网络和双向门控循环单元充分提取序列的高层信息和上下文信息,最后通过全连接层将这些高层特征连接到输出层mel-spectrogram,即得到待处理文本对应的mel-spectrogram特征。当有多个目标说话人时,需在mel-spectrogram预测网络基础上,将每个说话人都表示为one-hot向量,然后映射为连续的embedding向量;接着采用几层带Relu的FC层将embedding向量进行非线性映射,然后在输入高速公路网络前与卷积的输出、原始的输入相加,即可提取多说话人音素后验概率特征对应的mel-spectrogram特征。
本发明实施例的mel-spectrogram预测网络通过以下方式训练获得:
提取目标说话人的无标注语音的mel-spectrogram特征。
将目标说话人的mel-spectrogram特征输入到语音识别器,输出目标说话人的mel-spectrogram特征对应的音素后验概率特征。
基于每一条目标说话人的无标注语音数据的音素后验概率特征和mel-spectrogram特征,对mel-spectrogram预测网络进行训练。
目标说话人语音合成模块204用以通过声码器模型合成mel-spectrogram特征对应的目标说话人语音。本发明通过WaveGlow模型将mel-spectrogram恢复出高质量的语音,基于目标说话人的无标注语音数据较少的情况,采用一种说话人自适应的方法。本发明实例的声码器模型(Vocoder)通过以下方式训练获得:首先训练一个有大量语料的无关说话人的WaveGlow模型;然后以这个训练好的模型作为初始化模型,用少量的目标说话人的数据进行微调(fine-tune),得到目标说话人的WaveGlow模型,最后使用WaveGlow模型将mel-spectrogram快速的恢复出高质量的语音。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,其它未具体描述的部分,属于现有技术或公知常识。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种免标注的特定说话人语音合成方法及装置
- 基于单说话人语音合成数据集的声音克隆方法及装置