基于深度学习模型压缩的漏洞检测方法、系统及移动设备
文献发布时间:2023-06-19 11:44:10
技术领域
本发明涉及软件安全检测领域,特别是一种基于深度学习模型压缩的漏洞检测方法、系统及移动设备。
背景技术
随着全球信息化的快速发展,计算机在人们的生活中起着极大的作用。计算机软件作为信息时代的产品形式,已经深入到人民生活、国家经济、军事建设等各个领域。在互联网技术迅猛发展的今天,软件的安全性问题成了目前最为重要的话题。目前,很多软件都存在大大小小的漏洞,不法分子就可以通过软件漏洞去进行网络攻击,造成了用户信息泄露、系统崩溃、人民财产安全等问题,严重威胁了我国网络空间的安全建设,乃至威胁到整个社会、国家的安全与稳定。在软件的完整生命周期中,想要完全避免漏洞缺陷是不可能的,但如何能及时检测出来,避免损失是非常有意义的。因此,对软件漏洞进行快速检测是一项重要的研究内容。
近年来,软件漏洞被攻击利用的事件频发,造成了不可预估的损失,为了能够及时发现漏洞,有效预防,很多团队都在深入研究漏洞检测技术,提供漏洞检测工具及服务。其中,经典的方法是静态漏洞挖掘和动态漏洞挖掘技术。静态漏洞挖掘技术是指不执行目标程序,但对目标程序的语法语义、数据流、控制流等进行分析,同时考虑专家规则,共同挖掘程序中可能存在的漏洞。动态漏洞检测技术是指在执行目标程序的过程中监控其运行时的行为,分析其产生的数据流、控制流、程序状态、执行路径等,准确找到异常发生的地方,从而找出程序的漏洞。通过对程序的源代码进行静态漏洞分析产生的漏洞检测工具如Coverity、Klocwork等,通过动态分析方法进行错误排查的工具如libFuzzer、Radamsa等。在大数据时代,人工智能技术飞速发展,基于机器学习的漏洞检测技术也被相继提出,一些轻量级的漏洞检测工具也应用而生。如VDiscover工具,通过经典的机器学习算法,训练漏洞检测模型,用来预测程序中是都存在漏洞问题。VccFinder工具利用SVM(支持向量机)分类器对软件的异常情况进行标记,在一定程度上使误报率显著降低。
虽然漏洞检测工具层出不穷,但是对于基于机器学习的漏洞检测技术还面临着一些问题。首先,漏洞检测工具的准确率和效率还有待提升;其次,基于深度学习的漏洞检测模型占用空间大,计算复杂度较高,很难部署到资源受限的移动设备上。
发明内容
本发明所要解决的技术问题是,针对现有技术不足,提供一种基于深度学习模型压缩的漏洞检测方法、系统及移动设备,提高漏洞检测的效率和准确率,并且减少检测模型的内存占用和计算复杂度,使模型能够部署到资源受限的移动设备上。
为解决上述技术问题,本发明所采用的技术方案是:一种基于深度学习模型压缩的漏洞检测方法,包括以下步骤:
S1、对数据进行预处理,生成训练数据集和测试数据集;所述数据为灰度图像数据;
S2、利用所述训练数据集训练卷积神经网络,得到预训练模型;
S3、利用麻雀搜索算法压缩所述预训练模型,得到最终的检测模型。
本发明利用灰度图像训练卷积神经网络,利用麻雀搜索算法进行模型压缩,可以使最终的检测模型在准确率不降低的情况下实现模型压缩,减少空间占用,减少计算复杂度,使其能够部署到资源受限的移动设备上。
步骤S1的实现过程包括:
1)将采集到的包含漏洞的二进制文件转化为灰度图像;根据采集到的包含漏洞的二进制文件的漏洞类型、存储路径,生成标签文件;
2)基于所述标签文件和灰度图像,生成hdf5文件,得到训练数据集和测试数据集。
本发明将二进制文件转化为灰度图像用于模型的训练,可以解决训练数据少的问题。
步骤1)的具体实现过程包括:将一个包含漏洞的二进制文件按位读取为一维数组,其中每Mbit的数据作为该数组其中一个元素,所述数据的取值范围为0-255,固定行宽为256,将上述一维数组按照行宽生成一个二维数组,利用cv2库将该二维数据映射为灰度图像。利用B2M算法将二进制文件转化为灰度图像,就可以利用卷积神经网络提取图像纹理特征,进行模型训练。
步骤2)的具体实现过程包括:所述标签文件包括训练标签文件和测试标签文件;所述标签文件的内容以键值对(key,value)的形式存在;对于训练标签文件,key表示包含漏洞的二进制文件映射为灰度图像后的存储路径,value为包含漏洞的二进制文件的漏洞类型编号;对于测试标签文件,key为包含漏洞的二进制文件对应的漏洞类型编号,value为该漏洞类型标号的解释说明。训练标签文件是为对应的数据集打标签,实现模型训练;测试标签文件可以对检测结果的类型进行解释说明,使检测结果一目了然,方便查看。
所述卷积神经网络为VGG16网络模型;所述VGG16网络模型包括N个级联的卷积层,最后一个卷积层与至少一个全连接层连接;所述VGG16网络模型的输入层通道数为1,最后一层输出的分类数量与漏洞类型总数匹配。在进行灰度图像特征提取的过程中,该VGG16网络模型提供了精确有效的特征提取方案。步骤S3的具体实现过程包括:
A)将所述预训练模型的结构表示为X={x
x′
B)利用下式计算剪枝结构的适应度:
C)利用下式更新第t+1次迭代过程中第p只发现者的位置
其中,p∈[1,PN];t为当前迭代数;iter
利用下式更新第t+1次迭代过程中第q只加入者的位置
其中,q∈[PN+1,n];
利用下式更新第t+1次迭代过程中第s只警戒者的位置
其中,s∈[1,SD];
D)经过第t+1次迭代后,计算每个更新各位置后的剪枝结构的适应度值,根据适应度值对剪枝结构进行重新排序,若适应度值最高的剪枝结构的适应度值大于全局最优剪枝结构X′
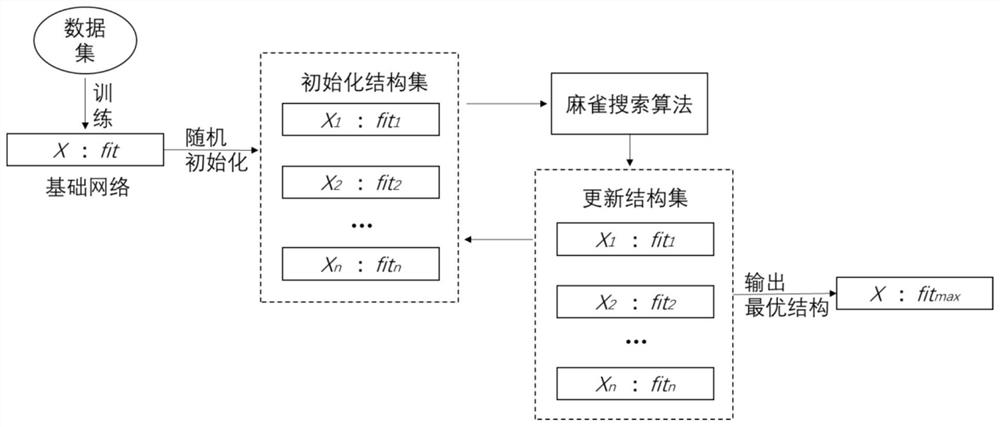
使用麻雀搜索算法搜索模型的最佳通道剪枝结构,实现模型压缩,是一种自动化搜索模型结构的方法,只需要确定每层的通道数,而无需选择重要的通道,可以减少人工干预,避免了基于经验设计的正则化或者重要性来选择通道的方法。麻雀搜索算法在优化问题上很有优势,收敛速度比较快,且稳定性很强,在全局范围内进行搜索的效果比较好,将麻雀搜索算法应用到模型压缩中能够快速得到最终的检测模型。
步骤S3之后,还包括:
S4、使用B2M算法将采集的二进制文件转化为灰度图像;
S5、将该灰度图像作为最终的检测模型的输入,根据输出结果做出预测,并输出所有结果中概率大于80%的预测结果及对应的概率。
通过这种方式,可以对二进制文件可能包含的多种漏洞进行检测,并给出相应的漏洞类型;输出所有结果中概率大于80%的结果,是为了确保准确率。
步骤S5中,根据漏洞编号和文字描述标签文件中的key、value键值对,直接输出漏洞编号对应的文字描述。可以使测试者直接了然的清楚被检测的二进制文件的漏洞编号和漏洞类型。
本发明还提供了一种基于深度学习模型压缩的漏洞检测系统,其包括计算机设备;所述计算机设备被配置或编程为用于执行上述方法的步骤。
作为一个发明构思,本发明还提供了一种移动设备,其内配置漏洞检测模型;所述漏洞检测模型被配置或编程为用于执行上述方法的步骤。
与现有技术相比,本发明所具有的有益效果为:本发明将包含漏洞的二进制文件映射为灰度图像,利用卷积神经网络提取灰度图像纹理特征,通过训练得到预训练模型,然后利用模型压缩的优势,基于麻雀搜索算法找到模型的最佳结构,实现自动化搜索模型结构的压缩方法,从而提高检测模型的准确率和效率,并且能够减少检测模型的空间占用,最终构建了一个面向资源受限的移动设备的高效漏洞检测模型。
附图说明
图1为本发明实施例基于深度学习的高效漏洞检测方法的过程;
图2为本发明实施例将二进制文件映射为灰度图像的过程;
图3为本发明卷积神经网络VGG16模型结构。
具体实施方式
本发明实施例的基于深度学习模型压缩的高效漏洞检测方法主要分为以下四个步骤,过程如图1所示:
第一步:采集数据进行预处理,生成训练数据集和测试数据集;
第二步:模型构建,利用卷积神经网络进行迭代训练;
第三步:将上述训练好的模型作为预训练模型,利用麻雀搜索算法进行模型压缩;
第四步:多次训练,调节参数,使训练达到最佳效果,找到漏洞检测模型的最佳结构。训练完成后,将待检测二进制文件转化为灰度图像,使用训练好的模型数据对其进行漏洞检测。
首先,采集数据进行预处理,生成训练数据集,其主要实施过程如下:
(1)将采集到的包含漏洞的二进制文件利用B2M算法转化为灰度图像。将一个包含漏洞的二进制文件按位读取为一维数组,其中每8bit的数据作为该数组其中一个元素,数据的取值范围为0-255。固定行宽为256,将上述一维数组按照行宽生成一个二维数组,利用cv2库将该二维数据映射为灰度图像,转化为灰度图像的过程如图2;
(2)根据采集到的包含漏洞的二进制文件的漏洞类型、存储路径,生成标签文件。包括训练标签文件和测试标签文件,标签文件的内容以键值对的形式存在(key,value)。对于训练标签文件,key表示该漏洞文件映射为灰度图像后的存储路径,value为该漏洞文件的漏洞类型编号。对于测试标签文件,key为对应的漏洞类型编号,value为该漏洞类型标号的解释说明;
(3)基于标签文件和灰度图像生成hdf5文件,作为深度学习模型的训练数据集和测试数据集。
其次,进行模型构建,利用卷积神经网络进行迭代训练,本发明选用的卷积神经网络为VGG16,其主要实施过程如下:
VGG16网络模型共有16层,如图3所示,前13层为卷积层,在每个卷积层中使用RELU激活函数进行非线性处理,每2个或3个卷积层后,使用最大池化层对卷积层的输出数据进行降维处理。后3层为全连接层,负责对提取的特征进行归一化处理,并在最后一个全连接层后使用Softmax函数进行分类输出。在本发明中,需对VGG16做一些调整:(1)由于训练数据集为灰度图像,只有一个通道,因此设置VGG16输入层的通道数为1;(2)最后一层输出的分类数量需与实际漏洞类型总数一致。
使用pytorch构建VGG16网络:
输入:无
输出:VGG16卷积神经网络
functionVGG16():
1:读取训练数据集,设置图像的宽高为固定值;
2:建立Conv1:使用64个3*3的卷积核进行2次卷积操作,每次卷积操作后都使用Relu激活函数对该次卷积操作的输出结果进行处理;
3:建立池化层1:使用2*2的池化单元对Conv1层的输出结果进行池化操作,采用最大池化的方法,设置步长为2;
4:建立Conv2:使用128个3*3的卷积核进行2次卷积操作,每次卷积操作后都使用Relu激活函数对该次卷积操作的输出结果进行处理;
5:建立池化层2:使用2*2的池化单元对Conv2层的输出结果进行池化操作,采用最大池化的方法,设置步长为2;
6:建立Conv3:使用256个3*3的卷积核进行3次卷积操作,每次卷积操作后都使用Relu激活函数对该次卷积操作的输出结果进行处理;
7:建立池化层3:使用2*2的池化单元对Conv3层的输出结果进行池化操作,采用最大池化的方法,设置步长为2;
8:建立Conv4:使用256个3*3的卷积核进行3次卷积操作,每次卷积操作后都使用Relu激活函数对该次卷积操作的输出结果进行处理;
9:建立池化层4:使用2*2的池化单元对Conv4层的输出结果进行池化操作,采用最大池化的方法,设置步长为2;
10:建立Conv5:使用256个3*3的卷积核进行3次卷积操作,每次卷积操作后都使用Relu激活函数对该次卷积操作的输出结果进行处理;
11:建立池化层5:使用2*2的池化单元对Conv5层的输出结果进行池化操作,采用最大池化的方法,设置步长为2;
12:全连接层1:使用4096个大小为7*7的卷积核对池化层5的输出数据进行卷积操作,完成后,对其进行dropout操作防止过拟合,该层输入的数据大小为1*1*4096;
13:全连接层2:使用4096个大小为1*1的卷积核对全连接层1的输出数据再次进行卷积操作,完成后,对其进行dropout操作防止过拟合,该层输入的数据大小为1*1*4096;
14:全连接层3:使用CLASS_NUM个大小为1*1的卷积核对全连接层2的输出数据进行卷积操作,完成后,使用softmax激活函数对结果进行处理,该步骤的输出结果为CLASS_NUM个float值,表示每种漏洞类型的概率。其中,CLASS_NUM是样本数据中漏洞类型的数量。
建立好卷积神经网络后,进行训练的过程如下:
(1)将第一步中生成的hdf5文件其中90%的数据作为训练数据集,10%的数据作为测试数据集加载进VGG16模型,设置训练数据集的迭代次数、每次训练的数据条数以及在训练过程中使用到的训练数据和验证数据所占比例。
(2)开始进行迭代训练,完成后得到预训练模型。
然后,将上述训练好的模型作为预训练模型,利用麻雀搜索算法搜索模型的最佳结构,确定每层的通道数,来实现模型压缩,具体过程如下:
(1)将上述得到的预训练模型的结构表示为X={x
(2)将预训练模型初始化为n个剪枝结构
x′
(3)计算每一种结构X′
T
(4),在每次迭代过程中,需要更新第1~PN只发现者的位置,计算方法为:
p∈[1,PN],t为当前迭代数,iter
(5)在每次迭代过程中,需要更新第PN+1~n只加入者的位置,计算方法为:
q∈[PN+1,n],
(6)在每次迭代过程中,更新SD只警戒者的位置,计算方法为:
s∈[1,SD],
(7)一轮迭代结束之后,计算每个更新各位置后的剪枝结构的适应度值,根据适应度值对剪枝结构进行重新排序,若适应度值最高的剪枝结构的适应度值大于全局最优剪枝结构X′
最后,使用上述漏洞检测模型对二进制文件进行漏洞挖掘,具体过程如下:
(1)使用B2M算法将二进制文件转化为灰度图像;
(2)将该灰度图像作为最终模型的输入,根据输出结果做出预测,并输出所有结果中概率大于80%的预测结果(漏洞编号)及对应概率。同时,为了方便用户理解,根据漏洞编号和文字描述标签文件中的key、value键值对,直接输出这些漏洞编号对应的文字描述。
本发明的另一实施例还提供了一种基于深度学习模型压缩的漏洞检测系统,其包括计算机设备;所述计算机设备被配置或编程为用于执行上述实施例方法的步骤。
本发明另一实施例还提供了一种移动设备,其内配置漏洞检测模型;所述漏洞检测模型被配置或编程为用于执行上述实施例方法的步骤。
本发明中,计算机设备可以是处理器、上位机等,移动设备可以是手机、平板电脑等。
通过本发明的方法,在Linux系统Ubuntu 18下进行试验,其GPU的型号为NVIDA1650。本实验的样本数据共有5644条,其中共包含58个不同的漏洞类型,在训练的过程中,将90%的数据作为训练数据集,10%的数据作为验证集。在初始训练完成后,将学习到的参数保存为预训练模型,然后加载预训练模型初始化一组结构集,经过麻雀搜索算法进行模型的结构优化,得到最终优化后的漏洞检测模型。在漏洞检测的时候将最终的模型加载进卷积神经网络中。针对该训练模型,使用参与训练的灰度图像文件对其进行正确率测试,其结果如表2所示。
表1使用本发明进行试验的检测结果准确率统计
对压缩前后的模型的通道数和FLOPs数进行比较,在保证精确度不变的情况下,压缩后的模型,通道数比压缩前的模型减少了58.30%,FLOPs数比压缩前的模型减少了69.66%。
相对于现有的漏洞检测技术,本发明改进了传统的基于深度学习的漏洞检测方法准确率和效率低的问题,以及庞大的神经网络模型难以部署到资源受限的移动设备上的问题。将带来以下几方面的优势:
(1)提出一种基于深度学习的漏洞检测方法,该方法将二进制文件转化为灰度图像,采用卷积神经网络对灰度图像样本数据进行特征提取,再进行漏洞检测,能够解决传统基于专家规则的漏洞检测方法不能及时检测潜在漏洞的问题。
(2)采用深度卷积神经网络进行特征提取、漏洞挖掘,能够在一定程度上提高检测模型的准确率。
(3)基于麻雀搜索算法进行模型压缩,实现了对模型结构的优化,提高了漏洞检测模型的检测效率,且减少了庞大的深度学习模型的内存占用。
- 基于深度学习模型压缩的漏洞检测方法、系统及移动设备
- 一种基于深度学习模型优化的XSS漏洞检测方法