一种任务依赖关系更新方法、装置及存储介质
文献发布时间:2023-06-19 11:45:49
技术领域
本说明书实施例涉及大数据处理技术领域,特别涉及一种任务依赖关系更新方法、装置及存储介质。
背景技术
随着大数据的应用,很多数据处理平台会对各种数据进行处理,比如ODPS平台(Open Data Processing Service,开放数据处理服务),该数据平台提供针对TB/PB级数据、实时性要求不高的分布式处理能力,可应用于数据分析、挖掘、商业智能等领域。在数据开发过程中,针对某个数据业务,开发者会将其拆解为一系列的任务部署到数据平台中,该任务是运行在数据平台上的最小调度作业单元。其中,各个任务之间可能存在某种依赖关系,每个任务可以认为是该数据业务中的一个任务节点。
以银行经营的业务为例,在银行业经营分析的任务数量众多,任务关系复杂,互相依赖层层嵌套,任务之间的依赖关系通过预设关系维护。现有调度,为了保证任务执行前必须执行前序加工任务,需要提前设置任务之间的依赖关系,以使各个任务有序地调度执行。
然而,通过提前设置任务之间的依赖关系的方式,一旦这些依赖关系上线,则会固化,不能在非停机状态下自由变动,如果新任务上线影响到存量的依赖关系时,需要停止任务的调度和执行,重新更新依赖关系。
现有的依赖关系的更新方式,导致任务的调度和执行不能24小时×7天运行,每月的投产浪费了跑批时间,并且需要追批,占用集群的时间、资源追平批量,增加了调度服务器、集群的调度负担。
发明内容
本说明书实施例的目的是提供一种任务依赖关系更新方法、装置及存储介质,以解决现有技术中需要停批刷新任务依赖的问题,实现不停机情况下的任务依赖局部更新,提高任务的执行效率。
为解决上述问题,本说明书实施例提供一种任务依赖关系更新方法,所述方法包括:获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
为解决上述问题,本说明书实施例还提供一种任务依赖关系更新装置,所述装置包括:获取模块,用于获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析模块,用于解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;更新模块,用于使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
为解决上述问题,本说明书实施例还提供一种电子设备,包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序以实现:获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
为解决上述问题,本说明书实施例还提供一种计算机可读存储介质,其上存储有计算机指令,所述指令被执行时实现:获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
由以上本说明书实施例提供的技术方案可见,本说明书实施例中,可以获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。本说明书实施例提供的方法,能够解决现有技术中需要停批刷新任务依赖的问题,实现不停机情况下的任务依赖局部更新,提高任务的执行效率。
附图说明
为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本说明书一个场景示例的示意图;
图2为本说明书实施例依赖关系更新的一个示例;
图3为本说明书一个场景示例依赖关系更新的流程图;
图4为本说明书实施例提供一种任务依赖关系更新方法的流程图;
图5为本说明书实施例一种电子设备的功能结构示意图;
图6为本说明书实施例一种任务依赖关系更新装置的功能结构示意图。
具体实施方式
下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书保护的范围。
在一些场景下,处理数据的时候往往都是分成好几个任务步骤来完成一个数据处理流程。多个任务单元之间往往有着强依赖关系,上游任务执行并成功,下游任务才可以执行。比如上游任务结束后拿到A结果,下游任务需结合A结果才能产出B结果,因此下游任务的开始一定是在上游任务成功运行拿到结果之后才可以开始。而为了保证数据处理结果的准确性,就必须要求这些任务按照上下游依赖关系有序、高效的执行。
为了保证任务执行前必须执行前序加工任务,需要提前设置任务之间的依赖关系,以使各个任务有序地调度执行。然而,通过提前设置任务之间的依赖关系的方式,一旦这些依赖关系上线,则会固化,不能在非停机状态下自由变动,如果新任务上线影响到存量的依赖关系时,需要停止任务的调度和执行,重新更新依赖关系。现有的依赖关系的更新方式,导致任务的调度和执行不能24小时×7天运行,每月的投产浪费了跑批时间,并且需要追批,占用集群的时间、资源追平批量,增加了调度服务器、集群的调度负担。
考虑到如果能够将任务之间依赖关系维护在开源关系型数据库中,每个任务只需获取自己的任务依赖和依赖于自己的任务清单,就可以完成批量运行。由于任务关系数据量小,数据量小,特别适合使用查询方便,利于统计的关系型数据库维护,从而有望解决现有技术中需要停批刷新任务依赖的问题,实现不停机情况下的任务依赖局部更新,提高任务的执行效率。基于此,本说明书实施例提供一种任务依赖关系更新方法、装置及存储介质。
请参阅图1,介绍本说明书一个场景示例。在本场景示例中,可以通过依赖维护程序来实现任务依赖关系的更新。所述依赖维护程序可以部署在调度服务器中的任意多台,执行时,通过调度全局锁(zookeeper组件注册服务)和自我锁(程序执行前自检查,采用启动前杀死之前进程策略)限制只有一个依赖维护程序可以在一个时间单独运行。
在本场景示例中,调度服务器可以通过调度程序对任务进行调度。具体的,调度程序可以通过一个服务器上的进程对应一个任务执行,另外一个进程作为守护进程,获取任务的执行状态等。
在本场景示例中,所述依赖维护程序可以包括元数据扫描模块101、任务清单管理模块102、解析模块103和校验模块104。通过各个模块的协同工作,实现任务依赖关系的更新。
所述元数据扫描模块101,用于使用ODBC接口连接hadoop、postgresql等数据库,查询元数据表以获取所有数据表和数据表的分区信息,维护在postgresql表中。所述元数据指的是数据表在数据库中的原始信息,如表名、字段名、分区数量、分区名等信息。
具体的,任务的元数据库来源丰富,以hadoop为例,有内表、外表,同时使用基于postgresql数据库的关系型数据,使用互联互通工具进行基础数据互通,那么元数据的维护需要多种odbc接口支持。本场景示例中,hadoop的元数据使用的是postgresql开源数据库作为元数据库,postgresql数据库的元数据库依然为postgresql数据库,则读取元数据的接口odbc可以为gsql接口。进一步的,选用postgresql数据库可以避免元数据库的性能和扩展性问题,开源数据库也能够节省成本。
所述任务清单管理模块102,用于连接postgresql数据库,基于数据库中的元数据,保存每一个版本中任务的脚本内容。具体可以包括各个任务不同版本的脚本内容的大小、修改时间等。所述脚本内容基于HQL(Hibernate Query Language,Hibernate查询语言)语句编写,HQL文件中的语句支持SQL-92标准中入门级(Entry Level)的DML语法,即select、delete、update和insert。其中,SQL-92是数据库的一个ANSI/ISO标准。它定义了一种语言(SQL)以及数据库的行为(事务、隔离级别等)。许多商业数据库至少在某种程度上是符合SQL-92标准的。共有4个层次,大多数开发商符合第一级别入门级(Entry level)。
所述任务清单管理模块102,还可以用于比较postgresql数据库中各个任务最近两个版本的脚本内容,从而确定脚本内容发生变化的任务,获得这些脚本内容发生变化的任务的清单,清单中的任务即为需要进行依赖关系更新的任务。
所述解析模块103,用于读取元数据扫描模块101、任务清单管理模块102模块的信息,读取清单中各个任务的hql脚本内容,以hql脚本为粒度,生成变动任务的新依赖关系,并将新依赖关系输入postgresql数据库的临时表中。其中,主要解析跟在UPDATE、INSERT、DELETE语句块后的FROM、JOIN、UNION表均获取到实际表信息,确定表对应的任务名称或参数表信息,从而获得任务的新依赖关系。任务的依赖关系维护在postgresql开源关系型数据库中,每个任务只需获取自己的任务依赖和依赖于自己的任务清单,就可以完成批量运行。由于任务关系数据量小,数据量小,特别适合使用查询方便,利于统计的关系型数据库维护。
具体的,解析模块103的调起方式可以包括自动触发和手工触发。在所述调起方式为自动触发的情况下,所述解析模块103执行上述所有步骤;在所述调起方式为手工触发的情况下,所述解析模块103可以忽略元数据扫描模块101的信息,直接对比清单,按照存量元数据进行依赖关系的生成和更新。
解析模块103在获取清单后,可以确定需要解析哪些脚本内容。具体的,需要解析的脚本内容可以包括脚本内容发生变化的任务;也可以包括动态分区脚本,分区不是简单的partition=’yyyy-mm-dd’,而是有其他判断逻辑,或者其他业务处理以后关联得到分区范围的,要确认本任务的依赖是否发生变动;还可以包括人工介入修改的任务,例如不想重新更新某些任务,想额外更新某些任务的情况。
所述校验模块104,可以用于验证临时表中的依赖关系是否存在任务环。具体的,可以将整体依赖关系组成DAG图(有向无环图),采用DFS算法(white-grey-black)验证是否存在任务环,通过验证的任务关系增量更新到postgresql数据库实际任务依赖关系表中。DFS(Depth First Search)算法即深度优先搜索算法,是按照深度优先的顺序,对于有向图的所有节点进行访问,寻找所有可达节点的算法。在本场景示例中用来寻找DAG图中的环结构。
其中,所述有向无环图中的节点表示目标任务和目标任务所依赖的任务,边表示依赖关系。所述任务环表示所述目标任务与依赖的上游任务之间形成环状的依赖关系,例如,任务A的执行依赖于任务B的执行,任务B的执行依赖于任务C的执行,任务C的执行依赖以任务A的执行,如此,形成了一个任务环,此时的依赖关系出现了异常。
这里介绍一下DFS(White-Gray-Black)算法在程序检验环依赖的实现和伪代码。选择原始任务作为顶点v1...vn,依次执行深度优先搜索,定义所有顶点的初始颜色为White,正在被访问的顶点颜色为Gray,已经被访问的节点为Black。当执行算法过程中,找到灰色顶点即为找到一个任务依赖环,遍历所有顶点可以找到所有异常环路。
伪代码如下:
For v in所有顶点
Do
所有顶点置白色
getCycleDFS(v)
done
Function getCycleDFS(){
当前v节点颜色标记为灰
For v’in所有v顶点的后续顶点{
Ifv’为黑then继续
Ifv’为灰then返回当前遍历所有灰色节点,存在环
Ifv’为白then getCycleDFS(v’)
}
检查结束,节点颜色置为黑色
返回true
}
图2为本场景示例中一次依赖关系更新的流程说明。
整体的依赖关系图表如表1所示。
表1
在本场景示例中,任务在正常运行时采用推模式,依赖的前序任务运行完成后,通过调度通知后续调度可以调起。任务A执行完成后,分别通知任务1、任务3开始,任务1、任务3自行判断自己的依赖是否已经全部满足,此时任务1为推模式执行调度。当需要更新任务依赖时,待更新任务的执行策略调整为拉模式,即扫描自己新的源表对应任务、其他的上一层任务修改自身依赖。如下,任务1的依赖任务由任务A修改为任务C,则依赖维护程序标记任务1使用拉模式调度;任务4与原依赖任务3删除依赖关系,标记任务4使用拉模式调度,其他作业维持原调度模式不变。其中,所述拉模式为目标任务扫描依赖的任务,在依赖的任务运行完毕后,执行所述目标任务;所述推模式为目标任务执运行完毕后,通知下一个任务运行。
修改后的依赖关系如表2所示。
表2
在本场景示例中,任务的推模式和拉模式转换,可以保证任务2不受其他任务的改变而影响自己的运行,如停机、停批等,任务1、任务4在更新完成依赖后的首次执行时采用拉模式,避免新依赖任务已经运行,而不通知新任务的情况。
图3为采用依赖维护程序进行任务依赖关系更新的一个示例。
在本场景示例中,依赖维护程序进行任务依赖关系更新的触发方式可以包括在任务发生删减、调整时触发,每日定时触发或人工调起触发。当然,还可以包括其他触发方式,本场景示例对此不作限定。
依赖维护程序进行任务依赖关系更新执行步骤可以包括:
步骤1:通过元数据扫描模块101获取元数据的更新情况。
通过分析元数据的更新情况,从而获取源表的实际分区情况和任务对应的数据表的分区情况。
步骤2:维护任务清单,找到发生变化的任务的脚本内容。
具体的,可以通过任务清单管理模块102获取脚本内容发生变化的任务清单,并临时暂停这些任务的触发状态,其他不涉及的任务可以继续执行。其中,暂停任务的触发状态表示暂时停止调度这些任务。
在本步骤中,可以通过增量方式读取数据库原始数据表、任务表的所有分区新增、修改信息,通过元数据接口gsql加载进入MetaData数据存储模块,从而找到发生变化的任务的脚本内容。
步骤3:解析任务清单中任务的脚本内容,得到所述任务的依赖关系。
在本步骤中,可以按照语法块进行解析,当出现insert、update、delete的语法时,根据执行语句对应的数据表以及分区标识,并记录强弱依赖关系;具体的,通过脚本中使用到的源表以及分区标志来判断作业使用到的前序作业。FROM、JOIN(left join,rightjoin,outer join,inner join)等关键字后面跟随的就是使用到的源表信息,而源表信息对应的任务,或者修改源表的任务就是需要依赖的任务。
其中,所述弱依赖关系表示目标任务使用依赖的上游任务对应的数据表指定分区已经加载完毕的数据;所述强依赖关系表示目标任务使用依赖的上游任务对应的数据表未完成加载的数据。举例来说,当A任务的T日任务使用到了源表α的T日分区(PT_DT=’T’),当α加载第T+1日分区数据的时候,只要不更新存量分区,那么A任务使用α表不受α任务自己加载影响,那么我们称A任务弱依赖于α任务。相反,如果A任务T日作业使用到了,源表α的T日以外的数据,如全表扫描所有分区数据时,A任务T日批量必须等待α表加载运行完成后才可以执行,我们称A任务强依赖于α表的加载任务。强弱依赖关系是区分任务能否并发执行的判断标准。当弱依赖的任务运行非T日数据批量时,依赖的任务可以同时运行T日数据不受影响。对于A任务,只维护A任务的依赖的上游任务,更新A任务依赖时也只需要修改A这一层的依赖即可,不需要调整整个链路的依赖情况,从头重新解析。
一般的与开发约定同一张表只有同名作业可以更新,这样能保证数据更新的唯一性,依赖解析程序可以快速定位作业、源表之间的一一对应关系。此外,HQL文件中还可以增加注释,指定依赖任务、去除依赖任务等等自定义操作。
步骤4:维护调整后的依赖关系,确认删减的任务,同步清理对应的依赖关系。
步骤5:更新任务的依赖关系。
具体的,可以先采用DFS算法验证新的依赖关系是否存在任务环,通过验证的依赖关系增量更新到postgresql数据库实际任务依赖关系表中。
在本场景示例中,通过上述方式进行任务依赖关系的更新,可以实现不停机情况下的依赖局部更新,实现了批量7×24小时不间断运行。同时,由于每日动态增量获取集群最新的原始数据分区信息,任务的强弱依赖关系可以被精确地维护,从而更加准确、高效的运行批量,避免因不必要等待引起的任务运行时间延长,尽可能增加批量运行的时效。通过任务依赖自动解析,减少人为配置失误,确保作业按照实际逻辑依赖运行作业级依赖,可以提高任务数据的质量、提升开发工作效率。
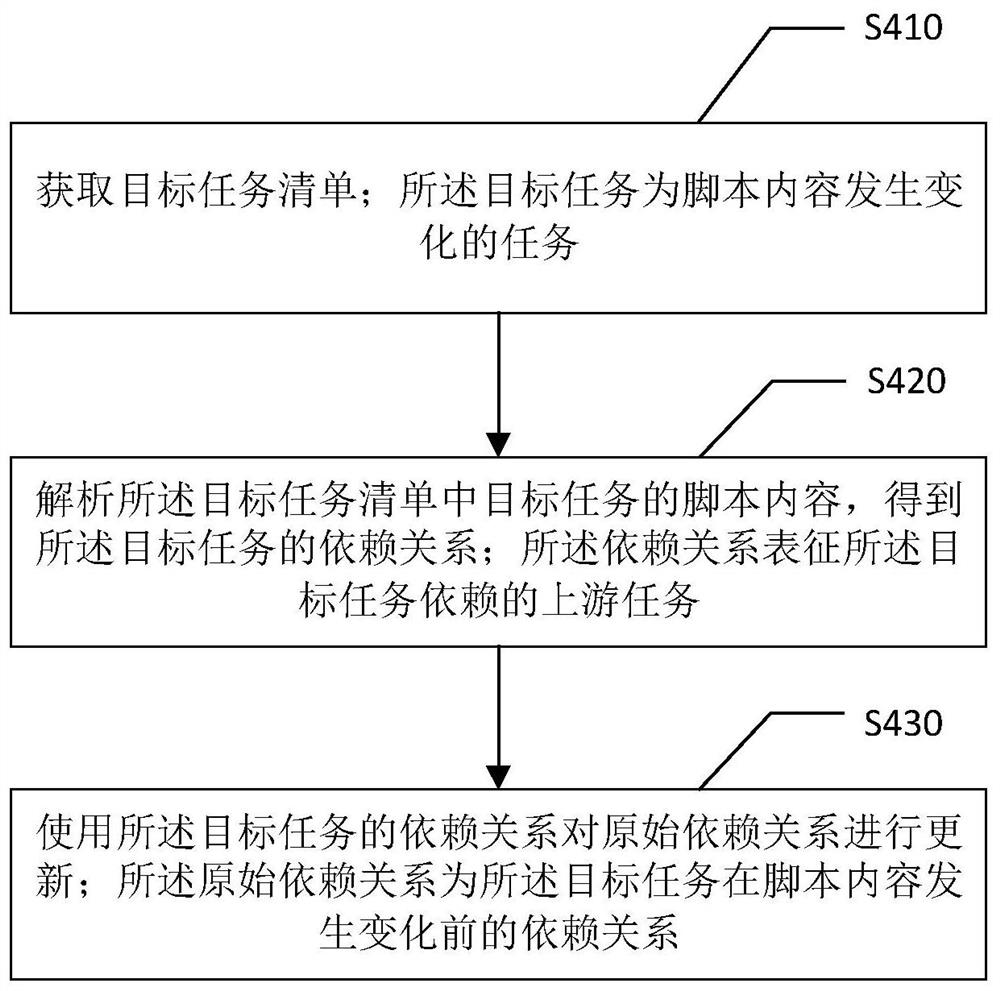
请参阅图4。本说明书实施例提供一种任务依赖关系更新方法。在本说明书实施例中,执行所述任务依赖关系更新方法的主体可以是具有逻辑运算功能的电子设备,所述电子设备可以是服务器。所述服务器可以是具有一定运算处理能力的电子设备。其可以具有网络通信单元、处理器和存储器等。当然,所述服务器并不限于上述具有一定实体的电子设备,其还可以为运行于上述电子设备中的软体。所述服务器还可以为分布式服务器,可以是具有多个处理器、存储器、网络通信模块等协同运作的系统。或者,服务器还可以为若干服务器形成的服务器集群。所述方法可以包括以下步骤。
S410:获取目标任务清单;所述目标任务为脚本内容发生变化的任务。
在一些实施例中,所述任务可以为对数据表进行某些操作,如对数据的提取、分析等。具体的,所述任务可以通过HQL编写的脚本实现。
在一些实施例中,可以通过以下方式获取目标任务清单:从预设的数据库中读取各个任务最近两个版本的脚本内容;根据各个任务最近两个版本的脚本内容确定脚本内容发生变化的任务。通过这种方式,可以实现目标任务清单的自动获取,提高了目标任务清单的获取效率。
在一些实施例中,所述postgresql数据库;所述postgresql数据库存储有各个任务每一版本的脚本内容的大小和修改时间。postgresql是一种特性非常齐全的自由软件的对象-关系型数据库管理系统(ORDBMS)。postgresql支持大部分的SQL标准并且提供了很多其他现代特性,如复杂查询、外键、触发器、视图、事务完整性、多版本并发控制等。同样,postgresql也可以用许多方法扩展,例如通过增加新的数据类型、函数、操作符、聚集函数、索引方法、过程语言等。通过选用postgresql数据库可以避免元数据库的性能和扩展性问题,数据库也能够节省成本。
在一些实施例中,所述预设的数据库中各个任务不同版本的脚本内容从存储各个任务的元数据的元数据库中得到。具体的,任务的元数据库来源丰富,以hadoop为例,有内表、外表,同时使用基于postgresql数据库的关系型数据,使用互联互通工具进行基础数据互通,那么元数据的维护需要多种odbc接口支持。hadoop的元数据使用的可以是postgresql开源数据库作为元数据库,postgresql数据库的元数据库依然为postgresql数据库,则读取元数据的接口odbc可以为gsql接口。基于元数据库的每日动态增量获取集群最新的原始数据分区信息,任务的强弱依赖关系可以被精确地维护,从而更加准确、高效的运行批量,避免因不必要等待引起的任务运行时间延长,尽可能增加批量运行的时效。
S420:解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务。
在一些实施例中,可以所述解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系包括:解析所述目标任务的脚本内容中的HQL语句用到的数据表和数据表的分区标识;根据所述数据表和数据表的分区标识获取所述目标任务依赖的上游任务;基于所述目标任务依赖的上游任务生成所述目标任务的依赖关系。
具体的,可以解析跟在UPDATE、INSERT、DELETE语句块后的FROM、JOIN、UNION表均获取到实际表信息,确定表对应的任务名称或参数表信息,从而获得任务的新依赖关系。通过上述方式,能够准确地得到各个任务依赖的上游任务,提高目标任务依赖关系的获取效率。
在一些实施例中,所述依赖关系可以包括强依赖关系和弱依赖关系;所述弱依赖关系表示目标任务使用依赖的上游任务对应的数据表指定分区已经加载完毕的数据;所述强依赖关系表示目标任务使用依赖的上游任务对应的数据表未完成加载的数据。
举例来说,当A任务的T日任务使用到了源表α的T日分区(PT_DT=’T’),当α加载第T+1日分区数据的时候,只要不更新存量分区,那么A任务使用α表不受α任务自己加载影响,那么我们称A任务弱依赖于α任务。相反,如果A任务T日作业使用到了,源表α的T日以外的数据,如全表扫描所有分区数据时,A任务T日批量必须等待α表加载运行完成后才可以执行,我们称A任务强依赖于α表的加载任务。强弱依赖关系是区分任务能否并发执行的判断标准。当弱依赖的任务运行非T日数据批量时,依赖的任务可以同时运行T日数据不受影响。对于A任务,只维护A任务的依赖的上游任务,更新A任务依赖时也只需要修改A这一层的依赖即可,不需要调整整个链路的依赖情况,从头重新解析。
S430:使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
在一些实施例中,在使用所述目标任务的依赖关系对原始依赖关系进行更新之前,还可以包括对所述目标任务的依赖关系的验证步骤。具体的,可以验证所述目标任务的依赖关系是否存在任务环;所述任务环表示所述目标任务与依赖的上游任务之间形成环状的依赖关系;相应的,在验证所述目标任务的依赖关系不存在任务环的情况下,使用所述目标任务的依赖关系对原始依赖关系进行更新。
通过上述方式,能够及时发现依赖关系中存在任务环的情况,有利于依赖关系的维护。例如,任务A的执行依赖于任务B的执行,任务B的执行依赖于任务C的执行,任务C的执行依赖以任务A的执行,如此,形成了一个任务环,此时的依赖关系出现了异常。
在一些实施例中,可以根据以下方式验证所述目标任务的依赖关系是否存在任务环:将所述目标任务的依赖关系保存在临时表中;基于所述临时表中的目标任务的依赖关系生成有向无环图;其中,所述有向无环图中的节点表示目标任务和目标任务所依赖的任务,边表示依赖关系;使用深度优先搜索算法检测所述有向无环图中是否存在环路。
具体的,深度优先搜索算法,是按照深度优先的顺序,对于有向图的所有节点进行访问,寻找所有可达节点的算法。
这里介绍一下DFS(White-Gray-Black)算法在程序检验环依赖的实现和伪代码。选择原始任务作为顶点v1...vn,依次执行深度优先搜索,定义所有顶点的初始颜色为White,正在被访问的顶点颜色为Gray,已经被访问的节点为Black。当执行算法过程中,找到灰色顶点即为找到一个任务依赖环,遍历所有顶点可以找到所有异常环路。
伪代码如下:
For v in所有顶点
Do
所有顶点置白色
getCycleDFS(v)
done
Function getCycleDFS(){
当前v节点颜色标记为灰
For v’in所有v顶点的后续顶点{
Ifv’为黑then继续
Ifv’为灰then返回当前遍历所有灰色节点,存在环
Ifv’为白then getCycleDFS(v’)
}
检查结束,节点颜色置为黑色
返回true
}
通过深度优先搜索算法通过遍历所有顶点的方式,能够准确发现有向无环图中是否具有环结构,从而及时发现目标任务的依赖关系是否发生异常。
在一些实施例中,所述方法还可以包括暂停所述目标任务的调度;在所述目标任务的依赖关系更新完成的情况下,重新调度所述目标任务,从而避免在目标任务的依赖关系进行更新的过程中,使用原始依赖关系错误的对目标任务的调度。
在一些实施例中,所述重新调度所述目标任务可以包括:在所述目标任务的依赖关系更新后的首次调度所述目标任务采用的调度策略为拉模式,后续调度所述目标任务采用的调度策略为推模式;其中,所述拉模式为目标任务扫描依赖的任务,在依赖的任务运行完毕后,执行所述目标任务;所述推模式为目标任务执运行完毕后,通知下一个任务运行。通过任务的推模式和拉模式转换,可以保证目标任务不受其他任务的改变而影响自己的运行,如停机、停批等,目标任务在更新完成依赖后的首次执行时采用拉模式,避免新依赖任务已经运行,而不通知新任务的情况。
本说明书实施例提供的方法,可以获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。本说明书实施例提供的方法,能够解决现有技术中需要停批刷新任务依赖的问题,实现不停机情况下的任务依赖局部更新,提高任务的执行效率。
图5为本说明书实施例一种电子设备的功能结构示意图,所述电子设备可以包括存储器和处理器。
在一些实施例中,所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现任务依赖关系更新方法的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据用户终端的使用所创建的数据。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘、智能存储卡(Smart Media Card,SMC)、安全数字(Secure Digital,SD)卡、闪存卡(Flash Card)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
所述处理器可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(APPlication Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。所述处理器可以执行所述计算机指令实现以下步骤:获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
在本说明书实施例中,该电子设备具体实现的功能和效果,可以与其它实施例对照解释,在此不再赘述。
图6为本说明书实施例一种任务依赖关系更新装置的功能结构示意图,该装置具体可以包括以下的结构模块。
获取模块610,用于获取目标任务清单;所述目标任务为脚本内容发生变化的任务;
解析模块620,用于解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;
更新模块630,用于使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
本说明书实施例还提供了一种任务调度方法的计算机可读存储介质,所述计算机可读存储介质存储有计算机程序指令,在所述计算机程序指令被执行时实现:获取目标任务清单;所述目标任务为脚本内容发生变化的任务;解析所述目标任务清单中目标任务的脚本内容,得到所述目标任务的依赖关系;所述依赖关系表征所述目标任务依赖的上游任务;使用所述目标任务的依赖关系对原始依赖关系进行更新;所述原始依赖关系为所述目标任务在脚本内容发生变化前的依赖关系。
在本说明书实施例中,上述存储介质包括但不限于随机存取存储器(RandomAccess Memory,RAM)、只读存储器(Read-Only Memory,ROM)、缓存(Cache)、硬盘(HardDisk Drive,HDD)或者存储卡(Memory Card)。所述存储器可用于存储所述计算机程序和/或模块,所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序等;存储数据区可存储根据用户终端的使用所创建的数据等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器。在本说明书实施例中,该计算机可读存储介质存储的程序指令具体实现的功能和效果,可以与其它实施方式对照解释,在此不再赘述。
需要说明的是,本说明书实施例提供的任务依赖关系更新方法、装置及存储介质,可以应用于大数据处理技术领域。当然,也可以应用于金融领域,或者除金融领域之外的任意领域,本说明书实施例对所述任务依赖关系更新方法、装置及存储介质的应用领域不做限定。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同或相似的部分互相参见即可,每个实施例重点说明的都是与其它实施例的不同之处。尤其,对于装置实施例和设备实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
本领域技术人员在阅读本说明书文件之后,可以无需创造性劳动想到将本说明书列举的部分或全部实施例进行任意组合,这些组合也在本说明书公开和保护的范围内。
在20世纪90年代,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(Programmable Logic Device,PLD)(例如现场可编程门阵列(Field Programmable GateArray,FPGA))就是这样一种集成电路,其逻辑功能由用户对器件编程来确定。由设计人员自行编程来把一个数字系统“集成”在一片PLD上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(Hardware Description Language,HDL),而HDL也并非仅有一种,而是有许多种,如ABEL(Advanced Boolean Expression Language)、AHDL(AlteraHardware DescriptionLanguage)、Confluence、CUPL(Cornell University Programming Language)、HDCal、JHDL(Java Hardware Description Language)、Lava、Lola、MyHDL、PALASM、RHDL(RubyHardware Description Language)等,目前最普遍使用的是VHDL(Very-High-SpeedIntegrated Circuit Hardware Description Language)与Verilog2。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机。具体的,计算机例如可以为个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本说明书可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本说明书的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本说明书各个实施例或者实施例的某些部分所述的方法。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
本说明书可用于众多通用或专用的计算机系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络PC、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。
本说明书可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本说明书,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
虽然通过实施例描绘了本说明书,本领域普通技术人员知道,本说明书有许多变形和变化而不脱离本说明书的精神,希望所附的权利要求包括这些变形和变化而不脱离本说明书的精神。
- 一种任务依赖关系更新方法、装置及存储介质
- 调度任务依赖关系识别方法、装置及计算机可读存储介质