一种基于重要性排序的地球应用模型编排系统及其方法
文献发布时间:2023-06-19 19:04:00
技术领域
本发明涉及服务资源整合技术,具体涉及一种基于重要性排序的地球应用模型编排系统及其方法。
背景技术
数字地球应用模型是联系底层地球数据与上层科学研究、专家决策的关键纽带,是新一代数字地球信息服务体系中的一类重要资源。面向服务的地球应用模型虽然能够实现业务过程在计算环境下的自动化,但是随着应用领域的扩大以及应用功能需求的增多,服务网络节点数量迅速增长,依赖关系愈趋复杂,带来了地球应用模型集成管理的困难。尤其是云计算环境下,大规模服务资源、存储等资源分布于不同的集群或服务器,功能属性相同的资源往往具有不同的系统架构、部署模式、运行状态、访问性能等,增加了地球应用模型资源选择与编排的难度。现有系统由于设计缺陷,在多源地球应用模型持续接入与集成使用方面,面临一些新的问题。针对地球应用模型多模式、多依赖、多实例的运行场景,现有平台缺少系统级别的智能化的编排辅助支撑机制。更重要的是,大多数平台只关注领域相关的数据、服务资源的静态信息,却忽略了资源使用状态与运行时信息对服务性能和平台资源利用效率的影响。由于云计算尤其容器云环境随机性较大,导致资源负载波动甚至资源稳定性问题,不合理的资源选择编排直接影响地球应用模型的整体服务性能。综上所述,目前在相关领域内缺少面向服务的地球应用模型智能编排管理方法和系统的研究,即在资源运行时分析的基础上建立基于资源重要性评价排序的智能化的编排辅助支撑机制。
发明内容
本发明的目的在于提出一种基于重要性排序的地球应用模型编排系统及其方法。
实现本发明目的的技术解决方案为:一种基于重要性排序的地球应用模型编排系统及其方法,包括:
资源信息聚合分析模块,用于地球应用模型依赖资源信息的聚合分析,支撑依赖资源重要性评价排序过程,包括资源注册与发现、资源运行时监控、资源指标聚合分析三个子功能模块。首先,建立资源目录和路由机制,实现资源信息的汇聚与共享;然后,建立在线监控机制,实现资源运行信息的采集。对于服务资源,进一步通过解析地球应用模型服务调用的上下文日志信息重塑调用链路,采集服务响应时间、调用次数等访问信息。最后,通过资源聚合,实现资源运行信息、访问信息等的聚合分析,以此作为资源重要性评价的决策因素,为依赖资源重要性评价排序模块提供数据支撑。
资源重要性评价排序模块,用于地球应用模型依赖资源的重要性评价排序,自动推荐优质资源实例支撑依赖资源的智能编排过程,包括服务资源重要性评价排序和存储资源重要性评价排序两个子功能模块。所述服务资源重要性评价排序包括服务预选、服务优选和服务排序三个步骤。首先,服务预选通过构造服务特征空间,基于孤立森林模型进行服务资源异常分析,剔除异常服务以防止异常服务资源参与编排带来服务性能隐患。然后,在服务预选的基础上进行服务优选,通过熵权法改进多准则决策方法的指标权重,综合考虑服务各项特征的作用,实现更为准确的服务重要性评价。最后,根据服务资源重要性大小排序服务并进行top-k操作,通过建立与在线地球应用模型编排模块的服务推送机制,提供近实时的服务资源推荐功能;所述存储资源重要性评价排序包括存储评价和存储排序两个步骤。在构建存储特征空间的基础上,使用改进的多准则决策方法评价存储资源的重要性。根据存储资源重要性大小排序存储并进行top-k推荐。
在线地球应用模型智能编排模块,用于地球应用模型依赖资源的智能化编排,实现地球应用模型服务能力集成,包括服务资源编排、存储资源编排、配置资源编排、计算资源编排四个子功能模块。首先,提供图形化交互界面构建地球应用模型依赖拓扑。然后,采用递归地球应用模型依赖拓扑的方式自动进行依赖资源的组装。对于服务资源编排,通过服务资源数据库检索可选服务资源实例,存在则进行服务资源重要性评价排序,自动组装推荐的服务资源实例,否则先对依赖服务自身进行编排,编排完成后再回溯到当前编排服务;对于存储资源编排,通过存储资源数据库检索可选存储资源实例,存在则进行存储资源重要性评价排序,自动组装推荐的存储资源实例,不存在则根据存储模板自动创建;对于配置资源编排,通过配置资源数据库检索相关配置实例集合,存在则获取当前激活的配置实例,并且将编排完成的依赖服务资源和存储资源的连接信息更新到所述配置实例,使用配置挂载方法注入服务容器。不存在则根据配置模板自动创建;对于计算资源编排,通过聚类分析自适应分配计算资源,配置运行参数,完成地球应用模型的自动编排过程。
一种基于重要性排序的地球应用模型编排系统及其方法,通过所述的基于重要性排序的地球应用模型编排系统,实现基于重要性排序的地球应用模型编排。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时,利用所述的基于重要性排序的地球应用模型编排系统,实现基于重要性排序的地球应用模型编排。。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,通过所述的基于重要性排序的地球应用模型编排系统,实现基于重要性排序的地球应用模型编排。
本发明与现有技术相比,其显著优点为:通过优质资源的在线推荐实现地球应用模型编排的智能化过程,提升了地球应用模型发布的效率和服务性能。
附图说明
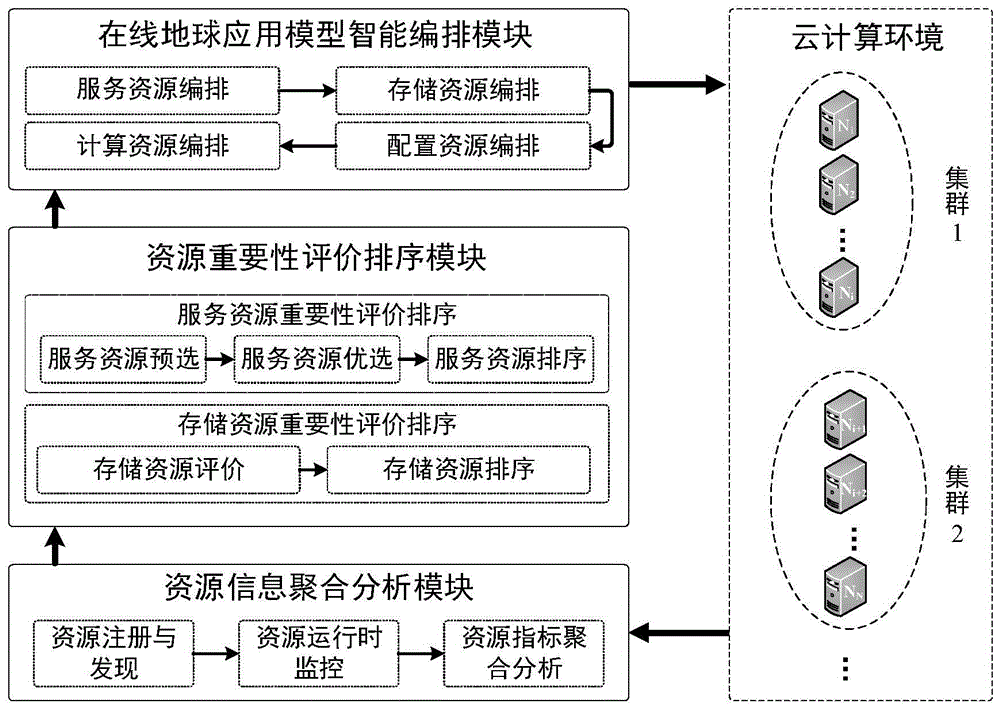
图1是本发明基于重要性排序的地球应用模型编排系统架构图。
图2是地球应用模型依赖拓扑示意图。
图3是服务资源重要性评价排序示意图。
图4是服务资源重要性评价排序算法流程图。
图5是存储资源重要性评价排序算法流程图。
图6是地球应用模型自动编排流程图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
本发明通过整合服务评价排序技术、服务智能编排技术等,实现了云计算环境下地球应用模型的自动编排管理过程,系统架构如图1所示,地球应用模型依赖拓扑示意如图2所示。所述地球应用模型依赖拓扑由服务节点(圆形)和存储节点(正方形)组成,箭头方向为依赖方向。地球应用模型自动编排通过对云环境中服务资源和存储资源评价,根据地球应用模型依赖拓扑选择优质资源组装成地球应用模型实例。一种基于重要性排序的地球应用模型编排系统及其方法,包括资源信息聚合分析模块、依赖资源重要性评价排序模块、在线地球应用模型智能编排模块。地球应用模型编排系统的执行流程包括:
a、资源信息聚合与分析模块,建立资源目录和路由机制实现资源信息汇聚,通过在线监控机制实现资源运行指标采集,通过运行指标的聚合分析实现资源状态表征,支撑依赖资源重要性评价评价排序过程。
b、依赖资源重要性评价排序模块,通过服务资源重要性评价排序算法和存储资源重要性评价排序算法实现优质资源筛选,通过优质资源推荐支撑在线地球应用模型智能编排过程。
c、在线地球应用模型智能编排模块,根据需求构建地球应用模型依赖拓扑,结合资源重要性评价排序算法,递归进行依赖服务资源、存储资源、配置资源、计算资源的自动编排过程。
下面结合附图2-6对各模块的组成和功能进行详细说明。
所述资源信息聚合与分析模块用于服务资源、存储资源信息的聚合分析,支撑依赖资源重要性评价排序过程,包括资源注册与发现、资源运行时监控、资源指标聚合分析三个子功能模块。参照图1所示的资源信息聚合分析模块部分。具体实施步骤如下:
(1)资源注册与发现
建立资源目录和路由机制,资源提供者通过主动或被动的方式将访问地址注册到资源目录,实现资源信息的汇聚。所述资源信息包括服务资源和存储资源。
(2)资源运行时监控
通过在线监控机制,实时采集资源运行指标。对于服务资源,采集CPU占用率、内存占用率、磁盘占用率、网络带宽占用率等基础指标,并且通过解析地球应用模型服务调用的上下文日志信息重塑服务调用链路,采集服务响应时间、服务调用次数(包括调用失败次数)等基础指标;对于存储资源,采集存储使用量、每秒处理查询数、每秒处理事务数、每秒处理磁盘I/O操作数等基础指标。
(3)资源指标聚合分析
进行服务资源、存储资源基础指标信息的聚合分析,作为资源重要性评价的决策因素,为依赖资源重要性评价排序模块提供数据支撑。在步骤(2)所示基础指标的基础上,进一步构建资源聚合指标。服务资源聚合指标包括平均资源占用率(RUR),资源使用失衡度(RID),服务吞吐量(TH),平均响应时间(RT)、服务等级协议违反率(SLA)和访问错误率(ERR)等。所述RUR聚合指标定义为各类资源(包括CPU、内存等)占用率的均值。所述RID聚合指标定义为各类资源占用率的方差。所述TH聚合指标定义为服务在观测时间窗口内的总访问数。所述SLA聚合指标定义为服务响应违反时间与平均响应时间RT的比值,设置服务响应阈值δ,平均响应时间RT大于δ即为违反,违反时间定为RT-δ。所述ERR指标定义为观测时间窗口内服务请求的成功访问数与总访问数的比值;存储资源聚合指标包括地球应用模型存储的剩余可用容量(CAP)、平均处理查询数(QPS)、平均处理事务数(TPS)和平均处理磁盘I/O操作数(IOPS)。其中,CAP聚合指标定义为观测时间窗口内存储资源配额与存储资源使用量的差值。其他聚合指标包括QPS、TPS、IOPS定义为观测时间窗口内相应指标的均值。
所述资源重要性评价排序模块用于地球应用模型依赖资源的重要性评价,通过自动推荐优质资源实例支撑依赖资源的智能编排过程,包括服务资源重要性评价排序和存储资源重要性评价排序两个子功能模块。服务资源重要性评价排序示意图参照图3,服务资源重要性评价排序的算法流程参照图4,存储资源重要性评价排序的算法流程参照图5,具体实施步骤如下:
(1)服务资源重要性评价排序
服务资源重要性评价与排序,通过算法分析相同功能服务资源的重要性价值,自动推送价值大的服务资源参与地球应用模型依赖编排。参照图3、4,包括服务资源预选、服务资源优选和服务资源排序三个步骤。总体流程为:首先,通过服务资源预选剔除异常服务实例。然后,通过服务资源优选评估服务重要性价值。最后,通过根据重要性价值大小进行服务实例排序,推送重要性价值最大的实例参与地球应用模型依赖资源编排。详细实施步骤如下:
a、服务资源预选
基于孤立森林模型进行服务资源异常分析,剔除异常服务以防止异常服务资源参与编排带来地球应用模型服务性能隐患。异常服务相较于正常服务通常表现出资源消耗大、响应时间长、SLA违反率高等特点,具有较为明显的离群性。所提基于孤立森林模型的服务资源预选方法,通过多次切分服务特征空间以孤立样本离群点,进而实现服务异常的检测。参照图4,具体实施步骤如下:
①构造服务特征空间
在资源信息聚合分析的基础上,选取六类典型聚合特征构建地球应用模型服务特征空间SF,如式(1),以此作为服务资源异常分析的决策因素。式中RUR,RID,SLA,QPS,RT,ERR分别为地球应用模型服务的平均资源占用率、资源使用失衡度、SLA违反率、服务吞吐量、服务平均响应时间、和服务访问错误率。
SF=(RUR,RID,SLA,QPS,RT,ERR) (1)
基于式(1)所述服务特征空间,采集历史环境下服务特征样本数据构建训练集S
⑤构造基于孤立森林的异常检测模型
使用训练集S
步骤1:从S
步骤2:随机选择一个属性q∈SF,在属性q取值范围内,随机产生一个切割点p。此切割点的选取生成了一个超平面,将当前节点的数据空间切分为2个子空间。把当前节点数据中属性值小于p的数据构建为左分支,把大于等于p的数据构建为右分支。
步骤3:在节点的左分支和右分支递归步骤2,不断构造新的叶子节点,直到叶子节点上只有一个样本数据或树已经生长到限制高度l。
步骤4:迭代步骤1~3,构建一个具有t棵子树的孤立森林模型,以此作为地球应用模型服务的异常检测模型。
⑥异常服务检测过滤
引入异常值函数
通过式(2)评估并标记测试集S
b、服务资源优选
在服务资源预选的基础上,进一步通过改进多准则决策方法评估服务资源的重要性,实现服务资源优选。由于传统方法使用服务特征值加权法评估服务重要性,可能出现个别属性值相对较优导致服务排名靠前的现象。因此,所提方法使用熵权法改进多准则决策法的指标权重系数,综合考虑各项特征的作用,实现更为准确的服务重要性评价。参照图4,具体实施步骤如下:
③计算服务特征权重系数
首先,使用式(4)通过预选服务特征集合S'计算服务特征信息熵E
然后,根据服务特征信息熵,使用式(5)计算服务特征权重系数W
④改进多准则决策方法评价服务重要性
首先,使用步骤①中所述的服务特征权重W
步骤1:使用预选服务特征集合S'构建N行K列的服务重要性决策矩阵DM
步骤2:计算正则化的服务重要性决策矩阵NDM
步骤3:确定最优方案
步骤4:计算各评价对象与最优方案的距离D
步骤5:根据最优、最劣距离计算服务重要性价值V
通过式(7)评价后,预选服务特征集合S′被转换为优选服务特征集合S”。
c、服务资源排序
根据步骤b所述的服务重要性价值从大到小对优选服务特征集合S”进行服务重要性排序,选取重要性价值最大的K
(2)存储资源重要性评价排序
存储资源重要性评价与排序,通过算法分析相同功能存储资源的重要性价值,自动推送价值大的存储资源参与地球应用模型依赖编排。参照图5,包括存储评价和存储排序两个步骤,具体实施步骤如下:
a、存储资源评价
在存储特征空间构建的基础上,使用改进的多准则决策方法评价存储资源的重要性。参照图5,具体实施步骤如下:
①构造存储特征空间
在存储资源信息聚合分析的基础上,选取四类典型指标特征构建地球应用模型存储特征空间,如式(8),以此作为存储资源异常分析的决策因素。式中CAP,QPS,TPS,IOPS分别为地球应用模型存储的容量、平均处理查询数、平均处理事务数、平均处理磁盘I/O操作数。
DF=(CAP,QPS,TPS,IOPS) (8)
基于式(8)所述存储特征空间,采集当前环境存储特征样本数据集D
②计算存储特征权重系数
使用熵权法计算特征权重系数。包括使用特征样本数据集计算存储特征信息熵,基于特征信息熵计算存储特征权重系数两个步骤。具体参照服务特征权重系数的计算方法。
③多准则决策方法评价存储重要性
使用基于熵权法的特征权重系数改进多准则决策方法以评价存储资源的重要性。包括使用存储特征样本数据集构建存储重要性决策矩阵,进行存储重要性决策矩阵正则化,确定最优方案和最劣方法,计算评价对象与最优方案、最劣方案的距离,以及计算存储资源重要性价值五个步骤。具体参照服务资源重要性评价方法,此处不再赘述。
b、存储排序
根据步骤a所述的存储资源重要性价值从大到小对存储特征样本集D
所述在线地球应用模型智能组装模块用于依赖资源的智能化编排,包括服务资源编排、存储资源编排、配置资源编排、计算资源编排四个子功能模块。参照图6,具体实施步骤如下:
首先,提供图形化交互界面构建地球应用模型依赖拓扑。参照图2,所述地球应用模型依赖拓扑包含服务节点和存储节点,节点之间通过资源标识建立关联关系,箭头指向被依赖资源;然后,基于可视化的地球应用模型依赖拓扑,采用递归节点的方式自动编排地球应用模型依赖的各类资源,包括:
(1)服务资源编排
参照图6中路径①,通过依赖服务资源标识SvcID检索服务资源数据库是否存在可选服务资源实例,存在则通过资源评价排序模块进行服务资源重要性评价排序,自动组装推荐的重要性价值最大的服务资源实例(记录所述服务资源实例的访问地址,其后注入编排服务的配置文件)。若没有检索到相关服务资源实例,则先对依赖服务自身进行编排,编排完成后再回溯到当前编排服务。
(2)存储资源编排
参照图6中路径②,通过依赖存储资源标识DataID检索存储资源数据库是否存在可选存储资源实例,存在则通过资源评价排序模块进行存储资源重要性评价排序,自动组装推荐的重要性价值最大的存储资源实例(记录所述存储资源实例的访问地址,其后注入编排服务的配置文件)。若没有检索到相关存储资源实例,则根据服务自身提供的存储模板创建存储实例。
(3)配置资源编排
参照图6中路径③,通过配置资源标识CfgID检索配置资源数据库是否存在已被激活的配置实例,并将步骤(1)(2)所述的依赖服务资源和存储资源的连接信息注入所述配置实例,使用配置挂载方法注入服务容器。若没有检索到相关配置实例,则进行新建。
(4)计算资源编排
参照图中路径④,通过对地球应用模型依赖拓扑中未部署的服务节点分配计算资源、配置运行参数,使用容器技术部署运行;对于已部署的服务节点则更新服务配置,刷新依赖资源连接信息。服务节点计算资源分配Q'通过相同类型的历史服务计算资源的平均使用量
本发明还提出一种基于重要性排序的地球应用模型编排方法,通过所述的基于重要性排序的地球应用模型编排系统,实现基于重要性排序的地球应用模型服务编排。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时,利用所述的基于重要性排序的地球应用模型编排系统,实现基于重要性排序的地球应用模型编排。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,通过所述的基于重要性排序的地球应用模型编排系统,实现基于重要性排序的地球应用模型编排。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请的保护范围应以所附权利要求为准。
- 一种Bug追踪系统测试人员重要性排序方法
- 一种基于排序引导回归的深度模型的人脸美丽评价方法
- 一种基于重要性排序的工作流编排系统及其方法
- 一种基于高阶增强的随机游走节点重要性排序的方法与系统