数据处理装置和数据处理方法
文献发布时间:2023-06-19 19:27:02
技术领域
本文中讨论的实施方式涉及数据处理装置和数据处理方法。
背景技术
马尔可夫链蒙特卡罗(MCMC)算法广泛用于离散优化、机器学习、医学应用、统计物理学等。附加地,MCMC算法用于模拟退火方法、退火重要性采样方法、并行回火方法(也称为副本交换方法)、群体退火方法等(参见,例如,非专利文献1至6)。在这些方法中,群体退火方法适用于利用并行硬件搜索针对大规模组合优化问题的解(参见,例如,非专利文献7和8)。
群体退火方法(通过逐渐降低温度)执行退火,如同在模拟退火方法中一样。然而,基于每个预定时间段针对玻尔兹曼机的多个副本分别获得的解搜索结果,群体退火方法获得了每个副本的权重(评估值)。具有小的评估值的副本被消除,而具有高的评估值的副本被复制(划分)。然后,重复搜索。基于评估值消除副本并以这种方式进行复制的处理称为重新采样处理。
就此而言,出于解决优化问题或自旋玻璃模拟的目的,MCMC算法可以用于根据玻尔兹曼机在低温下的玻尔兹曼分布进行采样(参见,例如,非专利文献9)。不利地影响玻尔兹曼机的性能的主要因素之一是拒绝提出的状态转换(下文中可以称为MCMC移动)。特别地,在根据粗略分布进行采样的情况下,许多提出的MCMC移动被拒绝。在这种情况下,状态保持不变,并且因此浪费了大量的计算时间。
为了解决该问题,提出了两种并行的MCMC算法:均匀选择MCMC算法(参见,例如,非专利文献1);以及跳转MCMC算法(参见,例如,非专利文献10)。代替提出单个MCMC移动以及接受或拒绝该提议,这些算法并行评估若干个潜在的MCMC移动,以便增加接受至少一个MCMC移动的概率。这些算法当在并行硬件中实现时特别地在接受率低的低温下表现出显著地加速。
(非专利文献1)M.Aramon等人,“Physics-inspired optimization forquadratic unconstrained problems using a digital annealer”,Frontiers inPhysics,2019年,第7卷,第48篇文章
(非专利文献2)M.Bagherbeik等人,“A permutational boltzmann machine withparallel tempering for solving combinatorial optimization problems”,InInternational Conference on Parallel Problem Solving from Nature,2020年,Springer(施普林格),第317页至第331页
(非专利文献3)S.Kirkpatrick、C.D.Gelatt和M.P.Vecchi,“Optimization bysimulated annealing”,Science,1983年,第220卷,第4598期,第671页至第680页
(非专利文献4)R.M.Neal,“Annealed importance sampling”,Statistics andComputing,2001年,第11卷,第2期,第125页至第139页
(非专利文献5)K.Hukushima和K.Nemoto,“Exchange monte carlo method andapplication to spin glass simulations”,Journal of the Physical Society ofJapan,1996年,第65卷,第6期,第1604页至第1608页
(非专利文献6)K.Hukushima和Y.Iba,“Population annealing and itsapplication to a spin glass”,AIP Conference Proceedings,2003年,第690卷,第1期,第200页至第206页
(非专利文献7)W.Wang、J.Machta和H.Katzgraber,“Comparing monte carlomethods for finding ground states of ising spin glasses:Population annealing,simulated annealing,and parallel tempering”,Physical Review E,2015年12月,第92卷
(非专利文献8)L.Y.Barash等人,“GPU accelerated population annealingalgorithm”,Computer Physics Communications,2017年,第220卷,第341页至第350页
(非专利文献9)K.Dabiri等人,“Replica exchange mcmc hardware withautomatic temperature selection and parallel trial”,IEEE Transactions onParallel and Distributed Systems,2020年,第31卷,第7期,第1681页至第1692页
(非专利文献10)J.S.Rosenthal等人,“Jump markov chains and rejection-free metropolis algorithms”,arXiv:1910.13316,2020年
使用群体退火方法搜索大规模组合优化问题的解存在高计算成本问题,因为该方法需要大量的副本。
发明内容
根据一个方面,本公开内容旨在提供一种能够降低计算成本的计算机程序、数据处理装置和数据处理方法。
根据一个方面,提供了一种存储计算机程序的非暂态计算机可读存储介质,所述计算机程序使计算机执行处理,所述处理包括:在第一存储装置中存储相对于用于玻尔兹曼机的多个副本中的每一个的多个离散变量的值和多个局部字段的值,所述多个离散变量被包括在组合优化问题转换成的玻尔兹曼机的评估函数中,所述多个局部字段各自表示当多个离散变量中之一的值改变时评估函数的值发生的改变;在为多个副本中的每一个提供的第二存储装置中存储相对于多个副本中的每一个的多个离散变量的值和多个局部字段的值;针对多个副本中的每一个重复更新处理,所述更新处理基于温度参数的设置值和存储在第二存储装置中的多个局部字段的值来更新多个离散变量中之一的值、评估函数的值以及多个局部字段的值;并且每当更新处理的迭代数达到预定值时,基于多个副本的多个离散变量的值和多个副本的评估函数的值来执行群体退火方法的重新采样处理,以及响应于在重新采样处理中通过复制多个副本中的第一副本创建了第二副本,从为第一副本提供的第一存储装置或第二存储装置中读取第一副本的多个离散变量的值和第一副本的多个局部字段的值,并且将所读取的多个离散变量的值和所读取的多个局部字段的值存储在为第二副本提供的第二存储装置中。
附图说明
图1A至图1F示出了不同温度下的玻尔兹曼分布的示例;
图2示出了针对玻尔兹曼机的马尔可夫链蒙特卡罗(MCMC)算法的示例;
图3示出了用于群体退火方法的整体算法的示例;
图4示出了用于重新采样处理的算法的示例;
图5示出了根据本实施方式的使用群体退火方法搜索组合优化问题的解的数据处理装置的示例;
图6是示出关于使用群体退火方法的解搜索处理的过程的示例的流程图;
图7是示出关于重新采样处理的过程的示例的流程图;
图8示出了MCMC模拟对最大切割问题(Max-Cut problem)的接受率的示例;
图9示出了并行归约树的示例;
图10示出了顺序选择MCMC算法的示例;
图11示出了并行最小归约树的示例;
图12是示出关于顺序选择MCMC算法的过程的示例的流程图;
图13示出了GPU实现方式的示例;
图14示出了在线程块中执行线程的示例;
图15A至图15C示出了用于均匀选择MCMC算法、顺序选择MCMC算法和跳转MCMC算法的样本的能量直方图的实验结果的示例;
图16示出了关于均匀选择MCMC算法、跳转MCMC算法和顺序选择MCMC算法的平均误差的计算结果的示例;
图17示出了簇(cluster)的示例;
图18示出了聚类算法的示例;
图19是示出关于聚类的过程的示例的流程图;
图20A和图20B示出了在聚类之前和聚类之后的权重系数矩阵的示例;
图21示出了聚类顺序选择MCMC算法的示例;
图22是示出关于聚类顺序选择MCMC算法的过程的示例的流程图;
图23是示出关于簇内并行更新处理的过程的示例的流程图;
图24示出了使用聚类顺序选择MCMC算法和非聚类顺序选择MCMC算法的最大切割问题的模拟结果;
图25示出了模拟退火方法(SA)、并行回火方法(PT)和群体退火方法(PA)针对二次分配问题(QAP)的性能的模拟结果;
图26示出了在PT中的温度阶梯大小与成功概率之间的关系;
图27示出了SA、PT和PA针对最大切割问题(G33)的性能的模拟结果;
图28示出了SA、PT和PA针对最大切割问题(G53)的性能的模拟结果;
图29示出了SA、PT和PA针对旅行商问题(TSP)的性能的模拟结果;
图30示出了并行的基于群体的玻尔兹曼机(PBBM)算法的示例;
图31示出了在针对每个副本进行10
图32示出了可以在整个群体中在一秒内运行的MCMC迭代的峰值数;
图33示出了关于PBBM(GPU实现方式)相对于其他求解器的加速的计算结果;
图34示出了第1类求解器的准确度的比较结果;
图35示出了第2类求解器的准确度的比较结果;以及
图36示出了作为数据处理装置的示例的计算机的硬件示例。
具体实施方式
将参照附图描述一个实施方式。
根据本实施方式的数据处理装置将组合优化问题转换成玻尔兹曼机评估函数并搜索解。作为评估函数,可以使用由等式(1)定义的二次无约束二元优化(QUBO)评估函数(也称为能量函数)。
等式(1)中的粗体字母x是具有N个离散变量(具有0或1的二元变量)的向量。该向量也称为状态向量,并且表示QUBO模型的状态。在下面,x可以简称为状态。在等式(1)中,w
搜索针对组合优化问题的解相当于搜索QUBO模型的状态,该状态具有由等式(1)定义的评估函数的最小值。评估函数的值对应于能量。使用符号已经改变的评估函数(加号改变成减号或减号改变成加号),QUBO模型可以被设计成搜索使评估函数的值最大化的状态。
QUBO模型等同于伊辛模型,并且这些模型很容易相互转换(参见,例如,AndrewLucas,“Ising formulations of many NP problems”,Frontiers in Physics,2014年2月,第2卷,第5篇文章)。
各种现实世界的问题可以被公式化成QUBO模型。QUBO模型与硬件兼容良好,并且适合用于在硬件中加速解搜索。
另外,根据本实施方式的数据处理装置实现了玻尔兹曼机的函数。现在将描述玻尔兹曼机。
(玻尔兹曼机)
玻尔兹曼机是具有全对全连接性的递归神经网络,并且可以使用QUBO能量函数。每个玻尔兹曼机都具有玻尔兹曼分布,所述玻尔兹曼分布表示由上述状态向量表示的每个状态的概率。由等式(2)给出玻尔兹曼分布。
在等式(2)中,β为1/T(T为温度)并且称为玻尔兹曼机的逆温度。Z
在统计物理学中,在自旋玻璃模拟中使用不同温度下的配分函数的值。然而,由于计算Z
根据玻尔兹曼分布进行采样也是用于搜索针对组合优化问题的解的方法。随着温度降低(β增加),全局最小值状态开始主导玻尔兹曼分布。因此,全局最小值状态的概率比任何其他状态的概率高,并且更可能在根据玻尔兹曼分布取得的样本中观察到全局最小值状态。
图1A至图1F示出了不同温度下的玻尔兹曼分布的示例。在图1A至图1F中,在等式(3)中使用能量函数E(x)=e
在较高的温度下,分布更平坦,而在较低的温度下,局部最大值和局部最小值放大。在最低的温度下,全局最小值状态(玻尔兹曼分布中的全局最大值)主导玻尔兹曼分布。
当根据玻尔兹曼分布进行采样时,马尔可夫链蒙特卡罗(MCMC)算法反转(翻转)离散变量的值,以便从特定状态移动至与该特定状态具有一个汉明距离的另一状态。使用Metropolis接受准则来以由等式(4)计算的概率接受该翻转。
在等式(4)中,ΔE
等式(5)的计算具有O(N)阶数的复杂度,并且等式(5)的计算的复杂度比具有O(N
图2示出了用于玻尔兹曼机的MCMC算法的示例。
输入是状态x、能量E(初始值)、逆温度β、权重系数矩阵w和偏置系数矩阵b。输出是状态x和能量E。
首先,提出翻转具有标识号j的离散变量x
当MCMC算法满足由等式(6)定义的平衡条件时,保证收敛于平衡分布π
在等式(6)中,p(x|x')表示提出到x'的移动、接受该移动并且从x移动至x'的概率。这是保证收敛的充分条件。然而,许多MCMC算法在实践中满足由等式(7)定义的详细平衡条件。该详细平衡条件是平衡条件的特殊情况。
详细平衡条件保证了收敛,尽管该详细平衡条件不是必不可少的条件。
在QUBO模型中满足详细平衡条件的简单方法是随机提出其值要被翻转的离散变量。在下文中,将该方法称为随机方法。在这种情况下,由等式(8)给出详细平衡条件。
在等式(8)中,ψ(x)是与x的汉明距离为1的所有N个状态的集合。
在QUBO模型中存在用于按顺序顺序地提出而非随机提出其值要被翻转的离散变量的另一方法(顺序方法)。换言之,在第k次迭代中,提出第r个离散变量用于值翻转。此处,k≡r–1(mod N)。
尽管该方法违反了详细平衡条件,但是该方法满足平衡条件,并且因此保证收敛(参见,例如,R.Ren和G.Orkoulas,“Acceleration of markov chain monte carlosimulations through sequential updating”,The Journal of Chemical Physics,2006年,第124卷,第6期,第064109页)。另外,例如,A.Barzegar等人,“Optimization ofpopulation annealing monte carlo for large-scale spin-glass simulations”,Phys.2018年11月,E版,第98卷,第053308页教导了:随着问题规模增加,顺序方法比随机方法更有效。此外,顺序方法不需要用于提议阶段的随机数生成器,这使得顺序方法比需要随机数生成器的随机方法更容易实现。另外,与随机方法相比,顺序方法实现了更快的计算。
(群体退火方法)
根据本实施方式的数据处理装置使用群体退火方法来搜索针对组合优化问题的解。现在将描述群体退火方法。
在群体退火方法中,根据玻尔兹曼分布的MCMC采样在高温下(β
等式(9)的评估值归一化成等式(10)。
然后,使用等式(10)的评估值τ
将β改变成β'=β+Δβ之后,群体规模(副本计数)根据等式(12)轻微波动。
/>
图3示出了用于群体退火方法的整体算法的示例。
输入是权重系数矩阵w、偏置系数矩阵b、副本计数R、起始逆温度β
首先,β被设置成β
然后,对于t=1至N
当u达到θ时,以上述方式为每个副本计算评估值W
图4示出了用于重新采样处理的算法的示例。
首先,使表示通过复制创建的新副本的初始状态的向量变量x
在j被初始化成零之后(行22),对于i=1至R
当i达到R
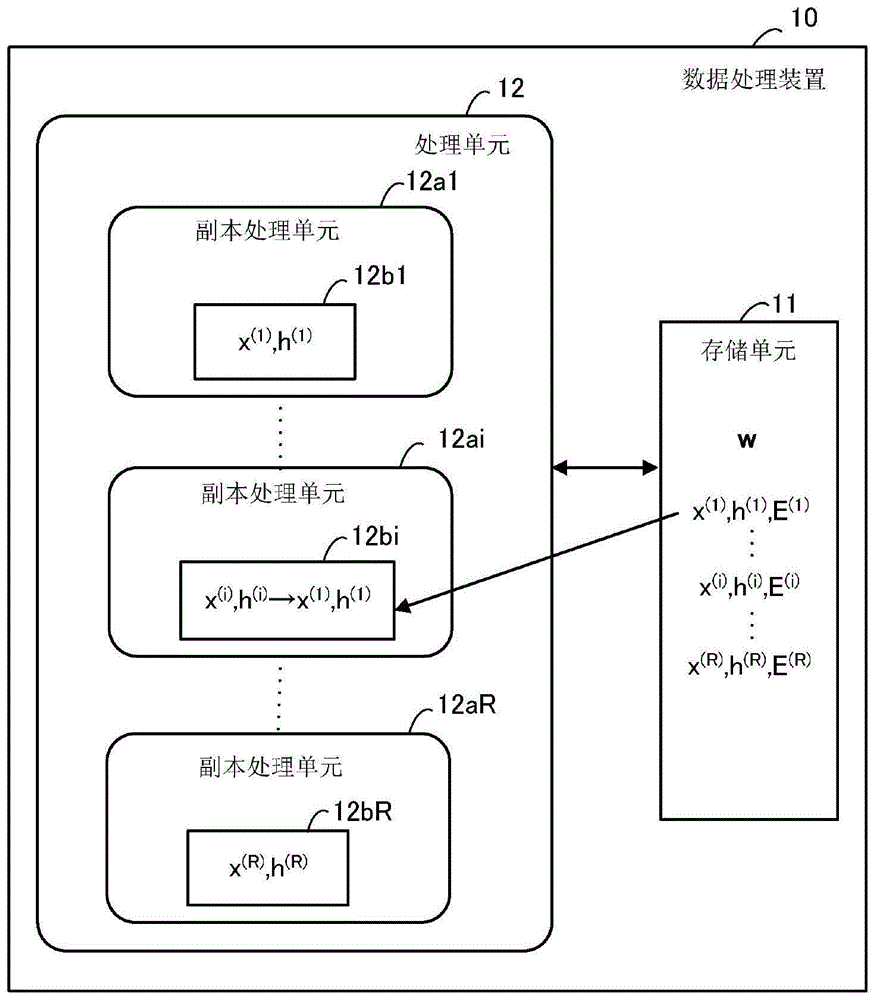
图5示出了根据本实施方式的使用群体退火方法搜索针对组合优化问题的解的数据处理装置的示例。
数据处理装置10例如是计算机,并且包括存储单元11和处理单元12。
存储单元11例如是作为诸如动态随机存取存储器(DRAM)的电子电路的易失性存储装置,或者作为诸如硬盘驱动器(HDD)或闪存的电子电路的非易失性存储装置。存储单元11可以是高带宽存储器(HBM)。另外,存储单元11可以包括诸如静态随机存取存储器(SRAM)寄存器的电子电路。
存储单元11保存相对于玻尔兹曼机的每个副本的x
使用局部字段将由等式(5)给出的能量增量重新公式化成等式(14)。
ΔE
就此而言,等式(5)表示当x
在图5中,针对R个副本中的第i个副本的x
就此而言,存储单元11还保存作为关于评估函数的信息的权重系数矩阵w和副本的能量E
处理单元12由作为诸如中央处理单元(CPU)、图形处理单元(GPU)或数字信号处理器(DSP)的硬件装置的处理器来实现。替选地,处理单元12可以由诸如专用集成电路(ASIC)或FPGA的电子电路来实现。例如,处理单元12执行存储在存储单元11中的程序以使数据处理装置10执行解搜索。就此而言,处理单元12可以是多个处理器的集合。
处理单元12包括分别运行玻尔兹曼机的副本的多个副本处理单元。图5示出了运行R个副本的R个副本处理单元12a1至12aR。例如,副本处理单元12a1至12aR由R个处理器或R个处理器核实现。就此而言,考虑到在重新采样处理中副本计数增加的可能性,可以提供多于R个副本处理单元12a1至12aR。
另外,副本处理单元12a1至12aR中的每一个都设置有存储单元。例如,副本处理单元12a1设置有存储单元12b1,副本处理单元12ai设置有存储单元12bi,以及副本处理单元12aR设置有存储单元12bR。
每个存储单元12b1至12bR都具有比存储单元11小的容量,但是被设计为比存储单元11更快的访问。例如,使用作为诸如SRAM寄存器(或高速缓冲存储器)的电子电路的易失性存储装置。就此而言,每个存储单元12b1至12bR可以是单个存储装置中的存储空间。
每个存储单元12b1至12bR在其中存储多个相对应的离散变量的值和多个相对应的局部字段的值。例如,当副本处理单元12a1运行第一个副本时,存储单元12b1在其中存储x
由于在MCMC更新处理的每次迭代下都访问存储单元12b1至12bR以更新局部字段,因此权重系数矩阵w可以存储在存储单元12b1至12bR中。然而,由于权重系数矩阵w太大而无法存储在SRAM寄存器或高速缓冲存储器中,因此在图5的示例中将其存储在存储单元11中。
就此而言,存储单元12b1至12bR可以设置在处理单元12的外部。
副本处理单元12a1至12aR基于温度参数的设定值(在下文中简称为温度)和存储在相对应的存储单元12b1至12bR中的h
每当更新处理的迭代数目达到预定值时,处理单元12基于多个离散变量的值和多个副本的能量E执行重新采样处理。例如,重新采样处理是根据图4中呈现的算法执行的。另外,当通过对多个副本中的第一副本进行复制来创建第二副本时,处理单元12从存储单元11读取针对第一副本的多个离散变量的值和多个局部字段的值,并将所述值存储(复制)在针对副本处理单元12a1至12aR中的要运行第二副本的副本处理单元提供的存储单元中。
例如,现在考虑在重新采样处理中第i个副本被消除且第一个副本被复制的情况。在这种情况下,例如,如图5所示,x
就此而言,在以上情况下,处理单元12可以从与第一副本相对应的存储单元而非存储单元11中读取针对第一副本的多个离散变量的值和多个局部字段的值,并且可以将所述值存储在针对要运行第二副本的副本处理单元提供的存储单元中。
以上处理消除了每次执行重新采样处理时的对复制副本的局部字段进行重新计算的需要。这降低了计算成本、提高了计算效率、并且改善了问题解决性能,即使在使用大量副本搜索针对大规模组合优化问题的解时也是如此。
图6是示出关于使用群体退火方法的解搜索处理的过程的示例的流程图。图6示出了根据用于图3中呈现的群体退火方法的整体算法的搜索处理的流程。
首先,设置各种参数(步骤S10)。在步骤S10处,设置了权重系数矩阵w、偏置系数矩阵b、副本计数R、起始逆温度β
然后,处理单元12确定初始操作参数(步骤S11)。例如,处理单元12将β=β
此后,处理单元12设置初始状态(步骤S12)。例如,处理单元12随机确定x
然后,从t=1起重复温度循环(步骤S13至步骤S21)直至t 在步骤S16处,例如,处理单元12根据图2中呈现的MCMC算法执行MCMC更新处理。 当u达到θ时,处理单元12根据等式(9)计算评估值W 当搜索完成时,数据处理装置10可以输出搜索结果(例如,最低能量值和提供最低能量值的状态x)。例如,搜索结果可以显示在连接至数据处理装置10的显示设备上,或者可以发送至外部装置。 就此而言,通过示例的方式,重复图6的步骤S14至步骤S19以按顺序运行副本。替选地,图5所示的副本处理单元12a1至12aR可以用于针对R个副本并行执行步骤S15至步骤S18。 图7是示出关于重新采样处理的过程的示例的流程图。 首先,从i=1起重复副本循环(步骤S30至步骤S34)直至i 在步骤S31处,处理单元12根据等式(10)计算评估值τ 之后,处理单元12确定是否rand()>τ 如果没有获得rand()>τ 当i达到R 之后,从i=1起重复副本循环(步骤S36至步骤S41)直至i 在步骤S38处,处理单元12复制副本。在步骤S38处,处理单元12将从存储单元11读取的第i个副本的状态x 然后,处理单元12将j+1替换成j(步骤S39)。如果t还没有达到c 如果t已经达到c 当i已经达到R 通过步骤S38和步骤S42执行上述处理,从存储单元11读取关于第一副本的多个离散变量的值和多个局部字段的值,并且将所述值存储在副本处理单元12a1至12aR中要运行第二副本的副本处理单元的存储单元中。 然后,处理单元12将β更新成β+Δβ(步骤S43),并且过程移动至图6的步骤S21。 就此而言,通过示例的方式,重复图7的步骤S30至步骤S34以按顺序运行副本。替选地,图5所示的副本处理单元12a1至12aR可以用于针对R个副本并行执行步骤S31至步骤S33。 另外,图6和图7所示的处理顺序作为示例并且可以适当地改变。 (并行MCMC算法) 在MCMC算法中,由于移动会显著地增加能量或温度非常低,因此在蒙特卡罗模拟期间,许多提出的MCMC移动可能会被拒绝。这在解决组合优化问题方面是浪费的,因为系统长时间处于相同的状态下。 图8示出了MCMC模拟对最大切割问题的接受率的示例。图8示出了使用作为最大切割实例的最大切割G54的示例(参见,例如,Y.ye,“Gset Max-Cut Library”,2003年,[2022年6月28日搜索],互联网<网址:https://web.stanford.edu/~yyye/yyye/Gset/>)。横轴表示逆温度,而纵轴表示接受率。 如图8中可见,逆温度为2.0或更高(超过整个模拟的一半)时的接受率小于10%。这意指超过90%的MCMC模拟迭代被浪费了。 为了避免提出的MCMC移动被拒绝,使用并行MCMC算法。替代提出翻转单个离散变量的值(单个MCMC移动)并确定是否接受该提议,并行MCMC算法评估并行翻转所有离散变量的相应值的接受率(该阶段被称为试验阶段)。之后,并行MCMC算法基于其接受率翻转离散变量中之一的值。该方法加快了采样问题中到目标分布的收敛,或者组合优化问题中全局最小值状态的检测。 下面使用两种并行MCMC算法作为示例。 (均匀选择MCMC算法) 在试验阶段之后,执行选择阶段。在选择阶段处,均匀选择MCMC算法并行生成针对相应离散变量的随机数,并且根据等式(4)确定离散变量的值翻转是否可能被接受。如果存在已经接受用于值翻转的多个离散变量,则均匀选择MCMC算法以均匀概率随机选择这些离散变量中之一,并翻转所选择的离散变量的值。 该方法不能保证收敛至均衡分布(参见,例如,非专利文献9)。事实上,随机地提出单个离散变量的值的翻转并确定是否接受,这与并行评估所有离散变量的值的翻转并随机选择被接受用于值翻转的离散变量中之一不同。 为了在实现并行处理的硬件中实现以上选择阶段,可以使用对被接受用于值翻转的成对离散变量进行比较并选择一个离散变量的并行归约树(参见,例如,非专利文献8)。该并行归约树随机地选择被接受用于值翻转的成对离散变量中之一。 图9示出了并行归约树的示例。 图9示出了用于具有六个离散变量(x 因此,并行归约树没有实现公平的均匀选择,并且可能导致错误分布。 (跳转MCMC算法) 为了解决上述均匀选择MCMC算法的收敛问题,开发了跳转MCMC算法(参见,例如,非专利文献9)。在试验阶段之后,根据等式(4)计算翻转第i个离散变量x 以p 由于p(x|x)=0,因此在翻转x p[M(x)=m]=α(x)(1-α(x)) 在等式(16)中,α(x)表示从状态x逃离的概率并且由等式(17)给出。 结果,代替常规样本,跳转MCMC算法产生加权样本,并且每个样本的权重等于其多重性。按等式(18)计算状态x的多重性的期望值。 虽然跳转MCMC算法解决了均匀选择MCMC算法的收敛问题,但是每个状态的多重性计算导致了额外的开销。此外,跳转MCMC算法使用随机地提出用于值翻转的离散变量的随机方法,并且效率低于顺序方法的效率。 顺序方法应用于稀疏连接的自旋玻璃模型并且实现了比随机方法快的操作(参见,非专利文献10和11)。然而,顺序方法尚未作为并行MCMC算法应用于全连接的玻尔兹曼机。 例如,本实施方式的数据处理装置10能够采用下面的顺序选择MCMC算法。 图10示出了顺序选择MCMC算法的示例。 输入是状态x、能量E、逆温度β、权重系数矩阵w、偏置系数矩阵b、以及其值被最后更新的神经元(离散变量)的标识号(索引)k。输出是状态x和能量E。 对于i=1至N,并行执行行2至行12的操作。在行2中,根据等式(5)计算ΔE 在行4中,生成在0至1范围中的均匀随机数r,以及在行5中,将带有标识号i的离散变量的整数标志值f 之后,如果p 在行14中,基于所获得的标志值并使用将要描述的并行最小归约树来确定要更新的离散变量(由标识号j标识)。 之后,如果f 如上所述,与其他并行MCMC算法中一样,在顺序选择MCMC算法中,首先,在试验阶段并行处理所有离散变量。在试验阶段之后,从标识号k之后的标识号中选择首先被接受用于值翻转的离散变量的标识号(k旁边的最小值)。为了加速该选择,可以使用并行最小归约树(参见,例如,M.Harris,“Optimizing Parallel Reduction in CUDA”,NVIDIADeveloper Technology,2007年)算法。 图11示出了并行最小归约树的示例。 图11示出了用于具有六个离散变量(x 与使用并行归约树的情况一样,在使用并行最小归约树选择用于翻转的离散变量时,比较成对的离散变量并选择一个离散变量。注意,在并行最小归约树中,从成对的离散变量中选择具有较小的标志值f 由等式(19)表示分配给具有标识号i的离散变量的标志值f 利用等式(19),将小的标志值f 如图11所示,k起初为零。在在第一试验阶段x 在在下一个试验阶段x 下面使用流程图总结由本实施方式的数据处理装置10执行的顺序选择MCMC算法的过程。在执行群体退火的数据处理装置10中,处理单元12的副本处理单元12a1至12aR能够并行单独执行下面的处理。 图12是示出关于顺序选择MCMC算法的过程的示例的流程图。图12示出了基于在图10中呈现的顺序选择MCMC算法的处理流程。 首先,副本处理单元12a1至12aR从i=1起执行试验循环(步骤S50至步骤S58)直至i 在试验循环中,副本处理单元12a1至12aR根据等式(14)计算ΔE 如果p 如果在步骤S54处没有获得pi>r,或者如果在步骤S56或步骤S57之后i尚未达到N,则副本处理单元12a1至12aR将i递增1并且过程返回至步骤S51。 当i达到N时,副本处理单元12a1至12aR使用上述并行最小归约树确定要更新的x 之后,副本处理单元12a1至12aR确定是否f 就此而言,在图12中,副本处理单元12a1至12aR可以对多个i并行执行步骤S50至步骤S58。 图12的处理顺序作为示例并且可以适当地改变。 (实验示例) 下面描述了用于对利用群体退火实现的顺序选择MCMC算法、均匀选择MCMC算法和跳转MCMC算法之间的性能进行比较的实验结果。 在下面的实验示例中,具有80个流式多处理器(SM)的GPU被用作处理单元12。每个SM具有能够并行执行命令的64个处理器内核。图5所示的副本处理单元12a1至12aR是通过多个线程块实现的。每个线程块包括多个线程。编译器自动地将每个线程块分配给SM,并且将每个线程分配给处理器内核。 图13示出了GPU实现方式的示例。在图5中使用的相同的附图标记被赋予图13中的相对应的部件。 图13示出了线程块1至R分别对应于副本处理单元12a1至12aR的示例。在该实验示例中,图5所示的每个存储单元12b1至12bR是线程块内的所有线程都可以访问的芯片上共享存储器。可以通过该共享存储器进行线程块内的线程之间的通信。 在将一个线程专用于一组ν个离散变量的情况下,线程的数目为N/ν。在在一个线程块中的线程的最大数目为1024且N大于1024的情况下,ν>1成立。在下面的实验示例中,使用了ν=16。 在并行MCMC算法的每次迭代中,每个线程评估将离散变量中之一的向该离散变量分配的值翻转的概率p 图14示出了执行线程块中的线程的示例。 图14示出了在运行第i个副本的副本处理单元12ai(与线程块i相对应)中执行线程的示例。在并行试验阶段,N/ν线程并行执行试验并将标志f 在均匀选择MCMC算法中标志为0或1,在跳转MCMC算法中标志为由等式(15)给出的概率,以及在顺序选择MCMC算法中标志根据等式(19)计算。 然后,执行归约树阶段。在图14中在竖直方向上的每个组中的线程一起同步。每个线程选择两个标志中的一个。 首先,利用精确已知的玻尔兹曼分布针对大规模问题测试以上三种MCMC算法的收敛性。然后,使用这些MCMC算法中的每一个计算最大切割实例。 具有双模态紊乱的二维伊辛模型是用于测试以上MCMC算法的适当基准,因为它是完全可解的。该问题使用其值为-1或+1的N个离散变量以及其值为-1、0或+1的N×N权重系数。当N个离散变量以二维网格布置时,每个离散变量与该离散变量的上、下、左和右四个相邻离散变量之间的每个权重系数被随机地设置成-1或+1,并且所有其他权重系数都被设置成零。 使用预先已知的能量分布生成1024自旋二维伊辛模型实例。通过等式(20)给出能量分布。 此处,实例具有两个基态:所有的1024个离散变量的值都为+1的状态;以及所有的1024个离散变量的值都为-1的状态。 以上三个MCMC算法中的每一个都以R=640个副本在T=1/β=10下运行,并且运行达N 图15A至图15C示出了关于均匀选择MCMC算法、顺序选择MCMC算法和跳转MCMC算法的样本的能量直方图的实验结果的示例。横轴表示能量,而纵轴表示概率。 图15A至图15C示出了除了关于MCMC算法的能量直方图之外的正确分布。 如图15A至图15C中可见,关于均匀选择MCMC算法的样本的能量直方图与正确分布有很大偏差。相比之下,关于由本实施方式的数据处理装置10执行的顺序选择MCMC算法的样本的能量直方图几乎与正确分布匹配,并且跳转MCMC算法也是如此。因此,顺序选择MCMC算法和跳转MCMC算法二者都产生正确的样本。 下面描述利用以上三种MCMC算法对从上述“Gset Max-Cut Library”取得的最大切割问题中的60个实例进行计算的实验结果。 最大切割问题旨在将图G的节点着色为黑色和白色,以使连接黑色节点和白色节点的边的权重之和被最大化。最大切割问题的QUBO能量函数由等式(21)表示。 在等式(21)中,e表示图G中的边的集合,以及e 就此而言,等式(21)可以变换成等式(1)的形式。 为了比较以上三种MCMC算法在最大切割问题上的性能,使用最佳值(最佳切割值)和平均值(平均切割值)。对于每个实例,每个MCMC算法运行100次,并且使用表1中列出的参数。 表1 在表2至表4中呈现模拟结果。 表2 表3 表4 表2至表4中的G1至G60是实例名称(“名称”)。“顺序”指示顺序选择MCMC算法的模拟结果,“跳转”指示跳转MCMC算法的模拟结果,以及“均匀”指示均匀选择MCMC算法的模拟结果。就此而言,在最佳切割值的结果中的括号中的每个值表示获得最佳切割值的次数(点击次数)。 就此而言,例如,从下面的参考文献1至4中取得最佳已知解(BKS)。 (参考文献1)Fuda Ma和Jin-Kao Hao,“A multiple search operator heuristicfor the max-k-cut problem”,Annals of Operations Research,2017年,248(1),第365页至第403页 (参考文献2)V.P.Shylo,O.V.Shylo和V. (参考文献3)Fuda Ma,Jin-Kao Hao和Yang Wang,“An effective iterated tabusearch for the maximum bisection problem”,Computers and Operations Research,2017年,81,第78页至第89页 (参考文献4)Qinghua Wu,Yang Wang和Zhipeng Lü,“A tabu search basedhybrid evolutionary algorithm for the max-cut problem”,Applied SoftComputing,2015年,34,第827页至第837页 按等式(22)定义每个实例中的每个MCMC算法的误差。 在等式(22)中,f 图16示出了关于均匀选择MCMC算法、跳转MCMC算法和顺序选择MCMC算法的平均误差的计算结果的示例。横轴表示误差(平均误差)(以百分比为单位),而纵轴指示三种MCMC算法。 图16呈现了针对表2至表4中列出的60个实例的每个MCMC算法的平均误差。如图16中可见,顺序选择算法的平均误差少于均匀选择MCMC算法的平均误差和跳转MCMC算法的平均误差,并且在解决最大切割问题方面更准确。 另外,在执行要描述的簇内并行更新处理的情况下,顺序选择算法比其他算法更容易实现。 (聚类) N个离散变量(神经元)可以包括彼此不耦合的离散变量的集合。 在下面的描述中,将彼此不耦合的n个连续离散变量的集合(神经元集合)称为C={x w 在等式(23)中,i和j表示C内的两个离散变量x 顺序选择MCMC算法的主要优点中之一在于:在确定翻转所有离散变量的值的概率的并行试验阶段中,同一簇内的被接受用于值翻转的所有离散变量都在单次试验中被并行更新。由于均匀选择MCMC算法和跳转MCMC算法随机地提出用于值翻转的离散变量,因此连续迭代的离散变量并不总是属于同一簇,这可能无法一起并行更新离散变量。 为了检测具有权重系数矩阵w和偏置系数矩阵b的QUBO模型问题中的簇,可以使用关于w的图着色问题,前提是为彼此不耦合的离散变量分配相同的颜色。 图17示出了簇的示例。 参照图17的示例,将相同的颜色分配给x 本实施方式的数据处理装置10利用顺序选择MCMC算法使用群体退火将图着色问题作为预处理来解决,由此对离散变量进行聚类(聚类)并检测离散变量的集合(簇)。 使用按等式(24)为预处理定义的权重系数矩阵(带有^标记的w)和偏置系数(带有^标记的b)以QUBO格式定义图着色问题。 /> 按等式(24)定义的权重系数矩阵对QUBO模型能量函数中的每一对耦合的离散变量(w 在MCMC算法的每次迭代中,通过解决预处理QUBO来识别不耦合的离散变量的簇。然后,从权重系数矩阵中去除与该簇相关的权重系数。重复该处理直至识别出所有簇为止。在将期望的离散变量部分分配给簇之后,将离散变量的其余部分分配给单独的簇(每个离散变量被分配给单个簇)。 从权重系数矩阵中去除与簇相关的权重系数以及在每次迭代时存储新的权重系数矩阵导致了额外的开销。为了避免这种情况,数据处理装置10简单地将属于簇的离散变量的偏置系数改变成足够大的数P,这确保了这些离散变量在下一次迭代中不会呈现在簇中。 根据等式(5),由表达式(25)表示由于值翻转引起的最大能量增量。 通过选择满足P>2N的P,离散变量将在下一次迭代中为零。 图18示出了聚类算法的示例。 图18中呈现的算法的输入是按等式(24)为预处理定义的权重系数矩阵(N×N个实数)和偏置系数(N个实数),以及要被着色的离散变量(神经元)的分数f(在0至1的范围中)。输出是着色结果(聚类结果)c(N个自然数的集合)。 首先,将k初始化为零(第1行)。在k 在图18的示例中,在群体退火中使用的参数是副本计数R=640、以及起始逆温度β 对于i=1至N,并行执行第5行和第6行上的操作。在第5行中,将b 当i达到N时,将P递增1(第8行)。根据P确定将哪种颜色分配给每个离散变量(分配哪个簇)。 如果k≥fN,则针对i=1至N执行第11行至第14行上的操作。在第11行至第14行中,如果b 当i达到N时,用b–P替换c(c、b和P均为具有N个元素的列向量)(第16行),并将c返回至调用函数(第17行)。 下面使用流程图总结通过本实施方式的数据处理装置10执行的聚类的过程。 图19是示出聚类的过程的示例的流程图。图19示出了基于图18中呈现的聚类算法的处理流程。 首先,处理单元12生成图着色问题(步骤S70)。如前所述,以QUBO格式定义图着色问题,并且通过获得用于使用等式(24)的预处理的权重系数矩阵和偏置系数来生成图着色问题。 然后,处理单元12将k初始化为零(步骤S71),并确定是否k 在步骤S73处,处理单元12使用由等式(24)给出的权重系数矩阵和偏置系数执行群体退火(在图19中称为PA)。然后,处理单元12从i=1起重复问题更新循环(步骤S74至S76)直至i 在问题更新循环中,处理单元12将b 当i达到N时,处理单元12将P递增1并重复步骤S72和后续步骤。 如果未获得k 在后处理循环中,处理单元12确定b 当i达到N时,处理单元12用b-P替换c(c,b,P均为具有N个元素的列向量),从而获得着色结果c(步骤S82)。现在完成聚类。 就此而言,图19的处理顺序作为示例并且可以适当的改变。 图20A和图20B示出了聚类之前和聚类之后的权重系数矩阵的示例。图20A和图20B均示出了G54的权重系数矩阵,其为N=1000的最大切割问题的实例。以黑色表示除了零以外的权重系数,以及以白色代表零权重系数。对聚类之后的权重系数矩阵进行重新排序,使得同一簇中的离散变量的标识号(i或j)定位成彼此相邻。 就此而言,在图13所示的实现方式中,添加了与其他离散变量不耦合的8个离散变量,从而以ν=16执行聚类。因此,i和j中的每一个最大为1008。对于聚类,图18中呈现的算法以N 作为聚类的结果,除了如图20B所示的分别包括346、250、160、104、58和40个离散变量的六个簇之外,通过图19的步骤S72至S77识别未示出的三个簇。之后,获得不属于任何簇的九个离散变量。这些离散变量通过图19的步骤S78至S81被识别为不同的簇。 使用如上所述的聚类结果,上述顺序选择MCMC算法可扩展成下面的算法(称为聚类顺序选择MCMC算法)。 图21示出了聚类顺序选择MCMC算法的示例。 输入是状态x、能量E、逆温度β、权重系数矩阵w、偏置系数矩阵b、关于m个簇C 以与图10中呈现的顺序选择MCMC算法相同的方式执行第1行至第14行上的操作。 在第15行中,获得了x 在第17行至第20行中,如果i≥j且f 下面使用流程图来总结由本实施方式的数据处理装置10进行的聚类顺序选择MCMC算法的过程。 图22是示出关于聚类顺序选择MCMC算法的过程的示例的流程图。图22示出了基于图21中呈现的聚类顺序选择MCMC算法的聚类步骤和处理流程。 处理单元12如图19所示执行聚类(步骤S90)。然后,在执行群体退火的数据处理装置10中,处理单元12中的副本处理单元12a1至12aR单独执行下面的处理。 副本处理单元12a1至12aR执行并行试验(步骤S91)。以与图12的步骤S50至S58相同的方式执行并行试验。然后,副本处理单元12a1至12aR执行与图12的步骤S59相同的步骤S92。 副本处理单元12a1至12aR获得其值将被翻转的x 图23是示出关于簇内并行更新处理的过程的示例的流程图。图23示出了基于图21中呈现的聚类顺序选择MCMC算法的处理流程。 副本处理单元12a1至12aR从i=j起执行簇内循环(步骤S100至S103)直至i 副本处理单元12a1至12aR确定是否f 当i达到j+N 就此而言,在图23中,副本处理单元12a1至12aR针对多个i并行执行步骤S100至S103。 (实验示例) 下面呈现关于对聚类顺序选择MCMC算法的效果进行验证的实验结果。 图24示出了使用聚类顺序选择MCMC算法和非聚类顺序选择MCMC算法的最大切割问题的模拟结果。横轴表示表时间(秒),而纵轴表示能量。 在该实验示例中,使用了最大切割实例G54。节点数为N=1008。在群体退火中的计算条件包括副本计数R=640、起始逆温度β 聚类顺序选择MCMC算法产生与非聚类顺序选择MCMC算法相同的结果(相同的最低能量),但是实现了比非聚类顺序选择MCMC算法获得结果快达三倍的加速。 下面呈现了关于在更多一些实例上聚类顺序选择MCMC算法相对于非聚类顺序选择MCMC算法的加速的实验结果。就此而言,对于聚类,在所有实例的计算中使用N 所有实例均以与用于获得图24中呈现的实验结果的相同计算条件运行。 表5 表5呈现了关于针对从表2至表4中列出的实例中选择的多个实例的聚类顺序选择MCMC算法相对于非聚类顺序选择MCMC算法的加速的实验结果。就此而言,t (群体退火方法与其他MCMC算法的比较) 在下面,使用模拟退火方法(以下称为“SA”)和平行回火方法(以下称为“PT”)作为其他MCMC算法。另外,在下文中将群体退火方法称为“PA”。 与使用固定温度的Metropolis算法不同,SA从足够高的温度(β 尽管SA最初不是基于群体的方法,但是SA通常以R次独立运行或以R个副本并行运行,以便能够与其他基于群体的算法PT和PA进行公平比较。期望将找到至少一个全局最小值状态。此处,R是群体规模(相当于PA和PT中的副本计数)。在SA中,如果状态在某个温度下陷入局部最小值,那么状态很可能会保持在那里直至模拟结束,因为降低温度会使得从局部最小值中逃离更难。 在PT中,玻尔兹曼机的R个副本并行运行。每个副本在根据预定义的温度阶梯选择的不同固定温度下执行MCMC采样。在每次MCMC迭代之后,相邻温度下的副本提议交换它们的温度。通过等式(27)给出交换接受概率(SAP)。 /> 在等式(27)中,i和j是具有相邻温度的两个副本的标识号,而E 与以上PT不同,PA中的多个副本与温度的选择无关。也就是说,在β (应用于三个不同的组合优化问题) 下面处理二次分配问题(QAP)、最大切割问题和旅行商问题(TSP)。 QAP是将n个设施分配给n个位置(每个设施分配给一个位置)以使位置之间的距离和设施之间的流量的乘积之和最小化的问题。通过等式(28)表示QAP的评估函数(能量函数)。 在等式(28)中,x 先前已经使用等式(21)等对最大切割问题进行了描述。 TSP是以下的问题:该问题旨在访问n个城市,每个城市一次,并且返回至第一个城市,从而使总旅行距离最小化。通过等式(29)表示TSP的评估函数(能量函数)。 在等式(29)中,x 等式(28)和等式(29)可转换成等式(1)。在这种情况下,x 如先前所提及的,SA的群体规模可以指指示有多少个副本在并行运行的副本计数。在SA中的单个副本能够以概率P P 由于PT在温度阶梯大小为r的情况下执行k次复制,因此由等式(31)给出成功概率P P 在等式(31)中,P PA的行为不同于SA和PT的行为,并且PA的性能是使用不同的问题进行实验测量的。例如,在将具有大量处理器核的大规模并行硬件用作处理单元12的情况下,PA表现出比SA和PT的性能更高的性能。即,期望由等式(32)表示PA的成功概率P P 在表达式(32)中,P (针对QAP的实验) 图25示出了针对QAP执行SA、PT和PA的模拟结果。横轴表示群体规模,而纵轴表示成功概率。 另外,图26示出了在PT中温度阶梯大小与成功概率之间的关系。横轴表示温度阶梯大小,而纵轴表示成功概率。就此而言,在图26中,群体规模为2560。 使用的实例是从QAPLIB即标准QAP基准库中取得的esc32实例(参见,RainerE.Burkard,Stefan E.Karisch,和Franz Rendl,“Qaplib–a quadratic assignmentproblem library”,Journal of Global Optimization,1997年,10(4),第391页至第403页)。 在这种情况下,n=32,N=1024,并且最优解是已知的。SA、PT、PA中的所有均以每个副本5×10 针对温度阶梯大小r=16呈现PT结果。实验发现这是最优配置,如图26中可见。在200次运行中在R=2560的情况下测量SA和PT的成功概率。成功概率分别符合等式(30)和等式(31)。在PA的情况下,在200次运行中在不同的群体规模的情况下测量成功概率。 如图25中可见,SA、PT和PA在小规模群体下表现出相似的性能。然而,随着群体规模增加,PA的性能比SA和PT的性能提高了更多,并且实现了由表达式(32)给出的成功概率。 在PA中成功概率变为99%的群体规模比在PT中的群体规模小3.8倍且比在SA中的群体规模小10.2倍。 (针对最大切割问题的实验) 图27示出了关于SA、PT和PA在最大切割问题(G33)上的性能的模拟结果。横轴表示群体规模,而纵轴表示平均切割值。 另外,图28示出了关于SA、PT和PA在最大切割问题(G53)上的性能的模拟结果。横轴表示群体规模,而纵轴表示针对解的平均迭代(ITS)即获得最佳已知解(BKS)的MCMC迭代数。 G33和G53实例是从先前提及的“Gset Max-Cut Library”中取得的。这些实例由以上列出的参考文献1进行基准测试。G33的N=2000,以及G53的N=1000。G33和G53的BKS也是从参考文献1中取得的。 针对两个实例设置了β 图27表示在SA、PT和PA中在100次运行(具有3×10 在图28中,PT表现出更好的性能,并且PT在小的群体规模(R=64)下比PA快大约3.3倍。然而,随着群体规模增加,PA的平均ITS比PT的平均ITS下降得更快。当群体规模为320时,PA比PT更快。当群体规模为1280时,PA比PT快2.5倍且比SA快10.8倍。 (针对TSP的实验) 图29示出了关于SA、PT和PA针对TSP的性能的模拟结果。横轴表示PA中的平均ITS,而纵轴表示平均ITS值。 图29示出了10个随机生成的具有32个城市的TSP实例(N=1024)中的平均ITS值。BKS是使用已知TSP求解器验证的值。在该实验中,所有实例都在R=1280、最优温度阶梯大小以及相同的β 如图29中可见,PA在所有的10个实例中都优于SA和PT,并且比PT快达4倍且比SA快达9倍。 如前所述,本实施方式的数据处理装置10使用PA解决组合优化问题,PA表现出如上所述的更好性能。如参照图5所描述的,本实施方式的数据处理装置10消除了在重新采样处理的每次迭代下重新计算对于复制副本的局部字段的需求。这甚至在群体规模(副本计数)R大的情况下也降低了计算成本,由此,与SA和PT相比,PA获得了更显著的性能提升并且提高了计算效率和改善了问题解决性能。 (使用数据处理装置10验证效果) 下面呈现了使用数据处理装置10验证效果的结果。 在下面的验证中,使用如图13所示配置的数据处理装置10。另外,使用具有80个SM的GPU作为处理单元12。每个SM具有能够并行执行指令的64个处理器核。 现在将呈现在该验证中使用的算法(在下文中称为并行的基于群体的玻尔兹曼机(PBBM)算法)。 图30示出了PBBM算法的示例。 输入与图3中呈现的PA算法中的输入相同。输出是找到的最低能量和具有最低能量的状态。PBBM算法的处理总结如下。 在β 用于第i副本的标志向量f 使用“Parallel_Reduction”表示的并行归约算法使用标志向量f 在x 图31示出了每个副本10 就此而言,图31示出了相对于多个不同的玻尔兹曼大小N(离散变量数)的运行时间与群体规模之间的关系。在N为1024或更大的情况下,图13中的ν被设置成ν=16。在N小于1024的情况下,ν被设置成ν=8。 如图31中可见,在N为1024或更少的情况下,高达640的群体规模(副本计数)的运行时间仅比80的群体规模的运行时间长最多27%。 图32示出了可以在整个群体中在一秒内运行的MCMC迭代的峰值数。横轴表示玻尔兹曼大小(离散变量数),而纵轴表示每秒MCMC迭代数。 在图32中,为了比较,在能够处理N≤1024的玻尔兹曼大小的非专利文献8(具有并行试验的PT的FPGA实现方式)中报告的峰值数由“常规”指示。PA重新采样和PT交换移动二者的开销可忽略不计,并且主要的性能标准是在一秒内可以运行多少次MCMC迭代。 (针对各种最大切割实例的与其他求解器的性能的比较示例) 在该实验示例中,将来自前述“Gset Max-Cut Library”的最大切割实例用作基准。 下面呈现了与报告了达到BKS的平均时间的下面的文献A至G中的最大切割求解器的比较结果。 文献A(与以上列出的参考文献1相同):Fuda Ma和Jin-Kao Hao,“A multiplesearch operator heuristic for the max-k-cut problem”,Annals of OperationsResearch,2017年,248(1),第365页至第403页 文献B(与以上列出的参考文献4相同):Qinghua Wu,Yang Wang,和Zhipeng Lü,“Atabu search based hybrid evolutionary algorithm for the max-cut problem”,Applied Soft Computing,2015年,34,第827页至第837页 文献C(与以上列出的参考文献3相同):Fuda Ma,Jin-Kao Hao,和Yang Wang,“Aneffective iterated tabu search for the maximum bisection problem”,ComputersOperations Research,2017年,81,第78页至第89页 文献D(与以上列出的参考文献2相同):V.P.Shylo,O.V.Shylo,和V.à.Roschyn,“Solving weighted max-cut problem by global equilibrium search”,Cyberneticsand Systems Analysis,2012年7月,第48卷,第4期,第563页至第567页 文献E:A.Yavorsky等人,“Highly parallel algorithm for the ising groundstate searching problem”,2019年7月16日,arXiv:1907.05124v2[quant-ph] 文献F:Yu Zou和Mingjie Lin,“Massively simulating adiabaticbifurcations with fpga to solve combinatorial optimization”,FPGA’20:Proceeding of the 2020ACM/SIGDA International Symposium on Field-ProgrammableGate Arrays,2020年2月 文献G:Chase Cook等人,“Gpu-based ising computing for solving max-cutcombinatorial optimization problems”,Integration,the VLSI Journal,2019年,69,第335页至第344页 表6中总结了这些求解器和他们的平台。 表6 表6呈现了相对于以上文献A至G的在以下描述的实验示例中使用的每个求解器的名称、算法、类型和平台(CPU、GPU或FPGA)。就此而言,本实施方式中使用的求解器的名称是“PBBM”。另外,为了与其他求解器进行公平比较,除了PBBM的GPU实现方式之外,还使用了PBBM的CPU实现方式。 类型有两种类型:第1类和第2类。第1类是一种花费足够的运行时间来达到BKS并报告其结果的求解器。第2类是一种花费短的运行时间(在大多数情况下少于一秒)并报告平均切割值的求解器。 为了评估每个求解器的性能,针对每个实例测量了在20次运行中达到最佳已知解(TTS)的平均时间。就此而言,对“Gset Max-Cut Library”实例中的具有N≤3000的G1至G54实例进行了计算。 在PBBM中,所有实例都在β 表7和表8呈现了平均TTS的测量结果。 表7 表8 在求解器在所有20次运行中未能获得实例的BKS的情况下,平均TTS未被定义并且由“X”表示。 如表7和表8中可见,通过本实施方式的数据处理装置10执行的PBBM(GPU实现方式)在54个实例中的51个实例中显著地优于其他求解器。 PBBM是高度并行算法并且是为大规模并行硬件设计的。即使在CPU实现方式的情况下,PBBM也在17个实例中优于所有其他求解器。 图33示出了关于PBBM(GPU实现方式)相对于其他求解器的加速的计算结果。横轴表示加速(等式(26)中的几何平均加速),而纵轴指示要与PBBM(GPU实现方式)进行比较的五个求解器。 如图33中可见,PBBM(GPU实现方式)比其他求解器实现了至少43倍的加速。 就此而言,表7和表8中呈现的平均TTS的测量结果极大地依赖于所使用的编程语言、编译器、编码技能等。为了解决该问题,依照求解器的平均误差对求解器进行比较。按等式(33)定义每个求解器的平均误差。 在等式(33)中,f 另外,依照以100%的置信度求解的实例的数目即其中f 图34示出了第1类求解器的准确度的比较结果。横轴指示五个求解器,而左侧的纵轴表示54个实例的平均误差,以及右侧的纵轴表示在20次运行中甚至一次也没有获得BKS的实例的数目(未以100%置信度求解的实例的数目)。 图34中的左侧栏表示每个求解器的平均误差,以及右侧栏表示上述实例数。PBBM(GPU实现方式)能够以100%置信度求解54个实例中的53个实例,这比所有其他的求解器都多。另外,PBBM(GPU实现方式)的平均误差比其他求解器中的最佳求解器的平均误差小近似八倍,这说明PBBM是最准确的求解器。 由于第2类求解器均为硬件加速求解器,因此在该实验示例中使用PBBM(GPU实现方式)。 报告了作为第2类求解器的MARS、SB和SA在17个实例中达到BKS的平均时间和平均获得的切割值。对于每个实例,将MCMC迭代数设置成致使运行时间等于所有其他求解器中的最少时间的值。每个实例在R=640、β 表9 如表9中可见,PBBM在17个实例中的15个实例中比所有其他求解器实现了更好的平均切割值,即使PBBM在所有实例中花费最少时间。 图35示出了第2类求解器的准确度的比较结果。横轴表示误差(平均误差),而纵轴指示四个第2类求解器。 如图35中可见,PBBM(GPU实现方式)是第2类求解器中最准确的,并且PBBM的误差比其他求解器的误差小约2.5倍。 现在已经完成了对PBBM与其他求解器在各种最大切割实例上的性能的比较结果的描述。 可以通过本实施方式的执行程序的数据处理装置10以软件实现上述处理内容(例如,图6、图7、图12、图19、图22、图23等)。 可以将程序存储在计算机可读存储介质中。存储介质例如包括磁盘、光盘、磁光(MO)盘、半导体存储器等。磁盘包括软盘(FD)和HDD。光盘包括致密盘(CD)、可刻录CD(CD-R)、可重写CD(CD-RW)、数字多功能盘(DVD)、DVD-R、DVD-RW等。可以将程序存储在便携式存储介质中,并且然后分发该程序。在这种情况下,可以将程序从便携式存储介质复制至其他存储介质并且然后执行该程序。 图36示出了作为数据处理装置的示例的计算机的硬件的示例。 计算机20包括处理器21、RAM 22、HDD 23、GPU 24、输入接口25、介质读取器26和通信接口27。这些单元连接至总线。 处理器21用作图5的处理单元12。处理器21是诸如GPU或CPU的处理器,包括执行程序指令的运算电路和诸如高速缓冲存储器的存储电路。处理器21将程序或数据的至少一部分从HDD 23加载至RAM 22并执行该程序。例如,处理器21可以包括用于并行运行多个副本或多个线程的多个处理器核,如图13所示。计算机20可以包括多个处理器。一组多个处理器(多处理器)可以被称为“处理器”。 RAM 22用作图5的存储单元11。RAM 22是在其中临时存储要由处理器21执行的程序和要由处理器21在处理中使用的数据的易失性半导体存储器。例如,RAM 22是HBM等。计算机20可以包括不同于RAM 22的另一类型的存储器或者包括多个存储器。 HDD 23是保存诸如操作系统(OS)、中间件和应用软件的软件程序和数据的非易失性存储设备。例如,程序包括使计算机20如上所述搜索针对组合优化问题的解的程序。就此而言,计算机20可以包括另一类型的存储设备例如闪存或固态驱动器(SSD),或者可以包括多个非易失性存储设备。 GPU 24根据来自处理器21的指令将图像(例如,表示针对组合优化问题的解的搜索结果的图像)输出至连接至计算机20的显示器24a。阴极射线管(CRT)显示器、液晶显示器(LCD)、等离子显示面板(PDP)、有机电致发光(OEL)显示器等可以用作显示器24a。 输入接口25从连接至计算机20的输入设备25a接收输入信号,并且将输入信号输出至处理器21。诸如鼠标、触摸面板、触摸板或轨迹球的指示设备、键盘、远程控制器、按钮开关等可以用作输入设备25a。另外,多种类型的输入设备可以连接至计算机20。 介质读取器26是从存储介质26a读取程序和数据的读取设备。例如,磁盘、光盘、MO盘、半导体存储器等可以用作存储介质26a。磁盘包括FD和HDD。光盘包括CD和DVD。 例如,介质读取器26将从存储介质26a读取的程序和数据复制至诸如RAM 22或HDD23的另一存储介质。例如,读取的程序由处理器21执行。存储介质26a可以是便携式存储介质,并且用于分发程序和数据。存储介质26a和HDD 23可以被称为计算机可读存储介质。 通信接口27连接至网络27a,以便能够通过网络27a与其他信息处理装置通信。通信接口27可以是通过线缆连接至诸如交换机的通信设备的有线通信接口或者通过无线链路连接至基站的无线通信接口。 本公开内容的计算机程序、数据处理装置和数据处理方法的一个方面已经作为实施方式进行了描述。然而,这仅仅是示例,并且不限于以上描述。 根据一个方面,本公开内容有助于降低在使用群体退火方法搜索组合优化问题的解时的计算成本。
- 数据处理方式的确定方法、装置、服务器和数据处理方法
- 用于区块链网络系统的数据处理方法和数据处理装置
- 一种高速追踪扫描共焦显微测量装置和数据处理方法
- 话音数据处理方法以及支持该话音数据处理方法的电子装置
- 一种数据处理方法、装置和用于数据处理的装置
- 数据处理设备、数据处理方法、程序转换处理设备和程序转换处理方法、程序转换处理设备、数据处理设备、程序转换处理方法和数据处理方法、数据处理设备、数据处理方法、程序分析处理设备和程序分析处理方法、数据处理设备、历史保存设备、数据处理方法和程序、以及编译处理设备
- 数据处理装置和数据处理方法、程序和程序记录介质、数据记录介质和数据结构