一种服务器的系统架构
文献发布时间:2023-06-19 19:28:50
技术领域
本发明实施例涉及互联网技术领域,特别是涉及一种服务器的系统架构。
背景技术
在实际的AI(Artificial Intelligence人工智能)训练中,GPU(GraphicsProcessing Unit图形处理单元)卡之间需要大量的参数进行通信,模型越复杂,通信量越大,因此,AI服务器除了要求单卡性能外,还要求多卡间的通信性能,也即是说,CPU(Central Processing Unit中央处理单元)与GPU之间、不同CPU挂载的GPU之间都需要高速互联。
在现有的方案中,虽然能够扩展GPU或者其他存储器,但是通常一组GPU只能定向接收特定的CPU所下发的数据和资源,不同CPU挂载的GPU之间不能互联,会存在不同组的GPU从CPU处获取的数据和资源不均衡的问题,并且如果某一CPU存在故障,则依靠该CPU传输指令和数据的相应组GPU都将不能工作,可靠性受到影响。
发明内容
本发明实施例是提供一种服务器的系统架构,以解决或部分解决一组GPU只能定向接收特定CPU所下发的数据和资源,不同CPU挂载的GPU之间不能互联导致分配给不同组的GPU的数据和资源不均衡和一个CPU发生故障影响传输可靠性的问题。
本发明实施例公开了一种服务器的系统架构,包括CPU和GPU组,所述GPU组包括多个GPU,其中:
不同的所述CPU之间相互连接以实现不同的所述CPU之间的数据通信,所述CPU与所述GPU组的所述GPU连接,其中,同一个所述GPU组中任意相邻的所述GPU分别连接不同的所述CPU以使同一个所述GPU组中的GPU受控于不同的所述CPU,同一个所述GPU组中任意相邻的所述GPU之间互相连接以实现同一个所述GPU组中任意相邻的所述GPU之间的数据通信。
可选地,所述CPU的数量至少包括两个,所述GPU组的数量至少包括两组。
可选地,不同的所述CPU之间通过CPU互联通道连接,所述CPU互联通道用于进行不同的所述CPU之间的数据通信。
可选地,所述CPU的PCIe接口与所述GPU组中所述GPU的转接板进行连接。
可选地,同一个所述GPU组中任意相邻的所述GPU之间通过GPU桥接器进行连接,所述GPU桥接器用于实现同一个所述GPU组中任意相邻的所述GPU之间的数据通信。
可选地,还包括:
当同一个所述GPU组中任意相邻的所述GPU之间的间距符合所述GPU桥接器的预设间距时,通过所述GPU桥接器将同一个所述GPU组中任意相邻的所述GPU进行连接。
可选地,所述CPU用于向不同的所述GPU组中的GPU下发数据和资源。
可选地,同一个所述GPU组包括不同的所述CPU的数据和资源。
可选地,包括:
当任意一个所述CPU出现故障时,若连接故障的所述CPU的其他的所述CPU保持正常运行,则使用正常运行的所述CPU控制故障的所述CPU的GPU。
可选地,还包括:
连接故障的所述CPU的GPU通过同一个所述GPU组中相邻的所述GPU获取正常运行的所述CPU下发的数据和资源。
本发明实施例包括以下优点:
在本发明实施例中,提供了一种服务器的系统架构,包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
附图说明
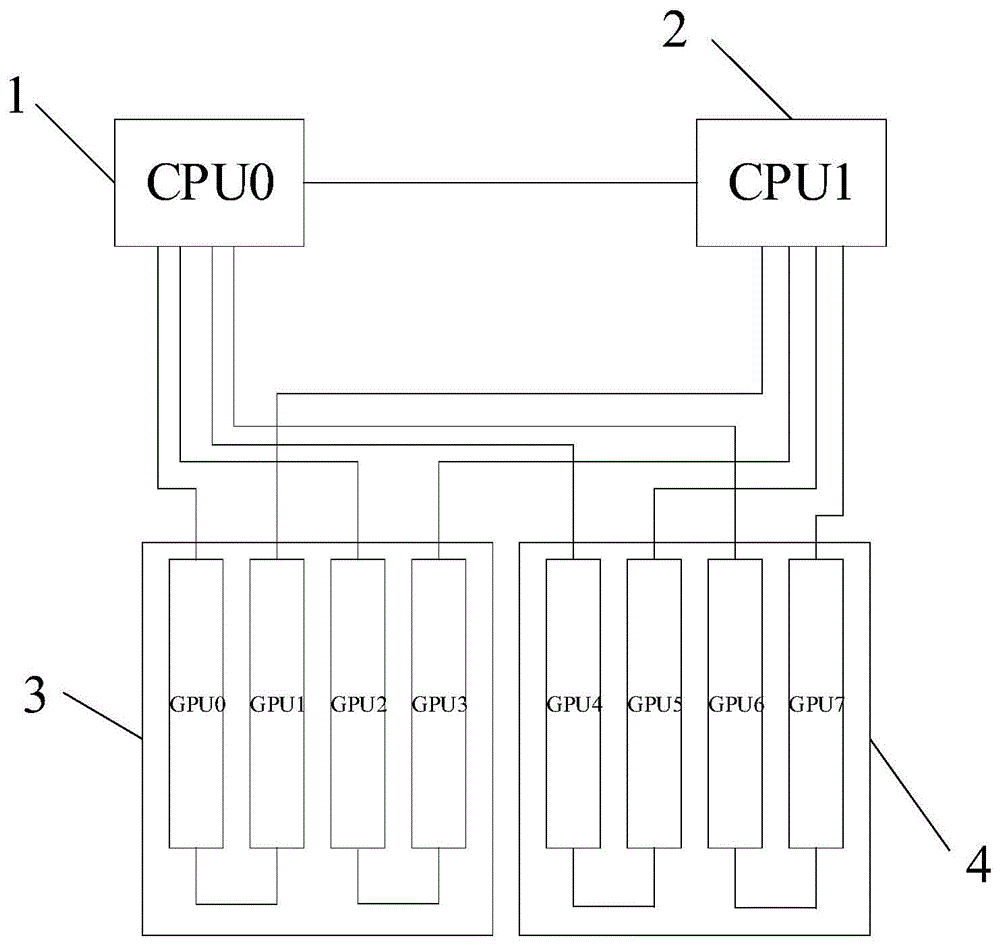
图1是本发明实施例中提供的一种服务器的系统架构的结构框图之一;
图2是本发明实施例中提供的一种服务器的系统架构的结构框图之二。
附图标记:
1、CPU0;2、CPU1;3GPU组1;4、GPU组2。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
为了使本领域技术人员更好地理解本发明实施例的技术方案,下面对本发明实施例中涉及的部分技术特征进行解释、说明:
AI(Artificial Intelligence人工智能),其可以为研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能为计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
GPU(Graphics Processing Unit图形处理单元),又称显示核心、视觉处理器、显示芯片,其可以为一种针对在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。GPU可以使显卡减少对CPU(CentralProcessing Unit中央处理器)的依赖,并进行部分原本CPU的工作,尤其是在3D(3-dimension三维)图形处理时GPU所采用的核心技术有硬件T&L(Transforming&Lighting几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以为GPU的标志。
GPU桥接器(GPU bridge),其可以用于进行多个GPU的互联,以实现任意相邻的GPU之间的数据通信。
PCIe(Peripheral Component Interconnect Express高速串行计算机扩展总线标准),又称PCI-Express,旨在替代旧的PCI(Peripheral ComponentInterconnect外设部件互连标准),PCI-X(PCI的更新版本)和AGP(Accelerated Graphics Port)总线标准。PCIe属于高速串行点对点双通道高带宽传输,所连接的设备分配为独享通道带宽,不共享总线带宽,主要支持主动电源管理,错误报告,端对端的可靠性传输,热插拔以及服务质量(Quality of Service简称QOS)等功能。
CPU(central processing unit中央处理单元),其可以作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。
P2P(Peer to Peer点对点传输),又称对等互联网络技术,是一种网络新技术,依赖网络中参与者的计算能力和带宽,而不是把依赖都聚集在较少的几台服务器上,P2P网络通常用于通过Ad Hoc(点对点)连接来连接节点。
显卡(Video card、Display card、Graphics card、Video adapter),是个人计算机基础的组成部分之一,将计算机系统需要的显示信息进行转换驱动显示器,并向显示器提供逐行或隔行扫描信号,控制显示器的正确显示,是连接显示器和个人计算机主板的重要组件,其内置的并行计算能力现阶段也用于深度学习等运算。
SXM,允许GPU通过Nvidia(英伟达)的NVLink(一种高带宽、节能的互连)相互之间进行通信或与CPU进行通信,其数据传输速度比PCIe快。
作为一种示例,在实际的AI训练中,GPU卡之间需要大量的参数进行通信,模型越复杂,通信量越大,因此,AI服务器除了要求单卡性能外,还要求多卡间的通信性能,也即是说,CPU与GPU之间、不同CPU挂载的GPU之间都需要高速互联。在现有的方案中,虽然能够扩展GPU或者其他存储器,但是通常一组GPU只能定向接收特定的CPU所下发的数据和资源,不同CPU挂载的GPU之间不能互联,会存在不同组的GPU从CPU处获取的数据和资源不均衡的问题,并且如果某一CPU存在故障,则依靠该CPU传输指令和数据的相应组GPU都将不能工作,可靠性受到影响。
对此,本发明的核心发明点之一在于提供了一种服务器的系统架构,包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
参照图1,示出了本发明实施例中提供的一种服务器的系统架构的结构框图之一,服务器的系统架构包括CPU和GPU组,所述GPU组包括多个GPU,其中:
不同的所述CPU之间相互连接以实现不同的所述CPU之间的数据通信,所述CPU与所述GPU组的所述GPU连接,其中,同一个所述GPU组中任意相邻的所述GPU分别连接不同的所述CPU以使同一个所述GPU组中的GPU受控于不同的所述CPU,同一个所述GPU组中任意相邻的所述GPU之间互相连接以实现同一个所述GPU组中任意相邻的所述GPU之间的数据通信。
在现有技术的AI训练中,GPU卡之间需要大量的参数进行通信,模型越复杂,通信量越大,因此,AI服务器除了要求单卡性能外,还要求多卡间的通信性能,例如采用PCI3.0(高速串行计算机扩展总线标准第三代)协议通信的P2P(Peer to Peer点对点传输)带宽可以达到32GB/s,采用SXM2(传输协议)协议通信的P2P带宽可以达到50GB/s,采用SXM3(传输协议)协议通信的P2P带宽可以达到300GB/s,也即是说,CPU与GPU之间、不同CPU挂载的GPU之间都需要高速互联。其中,当前AI服务器中CPU和GPU之间的传输方式包括PCIe形态以及OAM形态(GPU的一种形态),就PCIe而言,当前GPU的形态为PCIe的AI服务器通常为双路CPU服务器,以直连系统为例,每路CPU可以挂载2-5个GPU,在传统的AI服务器的GPU架构设计中,只是针对单路CPU下挂载的GPU进行互联,这样不能解决不同CPU之间GPU高速互联的性能问题。例如:假设第一组图形处理单元GPU1中的GPU1、GPU2、GPU3、GPU4通过PCIe高速连接线连接到第一个CPU1,而第二组图形处理单元GPU2中的GPU5、GPU6、GPU7、GPU8通过PCIe高速连接线连接到第二个CPU2,每组GPU中相邻的两个GPU之间通过桥接器进行互联,但是最终第一组GPU1中的子GPU只能连接到第一个CPU1,第二组GPU2中的子GPU只能连接到第二CPU2,即,第一组GPU只能接收第一CPU的数据和指令,第二组GPU只能接收第二CPU的数据和指令。这样的方案虽然能够扩展GPU或者其他存储器,但是由于一组GPU只能定向接收特定的第一CPU,不同CPU挂载的GPU之间不能互联,会存在不同组的GPU从CPU处获取的数据和资源不均衡的问题,并且如果某一CPU存在故障,则依靠该CPU传输指令和数据的相应组GPU都将不能工作,可靠性受到影响。
而在本发明实施例中,提供了一种服务器的系统架构,包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
如图1所示,服务器的系统架构包括CPU0、CPU1、GPU组1和GPU组2,GPU组1包括GPU0、GPU1、GPU2、GPU3,GPU组2包括GPU4、GPU5、GPU6、GPU7,其中,CPU0和CPU1之间相互连接以实现不同的CPU之间的数据通信,GPU0与GPU2连接到CPU0上,GPU1与GPU3连接到CPU1上,以及,GPU4与GPU6连接到CPU0上,GPU5与GPU7连接到CPU1上,通过同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,此外,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。
其中,系统架构可以为服务器的系统架构,其主要由CPU和GPU构成。通常情况下,在服务器中的计算机系统可以包括在第一CPU插槽(Socket)中的第一中央处理单元,例如CPU0,以及在第二CPU插槽中的第二中央处理单元,例如CPU1,为了将中央处理单元CPU的指令和数据传输到图形处理单元GPU,则可以使用传输线缆将CPU与GPU进行互联。
对于CPU,其可以作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU对应的数量至少包括两个,不同的CPU之间相互连接,例如,CPU包括CPU1和CPU0,则CPU1和CPU0之间可以通过连接从而实现数据之间的通信,CPU用于向不同的GPU组中的GPU下发数据和资源。
对于GPU,又称显示核心、视觉处理器、显示芯片,其可以为一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器,GPU可以使显卡减少对CPU的依赖,并进行部分原本CPU的工作;对于GPU组,其对应的数量也至少包括两组,每个GPU组包含多个GPU。具体地,CPU与GPU组的子GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。
在具体实现中,服务器的系统架构包括CPU和GPU组,在GPU组可以包括多个GPU,其中,不同的CPU之间相互连接可以实现不同的CPU之间的数据通信,CPU可以与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
在一种示例中,假设当前存在两个CPU、两个GPU组,其中,一个CPU为CPU0,一个CPU为CPU1,每个GPU组中包含四个子GPU。具体地,第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻,GPU0与GPU2连接到CPU0上,GPU1与GPU3连接到CPU1上;第二GPU组包括GPU4、GPU5、GPU6、GPU7,其中,GPU4与GPU5相邻,GPU6与GPU7相邻,其中,GPU4与GPU6连接到CPU0上,GPU5与GPU7连接到CPU1上;同时,CPU0和CPU1之间相互连接,同一个GPU组中任意相邻的GPU之间互相连接,即,GPU0与GPU1相互连接,GPU2与GPU3相互连接,以及,GPU4与GPU5相互连接,GPU6与GPU7相互连接。通过该连接架构保证了同一个CPU组中的相邻两个子GPU可以连接到不同的CPU上,使得每组GPU都能同时接受两个CPU的控制和数据传输;同时,实现了不同的CPU之间的数据通信以及同一个GPU组中任意相邻的GPU之间的数据通信,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
同理可得,在另一种示例中,假设当前存在两个CPU、两个GPU组,其中,一个CPU为CPU0,一个CPU为CPU1,每个GPU组中包含八个子GPU。具体地,第一GPU组包括GPU0、GPU1、GPU2、GPU3、GPU4、GPU5、GPU6、GPU7,其中GPU0与GPU1相邻、GPU2与GPU3相邻、GPU4与GPU5相邻、GPU6与GPU7相邻,GPU0、GPU2、GPU4以及GPU6连接到CPU0上,GPU1、GPU3、GPU5以及GPU7连接到CPU1上;第二GPU组包括GPU8、GPU9、GPU10、GPU11、GPU12、GPU13、GPU14、GPU15,其中,GPU8与GPU9相邻、GPU10与GPU11相邻、GPU12与GPU13相邻、GPU14与GPU15相邻;GPU8、GPU10、GPU12以及GPU14连接到CPU0上,GPU9、GPU11、GPU13与GPU15连接到CPU1上;同时,CPU0和CPU1之间相互连接,同一个GPU组中任意相邻的GPU之间互相连接,即GPU0与GPU1相互连接、GPU2与GPU3相互连接、GPU4与GPU5相互连接、GPU6与GPU7相互连接,以及,GPU8与GPU9相互连接、GPU10与GPU11相互连接、GPU12与GPU13相互连接、GPU14与GPU15相互连接。通过该连接架构保证了同一个CPU组中的相邻两个子GPU可以连接到不同的CPU上,使得每组GPU都能同时接受两个CPU的控制和数据传输;同时,实现了不同的CPU之间的数据通信以及同一个GPU组中任意相邻的GPU之间的数据通信,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
需要说明的是,上述列举的示例均仅作为一种示例,为方便解释说明,因此特将各项数据设置得较为简单,在实际应用中,一个系统架构还可能存在更多的CPU、更多GPU组以及更多的子GPU,可以理解的是,本发明实施例对此不作限制。
在本发明实施例中,提供了一种服务器的系统架构,包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能。
在一种可选实施例中,不同的所述CPU之间通过CPU互联通道连接,所述CPU互联通道用于进行不同的所述CPU之间的数据通信。
参照图2,示出了本发明实施例中提供的一种服务器的系统架构的结构框图之二,由图2可知,该系统架构为直连系统架构,CPU和GPU间主要以PCIe协议进行传输,CPU可以包含CPU0和CPU1,其中,CPU0和CPU1通过CPU互联通道进行连接,其中,CPU互联通道可以用于进行不同的CPU之间的数据通信,即图中的CPU0和CPU1可以通过CPU互联通道进行通信。
其中,对于CPU互联通道,其可以为AMD CPU的XGMI(CPU互联通道的一种),也可以为Intel CPU的UPI(CPU互联通道的一种),用于进行不同CPU之间的数据通信,需要说明的是,本领域技术人员可以根据实际情况对CPU互联通道的厂商进行选取,本发明实施例对此不作限制。
在具体实现中,假设当前存在两个CPU,其中,CPU可以为CPU0和CPU1,具体地,CPU0和CPU1可以通过AMD CPU的XGMI通道进行连接,也可以通过Intel CPU的UPI通道进行连接,其中,CPU互联通道可以用于进行不同的CPU之间的数据通信,即图2中的CPU0和CPU1可以通过CPU互联通道进行数据通信。
在本发明实施例中,不同的CPU之间可以通过CPU互联通道连接,其中,CPU互联通道用于进行不同的CPU之间的数据通信。
在一种可选实施例中,所述CPU的PCIe接口与所述GPU组中所述GPU的转接板进行连接。
其中,对于PCIe接口,其可以位于CPU中,PCIe接口用于与GPU组中GPU的转接板进行连接以进行数据通信。对于转接板,其可以位于GPU上,其可以用于连接CPU的PCIe接口以进行数据通信,需要说明的是,CPU的PCIe接口与GPU组中GPU的转接板进行连接可以采用线缆的方式进行连接,其中,线缆可以为PCIe高速线缆。
由图2可知,CPU可以包含CPU0和CPU1,其中,CPU0和CPU1通过CPU互联通道进行连接,第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻,GPU0与GPU2可以通过PCIe高速线缆连接到CPU0上,GPU1与GPU3可以通过PCIe高速线缆连接到CPU1上;第二组GPU包括GPU4、GPU5、GPU6、GPU7,其中GPU4与GPU5相邻,GPU6与GPU7相邻,其中,GPU4与GPU6可以通过PCIe高速线缆连接到CPU0上,GPU5与GPU7可以通过PCIe高速线缆连接到CPU1上。通过该连接架构保证了同一个CPU组中的相邻两个子GPU可以连接到不同的CPU上,使得每组GPU都能同时接受两个CPU的控制和数据传输。
需要说明的是,上述列举的示例均仅作为一种示例,为方便解释说明,因此特将各项数据设置得较为简单,在实际应用中,一个系统架构还可能存在更多的CPU、更多GPU组以及更多的子GPU,可以理解的是,本发明实施例对此不作限制。
在一种可选实施例中,同一个所述GPU组中任意相邻的所述GPU之间通过GPU桥接器进行连接,所述GPU桥接器用于实现同一个所述GPU组中任意相邻的所述GPU之间的数据通信。
其中,对于桥接器,其可以用于将两个相邻的且满足GPU桥接器的预设间距的GPU进行连接,能够实现两个GPU之间的数据通信。
在具体实现中,同一个GPU组中任意相邻的GPU之间可以通过GPU桥接器进行连接,GPU桥接器用于实现同一个GPU组中任意相邻的GPU之间的数据通信。
在一种示例中,假设第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻,因此,GPU0与GPU1可以通过GPU桥接器进行连接,GPU2与GPU3可以通过GPU桥接器进行连接;同理可得。假设第二GPU组包括GPU4、GPU5、GPU6、GPU7,其中,GPU4与GPU5相邻,GPU6与GPU7相邻,因此,GPU4与GPU5可以通过GPU桥接器进行连接,GPU6与GPU7可以通过GPU桥接器进行连接。通过GPU桥接器将同一个GPU组中任意相邻的GPU进行连接,能够实现相邻的GPU之间的数据通信。
可选地,当同一个所述GPU组中任意相邻的所述GPU之间的间距符合所述GPU桥接器的预设间距时,通过所述GPU桥接器将同一个所述GPU组中任意相邻的所述GPU进行连接。
在具体实现中,当同一个GPU组中任意相邻的GPU之间的间距符合GPU桥接器的预设间距时,通过GPU桥接器将同一个GPU组中任意相邻的GPU进行连接。示例性地,假设GPU桥接器的预设间距为8厘米时,当相邻的两个子GPU的物理空间相邻的间距也为8cm时,可以通过GPU桥接器进行连接。
由图2可知,第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻;第二组GPU包括GPU4、GPU5、GPU6、GPU7,其中,GPU4与GPU5相邻,GPU6与GPU7相邻,具体地,当GPU0与GPU1、GPU2与GPU3、GPU4与GPU5、GPU6与GPU7在物理空间上相应的间距符合GPU桥接器要求时,相邻的GPU之间可以搭设GPU桥接器,如图中所示,GPU0与GPU1通过桥接器1连接、GPU2与GPU3通过桥接器2连接、GPU4与GPU5通过桥接器3连接、GPU6与GPU7通过桥接器4连接。通过上述的连接方式,能够实现同一个GPU组中任意相邻的GPU之间的数据通信。
在一种示例中,假设GPU0和GPU1之间需要进行数据传输,若是未添加GPU桥接器进行相邻的GPU间的连接时,则GPU0与GPU1之间的数据传递路径为GPU0传输到CPU0,再通过CPU0传输到CPU1,最后再由CPU1传输到GPU1上,大大降低了数据传输的效率;当同一个GPU组中任意相邻GPU之间通过GPU桥接器进行连接时,可以直接通过GPU桥接器将GPU0中的数据和资源发送到GPU1中。通过使用GPU桥接器将相邻的GPU互联,不仅节省了从CPU到GPU之间的传输通道的占用空间,而且节省了CPU0与CPU1之间的传输通道的占用空间,较大程度地增强了GPU卡间的互联性能。
由图2可知,当前存在两个CPU、两个GPU组,其中,一个CPU为CPU0,一个CPU为CPU1,每个GPU组中包含四个子GPU。具体地,第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻,GPU0与GPU2通过PCIe高速线缆连接到CPU0上,GPU1与GPU3通过PCIe高速线缆连接到CPU1上;第二GPU组包括GPU4、GPU5、GPU6、GPU7,其中,GPU4与GPU5相邻,GPU6与GPU7相邻,其中,GPU4与GPU6通过PCIe高速线缆连接到CPU0上,GPU5与GPU7通过PCIe高速线缆连接到CPU1上;同时,CPU0和CPU1之间相互连接,同一个GPU组中任意相邻的GPU之间互相连接,即,GPU0与GPU1通过GPU桥接器相互连接,GPU2与GPU31通过GPU桥接器相互连接,以及,GPU4与GPU5通过GPU桥接器相互连接,GPU6与GPU7通过GPU桥接器相互连接。由上述可知,由于任意相邻两个子GPU连接到不同的CPU上,使得每组GPU都能同时受控于不同的CPU,解决了不同组GPU之间数据和资源分配不均衡的问题。
在本发明实施例中,服务器的系统架构包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能,并且通过PCIe高速线缆连接CPU和GPU,能够节省系统架构的搭建成本。
在一种可选实施例中,当任意一个所述CPU出现故障时,若连接故障的所述CPU的其他的所述CPU保持正常运行,则使用正常运行的所述CPU控制故障的所述CPU的GPU。
在具体实现中,服务器的系统架构包括CPU和GPU组,在GPU组可以包括多个GPU,其中,不同的CPU之间相互连接可以实现不同的CPU之间的数据通信,CPU可以与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信,当任意一个CPU出现故障时,若连接故障的CPU的其他的CPU保持正常运行,则使用正常运行的CPU控制故障的CPU的GPU。
在一种示例中,假设当前存在两个CPU、两个GPU组,其中,一个CPU为CPU0,一个CPU为CPU1,每个GPU组中包含四个子GPU。具体地,具体地,第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻,GPU0与GPU2通过PCIe高速线缆连接到CPU0上,GPU1与GPU3通过PCIe高速线缆连接到CPU1上;第二GPU组包括GPU4、GPU5、GPU6、GPU7,其中,GPU4与GPU5相邻,GPU6与GPU7相邻,其中,GPU4与GPU6通过PCIe高速线缆连接到CPU0上,GPU5与GPU7通过PCIe高速线缆连接到CPU1上;同时,CPU0和CPU1之间相互连接,同一个GPU组中任意相邻的GPU之间互相连接,即,GPU0与GPU1通过GPU桥接器相互连接,GPU2与GPU3通过GPU桥接器相互连接,以及,GPU4与GPU5通过GPU桥接器相互连接,GPU6与GPU7通过GPU桥接器相互连接。其中,当CPU1出现故障时,则无法向连接CPU1的GPU下发数据和资源,若连接故障的CPU1的CPU0保持正常运行,则使用正常运行的CPU0控制故障的CPU1所连接的GPU,解决了由于单块CPU出故障导致的可靠性问题,使得故障的CPU1所连接的多个GPU能够正常接收CPU0所下发的数据和资源,从而能够保持正常的工作状态,进而也不会影响系统的正常运行。
在本发明实施例中,服务器的系统架构包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能,并且通过PCIe高速线缆连接CPU和GPU,能够节省系统架构的搭建成本。此外,解决了由于单块CPU出故障导致的可靠性问题,使得故障的CPU1所连接的多个GPU能够正常接收CPU0所下发的数据和资源,从而能够保持正常的工作状态,进而也不会影响系统的正常运行。
在一种可选实施例中,连接故障的所述CPU的GPU通过同一个所述GPU组中相邻的所述GPU获取正常运行的所述CPU下发的数据和资源。
在具体实现中,当任意一个CPU出现故障时,若连接故障的CPU的其他的CPU保持正常运行,则使用正常运行的CPU控制故障的CPU的GPU,同时,连接故障的CPU的GPU通过同一个GPU组中相邻的GPU获取正常运行的CPU下发的数据和资源。
在一种示例中,假设当前存在两个CPU、两个GPU组,其中,一个CPU为CPU0,一个CPU为CPU1,每个GPU组中包含四个子GPU。具体地,具体地,第一GPU组包括GPU0、GPU1、GPU2、GPU3,其中,GPU0与GPU1相邻,GPU2与GPU3相邻,GPU0与GPU2通过PCIe高速线缆连接到CPU0上,GPU1与GPU3通过PCIe高速线缆连接到CPU1上;第二GPU组包括GPU4、GPU5、GPU6、GPU7,其中,GPU4与GPU5相邻,GPU6与GPU7相邻,其中,GPU4与GPU6通过PCIe高速线缆连接到CPU0上,GPU5与GPU7通过PCIe高速线缆连接到CPU1上;同时,CPU0和CPU1之间相互连接,同一个GPU组中任意相邻的GPU之间互相连接,即,GPU0与GPU1通过GPU桥接器相互连接,GPU2与GPU31通过GPU桥接器相互连接,以及,GPU4与GPU5通过GPU桥接器相互连接,GPU6与GPU7通过GPU桥接器相互连接。其中,当CPU1出现故障时,若连接故障的CPU1的CPU0保持正常运行,则使用正常运行的CPU0控制故障的CPU1的GPU,具体地,在CPU1出现故障,CPU0可以正常下发数据和资源时,则使用正常运行的CPU0控制故障的CPU1所连接的GPU1、GPU3、GPU5和GPU7,由于CPU1出现故障,则GPU1、GPU3、GPU5和GPU7无法接受到CPU1下发的数据和资源,因此,GPU1可以通过GPU桥接器从相邻的GPU0中获取CPU0中下发的数据和资源,保证了系统的正常运行。可以理解的是,由于同一GPU组中任意相邻的两个子GPU连接到不同的CPU上,使得每组GPU都能同时受控于两个CPU,解决了不同组GPU之间数据和资源分配不均衡的问题,并且在每组GPU同时受控于两个CPU的情况下,即使在单块CPU出现故障的情况下,也仍能保证所有GPU正常工作,因此解决了由于单块CPU出故障导致的可靠性问题。
在本发明实施例中,服务器的系统架构包括CPU和GPU组,GPU组包括多个GPU,其中,不同的CPU之间相互连接以实现不同的CPU之间的数据通信,CPU与GPU组的GPU连接,其中,同一个GPU组中任意相邻的GPU分别连接不同的CPU以使同一个GPU组中的GPU受控于不同的CPU,同一个GPU组中任意相邻的GPU之间互相连接以实现同一个GPU组中任意相邻的GPU之间的数据通信。通过上述服务器的系统架构,使得同一个GPU组中的GPU能够受控于不同的CPU,CPU能够向不同的GPU组分配到均衡的数据和资源,并且保证了CPU下发数据和资源的可靠性,同时,提高了不同CPU控制下的相邻GPU之间的点对点传输的性能,并且通过PCIe高速线缆连接CPU和GPU,能够节省系统架构的搭建成本。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本发明的保护之内。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 一种CRPS服务器电源及一种服务器
- 一种降低服务器存储和访问压力的勘察监管系统架构方法
- 一种基于集中式保护控制系统架构的配电边缘服务器系统