一种数据库频率估计方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于数据库技术领域,具体涉及一种新的数据库频率估计方法,提供存储在数据库中数据的频率统计信息,从而使数据库的查询效率更高。
背景技术
Count-Min Sketch是数据库中常用的一种频率估计方法,如TiDB就采用了这种方法用于统计信息的收集,在数据库点查询的时候进行频率估计。Count-Min Sketch的数据结构是一个二维数组,宽度w,深度d,具有d个两两相互独立的哈希函数h
Count-Min Sketch的缺点在于为了计数频率较高的数据项,计数器开辟空间的时候必须以最高频率为基准开辟出相同大小空间的计数器。然而在实际的应用中,对于那些计数较少的计数器将会有极大的空间浪费,况且由于这些空间在数据库运行时是从内存中开辟并且长时间持有,所以这项缺点将对数据库的性能产生极大的影响。
目前在数据库频率估计使用的方法主要是Count-Min Sketch,该方法存在问题主要有以下几点:
由于哈希冲突导致数据量很大的情况下精度降低;
内存使用效率低,因为计数器大小都需要以最高频率为基准均等分配内存,所以计数频率较低的计数器将会导致空间的极大浪费,这些浪费的空间如果被有效的利用将会改善数据库的运行压力。
发明内容
针对现有技术的不足,本发明拟解决的技术问题是,提供一种新的数据库频率估计方法,该估计方法基于Count-Min Sketch的基本思想,采用分层方式,保证在减少哈希冲突的同时充分利用内存空间,有效改善数据库的运行压力。
本发明解决所述技术问题采用的技术方案是:
第一方面,本发明提供一种数据库频率估计方法,该估计方法包括以下内容:
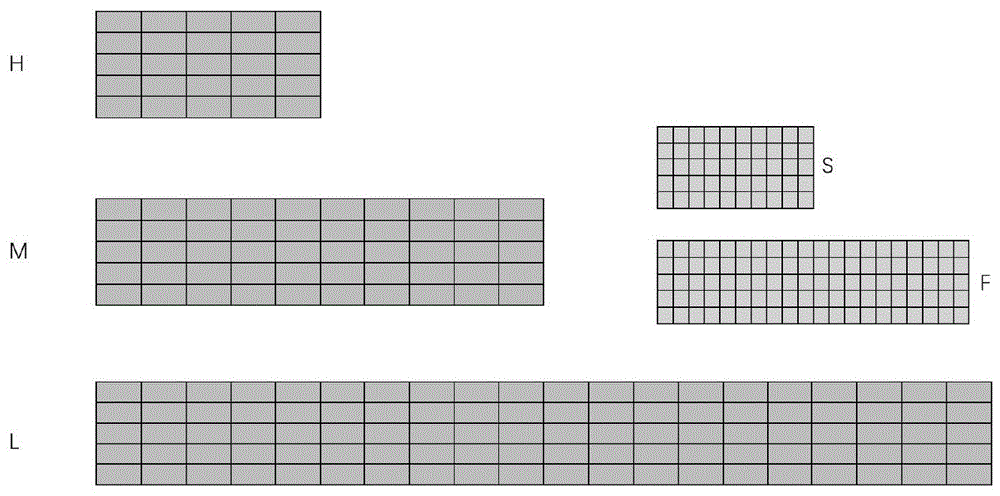
所述数据库的数据结构包括低频二维数组L、中频二维数组M、高频二维数组H这三层二维数组,三层二维数组的行数均相等,高频二维数组H的列数是中频二维数组M的列数的1/2,中频二维数组M的列数是低频二维数组L的列数的1/2;所述数据结构还包括两个位图,即低频位图F和中频位图S,低频位图F和中频位图S的行列数分别与低频二维数组L和中频二维数组M的行列数相同;
二维数组的结构由一个个固定大小的存储单元构成,将这些存储单元叫做计数器,依据二维数组的行号和列号定位计数器在二维数组中的位置,使用计数器记录数据的频率;低频二维数组L、中频二维数组M、高频二维数组H这三层二维数组的各自的计数器的最大阈值可相同或不同,同一层的所有计数器的最大阈值均相同;
位图的结构中每个存储单元的大小为1bit,这些存储单元叫做位,位图中的值只能是0和1,通过位图的行号和列号确定这些位在位图中的位置,低频位图F和中频位图S分别用于记录L和M中计数器的溢出情况;
在L中的每一个计数器L[i][j]使用相同的行号i和列号j都能在低频位图F中找到对应的位F[i][j],如果位F[i][j]上存储的值为0,表示计数器没有溢出,说明0对应的位置在L上没发生进位,取出L当前位置对应的值为频数;如果位F[i][j]上存储的值为1,表示计数器溢出过,发生了进位,再对M进行哈希计算;如果位S[i][j]上存储的值为0,说明0对应的位置在M上没发生进位,则此时的频数为M[i][D
所述三层二维数组L、M、H的行数均为5,H的列数是M列数的1/2,M的列数是L列数的1/2,L的列数默认是2048;5个哈希函数,设置L层计数器的大小为lbyte,M层计数器的大小为2byte,H层计数器的大小为2byte,所有计数器总占用空间大小为25K。
所述估计方法包括插入数据、查询数据和删除数据过程,设置高频、中频、低频二维数组中的计数器的最大阈值分别为MAX
步骤S1、将数据e插入到二维数组中,在插入第一条数据前先对所有二维数组和位图做初始化,即每个计数器和位的值都初始化为0;
步骤S1-1、设置i=0,从低频二维数组L开始计算,利用哈希函数计算数据e的哈希值,该哈希值即为将数据e映射到低频二维数组L中的列数D
步骤S1-2、判断计数器L[0][D
步骤S1-3、将D
步骤S1-4、判断计数器M[0][D
步骤S1-5、将D
步骤Sl-6、分别设置i=1,2,3,4,重复执行S1-1、S1-2、S1-3、S1-4、S1-5步骤;
步骤S1-7、插入数据e结束;
步骤S2、从二维数组中查询出数据e出现的频率,完成数据e的频率估计
步骤S2-1、从低频二维数组L开始查询,计算数据e的哈希值Hash
步骤S2-2、判断步骤S2-1中定位获得的位F[i][D
步骤S2-3、如果步骤S2-1中定位获得的位F[i][D
步骤S2-4、判断步骤S2-3定位获得的位S[i][D
步骤S2-5、如果步骤S2-3定位获得的位S[i][D
步骤S3、从二维数组中删除一个数据e的插入记录
步骤S3-1、从低频二维数组L开始删除,设置i=0,计算数据e的哈希值Hash
步骤S3-2、如果计数器L[0][D
步骤S3-3、将D
步骤S3-4、如果计数器M[0][D
步骤S3-5、如果计数器M[0][D
步骤S3-5、将D
步骤S3-6、分别设置i=1,2,3,4,重复执行S3-1、S3-2、S3-3、S3-4、S3-5步骤;
步骤S3-7、删除结束。
所述估计方法能够估算出数据库中数据的访问频率,实现冷热数据分离,设定热数据阈值top-k,将前k个访问频率最大的元素定义为热数据移动到内存,实现冷热数据的分离,缓解数据库的压力,并且提升查询效率。
所述估计方法是对Count-Min Sketch数据结构的改进,能应用于自然语言处理、数据流统计、计算点互信息、压缩传感的稀疏逼近、网络异常流检测、处理分布式数据集中,能够改善数据库运行压力,提高内存空间的利用率。
第二方面,本发明提供一种数据流统计中数据库频率估计方法,所述估计方法的步骤具体是:
步骤1:找到即将处理的数据流;
步骤2:初始化权利要求1中所述的数据结构,将数据结构的L层、M层、H层中所有的计数器的值设置为0,同时将低频位图F和中频位图S的值也设置为0,将数据流中的数据依次插入到所述的数据结构中;
步骤3:插入第一条数据e时,设置i=0,从低频二维数组L开始计算,利用哈希函数计算数据e的哈希值,该哈希值即为将数据e映射到低频二维数组L中的列数D
步骤4:判断计数器L[0][D
步骤5、将D
步骤6、判断计数器M[0][D
步骤7、将D
步骤8、分别设置i=1,2,3,4,重复执行3、4、5、6、7步骤;
步骤9、插入数据e结束;
步骤10、后续每当有数据插入则重复执行步骤3到步骤9,直到数据流中的所有数据都插入到所述数据结构中为止;
步骤11、当数据流中所有数据都插入完成以后,开始计算数据流中数据出现的频率;
步骤12、首先查询第1个数据e,从低频二维数组L开始查询,计算第1个数据e的哈希值Hash
步骤13、判断步骤12中定位获得的位F[i][D
步骤14、如果步骤12中定位获得的位F[i][D
步骤15、判断步骤14定位获得的位S[i][D
步骤16、如果步骤14定位获得的位S[i][D
步骤17、得到第一个数据e的频率;
步骤18、后续的数据按照步骤12到步骤16重复执行,最终得到数据流中所有数据的频率。
第三方面,本发明提供一种存储有计算机指令的计算机可读存储介质,当所述计算机指令被一个或多个处理器执行时,致使所述一个或多个处理器执行所述估计方法中的步骤。
第四方面,本发明提供一种数据处理系统,所述数据处理系统中的数据库的数据结构包括低频二维数组L、中频二维数组M、高频二维数组H这三层二维数组,三层二维数组的行数均相等,高频二维数组H的列数是中频二维数组M的列数的1/2,中频二维数组M的列数是低频二维数组L的列数的1/2;所述数据结构还包括两个位图,即低频位图F和中频位图S,低频位图F和中频位图S的行列数分别与低频二维数组L和中频二维数组M的行列数相同;
二维数组的结构由一个个固定大小的存储单元构成,将这些存储单元叫做计数器,依据二维数组的行号和列号定位计数器在二维数组中的位置,使用计数器记录数据的频率;同一层的所有计数器的最大阈值均相同;
位图的结构中每个存储单元的大小为1bit,这些存储单元叫做位,位图中的值只能是0和1,通过位图的行号和列号确定这些位在位图中的位置,低频位图F和中频位图S分别用于记录L和M中计数器的溢出情况。
在L中的每一个计数器L[i][j]使用相同的行号i和列号j都能在低频位图F中找到对应的位F[i][j],如果位F[i][j]上存储的值为0,表示计数器没有溢出,说明0对应的位置在L上没发生进位,取出L当前位置对应的值为频数;如果位F[i][j]上存储的值为1,表示计数器溢出过,发生了进位,再对M进行哈希计算;如果位S[i][j]上存储的值为0,说明0对应的位置在M上没发生进位,则此时的频数为M[i][D
与现有技术相比,本发明的有益效果是:
传统的Count-Min Sketch方式采用单层结构(一个二维数组),则计数器的容量均以计数最大值均等分配,在实际生产环境中低频的数据项会很多,Count-Min Sketch结构中记录这些低频数据的计数器将会浪费大量的内存空间。文中提出的新方法采用分层的设计思路,一种内存使用更为高效的频率估计方法,划分为L、M和H三层结构的方式(L层计数器最多,M层次之,H层最少),数据频率较低的数据项落入L层,随着数据频率的增加依次溢出到M和H层。与传统方式相比,L层的计数器更多、计数器的内存空间更小(计数范围更小),更多的计数器可以减少哈希冲突的概率,更小的内存空间可以在计数器记录低频数据项的时候减少空间的浪费,起到内存高效的目的。对于那些中高频数据项,在落入L层之后会再次溢出到M层和H层,因为实际生产环境中频率越高的数据项数量越少,尽管M和H层的计数器数量逐层变少,依然可以保证在减少哈希冲突的同时充分利用内存空间。
如此强调内存效率的主要原因是在数据库中有很多的表,每个表有很多列的情况下,将会有很多的频率估计统计信息,而这些统计信息为了快速响应需要常驻内存,会消耗很多的计算机内存,于是内存的高效就显得极为重要。文中的发明在一定程度上解决了这个问题。
综上所述,本发明方法在内存使用效率上更加高效,在某些特定的情况下点查询的效率更加迅速(例如:在哈希映射的计数器中,如果只有一个被映射的计数器没有溢出则直接返回该值就是估计的最小值,无须比较各个估计值的大小)。
本发明可以随着数据频率的增加依次从L层溢出到M层和H层。根据分层结构思想,可以分别设置H、M、L三个组内每一个计数器占用的空间,即可以分别设置MAX
附图说明
图1为传统Count-Min Sketch数据结构示意图。
图2为本发明提出的新的Count-Min Sketch数据结构示意图。
图3为本发明插入数据时的流程图。
图4为本发明中查询数据的频率的流程图。
图5本发明中删除数据的流程图。
图6为实施例1中插入完前六条数据后得到的数据结构中存储的结果图。
图7为实施例1中插入完表1所有数据后得到的数据结构中存储的结果图。
图8为本发明数据结构与传统的CMS结构性能对比图。
具体实施方式
下面结合实施例及附图进一步解释本发明,但并不以此作为对本申请保护范围的限定。
/>
本发明一种数据库频率估计方法,该估计方法包括以下内容:
所述数据库的数据结构如图2所示,包括低频二维数组L、中频二维数组M、高频二维数组H这三层二维数组,三层二维数组的行数均相等,高频二维数组H的列数是中频二维数组M的列数的1/2,中频二维数组M的列数是低频二维数组L的列数的1/2;所述数据结构还包括两个位图,即低频位图F和中频位图S,低频位图F和中频位图S的行列数分别与低频二维数组L和中频二维数组M的行列数相同;
二维数组的结构由一个个固定大小的存储单元构成,将这些存储单元叫做计数器,依据二维数组的行号和列号可以定位计数器在二维数组中的位置,故二维数组的作用是使用计数器记录数据的频率;低频二维数组L、中频二维数组M、高频二维数组H这三层二维数组的各自的计数器的最大阈值可相同或不同,同一层的所有计数器的最大阈值均相同。计数器的最大阈值就是计数器的存储容量。
位图结构和二维数组类似,但是每个存储单元的大小为1bit,这些存储单元叫做位,位图中的值只能是0和1,同样可以通过位图的行号和列号确定这些位在位图中的位置,低频位图F和中频位图S的作用是分别记录L和M中计数器的溢出情况。
本实施例中,三层二维数组(L、M、H)的行数均为5,H的列数是M列数的1/2,M的列数是L列数的l/2,L的列数默认是2048,每个小方框表示一个计数器,为每个计数器设置存储容量,占用多少为最大值,为自己设定的(依据具体的使用场景可以动态增减L的行列数)。位图F的行数和列数与L的行数和列数相同,S的行数和列数与M的行数和列数相同,于是在L中的每一个计数器L[i][j]使用相同的行号i和列号j都可以在F中找到对应的位F[i][j],位F[i][j]的作用就是记录计数器L[i][j]的溢出情况,如果位F[i][j]上存储的值为0,表示计数器没有溢出,说明0对应的位置在L上没发生进位,取出当前位置对应的值即可;如果位F[i][j]上存储的值为1,表示计数器溢出过,发生了进位,再对M进行哈希计算。M中的计数器和S中的位的对应关系也如此。
如果位S[i][j]上存储的值为0,说明0对应的位置在M上没发生进位,则此时的频数为M[i][D
估计方法的具体步骤是:
步骤S1、在插入第一条数据前先对所有二维数组和位图做初始化,即每个计数器和位的值都初始化为0;将数据e插入到二维数组中;步骤S1-1到S1-7是插入一个数据的完整步骤。如图3所示。
步骤S1-1、设置i=0,从低频二维数组L开始计算,利用哈希函数计算数据e的哈希值,该哈希值即为将数据e映射到低频二维数组L中的列数D
步骤S1-2、判断计数器L[0][D
步骤S1-3、将D
步骤S1-4、判断计数器M[0][D
步骤S1-5、将D
步骤S1-6、分别设置i=1,2,3,4,重复执行S1-1、S1-2、S1-3、S1-4、S1-5步骤;
步骤S1-7、插入数据e结束;
步骤S2、从二维数组中查询出数据e出现的频率,完成数据e的频率估计;如图4所示。
步骤S2-1、从低频二维数组L开始查询,计算数据e的哈希值Hash
步骤S2-2、判断步骤S2-1中定位获得的位F[i][D
步骤S2-3、如果步骤S2-1中定位获得的位F[i][D
步骤S2-4、判断步骤S2-3定位获得的位S[i][D
步骤S2-5、如果步骤S2-3定位获得的位S[i][D
步骤S3、从二维数组中删除一个数据e的插入记录;如图5所示。
步骤S3-1、从低频二维数组L开始删除,设置i=0,计算数据e的哈希值Hash
步骤S3-2、如果计数器L[0][D
步骤S3-3、将D
步骤S3-4、如果计数器M[0][D
步骤S3-5、如果计数器M[0][D
步骤S3-5、将D
步骤S3-6、分别设置i=1,2,3,4,重复执行S3-1、S3-2、S3-3、S3-4、S3-5步骤;
步骤S3-7、删除结束;
实施例1
假设数据库中有一张表(表结构如表1所示)记录了某个晚间电影点播平台一周内的电影点播记录,使用本申请方法对表中的Movie_code列进行频率估计。此实例中三个二维数组L、M和H的行数为5,L的列数为20,M的列数是10和H的列数是5。假设使用的哈希函数分别为:Hash
表1电影点播记录表
插入表1第一条数据155934:
步骤S1-1、插入第一条数据155934,设置i=0,计算数据155934的哈希值D
步骤S1-2、计数器L[0][15]上存储的值为0,0+1小于MAX
注:每行都要找到插入的位置,因为i是从0开始的,i必须要依次取过1,2,3,4,才算完成一条数据的插入,即使用Hash
步骤S1-6、分别设置i=1,2,3,4。重复执行S1-1、S1-2、S1-3、S1-4、S1-5步骤;
步骤S1-7、插入第一条数据155934结束;
其余数据的插入方式与上面的步骤相同,当表1中的第6条数据278955插入完成后得到的结果如图6所示,此时位图F和位图S中没有1出现,说明目前没有发生进位。然而当插入表1中的第7条数据155934(最后一条数据)时,Hash
表1中所有数据全部插入以后的结果如图7所示。
查询数据466008:
步骤S2-1、查询数据466008,首先从i=0开始,i∈{0,1,2,3,4},计算数据466008的哈希值D
步骤S2-2、判断F[0][9]、F[1][12]、F[2][15]、F[3][17]、F[4][18]上存储的值是否均为1;检查后发现这些位置上存储的值都为0,说明没有L内没有溢出;
步骤S2-3、取出L[0][9]、L[1][12]、L[2][15]、L[3][17]、L[4][18]上存储的值,从图7可以看出本实施例中存储的值都为l,然后比较大小,最小值1即为数据466008出现的频率,466008频率估计值为1;
删除数据466008:
步骤S3-1、设置i=0,计算数据466008的哈希值D
步骤S3-2、由上图可知此时计数器L[0][9]的值大于0,把计数器L[0][D
步骤S3-6、分别设置i=1,2,3,4,重复执行S3-1、S3-2、S3-3、S3-4、S3-5步骤;
步骤S3-7、删除结束;
具体实际应用:查询操作主要分为内存查找和外存查找,当内存中不存在目标数据时,就需要向外存中进行查找。二者的响应速度有很大差距,内存中的查找速度远高于外存中的查找速度。所以尽量将访问频率高的数据移动到内存中,提升内存的命中率进而使查询效率更高。由表l电影点播记录表可以得到所有的电影点播情况,通过本发明估计方法可以估算出每个电影的点播频率,将点播频率最大的几部电影数据移动到内存中,这里可以将“肖申克的救赎”移动到内存。通过对数据库中数据的访问频率进行估计,可以实现冷热数据分离,将访问最频繁的一些数据(与访问频率有关,可以根据实际情况按照访问频率来设定热数据阈值top-k,将前k个访问频率最大的元素放入内存中)定义为热数据移动到内存,可以有效的缓解数据库的压力,并且提升查询效率,实现冷热数据的分离。
注:top-k即求数据集合中前k个最大的元素或者最小的元素。
本发明是对Count-Min Sketch(简称CMS)的改进,所以适用于所有Count-MinSketch的使用场景,包括自然语言处理、数据流统计、计算点互信息、压缩传感的稀疏逼近、网络异常流检测、处理分布式数据集等等,能够改善数据库运行压力,提高内存空间的利用率。
从图8中可以看出,将传统的CMS列数设为2048列,5个哈希函数以及每个计数器的大小为4byte,每个计数器最大阈值为2
实施例2
本实施例数据流统计中数据库频率估计方法,在数据流统计中的应用,用于估计数据流中数据的频率高低,具体步骤如下:
步骤1:找到即将处理的数据流;
步骤2:初始化本申请的数据结构,将数据结构的L层、M层、H层中所有的计数器的值设置为0,同时将位图F和位图S的值也设置为0,将数据流中的数据依次插入到所述的数据结构中;
步骤3:插入第一条数据e时,设置i=0,从低频二维数组L开始计算,利用哈希函数计算数据e的哈希值,该哈希值即为将数据e映射到低频二维数组L中的列数D
步骤4:判断计数器L[0][D
步骤5、将D
步骤6、判断计数器M[0][D
步骤7、将D
步骤8、分别设置i=1,2,3,4,重复执行3、4、5、6、7步骤;
步骤9、插入数据e结束;
步骤10、后续每当有数据插入则重复执行步骤3到步骤9,直到数据流中的所有数据都插入到所述数据结构中为止;
步骤11、当所有数据都插入完成以后,开始计算数据流中数据出现的频率;
步骤12、首先查询第1个数据e,从低频二维数组L开始查询,计算第1个数据e的哈希值Hash
步骤13、判断步骤12中定位获得的位F[i][D
步骤14、如果步骤12中定位获得的位F[i][D
步骤15、判断步骤14定位获得的位S[i][D
步骤16、如果步骤14定位获得的位S[i][D
步骤17、得到第一个数据e的频率;
步骤18、后续的数据按照步骤12到步骤16重复执行,最终得到数据流中所有数据的频率。
本发明未述及之处适用于现有技术。
- 一种欠采样波形的短区间频率估计器方法及估计器
- 一种基于IpDFT的频率阶跃单频信号频率估计方法
- 一种基于频率相对偏差预估的分段综合单频信号频率估计方法