工序工时标准化方法、装置及电子设备
文献发布时间:2023-06-19 19:30:30
技术领域
本申请涉及工时计算技术领域,具体涉及一种工序工时标准化方法、装置及电子设备。
背景技术
工序工时是指在一定的技术状态和生产组织模式下,按照产品工序加工完成一个产品所需要的工作时间。根据标准的工序工时可以安排生产作业计划,进行成本核算,确定设备数量和人员编制,规划生产面积等。现有技术中,工作人员通过经验估计法、统计分析法、类比法等人工统计方式进行工序工时标准化作业,不仅容易导致工序标准化工时不准确,而且针对工时数据的数量较多的情况,统计得到工序标准化工时的工作效率很低。
发明内容
为了解决上述技术问题,本申请的实施例提供了一种工序工时标准化方法、装置及电子设备,其不仅可以提高工序标准化工时的准确性,而且可以提高计算得到工序标准化工时的工作效率。
第一方面,本申请一实施例提供了一种工序工时标准化方法,包括:
获取待加工物料的数量;
若所述待加工物料的数量小于数量阈值,运行标准计算模型,得到工序标准化工时;其中,所述标准计算模型表征应用加权平均算法的计算模型;
若所述待加工物料的数量大于或者等于所述数量阈值,运行聚类计算模型,得到工序标准化工时;其中,所述聚类计算模型表征应用聚类算法的计算模型。
根据本申请的第一方面,所述运行标准计算模型,得到工序标准化工时包括:
获取所述待加工物料在每个工位对应的多个工时数据;
根据多个所述工时数据,得到不同所述工位的权重系数;以及
根据多个所述工时数据和多个所述权重系数,得到所述工序标准化工时。
根据本申请的第一方面,所述运行聚类计算模型,得到工序标准化工时包括:
获取所述待加工物料在多个工位的工时数据集;
根据所述工时数据集,得到聚类参数;其中,所述聚类参数包括邻域最大半径和邻域中最少点数;以及
根据所述聚类参数,执行聚类算法,得到所述工序标准化工时。
根据本申请的第一方面,所述根据所述工时数据集,得到聚类参数包括:
构建数据窗口;其中,所述数据窗口表征从所述工时数据集中选取预设数量的样本工时数据;
多次移动所述数据窗口,直至遍历所述工时数据集;
得到每次移动后所述数据窗口内数据的第一波动特征参数以及所述数据窗口移动的总次数;其中,所述第一波动特征参数表征在所述数据窗口内,所述预设数量的所述样本工时数据的标准差;
根据所述工时数据集,得到所述工时数据集内数据的第二波动特征参数;其中,所述第二波动特征参数表征所述工时数据集内所有工时数据的标准差;
根据所述数据窗口移动的总次数、多个所述第一波动特征参数以及所述第二波动特征参数,得到所述邻域最大半径;
根据所述窗口移动的总次数,得到所述邻域中最少点数。
根据本申请的第一方面,所述根据所述数据窗口移动的总次数、多个所述第一波动特征参数以及所述第二波动特征参数,得到所述邻域最大半径包括:
根据多个所述第一波动特征参数和所述第二波动特征参数,得到多个所述第一波动特征参数与所述第二波动特征参数之间的最大差值和最小差值;以及
根据多个所述第一波动特征参数、所述最大差值、所述最小差值以及所述数据窗口移动的总次数,得到所述邻域最大半径。
根据本申请的第一方面,所述根据所述聚类参数,执行聚类算法,得到所述工序标准化工时包括:
根据所述聚类参数,获取每个所述工位的工时数据集在所述邻域最大半径内的第一样本数量;
若所述第一样本数量大于或等于所述邻域中最少点数,将对应所述工位的工时数据集标定为有效簇;
根据多个所述有效簇,得到所述工序标准化工时。
根据本申请的第一方面,在所述获取每个所述工位的工时数据集在所述邻域最大半径内的第一样本数量之后,所述根据所述聚类参数,执行聚类算法,得到所述工序标准化工时包括:
若所述第一样本数量小于所述邻域中最少点数,将对应所述工位的工时数据集标定为异常簇。
根据本申请的第一方面,在所述将对应所述工位的工时数据集标定为有效簇之后,所述根据所述聚类参数,执行聚类算法,得到所述工序标准化工时包括:
校验所述有效簇,并输出校验结果;
若所述校验结果表征所述有效簇内存在额外簇,将所述额外簇从所述有效簇中分离出,并将所述额外簇作为新有效簇;其中,所述额外簇表征在所述有效簇内,在所述邻域最大半径内的样本数量大于或等于所述邻域最少点数的工时数据集。
根据本申请的第一方面,所述校验所述有效簇,并输出校验结果包括:
获取所述有效簇内每组所述工时数据在所述邻域最大半径内的第二样本数量;
若所述第二样本数量大于或等于所述邻域最少点数,输出表征将对应组的所述工时数据标定为所述额外簇的校验结果。
根据本申请的第一方面,在所述得到工序标准化工时之后,所述工序工时标准化方法还包括:
获取所有物料的工序标准化工时和工序次数;
选取所述工序次数相等的第一类物料和第二类物料;
若所述第一类物料的工序标准化工时与所述第二类物料的工序标准化工时之差小于或者等于工时阈值,输出所述第一类物料和所述第二类物料的工序标准化工时合格的结果;
若所述第一类物料的工序标准化工时与所述第二类物料的工序标准化工时之差大于所述工时阈值,输出所述第一类物料和/或所述第二类物料的工序标准化工时不合格的结果。
第二方面,本申请一实施例还提供了一种工序工时标准化装置,包括:
第一获取模块,配置为获取待加工物料的数量;
第一计算模块,配置为若所述待加工物料的数量小于数量阈值,运行标准计算模型,得到工序标准化工时;其中,所述标准计算模型表征应用加权平均算法的计算模型;以及
第二计算模块,配置为若所述待加工物料的数量大于或者等于所述数量阈值,运行聚类计算模型,得到工序标准化工时;其中,所述聚类计算模型标准应用聚类算法的计算模型。
第三方面,本申请一实施例提供了电子设备,包括:
处理器;
用于存储所述处理器可执行指令的存储器;
所述处理器用于运行所述可执行指令以实现如前所述的工序工时标准化方法。
本申请实施例提供的工序工时标准化方法、装置及电子设备,其通过获取待加工物料的数量,然后以待加工物料的数量作为依据,运行标准计算模型或者聚类计算模型,得到工序标准化工时;第一方面,相比于人工通过统计分析进行工序工时标准化作业的方法,应用标准计算模型和聚类计算模型,可以更加方便快捷地得到工序标准化工时,有效地提高工作效率;第二方面,其通过根据待加工物料的数量,判断工时数据的数量,然后运行标准计算模型或者聚类计算模型,以不同的计算方法对工时数据进行针对性的计算,消除一些差异较大的数据对标准化结果的影响,有效地提高工序标准化工时的精度;第三方面,其在待加工物料的数量大于或者等于数量阈值的情况下,运行聚类计算模型,得到工序标准化工时,解决了大量工时数据差异较大,无法得到准确工序标准化工时的问题,其在待加工物料的数量小于数量阈值的情况下,运行标准计算模型,得到工序标准化工,解决了工时数据较少时无法有效聚类的问题。
附图说明
通过结合附图对本申请实施例进行更详细的描述,本申请的上述以及其他目的、特征和优势将变得更加明显。附图用来提供对本申请实施例的进一步理解,并且构成说明书的一部分,与本申请实施例一起用于解释本申请,并不构成对本申请的限制。在附图中,相同的参考标号通常代表相同部件或步骤。
图1为本申请一示例性实施例提供的工序工时标准化方法的流程示意图。
图2为本申请一示例性实施例提供的运行标准计算模型,得到工序标准化工时的流程示意图。
图3为本申请一示例性实施例提供的运行聚类计算模型,得到工序标准化工时的流程示意图。
图4为本申请一示例性实施例提供的根据工时数据集,得到聚类参数的流程示意图。
图5为本申请一示例性实施例提供的根据数据窗口移动的总次数、多个第一波动特征参数以及第二波动特征参数,得到邻域最大半径的流程示意图。
图6为本申请一示例性实施例提供的根据聚类参数,执行聚类算法,得到工序标准化工时的流程示意图。
图7为本申请另一示例性实施例提供的根据聚类参数,执行聚类算法,得到工序标准化工时的流程示意图。
图8为本申请另一示例性实施例提供的根据聚类参数,执行聚类算法,得到工序标准化工时的流程示意图。
图9为本申请一示例性实施例提供的校验有效簇,并输出校验结果的流程示意图。
图10为本申请另一示例性实施例提供的工序工时标准化方法的流程示意图。
图11为本申请一示例性实施例提供的工序工时标准化装置的结构框图。
图12为本申请另一示例性实施例提供的工序工时标准化装置的结构框图。
图13为本申请一示例性实施例提供的电子设备的结构框图。
具体实施方式
下面,将参考附图详细地描述根据本申请的示例实施例。显然,所描述的实施例仅仅是本申请的一部分实施例,而不是本申请的全部实施例,应理解,本申请不受这里描述的示例实施例的限制。
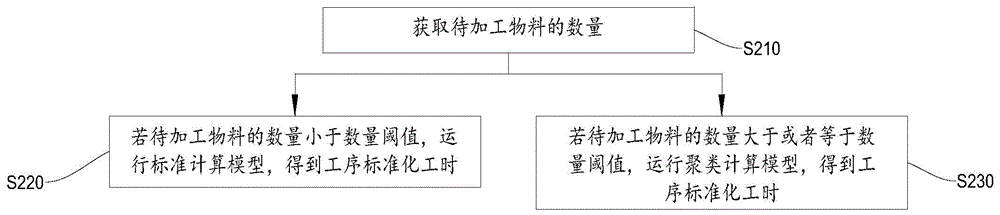
图1为本申请一示例性实施例提供的工序工时标准化方法的流程示意图。如图1所示,本申请实施例提供的工序工时标准化方法可以包括:
S210:获取待加工物料的数量。
具体地,以单个物料为例,加工单个物料,需要在多个工位进行多个工序加工,每个工序加工均存在对应的工时数据。应当理解的是,待加工物料的数量越多,工时数据的数量越多,因此,待加工物料的数量可以作为判断工时数据的数量的依据,便于后续针对不同数量的工时数据,应用不同的算法模型,得到较为准确的工序标准化工时。
S220:若待加工物料的数量小于数量阈值,运行标准计算模型,得到工序标准化工时。
具体地,若待加工物料的数量小于数量阈值,可以推导得到工序总数较少,工时数据的数量较少,在此种情况下,可以运行标准计算模型,得到工序标准化工时。
需要说明的是,考虑到工时数据的数量较少,在运行标准计算模型的过程中,直接应用加权平均算法进行计算,即可以得到较为准确的工序标准化工时。
应当理解的是,数量阈值可以根据实际情况进行设定,本申请对数量阈值不作具体限定。
S230:若待加工物料的数量大于或者等于数量阈值,运行聚类计算模型,得到工序标准化工时。
具体地,若待加工物料的数量大于或者等于数量阈值,可以推导得到工序总数较多,工时数据的数量较多,在此种情况下,可以运行聚类计算模型,得到工序标准化工时。
需要说明的是,考虑到工时数据的数量较多,工时数据之间的差异较大,因此,在运行聚类计算模型的过程中,应用聚类算法对大量的工时数据进行聚类计算,聚类得到相似性较高的工时数据,利用相似较高的工时数据,计算得到工序标准化工时,这样可以减少差异较大的数据对标准化结果的影响,提升工序标准化工时的精度。
应当理解的是,相比于人工通过统计分析进行工序工时标准化作业的方法,应用标准计算模型和聚类计算模型,可以更加方便快捷地得到工序标准化工时,有效地提高工作效率。
本申请实施例提供的工序工时标准方法,其通过获取待加工物料的数量,然后以待加工物料的数量作为依据,运行标准计算模型或者聚类计算模型,得到工序标准化工时;第一方面,相比于人工通过统计分析进行工序工时标准化作业的方法,应用标准计算模型和聚类计算模型,可以更加方便快捷地得到工序标准化工时,有效地提高工作效率;第二方面,其通过根据待加工物料的数量,判断工时数据的数量,然后运行标准计算模型或者聚类计算模型,以不同的计算方法对工时数据进行针对性的计算,消除一些差异较大的数据对标准化结果的影响,有效地提高工序标准化工时的精度;第三方面,其在待加工物料的数量大于或者等于数量阈值的情况下,运行聚类计算模型,得到工序标准化工时,解决了大量工时数据差异较大,无法得到准确工序标准化工时的问题,其在待加工物料的数量小于数量阈值的情况下,运行标准计算模型,得到工序标准化工,解决了工时数据较少时无法有效聚类的问题。
图2为本申请一示例性实施例提供的运行标准计算模型,得到工序标准化工时的流程示意图。如图2所示,步骤S220可以包括:
S221:获取待加工物料在每个工位对应的多个工时数据。
具体地,待加工物料在每个工位需要进行多个工序的加工作业,因此,每个工位可以对应多个工时数据。需要说明的是,每个工位对应的多个工时数据可以从数据库中获取。
S222:根据多个工时数据,得到不同工位的权重系数。
具体地,权重系数可以通过如下公式进行计算:
其中,W
S223:根据多个工时数据和多个权重系数,得到工序标准化工时。
具体地,通过加权平均算法,可以计算得到工序标准化工时,即:
其中,T
图3为本申请一示例性实施例提供的运行聚类计算模型,得到工序标准化工时的流程示意图。如图3所示,步骤S230可以包括:
S231:获取待加工物料在多个工位的工时数据集。
具体地,工时数据集可以以集合的形式表示:
X={X
其中,n为总工位数量,X
S232:根据工时数据集,得到聚类参数。
S233:根据聚类参数,执行聚类算法,得到工序标准化工时。
具体地,聚类参数可以包括邻域最大半径和邻域中最少点数。邻域N
N
其中,EPS表征邻域最大半径,也就是说,邻域可以理解为以x
需要说明的是,执行步骤S232,可以将聚类参数与工时数据关联起来,这样,根据获取的工时数据的分布特点,可以得到对应的聚类参数,使得聚类参数可以根据工时数据进行自适应调整,有利于后续得到更准确的工序标准化工时。具体地,根据工时数据计算得到聚类参数的过程后文进行详细叙述。
图4为本申请一示例性实施例提供的根据工时数据集,得到聚类参数的流程示意图。如图4所示,步骤S232可以包括:
S2321:构建数据窗口。
S2322:多次移动数据窗口,直至遍历工时数据集。
具体地,数据窗口可以理解为从工时数据集中选取预设数量的样本工时数据,每次移动数据窗口,即可以从工时数据集中选取到预设数量的样本工时数据。这样,在多次移动数据窗口后,可以遍历工时数据集,即将所有工时数据至少选取了一次。
应当理解的是,预设数量可以包括10、20等,预设数量可以根据实际情况进行设定,本申请对预设数量不作具体限定。
S2323:得到每次移动后数据窗口内数据的第一波动特征参数以及数据窗口移动的总次数。
具体地,每次移动数据窗口后,数据窗口内存在预设数量的样本工时数据,可以依据这些预设数量的样本工时数据,计算得到第一波动特征参数,然后在遍历工时数据集后,记录下数据窗口移动的总次数。
需要说明的是,第一波动特征参数表征在数据窗口内,预设数量的样本工时数据的标准差,这样,根据第一波动特征参数,可以推导数据窗口内的样本工时数据的平稳性。
应当理解的是,第一波动参数越大,表征数据窗口内的样本工时数据的平稳性越差,样本工时数据之间的差异越大;第一波动参数越小,表征数据窗口内的样本工时数据的平稳性越好,样本工时数据之间的差异越小。
在一实施例中,第一波动特征参数δ可以通过如下公式进行计算:
其中,δ表征第一波动特征参数;X
应当理解的是,在多次移动数据窗口后,可以计算得到多个第一波动特征参数,形成第一波动特征参数集合D:
D={δ
其中,t表征前述的数据窗口移动的总次数。
S2324:根据工时数据集,得到工时数据集内数据的第二波动特征参数。
具体地,第二波动特征参数可以表征工时数据集内所有工时数据的标准差,其计算的方式可以参照前述第一波动特征参数的计算方式。类似地,根据第二波动特征参数,可以推导工时数据集内的工时数据的平稳性,第二波动参数越大,表征工时数据集内的工时数据的平稳性越差,工时数据之间的差异越大;第二波动参数越小,表征工时数据集内的工时数据的平稳性越好,工时数据之间的差异越小。
S2325:根据数据窗口移动的总次数、多个第一波动特征参数以及第二波动特征参数,得到邻域最大半径。
具体地,若工时数据集中的工时数据发生变化或者工时数据的数量发生变化,多个第一波动特征参数和第二波动特征参数均会发生变化,相应地,邻域最大半径也会发生变化,后续依据邻域最大半径,进行聚类后的得到数据簇也就相应发生变化,其可以更准确地反应工时数据的特点,得到更加准确的工序标准化工时。
S2326:根据窗口移动的总次数,得到邻域中最少点数。
在一实施例中,邻域中最少点数可以等于窗口移动的总次数。
图5为本申请一示例性实施例提供的根据数据窗口移动的总次数、多个第一波动特征参数以及第二波动特征参数,得到邻域最大半径的流程示意图。如图5所示,步骤S2325可以包括:
S23251:根据多个第一波动特征参数和第二波动特征参数,得到多个第一波动特征参数与第二波动特征参数之间的最大差值和最小差值。
S23252:根据多个第一波动特征参数、最大差值、最小差值以及数据窗口移动的总次数,得到邻域最大半径。
具体地,计算邻域最大半径可以通过如下公式:
其中,EPS表征邻域最大半径;δ
由于前述的最大差值和最小差值表示对应的数据窗口内的样本工时数据与其它的工时数据之间的差异较大,会导致后续计算邻域最大半径的误差较大,因此,根据上述公式,在计算得到邻域最大半径的过程中,去掉了最大差值和最小差值,这样可以消除最大差值和最小差值对最大邻域半径的误差影响,提高最大邻域半径的准确性,从而有利于提高后续工序标准化工时的准确性。
图6为本申请一示例性实施例提供的根据聚类参数,执行聚类算法,得到工序标准化工时的流程示意图。如图6所示,步骤S233可以包括:
S2331:根据聚类参数,获取每个工位的工时数据集在邻域最大半径内的第一样本数量。
S2332:若第一样本数量大于或等于邻域中最少点数,将对应工位的工时数据集标定为有效簇。
S2333:根据多个有效簇,得到工序标准化工时。
具体地,在工时数据集中,遍历每个工位的每个工时数据,以每个工位的每个工时数据为中心,通过前述介绍的公式:
N
确定在邻域最大半径内的第一样本数量,然后判定第一样本数量与领域中最少点数之间的大小关系,若第一样本数量大于或等于邻域中最少点数,可以认为当前工位对应的工时数据集是较为收敛,可以标定为有效簇,并作为计算得到工序标准化工时的依据。
具体地,在得到多个有效簇,可以通过如下方式计算得到工序标准化工时:
T
其中,T
图7为本申请另一示例性实施例提供的根据聚类参数,执行聚类算法,得到工序标准化工时的流程示意图。如图7所示,在步骤S2331之后,步骤S233还可以包括:
S2334:若第一样本数量小于邻域中最少点数,将对应工位的工时数据集标定为异常簇。
具体地,若第一样本数量小于邻域中最少点数,可以认为当前工位对应的工时数据集是较为分散,误差较大,无法作为计算得到工序标准化工时的依据,可以标定为异常簇。
图8为本申请另一示例性实施例提供的根据聚类参数,执行聚类算法,得到工序标准化工时的流程示意图。如图8所示,在步骤S2332之后,步骤S233还可以包括:
S2335:校验有效簇,并输出校验结果。
S2336:若校验结果表征有效簇内存在额外簇,将额外簇从有效簇中分离出,并将额外簇作为新有效簇。
具体地,额外簇表征在有效簇内,在邻域最大半径内的样本数量大于或等于邻域最少点数的工时数据集。在得到有效簇后,可以对有效簇内的工时数据进行判断,确定有效簇内的工时数据是否还能单独聚类形成新的有效簇。因此,若校验结果表征有效簇内存在额外簇,将额外簇从有效簇中分离出,并将额外簇作为新有效簇,新有效簇将加入到原有的多个有效簇内,统一进行计算,得到工序标准化工时。
图9为本申请一示例性实施例提供的校验有效簇,并输出校验结果的流程示意图。如图9所示,步骤S2335可以包括:
S23351:获取有效簇内每组工时数据在邻域最大半径内的第二样本数量。
S23352:若第二样本数量大于或等于邻域最少点数,输出表征将对应组的工时数据标定为额外簇的校验结果。
具体地,在有效簇中,遍历有效簇内的每个工时数据,以每个工时数据为中心,通过前述介绍的公式:
N
确定在邻域最大半径内的第二样本数量,然后判定第二样本数量与领域中最少点数之间的大小关系,若第二样本数量大于或等于邻域中最少点数,可以认为当前组的工时数据集是较为收敛,可以将对应组的工时数据标定为额外簇,并输出对应的校验结果。
应当理解的是,若第二样本数量小于邻域中最少点数,那么可以当前组的工时数据集较为发散,无法形成新的有效簇,则直接保留原有的有效簇,进行后续的工序标准化工时计算。
图10为本申请另一示例性实施例提供的工序工时标准化方法的流程示意图。如图10所示,在步骤S220或者步骤S230之后,工序工时标准化方法还包括:
S240:获取所有物料的工序标准化工时和工序次数。
S250:选取工序次数相等的第一类物料和第二类物料。
S260:若第一类物料的工序标准化工时与第二类物料的工序标准化工时之差小于或者等于工时阈值,输出第一类物料和第二类物料的工序标准化工时合格的结果。
S270:若第一类物料的工序标准化工时与第二类物料的工序标准化工时之差大于工时阈值,输出第一类物料和/或第二类物料的工序标准化工时不合格的结果。
具体地,工序次数相等的第一类物料和第二类物料,可以认为是较为相似的物料,相似物料之间的工序标准化工时一般差别较小,因此,可以根据第一类物料与第二类物料之间的工序标准化工时,进行交叉校验,确认第一类物料和第二类物料的工序标准化工时是否合格。
具体地,若第一类物料的工序标准化工时与第二类物料的工序标准化工时之差小于或者等于工时阈值,则说明第一类物料和第二类物料满足相似物料之间的工序标准化工时差距较小的要求,因此,可以认为第一类物料和对第二类物料的工序标准化工时合格。若第一类物料的工序标准化工时与第二类物料的工序标准化工时之差大于工时阈值,则说明第一类物料和第二类物料不满足相似物料之间的工序标准化工时差距较小的要求,因此,可以认为第一类物料和对第二类物料中至少一者的工序标准化工时不合格,需要工作人员检验对应的工序标准化工时结果。
图11为本申请一示例性实施例提供的工序工时标准化装置的结构框图。如图11所示,本申请实施例提供的工序工时标准化装置400包括:第一获取模块410,配置为获取待加工物料的数量;第一计算模块420,配置为若待加工物料的数量小于数量阈值,运行标准计算模型,得到工序标准化工时;其中,标准计算模型表征应用加权平均算法的计算模型;以及第二计算模块430,配置为若待加工物料的数量大于或者等于数量阈值,运行聚类计算模型,得到工序标准化工时;其中,聚类计算模型标准应用聚类算法的计算模型。
本申请实施例提供的工序工时标准化装置,其通过获取待加工物料的数量,然后以待加工物料的数量作为依据,运行标准计算模型或者聚类计算模型,得到工序标准化工时;第一方面,相比于人工通过统计分析进行工序工时标准化作业的方法,应用标准计算模型和聚类计算模型,可以更加方便快捷地得到工序标准化工时,有效地提高工作效率;第二方面,其通过根据待加工物料的数量,判断工时数据的数量,然后运行标准计算模型或者聚类计算模型,以不同的计算方法对工时数据进行针对性的计算,消除一些差异较大的数据对标准化结果的影响,有效地提高工序标准化工时的精度;第三方面,其在待加工物料的数量大于或者等于数量阈值的情况下,运行聚类计算模型,得到工序标准化工时,解决了大量工时数据差异较大,无法得到准确工序标准化工时的问题,其在待加工物料的数量小于数量阈值的情况下,运行标准计算模型,得到工序标准化工,解决了工时数据较少时无法有效聚类的问题。
图12为本申请另一示例性实施例提供的工序工时标准化装置的结构框图。如图12所示,在一实施例中,第一计算模块420可以包括第二获取模块421,配置为:获取待加工物料在每个工位对应的多个工时数据;第三计算模块422,配置为根据多个工时数据,得到不同工位的权重系数;第四计算模块423,配置为根据多个工时数据和多个权重系数,得到工序标准化工时。
如图12所示,在一实施例中,第二计算模块430可以包括第三获取模块431,配置为获取待加工物料在多个工位的工时数据集;第五计算模块432,配置为根据工时数据集,得到聚类参数;其中,聚类参数包括邻域最大半径和邻域中最少点数;以及聚类模块433,配置为根据聚类参数,执行聚类算法,得到工序标准化工时。
如图12所示,在一实施例中,第五计算模块432可以包括构建模块4321,配置为构建数据窗口;其中,数据窗口表征从工时数据集中选取预设数量的样本工时数据;移动模块4322,配置为多次移动数据窗口,直至遍历工时数据集;第六计算模块4323,配置为得到每次移动后数据窗口内数据的第一波动特征参数以及数据窗口移动的总次数;其中,第一波动特征参数表征在数据窗口内,预设数量的样本工时数据的标准差;第七计算模块4324,配置为根据工时数据集,得到工时数据集内数据的第二波动特征参数;其中,第二波动特征参数表征工时数据集内所有工时数据的标准差;第八计算模块4325,配置为根据数据窗口移动的总次数、多个第一波动特征参数以及第二波动特征参数,得到邻域最大半径;第九计算模块4326,配置为根据窗口移动的总次数,得到邻域中最少点数。
如图12所示,在一实施例中,第八计算模块4325可以包括差值模块43251,配置为根据多个第一波动特征参数和第二波动特征参数,得到多个第一波动特征参数与第二波动特征参数之间的最大差值和最小差值;以及第十计算模块43252,配置为根据多个第一波动特征参数、最大差值、最小差值以及数据窗口移动的总次数,得到邻域最大半径。
如图12所示,在一实施例中,聚类模块433可以包括第四获取模块4331,配置为根据聚类参数,获取每个工位的工时数据集在邻域最大半径内的第一样本数量;第一标定模块4332,配置为若第一样本数量大于或等于邻域中最少点数,将对应工位的工时数据集标定为有效簇;第十一计算模块4333,配置为根据多个有效簇,得到工序标准化工时。
如图12所示,在一实施例中,聚类模块433可以包括第二标定模块4334,配置为若第一样本数量小于邻域中最少点数,将对应工位的工时数据集标定为异常簇。
如图12所示,在一实施例中,聚类模块433可以包括校验模块4335,配置为校验有效簇,并输出校验结果;
分离模块4336,配置为若校验结果表征有效簇内存在额外簇,将额外簇从有效簇中分离出,并将额外簇作为新有效簇;其中,额外簇表征在有效簇内,在邻域最大半径内的样本数量大于或等于邻域最少点数的工时数据集。
如图12所示,在一实施例中,校验模块4335可以包括第五获取模块43351,配置为获取有效簇内每组工时数据在邻域最大半径内的第二样本数量;第一输出模块43352,配置为若第二样本数量大于或等于邻域最少点数,输出表征将对应组的工时数据标定为额外簇的校验结果。
如图12所示,在一实施例中,工序工时标准化装置400可以包括第六获取模块440,配置为获取所有物料的工序标准化工时和工序次数;选取模块450,配置为选取工序次数相等的第一类物料和第二类物料;第二输出模块460,配置为若第一类物料的工序标准化工时与第二类物料的工序标准化工时之差小于或者等于工时阈值,输出第一类物料和第二类物料的工序标准化工时合格的结果;第三输出模块470,配置为若第一类物料的工序标准化工时与第二类物料的工序标准化工时之差大于工时阈值,输出第一类物料和/或第二类物料的工序标准化工时不合格的结果。
图13为本申请一示例性实施例提供的电子设备的结构框图。如图13所示,该电子设备600可以是第一设备和第二设备中的任一个或两者、或与它们独立的单机设备,该单机设备可以与第一设备和第二设备进行通信,以从它们接收所采集到的输入信号。
如图13所示,电子设备600包括一个或多个处理器610和存储器620,该存储器620可用于存储处理器可执行指令,该处理器610可用于运行可执行指令以实现如前所述的工序工时标准化方法。
处理器610可以是中央处理单元(CPU)或者具有数据处理能力和/或指令执行能力的其他形式的处理单元,并且可以控制电子设备600中的其他组件以执行期望的功能。
存储器620可以包括一个或多个计算机程序产品,所述计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。所述易失性存储器例如可以包括随机存取存储器(RAM)和/或高速缓冲存储器(cache)等。所述非易失性存储器例如可以包括只读存储器(ROM)、硬盘、闪存等。在所述计算机可读存储介质上可以存储一个或多个计算机程序指令,处理器610可以运行所述程序指令,以实现上文所述的本申请的各个实施例的控制方法以及/或者其他期望的功能。在所述计算机可读存储介质中还可以存储诸如输入信号、信号分量、噪声分量等各种内容。
在一个示例中,电子设备600还可以包括:输入装置630和输出装置640,这些组件通过总线系统和/或其他形式的连接机构(未示出)互连。
在该控制器是单机设备时,该输入装置630可以是通信网络连接器,用于从第一设备和第二设备接收所采集的输入信号。
此外,该输入装置630还可以包括例如键盘、鼠标等等。
该输出装置640可以向外部输出各种信息,包括确定出的距离信息、方向信息等。该输出装置640可以包括例如显示器、扬声器、打印机、以及通信网络及其所连接的远程输出设备等等。
当然,为了简化,图13中仅示出了该电子设备600中与本申请有关的组件中的一些,省略了诸如总线、输入/输出接口等等的组件。除此之外,根据具体应用情况,电子设备600还可以包括任何其他适当的组件。
所述计算机程序产品可以以一种或多种程序设计语言的任意组合来编写用于执行本申请实施例操作的程序代码,所述程序设计语言包括面向对象的程序设计语言,诸如Java、C++等,还包括常规的过程式程序设计语言,诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。
所述计算机可读存储介质可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以包括但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
以上结合具体实施例描述了本申请的基本原理,但是,需要指出的是,在本申请中提及的优点、优势、效果等仅是示例而非限制,不能认为这些优点、优势、效果等是本申请的各个实施例必须具备的。另外,上述公开的具体细节仅是为了示例的作用和便于理解的作用,而非限制,上述细节并不限制本申请为必须采用上述具体的细节来实现。
本申请中涉及的器件、装置、设备、系统的方框图仅作为例示性的例子并且不意图要求或暗示必须按照方框图示出的方式进行连接、布置、配置。如本领域技术人员将认识到的,可以按任意方式连接、布置、配置这些器件、装置、设备、系统。诸如“包括”、“包含”、“具有”等等的词语是开放性词汇,指“包括但不限于”,且可与其互换使用。这里所使用的词汇“或”和“和”指词汇“和/或”,且可与其互换使用,除非上下文明确指示不是如此。这里所使用的词汇“诸如”指词组“诸如但不限于”,且可与其互换使用。
还需要指出的是,在本申请的装置、设备和方法中,各部件或各步骤是可以分解和/或重新组合的。这些分解和/或重新组合应视为本申请的等效方案。
提供所公开的方面的以上描述以使本领域的任何技术人员能够做出或者使用本申请。对这些方面的各种修改对于本领域技术人员而言是非常显而易见的,并且在此定义的一般原理可以应用于其他方面而不脱离本申请的范围。因此,本申请不意图被限制到在此示出的方面,而是按照与在此公开的原理和新颖的特征一致的最宽范围。
为了例示和描述的目的已经给出了以上描述。此外,此描述不意图将本申请的实施例限制到在此公开的形式。尽管以上已经讨论了多个示例方面和实施例,但是本领域技术人员将认识到其某些变型、修改、改变、添加和子组合。
- 可弯曲电子设备、可弯曲电子设备的控制方法、装置及电子设备
- 一种工件工序加工时间的计算方法及装置
- 一种工件工序加工时间的计算方法及装置