一种基于自然文本描述的高保真三维人脸模型生成方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于计算机视觉领域,具体涉及一种基于自然文本描述的高保真三维人脸模型生成方法。
背景技术
3D人脸在现实许多领域中都有很高的要求,如数字人、临场感和电影特效等。而创建高保真3D人脸非常复杂,需要经验丰富的建模师花费大量时间。近年来,大批学者致力于文本到图像和图像到3D的合成,但这种模式会造成较大的中间误差,也缺乏在给定抽象描述的情况下合成3D人脸的能力。
当前,已经有部分学者尝试从文本中恢复出三维形状,但他们无法生成完全符合描述的三维模型。Chen等人(Kevin Chen,Christopher B Choy,Manolis Savva,Angel XChang,Thomas Funkhouser,and Silvio Savarese.Text2shape:Generating shapes fromnatural language by learning joint embeddings.In ACCV,pages 100–116.Springer,2018.2)提出,通过学习3D形状的语言和物理属性之间的隐式跨模态连接,从自然语言生成彩色3D形状。在进一步的研究中,Liu等人(Zhengzhe Liu,Yi Wang,Xiaojuan Qi,and Chi-Wing Fu.Towards implicit text-guided 3d shape generation.In CVPR,pages 17896–17906,2022.2)提出了对文本和形状中学习特征的形状和颜色预测进行解耦,并提出了单词级空间变换器,以将文本中的单词特征与形状中的空间特征相关联。在后续研究中,CLIP(Contrastive Language-Image Pre-training)发挥了重要作用,它是一个大型的预训练视觉语言模型,并且利用提示学习来利用CLIP模型的强大表示力。Jain等人(Ajay Jain,Ben Mildenhall,Jonathan T Barron,Pieter Abbeel,and Ben Poole.Zero-shot text-guided object generation with dream fields.In CVPR,pages 867–876,2022.2)提出将神经渲染与多模态图像和文本表示相结合,以从自然语言描述中合成不同的3D对象,Poole等人(Ben Poole,Ajay Jain,Jonathan T Barron,and BenMildenhall.Dreamfusion:Text-to-3d using 2ddiffusion.arXivpreprint arXiv:2209.14988,2022.2)进一步利用预训练的2D文本到图像扩散模型和NeRF,以更灵活的合成执行文本到3D的合成。
上述研究致力于从文本中恢复三维形状而非三维人脸,但目前只有Canfes等人(Zehranaz Canfes,M FurkanAtasoy,Alara Dirik,and Pinar Yanardag.Text and imageguided 3d avatar generation andmanipulation.arXiv preprint arXiv:2202.06079,2022.2,7)试图生成3D人脸,但其模型依赖于无约束的初始3D人脸,且仅适用于短语。因此,利用面部先验知识从自然语言文本中实现细粒度和高质量的3D人脸生成仍然是一个亟待解决的问题。
发明内容
为了从文本中直接生成精细的三维人脸模型,本发明提供了一种基于自然文本描述的高保真三维人脸模型生成方法。
为了实现上述发明目的,本发明方法采用的技术方案如下:
一种基于自然文本描述的高保真三维人脸模型生成方法,包括如下步骤:
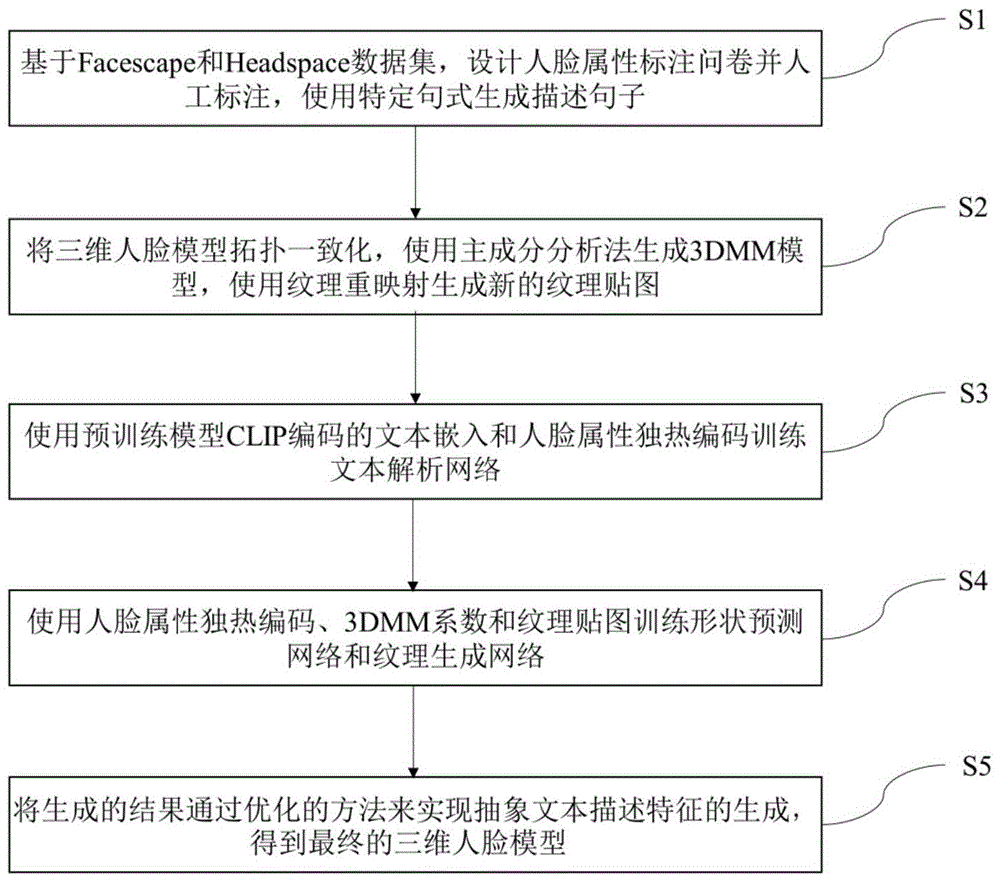
S1,获取三维人脸模型数据集,设计人脸面部属性描述问卷并人工标注,同时基于固定句式生成三维人脸模型对应的文本描述句子,生成人脸文本描述数据集;
S2,基于所述人脸文本描述数据集,利用非刚性迭代最近邻算法将所有三维人脸模型转变为拓扑一致的模型,即具有相同的顶点和面片数量的模型;将纹理重映射,生成对应于拓扑一致模型的纹理贴图;使用主成分分析法降维生成3DMM模型,获得对应的3DMM系数;
S3,根据步骤S1标注的人脸数据构建独热编码,使用预训练的视觉语言模型生成文本嵌入向量,构建文本解析网络训练数据,训练所述文本解析网络;
S4,根据步骤S3的独热编码和步骤2得到的3DMM系数、纹理贴图,训练从独热编码到3DMM系数和纹理贴图的网络,训练完成后将所述文本解析网络输出的几何独热编码和纹理独热编码分别输入形状预测网络和纹理生成网络生成对应的3DMM系数和纹理贴图;
S5,通过所述视觉语言模型的损失函数和L2损失函数优化所述形状预测网络和纹理生成网络输出的形状空间和纹理空间的参数向量,使其能符合抽象文本描述,并生成最终的三维人脸模型。
进一步地,所述步骤S3中,根据所述人脸面部属性描述问卷构建一个p×q维的矩阵,其中p表示p个不同的面部属性,q表示独热编码的维度;利用一个8层多层感知机作为文本解析网络,所述文本解析网络将视觉语言模型的文本嵌入向量作为输入,然后输出预测的独热编码,使用交叉熵损失作为训练的损失函数。
进一步地,所述步骤S4中,利用一个8层的多层感知机作为形状预测网络,所述形状预测网络将几何独热编码作为输入,然后输出对应的3DMM系数。
本发明构建了一个大规模文本-三维人脸数据集,包含不同对象的多种面部属性和自由描述,并提出了一个可行的从自由文本描述中生成三维人脸模型的方法。本发明首次实现了从自然文本描述中生成三维人脸模型,弥补了这方面的研究空白。所提出的方法可广泛应用于数字人、游戏创作、电影特效等领域,具有较高的实用价值和发展前景。
附图说明
图1为本发明方法的流程图。
图2为本发明实施例中人脸标注问卷的示意图。
图3为本发明实施例中特定区域三元组损失的示意图。
图4为本发明实施例中运行阶段的流程图。
图5为本发明实施例中的结果展示图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明的一种基于自然文本描述的高保真三维人脸模型生成方法,具体过程如下:
1.设计人脸描述标注问卷,从五官、肤色、胡须等涵盖了描述面部整体到局部的25个数据集属性,如图2所示。随后,从Facescape数据集(Yang,Haotian,et al."Facescape:alarge-scale high quality 3d face dataset and detailed riggable 3d faceprediction."Proceedings of the ieee/cvf conference on computer vision andpattern recognition.2020.)和Headspace数据集(Pears,N.E.(Creator),Duncan,C.(Creator),Smith,W.A.P.(Contributor),Dai,H.(Contributor)(6Jun 2018).TheHeadspace dataset.University of York.10.15124/6efa9588-b715-44ec-b7bb-f10dff7ca93e)中选取了1627个三维人脸模型,对每个人脸人工标注,获取其所有面部属性,并使用固定句式如“他的【眼睛】又【大】又【圆】”和“他有又【大】又【圆】的【眼睛】”的句式将其组合成完整的句子,构成文本描述-三维人脸数据集,具体如图2所示。
2.使用非刚性迭代最近邻算法,将所有的三维人脸模型注册为拓扑一致的三维网格,每个三维网格由26369个顶点和52536个面片组成。然后,将纹理重映射,获取对应于拓扑一致模型的纹理贴图,纹理贴图的分辨率为1024*1024,在本方法中,将纹理贴图降维到512*512分辨率以减小网络体积。随后,使用主成分分析法(Blanz,Volker,and ThomasVetter."A morphable model for the synthesis of 3D faces."Proceedings of the26th annual conference on Computer graphics and interactive techniques.1999.)将所有的三维人脸模型构造成一个三维形变人脸统计(3DMM)模型,生成对应的3DMM系数,每一个三维人脸形状由一个300维的向量表示;
3.根据先前标注的人脸数据,首先构造一个p×q维的矩阵,其中p表示p个不同的面部属性,q表示独热编码的维度。选取了除耳朵形状外的24个面部属性,设置p=24,q=8(根据8种眼型设置)。其中,p中有12个属性是对形状属性描述(眼睛大小、眼睛形状、眼间距、眼皮、鼻子大小、鼻翼宽窄、鼻梁高低、鼻基底形状、嘴巴宽窄、嘴唇厚薄、嘴唇形状、脸型、脸胖瘦、耳朵形状),9个属性是对纹理属性描述(眉毛形状、眉毛颜色、眉毛浓密、瞳孔颜色、有无胡须、胡须浓密、胡须颜色、胡须类型),3个公共属性描述(人种、性别和年龄)。这样,将人脸的所有属性用独热编码的形式表示。随后,使用大规模的预训练视觉语言模型CLIP(Radford,Alec,et al."Learning transferable visual models from naturallanguage supervision."International Conference on Machine Learning.PMLR,2021.),将标注的人脸属性根据上述固定句式组成句子,再经过CLIP的文本编码器将句子编码成512维的文本嵌入向量。这样,就将复杂的文本语义转换成了简单的编码和向量表示。设计一个8层的多层感知机作为文本解析网络,用前面构造的独热编码和文本嵌入向量来训练神经网络。采用交叉熵损失,具体的损失函数为:
其中,i是标注面部属性的索引,j是描述这一属性的特征选项的索引,y
4.根据独热编码的顺序,将其分为形状属性编码和纹理属性编码,并分别训练形状预测网络和纹理生成网络。
形状预测网络是一个8层多层感知机,输入形状属性的独热编码,输出对应的3DMM系数。使用带权重的L1损失函数和不同面部区域的三元组损失来训练形状预测网络。其中,带权重的L1损失函数是将面部分割为4个不同的区域:面部关键点、(眼睛、鼻子、嘴巴)、其他面部区域、除上述以外的其他区域,其他面部区域包括除去眼睛鼻子嘴巴以外的面部区域,其他区域包括耳朵和后脑勺。根据区域的重要性赋予不同的权重,68个面部关键点:(眼睛、鼻子、嘴巴):其他面部区域:(耳朵和后脑勺)=16:4:3:0。
其中α
特定区域的三元组损失是基于不同的区域构建面部的正反例数据对,使网络预测结果接近正例,远离反例,如图3所示。具体来说,以眼睛为例,当样本为小眼睛时,就从数据库中选取一个大眼睛的反例,并使网络预测结果接近样本真值,同时远离反例。损失函数为:
其中
纹理生成网络是一个基于StyleGAN(Karras,Tero,Samuli Laine,and TimoAila."Astyle-based generator architecture for generative adversarialnetworks."Proceedings of the IEEE/CVF conference on computer vision andpattern recognition.2019.)的网络结构,使用随机噪声z及独热编码作为网络的输入,训练其生成对应的纹理贴图。
基于步骤3中训练的文本解析网络,输入一段文本描述,可以预测出一个24*8的独热编码矩阵。将预测的形状属性的编码和纹理属性的编码分别输入训练好的的形状预测网络和纹理生成网络,得到3DMM系数和纹理贴图,可生成符合描述的三维人脸模型。
5.经过步骤4,已经可以获取符合文本描述的带纹理的三维人脸模型。除此之外,还可以通过抽象文本描述赋予其更独特的特征,如“他长得像托尼斯塔克”,“她化了妆”等。在抽象特征生成中,使用一个可微渲染器,将步骤4生成的三维人脸模型以-30°,0°,30°三个不同的角度渲染成二维图片,并使用CLIP模型将抽象文本描述编码为嵌入向量,使用CLIP Loss来衡量生成的三维模型和抽象文本描述的差异:
L
其中,E
同时,本实施例添加了两项正则化L2损失函数共同优化3DMM系数和纹理贴图,完整的损失函数为:
/>
其中,s
通过以上步骤,本发明可以从一段自然文本描述中直接生成高保真度的三维人脸模型,生成结果如图5所示。
本发明提出的基于自然文本的高保真三维人脸模型生成方法实现了从文本直接生成三维人脸,降低了三维模型获取成本,有助于三维人脸生成的相关研究,生成的三维人脸可应用于影视、游戏、安全等多个领域。
- 一种基于统一式生成模型的跨衰老人脸识别方法
- 一种基于特征描述子的三维模型双层检索方法和装置
- 训练描述文本生成模型的方法、生成描述文本的方法及装置
- 训练描述文本生成模型的方法、生成描述文本的方法及装置