基于上下文的模型选择
文献发布时间:2024-01-17 01:21:27
I.优先权要求
本申请要求于2020年11月24日提交的共同拥有的美国非临时专利申请No.17/102,748的优先权权益,其内容通过援引整体明确纳入于此。
II.领域
本公开一般涉及基于上下文的模型选择。
III.相关技术描述
技术进步已导致更小且更强大的计算设备。例如,当前存在各种各样的便携式个人计算设备,包括小型、轻量级且易于用户携带的无线电话(诸如移动和智能电话、平板设备和膝上型计算机)。这些设备可以在无线网络上传达语音和数据分组。此外,许多此类设备结合了附加功能性,诸如静态式数字相机、数字视频相机、数字录音机和音频文件播放器。此外,此类设备可以处理可执行指令,包括可被用于访问因特网的软件应用(诸如web浏览器应用)。如此,这些设备可以包括相当重要的计算能力,包括例如尝试识别音频信号中的声音事件(例如,关门、汽车喇叭等)的声音事件分类(SEC)系统、降噪系统、自动话音识别(ASR)系统、自然语言处理(NLP)系统等。
执行操作(诸如SEC、降噪、ASR、NLP等)的系统可以使用经训练以提供广泛适用性但难以更新或更新成本高昂的模型。例如,SEC系统一般使用监督式机器学习技术进行训练以识别在经标记训练数据中标识的具体声音集合。结果,每个SEC系统往往是特定于领域的(例如,能够对预定声音集合进行分类)。在该SEC系统被训练之后,更新该SEC系统以识别未在经标记训练数据中标识的新声音类别是困难的。附加地,SEC系统被训练以检测的一些声音类别可表示具有相较于经标记训练数据中所表示的更多变体的声音事件。尽管可以通过更新这些模型以提高用户设备通常暴露于的环境的准确性来提升用户体验,但是更新这些模型所涉及的训练可能非常耗时且需要大数据量,并且这些模型被更新以识别的不同类别(例如,用于SEC系统的不同的新声音)的数目可以快速增长以消耗设备处的大量存储器。
IV.概述
在一特定方面,一种设备包括一个或多个处理器,该一个或多个处理器被配置成从一个或多个传感器设备接收传感器数据。该一个或多个处理器还被配置成基于该传感器数据来确定该设备的上下文。该一个或多个处理器被进一步配置成基于该上下文来选择模型。该一个或多个处理器还被配置成使用该模型来处理输入信号以生成因上下文而异的输出。在一特定方面,一种方法包括:在设备的一个或多个处理器处从一个或多个传感器设备接收传感器数据。该方法包括在该一个或多个处理器处基于该传感器数据来确定该设备的上下文。该方法包括在该一个或多个处理器处基于该上下文来选择模型。该方法还包括在该一个或多个处理器处使用该模型来处理输入信号以生成因上下文而异的输出。在一特定方面,一种设备包括用于接收传感器数据的装置。该设备包括用于基于该传感器数据来确定上下文的装置。该设备包括用于基于该上下文来选择模型的装置。该设备还包括用于使用该模型来处理输入信号以生成因上下文而异的输出的装置。
在一特定方面,一种非瞬态计算机可读存储介质包括指令,这些指令在由处理器执行时使该处理器从一个或多个传感器设备接收传感器数据。这些指令在由该处理器执行时使该处理器基于该传感器数据来确定上下文。这些指令在由该处理器执行时使该处理器基于该上下文来选择模型。这些指令在由该处理器执行时还使该处理器使用该模型来处理输入信号以生成因上下文而异的输出。
本公开的其他方面、优点、和特征将在阅读整个申请后变得明了,整个申请包括以下章节:附图简述、详细描述、以及权利要求。
V.附图简述
图1是根据本公开的一些示例的包括被配置成执行基于上下文的模型选择的设备的系统的示例的框图。
图2是根据本公开的一些示例的解说图1的组件的操作的各方面的示图。
图3是根据本公开的一些示例的解说可由图1的设备执行的更新模型的各方面的示图。
图4是根据本公开的一些示例的解说更新声音事件分类模型以计及漂移的各方面的示图。
图5是根据本公开的一些示例的解说更新声音事件分类模型以计及新声音类别的各方面的示图。
图6是根据本公开的一些示例的解说可由图1的设备执行的更新模型的特定示例的示图。
图7是根据本公开的一些示例的解说可由图1的设备执行的更新模型的另一特定示例的示图。
图8是根据本公开的一些示例的解说图1的设备的特定示例的框图。
图9是根据本公开的一些示例的纳入图1的设备的各方面的交通工具的解说性示例。
图10解说了根据本公开的一些示例的纳入图1的设备的各方面的虚拟现实、混合现实或增强现实头戴式设备。
图11解说了根据本公开的一些示例的纳入图1的设备的各方面的可穿戴电子设备。
图12解说了根据本公开的一些示例的纳入图1的设备的各方面声控扬声器系统。
图13解说了根据本公开的一些示例的纳入图1的设备的各方面的相机。
图14解说了根据本公开的一些示例的纳入图1的设备的各方面的移动设备。
图15解说了根据本公开的一些示例的纳入图1的设备的各方面的助听器设备。
图16解说了根据本公开的一些示例的纳入图1的设备的各方面的空中设备。
图17解说了根据本公开的一些示例的纳入图1的设备的各方面的头戴式设备。
图18解说了根据本公开的一些示例的纳入图1的设备的各方面的电器。
图19是根据本公开的一些示例的解说图1的设备的操作方法的示例的流程图。
图20是解说根据本公开的一些示例的图1的设备的另一操作方法的示例的流程图。
图21是解说根据本公开的一些示例的图1的设备的另一操作方法的示例的流程图。
图22是解说根据本公开的一些示例的图1的设备的另一操作方法的示例的流程图。
图23是解说根据本公开的一些示例的图1的设备的另一操作方法的示例的流程图。
图24是解说根据本公开的一些示例的图1的设备的另一操作方法的示例的流程图。
VI.详细描述
执行操作(诸如SEC、降噪、ASR、NLP等)的系统可以使用经训练以提供广泛适用性但难以更新或更新成本高昂的模型。尽管可以通过更新模型以提升用户或用户装备通常暴露于的环境的准确性来改进用户体验,但是重新训练此类模型可能非常耗时并且需要大量数据。此外,随着用户在日常生活中遭遇到越来越多的环境和情况,更新模型以适配新的环境和情况会导致模型消耗不断增长的存储器量。
根据一些方面,所公开的系统和方法使用上下文感知模型选择基于所选模型将在其中使用的上下文(例如,声学环境)来从多个模型中进行选择。例如,可以为特定声学环境选择合适的声学模型,以在大多数语音用户接口应用中递送更好的用户体验。作为解说,为了向助听器的用户提供愉快的聆听体验,应当正确地估计周围的噪声。作为解说性非限制性示例,可以基于用户的特定位置(诸如特定街角、建筑物或餐厅)或者基于用户的环境类型(诸如在交通工具中、在公园中或在地铁站中)来选择恰适的模型。可以基于各种各样的技术中的一种或多种(诸如经由位置数据(例如,来自全球定位系统(GPS)系统)、活动检测数据、相机识别、音频分类、用户输入、一个或更多其他技术、或其任何组合)来标识特定上下文。
根据一些方面,嘈杂区域(诸如商场、餐厅、体育馆等)的声学特性可以是已知的,并且使得它们的模型供用户公开获得。当用户走进这些位置中的任一者时,可以向用户准予对该位置的模型的访问准许。在用户离开后,模型可从用户的设备中被移除或“修剪”。在另一方面,当用户从一个地方行进到另一地方(例如,驾车、步行或经由公共交通)时,用户的设备可换掉模型,以使得可以针对该用户遇到的每个位置或设置使用最恰适的模型。在一些方面,提供可用模型库以使得能够搜索和下载恰适的模型。一些模型可由其他用户上载(诸如已经基于其他用户的设备暴露于各种环境而被训练的经更新模型),并且可作为众包上下文感知模型库的一部分公开获得(或在具有具体访问准许的情况下获得)。
根据一特定方面,各模型可以通过以下方式来被组合或“概括”:将相关门类的类别分组到一个模型中并且创建各种源模型的集合。例如,在SEC应用中,可以基于位置、声音类型或一个或多个其他特性来对相关声音类别进行编群。为了解说,一个模型可以包括通常表示拥挤区域(诸如公共广场、购物中心、地铁等)的一群声音类别,而另一模型可以包括与家庭活动相关的一群声音类别。这些经概括模型基于经概括模型的广泛门类来实现普遍提升的性能,而同时相较于用于多个具体模型容适每个具体环境或活动的存储器量而言使用减少的存储器。此外,如果具体模型由于隐私问题或其他可访问性限制而不可用,则可以改为使用更通用的模型。例如,如果用户到达一家繁忙的餐厅,而该餐厅没有可供使用的用于该餐厅的具体公共模型,则可以改为将用于拥挤区域的通用模型或用于拥挤餐厅的通用模型下载到用户的设备并使用。
通过基于设备的上下文来改变模型,与针对所有上下文使用单个模型相比,使用此类模型的系统能以更高的准确性运转。此外,改变模型使此类系统能够以提高的准确性运转,而不会招致与针对特定上下文在设备处从头开始重新训练现有模型相关联的功耗、存储器要求和处理资源使用。使用基于上下文的经概括模型相较于使用默认模型而言实现系统的提升的性能,并且相较于下载多个高准确性的、因上下文而异的模型并在其之间进行切换而言还可以实现减少的带宽、存储器和处理资源使用。此外,使用基于上下文的模型的此类系统的操作实现设备自身的改进的操作,诸如通过在执行迭代或动态过程(例如,在噪声消除技术中)时由于使用特定于特定上下文的较高准确性模型而实现较快收敛。
本公开的各特定方面在下文参照附图来描述。在本说明书中,共用的特征由共用的附图标记来指定。如本文所使用的,各种术语是仅出于描述特定实现的目的使用的,而并不旨在限定实现。例如,单数形式的“一”、“某”和“该”旨在也包括复数形式,除非上下文另外明确指示。此外,本文所描述的一些特征在一些实现中是单数,而在其他实现中是复数。为了解说,图1描绘了包括一个或多个处理器(图1中的“(诸)处理器”110)的设备101,其指示在一些实现中,设备101包括单个处理器110,而在其他实现中,设备101包括多个处理器110。为了便于本文引述,此类特征一般被介绍为“一个或多个”特征,并且随后以单数或可任选的复数(通常由以“(诸)”结尾的术语来指示)引用,除非正在描述与这些特征中的多个特征相关的方面。
术语“包括”、“具有”和“含有”在本文中与“包含”、“带有”或“拥有”互换地使用。另外,术语“其中”与“在该情况下”互换地使用。如本文中所使用的,“示例性”指示一示例、一实现和/或一方面,并且不应当被构造为限制或指示偏好或优选实现。如本中文所使用的,用于修饰元素(诸如结构、组件、操作等)的序数词(例如,“第一”、“第二”、“第三”等)本身并不指示该元素相对于另一元素的任何优先级或次序,而是仅仅将该元素与具有相同名称(但使用序数词)的另一元素区分开。如本文中所使用的,术语“集(集合)”指一个或多个特定元素,而术语“多个”指多个特定元素(例如,两个或更多个特定元素)。
如本文中所使用的,“耦合”可包括“通信地耦合”、“电耦合”或“物理耦合”,并且可另外地(或替换地)包括其任何组合。两个设备(或组件)可以直接地或经由一个或多个其他设备、组件、导线、总线、网络(例如,有线网络、无线网络、或其组合)等间接地耦合(例如,通信地耦合、电耦合、或物理地耦合)。电耦合的两个设备(或组件)可被包括在相同设备或不同设备中,并且可以经由电子器件、一个或多个连接器或电感式耦合进行连接,作为解说性非限制性示例。在一些实现中,通信地耦合的两个设备(或组件)(诸如在电通信中)可以直接地或间接地经由一个或多个导线、总线、网络等发送和接收电信号(例如,数字信号或模拟信号)。如本文中所使用的,“直接耦合”指两个设备在没有居间组件的情况下耦合(例如,通信地耦合、电耦合或物理耦合)。
在本公开中,诸如“确定”、“计算”、“估计”、“移位”、“调整”等术语可被用于描述如何执行一个或多个操作。应当注意,此类术语不应被解读为限制性的,并且可以利用其他技术来执行类似的操作。另外,如本文中引用的,“生成”、“计算”、“估计”、“使用”、“选择”、“访问”和“确定”可以可互换地使用。例如,“生成”、“计算”、“估计”或“确定”参数(或信号)可指主动地生成、估计、计算或确定参数(或信号),或者可指使用、选择或访问(诸如由另一组件或设备)已经生成的参数(或信号)。
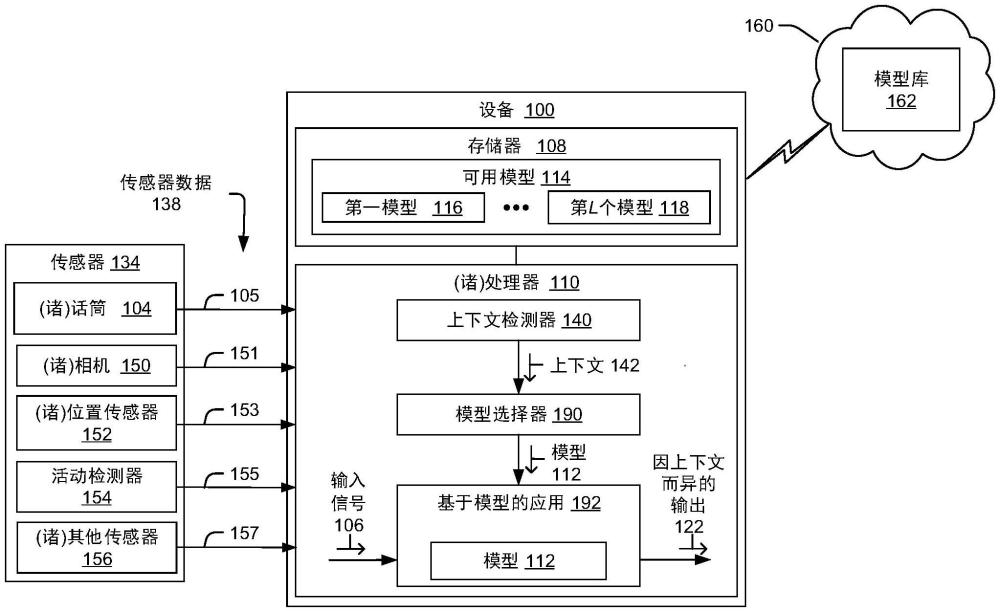
图1是包括被配置成执行基于上下文的模型选择的设备100的系统的示例的框图。设备100包括耦合到存储器108的一个或多个处理器110。存储器108包括可以由一个或多个处理器110选择的L个可用模型114(L是大于1的整数),其被解说为第一模型116以及包括第L个模型118的一个或多个附加模型。
一个或多个处理器110被配置成从一个或多个传感器设备134接收传感器数据138以及基于传感器数据138来确定设备100的上下文142。尽管传感器设备134被解说为耦合到设备100,但是在其他实现中,一个或多个(或所有)传感器设备134与设备100集成或被包括在设备100中。
一个或多个传感器设备134包括耦合到一个或多个处理器110的一个或多个话筒104,并且传感器数据138包括来自一个或多个话筒104的音频数据105。在一示例中,音频数据105对应于音频场景,并且上下文142至少部分地基于音频场景。为了解说,基于在音频数据中检测到的噪声的量和类型、以及声学特性(诸如回声和吸收),音频场景可以指示设备100处于密闭的嘈杂空间、大的封闭空间、大的室外空间、行进中交通工具等中。
一个或多个传感器设备134包括耦合到一个或多个处理器110的位置传感器152,并且传感器数据138包括来自位置传感器152(诸如为设备100提供全球位置数据的全球定位传感器)的位置数据153。在一示例中,位置数据153指示设备100的位置,并且上下文142至少部分地基于该位置。
一个或多个传感器设备134包括耦合到一个或多个处理器110的相机150,并且传感器数据138包括来自相机150的图像数据151(例如,静止图像数据、视频数据或这两者)。在一示例中,图像数据151对应于视觉场景,并且上下文142至少部分地基于该视觉场景。
一个或多个传感器设备134包括耦合到一个或多个处理器110的活动检测器154,并且传感器数据138包括运动数据,诸如来自活动检测器154的活动数据155。在一示例中,运动数据对应到设备100的运动,并且上下文142至少部分地基于设备100的该运动。
一个或多个传感器设备134还可包括一个或多个其他传感器156,其向一个或多个处理器110提供附加传感器数据157以供在确定上下文142时使用。(诸)其他传感器156可包括例如取向传感器、磁力计、光传感器、接触传感器、温度传感器、或耦合到设备100或被包括在设备100内并且可被用于生成对确定在特定时间与设备100相关联的上下文142有用的传感器数据157的任何其他传感器。作为另一示例,(诸)其他传感器156可以包括无线网络检测器,其可被用于确定上下文142,诸如通过检测设备100何时在已识别的无线网络位置附近(例如,通过检测与设备100的用户的朋友或家人相关联的家庭或企业WiFi网络或者蓝牙网络)。
一个或多个处理器110包括上下文检测器140、模型选择器190和基于模型的应用192。在特定实现中,上下文检测器140是被训练以基于传感器数据138来确定上下文142的神经网络。在其他实现中,上下文检测器140是使用不同机器学习技术来训练的分类器。例如,上下文检测器140可以包括或对应于决策树、随机森林、支持向量机或被训练以基于传感器数据138来生成指示上下文142的输出的另一分类器。在又其他实现中,上下文检测器140使用试探法基于传感器数据138来确定上下文142。在又其他实现中,上下文检测器140使用人工智能和试探法的组合基于传感器数据138来确定上下文142。例如,传感器数据138可包括图像数据、视频数据或这两者,并且上下文检测器140可包括使用机器学习技术训练以检测特定对象、运动、背景或其他图像或视频信息的图像识别模型。在这个示例中,图像识别模型的输出可以经由一个或多个试探法来评估以确定上下文142。
模型选择器190被配置成基于上下文142来选择模型112。在一些实现中,模型112是从存储在存储器108处的多个可用模型114中选择的。在一些实现中,模型112是从可经由网络160访问的模型库162(诸如可用于搜索和下载的基于云的模型库)中选择的。模型库162的示例将参考图2进一步详细地描述。
如本文中所使用的,“下载”和“上载”模型包括在有线链路、无线链路或其组合上传递与模型相对应的数据(例如,经压缩数据)。例如,无线局域网(“WLAN”)可被用来作为有线网络的代替或补充。无线技术(诸如
设备(例如,先前提及的那些设备)可能具有蓝牙和Wi-Fi能力、或其他无线方式来相互通信。联网设备可能具有相互通信的无线方式,并且还可能基于不同的蜂窝通信系统(诸如长期演进(LTE)系统、码分多址(CDMA)系统、用于移动通信(GSM)系统的全球系统、无线局域网(WLAN)系统或其他一些无线系统)来连通。CDMA系统可以实现宽带CDMA(WCDMA)、CDMA1X、演进数据优化(EVDO)、时分同步CDMA(TD-SCDMA)或某个其他版本的CDMA。如本文中所使用的,“无线”指一种或多种以上列出的技术、能够经由除了有线以外的方式来传递信息的一种或多种其他技术、或其组合。
基于模型的应用192被配置成使用所选模型112来处理输入信号106以生成因上下文而异的输出122。尽管解说了单个基于模型的应用192,但是在其他实现中,一个或多个处理器110可以使用基于上下文142选择的各种模型112来执行多个基于模型的应用192以执行各种操作。
例如,在一些实现中,模型112包括声音事件检测模型,并且输入信号106包括音频信号(诸如来自话筒104的音频数据105、从存储器108处的音频文件检索的音频数据、经由无线传输(诸如电话呼叫或流送式音频会话)接收的音频信号、或其任何组合。基于模型的应用192被配置成使用声音事件检测模型来处理输入信号106以生成包括对音频信号中的声音事件的分类的因上下文而异的输出122。
在一些实现中,模型112包括降噪模型,并且输入信号106包括音频信号(诸如来自话筒104的音频数据105、从存储器108处的音频文件检索的音频数据、经由无线传输(诸如电话呼叫或流送式音频会话)接收的音频信号、或其任何组合。基于模型的应用192被配置成使用降噪模型来处理输入信号106以生成包括基于音频信号的经降噪音频信号的因上下文而异的输出122。
在一些实现中,模型112包括自动话音识别(ASR)模型,并且输入信号106包括音频信号(诸如来自话筒104的音频数据105、从存储器108处的音频文件检索的音频数据、经由无线传输(诸如电话呼叫或流送式音频会话)接收的音频信号、或其任何组合。基于模型的应用192被配置成使用ASR模型来处理输入信号106以生成包括表示音频信号中的话音的文本数据的因上下文而异的输出122。
在一些实现中,模型112包括自然语言处理(NLP)模型,并且输入信号106包括文本数据,诸如由NLP模型生成的文本数据、用户键盘输入、文本消息等。基于模型的应用192被配置成使用NLP模型来处理输入信号106以生成包括基于文本数据的NLP输出数据的因上下文而异的输出122。
在一些实现中,模型112与设备操作模式的自动调整相关联。例如,模型112可以基于上下文142将用户输入(例如,语音命令、手势、触摸屏选择等)映射到或以其他方式关联到操作模式调整。为了解说,当基于与公共区域相对应的上下文142选择模型112时,模型112可以使基于模型的应用192将用户命令“播放音乐”映射到用户的耳机处的回放操作,并且因上下文而异的输出122可以包括用于调整设备操作模式以发起音频回放操作以及将输出音频信号路由到用户的耳机的信号。然而,当基于与用户房屋相对应的上下文142选择模型112时,模型112可以使基于模型的应用192将“播放音乐”命令映射到用户家庭娱乐系统处的回放操作,并且因上下文而异的输出122可以包括用于调整设备操作模式以发起音频回放以及将输出音频信号路由到家庭娱乐系统的扬声器的信号。
在一些实现中,模型选择器190被配置成响应于检测到上下文142中的改变(诸如当上下文142中的改变导致模型112不再适用于改变的上下文142或相比于另一可用模型而言更不适用于改变的上下文142时)来修剪模型112。如本文中所使用的,“修剪”模型包括停止使用该模型,诸如通过在基于模型的应用192处用另一模型替代该模型、从存储器108中永久删除该模型、从基于模型的应用192中删除该模型、将该模型标记为未使用、以其他方式使该模型不可访问(例如,通过删除对模型的访问准许,如参考图2进一步描述的)、或其组合。在一些实现中,修剪模型可以减少存储器使用、处理器循环、一个或多个其他处理或系统资源、或其组合,并且因此可以改进一个或多个处理器110或设备100整体的运作(例如,提高的速度、降低的功耗)。在其中模型已在设备100处被更新的实现中,修剪模型可以包括保留对模型的更新。例如,作为解说性的非限制性示例,如果在设备100处的使用期间已创建或修改了声音模型以标识新声音类别(诸如参考图3-5所描述的),则这些新声音类别可被保留(诸如在存储器108中或上载到模型库162)。
在操作期间,上下文检测器140监视传感器数据138并且可以基于检测到传感器数据138中的改变来更新上下文142。响应于上下文142的改变,模型选择器190访问存储器108中、模型库162中、或这两者中的可用模型114以选择可能比当前模型112更适用于经更新上下文142的一个或多个模型。例如,模型选择器190可以向模型库162发送标识上下文142的一个或多个方面(诸如地理位置、场所名称、声学场景或视觉场景描述、一个或多个其他方面或其组合)的查询。模型选择器190可以接收查询的结果、基于查询结果来选择特定模型、以及使设备100从模型库162下载特定模型并且将所下载的模型存储在存储器108中。在一些实现中,响应于检测到上下文142已改变,当前选择的模型112被修剪(例如,模型选择器190使基于模型的应用192停止使用模型112)并且被从存储器108下载的模型所替代。
通过基于上下文142来改变模型,与使用单个默认模型相比,设备100能以更高的准确性执行基于模型的应用192。结果,可以提升设备100的用户体验。
在一些实现中,设备100还被配置成修改或定制所选模型112以进一步提高准确性,诸如响应于检测到新声音事件或可能无法被模型112准确标识的现有分类的变体。基于在设备100处获取的数据(例如,传感器数据138)来修改模型112的示例将参考图3-5进一步描述。在修改模型112之后,设备100可以将经修改的模型112上载到模型库162以可用于其他设备。在一些实现中,模型112包括从另一用户设备上载到库162的经训练模型。因此,设备100可以利用分布式上下文感知系统中的众包模型库并对其作出贡献。设备100可以包括、对应于或被包括在以下各项内:语音激活的设备、音频设备、无线扬声器和语音激活的设备、便携式电子设备、汽车、交通工具、计算设备、通信设备、物联网(IoT)设备、虚拟现实(VR)设备、增强现实(AR)设备、混合现实(MR)设备、助听器设备、智能扬声器、移动计算设备、移动通信设备、智能手机、蜂窝电话、膝上型计算机、计算机、平板式设备、个人数字助理、显示设备、电视、游戏控制台、电器、音乐播放器、收音机、数字视频播放器、数字视频光盘(DVD)播放器、调谐器、相机、导航设备或其任何组合。在一特定方面,一个或多个处理器110、存储器108或其组合被包括在集成电路中。包括设备100的各方面的各种实现将参考图7-16进一步描述。
尽管设备100被描述为将可用模型114存储在存储器108中并且访问模型库162,但是在其他实现中,设备100可以不将模型存储在存储器108处,并且可以改为响应于检测到上下文142中的改变而从模型库162中检索模型。在其他实现中,设备100在不访问模型库162的情况下操作,并且改为从存储器108处的可用模型114之中进行选择。在一些实现中,存储器108处的可用模型114表示分布式上下文感知系统的本地存储的部分并且可以作为模型库162的一部分被其他设备访问,诸如在对等模型共享配置中。
尽管传感器134被解说为包括(诸)话筒104、(诸)相机150、(诸)位置传感器152、活动检测器154和(诸)其他传感器156,但在其他实现中,(诸)话筒104、(诸)相机150、(诸)位置传感器152、活动检测器154或其他传感器156中的一者或多者被省略。在解说性示例中,上下文检测器140仅使用音频数据105、图像数据151、位置数据153、活动数据155或该另一传感器数据157进行操作。在另一解说性示例中,上下文检测器140使用音频数据105、图像数据151、位置数据153、活动数据155和该另一传感器数据157中的两者,使用音频数据105、图像数据151、位置数据153、活动数据155和该另一传感器数据157中的三者,或者使用音频数据105、图像数据151、位置数据153、活动数据155和该另一传感器数据157中的四者进行操作。
尽管上下文检测器140、模型选择器190和基于模型的应用192被描述为单独的组件,但是在其他实现中,上下文检测器140和模型选择器190被组合成单个组件,模型选择器190和基于模型的应用192被组合成单个组件,或者上下文检测器140、模型选择器190和基于模型的应用192被组合成单个组件。在一些实现中,上下文检测器140、模型选择器190和基于模型的应用192中的每一者可以经由处理器执行的指令、专用硬件或电路系统或这两者的组合来实现。
图2解说了设备100和模型库162的操作的各方面的特定示例。设备100被解说在建筑物202(诸如办公楼)内,该建筑物202包括房间204、房间206和电梯208。设备100与模型库162处于无线通信。
模型库162包括各种类型的模型,诸如代表性声音事件检测模型220、代表性降噪模型222、代表性ASR模型224、代表性NLP模型226、代表性操作模式调整模型228、以及各种声学模型250。尽管出于解说清楚起见,解说了声音事件检测模型220、降噪模型222、ASR模型224、NLP模型226和操作模式调整模型228中的每一者的单个模型,但是应当理解,模型库162可以包括这些不同类型的模型中的每一者的多个版本,诸如已经针对不同上下文、不同个性化和不同通用性级别以与下面关于声学模型250描述的类似方式被训练的模型。
声学模型250以如下布置来解说:用于通用门类的模型(例如,经概括模型)被描绘为树结构的根,并且用于更具体的上下文的模型被描绘为树结构的分支或叶。例如,“拥挤区域”模型252是通用门类模型,其分支包括(诸)“高速公路”模型、(诸)“地铁中心”模型、(诸)“郊区”模型、(诸)“主题公园”模型、(诸)“购物中心”模型和(诸)“公共广场”模型。尽管未解说,但分支模型中的每一者都可用作用于各种更具体模型的通用门类模型。例如,模型库162可以包括用于多个具体主题公园的声学模型。如果用户的设备(例如,设备100)在特定主题公园处,则该设备可以请求用于该特定主题公园的声学模型。如果没有声学模型可用于该特定主题公园,则用户的设备可以请求“主题公园”模型,该“主题公园”模型广泛地适用于主题公园但不专门用于任何特定主题公园。如果“主题公园”模型不可用,则用户的设备可以请求“拥挤区域”模型,该“拥挤区域”模型广泛地适用于拥挤区域但不专用于主题公园。因此,用户的设备可以搜索并选择在模型库162中可用于该设备的特定上下文的最具体模型。
声学模型250还包括“密闭空间”模型254,它是具有与“办公楼”模型262、“房屋”模型264和“交通工具”模型266相对应的分支的通用门类模型。“办公楼”模型262是用于办公楼内的各种位置的通用门类模型。用于办公楼内的各种位置的更具体模型包括“大厅”模型270、“电梯”模型272和“办公室”模型274。“房屋”模型264是用于房屋内的各种位置的通用门类模型。用于房屋内的位置的更具体模型包括“厨房”模型、“房间”模型和“车库”模型。“交通工具”模型266是用于交通工具内的各种位置的通用门类模型。用于交通工具内的位置的更具体模型包括“驾驶座”模型、“乘客座椅”模型和“后座”模型。
应当理解,所解说的模型是出于解说和解释清楚的目的而描绘的。在其他实现中,模型库162可以具有以任何数目的通用性级别、针对任何数目的不同上下文、针对任何数目的不同应用布置的任何数目(例如,数百、数千、数百万等)的模型。还应当理解,虽然声学模型250是根据树结构来组织的,但是在其他实现中,模型库162利用一种或多种其他数据结构或分类技术作为树结构的代替或补充。
如所解说的,设备100基于传感器134来确定设备100的上下文142在房间204内。设备100可以确定模型库162的可用声学模型250是否包括特定于与上下文142相关联并且可用于设备100(例如,模型选择器190)的特定声学环境的声学模型。例如,设备100传送指示设备100的声学环境210的数据,诸如位置数据、建筑物202的名称、建筑物202的通用描述(例如,“办公楼”)、房间204的通用描述(例如,“办公室”)或其任何组合。在特定实现中,响应于模型库162不具有特定于特定声学环境210并且可用于一个或多个处理器110的声学模型,设备100(例如,模型选择器190)确定用于特定声学环境210的通用门类的声学模型是否可用。
作为解说性示例,设备100可以通过传送设备100的位置坐标来发送指示声学环境210的数据。如果模型库162具有特定于(例如,匹配)设备100的位置的声学模型(例如,与包含设备100的位置的区域的地理围栏相对应的声学模型),则设备100下载与该位置相对应的声学模型212。否则,响应于模型库216不具有特定于位置坐标(例如,不特定于建筑物202)的模型,设备100可以传送指示声学环境210的附加数据,诸如房间204的“办公室”描述符。响应于确定模型库162包括可用于设备100的“办公室”模型274,设备100下载“办公室”模型274作为声学模型212以供在房间204内使用。在“办公室”模型274不可用的情况下,设备100可以请求更通用的“办公楼”模型262,或者甚至更通用的“密闭空间”模型254。在一些实现中,模型库162被配置成自动定位并且向设备100传送与声学环境210相对应的最具体模型,而不是设备100发送对越来越概括的模型的一系列请求直到定位到恰适模型。
在一些实现中,设备100还可以接收授权设备100访问声学模型212的一个或多个访问准许214。访问准许214可以实现预存留设备100被预测要使用的模型。例如,经预存留的模型可以在所预测使用之前从模型库162被下载到设备100的存储器108。提前下载此类模型可以基于可用带宽来调度(例如,在网络话务减少的时段期间),或者以在检测到设备100的上下文142已改变时减少访问模型的等待时间。经预存留模型中的每一者在存储器108处保持不可访问(例如,被加密),直到从模型库162或另一准许管理系统接收到对模型的对应准许214(例如,加密密钥)。例如,设备100可以至少部分地基于设备100的位置与关联于模型112的特定位置(例如,特定位置)相匹配来接收对模型112的访问准许214。
在特定示例中,设备100传送指示房间204的声学环境210的数据,从模型库162接收“办公室”模型274(以及任何相关联的访问准许214),在存储器108处存储“办公室”模型274的副本,以及在基于模型的应用197处使用“办公室”模型274(诸如以执行降噪)。当设备100在建筑物202内从房间204被移动到电梯208时,设备100检测到新上下文142并请求用于与电梯208相对应的声学环境210的声学模型。作为响应,“电梯”模型272作为声学模型212被传送给设备100,并且还可以传送对“电梯”模型272的访问准许214。设备100在基于模型的应用192处用“电梯”模型272替代“办公室”模型274。在一些实现中,设备100从存储器108中移除“办公室”模型274,诸如当在存储器108处的可用存储容量受约束时。
在退出电梯208并进入房间206之际,设备100可以搜索存储器108处的可用模型114以寻找“办公室”模型274。如果在存储器108处“办公室”模型不可用,则设备100传送指示房间206的声学环境210的数据,从模型库162接收“办公室”模型274(以及任何相关联的访问准许214),在存储器108处存储“办公室”模型274的副本,以及在基于模型的应用197处使用“办公室”模型274。因此,随着设备100从一个位置移动到下一位置,模型被切换为针对设备100的变化的上下文142的更恰适模型。在一些实现中,当设备100退出建筑物202时,可以删除或存档存储器108中特定于建筑物202的任何所存储模型以节省存储器108中的存储空间,或者可以响应于对模型的使用施加的地理或其他约束的访问准许214而使其不可访问。
结合参照图1和图2所描述的各个方面,设备100包括一个或多个处理器110,其被配置成选择与建筑物中设备100位于其中的特定房间相对应的声学模型(诸如与建筑物202的房间204相对应的声学模型212),以及使用声学模型212来处理输入音频信号。例如,输入信号106可以包括由(诸)话筒104生成并且在基于模型的应用192处理以执行降噪的音频数据105。
在一些实现中,一个或多个处理器110被配置成响应于确定设备100已进入该特定房间204而从声学模型库162下载声学模型212。在一些实现中,一个或多个处理器110被进一步配置成响应于设备100离开特定房间204而移除声学模型212。作为非限制性示例,移除声学模型212可包括:在基于模型的应用192处用另一模型替代声学模型212,从存储器108中删除声学模型212,从基于模型的应用192中删除声学模型212,将声学模型212标记为未使用,或使声学模型212不可访问(例如,删除对声学模型212的访问准许214)。
耦合到一个或多个处理器110的一个或多个传感器设备134(也被称为“传感器134”)被配置成生成指示设备100的位置的传感器数据138,并且一个或多个处理器110被配置成基于传感器数据138来选择声学模型212。例如,设备100可以包括调制解调器(如参考图6所描述的),该调制解调器耦合到一个或多个处理器110并且被配置成接收指示设备100的位置的位置数据153,并且一个或多个处理器110被配置成基于位置数据153来选择声学模型212。
在一些实现中,可以基于上下文142预测性地执行对模型的选择。例如,基于传感器数据138(例如,活动检测、GPS分析、相机识别、音频分类、或其组合),一个或多个处理器110可以确定设备100的用户正行进至新位置(例如,纽约市),其中与用户关联的辅助式物联网(IoT)设备可以通过用于新位置的经更新设置来展示提升的性能。结果,可以从存储器108中或从一个或多个模型库(例如,模型库162)中检索并使用恰适的源模型(例如,用于交通的声学模型)。在离开新位置之际,用于新位置的源模型被移除并且先前源模型可以被恢复。
结合参照图1和图2所描述的各个方面,响应于设备100进入交通工具(诸如进一步参照图7所描述的),一个或多个处理器110被配置成从与交通工具相对应的多个个性化声学模型之中为设备100的用户选择个性化声学模型,以及使用该个性化声学模型来处理输入音频信号。例如,设备100可以训练或以其他方式生成特定于设备100的特定用户的模型(如参考图3-图5进一步详细描述的),以及可以从模型库162、存储器108或这两者访问个性化声学模型。为了解说,一个或多个处理器110可以被配置成响应于确定设备100已进入交通工具而从声学模型库下载个性化声学模型(例如,模型库162中的声学模型250)。在一些实现中,一个或多个处理器110被进一步配置成响应于设备100离开交通工具而移除个性化声学模型。
例如,一个或多个处理器110可以被配置成基于传感器数据138来确定设备100已进入交通工具。为了解说,一个或多个处理器110可以基于位置数据153来确定设备100已进入交通工具(或已退出交通工具)。
结合参照图1和图2所描述的各个方面,设备100的一个或多个处理器110被配置成下载与设备100位于其中的特定位置相对应的声学模型,使用该声学模型来处理输入音频信号,以及响应于设备100退出该位置而移除该声学模型。在解说性示例中,位置对应于特定餐厅,并且该声学模型是响应于确定设备100已进入该特定餐厅而从声学模型库(例如,模型库162中的声学模型250)下载的。
结合参照图1和图2所描述的各个方面,设备100的一个或多个处理器110被配置成选择与特定位置相对应的声学模型,至少部分地基于设备100的位置与特定位置匹配而接收对于该声学模型的访问准许,以及使用该声学模型来处理输入音频信号。
在一些实现中,作为解说性的非限制性示例,图1和图2的设备100被进一步配置成更新一个或多个模型,诸如以将用于特定用户的模型个性化或提供用于设备100频繁遭遇的环境的模型的准确性。图3-5描绘了其中设备100被配置成更新模型的解说性示例。尽管图3-5描述了更新声音事件分类模型作为特定示例,但是所描述的技术一般适用于更新设备100可以使用的任何类型的模型。
图3是设备100的组件的示例的框图,设备100被配置成响应于音频数据样本310而生成声音标识数据并且被配置成更新声音事件分类模型。图3的设备100包括一个或多个话筒304(例如,(诸)话筒104),其被配置成基于在声学环境内检测到的声音302来生成音频信号306(例如,音频数据105)。(诸)话筒304耦合到基于音频信号306生成音频数据样本310的特征提取器308。例如,音频数据样本310可以包括数据元素的阵列或矩阵,其中每个数据元素对应于在音频信号306中所检测到的特征。作为具体示例,音频数据样本310可以对应于从一秒音频信号306中提取的梅尔频谱特征。在该示例中,音频数据样本310可以包括128x128的特征值元素矩阵。在其他示例中,可以使用其他音频数据样本配置或大小。
音频数据样本310被提供给声音事件分类(SEC)引擎320(例如,基于模型的应用192)。SEC引擎320被配置成基于一个或多个SEC模型(诸如SEC模型312)来执行推断操作。“推断操作”指在音频数据样本310的声音类别被SEC模型312识别出的情况下将音频数据样本310指派给该声音类别。例如,SEC引擎320可以包括或对应于实现机器学习运行时环境的软件,诸如高通神经处理SDK(Qualcomm Neural Processing SDK),其可从美国加利福尼亚州圣地亚哥的高通技术公司获得。在一特定方面,SEC模型312是可用于SEC引擎320的多个SEC模型(例如,可用SEC模型314)之一。
在特定示例中,每个可用SEC模型314(例如,存储在存储器108处或模型库162处)包括或对应于被训练为声音事件分类器的神经网络。为了解说,SEC模型312(以及其他可用SEC模型314中的每一者)可以包括输入层、一个或多个隐藏层和输出层。在该示例中,输入层被配置成对应于由特征提取器308生成的音频数据样本310的值阵列或矩阵。为了解说,如果音频数据样本310包括15个数据元素,则输入层可以包括15个节点(例如,每数据元素一个节点)。输出层被配置成对应于SEC模型312被训练以识别的声音类别。输出层的具体布置可以取决于要作为输出来提供的信息而变化。作为一个示例,SEC模型312可以被训练以输出包括每声音类别一个比特的阵列,其中输出层执行“独热编码”以使得输出阵列的除一个比特之外的所有比特都具有值0,并且对应于检测到的声音类别的比特具有值1。可使用其他输出方案来指示例如每个声音类别的置信度量值,其中置信度量值指示音频数据样本310对应于相应声音类别的概率估计。为了解说,如果SEC模型312被训练以识别四个声音类别,则SEC模型312可以生成包括四个值(每声音类别一个值)的输出数据,并且每个值可以指示音频数据样本310对应于相应声音类别的概率估计。
隐藏层中的每一者包括多个节点,并且每个节点与相同层或不同层中的其他节点(经由链路)互连。节点的每个输入链路与链路权重相关联。在操作期间,节点从该节点被链接至的其他节点接收输入值,基于对应的链路权重对输入值进行加权以确定组合值,以及将组合值代入激活函数以生成该节点的输出值。输出值经由节点的输出链路被提供给一个或多个其他节点。节点还可以包括被用于生成组合值的偏置值。各节点可以按各种布置进行链接并且可以包括各种其他特征(例如,先验值记忆)以促成特定数据的处理。在音频数据样本的情形中,可以使用卷积神经网络(CNN)。为了解说,SEC模型312中的一者或多者可包括三个经链接CNN,并且每个CNN可包括二维(2D)卷积层、最大池化层和批归一化层。在其他实现中,隐藏层包括不同数目的CNN或其他层。训练神经网络包括修改链路权重以减小该神经网络的输出误差。
在操作期间,SEC引擎320可以将音频数据样本310作为输入提供给单个SEC模型(例如,SEC模型312)、提供给多个所选SEC模型(例如,SEC模型312和可用SEC模型314中的第K个SEC模型318)或提供给每个SEC模型(例如,SEC模型312、可用SEC模型314中的第一SEC模型316、第K个SEC模型318和任何其他SEC模型)。例如,SEC引擎320(或设备100的另一组件)可以基于例如用户输入、与设备100相关联的设备设置、传感器数据、音频数据样本310被接收的时间,或其他因素来从可用SEC模型314之中选择SEC模型312。在该示例中,SEC引擎320可以选择仅使用SEC模型312或者可以选择使用可用SEC模型314中的两个或更多个SEC模型。为了解说,设备设置可以指示在特定时间帧期间要使用SEC模型312和第一SEC模型316。在另一示例中,SEC引擎320可以(例如,顺序地或并行地)将音频数据样本310提供给可用SEC模型314中的每一者以从每个SEC模型生成输出。在一特定方面,SEC模型被训练以识别不同的声音类别、以识别不同声学环境中的相同声音类别、或这两者。例如,SEC模型312可被配置成识别第一声音类别集合并且第一SEC模型316可被配置成识别第二声音类别集合,其中第一声音类别集合不同于第二声音类别集合。
在一特定方面,SEC引擎320基于SEC模型312的输出来确定SEC模型312是否识别出音频数据样本310的声音类别。如果SEC引擎320将音频数据样本310提供给多个SEC模型,则SEC引擎320可以基于这些SEC模型中的每一者的输出来确定这些SEC模型中是否有任一者识别出音频数据样本310的声音类别。如果SEC模型312(或可用SEC模型314中的另一者)识别出音频数据样本310的声音类别,则SEC引擎320生成指示音频数据样本310的声音类别322的输出324。例如,输出324可以被发送给显示器以向用户通知检测到与声音302相关联的声音类别322或可以被发送给另一设备或设备100的另一组件并且被用于触发动作(例如,响应于识别出关门的声音而发送命令以激活灯)。
如果SEC引擎320确定SEC模型312(以及可用SEC模型114中被提供了音频数据样本310的其他SEC模型)没有识别出音频数据样本310的声音类别,则SEC引擎320向漂移检测器328提供触发信号326。例如,SEC引擎320可以在设备100的存储器中设置触发标志。在一些实现中,SEC引擎320还可以向漂移检测器328提供其他数据。为了解说,如果SEC模型312针对SEC模型312被训练以识别的每个声音类别生成置信度量值,则这些置信度量值中的一者或多者可被提供给漂移检测器328。例如,如果SEC模型312被训练以识别三个声音类别,则SEC引擎320可以向漂移检测器328提供由SEC模型312输出的三个置信值(这三个声音类各一个)之中的最高置信值。
在一特定方面,SEC引擎320基于置信度量值来确定SEC模型312是否识别出音频数据样本310的声音类别。在此特定方面,特定声音类别的置信度量值指示音频数据样本310的与该特定声音类相关联的概率。为了解说,如果SEC模型312被训练以识别四个声音类别,则SEC模型312可以生成包括四个置信度量值(每个声音类别一个值)的阵列作为输出。在一些实现中,如果音频数据样本310的声音类别322的置信度量值大于检测阈值,则SEC引擎320确定SEC模型312识别出声音类别322。例如,如果音频数据样本310的声音类别322的置信度量值大于0.90(例如,90%置信度)、0.95(例如,95%置信度)或检测阈值的某个其他值,则SEC引擎320确定SEC模型312识别出声音类别322。在一些实现中,如果SEC模型312被训练以识别的每个声音类别的置信度量值小于检测阈值,则SEC引擎320确定SEC模型312未识别出音频数据样本310的声音类别。例如,如果每个置信度量值小于0.90(例如,90%置信度)、0.95(例如,95%置信度)或检测阈值的某个其他值,则SEC引擎320确定SEC模型312未识别出音频数据样本310的声音类别322。
漂移检测器328被配置成确定不能够识别出音频数据样本310的声音类别的SEC模型312是否对应于与音频数据样本310相关联的音频场景342。在图1中所解说的示例中,场景检测器340(例如,上下文检测器140)被配置成接收场景数据338(例如,包括传感器数据138的一部分)以及使用场景数据338来确定与音频数据样本310相关联的音频场景342(例如,上下文142)。在一特定方面,场景数据338是基于指示与设备100相关联的一个或多个设备设置的设置数据330、时钟332的输出、来自一个或多个传感器334(例如,传感器134)的传感器数据、经由输入设备336接收到的输入或其组合来生成的。在一些方面,场景检测器340使用与SEC引擎320用来选择SEC模型312的信息不同的信息来确定音频场景342。为了解说,如果SEC引擎320基于一天中的时间来选择SEC模型312,则场景检测器340可以使用来自(诸)传感器334中的位置传感器的位置传感器数据来确定音频场景342。在一些方面,场景检测器340使用与SEC引擎320用来选择SEC模型312的信息相同的信息中的至少一些信息并使用附加信息。为了解说,如果SEC引擎320基于一天中的时间和设置数据330来选择SEC模型312,则场景检测器340可以使用位置传感器数据和设置数据330来确定音频场景342。因此,场景检测器340使用与由SEC引擎320用来选择SEC模型312的音频场景检测模式不同的音频场景检测模式。
在特定实现中,场景检测器340是被训练以基于场景数据338来确定音频场景342的神经网络。在其他实现中,场景检测器340是使用不同机器学习技术来训练的分类器。例如,场景检测器340可以包括或对应于决策树、随机森林、支持向量机或被训练以生成基于场景数据338指示音频场景342的输出的另一分类器。在又其他实现中,场景检测器340使用试探法基于场景数据338来确定音频场景342。在又其他实现中,场景检测器340使用人工智能和试探法的组合基于场景数据338来确定音频场景342。例如,场景数据338可包括图像数据、视频数据或这两者,并且场景检测器340可包括使用机器学习技术训练以检测特定对象、运动、背景或其他图像或视频信息的图像识别模型。在这个示例中,图像识别模型的输出可以经由一个或多个试探法来评估以确定音频场景342。
漂移检测器328将场景检测器340所指示的音频场景342与描述SEC模型312的信息进行比较,以确定SEC模型312是否与音频数据样本310的音频场景342相关联。如果漂移检测器328确定SEC模型312与音频数据样本310的音频场景342相关联,则漂移检测器328使漂移数据344被存储为模型更新数据348。在特定实现中,漂移数据344包括音频数据样本310和标签,其中该标签标识SEC模型312、指示与音频数据样本310相关联的声音类别、或这两者。如果漂移数据344指示与音频数据样本310相关联的声音类别,则该声音类别可以基于由SEC模型312生成的最高置信度值而被选择。作为解说性示例,如果SEC引擎320使用检测阈值0.90,并且对于特定声音类别,由SEC模型312输出的最高置信度量值是0.85,则SEC引擎320确定未识别出音频数据样本310的声音类别并且向漂移检测器328发送触发信号326。在该示例中,如果漂移检测器328确定SEC模型312对应于音频数据样本310的音频场景342,则漂移检测器328将音频数据样本310存储为与特定声音类别相关联的漂移数据344。在一特定方面,与SEC模型314相关联的元数据包括指定与每个SEC模型314相关联的一个或多个音频场景的信息。例如,SEC模型312可以被配置成检测用户家庭中的声音事件,在这种情形中,与SEC模型312相关联的元数据可以指示SEC模型312与“家庭”音频场景相关联。在该示例中,如果音频场景342指示设备100在家庭位置(例如,基于定位信息、用户输入、检测到家庭无线网络信号、表示家庭位置的图像或视频数据等),则漂移检测器328确定SEC模型312对应于音频场景342。
在一些实现中,漂移检测器328还使一些音频数据样本310被存储为模型更新数据348并且被指定为未知数据346。作为第一示例,如果漂移检测器328确定SEC模型312不对应于音频数据样本310的音频场景342,则漂移检测器328可以存储未知数据346。作为第二示例,如果由SEC模型312输出的置信度量值未能满足漂移阈值,则漂移检测器328可以存储未知数据346。在此示例中,漂移阈值小于由SEC引擎320使用的检测阈值。例如,如果SEC引擎320使用检测阈值0.95,则漂移阈值可以具有0.80、0.75或小于0.95的某个其他值。在该示例中,如果音频数据样本310的最高置信度量值小于漂移阈值,则漂移检测器328确定音频数据样本310属于SEC模型312未被训练以识别的声音类别并将音频数据样本310指定为未知数据346。在一特定方面,如果漂移检测器328确定SEC模型312对应于音频数据样本310的音频场景342,则漂移检测器328仅存储未知数据346。在另一特定方面,漂移检测器328存储未知数据346,而无论漂移检测器328是否确定SEC模型312对应于音频数据样本310的音频场景342。
在模型更新数据348被存储之后,模型更新器352可以访问模型更新数据348并且使用模型更新数据348来更新可用SEC模型314之一(例如,SEC模型312)。例如,模型更新数据348的每个条目指示与该条目相关联的SEC模型,并且模型更新器352使用该条目作为训练数据来更新对应的SEC模型。在一特定方面,当更新准则被满足时或当用户或另一方(例如,设备100的供应商、SEC引擎320、SEC模型314等)发起模型更新时,模型更新器352更新SEC模型。当模型更新数据348中有特定数目的条目可用时、当模型更新数据348中对于特定SEC模型有特定数目的条目可用时、当模型更新数据348中对于特定声音类别有特定数目的条目可用时、当自先前更新以来已经流逝了特定时间量时、当发生其他更新时(例如,当发生与设备100相关联的软件更新时)、或基于另一事件的发生,更新准则可被满足。
模型更新器352利用反向传播或类似的机器学习优化过程使用漂移数据344作为经标记训练数据来更新SEC模型312的训练。例如,模型更新器352提供来自模型更新数据348的漂移数据344的音频数据样本作为SEC模型312的输入,基于SEC模型312的输出和与音频数据样本相关联的标签(如在由漂移检测器328所存储的漂移数据344中指示的)来确定误差函数(也被称为损失函数)的值,以及使用梯度下降操作(或其某个变体)或另一机器学习优化过程来确定SEC模型312的经更新的链路权重。
模型更新器352(除了漂移数据344的音频数据样本之外)还可以在更新训练期间向SEC模型312提供其他音频数据样本。例如,模型更新数据348可以包括一个或多个已知音频数据样本(诸如最初用来训练SEC模型312的音频数据样本的子集),这可以减少更新训练导致SEC模型312遗忘先前训练的机会(其中这里的“遗忘”指失去检测SEC模型312先前被训练以识别的声音类别的可靠性)。由于与漂移数据344的音频数据样本相关联的声音类别由漂移检测器328指示,因此更新训练以计及漂移可以自动完成(例如,无需用户输入)。结果,设备100的功能性(例如,识别声音类别的准确性)可以在没有用户干预的情况下随时间推移而改进并且使用相较于会被用来从头开始生成新SEC模型的计算资源少的计算资源。参考图4描述了模型更新器352可用于基于漂移数据344来更新SEC模型312的迁移学习过程的特定示例。
在一些方面,模型更新器352还可以使用模型更新数据348的未知数据346来更新SEC模型312的训练。例如,周期性地或偶尔地,诸如当更新准则被满足时,模型更新器352可以提示用户要求该用户标记模型更新数据348中的未知数据346的条目的声音类别。如果用户选择标记未知数据346的条目的声音类别,则设备100(或另一设备)可以播放与未知数据346的音频数据样本相对应的声音。用户可以(例如,经由输入设备336)提供标识音频数据样本的声音类别的一个或多个标签350。如果由用户指示的声音类别是SEC模型312被训练以识别的声音类别,则未知数据346被重新分类为与用户指定的声音类别和SEC模型312相关联的漂移数据344。取决于模型更新器352的配置,如果由用户指示的声音类别是SEC模型312未被训练以识别的声音类别(例如,是新声音类别),则模型更新器352可以丢弃未知数据346,向另一设备发送未知数据346和用户指定的声音类别以供用于生成新SEC模型或经更新的SEC模型,或者可以使用未知数据346和用户指定的声音类别来更新SEC模型312。参考图5描述了模型更新器352可用于基于未知数据346和用户指定的声音类别来更新SEC模型312的迁移学习过程的特定示例。
由模型更新器352生成的经更新SEC模型354被添加到可用SEC模型314,以使得经更新SEC模型354可用于评估在生成经更新SEC模型354之后接收到的音频数据样本310。因此,可被用于评估声音的可用SEC模型314集合是动态的。例如,可用SEC模型314中的一者或多者可被自动地更新以计及漂移数据344。附加地,可用SEC模型314中的一者或多者可使用迁移学习操作来更新以计及未知声音类别,这些迁移学习操作相较于从头开始训练新SEC模型而言使用更少的计算资源(例如,存储器、处理时间和功率)。
图4是解说根据特定示例的解说更新SEC模型408以计及漂移的各方面的示图。图4的SEC模型408包括或对应于图3的可用SEC模型314中与漂移数据344相关联的特定SEC模型。例如,如果SEC引擎320响应于SEC模型312的输出而生成了触发信号326,则漂移数据344与SEC模型312相关联,并且SEC模型408对应于或包括SEC模型312。作为另一示例,如果SEC引擎320响应于第K个SEC模型318的输出而生成了触发信号326,则漂移数据344与第K个SEC模型318相关联,并且SEC模型408对应于或包括第K个SEC模型318。
在图4中所解说的示例中,训练数据402被用于更新SEC模型408。训练数据402包括漂移数据344和一个或多个标签404。漂移数据344的每个条目包括音频数据样本(例如,音频数据样本406)并且与(诸)标签404中的对应标签相关联。漂移数据344的条目的音频数据样本包括表示从未被SEC模型408识别的声音中提取的或基于该声音来确定的特征的值集合。与漂移数据344的条目相对应的标签404标识预期声音所属的声音类别。作为示例,与漂移数据344的条目相对应的标签404可以是由图3的漂移检测器328响应于确定SEC模型408对应于生成音频数据样本的音频场景而指派的。在该示例中,漂移检测器328可以将音频数据样本指派给在SEC模型408的输出中与最高置信度量值相关联的声音类别。
在图4中,对应于声音的音频数据样本406被提供给SEC模型408,并且SEC模型408生成输出410,该输出410指示音频数据样本406被指派给的声音类别、一个或多个置信度量值、或这两者。模型更新器352使用输出410和与音频数据样本406相对应的标签404来确定SEC模型408的经更新链路权重412。SEC模型408基于经更新链路权重412来被更新,并且迭代地重复训练过程,直到训练终止条件被满足。在训练期间,漂移数据344的每个条目可被提供给SEC模型408(例如,每次迭代一个条目)。附加地,在一些实现中,其他音频数据样本(例如,先前用于训练SEC模型408的音频数据样本)也可以被提供给SEC模型408以减小SEC模型408遗忘先前训练的机会。
当所有漂移数据344已被提供给SEC模型408至少一次时、在已执行了特定次数的训练迭代之后、当收敛度量满足收敛阈值时、或当指示训练结束的某个其他条件得到满足时,训练终止条件可被满足。当训练终止条件被满足时,模型更新器352存储经更新的SEC模型414,其中经更新SEC模型414对应于具有基于在训练期间应用的经更新链路权重412的链路权重的SEC模型408。
图5是解说根据特定示例的基于训练数据502来更新SEC模型510以计及未知数据的各方面的示图。图5的SEC模型510包括或对应于图3的可用SEC模型314中与未知数据346相关联的特定SEC模型。例如,如果SEC引擎320响应于SEC模型312的输出而生成了触发信号326,则未知数据346与SEC模型312相关联,并且SEC模型510对应于或包括SEC模型312。作为另一示例,如果SEC引擎320响应于第K个SEC模型318的输出而生成了触发信号326,则未知数据346与第K个SEC模型318相关联,并且SEC模型510对应于或包括第K个SEC模型318。
在图5的示例中,模型更新器352生成更新模型506。更新模型506包括要被更新的SEC模型510、增量模型508和一个或多个适配器网络512。增量模型508是SEC模型510的具有与SEC模型510不同的输出层的副本。具体而言,增量模型508的输出层相较于SEC模型510的输出层而言包括更多的输出节点。例如,SEC模型510的输出层包括第一计数个节点(例如,N个节点,其中N是与SEC模型510被训练以识别的声音类别的数目相对应的正整数),并且增量模型508的输出层包括第二计数个节点(例如,N+M个节点,其中M是与经更新SEC模型524被训练以识别而SEC模型510未被训练以识别的新声音类别的数目相对应的正整数)。第一节点计数对应于SEC模型510被训练以识别的第一声音类别集合的声音类别计数(例如,第一声音类别集合包括SEC模型510能识别的N个不同的声音类别),并且第二节点计数对应于经更新SEC模型524要被训练以识别的第二声音类别集合的声音类别计数(例如,第二声音类别集合包括经更新SEC模型524要被训练以识别的N+M个不同的声音类别)。第二声音类别集合包括第一声音类别集合(例如,N个类别)加上一个或多个附加声音类别(例如,M个类别)。增量模型508的模型参数(例如,链路权重)被初始化为等于SEC模型510的模型参数。
(诸)适配器网络512包括神经适配器和合并适配器。神经适配器包括一个或多个适配器层,这些适配器层被配置成从SEC模型510接收输入并生成可以与增量模型508的输出合并的输出。例如,SEC模型510生成与第一声音类别集合的第一类别计数相对应的第一输出。在一特定方面,第一输出包括针对SEC模型510的输出层的每个节点的一个数据元素(例如,N个数据元素)。相比之下,增量模型508生成与第二声音类别集合的第二类别计数相对应的第二输出。例如,第二输出包括针对增量模型508的输出层的每个节点的一个数据元素(例如,N+M个数据元素)。在该示例中,(诸)适配器网络512的适配器层接收SEC模型510的输出作为输入并且生成具有第二计数个(例如,N+M个)数据元素的输出。在特定示例中,(诸)适配器网络512的适配器层包括两个全连接层(例如,包括N个节点的输入层和包括N+M个节点的输出层,其中输入层的每个节点连接到输出层的每一个节点)。
(诸)适配器网络512的合并适配器被配置成:通过将(诸)适配器层的输出和增量模型508的输出合并来生成更新模型506的输出514。例如,合并适配器按逐元素方式将(诸)适配器层的输出和增量模型508的输出组合以生成组合输出,并且将激活函数(诸如sigmoid函数)应用于该组合输出以生成输出514。输出514指示由更新模型506将音频数据样本504指派给的声音类别、由更新模型506确定的一个或多个置信度量值、或这两者
模型更新器352使用输出504和与音频数据样本514相对应的标签350来确定增量模型508、(诸)适配器网络512或这两者的经更新链路权重508。SEC模型510的链路权重在训练期间未改变。迭代地重复训练过程,直到训练终止条件被满足。在训练期间,未知数据346的每个条目可被提供给更新模型506(例如,每次迭代一个条目)。附加地,在一些实现中,其他音频数据样本(例如,先前用于训练SEC模型510的音频数据样本)也可以被提供给更新模型506以减小增量模型508遗忘SEC模型510的先前训练的机会。
当所有未知数据346都已被提供给更新模型506至少一次时、在已执行了特定次数的训练迭代之后、当收敛度量满足收敛阈值时、或当指示训练结束的某个其他条件得到满足时,训练终止条件可被满足。当训练终止条件被满足时,模型检查器520从增量模型508与更新模型506之间选择经更新的SEC模型524(例如,SEC模型510、增量模型508和(诸)适配器网络512的组合)。
在一特定方面,模型检查器520基于由增量模型508指派的声音类别522的准确性和由SEC模型510指派的声音类别522的准确性来选择经更新SEC模型524。例如,模型检查器520可以确定增量模型508的F1得分(基于由增量模型508指派的声音类别522)和SEC模型510的F1得分(基于由SEC模型510指派的声音类别522)。在该示例中,如果增量模型508的F1得分值大于或等于SEC模型510的F1得分值,则模型检查器520选择增量模型508作为经更新SEC模型524。在一些实现中,如果增量模型508的F1得分值大于或等于SEC模型510的F1得分值(或小于SEC模型510的F1得分值不到阈值量),则模型检查器520选择增量模型508作为经更新SEC模型524。如果增量模型508的F1得分值小于SEC模型510的F1得分值(或小于SEC模型510的F1得分值超过阈值量),则模型检查器520选择更新模型506作为经更新SEC模型524。如果增量模型508被选择为经更新SEC模型524,则SEC模型510、(诸)适配器网络512或这两者可被丢弃。
在一些实现中,模型检查器520被省略或与模型更新器352集成。例如,在训练更新模型506之后,更新模型506可被存储为经更新SEC模型524(例如,没有更新模型506与增量模型508之间的选择)。作为示例,在训练更新模型506之时,模型更新器352可以确定增量模型508的准确性度量。在这个示例中,训练终止条件可以基于增量模型508的准确性度量,以使得在训练之后,增量模型508被存储为经更新SEC模型524(例如,没有更新模型506与增量模型508之间的选择)。
利用参考图5所描述的迁移学习技术,模型检查器520使图3的设备100能够更新SEC模型以识别先前未知的声音类别。附加地,所描述的迁移学习技术使用比会被用来从头开始训练SEC模型的计算机资源(例如,存储器、处理时间和功率)少得多的计算机资源来识别先前未知的声音类别。
在一些实现中,参考图4所描述的操作(例如,基于漂移数据344来生成经更新SEC模型414)在图3的设备100处(例如,在一个或多个处理器110处)执行,并且参考图5所描述的操作(例如,基于未知数据346来生成经更新SEC模型524)在不同设备(诸如图8的远程计算设备818)处执行。为了解说,未知数据346和(诸)标签350可以在设备100处被捕获并且被传送到具有更多的可用计算资源的第二设备。在该示例中,第二设备生成经更新SEC模型524并且设备100从第二设备下载或接收表示经更新SEC模型524的传输或数据。相较于基于漂移数据344来生成经更新SEC模型414,基于未知数据346生成经更新SEC模型524是资源更密集的过程(例如,使用更多的存储器、功率和处理器时间)。因此,在不同设备之间划分参考图4所描述的操作和参考图5所描述的操作可以节省设备100的资源。
图6是解说图1的设备100的操作的特定实例的示图,其中关于活跃SEC模型(例如,SEC模型312)是否对应于音频数据样本310被捕获的音频场景的确定基于将当前音频场景与先前音频场景作比较。
在图6中,由(诸)话筒104捕获的音频数据被用于生成音频数据样本310。音频数据样本310被用于执行音频分类602。例如,可用SEC模型314中的一者或多者被图3的SEC引擎320用作活跃SEC模型。在一特定方面,活跃SEC模型是在先前采样周期期间基于由场景检测器340指示的音频场景(其也被称为先前音频场景608)来从可用SEC模型314之中选择的。
音频分类602使用活跃SEC模型基于对音频数据样本310的分析来生成结果604。结果604可指示与音频数据样本310相关联的声音类别、音频数据样本310对应于特定声音类别的概率、或音频数据样本310的声音类别是未知的。如果结果604指示音频数据样本310对应于已知的声音类别,则在框606作出决策以生成指示与音频数据样本310相关联的声音类别322的输出324。例如,图1的SEC引擎320可以生成输出324。
如果结果604指示音频数据样本310不对应于已知的声音类别,则在框606作出决策以生成触发326。触发326激活漂移检测方案,其在图6中包括使场景检测器340基于来自(诸)传感器134的数据来标识当前音频场景607。
在框610,将当前音频场景607与先前音频场景608进行比较以确定自选择活跃SEC模型以来是否已发生音频场景改变。在框612,作出关于音频数据样本310的声音类别是否由于漂移而未被识别的确定。例如,如果当前音频场景607不对应于先前音频场景608,则框612的确定是:漂移不是音频数据样本310的声音类别未被识别的原因。在这种情况下,音频数据样本310可以被丢弃或者在框614被存储为未知数据。
如果当前音频场景607对应于先前音频场景608,则在框612的确定是:音频数据样本310的声音类别由于漂移而未被识别,这是因为活跃SEC模型对应于当前音频场景607。在这种情况下,已漂移了的声音类别在框616被标识,并且音频数据样本310和该声音类别的标识符在框618被存储为漂移数据。
当存储了足够的漂移数据时,SEC模型在框620被更新以生成经更新SEC模型354。经更新SEC模型354被添加到可用SEC模型314。在一些实现中,经更新SEC模型354替代生成了结果604的活跃SEC模型。
图6是解说图1的设备100的操作的另一特定实例的示图,其中关于活跃SEC模型(例如,SEC模型312)是否对应于音频数据样本310被捕获的音频场景的确定基于将当前音频场景描述活跃SEC模型的信息作比较。
在图6中,由(诸)话筒104捕获的音频数据被用于生成音频数据样本310。音频数据样本310被用于执行音频分类602。例如,可用SEC模型314中的一者或多者被图3的SEC引擎320用作活跃SEC模型。在一特定方面,活跃SEC模型是从可用SEC模型314之中选择的。在一些实现中,使用可用SEC模型314的集合,而不是选择可用SEC模型314中的一者或多者作为活跃SEC模型。
音频分类602使用可用SEC模型中的一者或多者基于对音频数据样本310的分析来生成结果604。结果604可指示与音频数据样本310相关联的声音类别、音频数据样本310对应于特定声音类别的概率、或音频数据样本310的声音类别是未知的。如果结果604指示音频数据样本310对应于已知的声音类别,则在框606作出决策以生成指示与音频数据样本310相关联的声音类别322的输出324。例如,图3的SEC引擎320可以生成输出324。
如果结果604指示音频数据样本310不对应于已知的声音类别,则在框606作出决策以生成触发326。触发326激活漂移检测方案,其在图7中包括使场景检测器340基于来自(诸)传感器134的数据来标识当前音频场景以及确定当前音频场景是否对应于生成导致要发送触发326的结果604的SEC模型。
在框612,作出关于音频数据样本310的声音类别是否由于漂移而未被识别的确定。例如,如果当前音频场景不对应于生成了结果604的SEC模型,则框612的确定是:漂移不是音频数据样本310的声音类别未被识别的原因。在这种情况下,音频数据样本310可以被丢弃或者在框614被存储为未知数据。
如果当前音频场景对应于生成了结果604的SEC模型,则框612处的确定是:音频数据样本310的声音类别由于漂移而未被识别。在这种情况下,已漂移了的声音类别在框616被标识,并且音频数据样本310和该声音类别的标识符在框618被存储为漂移数据。
当存储了足够的漂移数据时,SEC模型在框620被更新以生成经更新SEC模型354。经更新SEC模型354被添加到可用SEC模型314。在一些实现中,经更新SEC模型354替代生成了结果604的活跃SEC模型。
如参考图3-7所描述的用于更新模型的操作可以结合如参考图1-2所描述的基于上下文的模型选择来使用。例如,一起住在第一住所(例如,农村房屋)的第一人和第二人可能具有使用与第一住所相关联的共用模型的设备,并且可以通过训练模型来更新此类模型以容适与第一住所相关联的新声音事件和漂移。在第一人移动到第二住所(例如,大学宿舍)之后,第一人的设备可以更新一个或多个模型以提高第二住所处的准确性,并且因此由第一人和第二人的设备使用的模型可能会显著不同。在第一人返回到第一住所之际,第一人的设备可以选择并下载由第二人的设备使用的模型,以在第一住所处的使用期间达成更高的准确性。例如,第二个人可以提供访问准许以与第一人的设备共享一个或多个模型,诸如经由设备之间的对等传递或经由本地无线家庭网络。在退出第一住所之际,第一人的设备可以移除与第一住所相关联的共享模型并且恢复到与第二住所相关联的模型。
图8是解说图1的设备100的特定实例的框图。在各种实现中,设备100可具有比图8中所解说的更多或更少的组件。
在特定实现中,设备100包括处理器804(例如,中央处理单元(CPU))。设备100可以包括一个或多个附加处理器806(例如,一个或多个数字信号处理器(DSP))。处理器804、(诸)处理器806或这两者可对应于一个或多个处理器110。例如,在图8中,(诸)处理器806包括上下文检测器140、模型选择器190和基于模型的应用192。
在图8中,设备100还包括存储器108和CODEC(编解码器)824。存储器108存储可由处理器804或(诸)处理器806执行的指令860,以实现参考图1-7所描述的一个或多个操作。在一示例中,存储器108对应于存储可由一个或多个处理器110执行的指令860的非瞬态计算机可读介质,并且指令860包括或对应于上下文检测器140(例如,可由处理器执行以执行对上下文检测器140作出贡献的操作)、模型选择器190、基于模型的应用192或其组合。存储器108还可以存储可用模型114。
在图8中,(诸)扬声器822和(诸)话筒104可被耦合到CODEC 824。在图8中所解说的示例中,CODEC 824包括数模转换器(DAC 826)和模数转换器(ADC 828)。在特定实现中,CODEC 824从(诸)话筒104接收模拟信号,使用ADC 828将模拟信号转换成数字信号,以及向(诸)处理器806提供数字信号。在特定实现中,(诸)处理器806向CODEC 824提供数字信号,并且CODEC 824使用DAC 826将数字信号转换为模拟信号,以及向(诸)扬声器822提供模拟信号。
在图8中,设备100还包括输入设备336。设备100还可以包括耦合到显示控制器810的显示器820。在一特定方面,输入设备336包括传感器、键盘、定点设备等。在一些实现中,输入设备336和显示器820在触摸屏或类似的触摸或运动敏感显示器中被组合。
在一些实现中,设备100还包括耦合到收发机814的调制解调器812。如图8所示,收发机814耦合到天线816以实现与其他设备(诸如远程计算设备818(例如,存储模型库162的至少一部分的服务器或网络存储器))的无线通信。例如,调制解调器812可被配置成至少部分地基于设备100的位置与特定位置相匹配而经由无线传输从远程计算设备818接收模型112、对模型112的访问准许或这两者。在其他示例中,收发机814另外地或者替换地耦合到通信端口(例如,以太网端口)以实现与其他设备(诸如远程计算设备818)的有线通信。
在图8中,设备100包括时钟332和传感器134。作为具体示例,传感器134包括一个或多个相机150、一个或多个位置传感器152、(诸)话筒104、活动检测器154、(诸)其他传感器156,或其组合。
在一特定方面,时钟332生成时钟信号,该时钟信号可被用于将时间戳指派给特定传感器数据样本以指示特定传感器数据样本何时被接收到。在这方面,模型选择器190可以使用时间戳来选择要用来处理输入数据的模型。附加地或替换地,时间戳可以被上下文检测器140用来确定与特定传感器数据样本相关联的上下文142。
在一特定方面,(诸)相机150生成图像数据、视频数据或这两者。模型选择器190可以使用图像数据、视频数据或这两者来选择特定模型以用于分析输入数据。附加地或替换地,图像数据、视频数据或这两者可被上下文检测器140用来确定与特定传感器数据样本相关联的上下文142。例如,特定模型112可被指定供户外使用,并且图像数据、视频数据或这两者可被用于确认设备100位于户外环境。
在一特定方面,(诸)位置传感器152生成位置数据,诸如指示设备100的位置的全球定位数据。模型选择器190可以使用位置数据来选择要用于分析输入数据的模型。附加地或替换地,定位数据可以被上下文检测器140用来确定与特定传感器数据样本相关联的上下文142。例如,特定模型112可以被指定供在家庭使用,并且位置数据可被用于确认设备100位于家庭位置。(诸)位置传感器852可以包括用于基于卫星的定位系统的接收器、用于本地定位系统接收机、惯性导航系统、基于地标的定位系统的接收器、或其组合。
(诸)其他传感器156可包括例如取向传感器、磁力计、光传感器、接触传感器、温度传感器或耦合到设备100或被包括在设备100内并且可被用于生成对确定在特定时间与设备100相关联的上下文142有用的传感器数据的任何其他传感器。
在特定实现中,设备100被包括在系统级封装或片上系统设备802中。在特定实现中,存储器108、处理器804、(诸)处理器806、显示控制器810、CODEC 824、调制解调器812和收发机814被包括在系统级封装或片上系统设备802中。在特定实现中,输入设备336和电源830被耦合到片上系统设备802。此外,在特定实现中,如图8中所解说的,显示器820、输入设备336、(诸)扬声器822、传感器134、时钟332、天线816和电源830在片上系统设备802的外部。在特定实现中,显示器820、输入设备336、(诸)扬声器822、传感器134、时钟332、天线816和电源830中的每一者都可被耦合到片上系统设备802的组件,诸如接口或控制器。
设备100可以包括、对应于或被包括在以下各项内:语音激活的设备、音频设备、无线扬声器和语音激活的设备、便携式电子设备、汽车、交通工具、计算设备、通信设备、物联网(IoT)设备、虚拟现实(VR)设备、增强现实(AR)设备、混合现实(MR)设备、智能扬声器、移动计算设备、移动通信设备、智能电话、蜂窝电话、膝上型计算机、计算机、平板式设备、个人数字助理、显示设备、电视、游戏控制台、电器、音乐播放器、收音机、数字视频播放器、数字视频光盘(DVD)播放器、调谐器、相机、导航设备或其任何组合。在一特定方面,处理器804、(诸)处理器806或其组合被包括在集成电路中。
图9是纳入图1的设备100的各方面的交通工具900的解说性示例。根据一种实现,交通工具900是自动驾驶汽车。根据其他实现,交通工具900是汽车、卡车、摩托车、飞行器、水上交通工具等。在图9中,交通工具900包括显示器820、一个或多个传感器134、包括上下文检测器140的设备100、模型选择器190、基于模型的应用192或其组合。传感器134、上下文检测器140、模型选择器190和基于模型的应用192使用虚线示出以指示这些组件可能对交通工具900的乘客可能不可见。设备100可被集成到交通工具900或耦合到交通工具900。
在一特定方面,设备100耦合到显示器820并且响应于基于模型的应用192(诸如响应于检测到或识别出本文中所描述的各种事件(例如,声音事件))而向显示器820提供输出。例如,设备100向显示器820提供图3的输出324,该输出324指示从(诸)话筒104接收的音频数据105中的声音302(诸如汽车喇叭)的声音类别。在一些实现中,设备100可以响应于识别出声音事件而执行动作,诸如提醒交通工具的操作员或激活传感器134之一。在特定示例中,设备100提供指示是否正在响应于已识别的声音事件而执行动作的输出。在一特定方面,用户可选择在显示器820上显示的选项以启用或禁用响应于已识别声音事件而执行动作。
在特定实现中,传感器134包括图1的(诸)话筒104、交通工具乘载传感器、眼睛跟踪传感器、(诸)位置传感器152、或外部环境传感器(例如,激光雷达传感器或相机)。在一特定方面,传感器134的传感器输入指示用户的位置。例如,传感器134与交通工具900内的各个位置相关联。
因此,参考图1-8所描述的技术使交通工具900的用户能够基于设备100在其中操作的具体上下文来选择要使用的模型。
图10描绘了耦合到头戴式耳机1002或集成在头戴式设备1002内的设备100的示例,头戴式设备1002诸如虚拟现实头戴式设备、增强现实头戴式设备、混合现实头戴式设备、扩展现实头戴式设备、头戴式显示器、或其组合。可视接口设备(诸如显示器820)被放置在用户眼前以使在头戴式设备1002被佩戴时能够向用户显示增强现实、混合现实或虚拟现实图像或场景。在特定示例中,显示器820被配置成显示设备100的输出。头戴式设备1002包括传感器134,诸如话筒104、(诸)相机150、(诸)位置传感器152、其他传感器156或其组合。尽管在单个位置中被解说,但在其他实现中,传感器134可被定位在头戴式设备1002的其他位置(诸如分布在头戴式设备1002周围的一个或多个话筒和一个或多个相机的阵列)以检测多模态输入。
传感器134使得能够检测传感器数据,设备100使用该传感器数据来检测头戴式设备1002的上下文以及基于所检测到的上下文来更新模型。例如,基于模型的应用192(例如,SEC引擎320)可以使用一个或多个模型来生成声音事件分类数据,该声音事件分类数据可被提供给显示器820以指示在从传感器134接收到的音频数据样本中检测到已识别声音事件(诸如汽车喇叭)。在一些实现中,设备100可以响应于识别出声音事件而执行动作,诸如激活相机或另一传感器134、或者向用户提供触觉反馈。
图11描绘了集成到可穿戴电子设备1102中的设备100的示例,可穿戴电子设备1102(被解说为“智能手表”)包括显示器820和传感器134。传感器134例如基于模态(诸如位置、视频、话音和手势)来实现上下文检测,设备100可以使用这些模态来更新由基于模型的应用192使用的一个或多个模型。传感器134还使得能够检测可穿戴电子设备1102周围的环境中的声音和其他事件,设备100可以使用基于模型的应用192来检测或解读这些声音和其他事件。例如,设备100向显示器820提供图3的输出324,该输出324指示在从传感器134接收到的音频数据样本中检测到已识别声音事件。在一些实现中,设备100可以响应于识别出声音事件而执行动作,诸如激活相机或另一传感器134、或者向用户提供触觉反馈。
图12是语音控制扬声器系统1200的解说性示例。语音控制扬声器系统1200可以具有无线网络连通性并且被配置成执行辅助操作。在图12中,设备100被包括在语音控制扬声器系统1200中。语音控制扬声器系统1200还包括扬声器1202和传感器134。传感器134包括图1的(诸)话筒104以接收语音输入或其他音频输入。
在操作期间,响应于接收到口头命令或已识别声音事件,语音扬声器系统1200可以执行辅助操作。辅助操作可以包括调节温度、播放音乐、开灯等。传感器134使得能够检测数据样本,设备100可以使用这些数据样本来更新语音控制扬声器系统1200的上下文并且基于该上下文来更新一个或多个模型。附加地,语音控制扬声器系统1200可以基于由设备100识别的事件来执行一些操作。例如,如果设备100识别出关门的声音,则语音控制扬声器系统1200可以打开一个或多个灯。
图13解说了纳入图1的设备100的各方面的相机1300。在图13中,设备100被纳入相机1300中或与之耦合。相机1300包括图像传感器1302和一个或多个其他传感器(例如,传感器134),诸如图1的(诸)话筒104。附加地,相机1300包括设备100,其被配置成确定相机1300的上下文并且基于上下文来更新一个或多个模型。在一特定方面,相机1300被配置成响应于已识别声音事件而执行一个或多个动作。例如,相机1300可以使图像传感器1302响应于设备100在来自传感器134的音频数据样本中检测到特定声音事件而捕获图像。
图14解说了纳入图1的设备100的各方面的移动设备1400。在图14中,移动设备1400包括或耦合到图1的设备100。移动设备1400包括电话或平板设备,作为解说性非限制性示例。移动设备1400包括显示器820和传感器134,诸如(诸)话筒104、(诸)相机150、(诸)位置传感器152或(诸)其他传感器156。在操作期间,移动设备1400可以响应于设备100识别出特定声音事件而执行特定动作。例如,这些动作可以包括向其他设备(诸如恒温器、家庭自动化系统、另一移动设备等)发送命令。
图15解说了纳入图1的设备100的各方面的助听器设备1500。在图15中,助听器设备1500包括或耦合到图1的设备100。助听器设备1500包括传感器134,诸如(诸)话筒104、(诸)相机150、(诸)位置传感器152或(诸)其他传感器156。在操作期间,助听器设备1500可以响应于设备100识别助听器设备1500的上下文(诸如助听器设备1500的声学环境)而更新一个或多个模型,以供基于模型的应用192用于处理音频数据(诸如用于因位置而异的降噪)。
图16解说了纳入图1的设备100的各方面的空中设备1600。在图16中,空中设备1600包括或耦合到图1的设备100。空中设备1600是载人、无人或遥控空中设备(例如,包裹递送无人机)。空中设备1600包括控制系统1602和传感器134,诸如(诸)话筒104、(诸)相机150、(诸)位置传感器152或(诸)其他传感器156。控制系统1602控制空中设备1600的各种操作,诸如货物释放、传感器激活、起飞、导航、着陆或其组合。例如,控制系统1602可以控制空中设备1600在指定点之间的飞行和货物在特定位置处的部署。在操作期间,空中设备1600可以响应于设备100识别空中设备1600的上下文(诸如空中设备1600的位置或声学环境)而更新一个或多个模型,以供基于模型的应用192用于检测事件。为了解说,控制系统1602可以响应于设备100检测到飞机引擎而发起安全着陆协议。
图17解说了纳入图1的设备100的各方面的头戴式设备1700。在图17中,头戴式设备1700包括或耦合到图1的设备100。头戴式设备1700包括图1的(诸)话筒104,其被定位成主要捕获用户的话音。头戴式设备1700还可以包括一个或多个附加话筒,其被定位成主要捕获环境声音(例如,以用于噪声消除操作);以及一个或多个传感器134(诸如(诸)相机150、(诸)位置传感器152或(诸)其他传感器156)。在一特定方面,头戴式设备1700可以响应于设备100识别头戴式设备1700的上下文(诸如头戴式设备1700的位置或声学环境)改变而更新一个或多个模型,以供基于模型的应用192用于执行操作(诸如噪声消除特征)。
图18解说了纳入图1的设备100的各方面的电器1800。在图18中,电器1800是台灯;然而,在其他实现中,电器1800包括另一物联网电器,诸如冰箱、咖啡机、烤箱、另一家用电器等。电器1800包括或耦合到图1的设备100。电器1800包括传感器134,诸如(诸)话筒104、(诸)相机150、(诸)位置传感器152、活动检测器154、或(诸)其他传感器156。在一特定方面,电器1800可以响应于设备100识别电器1800的上下文的改变而更新一个或多个模型,以供基于模型的应用192用于执行操作(诸如响应于设备100检测到门关闭而激活灯)。
图19是解说图1的设备100的操作方法1900的示例的流程图。方法1900可由设备100发起、控制或执行。例如,(诸)处理器110可执行来自存储器108的指令(诸如图8的指令860)以执行基于上下文的模型选择。
方法1900包括:在框1902,在设备的一个或多个处理器处从一个或多个传感器设备接收传感器数据。例如,一个或多个处理器110中的上下文检测器140从一个或多个传感器设备134接收传感器数据138。在一些实现中,传感器数据包括设备的位置的位置数据,诸如位置数据153,并且上下文至少部分地基于该位置。在一些实现中,传感器数据包括对应于视觉场景的图像数据,诸如图像数据151,并且上下文至少部分地基于视觉场景。在一些实现中,传感器数据包括对应于音频场景的音频,诸如音频数据105,并且上下文至少部分地基于音频场景。在一些实现中,传感器数据包括对应于设备的运动的运动数据,诸如活动数据155,并且上下文至少部分地基于该设备的运动。在框1904中,方法1900包括在该一个或多个处理器处基于该传感器数据来确定该设备的上下文。例如,一个或多个处理器110中的上下文检测器140从一个或多个传感器设备134接收传感器数据138以及基于传感器数据138来确定上下文142。在一些实现中,
在框1906中,方法1900包括在该一个或多个处理器处基于该上下文来选择模型。例如,模型选择器190基于上下文142来选择模型112。在特定实现中,模型是从存储在设备的存储器处的多个模型之中选择的,诸如可用模型114。根据一些实现,该模型是从与共享模型的库相对应的库(诸如模型库162)中下载的。该模型可以包括从另一用户设备上载到该库的经训练模型。在一示例中,该库对应于众包模型库。该库可被包括在分布式上下文感知系统中。
在框1908中,方法1900包括在该一个或多个处理器处使用该模型来处理输入信号以生成因上下文而异的输出。例如,基于模型的应用192使用所选模型112来处理输入信号106以生成因上下文而异的输出122。
在一些实现中,方法1900包括响应于确定该上下文已改变而修剪该模型。例如,模型选择器190可以响应于检测到上下文142已改变(例如,设备100被移动到不同的位置)并且检测到当前模型不再适合于新上下文或者另一模型更适合于新上下文而永久性地删除模型。
在一些实现中,该模型包括声音事件检测模型,该输入信号包括音频信号,并且该因上下文而异的输出包括对该音频信号中的声音事件的分类。在一些实现中,该模型包括自动话音识别模型,该输入信号包括音频信号,并且该因上下文而异的输出包括表示该音频信号中的话音的文本数据。在一些实现中,该模型包括自然语言处理(NLP)模型,该输入信号包括文本数据,并且该因上下文而异的输出包括基于该文本数据的NLP输出数据。在一些实现中,该模型包括降噪模型,该输入信号包括音频信号,并且该因上下文而异的输出包括基于该音频信号的经降噪音频信号。在一些实现中,该模型与设备操作模式的自动调整相关联,并且其中该因上下文而异的输出包括用来调整该设备操作模式的信号。
在一些实现中,方法1900包括经由无线传输从第二设备接收该模型。例如,该上下文可对应于该设备的位置,并且该模型包括对应于特定位置的声学模型。在一些实现中,方法1900包括:至少部分地基于设备的位置与特定位置相匹配来接收对模型的访问准许。
在一些实现中,上下文包括特定声学环境,并且方法1900包括确定可用声学模型库是否包括特定于该特定声学环境且可用于该设备的声学模型,以及响应于没有特定于该特定声学环境的声学模型可用于该设备而确定用于该特定声学环境的通用门类的声学模型是否可用于该设备。例如,响应于当设备100位于房间204中时模型库162没有可用于设备100的“办公室”模型274,设备100可以请求用于房间204的声学环境的通用模型的“办公楼”模型262。
通过基于设备的上下文来选择模型,与针对所有上下文使用单个模型相比而言方法1900使设备能够以更高的准确性运行。此外,改变模型使设备能够以提高的准确性运行,而不会招致与针对特定上下文在设备处从头开始重新训练现有模型相关联的功耗、存储器要求和处理资源使用。此外,使用基于上下文的模型对设备进行操作实现设备自身的改进的操作,诸如通过在执行迭代或动态过程(例如,在噪声消除技术中)时由于使用特定于特定上下文的较高准确性模型而实现更快收敛。
图18是解说图1的设备100的操作方法1800的示例的流程图。方法1800可由设备100发起、控制或执行。例如,(诸)处理器110可执行来自存储器108的指令(诸如图6的指令660)以执行基于上下文的模型选择。
方法1800包括:在框1802,在设备的一个或多个处理器处选择与建筑物中该设备位于其中的特定房间相对应的声学模型。例如,模型选择器190选择图2的声学模型212,该声学模型212对应于设备100位于其中的房间204。
方法2000包括:在框2004,在该一个或多个处理器处使用该声学模型来处理输入音频信号。作为解说性示例,基于模型的应用192使用声学模型212对输入信号106(例如,来自(诸)话筒104的音频数据105)执行降噪以生成经降噪音频信号作为因上下文而异的输出122。
在一些实现中,方法2000包括响应于确定该设备已进入该特定房间而从声学模型库下载该声学模型。在一些实现中,方法2000包括响应于该设备离开该特定房间而修剪(例如,移除)该声学模型。在一些实现中,方法2000包括基于指示设备的位置的传感器数据(诸如通过分析图像数据151来检测设备100的位置)来选择声学模型。在一些实现中,方法2000包括基于指示该设备的位置的位置数据(诸如位置数据153)来选择该声学模型。
通过基于设备的上下文来选择声学模型,与针对所有上下文使用单个声学模型相比而言方法2000使设备能够以更高的准确性运行。此外,改变声学模型使设备能够以提高的准确性运行,而不会招致与针对特定上下文在设备处从头开始重新训练现有声学模型相关联的功耗、存储器要求和处理资源使用。此外,使用基于上下文的声学模型对设备进行操作实现设备自身的改进的操作,诸如通过在执行迭代或动态过程(例如,在噪声消除技术中)时由于使用特定于特定上下文的较高准确性声学模型而实现更快收敛。
图21是解说图1的设备100在交通工具内(诸如集成在图9的交通工具900中)的操作方法2100的示例的流程图。方法2100可由设备100发起、控制或执行。例如,(诸)处理器110可执行来自存储器108的指令(诸如图8的指令860)以执行基于上下文的模型选择。
方法2100包括:在框2102,在设备的一个或多个处理器处且响应于检测到用户进入交通工具而从与该交通工具相对应的多个个性化声学模型之中为该用户选择个性化声学模型。例如,图9的交通工具900中的设备100可以存储针对交通工具900的每个用户所个性化的多个声学模型,并且可以为进入交通工具900的特定用户选择个性化模型或模型集合。在一些实现中,方法2100包括基于指示该用户的位置的传感器数据来确定该用户已进入该交通工具。为了解说,图9的(诸)传感器134可以经由面部识别、语音识别、通过手势、语音或与输入设备(例如,交通工具900中的触摸屏)的交互输入身份或用于标识用户的一种或多种其他技术来确定用户在交通工具900内。
方法2100包括:在框2104,在该一个或多个处理器处使用该个性化声学模型来处理输入音频信号。例如,在一些实现中,个性化声学模型对应于针对特定用户所训练的ASR模型,并且个性化声学模型由交通工具900中基于模型的应用192用来对用户的经由交通工具900中的一个或多个话筒捕获的话音执行话音识别。为了解说,ASR模型被用于增强用于控制交通工具900的一个或多个操作(例如,导航系统、娱乐系统、气候控制、驾驶辅助或自动驾驶设置等)的语音接口的准确性。作为另一示例,个性化声学模型可以包括针对特定用户所个性化的SEC模型。为了解说,如果特定用户频繁地带着用户的狗去驾车旅行,则用户的供在交通工具900中使用的个性化SEC模型可被训练来识别附加声音类别“交通工具内的犬吠”。
在一些实现中,方法2100包括响应于确定该用户已进入该交通工具而从声学模型库下载该个性化声学模型。在一些实现中,方法2100包括响应于该设备离开该交通工具而修剪(例如,移除)该个性化声学模型。
通过响应于检测到用户进入交通工具而选择个性化声学模型,与针对所有上下文使用单个声学模型相比而言方法2100使设备能够以更高的准确性运行。此外,改变声学模型使设备能够以更高的准确性运行,而不会招致与针对特定上下文在设备处从头开始重新训练现有声学模型相关联的功耗、存储器要求和处理资源使用。此外,使用基于上下文的声学模型对设备进行操作实现设备自身的改进的操作,诸如通过在执行迭代或动态过程(例如,在噪声消除技术中)时由于使用特定于特定上下文的较高准确性声学模型而实现更快收敛。
图22是解说图1的设备100的操作方法2200的示例的流程图。方法2200可由设备100发起、控制或执行。例如,(诸)处理器110可执行来自存储器108的指令(诸如图8的指令860)以执行基于上下文的模型选择。
方法2200包括:在框2202,在设备的一个或多个处理器处下载与该设备位于其中的特定位置相对应的声学模型。在一些实现中,方法2200包括基于指示该设备的位置的传感器数据来确定该设备已进入该特定位置。在一示例中,响应于设备100进入房间204或(例如,基于位置数据153)确定设备的位置位于房间204内,设备100下载声学模型212(例如,与房间204相对应的“办公室”模型274)。
方法2200包括:在框2204,在该一个或多个处理器处使用该声学模型来处理输入音频信号。在一示例中,设备100对应于图15的助听器设备1500,并且在基于模型的应用192处使用声学模型212(例如,与房间204相对应的“办公室”模型274)来执行降噪。
方法2200包括:在框2206,在该一个或多个处理器处响应于该设备退出该位置而移除该声学模型。在一些实现中,方法2200包括基于指示该设备的位置的位置数据来确定该设备已进入该特定位置。在一示例中,响应于设备100退出房间204或(例如,基于位置数据153)确定设备的位置不再位于房间204内,设备100修剪声学模型212(例如,与房间204相对应的“办公室”模型274)。
尽管上面提供的示例解说了在图2的建筑物202中执行方法2200,但是应当理解,方法2200不限于任何特定位置或位置类型。例如,在一些实现中,位置对应于特定餐厅,并且该声学模型是响应于确定设备已进入该特定餐厅而从声学模型库下载的。在其他实现中,该位置可以对应于公园、地铁站、汽车、火车、飞机、用户家中的特定房间、博物馆中的特定房间、礼堂或音乐厅等。
通过选择与设备的特定位置相对应的声学模型,与针对所有位置使用单个声学模型相比而言方法2200使设备能够以更高的准确性运行。此外,改变声学模型使设备能够以更高的准确性运行,而不会招致与针对特定上下文在设备处从头开始重新训练现有声学模型相关联的功耗、存储器要求和处理资源使用,并且响应于设备退出该位置而移除声学模型通过释放与继续存储不再使用的声学模型相关联的存储器和资源改进了设备的操作,这使得能够减少与模型存储相关联的功耗和与存储在设备处的声学模型的后续搜索相关联的等待时间。此外,使用基于位置的声学模型对设备进行操作实现设备自身的改进的操作,诸如通过在执行迭代或动态过程(例如,在噪声消除技术中)时由于使用特定于特定位置的较高准确性声学模型而实现更快收敛。
图23是解说图1的设备100的操作方法2300的示例的流程图。方法2300可由设备100发起、控制或执行。例如,(诸)处理器110可执行来自存储器108的指令(诸如图8的指令860)以执行基于上下文的模型选择。
方法2300包括:在框2302,在设备的一个或多个处理器处选择与特定位置相对应的声学模型。
方法2300包括:在框2304,在该一个或多个处理器处至少部分地基于该设备的位置与该特定位置相匹配来接收对该声学模型的访问准许。在一些实现中,方法2300包括响应于在该特定位置内检测到该设备而接收该访问准许。例如,设备100可以响应于在房间204中检测到设备100而接收对使用图2的“办公室”模型274的访问准许214。设备100可以传送指示声学环境210的数据(诸如位置数据),并且作为响应,准许管理系统可以向设备100发送访问准许,诸如参考图2所描述的。
方法2300包括:在框2306,在该一个或多个处理器处使用该声学模型来处理输入音频信号。
通过选择与设备的特定位置相对应的声学模型,与针对所有位置使用单个声学模型相比而言方法2300使设备能够以更高的准确性运行。此外,通过防止在除了当设备处于特定位置之外的情况下使用声学模型,基于位置匹配来接收对声学模型的访问准许使得声学模型的安全性能够得到维护。此类安全性使得声学模型能够作为预存留数据被下载到设备,诸如以减少峰值网络带宽使用并减少与使用声学模型相关联的等待时间,这是因为该声学模型可能已被存储在设备处并且不需要在进入特定位置之际被下载。此外,使用基于位置的声学模型对设备进行操作实现设备自身的改进的操作,诸如通过在执行迭代或动态过程(例如,在噪声消除技术中)时由于使用特定于特定位置的较高准确性声学模型而实现更快收敛。
图24是解说图1的设备100的操作方法2400的示例的流程图。方法2400可由设备100发起、控制或执行。例如,(诸)处理器110可执行来自存储器108的指令(诸如图8的指令860)以执行基于上下文的模型选择。
方法2400包括:在框2402,在该设备的一个或多个处理器处检测该设备的上下文。为了解说,在一些实现中,一个或多个处理器110被配置成检测上下文,诸如由上下文检测器142基于传感器数据138而检测到的上下文142。在解说性非限制性实例中,该上下文对应于位置或活动,诸如在汽车中驾驶。
方法2400包括:在框2404,向远程设备发送指示该上下文的请求。为了解说,在一些实现中,一个或多个处理器110被配置成发起向远程设备(诸如远程计算设备818(例如,服务器(其可以是服务的一部分))或存储模型库162的至少一部分的网络存储器)发送指示上下文(例如,声学环境210)的请求。
方法2400包括:在框2406,接收与该上下文相对应的模型。为了解说,在一些实现中,一个或多个处理器110被配置成响应于发送指示上下文的请求而从远程计算设备818或存储模型库162的至少一部分的另一服务器或网络存储器接收模型112。在一些实现中,模型112被接收为经压缩源模型并且由一个或多个处理器110解压缩以供在设备100处使用。在一些实现中,该模型是基于私有访问来接收的。在解说性示例中,声学模型212是连同对设备100访问声学模型212进行授权的访问准许214(例如,连同对使用模型212的执照)一起被接收的。在一解说性示例中,该模型是基于由设备100的用户的家人或朋友所准予的访问来接收的。
方法2400包括:在框2408,在该一个或多个处理器处在该上下文保持被检测到时使用该模型。为了解说,在一些实现中,一个或多个处理器110被配置成响应于发送指示上下文142的请求而接收模型112;以及在上下文142保持不变时在基于模型的应用192处继续使用模型112(例如,只要检测到上下文142就临时地使用所接收到的模型112)。
方法2400包括:在框2410,在该一个或多个处理器处响应于检测到该上下文的改变而修剪该模型。为了解说,在一些实现中,一个或多个处理器110被配置成响应于检测到上下文142的改变而修剪模型112(例如,一旦上下文改变就修剪模型112)。在一些实现中,修剪该模型包括永久性地删除该模型。
在一些实现中,方法2400包括在该上下文保持被检测到时生成至少一个新声音类别,并且修剪该模型包括保留该至少一个新声音类别。为了解说,在一些实现中,一个或多个处理器110被配置成生成新声音类别(诸如通过生成经更新模型或新模型,如参考图3-5所描述的(例如,更新模型506)),这些新声音类别通过(诸如在存储器108处或经由上载到模型库162)存储经更新模型或新模型来被保留。
结合所描述的实现,一种装备包括用于接收传感器数据的装置。例如,用于接收传感器数据的装置包括设备100、指令860、处理器804、(诸)处理器806、上下文检测器140、(诸)话筒104、(诸)相机150、(诸)位置传感器152、活动检测器154、(诸)其他传感器156、CODEC 824、配置成接收传感器数据的一个或多个其他电路或组件、或其任何组合。
该装备还包括用于基于传感器数据来确定上下文的装置。例如,用于基于传感器数据来确定上下文的装置包括设备100、指令860、处理器804、(诸)处理器806、上下文检测器140、配置成确定基于传感器数据来确定上下文的一个或多个电路或组件、或其任何组合。
该装备还包括用于基于上下文来选择模型的装置。例如,用于基于上下文来选择模型的装置包括设备100、指令860、处理器804、(诸)处理器806、模型选择器190、配置成基于上下文来选择模型的一个或多个电路或组件、或其任何组合。
该装备还包括用于使用模型来处理输入信号以生成因上下文而异的输出的装置。例如,用于使用模型来处理输入信号以生成因上下文而异的输出的装置包括设备100、指令860、处理器804、(诸)处理器806、基于模型的应用192、配置成使用模型来处理输入信号以生成因上下文而异的输出的一个或多个电路或组件、或其任何组合。
技术人员将进一步领会,结合本文所公开的实现所描述的各种解说性逻辑框、配置、模块、电路、和算法步骤可被实现为电子硬件、由处理器执行的计算机软件、或这两者的组合。各种解说性组件、框、配置、模块、电路、和步骤已经在上文以其功能性的形式作了通用描述。此类功能性是被实现为硬件还是处理器可执行指令取决于具体应用和施加于整体系统的设计约束。技术人员可针对每种特定应用以不同方式来实现所描述的功能性,此类实现决策将不被解读为致使脱离本公开的范围。
结合本文中所公开的实现所描述的方法或算法的步骤可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中实施。软件模块可驻留在随机存取存储器(RAM)、闪存、只读存储器(ROM)、可编程只读存储器(PROM)、可擦式可编程只读存储器(EPROM)、电可擦式可编程只读存储器(EEPROM)、寄存器、硬盘、可移动盘、压缩盘只读存储器(CD-ROM)、或本领域中所知的任何其他形式的非瞬态存储介质中。示例性存储介质耦合至处理器,以使该处理器可从/向该存储介质读写信息。在替换方案中,存储介质可被整合到处理器。处理器和存储介质可驻留在专用集成电路(ASIC)中。ASIC可驻留在计算设备或用户终端中。在替换方案中,处理器和存储介质可作为分立组件驻留在计算设备或用户终端中。
本公开的特定方面在以下第一组相互关联的条款中作了描述:
根据条款1,一种设备包括一个或多个处理器,该一个或多个处理器被配置成:从一个或多个传感器设备接收传感器数据;基于该所述传感器数据来确定该设备的上下文;基于该上下文来选择模型;以及使用该模型来处理输入信号以生成因上下文而异的输出。
条款2包括条款1的设备,并且进一步包括:耦合到该一个或多个处理器的位置传感器,其中该传感器数据包括来自该位置传感器的位置数据,该位置数据指示该设备的位置,并且其中该上下文至少部分地基于该位置。
条款3包括条款1或条款2的设备,并且进一步包括:耦合到该一个或多个处理器的相机,其中该传感器数据包括来自该相机的图像数据,该图像数据对应于视觉场景,并且其中该上下文至少部分地基于该视觉场景。
条款4包括条款1到3中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的话筒,其中该传感器数据包括来自该话筒的音频数据,该音频数据对应于音频场景,并且其中该上下文至少部分地基于音频场景。
条款5包括条款1到4中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的活动检测器,其中该传感器数据包括来自该活动检测器的运动数据,该运动数据对应于该设备的运动,并且其中该上下文至少部分地基于该设备的运动。
条款6包括条款1到5中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的存储器,其中该模型选自存储在该存储器处的多个模型。
条款7包括条款1到6中任一项的设备,其中:该模型包括声音事件检测模型,该输入信号包括音频信号,并且该因上下文而异的输出包括对该音频信号中的声音事件的分类。
条款8包括条款1到7中任一项的设备,其中:该模型包括自动话音识别模型,该输入信号包括音频信号,并且该因上下文而异的输出包括表示该音频信号中的话音的文本数据。
条款9包括条款1到8中任一项的设备,其中:该模型包括自然语言处理(NLP)模型,该输入信号包括文本数据,并且该因上下文而异的输出包括基于该文本数据的NLP输出数据。
条款10包括条款1到9中任一项的设备,其中:该模型包括降噪模型,该输入信号包括音频信号,并且该因上下文而异的输出包括基于该音频信号的经降噪音频信号。
条款11包括条款1到10中任一项的设备,其中:该模型与设备操作模式的自动调整相关联,并且其中该因上下文而异的输出包括用来调整该设备操作模式的信号。
条款12包括条款1到11中任一项的设备,并且进一步包括:调制解调器,该调制解调器耦合到该一个或多个处理器并且被配置成经由无线传输从第二设备接收该模型。
条款13包括条款12的设备,其中:该上下文对应于该设备的位置,并且其中该模型包括对应于特定位置的声学模型。
条款14包括条款13的设备,其中:该一个或多个处理器被进一步配置成:至少部分地基于该设备的位置与该特定位置相匹配而经由该调制解调器来接收对该模型的访问准许。
条款15包括条款1到14中任一项的设备,其中:该一个或多个处理器被进一步配置成响应于确定该上下文已改变而修剪该模型。
条款16包括条款1到15中任一项的设备,其中:该模型下载自共享模型的库。
条款17包括条款16的设备,其中:该模型包括从另一用户设备上载到该库的经训练模型。
条款18包括条款16或条款17的设备,其中:该库对应于众包模型库。
条款19包括条款16到条款18中任一项的设备,其中:该库被包括在分布式上下文感知系统中。
条款20包括条款1到19中任一项的设备,其中:该上下文包括特定声学环境,并且其中该一个或多个处理器被配置成:确定可用声学模型库是否包括特定于该特定声学环境且可用于该一个或多个处理器的声学模型;以及响应于没有特定于该特定声学环境的声学模型可用于该一个或多个处理器而确定用于该特定声学环境的通用门类的声学模型是否可用于该一个或多个处理器。
条款21包括条款1到20中任一项的设备,其中:该一个或多个处理器被集成在集成电路中。
条款22包括条款1到20中任一项的设备,其中:该一个或多个处理器被集成在交通工具中。
条款23包括条款1到20中任一项的设备,其中:该一个或多个处理器被集成在以下至少一者中:移动电话、平板计算机设备、虚拟现实头戴式设备、增强现实头戴式设备、混合现实头戴式设备、无线扬声器设备、可穿戴设备、相机设备、或助听器设备。
本公开的特定方面在以下第二组相互关联的条款中作了描述:
根据条款24,一种方法包括:在设备的一个或多个处理器处从一个或多个传感器设备接收传感器数据;在该一个或多个处理器处基于该传感器数据来确定该设备的上下文;在该一个或多个处理器处基于该上下文来选择模型;以及在该一个或多个处理器处使用该模型来处理输入信号以生成因上下文而异的输出。
条款25包括条款24的方法,其中:该传感器数据包括该设备的位置的位置数据,并且其中该上下文至少部分地基于该位置。
条款26包括条款24或条款25的方法,其中:该传感器数据包括对应于视觉场景的图像数据,并且其中该上下文至少部分地基于该视觉场景。
条款27包括条款24到26中任一项的方法,其中:该传感器数据包括对应于音频场景的音频,并且其中该上下文至少部分地基于音频场景。
条款28包括条款24到27中任一项的方法,其中:该传感器数据包括对应于该设备的运动的运动数据,并且其中该上下文至少部分地基于该设备的运动。
条款29包括条款24到28中任一项的方法,其中:该模型选自存储在该设备的存储器处的多个模型。
条款30包括条款24到29中任一项的方法,其中:该模型包括声音事件检测模型,该输入信号包括音频信号,并且该因上下文而异的输出包括对该音频信号中的声音事件的分类。
条款31包括条款24到30中任一项的方法,其中:该模型包括自动话音识别模型,该输入信号包括音频信号,并且该因上下文而异的输出包括表示该音频信号中的话音的文本数据。
条款32包括条款24到31中任一项的方法,其中:该模型包括自然语言处理(NLP)模型,该输入信号包括文本数据,并且该因上下文而异的输出包括基于该文本数据的NLP输出数据。
条款33包括条款24到32中任一项的方法,其中:该模型包括降噪模型,该输入信号包括音频信号,并且该因上下文而异的输出包括基于该音频信号的经降噪音频信号。
条款34包括条款24到33中任一项的方法,其中:该模型与设备操作模式的自动调整相关联,并且其中该因上下文而异的输出包括用来调整该设备操作模式的信号。
条款35包括条款24到34中任一项的方法,并且进一步包括:经由无线传输从第二设备接收该模型。
条款36包括条款24到35中任一项的方法,其中:该上下文对应于该设备的位置,并且其中该模型包括对应于特定位置的声学模型。
条款37包括条款36的方法,并且进一步包括:至少部分地基于该设备的位置与该特定位置相匹配来接收对该模型的访问准许。
条款38包括条款24到37中任一项的方法,并且进一步包括:响应于确定该上下文已改变而修剪该模型。
条款39包括条款24到38中任一项的方法,其中:该模型下载自共享模型的库。
条款40包括条款39的方法,其中:该模型包括从另一用户设备上载到该库的经训练模型。
条款41包括条款39或条款40的方法,其中:该库对应于众包模型库。
条款42包括条款39到41中任一项的方法,其中:该库被包括在分布式上下文感知系统中。
条款43包括条款24到42中任一项的方法,其中:该上下文包括特定声学环境,并且该方法进一步包括:确定可用声学模型库是否包括特定于该特定声学环境且可用于该设备的声学模型;以及响应于没有特定于该特定声学环境的声学模型可用于该设备而确定用于该特定声学环境的通用门类的声学模型是否可用于该设备。
本公开的特定方面在以下第三组相互关联的条款中作了描述:
根据条款44,一种设备包括:用于接收传感器数据的装置;用于基于该传感器数据来确定上下文的装置;用于基于该上下文来选择模型的装置;以及用于使用该模型来处理输入信号以生成因上下文而异的输出的装置。
条款45包括条款44的设备,其中:该传感器数据包括该设备的位置的位置数据,并且其中该上下文至少部分地基于该位置。
条款46包括条款44或条款45的设备,其中:该传感器数据包括对应于视觉场景的图像数据,并且其中该上下文至少部分地基于该视觉场景。
条款47包括条款44到46中任一项的设备,其中:该传感器数据包括对应于音频场景的音频,并且其中该上下文至少部分地基于音频场景。
条款48包括条款44到47中任一项的设备,其中:该传感器数据包括对应于该设备的运动的运动数据,并且其中该上下文至少部分地基于该设备的运动。
条款49包括条款44到48中任一项的设备,并且进一步包括:用于存储模型的装置,其中该模型选自存储在用于存储模型的装置处的多个模型。
条款50包括条款44到49中任一项的设备,其中:该模型包括声音事件检测模型,该输入信号包括音频信号,并且该因上下文而异的输出包括对该音频信号中的声音事件的分类。
条款51包括条款44到50中任一项的设备,其中:该模型包括自动话音识别模型,该输入信号包括音频信号,并且该因上下文而异的输出包括表示该音频信号中的话音的文本数据。
条款52包括条款44到51中任一项的设备,其中:该模型包括自然语言处理(NLP)模型,该输入信号包括文本数据,并且该因上下文而异的输出包括基于该文本数据的NLP输出数据。
条款53包括条款44到52中任一项的设备,其中:该模型包括降噪模型,该输入信号包括音频信号,并且该因上下文而异的输出包括基于该音频信号的经降噪音频信号。
条款54包括条款44到53中任一项的设备,其中:该模型与设备操作模式的自动调整相关联,并且其中该因上下文而异的输出包括用来调整该设备操作模式的信号。
条款55包括条款44到54中任一项的设备,其中:该模型是经由无线传输从第二设备接收的。
条款56包括条款44到55中任一项的设备,其中:该上下文对应于该设备的位置,并且其中该模型包括对应于特定位置的声学模型。
条款57包括条款56的设备,其中:对该模型的访问准许是至少部分地基于该设备的位置与该特定位置相匹配来接收的。
条款58包括条款56的设备,并且进一步包括:用于响应于该设备离开该特定位置而移除该模型的装置。
条款59包括条款44到58中任一项的设备,其中:该模型下载自共享模型的库。
条款60包括条款59的设备,其中:该模型包括从另一用户设备上载到该库的经训练模型。
条款61包括条款59或条款60的设备,其中:该库对应于众包模型库。
条款62包括条款59到61中任一项的设备,其中:该库被包括在分布式上下文感知系统中。
本公开的特定方面在以下第四组相互关联的条款中作了描述:
根据条款63,一种包括指令的非瞬态计算机可读存储介质,这些指令在由设备的处理器执行时使该处理器:从一个或多个传感器设备接收传感器数据;确定关于该传感器数据的上下文;基于该上下文来选择模型;以及使用该模型来处理输入信号以生成因上下文而异的输出。
条款64包括条款63的非瞬态计算机可读存储介质,其中:该传感器数据包括该设备的位置的位置数据,并且其中该上下文至少部分地基于该位置。
条款65包括条款63或条款64的非瞬态计算机可读存储介质,其中:该传感器数据包括对应于视觉场景的图像数据,并且其中该上下文至少部分地基于该视觉场景。
条款66包括条款63到65中任一项的非瞬态计算机可读存储介质,其中:该传感器数据包括对应于音频场景的音频,并且其中该上下文至少部分地基于音频场景。
条款67包括条款63到66中任一项的非瞬态计算机可读存储介质,其中:该传感器数据包括对应于该设备的运动的运动数据,并且其中该上下文至少部分地基于该设备的运动。
条款68包括条款63到67中任一项的非瞬态计算机可读存储介质,其中:该模型选自存储在该设备的存储器处的多个模型。
条款69包括条款63到68中任一项的非瞬态计算机可读存储介质,其中:该模型包括声音事件检测模型,该输入信号包括音频信号,并且该因上下文而异的输出包括对该音频信号中的声音事件的分类。
条款70包括条款63到69中任一项的非瞬态计算机可读存储介质,其中:该模型包括自动话音识别模型,该输入信号包括音频信号,并且该因上下文而异的输出包括表示该音频信号中的话音的文本数据。
条款71包括条款63到70中任一项的非瞬态计算机可读存储介质,其中:该模型包括自然语言处理(NLP)模型,该输入信号包括文本数据,并且该因上下文而异的输出包括基于该文本数据的NLP输出数据。
条款72包括条款63到71中任一项的非瞬态计算机可读存储介质,其中:该模型包括降噪模型,该输入信号包括音频信号,并且该因上下文而异的输出包括基于该音频信号的经降噪音频信号。
条款73包括条款63到72中任一项的非瞬态计算机可读存储介质,其中:该模型与设备操作模式的自动调整相关联,并且其中该因上下文而异的输出包括用来调整该设备操作模式的信号。
条款74包括条款63到73中任一项的非瞬态计算机可读存储介质,其中:这些指令进一步使该处理器经由无线传输从第二设备接收该模型。
条款75包括条款63到74中任一项的非瞬态计算机可读存储介质,其中:该上下文对应于该设备的位置,并且其中该模型包括对应于特定位置的声学模型。
条款76包括条款75的非瞬态计算机可读存储介质,其中:这些指令进一步使该处理器至少部分地基于该设备的位置与该特定位置相匹配来接收对该模型的访问准许。
条款77包括条款75的非瞬态计算机可读存储介质,其中:这些指令进一步使该处理器响应于该设备离开该特定位置而移除该模型。
条款78包括条款63到77中任一项的非瞬态计算机可读存储介质,其中:该模型下载自共享模型的库。
条款79包括条款78的非瞬态计算机可读存储介质,其中:该模型包括从另一用户设备上载到该库的经训练模型。
条款80包括条款78或条款79的非瞬态计算机可读存储介质,其中:该库对应于众包模型库。
条款81包括条款78到80中任一项的非瞬态计算机可读存储介质,其中:该库被包括在分布式上下文感知系统中。
条款82包括条款63到81中任一项的非瞬态计算机可读存储介质,其中:该上下文包括特定声学环境,并且其中这些指令进一步使该处理器:确定可用声学模型库是否包括特定于该特定声学环境且可用于该设备的声学模型;以及响应于没有特定于该特定声学环境的声学模型可用于该设备而确定用于该特定声学环境的通用门类的声学模型是否可用于该设备。
本公开的特定方面在以下第五组相互关联的条款中作了描述:
根据条款83,一种设备包括一个或多个处理器,该一个或多个处理器被配置成:选择与建筑物中该设备位于其中的特定房间相对应的声学模型;以及使用该声学模型来处理输入音频信号。
条款84包括条款83的设备,其中该一个或多个处理器被配置成:响应于确定该设备已进入该特定房间而从声学模型库下载该声学模型。
条款85包括条款83或84的设备,其中该一个或多个处理器被进一步配置成:响应于该设备离开该特定房间而移除该声学模型。
条款86包括条款83到85中任一项的设备,并且进一步包括:一个或多个话筒,该一个或多个话筒被配置成生成该输入音频信号。
条款87包括条款83到86中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的一个或多个传感器设备,并且该一个或多个传感器设备被配置成生成指示该设备的位置的传感器数据,并且其中该一个或多个处理器被配置成基于该传感器数据来选择该声学模型。
条款88包括条款83到87中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的调制解调器,并且该调制解调器被配置成接收指示该设备的位置的位置数据,并且其中该一个或多个处理器被配置成基于该位置数据来选择该声学模型。
本公开的特定方面在以下第六组相互关联的条款中作了描述:
根据条款89,一种方法包括:在设备的一个或多个处理器处选择与建筑物中该设备位于其中的特定房间相对应的声学模型;以及在该一个或多个处理器处使用该声学模型来处理输入音频信号。
条款90包括条款89的方法,并且进一步包括:响应于确定该设备已进入该特定房间而从声学模型库下载该声学模型。
条款91包括条款89或条款90的方法,并且进一步包括:响应于该设备离开该特定房间而移除该声学模型。
条款92包括条款89到91中任一项的方法,并且进一步包括:基于指示该设备的位置的传感器数据来选择该声学模型。
条款93包括条款89到91中任一项的方法,并且进一步包括:基于指示该设备的位置的位置数据来选择该声学模型。
根据条款94,一种设备包括:用于选择与建筑物中该设备位于其中的特定房间相对应的声学模型的装置;以及用于使用该声学模型来处理输入音频信号的装置。
根据条款95,一种包括指令的非瞬态计算机可读存储介质,这些指令在由设备的处理器执行时使该处理器:选择与建筑物中该设备位于其中的特定房间相对应的声学模型;以及使用该声学模型来处理输入音频信号。
本公开的特定方面在以下第七组相互关联的条款中作了描述:
根据条款96,一种设备包括:一个或多个处理器,该一个或多个处理器被配置成:响应于该设备进入交通工具而从与该交通工具相对应的多个个性化声学模型之中为该设备的用户选择个性化声学模型;以及使用该个性化声学模型来处理输入音频信号。
条款97包括条款96的设备,其中该一个或多个处理器被配置成:响应于确定该设备已进入该交通工具而从声学模型库下载该个性化声学模型。
条款98包括条款96或条款97的设备,其中该一个或多个处理器被进一步配置成:响应于该设备离开该交通工具而移除该个性化声学模型。
条款99包括条款96到98中任一项的设备,并且进一步包括:一个或多个话筒,该一个或多个话筒被配置成生成该输入音频信号。
条款100包括条款96到99中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的一个或多个传感器设备,并且该一个或多个传感器设备被配置成生成指示该设备的位置的传感器数据,并且其中该一个或多个处理器被配置成基于该传感器数据来确定该设备已进入该交通工具。
条款101包括条款96到100中任一项的设备,并且进一步包括:调制解调器,该调制解调器耦合到该一个或多个处理器并且被配置成接收指示该设备的位置的位置数据,并且其中该一个或多个处理器被配置成基于该位置数据来确定该设备已进入该交通工具。
本公开的特定方面在以下第八组相互关联的条款中作了描述:
根据条款102,一种方法包括:在设备的一个或多个处理器处且响应于检测到用户进入交通工具而从与该交通工具相对应的多个个性化声学模型之中为该用户选择个性化声学模型;以及在该一个或多个处理器处使用该个性化声学模型来处理输入音频信号。
条款103包括条款102的方法,并且进一步包括:响应于确定该用户已进入该交通工具而从声学模型库下载该个性化声学模型。
条款104包括条款102或条款103的方法,并且进一步包括:响应于该用户离开该交通工具而移除该个性化声学模型。
条款105包括条款102到104中任一项的方法,并且进一步包括:基于指示该用户的位置的传感器数据来确定该用户已进入该交通工具。
根据条款106,一种设备包括:用于响应于检测到用户进入交通工具而从与该交通工具相对应的多个个性化声学模型之中为该用户选择个性化声学模型的装置;以及用于使用该个性化声学模型来处理输入音频信号的装置。
根据条款107,一种包括指令的非瞬态计算机可读存储介质,这些指令在由设备的处理器执行时使该处理器:响应于检测到用户进入交通工具而从与该交通工具相对应的多个个性化声学模型之中为该用户选择个性化声学模型;以及使用该个性化声学模型来处理输入音频信号。
本公开的特定方面在以下第九组相互关联的条款中作了描述:
根据条款108,一种设备包括:一个或多个处理器,该一个或多个处理器被配置成:下载与该设备位于其中的特定位置相对应的声学模型;使用该声学模型来处理输入音频信号;以及响应于该设备退出该位置而移除该声学模型。
条款109包括条款108的设备,其中:该位置对应于特定餐厅,并且其中该声学模型是响应于确定该设备已进入该特定餐厅而从声学模型库下载的。
条款110包括条款108或109的设备,并且进一步包括:一个或多个话筒,该一个或多个话筒被配置成生成该输入音频信号。
条款111包括条款108到110中任一项的设备,并且进一步包括:耦合到该一个或多个处理器的一个或多个传感器设备,并且该一个或多个传感器设备被配置成生成指示该设备的位置的传感器数据,并且其中该一个或多个处理器被配置成基于该传感器数据来确定该设备已进入该特定位置。
条款112包括条款108到110中任一项的设备,并且进一步包括:调制解调器,该调制解调器耦合到该一个或多个处理器并且被配置成接收指示该设备的位置的位置数据,并且其中该一个或多个处理器被配置成基于该位置数据来确定该设备已进入该特定位置。
本公开的特定方面在以下第十组相互关联的条款中作了描述:
根据条款113,一种方法包括:在设备的一个或多个处理器处下载与该设备位于其中的特定位置相对应的声学模型;在该一个或多个处理器处使用该声学模型来处理输入音频信号;以及在该一个或多个处理器处响应于该设备退出该位置而移除该声学模型。
条款114包括条款113的方法,其中:该位置对应于特定餐厅,并且其中该声学模型是响应于确定该设备已进入该特定餐厅而从声学模型库下载的。
条款115包括条款113或条款114的方法,并且进一步包括:基于指示该设备的位置的传感器数据来确定该设备已进入该特定位置。
条款116包括条款113或114的方法,并且进一步包括:基于指示该设备的位置的位置数据来确定该设备已进入该特定位置。
根据条款117,一种设备包括:用于下载与该设备位于其中的特定位置相对应的声学模型的装置;用于使用该声学模型来处理输入音频信号的装置;以及用于响应于该设备退出该位置而移除该声学模型的装置。
根据条款118,一种包括指令的非瞬态计算机可读存储介质,这些指令在由设备的处理器执行时使该处理器:下载与该设备位于其中的特定位置相对应的声学模型;使用该声学模型来处理输入音频信号;以及响应于该设备退出该位置而移除该声学模型。
本公开的特定方面在以下第十一组相互关联的条款中作了描述:
根据条款119,一种设备包括:一个或多个处理器,该一个或多个处理器被配置成:选择与特定位置相对应的声学模型;至少部分地基于该设备的位置与该特定位置相匹配来接收对该声学模型的访问准许;以及使用该声学模型来处理输入音频信号。
条款120包括条款119的设备,并且进一步包括调制解调器,并且其中该一个或多个处理器被进一步配置成响应于在该特定位置内检测到该设备而经由该调制解调器来接收该访问准许。
本公开的特定方面在以下第十二组相互关联的条款中作了描述:
根据条款121,一种方法包括:在设备的一个或多个处理器处选择与特定位置相对应的声学模型;在该一个或多个处理器处至少部分地基于该设备的位置与该特定位置相匹配来接收对该声学模型的访问准许;以及在该一个或多个处理器处使用该声学模型来处理输入音频信号。
条款122包括条款121的方法,并且进一步包括:响应于在该特定位置内检测到该设备而接收该访问准许。
根据条款123,一种设备包括:用于选择与特定位置相对应的声学模型的装置;用于至少部分地基于该设备的位置与该特定位置相匹配来接收对该声学模型的访问准许的装置;以及用于使用该声学模型来处理输入音频信号的装置。
根据条款124,一种包括指令的非瞬态计算机可读存储介质,这些指令在由设备的处理器执行时使该处理器:选择与特定位置相对应的声学模型;至少部分地基于该设备的位置与该特定位置相匹配来接收对该声学模型的访问准许;以及使用该声学模型来处理输入音频信号。
本公开的特定方面在以下第十三组相互关联的条款中作了描述:
根据条款125,一种设备包括一个或多个处理器,该一个或多个处理器被配置成:检测该设备的上下文;向远程设备发送指示该上下文的请求;接收与该上下文相对应的模型;在该上下文保持被检测到时使用该模型;以及响应于检测到该上下文的改变而修剪该模型。
条款126包括条款125的设备,其中:该一个或多个处理器被进一步配置成在该上下文保持被检测到时生成至少一个新声音类别,并且其中修剪该模型包括保留该至少一个新声音类别。
条款127包括条款125或条款126的设备,其中:修剪该模型包括永久性地删除该模型。
条款128包括条款125到127中任一项的设备,其中:该一个或多个处理器被进一步配置成基于私有访问来接收该模型。
根据条款129,一种方法包括:在该设备的一个或多个处理器处检测该设备的上下文;向远程设备发送指示该上下文的请求;接收与该上下文相对应的模型;在该一个或多个处理器处在该上下文保持被检测到时使用该模型;以及在该一个或多个处理器处响应于检测到该上下文的改变而修剪该模型。
条款130包括条款129的方法,进一步包括:在该上下文保持被检测到的同时生成至少一个新声音类别,并且其中修剪该模型包括保留该至少一个新声音类别。
条款131包括条款129或条款130的方法,其中:修剪该模型包括永久性地删除该模型。
条款132包括条款129到131中任一项的方法,其中:该模型是基于私有访问来接收的。
根据条款133,一种装备包括:用于向远程设备发送指示该上下文的请求的装置;用于接收与该上下文相对应的模型的装置;用于在该上下文保持被检测到时使用该模型的装置;以及用于响应于检测到该上下文的改变而修剪该模型的装置。
根据条款134,一种包括指令的非瞬态计算机可读存储介质,这些指令在由设备的处理器执行时使该处理器:检测设备的上下文;向远程设备发送指示该上下文的请求;接收与该上下文相对应的模型;在该上下文保持被检测到时使用该模型;以及响应于检测到该上下文的改变而修剪该模型。
提供对所公开各方面的先前描述是为使本领域技术人员皆能够制作或使用所公开各方面。对这些方面的各种修改对于本领域技术人员而言将是显而易见的,并且本文中定义的原理可被应用于其他方面而不会脱离本公开的范围。由此,本公开并非旨在限定于本文中示出的各方面,而是应被授予可能与如由所附权利要求所定义的原理和新颖性特征一致的最广义的范围。
- 混合视频编码工具的用例驱动上下文模型选择
- 一种上下文模型选择的方法和装置