问答系统及其操作方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及一种问答系统,尤其是一种利用深度学习的问答系统及其操作方法。
背景技术
常见问答集(Frequently Asked Question,FAQ)可以被汇整并被呈现于网页中,也可以被建立成问答系统。一般而言,基于FAQ检索式的问答系统可以利用机器学习方法来被实现。然而,目前利用机器学习的问答系统在训练时无法取得充足的的样本数据,导致训练结果的准确率低落。
发明内容
本发明是针对一种问答系统,能够根据用户的反馈来更新深度学习训练所使用的训练数据库,以增加问答系统的准确度。
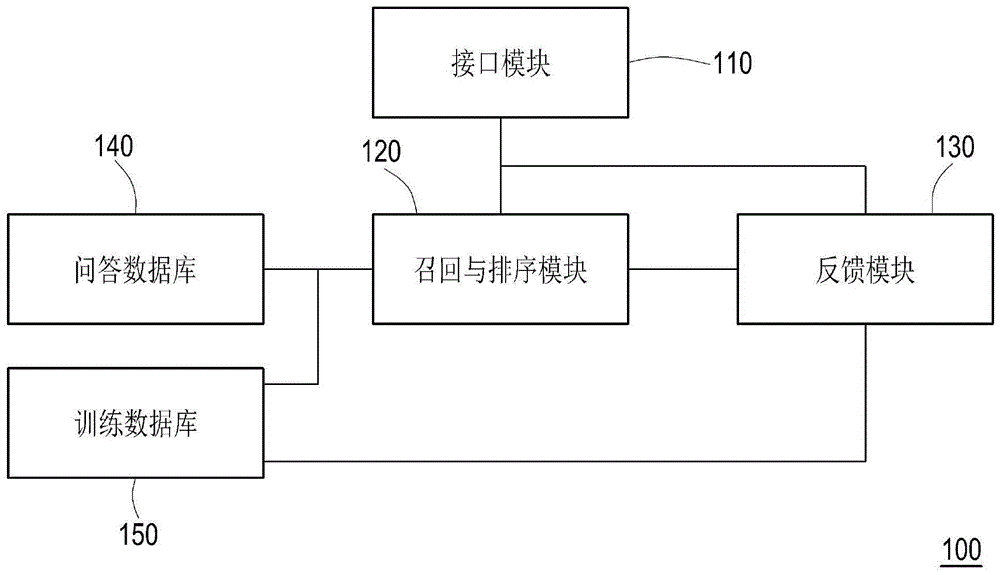
根据本发明的实施例,本发明的问答系统包括问答数据库、训练数据库、接口模块、召回与排序模块以及反馈模块。接口模块用以获取用户请求。召回与排序模块用以根据训练数据库进行训练。召回与排序模块用以经训练后,根据用户请求以及问答数据库来生成多个候选答案,以使接口模块输出多个候选答案并获取用户反馈。反馈模块用以根据用户反馈来生成新增问题,并根据新增问题来更新训练数据库。
根据本发明的实施例,本发明的问答系统的操作方法包括以下的步骤。获取用户请求。通过召回与排序模块根据训练数据库进行训练。通过经训练后的召回与排序模块根据用户请求以及问答数据库来生成多个候选答案。输出多个候选答案并获取用户反馈。根据用户反馈来生成新增问题。根据新增问题来更新训练数据库。
基于上述,本发明的问答系统以及问答系统的操作方法可基于用户反馈来对训练数据库进行更新,以使训练数据库能够基于实际操作结果来提高样本数据量。如此一来,更新后的训练数据库能够提高召回与排序模块的训练准确率,以提高经训练后所生成的候选答案的准确率。
为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合附图作详细说明如下。
附图说明
图1是本发明的一实施例的问答系统的电路方块图;
图2是本发明的一实施例的问答系统的操作方法的流程图;
图3A至3C是本发明的一实施例的问答系统的操作方法的动作示意图;
图4是本发明的图3B实施例的问答系统的操作方法的动作示意图;
图5是本发明的图3B实施例的问答系统的操作方法的动作示意图;
图6是本发明的另一实施例的问答系统的操作方法的动作示意图。
附图标记说明
100、600:问答系统;
110:接口模块;
120:召回与排序模块;
130:反馈模块;
140:问答数据库;
150:训练数据库;
S210~S260:步骤;
S311~S364、S411~S416、S511~S528、S611~S633:模块。
具体实施方式
现将详细地参考本发明的示范性实施例,示范性实施例的实例说明于附图中。只要有可能,相同元件符号在图式和描述中用来表示相同或相似部分。
图1是本发明的一实施例的问答系统的电路方块图。参考图1,问答系统100可提供平台即服务(Platform as a service,PaaS)。各种云端服务平台(未绘示)可应用问答系统100,以通过问答系统100提供相关的问答集服务。问答系统100可利用深度学习(deeplearning)平台(或模型)来实现常见问答集(Frequently Asked Question,FAQ)检索式的服务。在本实施例中,问答系统100可包括接口模块110、召回与排序模块120、反馈模块130、问答数据库140以及训练数据库150。
在本实施例中,接口模块110耦接召回与排序模块120以及反馈模块130。接口模块110可获取用户输入的数据,并且输出召回与排序模块120的计算结果以供用户参考。在本实施例中,接口模块110可例如是用户接口(User Interface,UI)。
在本实施例中,召回与排序模块120耦接问答数据库140以及训练数据库150。召回与排序模块120可包括深度学习平台(或模型)。召回与排序模块120可使用前述的模型以根据训练数据库150进行训练。经训练后的召回与排序模块120可根据问答数据库140以及用户所输入的数据来进行推论以生成计算结果。在本实施例中,召回与排序模块120可例如是信号转换器、现场可程序化逻辑门阵列(Field Programmable Gate Array,FPGA)、中央处理单元(Central Processing Unit,CPU),或是其他可程序化之一般用途或特殊用途的微处理器(Microprocessor)、数字信号处理器(Digital Signal Processor,DSP)、可程序化控制器、特殊应用集成电路(Application Specific Integrated Circuits,ASIC)、可程序化逻辑设备(Programmable Logic Device,PLD)或其他类似装置或这些装置的组合,其可加载并执行计算机程序相关韧体或软件,以实现神经网络的训练与推论等功能。
在本实施例中,反馈模块130耦接训练数据库150。反馈模块130可维护与更新训练数据库150。在本实施例中,反馈模块130可例如是信号转换器、现场可程序化逻辑门阵列(Field Programmable Gate Array,FPGA)、中央处理单元(Central Processing Unit,CPU),或是其他可程序化之一般用途或特殊用途的微处理器(Microprocessor)、数字信号处理器(Digital Signal Processor,DSP)、可程序化控制器、特殊应用集成电路(Application Specific Integrated Circuits,ASIC)、可程序化逻辑设备(ProgrammableLogic Device,PLD)或其他类似装置或这些装置的组合,其可加载并执行计算机程序相关韧体或软件,以实现数据处理等功能。
在本实施例中,问答数据库140可储存多个数据。前述的数据可关联于默认的多个问题、多个相似问题以及对应的答案。这些问题以及这些答案可分别是以中文语句来被实现。在本实施例中,问答数据库140可例如是关系型数据库或非关系型数据库。
在本实施例中,训练数据库150可储存多个数据。前述的数据可关联于开发人员提供的多个问题以及对应的答案、以及云端服务平台所收集到的多个问题以及对应的答案。这些问题以及这些答案可分别是以中文语句来被实现。在本实施例中,前述的云端服务平台可例如是云端客服系统或是企业资源规划系统(Enterprise resource planning,ERP)等服务平台,以提供用户各种服务。在本实施例中,训练数据库150可例如是关系型数据库或非关系型数据库。
应注意的是,问答数据库140中的数据为固定的,以使召回与排序模块120基于问答数据库140进行推论。训练数据库150中的数据为动态的,以通过反馈模块130来进行维护与更新,以及通过召回与排序模块120基于训练数据库150来进行训练。
图2是本发明的一实施例的问答系统的操作方法的流程图。参考图1以及图2,问答系统100可执行如以下步骤S210~S260,以示例说明问答系统100实现智能FAQ检索式的服务。这些步骤S210~S260的顺序仅为示例说明,并不以此为限。
在步骤S210,通过接口模块110获取用户所输入的用户请求。在本实施例中,用户请求可以中文语句来被实现,并可例如是问句、肯定句、否定句或至少一个单词。举例来说,对于应用于ERP服务平台的问答系统100而言,用户请求可例如是”不同库别性质的仓库可不可以转拨?”。
在步骤S220,通过召回与排序模块120根据训练数据库150进行训练。
在步骤S230,通过经训练后的召回与排序模块120根据用户请求以及问答数据库140来生成多个候选答案。也就是说,经训练后的召回与排序模块120可对步骤S210的用户请求以及问答数据库140来进行推论,以生成计算结果(即,对应于用户请求的多个候选答案)。
在步骤S240,通过接口模块110输出多个候选答案以供用户参考,并获取用户所输入且对应于这些候选答案的用户反馈。举例来说,这些候选答案可例如是”不同库别性质的仓库可以转拨”以及”仓库的转拨操作包括…”等。当用户获得这些候选答案后,用户可通过接口模块110输入这些候选答案中至少一者的意见,以反馈这些候选答案是否有帮助。
在步骤S250,通过反馈模块130根据用户反馈来生成新增问题。也就是说,反馈模块130可将步骤S240中的用户反馈以及对应的用户请求生成一组问题与答案对(即,问答集)以作为新增问题。
在步骤S260,通过反馈模块130根据新增问题来更新训练数据库150。也就是说,对于目前经训练后的召回与排序模块120而言,反馈模块130基于用户对目前问答系统100的答案的反馈来生成额外的样本数据(即,新增问题),并以此样本数据来更新训练用的训练数据库150。
在此值得一提的是,反馈模块130可基于用户反馈来生成新的样本数据(即,新增问题)以对训练数据库150进行更新,能够增加训练数据库150的数据量。因此,召回与排序模块120可基于经更新后的训练数据库150来进行训练,以提高训练时的准确率。此外,经再次训练后的召回与排序模块120能够生成的更高准确率的候选答案。
图3A至3C是本发明的一实施例的问答系统的操作方法的动作示意图。参考图3A至3C以及图1,问答系统100可执行多个模块S311~S365,以示例说明问答系统100实现智能FAQ检索式的服务。
在模块S311~S316中,用户可输入问题,并通过经训练后的问答系统100获得对应此问题的多个候选答案。用户可针对所获得的这些候选答案进行反馈。详细而言,在模块S311中,通过接口模块110获取用户所输入的用户请求。
在模块S312以及S313中,通过经训练后的召回与排序模块120根据用户请求以及问答数据库140来分别进行问题召回以及问题排序,以生成多个候选答案。也就是说,经训练后的召回与排序模块120可针对用户所提出的用户请求进行推论,并在问答数据库140中找到最相近于用户请求的多个问题及/或对应的答案。
在本实施例中,模块S312中关于问题召回可包括以下的操作细节。通过经训练后的召回与排序模块120对用户请求的询问(query)解析以及意图理解。通过经训练后的召回与排序模块120根据经解析的用户请求,对问答数据库140进行精准召回以及语意召回,以获得与用户请求最相近的多个问题及/或对应的答案。举例来说,经训练后的召回与排序模块120可使用表示型(Representation-based)的文本匹配模型提取问答数据库140中所有关于用户请求的语意向量,并使用(Facebook AI Similarity Search,Fasis)工具作为向量索引以进行语意召回。或者,经训练后的召回与排序模块120可将问答数据库140中所有关于用户请求的数据按照大类归纳进行分类,并将这些经分类后的数据进行向量索引以进行语意召回。也就是说,经训练后的召回与排序模块120可在召回前先使用分类模型对这些数据进行分类,接着对大类归纳中的这些向量索引进行语意召回。
在本实施例中,模块S313中关于问题排序可包括以下的操作细节。通过经训练后的召回与排序模块120使用相似度模型及/或点击率(click-through rate,CTR)模型对经问题召回的这些问题及/或对应的答案进行排序,以生成最后的计算结果(即,多个候选答案)。前述的候选答案可依照相似度的最高至最低依序排序。或者,经训练后的召回与排序模块120可使用交互型(Interaction-based)的文本匹配模型来执行模块S313。
在模块S314中,通过接口模块110进行曝光问题以输出多个候选答案供用户参考。在模块S315中,通过接口模块110进行用户点击以获取用户所输入且对应于这些候选答案的用户反馈。
在模块S316中,通过反馈模块130获取用户反馈。也就是说,在模块S311至模块S315关于问答系统100与用户的交流过程中,通过经训练后的召回与排序模块120推出最准确(或最相似)的多个候选答案后,通过接口模块110提示用户对于此(些)候选答案是否有用,以通过反馈模块130记录用户的行为。在一些实施例中,当用户未点击而没有提供用户反馈时,反馈模块130推定用户认为这些候选答案符合用户请求而具有实质帮助。此时,接口模块110生成表示为有用的用户反馈。
在模块S321~S325中,通过经训练后的问答系统100根据用户反馈来生成新增问题,并且根据新增问题来更新训练数据库150。详细而言,在模块S321中,通过反馈模块130根据用户反馈来生成新增问题。当用户反馈表示为有用时,通过反馈模块130对(一个或多个)候选答案以及用户请求进行聚类挖掘以计算出相同的类别(或簇)(即,新增问题)。当用户反馈表示为有没用时,通过反馈模块130执行前述关于聚类挖掘的操作以生成新增问题。
在模块S322中,通过反馈模块130根据模块S321中的新增问题以及问答系统100所提供的审核结果来进行审核,以判断是否将新增问题新增至训练数据库150,以更新训练数据库150。在本实施例中,问答系统100的开发者可通过问答系统100的后端(未绘示)来随机挑选新增问题以及对应的用户反馈与用户请求,并对经挑选的这些数据进行审核以输入审核结果至反馈模块130。审核结果可例如是专业人员对于新增问题的评断,以提供新增问题是否入库的建议。
当反馈模块130拒绝新增问题新增至训练数据库150时,经训练后的问答系统100执行模块S323。反之,当反馈模块130同意新增问题新增至训练数据库150时,经训练后的问答系统100执行模块S324。
在模块S323中,通过反馈模块130拒绝新增问题新增至训练数据库150以进行拒绝入库(即,负反馈操作)。详细而言,当反馈模块130拒绝新增问题新增至训练数据库150时,通过反馈模块130生成对应于新增问题的负样本数据至训练数据库150。举例来说,当用户反馈表示为没用时,表示模块S314所输出的所有候选答案皆不符合用户请求。此时,反馈模块130可将这些候选答案以及用户请求作为新增问题,以生成对应于此新增问题的负样本数据。
在模块S324中,通过反馈模块130同意新增问题新增至训练数据库150以进行同意入库(即,正反馈操作)。详细而言,当反馈模块130同意新增问题新增至训练数据库150时,通过反馈模块130生成对应于新增问题的正样本数据至训练数据库150。举例来说,当用户反馈表示为有用时,表示模块S314所输出的某个候选答案符合用户请求。这个候选答案是目前经训练后的召回与排序模块120能够根据用户请求所召回的数据,因此相同的数据不需要再重复新增至训练数据库150中。此时,反馈模块130可将其他的候选答案以及用户请求作为新增问题,以生成对应于此新增问题的正样本数据。
在模块S325中,通过反馈模块130将对应于新增问题的负样本数据或正样本数据新增至训练数据库150,以更新训练数据库150。
应注意的是,不论用户反馈表示为有用或没用,反馈模块130可基于用户反馈的新增问题来将负样本数据及正样本数据新增至训练数据库150,以累积并扩大训练数据库150的数据量。因此,召回与排序模块120可基于训练数据库150进行训练,以不断优化召回与排序模块120的深度学习模型。
在模块S331~S336中,通过问答系统100根据训练数据库150来进行训练,或者,通过经训练后的问答系统100根据经更新后的训练数据库150来进行训练,以建立相似度模型。在一些实施例中,问答系统100可重复执行模块S331~S336,直到完成训练而建立相似度模型。
详细而言,在模块S331中,通过召回与排序模块120来选取并建立模型,并进行模型训练。在模块S332中,通过召回与排序模块120使用交互型的文本匹配模型来进行训练。
在模块S333中,通过召回与排序模块120使用文本匹配模型并利用预训练语言模型来进行训练,例如是进行Bert-base模型生成。Bert-base模型可针对训练数据库150中用作语意训练的参数进行微调,以加快训练的速度。在模块S334中,通过召回与排序模块120使用文本匹配模型并利用交互型的句子相似度比较模型来进行训练,例如是进行自然语言推论Enhanced LSTM for Natural Language Inference,ESIM)模型试验。ESIM模型可捕捉语句向量之间的交互信息,以提高相似度计算的准确率。
在模块S335中,通过召回与排序模块120进行模型调参,以优化文本匹配模型所使用的各种参数。也就是说,召回与排序模块120可微调文本匹配模型的一个或多个参数,并以此(些)经微调的参数进行大量训练。
在模块S336中,通过经训练后的召回与排序模块120来建立相似度模型。也就是说,经过模块S331至模块S335的训练,召回与排序模块120可基于文本匹配模型,根据训练数据库150或经更新的训练数据库150以及经微调的多个参数来进行训练,以生成用以推论的相似度模型。在本实施例中,通过经训练后的召回与排序模块120使用模块S336中的相似度模型可执行模块S313,以根据问答数据库140进型推论以生成最相近于用户请求的多个候选答案。
在模块S341~S342中,通过问答系统100的数据处理模块(未绘示于图1)处理训练数据库150中的数据。在本实施例中,数据处理模块可例如是信号转换器、现场可程序化逻辑门阵列(Field Programmable Gate Array,FPGA)、中央处理单元(Central ProcessingUnit,CPU),或是其他可程序化之一般用途或特殊用途的微处理器(Microprocessor)、数字信号处理器(Digital Signal Processor,DSP)、可程序化控制器、特殊应用集成电路(Application Specific Integrated Circuits,ASIC)、可程序化逻辑设备(ProgrammableLogic Device,PLD)或其他类似装置或这些装置的组合,其可加载并执行计算机程序相关韧体或软件,以实现计算等功能。在一些实施例中,数据处理模块与召回与排序模块120整合在一起。
详细而言,在模块S341中以及图3B实施例所示的模块S531~S356中,通过数据处理模块生成并处理多个负样本数据至训练数据库150。在模块S342中以及图3C实施例所示的模块S361~S365中,通过数据处理模块生成并处理多个正样本数据至训练数据库150。
在模块S351中,问答系统100的开发者可通过问答系统100的后端,将专业人员对于问答集的总结归纳输入至问答系统100。在模块S353中,通过数据处理模块进行原始数据获取,以获取模块S531所提供的多个第一问答集。在本实施例中,这些第一问答集包括多个问题以及对应的答案。前述的专业人员可例如是应用问答系统100的云端服务平台的开发者或业务专家。专业人员了解哪些问答对是最常使用且对于云端服务平台为重要的。专业人员可搜集来自云端服务平台相关产品的说明书及实施手册等,以总结归纳出这些第一问答集。
在模块S352中,通过数据处理模块获取应用问答系统100的云端服务平台的数据。在本实施例中,前述的数据包括云端服务平台中的历史数据。这些历史数据是云端服务平台在使用过程中所生成的客服应答。这些历史数据可例如是以中文语句来被实现,并以问答对来被呈现。在模块S354中,通过数据处理模块对云端服务平台进行数据挖掘以获得多个第二问答集。也就是说,通过数据处理模块总结归纳模块S352中所获取的数据,以生成用户实际使用云端服务平台所遇到的这些第二问答集。
在模块S355~S356中,通过数据处理模块接收来自专业人员的多个第一问答集以及来自云端服务平台的多个第二问答集,并且根据问答数据库140、这些第一问答集以及这些第二问答集进行召回策略以及语意向量召回以生成多个负样本数据至训练数据库150。
详细而言,在模块S355中,通过数据处理模块对多个第一问答集以及多个第二问答集进行数据预处理,以针对各个问题进行召回策略。举例来说,对于这些第一问答集以及这些第二问答集中的某个问题(以下称为原问题),通过数据处理模块从问答数据库140中召回与原问题相似的5笔相似问题作为原问题的负样本数据。通过数据处理模块及/或专业人员判断原问题以及这些5笔相似问题中是否有与原问题语意相同者。当相似问题与原问题语意不相同时,数据处理模块及/或专业人员将此相似问题设置为负样本数据。反之,当相似问题与原问题语意相同时,数据处理模块及/或专业人员将此相似问题设置为正样本数据。在模块S356中,通过数据处理模块对经数据预处理的问答集进行召回策略,以针对各个问题进行语意向量召回并生成多个负样本数据。
在模块S361~S365中,通过数据处理模块对模块S351~S356中的多个第一问答集以及多个第二问答集进行数据增强以生成多个正样本数据以及多个负样本数据中至少一者至训练数据库150。
详细而言,在模块S361中,通过数据处理模块对多个第一问答集以及多个第二问答集进行同义词替换,以改写文本而生成多个正样本数据。举例来说,对于这些第一问答集以及这些第二问答集中的某个问题(以下称为原问题),通过数据处理模块利用同义词随机替换原问题中的关键词。数据处理模块例如是将原问题”不同库别性质的仓库可不可以转拨?”中的关键词”可不可以”替换成”该如何”,以生成相似问题”不同库别性质的仓库该如何转拨?”。
在模块S362中,通过数据处理模块对多个第一问答集以及多个第二问答集进行随机交换,以改写文本而生成多个正样本数据。举例来说,对于原问题,通过数据处理模块随机调换相邻的两个词。数据处理模块例如是将原问题”不同库别性质的仓库可不可以转拨?”中的词”库别性质”以及”仓库”互换,以生成相似问题”不同仓库的库别性质该如何转拨?”。
在模块S363中,通过数据处理模块对多个第一问答集以及多个第二问答集进行随机插入或回译法,以改写文本而生成多个正样本数据。举例来说,对于原问题,通过数据处理模块将中文转换成英文,再将英文转换成中文以获得相似语句。数据处理模块例如是将原问题”不同库别性质的仓库可不可以转拨?”转换成”Can different warehouses betransferred?”,并再将前述的英文语句转换成”不同的仓库可以转运吗?”的相似问题。
在模块S364中,通过数据处理模块对多个第一问答集以及多个第二问答集进行随机删除,以改写文本而生成多个负样本数据。举例来说,对于原问题,通过数据处理模块随机删除原问题中的关键词。数据处理模块例如是将原问题”不同库别性质的仓库可不可以转拨?”中的关键词”可不可以”删除,以生成相似问题”不同库别性质的仓库转拨?”。
应注意的是,在模块S361~S363中,数据处理模块所进行的改写文本能够基于模块S351~S356所获取的数据来新增语意相近或相似的数据,以增强正样本数据。在模块S364中,数据处理模块所进行的改写文本则能够基于模块S351~S356所获取的数据来新增语意经改变的数据,以增强负样本数据。
在模块S365中,通过数据处理模块对模块S361~S364所生成的正样本数据以及负样本数据进行数据增强,以根据正样本数据及/或负样本数据来更新训练数据库150。
在本实施例中,模块S365中关于数据增强可包括以下的操作细节。通过数据处理模块对正样本数据以及负样本数据分别进行语意关系的传递性规则,以增加数据的数量与质量而能够使召回与排序模块120根据这些正、负样本数据来进行训练。举例来说,针对正样本数据,假设第一原问题”报废的流程”与第二原问题”报废的各个环节”具有相似词,数据处理模块将第一原问题以及第二原问题之间的关系标记为”1”。假设第一原问题与第三原问题”报废的操作步骤”具有相似词,数据处理模块将第一原问题以及第三原问题之间的关系也标记为”1”。此时,数据处理模块根据前述的多个标记可推得第二原问题与第三原问题具有相似词,并且将第二原问题以及第三原问题之间的关系标记为”1”。又例如,针对负样本数据,假设第一原问题与第四原问题”报废的定义”不具有相似词,数据处理模块将第一原问题以及第四原问题之间的关系标记为”0”。此时,数据处理模块根据前述的多个标记可推得第二原问题与第四原问题不具有相似词,并且将第二原问题以及第四原问题之间的关系标记为”0”。
图4是本发明的图3B实施例的问答系统的操作方法的动作示意图。参考图4以及图1,问答系统100可执行多个模块S411~S416,以示例说明问答系统100生成并处理多个负样本数据(即,模块S531~S356)的另一实施操作细节。
在模块S411中,通过数据处理模块或者问答系统100的后端获取专业人员对于问答集的总结归纳。在模块S412中,通过数据处理模块从应用问答系统100的云端服务平台的历史数据中挖掘。
在模块S413中,通过数据处理模块进行文本聚类(Clustering),以对前述的所有历史数据进行聚类。在模块S414中,通过数据处理模块进行文本聚类,以对各个聚类的簇进行计数。在模块S415中,通过数据处理模块进行文本聚类,以设定预设数量,其中当各个聚类的某个簇所包括的数据样本数量超过预设数量,通过数据处理模块将此簇定义为常见问题。
在本实施例中,数据处理模块可使用k-平均(k-means)聚类算法以进行模块S413~S415的文本聚类。具体来说,数据处理模块可获取历史数据中的样本集合D,并设定各个聚类的簇的数量k,其中数量k为正整数。数据处理模块从样本集合D中随机选取k个历史数据作为初始均值向量initial_mean_vector_list。接着,数据处理模块设定迭代轮次epoch,并在各个迭代轮次epoch中循环样本集合D。数据处理模块定义列表以存放聚类后的簇集合C。数据处理模块计算各个历史数据与各个迭代轮次epoch中对应的均值向量的欧式距离。数据处理模块将历史数据存放于与其欧式距离最小的均值向量所在的簇集合C中。数据处理模块重复前述的多个操作,直到簇集合C中的历史数据的数量大于预设数量,以设定此簇集合C为常见问题。
在模块S416中,通过数据处理模块形成标准问题,以补充训练数据库150。也就是说,数据处理模块可将模块S415中的常见问题作为标准问题,并将标准问题新增至训练数据库150以扩充其数据量。
图5是本发明的图3B实施例的问答系统的操作方法的动作示意图。参考图5以及图1,问答系统100可执行多个模块S511~S523,以示例说明问答系统100进行召回策略以及语意向量召回的实施操作细节。
在模块S511~S513中,通过数据处理模块根据问答数据库140、各个第一问答集以及各个第二问答集进行语意向量召回。也就是说,通过数据处理模块对各个第一问答集以及各个第二问答集从问答数据库140中召回多笔相似问题。前述的相似问题的数量可以由问答系统100的来设定,例如是最相似的5笔。
在模块S521~S528中,通过数据处理模块对这些召回的多笔相似问题进行文本向量化。详细而言,在模块S521中,数据处理模块可例如是使用SimBERT模型来对各个相似问题的多个语句(例如是语句sent_a以及sent_b)进行编码,以得到多个语意表示向量。语意表示向量可例如是模块S525所示的向量。
在模块S522中,通过数据处理模块对多个语意表示向量所形成的向量矩阵进行计算。举例来说,数据处理模块可对各个语意表示向量进行距离计算以获得对应的损失(loss)。数据处理模块根据此损失来更新SimBERT模型的参数。
在模块S523中,通过数据处理模块使用Fasis工具来处理多个语意表示向量。举例来说,数据处理模块可使用经训练好的SimBERT模型来对各个语意表示向量进行推论,以脱机得到多个项目(item)向量。
在模块S524中,通过数据处理模块将模块S5235中的多个项目向量保存在Fasis工具中以作为向量索引(index)。举例来说,数据处理模块可使用倒排(Inverted indexFile,IVFx)平面(Flat)索引来建构向量索引。前述的倒排是指一个语词(term)对应多个文档以建构语词对文档矩阵。
在本实施例中,模块S524中关于向量索引可包括以下的操作细节。通过数据处理模块对各个相似问题进行分词以获得各个分词对应的文档。通过数据处理模块计算这些文文件与对应的分词间的相似度。通过数据处理模块将所有语意表示向量进行聚类以获得聚类簇中心的身分(ID),以获得身分对文档向量间的对应关系。通过数据处理模块计算相似问题向量与聚类簇中心向量间的欧式距离以获得距离最近的数个身分。接着,通过数据处理模块分别计算这些身分所对应的多个文档向量的欧式距离。
在模块S525中,通过数据处理模块使用SimBERT模型来对一串文本进行计算以获得对应的向量(可例如是向量[0.002,0.0023,…])。
在模块S526~S528中,通过数据处理模块从Fasis工具中进行实时召回以获得最相似的数个向量。前述的向量例如是模块S527所示的向量[0.002,0.0023,…]。通过数据处理模块可将前述的向量作为实时召回的召回结果,以获得对应的向量身分。前述的向量身分可例如是模块S528所示的向量身分[12,30,100,208…]。
在本实施例中,在实时召回后,数据处理模块可获得对于各个第一问答集以及各个第二问答集与对应的最相似的数个向量(即,1:k个问题与相似问题)。也就是说,数据处理模块可将这些召回的数个向量对应的相似问题作为多个负样本数据。
图6是本发明的另一实施例的问答系统的操作方法的动作示意图。参考图6,问答系统600可以参照问答系统100的相关说明并且加以类推,故在此不另重述。在本实施例中,问答系统600可包括接口模块、召回与排序模块、反馈模块、问答数据库、训练数据库以及数据处理模块以分别执行对应的操作。
在模块S611中,通过接口模块获取用户输入的文本、问句等数据。在模块S612中,通过召回与排序模块进行意图识别。举例来说,召回与排序模块可进行意图归纳以及使用意图分类模型进行意图识别。在模块S613中,通过召回与排序模块进行召回策略。举例来说,召回与排序模块可使用Elasticsearch(ES)模型及/或BM25模型来进行召回策略以及语意向量召回以形成多个负样本数据。召回与排序模块可使用Fasis工具来建立向量索引以形成多个负样本数据。
在模块S621中,通过召回与排序模块建立深度学习平台。举例来说,召回与排序模块可使用TensorFlow的开源软件库来实现(或开发)深度学习平台。召回与排序模块可使用Keras的开源程序来来实现深度学习平台。在模块S622中,通过召回与排序模块进行模行训练。举例来说,召回与排序模块可根据训练数据库中的训练集以及测试集来进行训练。召回与排序模块可进行ESIM模型试验。此外,召回与排序模块可进行Bert-base模型生成。召回与排序模块可基于Bert-base模型来对参数进行微调以重复测试出合适的指标。前述的指标例如是包括准确率(precision)、召回率(recall)以及F值(F-score)等。在模块S623中,通过召回与排序模块根据用户输入的数据(例如是用户请求以及用户反馈)以及问答数据库进行答案推荐。举例来说,召回与排序模块可根据用户请求以及问答数据库进行问题召回以生成模板(例如是多个候选答案)。召回与排序模块可根据用户反馈以及问答数据库进行问题召回以进行互动反馈。在模块S624中,通过反馈模块根据用户反馈来进行模型更新。举例来说,反馈模块可记录用户行为、根据用户反馈来生成新增问题而生成正样本数据及/或负样本数据、以及根据新增问题来更新训练数据库以及召回与排序模块所使用的模型。
在模块S631中,通过问答数据库以及训练数据库来维护数据。举例来说,通过数据处理模块从云端服务平台获取历史数据。通过反馈模块以新增问题来更新训练数据库。通过数据处理模块获取专业人员的问答集。在模块S632中,通过数据处理模块进行负样本数据正样本数据的数据增强。举例来说,数据处理模块可对正样本数据及/或负样本数据进行语意关系的传递性规则、同义词替换、随机交换、随机插入、随机删除以及回译法等。在模块S633中,通过反馈模块根据用户反馈来生成新增问题以更新训练数据库。举例来说,反馈模块可根据用户反馈以及审核结果来对新增问题进行同意入库(即,正反馈操作)、拒绝入库(即,负反馈操作),以及对新增问题来进行问句提取、问句距离计算以及增量聚类等操作以补充训练数据库的数据。
综上所述,本发明的问答系统以及问答系统的操作方法可通过获取用户反馈,并基于用户反馈来生成新的样本数据(即,新增问题)以对训练数据库进行更新,并据以再次训练深度学习模型(即,召回与排序模块)。因此,前述的方式能够提高训练时的准确率,并能够提高推论时的准确率以提供有用的候选答案。在部分实施例中,通过数据处理模块能够对正样本数据以及负样本数据进行数据增强,以扩大训练数据库中的数据量。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 一种专家问答系统及其操作方法
- 一种专家问答系统及其操作方法