一种基于提示学习和双信息源融合的API推荐方法
文献发布时间:2024-04-18 19:57:50
技术领域
本发明属于API推荐技术领域,具体涉及一种基于提示学习和双信息源融合的API推荐方法,主要用于更好利用嵌入在前训练过程中的丰富语义信息和语言知识,将下游任务重新规划为预训练语言模型(PLM)培训任务,提供更高效、更准确的API选择和使用体验。
背景技术
随着数字化时代的到来,应用程序编程接口(API)已成为现代软件开发中不可或缺的一部分。API是一组定义了软件组件之间交互方式的规范,允许不同的应用程序之间进行数据和功能的共享。为了帮助API搜索,人们提出了许多自动化的API推荐方法。该任务有两种正交的方法,即基于信息检索的方法和基于神经的方法。然而这些方法忽略了真实大规模语料库中丰富的语义和语言信息。
最近的一些方法更进一步,引入了一种预训练语言模型(pre-train languagemodel,PLM)来学习API推荐。一些常见的方法使用了普通的预训练和微调范式来调整推荐任务。虽然这些方法在性能上有很好的提高,但由于下游任务和PLM培训目标不一致,它们并没有很好地利用大规模PLM中丰富的百科全书式知识。如图4所示,最近一种新的预训练、提示和预测范式即提示学习在自然语言处理(NLP)领域的许多应用中取得了显著的成功。这种新范式的基础是通过设计与任务相关的提示模板和回答词空间,将下游任务重新规划为PLM培训任务。因而,本文将提示学习融入了下游API推荐任务。
发明内容
本发明的目的在于提供一种基于提示学习和双信息源融合的API推荐方法,该方法基于提示学习对API推荐列表进行重排序,并结合SO网站问答帖子和API参考文档双信息源进行API推荐,提高推荐的准确性。
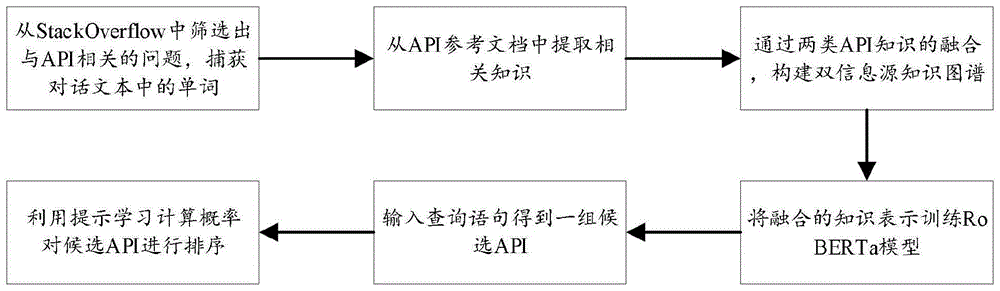
为解决上述技术问题,本发明的实施提供一种基于提示学习和双信息源融合的API推荐方法,包括如下步骤:
S1、从StackOverflow中筛选出与API相关的问题,捕获对话文本中的单词;
S2、从API参考文档中提取相关信息;
S3、通过两类API知识的融合,构建基于启发式方法的API与问答QA的关系;
S4、将融合的知识表示训练最新的句子嵌入模型,得到BERT变体模型RoBERTa;
S5、输入查询语句得到一组候选API;
S6、利用提示学习计算概率对候选API进行重排序,完成API推荐。
其中,对SO问答网站标签为Java的问答进行知识的表示及获取,步骤S1包括如下步骤:
S1.1、获取SO问答网站中涉及的API相关的问题;
S1.2、删除HTML标签中包含的长代码片段;
S1.3、通过自然语言处理工具包(NLTK)包将解析后的文本拆分成单词;
S1.4、基于上述文本解析与单词拆分,形成单词语料库;
S1.5、通过训练词嵌入(word2vec)模型来学习单词嵌入。
其中,从API参考文档中提取相关实体信息和关系,步骤S2包括如下步骤:
S2.1、API参考文档提供所有API的功能描述及其相关属性信息,主要选用PyTorch框架的API参考文档,进行知识表示和获取;
S2.2、对文本进行词法和句子结构分析;
S2.3、根据类的声明规则,采用正则表达式提取类和基类之间的继承关系,实现API实体及关系的识别和提取;
S2.4、使用文档数据库将抽取出的实体信息和关系进行存储。
其中,建立单词和实体之间的关联,步骤S3包括如下步骤:
S3.1、加载词向量和文档数据库存储的API实体和关系信息到内存中进行处理;
S3.2、使用启发式方法构建问题-回答模型;
S3.3、通过解析HTML的标签,识别问答QA提及API的模块或类;
S3.4、通过制定正则表达式识别代码模块或类确定其API;
S3.5、当识别了无歧义的API后,便可在问答QA和API之间建立“提及”的关联联系。
其中,步骤S4包括如下步骤:
S4.1、根据RoBERTa模型的输入要求,为每个问题-答案对构建输入序列,其中问题部分包含Stack Overflow网站的单词信息的表示,而答案部分包含融合的API文档实体信息的表示。
S4.2、对步骤S4.1中的输入序列进行编码,转换为词向量;
S4.3、使用融合的API知识作为训练数据,然后,使用RoBERTa模型的预训练权重作为起点,让模型学习API相关的语义信息。
其中,对查询语句进行推理,从API知识库中检索出与查询相关的候选API,步骤S5包括如下步骤:
S5.1、给定一个自然语言描述的查询Q,第一步是从SO网站中检索前k个候选问题;
S5.2、通过训练过的RoBERTa模型将其转换成句子嵌入,得到候选API列表;
S5.3、通过RoBERTa模型的输出,获取每个API提及的相关性得分并进行排序。
其中,步骤S6包括如下步骤:
S6.1、准备一个训练数据集,包括候选API列表、查询语句Q和相关性标签,每个样本表示一个查询语句和对应的候选API列表,以及每个候选API与查询的相关性标签;
S6.2、为查询语句和候选API提取特征表示,使用词向量模型将查询语句和API转换为向量表示,确保查询语句和候选API的特征表述具有一致的维度;
S6.3、选择RoBERTa模型进行提示学习,输入查询语句和候选API的特征表示,并输出一个代表相关性的分数;
S6.4、提示模板T(·)作为提示学习框架(promptAPIRec)的核心组件,将输入数据(
x
其中,x
S6.5、设计了提示模板,捕捉查询语句和候选帖子之间的匹配信号;
S6.6、给定一组候选API列表和对应的查询语句query,它们对应一个真实的标签y∈{0,1},反映用户是否选择该候选API,设计一个标签词映射verbalizer v(·);
S6.7、使用训练好的模型,对新的问题和候选API进行特征提取,并计算每个API的概率;根据概率对API进行排序,以便根据模型预测的可能性提供合理的候选API排序,完成API推荐。
附图说明
图1为本发明的流程图;
图2为API推荐整体的流程图;
图3为基于提示学习范式的框架思想;
图4为本发明提示学习promptAPIRec框架的流程图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
如图1-图3所示,本发明提供一种基于提示学习和双信息源融合的API推荐方法,包括如下步骤:
S1、从StackOverflow中筛选出与API相关的问题,捕获对话文本中单词,包括如下步骤:
S1.1、下载SO网站的官方转储数据,抽取了1347908个带有“Java”标签的问题;
S1.2、使用正则表达式,匹配HTML标签、特殊字符、链接等非文本内容,将其删除。
S1.3、移除常见的停用词,例如“the”、“is”等;
S1.3.1、获取SO网站的文本,清除干扰词;
S1.3.2、获取词频;
S1.3.3、去除停用词。
S1.4、基于步骤S1.1的这些问题及其答案,经过S1.2-S1.3处理后,使用纯文本构建了一个文本预料库来训练单词嵌入模型;
S1.4.1、使用python工具包Gensim库,通过训练Word2vec模型来学习单词嵌入;
S1.4.2、设置Word2vec模型的词向量维度为100,窗口大小为5,最小词频为5,将训练好的词向量保存到名为“word_word2vec.txt”的文本文件中,每一行为一个词向量,以词汇及其对应的100维向量表示。
S2、API参考文档属于半结构化数据,不同的HTML标签表示不同类型的API实体,API标签下含有API实体的属性信息,如功能描述、参数、返回值和返回值类型等。因此从API参考文档中提取相关信息,包括如下步骤:
S2.1、打开并下载JavaAPI在线文档;
S2.2、使用词法分析器(tokenizer)将文本分解为单词或标记;
S2.3、然后用句法分析器(parser)将句子结构进行分析,识别出名词、动词、形容词等语法分析;
S2.4、使用训练好的实体识别模型,如条件随机场(CRF)对文本进行实体识别,有助于准确地识别和标记API文档中的实体;
S2.5、实体被识别后,为了进一步识别实体的属性,定义“参数名+类型”这样的模式来提取出参数的数据类型属性。
S2.6、根据API文档中的上下文信息,识别并抽取API实体之间的关系;
S2.6.1、准备未标注的JavaAPI文档数据;
S2.6.2、使用词频-逆文本频率(TF-IDF)方法提取每个文档的文本表示,即先将文档进行分词,拆分为独立的词语或单词,然后计算每个词语在该文档中出现的频率,接着计算每个词语的逆文档频率,具体公式如式(2)所示,从而得到TF-IDF值。
IDF=log(N/DF)(2);
其中,N是API文档的总数,DF是包含该词语的文档数量;
S2.7、使用文档数据库将抽取出的实体信息和关系进行存储。
S3、通过两类API知识的融合,构建基于启发式方法的API与问答QA的关系,包括如下步骤:
S3.1、加载词向量,使用Gensim库中的Word2Vec模块将步骤S1.4.2中的名为“word_word2vec.txt”的文本文件加载到内存中并使用;
S3.2、从文档数据库中提取存储的API实体和关系信息,并将其加载到内存中进行处理;
S3.2.1、连接数据库;
S3.2.2、执行查询;
S3.2.3、获取查询结果;
S3.2.4、将数据加载到内存,使用列表来保存API实体和关系的信息。
S3.3、构建问题-回答模型,使用启发式方法构建API与问答QA的关系;
S3.3.1、SO问答中的代码元素出现有局限性,即同一问答出现的API通常属于同一模块或类。通过制定正则表达式识别代码块中的模块或类确定其API。当识别了无歧义的API后,便可以在问答QA和API之间建立“提及”的关联关系。
S4、将融合的知识表示训练RoBERTa模型,包括如下步骤:
S4.1、对数据进行预处理以适应RoBERTa模型的输入格式;
S4.1.1、将文本数据标记化为单词或子词单元;
S4.1.2、在标记化的文本中添加特殊的标记,以便模型可以识别句子的开始和结束。比如在每个输入序列开头添加’[cls]’标记,并在问题和答案之间添加一个分隔标记,如’[SEP]’;
S4.1.3、将长文本分为多个较短的片段,并在每个片段的开头添加一个分隔标记;
S4.1.4、将标记化后的文本转换为对应的索引表示。
S4.2、使用Roberta模型的预训练权重作为起点,采用Pytorch深度学习框架,将问题、答案和API提及之间的关联信息作为输入,构建一个问题-提及关联的模型结构;
S4.2.1、使用’RobertaModel.from_pretrained(‘roberta-base’)’加载RoBERTa模型的预训练权重,然后再RoBERTa模型之上添加了一个’Dropout’层和一个全连接层作为分类器,最后通过’forward’方法定义了模型的前向传播过程。
S4.3、定义二元交叉熵损失函数来衡量模型预测与真实关联之间的差异;
S4.3.1、如果问题和答案对应的API提及是正确的,那么它们被认为是正例;如果不是正确的API提及,那它们被认为是负例。
S4.4、训练过程中,将数据馈送到模型中,通过反向传播更新模型的权重,选择Adam自适应学习率的优化算法,使用’torch.optim.Adam’来实现,当epoch=40为降低学习率,使用torch.optim.lr_scheduler.StepLR来实现。
S5、输入查询语句得到一组候选API,包括如下步骤:
S5.1、提供一个查询语句作为输入,对查询语句进行与训练数据相同的预处理步骤,见步骤S4.1;
S5.2、将预处理后的查询语句输入传递给经过训练的Roberta模型进行推理;
S5.3、通过模型的输出,获取每个API提及的相关性得分;
S5.4、根据相关性得分对API进行排序,并选择前N个得分最高的API作为推荐列表。
S6、利用提示学习计算概率对候选API进行重排序,包括如下步骤:
S6.1、图4是提示学习prompAPIRec的整体框架图,它包含三个主要模块:(1)数据格式转换;(2)提示模板;(3)答案预测;
S6.2、给定一组候选API列表和一个查询语句query,我们将它们转换成自然语言句子,以适应之后的提示学习范式,分别表示为
其中,
S6.3、提示模板T(·)作为提示学习框架promptAPIRec的核心组件,将输入数据(
x
其中,x
设计的两个提示模板,分别为
S6.4、给定一组候选API列表和对应的查询语句query,它们对应一个真实的标签y∈{0,1},反映用户是否选择该候选API,设计了一个verbalizerv(·)将标签映射到PLM对应的两个候选区间,如式(4)所示;
其中,pos表示用户选择的正确的API,neg表示未被用户选择的API;
概率计算公式如式(5)所示:
P(y|candidate,query)=P
其中,P
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种基于学习者模型的学习资源智能推荐方法
- 一种基于提示学习和数据增强的API补全方法
- 一种基于提示学习的API误用缺陷修复方法