一种利用机器听觉检测扬声器状态的方法和系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于机器听觉检测技术领域,具体涉及一种利用机器听觉检测扬声器状态的方法和系统。
背景技术
机器听觉是指机器通过模拟人类听觉系统,实现对声音和音频信号的感知和理解能力,它可以用于语音识别、语音合成、音频分析等领域,在语音识别方面,机器听觉可以将语音信号转换为文本,使得机器可以理解和处理语音信息,这在语音助手、语音识别软件和智能音箱等应用中得到广泛应用,另外,机器听觉也可以用于语音合成,通过分析文本,机器可以生成自然流畅的语音输出,实现与人类的交互,此外,机器听觉还可以进行音频分析,如声音分类、声音增强、音乐分析等,通过对音频信号的处理和分析,机器可以提取有用的信息,并作出相应的响应或决策,机器听觉技术的发展为人机交互、语音识别和语音合成等领域带来了巨大的进步,为我们的生活带来了更多的便利和可能性;
现有的机器听觉检测系统对于扬声器状态的检测时对于噪音去除的方式较为单一,在不同工作场景下不便于消除干扰信号,声音信息的获取准确性较差,为此我们提出一种利用机器听觉检测扬声器状态的方法和系统来解决上述问题。
发明内容
本发明的目的是提供一种利用机器听觉检测扬声器状态的方法和系统,能够提供更准确的状态评价,提高系统的整体性能,多种去噪方式能够有效的消除干扰信号,能够提高声音信息获取的准确性。
本发明采取的技术方案具体如下:
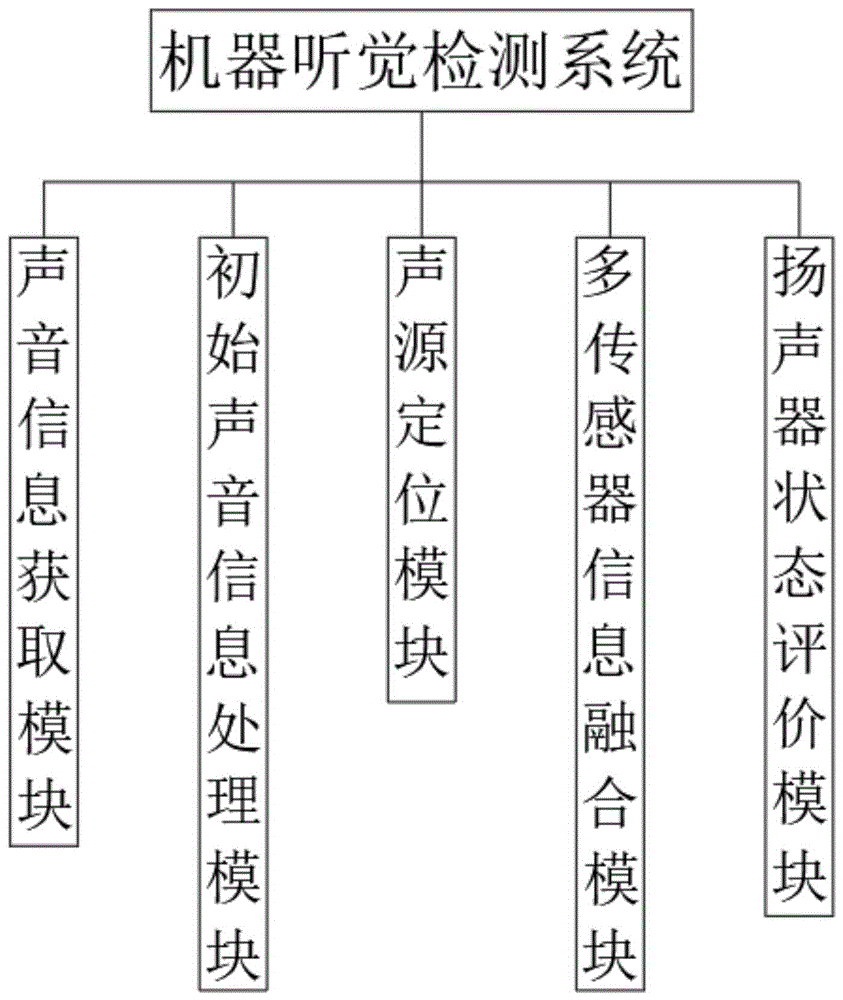
一种利用机器听觉检测扬声器状态的方法和系统,所述机器听觉检测系统包括声音信息获取模块、初始声音信息处理模块、声源定位模块、多传感器信息融合模块、扬声器状态评价模块。
在一种优选方案中,所述声音信息获取模块为仿造人耳的听觉系统,将多个传声器组成的阵列作为机器人的“双耳”对声音信息进行处理,所述传声器阵列是由多个传声器构成一定几何形状而组成的阵列,所述传声器阵列具有很强的空间选择性,同时还可以在一定的范围内实现声源的自适应检测定位及跟踪,所述传声器阵列的构建包括阵元间距、阵元个数和采用的麦克风类型。
在一种优选方案中,所述初始声音信息处理模块运行包括声音信号的放大、滤波、模/数转换、去噪,由于麦克风的拾音范围有限,当声源距离麦克风较远时,麦克风采集到的信号很小,因此,有必要对麦克风采集到的模拟信号进行放大,滤波是将系统采集到的原始信号进行格式转换,并将不感兴趣的频段信号加以滤除,为后续算法处理提供理想的数字信号,由于初始声音信号中包括了背景噪声和回声等干扰,影响了声源定位的精度,因此去噪问题十分重要,如果噪声信号的特性可以被单独测量,那么声音信息获取的准确性就会大大提高。
在一种优选方案中,所述声源定位模块通过传声器拾取语音信号,并采用数字信号处理技术对其进行分析和处理,继而确定和跟踪声源的空间位置。
在一种优选方案中,所述多传感器信息融合模块运行为不断接收扬声器的声波,根据声波的变化随时调整接收的方向,通过仿生学的方法,利用音频听觉、摄像头视觉和超声装置等多个传感器信息的综合来提高听觉定位的精度和鲁棒性。
在一种优选方案中,所述扬声器状态评价模块使用机器学习或信号处理技术,从预处理后的音频数据中提取有关声音的特征,使用已标记的音频数据集,训练一个机器学习模型,以识别不同状态下的扬声器声音,用另一组未标记的音频数据进行测试和验证,将这些音频数据输入已训练好的模型中,观察模型对声音状态的检测准确性,根据模型的输出,可以判断扬声器的声音是正常的还是存在问题。
在一种优选方案中,所述传声器阵列的几何结构包括直线阵、平面阵和三维阵,所述均匀直线阵列结构简单,但不适用于全向定位,所述平面阵可用于全向定位,性价比高,但不太适用于近场定位,所述三维阵包括近场模型及远场模型,所述近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元因接收信号幅度衰减的不同所带来的影响。
在一种优选方案中,一种利用机器听觉检测扬声器状态的方法和系统,所述利用机器听觉检测扬声器状态的方法包括以下步骤:
步骤1.去噪;
广义互相关法:对信号和噪声进行白化处理,增强信号中信噪比较高的频率成分,对背景噪声和回声都起到一定的抑制作用;
基于建立信号和互功率时延估计法:利用了人耳定位原理,能在很大程度上抑制回声的影响,彻底抑制背景噪声,在低信噪比环境下有较好的去噪效果;
优先效应法:原声到达后,混响经一段时延才第一次到达并且开始干扰。在这个短暂时间,信号不包含回响部分,可用来进行无回响干扰的定位计算,将小波变换引入声源定位,可以有效解决与目标声源相似的背景噪声的去除问题,实现目标声源的识别和分离;
步骤2.声源定位:基于时延估计的声源定位方法:先进行声达时间差估计,并从中获取传声器阵列中阵元间的声延迟,再利用获取的声达时间差,结合已知的传声器阵列的空间位置进一步定出声源的位置,估计时延通常采用相位数据法、广义相关法、基于自适应滤波的参数模型法、谱细化方法和相关峰插值法;空间搜索算法主要有基于目标函数搜索的算法、基于空间几何的算法和基于线性内插值的算法;
步骤3.传感器信息融合:
独立决策融合:首先听觉、视觉传感器根据各自的信息进行独立决策,然后再将各决策结果进行融合,这种方法的特点是融合过程简单,但容易丢失有用信息;
整合准测融合:首先将听觉、视觉传感器信息按照一定准则进行融合,再依据融合后的信息进行决策,这种方法定位更为准确。
本发明取得的技术效果为:通过利用传声器阵列和声源定位模块,可以准确地确定和跟踪声源的空间位置,这有助于定位扬声器的位置和方向,从而提供更准确的状态评价;
通过综合音频听觉、摄像头视觉和超声装置等多个传感器的信息,可以提高听觉定位的精度和鲁棒性,这种信息融合可以弥补单一传感器的局限性,提高系统的整体性能;
初始声音信息处理模块中的去噪步骤可以有效地减少背景噪声和回声等干扰,提高声源定位的精度,这有助于消除干扰信号,提取出目标声音,提高声音信息获取的准确性;
通过使用机器学习或信号处理技术,可以从预处理后的音频数据中提取有关声音的特征,并训练一个机器学习模型来识别不同状态下的扬声器声音,这可以帮助判断扬声器的声音是正常的还是存在问题;
根据实际需求,可以选择适当的传声器阵列结构,如直线阵、平面阵和三维阵。不同的结构具有不同的特点和适用范围,可以根据具体情况进行选择,以获得最佳的扬声器状态检测效果。
附图说明
图1是本发明的一种利用机器听觉检测扬声器状态的方法和系统组成示意图;
图2是本发明的一种利用机器听觉检测扬声器状态的方法和系统的传声器直线阵列示意图;
图3是本发明的一种利用机器听觉检测扬声器状态的方法和系统的传声器平面阵列示意图;
图4是本发明的一种利用机器听觉检测扬声器状态的方法和系统的传声器三维阵列示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个较佳的实施方式中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
再其次,本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
实施例一
请参阅图1-4所示,本发明提供了一种利用机器听觉检测扬声器状态的方法和系统,机器听觉检测系统包括声音信息获取模块、初始声音信息处理模块、声源定位模块、多传感器信息融合模块、扬声器状态评价模块,声音信息获取模块为仿造人耳的听觉系统,将多个传声器组成的阵列作为机器人的“双耳”对声音信息进行处理,传声器阵列是由多个传声器构成一定几何形状而组成的阵列,传声器阵列具有很强的空间选择性,同时还可以在一定的范围内实现声源的自适应检测定位及跟踪,传声器阵列的构建包括阵元间距、阵元个数和采用的麦克风类型,初始声音信息处理模块运行包括声音信号的放大、滤波、模/数转换、去噪,由于麦克风的拾音范围有限,当声源距离麦克风较远时,麦克风采集到的信号很小,因此,有必要对麦克风采集到的模拟信号进行放大,滤波是将系统采集到的原始信号进行格式转换,并将不感兴趣的频段信号加以滤除,为后续算法处理提供理想的数字信号,由于初始声音信号中包括了背景噪声和回声等干扰,影响了声源定位的精度,因此去噪问题十分重要,如果噪声信号的特性可以被单独测量,那么声音信息获取的准确性就会大大提高;
声源定位模块通过传声器拾取语音信号,并采用数字信号处理技术对其进行分析和处理,继而确定和跟踪声源的空间位置,多传感器信息融合模块运行为不断接收扬声器的声波,根据声波的变化随时调整接收的方向,通过仿生学的方法,利用音频听觉、摄像头视觉和超声装置等多个传感器信息的综合来提高听觉定位的精度和鲁棒性,扬声器状态评价模块使用机器学习或信号处理技术,从预处理后的音频数据中提取有关声音的特征,使用已标记的音频数据集,训练一个机器学习模型,以识别不同状态下的扬声器声音,用另一组未标记的音频数据进行测试和验证,将这些音频数据输入已训练好的模型中,观察模型对声音状态的检测准确性,根据模型的输出,可以判断扬声器的声音是正常的还是存在问题,传声器阵列的几何结构包括直线阵、平面阵和三维阵,均匀直线阵列结构简单,但不适用于全向定位,平面阵可用于全向定位,性价比高,但不太适用于近场定位,三维阵包括近场模型及远场模型,近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元因接收信号幅度衰减的不同所带来的影响;
一种利用机器听觉检测扬声器状态的方法和系统,利用机器听觉检测扬声器状态的方法包括以下步骤:
步骤1.去噪;
广义互相关法:对信号和噪声进行白化处理,增强信号中信噪比较高的频率成分,对背景噪声和回声都起到一定的抑制作用;
步骤2.声源定位:基于时延估计的声源定位方法:先进行声达时间差估计,并从中获取传声器阵列中阵元间的声延迟,再利用获取的声达时间差,结合已知的传声器阵列的空间位置进一步定出声源的位置,估计时延通常采用相位数据法、广义相关法、基于自适应滤波的参数模型法、谱细化方法和相关峰插值法;空间搜索算法主要有基于目标函数搜索的算法、基于空间几何的算法和基于线性内插值的算法;
步骤3.传感器信息融合:
独立决策融合:首先听觉、视觉传感器根据各自的信息进行独立决策,然后再将各决策结果进行融合,这种方法的特点是融合过程简单,但容易丢失有用信息;
整合准测融合:首先将听觉、视觉传感器信息按照一定准则进行融合,再依据融合后的信息进行决策,这种方法定位更为准确。
实施例二
请参阅图1-4所示,本发明提供了一种利用机器听觉检测扬声器状态的方法和系统,机器听觉检测系统包括声音信息获取模块、初始声音信息处理模块、声源定位模块、多传感器信息融合模块、扬声器状态评价模块,声音信息获取模块为仿造人耳的听觉系统,将多个传声器组成的阵列作为机器人的“双耳”对声音信息进行处理,传声器阵列是由多个传声器构成一定几何形状而组成的阵列,传声器阵列具有很强的空间选择性,同时还可以在一定的范围内实现声源的自适应检测定位及跟踪,传声器阵列的构建包括阵元间距、阵元个数和采用的麦克风类型,初始声音信息处理模块运行包括声音信号的放大、滤波、模/数转换、去噪,由于麦克风的拾音范围有限,当声源距离麦克风较远时,麦克风采集到的信号很小,因此,有必要对麦克风采集到的模拟信号进行放大,滤波是将系统采集到的原始信号进行格式转换,并将不感兴趣的频段信号加以滤除,为后续算法处理提供理想的数字信号,由于初始声音信号中包括了背景噪声和回声等干扰,影响了声源定位的精度,因此去噪问题十分重要,如果噪声信号的特性可以被单独测量,那么声音信息获取的准确性就会大大提高;
声源定位模块通过传声器拾取语音信号,并采用数字信号处理技术对其进行分析和处理,继而确定和跟踪声源的空间位置,多传感器信息融合模块运行为不断接收扬声器的声波,根据声波的变化随时调整接收的方向,通过仿生学的方法,利用音频听觉、摄像头视觉和超声装置等多个传感器信息的综合来提高听觉定位的精度和鲁棒性,扬声器状态评价模块使用机器学习或信号处理技术,从预处理后的音频数据中提取有关声音的特征,使用已标记的音频数据集,训练一个机器学习模型,以识别不同状态下的扬声器声音,用另一组未标记的音频数据进行测试和验证,将这些音频数据输入已训练好的模型中,观察模型对声音状态的检测准确性,根据模型的输出,可以判断扬声器的声音是正常的还是存在问题,传声器阵列的几何结构包括直线阵、平面阵和三维阵,均匀直线阵列结构简单,但不适用于全向定位,平面阵可用于全向定位,性价比高,但不太适用于近场定位,三维阵包括近场模型及远场模型,近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元因接收信号幅度衰减的不同所带来的影响;
一种利用机器听觉检测扬声器状态的方法和系统,利用机器听觉检测扬声器状态的方法包括以下步骤:
步骤1.去噪;
基于建立信号和互功率时延估计法:利用了人耳定位原理,能在很大程度上抑制回声的影响,彻底抑制背景噪声,在低信噪比环境下有较好的去噪效果;
步骤2.声源定位:基于时延估计的声源定位方法:先进行声达时间差估计,并从中获取传声器阵列中阵元间的声延迟,再利用获取的声达时间差,结合已知的传声器阵列的空间位置进一步定出声源的位置,估计时延通常采用相位数据法、广义相关法、基于自适应滤波的参数模型法、谱细化方法和相关峰插值法;空间搜索算法主要有基于目标函数搜索的算法、基于空间几何的算法和基于线性内插值的算法;
步骤3.传感器信息融合:
独立决策融合:首先听觉、视觉传感器根据各自的信息进行独立决策,然后再将各决策结果进行融合,这种方法的特点是融合过程简单,但容易丢失有用信息;
整合准测融合:首先将听觉、视觉传感器信息按照一定准则进行融合,再依据融合后的信息进行决策,这种方法定位更为准确。
实施例三
请参阅图1-4所示,本发明提供了一种利用机器听觉检测扬声器状态的方法和系统,机器听觉检测系统包括声音信息获取模块、初始声音信息处理模块、声源定位模块、多传感器信息融合模块、扬声器状态评价模块,声音信息获取模块为仿造人耳的听觉系统,将多个传声器组成的阵列作为机器人的“双耳”对声音信息进行处理,传声器阵列是由多个传声器构成一定几何形状而组成的阵列,传声器阵列具有很强的空间选择性,同时还可以在一定的范围内实现声源的自适应检测定位及跟踪,传声器阵列的构建包括阵元间距、阵元个数和采用的麦克风类型,初始声音信息处理模块运行包括声音信号的放大、滤波、模/数转换、去噪,由于麦克风的拾音范围有限,当声源距离麦克风较远时,麦克风采集到的信号很小,因此,有必要对麦克风采集到的模拟信号进行放大,滤波是将系统采集到的原始信号进行格式转换,并将不感兴趣的频段信号加以滤除,为后续算法处理提供理想的数字信号,由于初始声音信号中包括了背景噪声和回声等干扰,影响了声源定位的精度,因此去噪问题十分重要,如果噪声信号的特性可以被单独测量,那么声音信息获取的准确性就会大大提高;
声源定位模块通过传声器拾取语音信号,并采用数字信号处理技术对其进行分析和处理,继而确定和跟踪声源的空间位置,多传感器信息融合模块运行为不断接收扬声器的声波,根据声波的变化随时调整接收的方向,通过仿生学的方法,利用音频听觉、摄像头视觉和超声装置等多个传感器信息的综合来提高听觉定位的精度和鲁棒性,扬声器状态评价模块使用机器学习或信号处理技术,从预处理后的音频数据中提取有关声音的特征,使用已标记的音频数据集,训练一个机器学习模型,以识别不同状态下的扬声器声音,用另一组未标记的音频数据进行测试和验证,将这些音频数据输入已训练好的模型中,观察模型对声音状态的检测准确性,根据模型的输出,可以判断扬声器的声音是正常的还是存在问题,传声器阵列的几何结构包括直线阵、平面阵和三维阵,均匀直线阵列结构简单,但不适用于全向定位,平面阵可用于全向定位,性价比高,但不太适用于近场定位,三维阵包括近场模型及远场模型,近场模型和远场模型最主要的区别在于是否考虑麦克风阵列各阵元因接收信号幅度衰减的不同所带来的影响;
一种利用机器听觉检测扬声器状态的方法和系统,利用机器听觉检测扬声器状态的方法包括以下步骤:
步骤1.去噪;
优先效应法:原声到达后,混响经一段时延才第一次到达并且开始干扰。在这个短暂时间,信号不包含回响部分,可用来进行无回响干扰的定位计算,将小波变换引入声源定位,可以有效解决与目标声源相似的背景噪声的去除问题,实现目标声源的识别和分离;
步骤2.声源定位:基于时延估计的声源定位方法:先进行声达时间差估计,并从中获取传声器阵列中阵元间的声延迟,再利用获取的声达时间差,结合已知的传声器阵列的空间位置进一步定出声源的位置,估计时延通常采用相位数据法、广义相关法、基于自适应滤波的参数模型法、谱细化方法和相关峰插值法;空间搜索算法主要有基于目标函数搜索的算法、基于空间几何的算法和基于线性内插值的算法;
步骤3.传感器信息融合:
独立决策融合:首先听觉、视觉传感器根据各自的信息进行独立决策,然后再将各决策结果进行融合,这种方法的特点是融合过程简单,但容易丢失有用信息;
整合准测融合:首先将听觉、视觉传感器信息按照一定准则进行融合,再依据融合后的信息进行决策,这种方法定位更为准确。
本发明中通过利用传声器阵列和声源定位模块,可以准确地确定和跟踪声源的空间位置,这有助于定位扬声器的位置和方向,从而提供更准确的状态评价,通过综合音频听觉、摄像头视觉和超声装置等多个传感器的信息,可以提高听觉定位的精度和鲁棒性,这种信息融合可以弥补单一传感器的局限性,提高系统的整体性能,初始声音信息处理模块中的去噪步骤可以有效地减少背景噪声和回声等干扰,提高声源定位的精度,这有助于消除干扰信号,提取出目标声音,提高声音信息获取的准确性,通过使用机器学习或信号处理技术,可以从预处理后的音频数据中提取有关声音的特征,并训练一个机器学习模型来识别不同状态下的扬声器声音,这可以帮助判断扬声器的声音是正常的还是存在问题,根据实际需求,可以选择适当的传声器阵列结构,如直线阵、平面阵和三维阵。不同的结构具有不同的特点和适用范围,可以根据具体情况进行选择,以获得最佳的扬声器状态检测效果。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本发明中未具体描述和解释说明的结构、装置以及操作方法,如无特别说明和限定,均按照本领域的常规手段实施。
- 一种车载扬声器工作状态检测电路和方法
- 一种机器人控制系统、机器人运动状态监控方法及机器人
- 一种机器人控制系统、机器人异常信号检测方法及机器人
- 一种用于检测用户睡眠状态的检测系统及检测方法
- 一种基于扬声器阵列的虚拟听觉环境可听化实现方法及系统
- 一种基于扬声器阵列的虚拟听觉环境可听化实现方法及系统