一种基于任务的集群自动化控制方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及信息技术领域,尤其涉及一种基于任务的集群自动化控制方法。
背景技术
随着任务量的增加和集群内机器数量的增加,任务执行的效率和能耗管理成为了一个迫切需要解决的问题。现有任务调度方法往往无法根据任务类型和执行要求来确定任务的优先级,导致任务执行顺序混乱,影响整个系统的性能。由于忽略了任务的类型和执行要求,现有任务调度方法无法准确评估任务的关键性和紧急程度。结果是任务执行顺序混乱,可能导致任务之间的冲突和资源浪费。某些类型的任务可能需要更多的计算资源,但由于优先级低,却被在资源分配上被忽视,导致任务执行效率低下。另一方面,某些任务可能对存储资源有更高的需求,但由于调度方法无法识别这些差异,任务可能被分配到不合适的节点上,导致数据传输延迟和能耗浪费。不同类型的任务可能对硬件资源的要求有所不同,如果在节点管理过程中没有考虑到这些要求,这导致任务在执行过程中可能无法得到最优的硬件支持,影响了任务的执行效率和能耗消耗。同时,由于集群节点的负载不均衡,一些节点可能会出现阻塞现象,严重影响任务的执行效率。这导致在某些情况下存在阻塞节点的问题,影响了整个系统的性能和能耗。此外,由于每个节点的硬件配置不同,执行同样任务的节点的能耗也会存在差异。在现实情况下,节点的能耗水平是随着任务的执行而变化的,而现有方法未对此进行考虑。因此,当选择节点执行任务时,不能准确地预测节点的实际能耗情况,从而导致无法选择最佳节点来执行任务,进一步影响了整个系统的能耗效率。最后,系统无法根据任务的变动性来动态调整节点的配置,无法实现任务的优化执行和负载均衡控制。由于任务的特性和执行要求可能会随时间发生变化,现有方法未能实现对节点配置的动态调整。这会导致任务可能被分配给不适合的节点,从而影响任务的执行效率和负载均衡控制。
发明内容
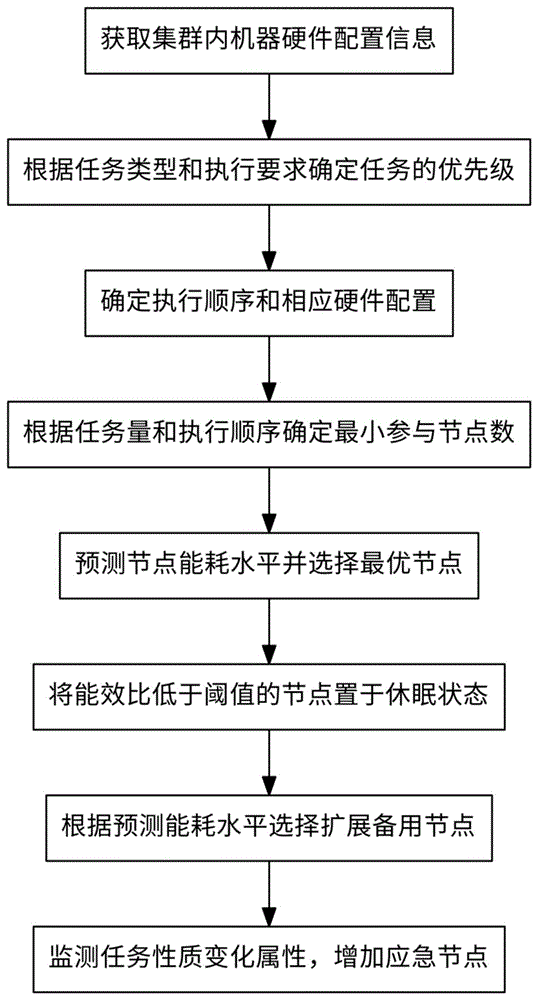
本发明提供了一种基于任务的集群自动化控制方法,主要包括:
获取集群内机器的硬件配置信息,根据任务类型和执行要求确定任务的优先级,并确定执行顺序和相应的硬件配置;根据任务量和所述执行顺序和相应的硬件配置,判断最少需要多少集群节点参与,得到最小参与节点数;基于所述最小参与节点数,预测节点的能耗水平,选择满足计算需求且能耗最低的节点进行执行,将能效比低于能效比阈值的节点置于休眠状态,得到节点执行策略;根据预测的节点能耗水平,将预测能耗水平更高的节点选为扩展备用节点,得到扩展备用节点;监测任务的性质变化属性,判断何时需要加入所述扩展备用节点;基于所述节点执行策略,分析系统中的阻塞节点情况,确定阻塞的原因和位置,并根据需要增加应急节点;基于所述节点执行策略,动态调整节点配置,优化执行效率和降低能耗;根据系统运行结果,判断任务是否达到满足计算需求且降低能耗的目标,并对整个系统进行优化和迭代。
进一步地,所述获取集群内机器的硬件配置信息,根据任务类型和执行要求确定任务的优先级,并确定执行顺序和相应的硬件配置,包括:
通过集群管理系统,确定集群内可用的机器的列表;遍历机器列表,获取每台机器的硬件配置信息并记录,包括CPU信息、内存信息、存储信息、网络信息、GPU信息和特殊硬件信息;将获取到的硬件配置信息整理并使用数据库存储;根据任务的类型和执行要求,确定任务的优先级,所述任务类型包括紧急任务和常规任务,所述执行要求包括截止时间、执行时长;遍历任务列表,判断每个任务所需的资源,并根据资源的可用性和任务的优先级,确定任务的执行顺序;根据任务对资源的需求程度,匹配可用的硬件配置,选择相应的机器来执行任务。
进一步地,所述根据任务量和所述执行顺序和相应的硬件配置,判断最少需要多少集群节点参与,得到最小参与节点数,包括:
根据节点的硬件配置信息,计算每个节点的权重值;将所有节点及其权重值存放在一个列表中,并按照权重值从高到低的顺序进行排序;初始化一个计数器,记录当前已经分配的任务数;当有新任务到来时,选择列表中权重值最高的节点,将任务分配给该节点;根据节点的负载情况,更新选中节点的权重值,包括执行任务后节点负载增加,权重值相应降低,负载减少则权重值相应增加;更新计数器,记录已经分配的任务数;重复任务分配和权重值更新,直到所有任务都被分配完毕;根据任务分配结果,判断最少需要多少集群节点参与,得到最小参与节点数。
进一步地,所述基于所述最小参与节点数,预测节点的能耗水平,选择满足计算需求且能耗最低的节点进行执行,将能效比低于能效比阈值的节点置于休眠状态,得到节点执行策略,包括:
收集节点负载和能耗的历史数据,采用加权轮询算法进行能耗模型的建立,根据节点负载情况,预测节点的能耗;根据节点能耗预测结果,选择预测能耗最低的节点进行任务分配;基于均值和标准差的阈值划定,确定能效比阈值,当节点能效比低于能效比阈值时,将节点置于休眠状态;利用心跳机制,检测故障节点并将任务迁移到正常节点上,得到节点执行策略;还包括:采用加权轮询算法建立能耗模型,预测节点的能耗水平。
所述采用加权轮询算法建立能耗模型,预测节点的能耗水平,具体包括:
根据节点的负载和能耗情况,收集历史数据,所述历史数据包括节点的任务执行情况、处理器利用率、内存使用情况、能源消耗信息。根据历史数据,提取节点的属性特征,所述节点的属性特征包括负载水平、能源利用效率、节点类型和环境因素。采用加权轮询算法,根据节点的属性特征作为输入,能耗水平作为输出,建立能耗预测模型。通过训练模型来学习节点属性特征与能耗水平之间的关系,实现对未来节点能耗的预测。使用收集的历史数据中的一部分作为训练集,将模型应用于剩余的数据作为测试集,通过评估模型预测的能耗水平与实际能耗水平的差异来验证模型的准确性。根据节点的实时负载和环境因素数据,通过模型预测节点的能耗水平。通过实时监控节点的能耗情况,将节点的实际能耗与预测结果进行分析,发现和解决能耗异常问题。根据节点的实际使用情况和反馈信息,持续改进和优化能耗预测模型和能源管理策略。
进一步地,所述根据预测的节点能耗水平,将预测能耗水平更高的节点选为扩展备用节点,得到扩展备用节点,包括:
根据节点的当前负载情况,判断扩展备用节点的可用性和适合性,所述负载情况包括节点的CPU使用率、内存使用率和磁盘IO指标;获取节点的能源供应情况,判断扩展备用节点的能源供应是否稳定或有限,确定节点能否作为备用节点,所述节点的能源供应情况包括稳定性和可用性;在主节点故障或负载超出负载阈值的情况下接管任务,确保任务的连续性和集群的稳定性。
进一步地,所述监测任务的性质变化属性,判断何时需要加入所述扩展备用节点,包括:
通过Zabbix,获取负载变化数据;将负载变化数据作为加权轮询建立的能耗模型的输入,得到在不同负载下节点的能耗变化情况;根据瞬时负载和长期负载的差异,判断当前系统的负载情况是否超出负载阈值;进行性能测试和能耗测试,判断加入扩展备用节点能否降低系统的能耗,同时保持性能;在当前系统负载超出负载阈值且加入扩展备用节点可降低能耗的情况下,加入扩展备用节点;通过数据迁移、任务重分配,实现集群的重新平衡。
进一步地,所述基于所述节点执行策略,分析系统中的阻塞节点情况,确定阻塞的原因和位置,并根据需要增加应急节点,包括:
使用任务管理器,分析系统性能指标,包括CPU利用率、内存使用情况,得到阻塞的导致因素;使用MTR,根据导致因素的分析结果,确定阻塞发生的位置;通过分析阻塞带来的影响,包括任务执行时间的影响、系统吞吐量的下降,判断阻塞的紧急性和优先级;根据系统的需求变化,分析任务执行时间、资源利用率,评估是否需要增加应急节点,所述系统的需求变化包括系统的负载增加、任务数量增加或任务类型变化;根据需求评估的结果,通过用户反馈方式,确定需要增加的应急节点的类型和规模;根据节点之间的通信延迟和网络拓扑及应急节点的类型和规模,在系统中选取位置部署应急节点;通过配置节点的参数和负载测试方法测试节点的功能和性能,确保其正常工作并提供所需的服务;通过重新设置负载阈值,进行监控和日志分析,及时发现问题并调整配置,优化应急节点的性能和可靠性;还包括:根据系统的需求变化,评估是否需要调整应急节点。
所述根据系统的需求变化,评估是否需要调整应急节点,具体包括:
通过集群管理系统,获取节点的负载情况、任务的数量、类型和优先级属性。判断系统的任务执行时间是否延长,资源利用率是否上升,评估系统的性能是否受到影响。基于历史数据,根据系统的任务类型和需求资源,获取任务执行时间的预估值。通过监测系统的性能指标,判断系统是否在处理新任务时出现资源不足或处理能力不够情况,所述性能指标包括CPU利用率、内存使用情况、磁盘IO、网络带宽和响应时间。根据评估的结果,判断是否增加应急节点来提供额外的资源和处理能力,确定增加应急节点的数量和配置。判断增加应急节点后的效果,所述效果包括任务执行时间的缩短和资源利用率的改善。根据效果评估的结果,判断是否进一步调整应急节点的数量和配置。
进一步地,所述基于所述节点执行策略,动态调整节点配置,优化执行效率和降低能耗,包括:
根据节点的硬件和软件属性及资源监测,获取节点的可用资源情况;根据任务执行时间、吞吐量和响应时间指标,评估每个节点的执行效率;根据任务的要求和节点的能耗情况,动态确定节点配置的增加或减少、硬件或软件配置方式的调整方向;通过增加或减少节点数量、调整节点硬件或软件配置方式,优化执行效率和降低能耗;监测任务负载和节点的执行情况,判断是否需要对节点的配置进行调整;若需要,则动态调整节点配置,获取更新后的节点配置信息,进行任务分配。
进一步地,所述根据系统运行结果,判断任务是否达到满足计算需求且降低能耗的目标,并对整个系统进行优化和迭代,包括:
根据任务完成率或任务响应时间,评估任务在系统中的执行情况和计算结果的准确性,得到计算需求满足度的数据;根据系统能耗减少的百分比,评估优化前后的能耗消耗情况,并得到能耗降低度的数据;根据计算资源利用率或任务并行度,评估优化后的系统是否更好地利用了计算资源,并获得资源利用率提高的数据;根据系统处理更大规模任务时的性能变化,评估优化后的系统的扩展性,能否应对未来增加的计算需求和更大规模的任务,并获取可扩展性的数据;根据系统运行过程中的错误处理能力和故障恢复时间,评估优化后的系统的容错能力,是否保持了稳定的性能,能否应对异常情况和故障,并获得稳定性和可靠性的数据;根据系统的修改和维护难易程度,评估优化后的系统的可维护性,并获取可维护性的数据;通过对评估结果分析,判断是否对整个系统进行优化和迭代。
本发明实施例提供的技术方案可以包括以下有益效果:
本发明公开了一种基于硬件配置信息和任务优先级确定的集群节点管理方法。该方法根据任务类型和执行要求确定任务的优先级,并确定执行顺序和相应的硬件配置。然后根据执行顺序和硬件配置,计算最少需要多少集群节点参与任务执行,得到最小参与节点数。接下来根据最小参与节点数,预测节点的能耗水平,并选择满足计算需求且能耗最低的节点进行执行,并将能效比低于能效比阈值的节点置于休眠状态,得到节点执行策略。根据预测的节点能耗水平,选取能耗水平更高的节点作为扩展备用节点。监测任务的性质变化属性,判断何时需要加入扩展备用节点。根据节点执行策略,分析系统中的阻塞节点情况,确定阻塞原因和位置,并根据需要增加应急节点。根据节点执行策略,动态调整节点配置,以优化执行效率和降低能耗。根据系统运行结果,判断任务是否达到满足计算需求且降低能耗的目标,并对整个系统进行优化和迭代。通过融合以上技术,实现了集群节点管理方法的优化和提高效果。
附图说明
图1为本发明的一种基于任务的集群自动化控制方法的流程图。
图2为本发明的一种基于任务的集群自动化控制方法的示意图。
图3为本发明的一种基于任务的集群自动化控制方法的又一示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本实施例一种基于任务的集群自动化控制方法具体可以包括:
步骤S101,获取集群内机器的硬件配置信息,根据任务类型和执行要求确定任务的优先级,并确定执行顺序和相应的硬件配置。
通过集群管理系统,确定集群内可用的机器的列表。遍历机器列表,获取每台机器的硬件配置信息并记录,包括CPU信息、内存信息、存储信息、网络信息、GPU信息和特殊硬件信息。将获取到的硬件配置信息整理并使用数据库存储。根据任务的类型和执行要求,确定任务的优先级,所述任务类型包括紧急任务和常规任务,所述执行要求包括截止时间、执行时长。遍历任务列表,判断每个任务所需的资源,并根据资源的可用性和任务的优先级,确定任务的执行顺序。根据任务对资源的需求程度,匹配可用的硬件配置,选择相应的机器来执行任务。例如,遍历机器列表,集群内有3台机器,分别是机器A、机器B和机器C。获取每台机器的硬件配置信息,并记录如下,机器A的CPU型号为IntelXeonE5-2690,内存容量为64GB,存储容量为1TB,网络带宽为1Gbps,无GPU,无特殊硬件,机器B的CPU型号为IntelCorei7-9700K,内存容量为32GB,存储容量为500GB,网络带宽为500Mbps,有NVIDIAGeForceRTX2080TiGPU,无特殊硬件,机器C的CPU型号为AMDRyzen93900X,内存容量为16GB,存储容量为2TB,网络带宽为1Gbps,无GPU,有FPGA加速卡。将获取到的硬件配置信息整理并存储在数据库中。有以下任务列表,任务1为紧急任务,截止时间为今天下午3点,执行时长为1小时,任务2为常规任务,截止时间为明天上午10点,执行时长为2小时,任务3为紧急任务,截止时间为明天下午2点,执行时长为3小时。根据任务的优先级,按照优先级高低对任务列表进行排序,任务1、任务3、任务2。接下来,遍历任务列表,并判断每个任务所需的资源。任务1需要2个CPU核心、32GB内存和500GB存储空间;任务2需要4个CPU核心、16GB内存和1TB存储空间;任务3需要8个CPU核心、64GB内存和2TB存储空间。根据资源的可用性和任务的优先级,确定任务的执行顺序和所选硬件配置。根据任务对资源的需求程度,匹配可用的硬件配置,并选择相应的机器来执行任务。选择机器B来执行任务1,因为机器B拥有2个CPU核心、32GB内存和500GB存储空间,满足任务的资源需求,并且任务1是紧急任务。接着,选择机器A来执行任务3,因为机器A拥有8个CPU核心、64GB内存和1TB存储空间,满足任务的资源需求,并且任务3也是紧急任务。最后,选择机器C来执行任务2,因为机器C拥有4个CPU核心、16GB内存和2TB存储空间,满足任务的资源需求,并且任务2是常规任务。
步骤S102,根据任务量和所述执行顺序和相应的硬件配置,判断最少需要多少集群节点参与,得到最小参与节点数。
根据节点的硬件配置信息,计算每个节点的权重值。将所有节点及其权重值存放在一个列表中,并按照权重值从高到低的顺序进行排序。初始化一个计数器,记录当前已经分配的任务数。当有新任务到来时,选择列表中权重值最高的节点,将任务分配给该节点。根据节点的负载情况,更新选中节点的权重值,包括执行任务后节点负载增加,权重值相应降低,负载减少则权重值相应增加。更新计数器,记录已经分配的任务数。重复任务分配和权重值更新,直到所有任务都被分配完毕。根据任务分配结果,判断最少需要多少集群节点参与,得到最小参与节点数。例如,有以下节点的硬件配置信息,节点1的CPU核心数为4,内存大小为8GB,节点2的CPU核心数为8,内存大小为16GB,节点3的CPU核心数为6,内存大小为12GB。根据节点的硬件配置信息,可以计算节点的权重值。一种简单的计算方式是将节点的CPU核心数和内存大小相加,作为节点的权重值。节点1的权重值=4+8=12,节点2的权重值=8+16=24,节点3的权重值=6+12=18,将所有节点及其权重值存放在一个列表中,并按照权重值从高到低的顺序进行排序,节点2、节点3、节点1。接下来,初始化一个计数器,记录当前已经分配的任务数。当前已经分配了3个任务。当有新任务到来时,选择列表中权重值最高的节点,将任务分配给该节点。根据当前的列表排序,选择节点2来执行任务。根据节点的负载情况,更新选中节点的权重值。执行任务后,节点2的负载增加,权重值相应降低1个单位。更新后的节点2权重值=24-1=23,更新计数器,记录已经分配的任务数。已经分配了4个任务。重复任务分配和权重值更新的过程,直到所有任务都被分配完毕。根据任务分配结果,判断最少需要多少集群节点参与,得到最小参与节点数。所有任务都被分配给节点2执行,最少需要1个节点参与。
步骤S103,基于所述最小参与节点数,预测节点的能耗水平,选择满足计算需求且能耗最低的节点进行执行,将能效比低于能效比阈值的节点置于休眠状态,得到节点执行策略。
收集节点负载和能耗的历史数据,采用加权轮询算法进行能耗模型的建立,根据节点负载情况,预测节点的能耗。根据节点能耗预测结果,选择预测能耗最低的节点进行任务分配。基于均值和标准差的阈值划定,确定能效比阈值,当节点能效比低于能效比阈值时,将节点置于休眠状态。利用心跳机制,检测故障节点并将任务迁移到正常节点上,得到节点执行策略。例如,有一个由4个节点组成的系统,节点1、节点2、节点3和节点4。收集了节点负载和能耗的历史数据,节点1负载80%,能耗120W,节点2负载60%,能耗100W,节点3负载50%,能耗90W,节点4负载70%,能耗110W,根据这些历史数据,可以使用加权轮询算法建立能耗模型。使用节点的负载作为权重,那么节点的能耗模型可以表示为节点能耗=负载×能耗,根据这个模型,可以预测每个节点的能耗,节点1的能耗=80%×120W=96W,节点2的能耗=60%×100W=60W,节点3的能耗=50%×90W=45W,节点4的能耗
=70%×110W=77W,根据节点能耗的预测结果,可以选择预测能耗最低的节点进行任务分配。节点3的能耗最低,因此将任务分配给节点3。接下来,可以基于均值和标准差的阈值划定确定能效比阈值。计算所有节点的能效比的均值和标准差如下,能效比的均值
=(96W+60W+45W+77W)/4=65W,能效比的标准差=19.56W,将能效比的均值减去两倍的能效比的标准差作为能效比阈值,能效比阈值=25.88W,当节点的能效比低于能效比阈值时,将节点置于休眠状态。最后,可以利用心跳机制检测故障节点并将任务迁移到正常节点上,得到节点执行策略。节点2发生故障,无法正常工作。通过心跳机制,系统可以检测到节点2的故障,并将节点2上的任务迁移到其他正常节点上,如节点1、节点3或节点4。
采用加权轮询算法建立能耗模型,预测节点的能耗水平。
根据节点的负载和能耗情况,收集历史数据,所述历史数据包括节点的任务执行情况、处理器利用率、内存使用情况、能源消耗信息。根据历史数据,提取节点的属性特征,所述节点的属性特征包括负载水平、能源利用效率、节点类型和环境因素。采用加权轮询算法,根据节点的属性特征作为输入,能耗水平作为输出,建立能耗预测模型。通过训练模型来学习节点属性特征与能耗水平之间的关系,实现对未来节点能耗的预测。使用收集的历史数据中的一部分作为训练集,将模型应用于剩余的数据作为测试集,通过评估模型预测的能耗水平与实际能耗水平的差异来验证模型的准确性。根据节点的实时负载和环境因素数据,通过模型预测节点的能耗水平。通过实时监控节点的能耗情况,将节点的实际能耗与预测结果进行分析,发现和解决能耗异常问题。根据节点的实际使用情况和反馈信息,持续改进和优化能耗预测模型和能源管理策略。例如,有一个节点的负载数据如下:第1分钟50%,第2分钟70%,第3分钟60%,第4分钟80%,第5分钟75%,同时,还有该节点的能耗数据如下:第1分钟1000J,第2分钟1200J,第3分钟1100J,第4分钟1300J,第5分钟1250J,根据这些历史数据,可以计算出该节点的平均负载水平为(50%+70%+60%+80%+75%)/5=67%,平均能源利用效率为(1000J+1200J+1100J+1300J+1250J)/5=1170J。同时,还可以观察到该节点的任务执行情况良好,处理器利用率较高,内存使用情况合理,能源消耗较为稳定。基于这些属性特征,可以使用加权轮询算法建立能耗预测模型。使用负载水平和能源利用效率作为输入,能耗水平作为输出。通过训练模型,可以学习到负载水平和能源利用效率与能耗水平之间的关系。使用60%的历史数据作为训练集,剩余40%的数据作为测试集。可以使用模型来预测测试集中节点的能耗水平,并与实际能耗水平进行比较,评估模型的准确性。使用模型对第4分钟的能耗进行预测,得到预测值为1150J。而实际的能耗为1300J。通过计算差异,可以评估模型的预测误差为1300J-1150J=150J。根据模型预测的能耗水平,可以实时监控节点的能耗情况。如果实际能耗与预测结果存在较大差异,可以发现并解决可能存在的能耗异常问题。同时,根据节点的实际使用情况和反馈信息,可以持续改进和优化能耗预测模型和能源管理策略,以提高预测的准确性和实际能耗的节约效果。
步骤S104,根据预测的节点能耗水平,将预测能耗水平更高的节点选为扩展备用节点,得到扩展备用节点。
根据节点的当前负载情况,判断扩展备用节点的可用性和适合性,所述负载情况包括节点的CPU使用率、内存使用率和磁盘IO指标。获取节点的能源供应情况,判断扩展备用节点的能源供应是否稳定或有限,确定节点能否作为备用节点,所述节点的能源供应情况包括稳定性和可用性。在主节点故障或负载超出负载阈值的情况下接管任务,确保任务的连续性和集群的稳定性。例如,现有一个节点集群,包括节点A、节点B和节点C。根据节点的能耗水平数据,可以获取到节点A的能耗为10W,节点B的能耗为15W,节点C的能耗为12W。根据预测节点能耗水平选择节点执行任务,有一个任务需要执行,可以选择能耗最低的节点A来执行任务,因为它能耗最低,节约能源。然后,根据节点的当前负载情况来判断节点的可用性和适合性。节点A的CPU使用率为60%,内存使用率为80%,磁盘IO指标为50%。根据这些指标,可以评估节点A的负载情况,判断其是否适合执行任务。接下来,需要获取节点的能源供应情况,判断节点的能源供应是否稳定或有限。节点A的能源供应是稳定的且可用性高,那么它可以被作为备用节点来接管任务,以确保任务的连续性和集群的稳定性。当主节点故障时,节点A可以接管任务,以确保任务的连续性和集群的稳定性。
步骤S105,监测任务的性质变化属性,判断何时需要加入所述扩展备用节点。
通过Zabbix,获取负载变化数据。将负载变化数据作为加权轮询建立的能耗模型的输入,得到在不同负载下节点的能耗变化情况。根据瞬时负载和长期负载的差异,判断当前系统的负载情况是否超出负载阈值。进行性能测试和能耗测试,判断加入扩展备用节点能否降低系统的能耗,同时保持性能。在当前系统负载超出负载阈值且加入扩展备用节点可降低能耗的情况下,加入扩展备用节点。通过数据迁移、任务重分配,实现集群的重新平衡。例如,通过Zabbix,获取负载变化数据。有一个集群系统,其中包含3个节点。使用Zabbix监控每个节点的负载情况,并将负载数据作为加权轮询建立的能耗模型的输入,以计算每个节点在不同负载下的能耗变化情况。节点1的负载为50%,节点2的负载为70%,节点3的负载为80%。根据能耗模型计算得出,节点1的能耗为100W,节点2的能耗为150W,节点3的能耗为180W。接下来,需要判断当前系统的负载情况是否超出负载阈值。设置的负载阈值为75%。根据瞬时负载和长期负载的差异,可以比较当前负载和负载阈值的差异。当前系统的负载为80%,超出了负载阈值,表示系统负载过高。接着,进行性能测试和能耗测试,以判断加入扩展备用节点能否降低系统的能耗,同时保持性能。加入了一个扩展备用节点,并将负载均衡调整为50%、50%、50%、50%。再次使用能耗模型计算得出,每个节点的能耗均为100W,相比之前的能耗有所降低。在当前系统负载超出负载阈值且加入扩展备用节点可降低能耗的情况下,决定加入扩展备用节点。通过数据迁移和任务重分配,实现集群的重新平衡。将一部分任务从节点3迁移到扩展备用节点上,并将任务在扩展备用节点上重新分配。经过重新平衡后,每个节点的负载均衡为50%。
步骤S106,基于所述节点执行策略,分析系统中的阻塞节点情况,确定阻塞的原因和位置,并根据需要增加应急节点。
使用任务管理器,分析系统性能指标,包括CPU利用率、内存使用情况,得到阻塞的导致因素。使用MTR,根据导致因素的分析结果,确定阻塞发生的位置。通过分析阻塞带来的影响,包括任务执行时间的影响、系统吞吐量的下降,判断阻塞的紧急性和优先级。根据系统的需求变化,分析任务执行时间、资源利用率,评估是否需要增加应急节点,所述系统的需求变化包括系统的负载增加、任务数量增加或任务类型变化。根据需求评估的结果,通过用户反馈方式,确定需要增加的应急节点的类型和规模。根据节点之间的通信延迟和网络拓扑及应急节点的类型和规模,在系统中选取位置部署应急节点。通过配置节点的参数和负载测试方法测试节点的功能和性能,确保其正常工作并提供所需的服务。通过重新设置负载阈值,进行监控和日志分析,及时发现问题并调整配置,优化应急节点的性能和可靠性。例如,要对一个电商系统进行性能分析。首先,可以使用任务管理器来监测系统的CPU利用率和内存使用情况。分析发现CPU利用率达到80%,而内存使用率达到90%,这表明系统存在性能瓶颈。接下来,需要确定阻塞的导致因素。通过进一步分析,发现磁盘IO操作过多导致了CPU和内存的资源竞争,从而导致了系统的阻塞。根据导致因素的分析结果,可以确定阻塞发生在磁盘IO操作的位置。可能是某个数据库查询或文件读写操作导致了阻塞。接下来,分析阻塞带来的影响。任务执行时间由于阻塞的存在增加了50%,系统吞吐量下降了30%。根据系统的需求变化,评估是否需要增加应急节点。系统的负载增加了50%,任务数量增加了20%。通过分析任务执行时间和资源利用率,得出结论需要增加两个应急节点。通过用户反馈方式,确定需要增加的应急节点的类型和规模。用户反馈称系统响应速度下降,因此决定增加两个高性能的数据库节点。根据节点之间的通信延迟和网络拓扑,决定在系统中选取合适的位置部署应急节点。然后,配置节点的参数并进行负载测试,以确保它们能够正常工作并提供所需的服务。测试节点的吞吐量和响应时间,确保它们满足系统的需求。最后,重新设置负载阈值,进行监控和日志分析,以便及时发现问题并进行配置调整,优化应急节点的性能和可靠性。设置CPU利用率阈值为70%,一旦超过该值就触发警报。
根据系统的需求变化,评估是否需要调整应急节点。
具体来说,通过集群管理系统,获取节点的负载情况、任务的数量、类型和优先级属性,例如获取到节点1的负载为80%,节点2的负载为60%。同时获取到集群中共有100个任务,其中有30个是类型A的任务,40个是类型B的任务,30个是类型C的任务。根据历史数据,类型A的任务平均执行时间为10秒,类型B的任务平均执行时间为8秒,类型C的任务平均执行时间为12秒。通过监测系统的性能指标,CPU利用率为90%,内存使用率为70%,磁盘IO为100MB/s,网络带宽为500Mbps,平均响应时间为300ms。根据这些性能指标,可以判断系统资源利用率较高,但响应时间较长。根据评估的结果,如果发现系统执行新任务时出现资源不足或处理能力不够的情况,可以考虑增加应急节点来提供额外的资源和处理能力。增加2个应急节点,并配置每个节点的CPU为8核,内存为16GB。增加应急节点后,重新评估系统的性能指标。任务执行时间缩短为类型A任务平均执行时间为8秒,类型B任务平均执行时间为6秒,类型C任务平均执行时间为10秒。同时,CPU利用率下降为70%,内存使用率下降为50%,磁盘IO为80MB/s,网络带宽为600Mbps,平均响应时间为200ms。根据效果评估的结果,发现增加应急节点后,任务执行时间得到了缩短,资源利用率也得到了改善。可以进一步判断是否需要调整应急节点的数量和配置,根据实际情况进行调整。如果发现任务执行时间仍然较长,可以再增加1个应急节点并调整配置,继续评估系统的性能指标,直到达到预期的性能改善效果。通过集群管理系统,获取节点的负载情况、任务的数量、类型和优先级属性,例如获取到节点1的负载为80%,节点2的负载为60%。同时获取到集群中共有100个任务,其中有30个是类型A的任务,40个是类型B的任务,30个是类型C的任务。根据历史数据,类型A的任务平均执行时间为10秒,类型B的任务平均执行时间为8秒,类型C的任务平均执行时间为12秒。通过监测系统的性能指标,CPU利用率为90%,内存使用率为70%,磁盘IO为100MB/s,网络带宽为500Mbps,平均响应时间为300ms。根据这些性能指标,可以判断系统资源利用率较高,但响应时间较长。根据评估的结果,如果发现系统执行新任务时出现资源不足或处理能力不够的情况,可以考虑增加应急节点来提供额外的资源和处理能力。增加2个应急节点,并配置每个节点的CPU为8核,内存为16GB。增加应急节点后,重新评估系统的性能指标。任务执行时间缩短为类型A任务平均执行时间为8秒,类型B任务平均执行时间为6秒,类型C任务平均执行时间为10秒。同时,CPU利用率下降为70%,内存使用率下降为50%,磁盘IO为80MB/s,网络带宽为600Mbps,平均响应时间为200ms。根据效果评估的结果,发现增加应急节点后,任务执行时间得到了缩短,资源利用率也得到了改善。可以进一步判断是否需要调整应急节点的数量和配置,根据实际情况进行调整。如果发现任务执行时间仍然较长,可以再增加1个应急节点并调整配置,继续评估系统的性能指标,直到达到预期的性能改善效果。
步骤S107,基于所述节点执行策略,动态调整节点配置,优化执行效率和降低能耗。
根据节点的硬件和软件属性及资源监测,获取节点的可用资源情况。根据任务执行时间、吞吐量和响应时间指标,评估每个节点的执行效率。根据任务的要求和节点的能耗情况,动态确定节点配置的增加或减少、硬件或软件配置方式的调整方向。通过增加或减少节点数量、调整节点硬件或软件配置方式,优化执行效率和降低能耗。监测任务负载和节点的执行情况,判断是否需要对节点的配置进行调整。若需要,则动态调整节点配置,获取更新后的节点配置信息,进行任务分配。例如,有一个云计算集群,包括5个节点,每个节点的硬件和软件配置如下,节点1CPU核心数4个,内存大小8GB,硬盘空间500GB,操作系统Linux,节点2CPU核心数8个,内存大小16GB,硬盘空间1TB,操作系统Windows,节点3CPU核心数8个,内存大小16GB,硬盘空间1TB,操作系统Linux,节点4CPU核心数4个,内存大小8GB,硬盘空间500GB,操作系统Windows,节点5CPU核心数8个,内存大小16GB,硬盘空间1TB,操作系统Linux。任务1需要占用2个CPU核心、4GB内存和100GB硬盘空间,在Linux操作系统下运行,执行时间为1小时,任务2需要占用4个CPU核心、8GB内存和200GB硬盘空间,在Windows操作系统下运行,执行时间为2小时,任务3需要占用2个CPU核心、4GB内存和100GB硬盘空间,在Linux操作系统下运行,执行时间为5小时。首先,根据节点的硬件和软件属性,计算每个节点的可用资源情况,节点1可用资源包括,CPU核心数为4-2=2,内存大小为8-4=4GB,硬盘空间为500-100=400GB,节点2可用资源包括,CPU核心数为8-4=4,内存大小为16-8=8GB,硬盘空间为1TB-200GB=800GB,节点3可用资源包括,CPU核心数为8-2=6,内存大小为16-4=12GB,硬盘空间为1TB-100GB=900GB,节点4可用资源包括,CPU核心数为4-4=0,内存大小为8-8=0GB,硬盘空间为500GB-0GB=500GB,节点5可用资源包括,CPU核心数为8-2=6,内存大小为16-4=12GB,硬盘空间为1TB-100GB=900GB。根据任务执行时间、吞吐量和响应时间指标,评估每个节点的执行效率。节点1执行任务1所需时间1小时,吞吐量为1/1=1个任务/小时,响应时间为1小时,节点2执行任务2所需时间2小时,吞吐量为1/2=0.5个任务/小时,响应时间为2小时,节点3执行任务3所需时间5小时,吞吐量为1/5=0.2个任务/小时,响应时间为5小时,节点4没有可用资源,无法执行任务,节点5执行任务2所需时间2小时,吞吐量为1/2=0.5个任务/小时,响应时间为2小时。根据任务的要求和节点的能耗情况,动态确定节点配置的增加或减少、硬件或软件配置方式的调整方向。由于节点4没有可用资源,无法执行任务,可以考虑增加节点数量或调整节点硬件配置。节点1的硬件配置较低,可以考虑增加CPU核心数或内存大小来提高执行效率,节点2的执行效率较低,可以考虑增加CPU核心数或内存大小来提高吞吐量,节点3的硬件配置较高,可以考虑减少CPU核心数或内存大小来降低能耗。通过增加或减少节点数量、调整节点硬件或软件配置方式,优化负载均衡和降低能耗。增加一个节点6,硬件配置与节点2相同,将任务1分配给节点6执行。节点1执行任务1,节点2执行任务2,节点3执行任务3,节点5不再执行任务。通过监测任务负载和节点的执行情况,判断是否需要对节点的配置进行调整:在任务执行过程中,监测节点的负载情况和执行效率。如果节点的负载过高或执行效率低于预期,可以考虑调整节点配置。通过动态调整节点配置,获取更新后的节点配置信息,并重新确定负载均衡策略,并进行任务分配。根据节点的更新配置信息,重新评估每个节点的执行效率。根据负载均衡策略,将任务分配给执行效率高的节点执行。
步骤S108,根据系统运行结果,判断任务是否达到满足计算需求且降低能耗的目标,并对整个系统进行优化和迭代。
根据任务完成率或任务响应时间,评估任务在系统中的执行情况和计算结果的准确性,得到计算需求满足度的数据。根据系统能耗减少的百分比,评估优化前后的能耗消耗情况,并得到能耗降低度的数据。根据计算资源利用率或任务并行度,评估优化后的系统是否更好地利用了计算资源,并获得资源利用率提高的数据。根据系统处理更大规模任务时的性能变化,评估优化后的系统的扩展性,能否应对未来增加的计算需求和更大规模的任务,并获取可扩展性的数据。根据系统运行过程中的错误处理能力和故障恢复时间,评估优化后的系统的容错能力,是否保持了稳定的性能,能否应对异常情况和故障,并获得稳定性和可靠性的数据。根据系统的修改和维护难易程度,评估优化后的系统的可维护性,并获取可维护性的数据。通过对评估结果分析,判断是否对整个系统进行优化和迭代。例如,一个系统中有100个任务需要执行,通过评估任务完成率可以得到任务在系统中的执行情况。如果有90个任务成功完成,则任务完成率为90%。另外,系统中有一个任务的响应时间为10秒,通过评估任务响应时间可以得到系统的任务执行效率。如果系统中大多数任务的响应时间在5秒以内,则可以认为系统的任务响应时间较短。此外,系统的能耗在优化之前是1000瓦,优化后降低到800瓦,通过评估能耗减少的百分比可以得到能耗的降低程度,能耗减少的百分比为20%。系统的计算资源利用率在优化之前为50%,优化后提高到70%,通过评估资源利用率提高的数据可以得出系统更好地利用了计算资源,计算资源利用率提高了40%。系统在处理1000个任务时的性能为100秒,通过评估系统的扩展性可以判断系统是否能应对未来更大规模的任务。如果系统在处理2000个任务时的性能也为100秒,则系统具有良好的可扩展性。另外,假设系统在运行过程中的错误处理能力很强,故障恢复时间较短。通过评估容错能力可以判断系统是否能应对异常情况和故障。如果系统在出现错误时能够快速恢复并保持稳定的性能,则系统具有较高的稳定性和可靠性。系统的修改和维护较为困难,需要花费大量时间和资源。通过评估可维护性可以判断系统的修改和维护难易程度。如果系统的修改和维护较为简单,可以快速进行更新和维护,则系统具有较高的可维护性。通过对以上评估结果的分析,可以判断系统是否需要进行优化和迭代。如果系统的任务完成率、能耗减少程度、资源利用率、可扩展性、稳定性和可维护性等方面都有明显改进的空间,那么就可以考虑对整个系统进行优化和迭代。
以上实施例仅用以说明本发明的技术方案而非限定,仅仅参照较佳实施例对本发明进行了详细说明。本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
- 一种基于动态任务粒度的负载均衡集群渲染方法
- 一种RPA集群机构及基于RPA集群机构的任务处理方法
- 基于动态最优路径规划的多任务无人集群控制系统及方法