一种支持指代消解和一语多义的多任务学习对话方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及智能对话领域,更具体地说,涉及一种支持指代消解和一语多义的多任务学习对话方法。
背景技术
智能对话系统目前广泛应用于客服、营销、企业服务等多方场景,依托于对话系统的对话机器人以文本、语音和多模态的产品形式,辅助或替代人工对话,赋能对话全流程以实现降本增效。
受益于人工智能的技术突破和产品落地,对话机器人赛道从2015年开始快速升温,在2018年融资事件数量达到峰值,而后进入平稳发展阶段。《2021年中国对话机器人chatbot行业发展研究报告》指出:2020年对话机器人行业市场规模为27.1亿元,预计在2025年将达到98.5亿元。从行业竞争格局来看,参与企业类型丰富,厂商以语音能力、语义能力、平台能力、标准化产品、垂类场景等策略切入市场,在发展中策略又趋于融合。因此,研究出更智能、更加符合人类语言习惯的智能对话系统成为行业亟待解决的问题。
在用户的真实日常聊天中,经常会出现指代的说法,如“北京的天气好的话,我明天想坐飞机去那里旅游”,而传统的对话系统无法快速实现识别文本中的指代词和零代词所指代的被指代词,导致多轮对话无法连贯回复用户的问题;同时,用户也经常会在一句话中说明多种意图,如:“我想打开空调然后关闭天窗”,这句话中包含了“我想打开空调”的意图和“关闭天窗”的意图,而传统的对话系统只能识别单一意图,无法理解用户的真正意图。
发明内容
本发明为解决现有技术处理的缺陷和不足,提供一种支持指代消解和一语多义的多任务学习对话方法。
为实现上述目的,本发明采取的技术方案是一种支持指代消解和一语多义的多任务学习对话方法,所述方法通过指代消解模型、一语多义模型、多任务学习模型实现,所述方法包括以下步骤,
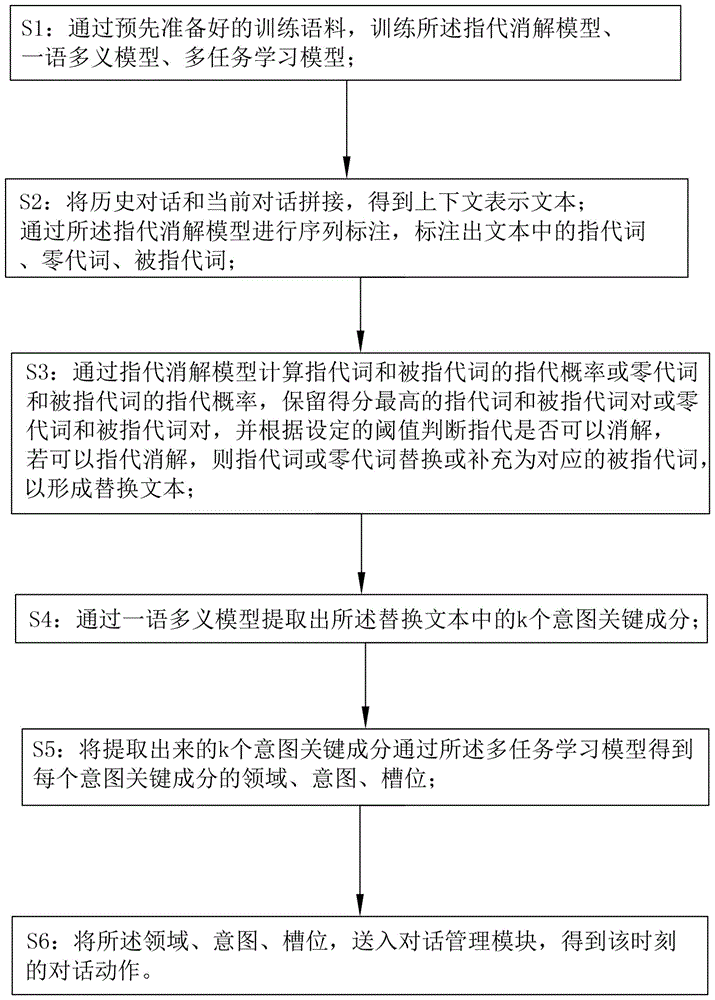
S1:通过预先准备好的训练语料,训练所述指代消解模型、一语多义模型、多任务学习模型;
S2:将历史对话和当前对话拼接,得到上下文表示文本,通过所述指代消解模型进行序列标注,标注出文本中的指代词、零代词、被指代词;
S3:通过指代消解模型计算指代词和被指代词的指代概率或零代词和被指代词的指代概率,保留得分最高的指代词和被指代词对或零代词和被指代词对,并根据设定的阈值δ判断指代是否可以消解,若可以指代消解,则指代词或零代词替换或补充为对应的被指代词,以形成替换文本;
S4:通过一语多义模型提取出所述替换文本中的k个意图关键成分;
S5:将提取出来的k个意图关键成分通过所述多任务学习模型得到每个意图关键成分的领域、意图、槽位;
S6:将所述领域、意图、槽位,送入对话管理模块,得到该时刻的对话动作。
所述S1包括以下步骤:
S1.1:训练所述指代消解模型,所述指代消解模型包括CRF层和线性分类层,所述CRF层用于识别指代词、零代词和被指代词,所述线性分类层用于进行指代概率计算以及领域和意图分类,针对零指代和共指两种情况,设计两种序列标注方式,对训练语料的指代词、零代词和被指代词进行标注,通过标注好的训练语料训练BERT+CRF模型并优化损失函数,再通过指代词向量和被指代词的向量计算指代概率;
S1.2:训练所述一语多义模型,对训练语料的意图关键成分进行标注:对训练语料进行预处理,通过预处理过后的训练语料训练BERT+CRF模型,再通过Adam优化方法优化其损失函数,以得到训练好的一语多义模型;
S1.3:训练所述多任务学习模型,统计训练语料的意图、槽位的数据样本量,确定数据样本的比例,并转换成整数,确定每次迭代的次数,确保每轮每类样本比例基本一致,并创建迭代器,将样本数据用于训练多任务学习模型,直至迭代器中数据为空,并通过线性分类层预测领域和意图,CRF层预测槽位,优化总损失函数,得到训练好的多任务学习模型。
所述S1.1包括以下步骤:
S1.1.1:针对零指代和共指两种情况,设计两种序列标注方式:所述被指代词,以span1作为标识符,BMES为词的位置符;所述零代词,加入零代词的上下文字符,以span_start和span_end作为标识符;所述指代词用span2作为标识符,BMES为词的位置符,同时加入其上下文字符,对训练语料的指代词、零代词和被指代词进行预处理;
S1.1.2:训练BERT+CRF模型,采用预处理过的训练语料对BERT+CRF模型进行训练,BERT+CRF模型将预处理过的训练语料转化成向量并对其进行分类处理,通过Adam优化方法优化损失函数,以得出训练好的指代消解模型;
S1.1.3:根据识别出的指代词向量或零代词向量vec
vec
logit
其中,vec
其中,loss
所述S1.2包括以下步骤:
S1.2.1:通过BMES标注方法对训练语料的k个意图关键成分进行标注;
S1.2.2:采用BERT预训练模型将标注好的k个意图关键成分转化成向量,再通过CRF模型进行序列标注,以此训练BERT+CRF模型;
S1.2.3:通过Adam优化方法优化损失函数,得到训练好的一语多义模型。
所述S1.3包括以下步骤:
S1.3.1:统计训练语料的意图、槽位的数据样本量,确定数据样本的比例并转换成整数,确定每次迭代的次数,保证每轮每类数据样本比例一致;
S1.3.2:创建迭代器,每次分别取出比例一致的槽位数据样本和意图数据样本用于训练模型,直到迭代器中数据为空,则进入下一轮训练;
S1.3.3:通过线性分类层进行意图分类和领域分类,所述意图识别损失函数为预测输出与真实意图的交叉熵;
S1.3.4:通过CRF层预测槽位的BMES标签;
S1.3.5:优化总损失函数,得到训练好的多任务学习模型。所述总损失函数为意图识别损失函数和槽位识别损失函数的加权和,如下:
loss=α×loss
其中,loss
所述S2包括以下步骤:
S2.1:将历史对话和当前对话拼接以得到上下文表示文本,再通过BERT预训练模型转化成向量;
S2.2:通过所述指代消解模型的CRF层识别出文本中的指代词、零代词和被指代词。
所述S3包括以下步骤:
S3.1:通过指代消解模型的线性分类层计算指代词与被指代词或零代词与被指代词之间的指代概率;
S3.2:保留得分最高的指代词和被指代词对或零代词和被指代词对,并根据设定的阈值δ判断指代是否可以消解,若可以指代消解,则指代词或零代词替换或补充为对应的被指代词,以形成替换文本。
所述对话管理模块,包括对话状态维护模块和生成系统决策模块,所述对话状态维护模块是根据第t个时刻的对话状态S
S
其中,函数f
所述生成系统决策模块是指根据所述对话状态模块中的对话状态St,产生系统行为反馈Action
Action
其中,函数f
本发明的有益效果:
本发明提供了一种支持指代消解和一语多义的多任务学习对话方法,通过引入指代消解模型、一语多义模型和多任务学习模型,提出了一种智能的多轮对话系统,从而能够更加快速、精准地理解用户的意图,完成用户期望的对话回复动作。通过实验验证,相对传统的串行式对话系统,本发明能够缩短响应时间,提高对话准确率。
附图说明
图1为本发明一种支持指代消解和一语多义的多任务学习对话方法的步骤图。
具体实施方式
下面结合附图对本发明作进一步地详细的说明,这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,本具体实施的方向以图1方向为标准。
如图1所示,一种支持指代消解和一语多义的多任务学习对话方法,所述方法通过指代消解模型、一语多义模型、多任务学习模型实现,所述方法包括以下步骤,
S1:通过预先准备好的训练语料,训练所述指代消解模型、一语多义模型、多任务学习模型;
S2:将历史对话和当前对话拼接,得到上下文表示文本,通过所述指代消解模型进行序列标注,标注出文本中的指代词、零代词、被指代词;
S3:通过指代消解模型计算指代词和被指代词的指代概率或零代词和被指代词的指代概率,保留得分最高的指代词和被指代词对或零代词和被指代词对,并根据设定的阈值δ判断指代是否可以消解,若可以指代消解,则指代词或零代词替换或补充为对应的被指代词,以形成替换文本;
S4:通过一语多义模型提取出所述替换文本中的k个意图关键成分,K={key_span
S5:将提取出来的k个意图关键成分通过所述多任务学习模型得到每个意图关键成分的领域domain
例如:K→{(domain
domain
intent
slots
S6:将所述领域、意图、槽位,送入对话管理模块,得到该时刻的对话动作。
本发明中的多任务学习模型同时学习领域分类、意图分类、槽位识别3种任务,指代消解模型用于将对话文本中的指代词或零代词用对应的被指代词进行替换消解,一语多义模型用于提取对话文本中的多个意图关键成分。
意图是指智能对话中用户所需要完成的具体任务,如“查询有没有下雨”、“导航去目的地”。
领域:领域分类,又称主题标注或主题识别,是一种文本分类方法,用于为各种类型和长度的文档分配文档领域或类别标签。一个“领域”或“类别”可以被理解为一个会话领域,一个特定的行业部分,甚至是一个特定的文本流派,这取决于应用程序。比如,“查询有没有下雨”和“查询有没有下雪”都属于“天气”领域。
意图关键成分是指智能对话中涉及用户所需要完成的具体任务的关键成分,例如“导航去某某公司”,其对应的意图为导航去目的地。
所述S1包括以下步骤:
S1.1:训练所述指代消解模型,所述指代消解模型包括CRF层和线性分类层,所述CRF层用于识别指代词、零代词和被指代词,所述线性分类层用于进行指代概率计算以及领域和意图分类,针对零指代和共指两种情况,设计两种序列标注方式,对训练语料的指代词、零代词和被指代词进行标注,通过标注好的训练语料训练BERT+CRF模型并优化损失函数,再通过指代词向量和被指代词的向量计算指代概率;
S1.2:训练所述一语多义模型,对训练语料的意图关键成分进行标注:对训练语料进行预处理,通过预处理过后的训练语料训练BERT+CRF模型,再通过Adam优化方法优化其损失函数,以得到训练好的一语多义模型;
S1.3:训练所述多任务学习模型,统计训练语料的意图、槽位的数据样本量,确定数据样本的比例,并转换成整数,确定每次迭代的次数,确保每轮每类样本比例基本一致,并创建迭代器,将样本数据用于训练多任务学习模型,直至迭代器中数据为空,并通过线性分类层预测领域和意图,CRF层预测槽位,优化总损失函数,得到训练好的多任务学习模型。
所述S1.1包括以下步骤:
S1.1.1:针对零指代和共指两种情况,设计两种序列标注方式:所述被指代词,以span1作为标识符,BMES为词的位置符;所述零代词,加入零代词的上下文字符,以span_start和span_end作为标识符;所述指代词用span2作为标识符,BMES为词的位置符,同时加入其上下文字符,对训练语料的指代词、零代词和被指代词进行预处理;
例如:“能看看最近有几趟高铁去珠海,然后看看那里的天气如何。”
珠海:B-span1 E-span1,那里:span_start B-span2 E-span2 span_end。
又例如:“搜查王小波的作品,我不知道名字。”
王小波的作品:B-span1 M-span1 M-span1 M-span1 M-span1 E-span1,
道(零代词)名:span_start span_end。
S1.1.2:训练BERT+CRF模型,采用预处理过的训练语料对BERT+CRF模型进行训练,BERT+CRF模型将预处理过的训练语料转化成向量并对其进行分类处理,通过Adam优化方法优化损失函数,以得出训练好的指代消解模型;
CRF的损失函数具体计算方法如下;
其中,x为观测序列,y为标签序列l的隐状态序列。
S1.1.3:根据识别出的指代词向量或零代词向量vec
其中,vec
其中,loss
所述S1.2包括以下步骤:
S1.2.1:通过BMES标注方法对训练语料的k个意图关键成分进行标注;
S1.2.2:采用BERT预训练模型将标注好的k个意图关键成分转化成向量,再通过CRF模型进行序列标注,以此训练BERT+CRF模型;
S1.2.3:通过Adam优化方法优化损失函数,得到训练好的一语多义模型。
例如:训练语料为“风扇关掉,然后打开空调”,其意图关键成分K={风扇关掉,打开空调}。
所述S1.3包括以下步骤:
S1.3.1:统计训练语料的意图、槽位的数据样本量,确定数据样本的比例并转换成整数,确定每次迭代的次数,保证每轮每类数据样本比例一致;
S1.3.2:创建迭代器,每次分别取出比例一致的槽位数据样本和意图数据样本用于训练模型,直到迭代器中数据为空,则进入下一轮训练;
S1.3.3:通过线性分类层进行意图分类和领域分类,所述意图识别损失函数为预测输出与真实意图的交叉熵;
S1.3.4:通过CRF层预测槽位的BMES标签;
S1.3.5:优化总损失函数,得到训练好的多任务学习模型。所述总损失函数为意图识别损失函数和槽位识别损失函数的加权和,如下:
loss=α×loss
其中,loss
所述S2包括以下步骤:
S2.1:将历史对话和当前对话拼接以得到上下文表示文本,再通过BERT预训练模型转化成向量;
S2.2:通过所述指代消解模型的CRF层识别出文本中的指代词、零代词和被指代词。
所述S3包括以下步骤:
S3.1:通过指代消解模型的线性分类层计算指代词与被指代词或零代词与被指代词之间的指代概率;
S3.2:保留得分最高的指代词和被指代词对或零代词和被指代词对,并根据设定的阈值δ判断指代是否可以消解,若可以指代消解,则指代词或零代词替换或补充为对应的被指代词,以形成替换文本。
例如:历史对话为“你能看看最近有几趟高铁去珠海吗”,当前对话为“我看看那里的天气如何。”拼接后的上下文表示文本为“你能看看最近有几趟高铁去珠海吗,我看看那里的天气如何。”CRF层识别出的指代词为“那里”,被指代词为“珠海”。计算“那里”与“珠海”之间的指代概率,若该指点概率超过设定的阈值δ,则进行指代消解,其替换文本为“你能看看最近有几趟高铁去珠海吗,我看看珠海的天气如何。”设定的阈值δ可以根据用户所需进行预设,一般可以是0.8,0.9或是其他数值。
所述对话管理模块,包括对话状态维护模块和生成系统决策模块,所述对话状态维护模块是根据第t个时刻的对话状态S
S
其中,函数f
所述生成系统决策模块是指根据所述对话状态模块中的对话状态S
Action
其中,函数f
本发明还包括一种支持指代消解和一语多义能力的多任务学习对话的系统,该系统通过上述方法实现,该系统包括以下模块:
上下文信息表示模块、深度检测模块、替换模块、一语多义识别模块、意图词槽多任务学习模块、对话管理模块。
所述上下文信息表示模块,将历史对话和当前对话拼接得到上下文表示文本,然后标注出上下文表示文本中的指代词、零代词、被指代词。
所述深度检测模块,是指判断上下文表示文本中是否存在指代现象,并识别零代词、指代词以及被指代词,并计算零代词与被指代词或指代词与被指代词之间的指代概率,若指代概率大于设定的阈值δ,则判定为可以指代,否则判定为不可指代。
所述替换模块,是指将可以指代的指代词或零代词替换成被指代词。
所述一语多义识别模块,是指通过特征提取的方式识别上下文表示文本中出现的k个意图关键成分K={key_span
所述领域意图词槽多任务学习模块,是将意图关键成分K通过预训练模型表示文本特征,再通过CRF层和线性分类层同时识别出文本第i个意图关键成分的领域、意图、槽位。
所述对话管理模块,包括对话状态维护模块和生成系统决策模块,所述对话状态维护模块是根据第t个时刻的对话状态S
S
其中,函数f
所述生成系统决策模块是指根据所述对话状态模块中的对话状态S
Action
其中,函数f
本发明能同时识别代词和零代词的指代消解问题,并且能够根据实际效果灵活的设置触发替换的阈值,适合工程化实践;由于本发明不是通过传统的多分类意图识别方式进行一语多义检测,而是通过识别意图关键成分的方式,本发明能够识别2个以上意图上的多意图任务,从而能更加智能和精准地理解用户的真实意图;本发明不同于传统的领域、意图、实体识别串行模型,采用了融合式的多任务学习模型来识别意图关键成分的领域、意图和实体,能够充分利用文本中的各种特征,并且能够加速NLU的响应。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 一种端到端的多任务学习的对话指代消解方法及系统
- 一种基于对抗多任务学习的统一语义性中文文本润色方法